ElasticSearch学习
- 一、 初识ES
- 1、 认识与安装
- 2、 倒排索引
- 2.1 正向索引
- 2.2 倒排索引
- 3、 基本概念
- 3.1 文档和字段
- 3.2 索引和倒排
- 4 、 IK分词器
- 二、 操作
- 1、 mapping 映射属性
- 2、 索引库增删改查
- 3、 文档的增删改查
- 3.1 新增文档
- 3.2 查询文档
- 3.3 删除文档
- 3.4 修改文档
- 3.5 批处理
- 三、 RestAPI
- 3.1 索引库操作
- 3.1.1 创建索引库
- 3.1.2 删除索引库
- 3.1.3 查找索引库
- 3.2 文档操作
- 3.2.1 新增文档
- 3.2.2 查询文档
- 3.2.3 删除文档
- 3.2.4 修改文档
- 3.3 批量导入文档
一、 初识ES
1、 认识与安装
官网:https://www.elastic.co/cn/elasticsearch
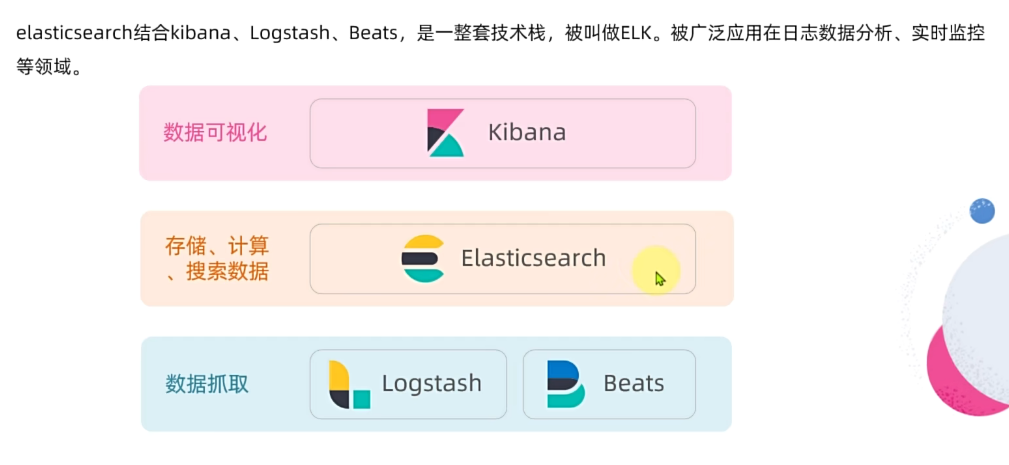
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
- 对Elasticsearch数据的搜索、展示
- Elasticsearch数据的统计、聚合,并形成图形化报表、图形
- 对Elasticsearch的集群状态监控
- 它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
安装es
// 安装命令
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
端口 9200:
这是用于 HTTP 协议的端口,客户端通过这个端口发送 REST API 请求来与 Elasticsearch 交互,比如索引数据、查询数据、管理集群等。通常你用浏览器或 REST 客户端访问的都是这个端口。
端口 9300:
这是用于 集群内部节点通信和 Java Transport 协议的端口。Elasticsearch 集群中的节点通过该端口相互通讯,比如数据同步、节点发现和分片分配等。除非你搭建多节点集群,否则普通用户一般不会直接访问这个端口。
安装 kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
安装完成后,直接访问5601端口,即可看到控制台页面:
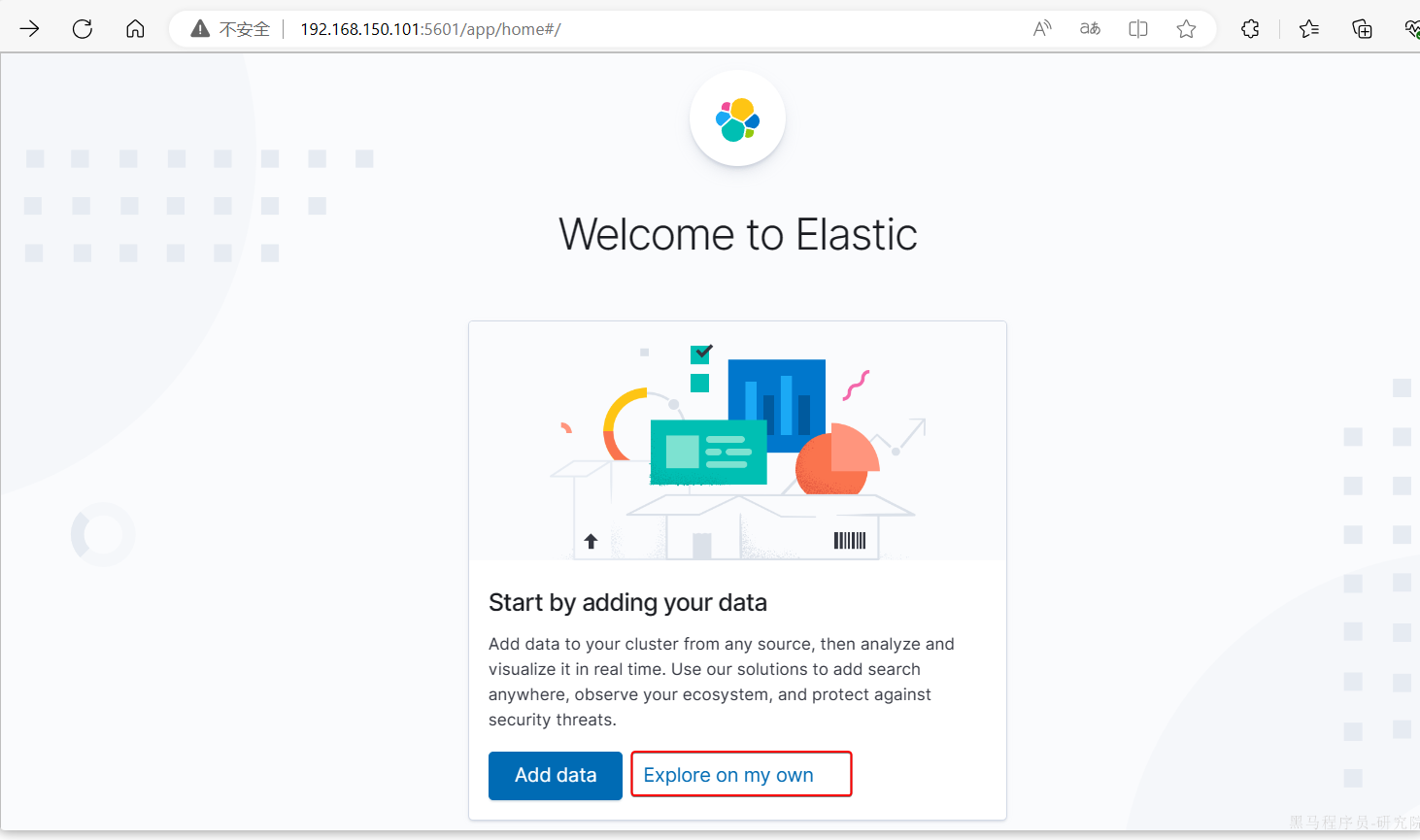
选择Explore on my own之后,进入主页面:
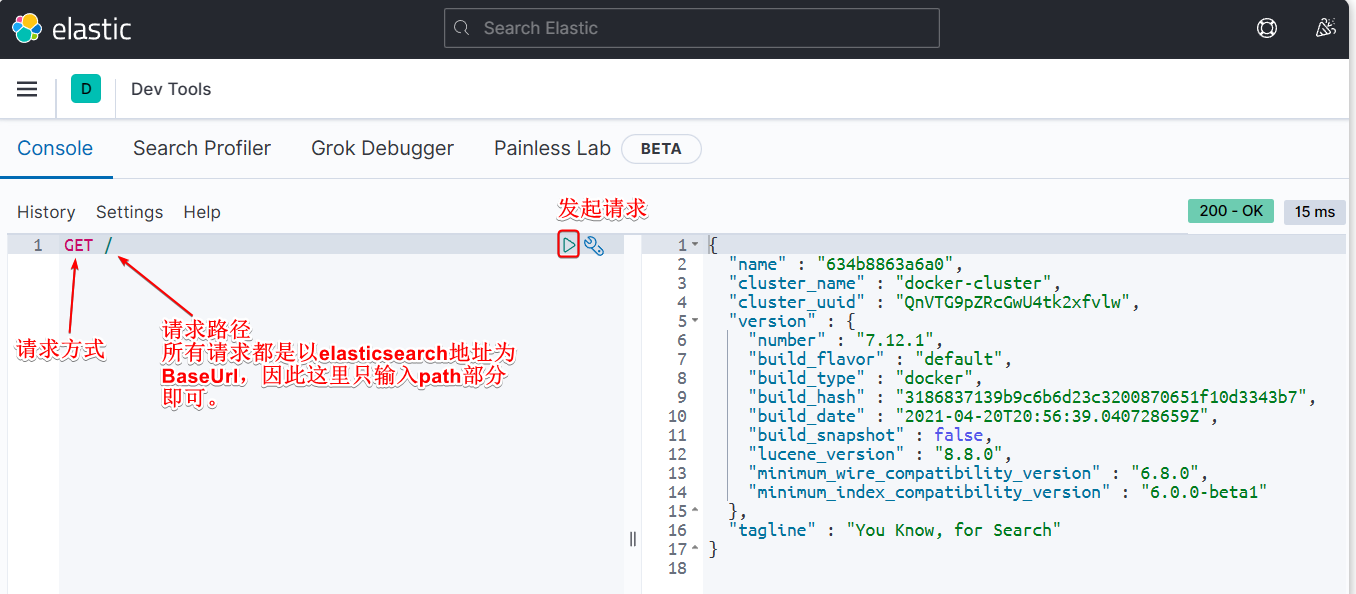
然后选中Dev tools,进入开发工具页面:
2、 倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术。那么什么是倒排索引呢?
倒排索引的概念是基于MySQL这样的正向索引而言的。
2.1 正向索引
例如有一张名为tb_goods的表:
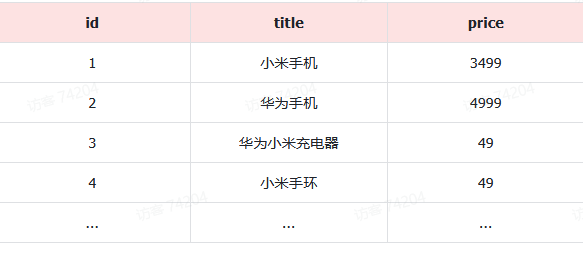
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此我们根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like ‘%手机%’;
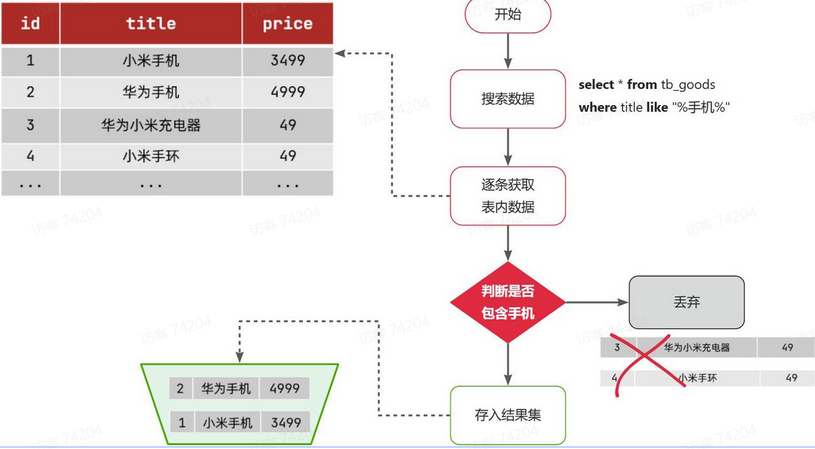
说明:
- 1)检查到搜索条件为like ‘%手机%’,需要找到title中包含手机的数据
- 2)逐条遍历每行数据(每个叶子节点),比如第1次拿到id为1的数据
- 3)判断数据中的title字段值是否符合条件
- 4)如果符合则放入结果集,不符合则丢弃
- 5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
2.2 倒排索引
倒排索引中有两个非常重要的概念:
- 文档(Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
- 词条(Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
- 将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建正向索引
此时形成的这张以词条为索引的的表,就是倒排索引
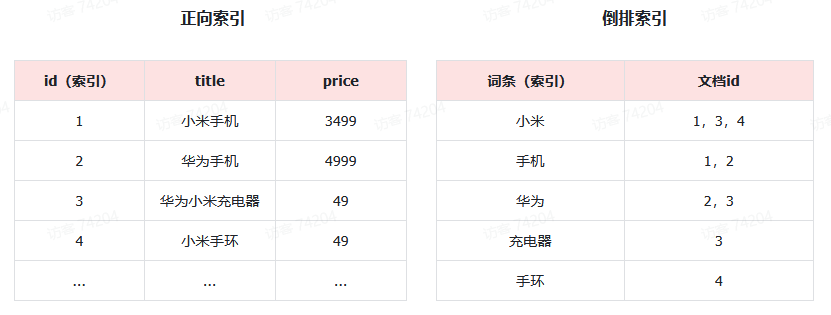
倒排索引搜索流程:
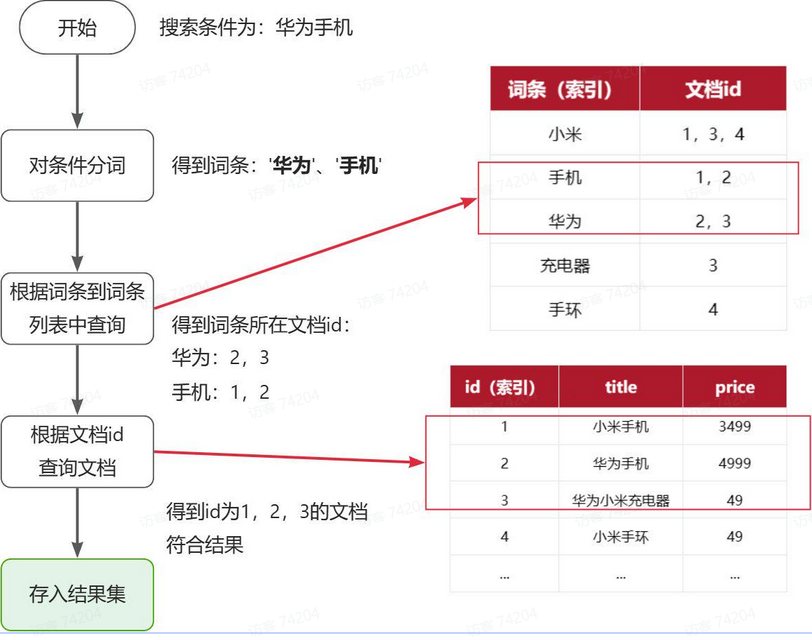
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
区别:
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引搜索速度很快
- 缺点
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索速度很快
- 缺点
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
3、 基本概念
3.1 文档和字段
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
3.2 索引和倒排
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等:
所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:

- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;
因此 索引相当于数据库中的表
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
ES 和 Mysql 对比:
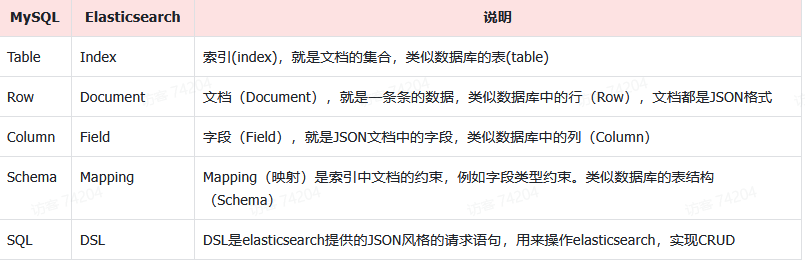
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
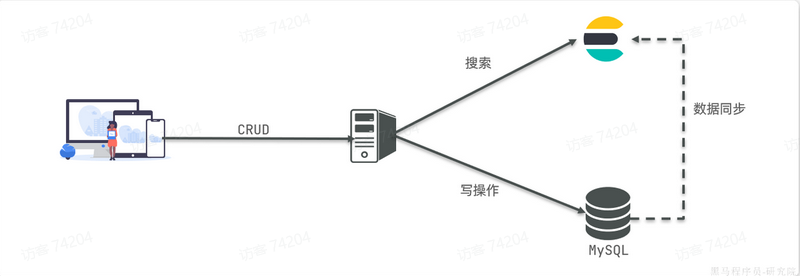
- 两者再基于某种方式,实现数据的同步,保证一致性
4 、 IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法。
安装
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip
// 重启
docker restart es
IK分词器包含两种模式:
- ik_smart:智能语义切分
- ik_max_word:最细粒度切分
POST /_analyze
{
"analyzer": "standard", // 这是es官方分词器
"text": "学习java太棒了"
}
结果是
{
"tokens" : [
{
"token" : "学",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "习",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "太",
"start_offset" : 11,
"end_offset" : 12,
"type" : "<IDEOGRAPHIC>",
"position" : 8
},
{
"token" : "棒",
"start_offset" : 12,
"end_offset" : 13,
"type" : "<IDEOGRAPHIC>",
"position" : 9
},
{
"token" : "了",
"start_offset" : 13,
"end_offset" : 14,
"type" : "<IDEOGRAPHIC>",
"position" : 10
}
]
}
使用IK分词器
POST /_analyze
{
"analyzer": "ik_smart",
"text": "学习java太棒了"
}
结果
{
"tokens" : [
{
"token" : "学习",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "java",
"start_offset" : 7,
"end_offset" : 11,
"type" : "ENGLISH",
"position" : 3
},
{
"token" : "太棒了",
"start_offset" : 11,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 4
}
]
}
拓展词典
要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
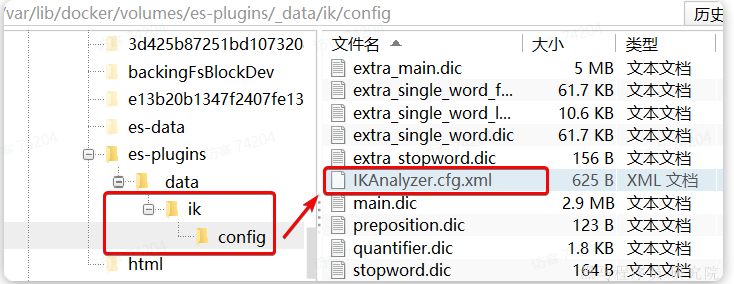
注意,如果采用在线安装的通过,默认是没有config目录的
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典-->
<entry key="ext_dict">ext.dic</entry>
</properties>
3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改
笑屎了
4) 重启es
二、 操作
1、 mapping 映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如:
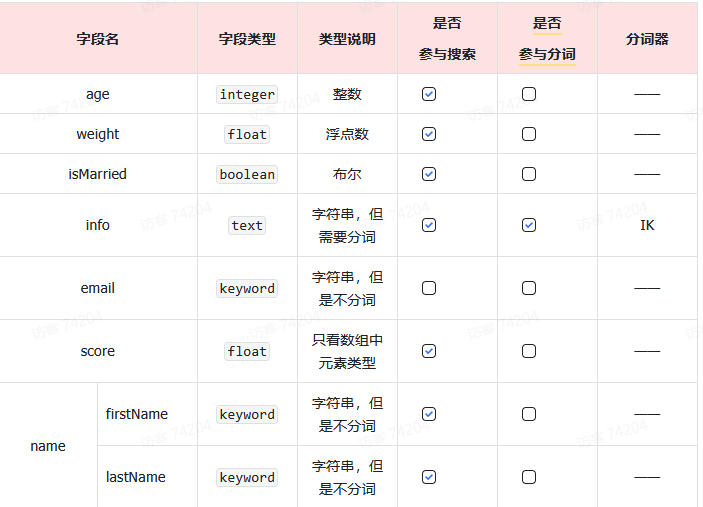
2、 索引库增删改查
由于Elasticsearch采用的是Restful风格的API,因此其请求方式和路径相对都比较规范,而且请求参数也都采用JSON风格。
我们直接基于Kibana的DevTools来编写请求做测试,由于有语法提示,会非常方便。
- 创建索引库
基本语法:
- 请求方式:/PUT
- 请求路径:/索引库名
- 请求参数:mapping映射
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
- 查询索引库
基本语法:
-
- 请求方式:GET
-
- 请求路径:/索引库名
-
- 请求参数:无
GET /索引库名
- 修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
- 删除索引库
基本语法:
-
- 请求方式:DELETE
-
- 请求路径:/索引库名
-
- 请求参数:无
总结:
-
- 创建索引库:PUT /索引库名
-
- 查询索引库:GET /索引库名
-
- 删除索引库:DELETE /索引库名
-
- 修改索引库,添加新字段:PUT /索引库名/_mapping
3、 文档的增删改查
3.1 新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
}
// 示例
POST /test/_doc/1
{
"info": "今天是端午节",
"email": "111@qq.com.cn",
"name": {
"firstName": "D",
"lastName": "H"
}
}
3.2 查询文档
GET /{索引库名称}/_doc/{id}
// 示例
GET/test1/_doc/1
3.3 删除文档
DELETE /{索引库名}/_doc/id值
// 示例
DELETE/test1/_doc/1
3.4 修改文档
修改有两种方式:
- 全量修改:直接覆盖原来的文档
- 局部修改:修改文档中部分字段
全量修改
全量修改是覆盖原来的文档,其本质是两步操作。1.根据指定id删除文档,新增一个相同id的文档
如果id不存在,那么就相当于新增一个id的文档
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}

局部修改
局部修改只修改指定id的文档中的部分字段
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}
3.5 批处理
批处理采用POST请求,基本语法如下
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
其中:
- index代表新增操作
- _index:指定索引库名
- _id:指定要操作的文档id
- {“filed1”:“value1”}:要新增的文档内容
- delete代表删除操作
- _index:指定索引库名
- _id :指定要操作的文档id
- update代表更新操作
- _index:指定索引库名
- _id :指定要操作的文档id
- {“doc”:{“filed2”:“value2”} }:要更新的字段
// 批量新增
POST /_bulk
{"index": {"_index":"test1", "_id": "3"}}
{"info": "C++", "email": "111222@q.com", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "前端", "email": "333444@qq.com", "name":{"firstName": "三", "lastName":"张"}}
// 批量删除
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}
三、 RestAPI
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求发送给ES。
官方文档地址:
https://www.elastic.co/guide/en/elasticsearch/client/index.html
// 引入es的RestHighLevelClient依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
写一个测试类:
package com.hmall.item.es;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class IndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.1.1:9200")
));
}
@Test
void testConnect() {
System.out.println(client);
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
3.1 索引库操作
3.1.1 创建索引库
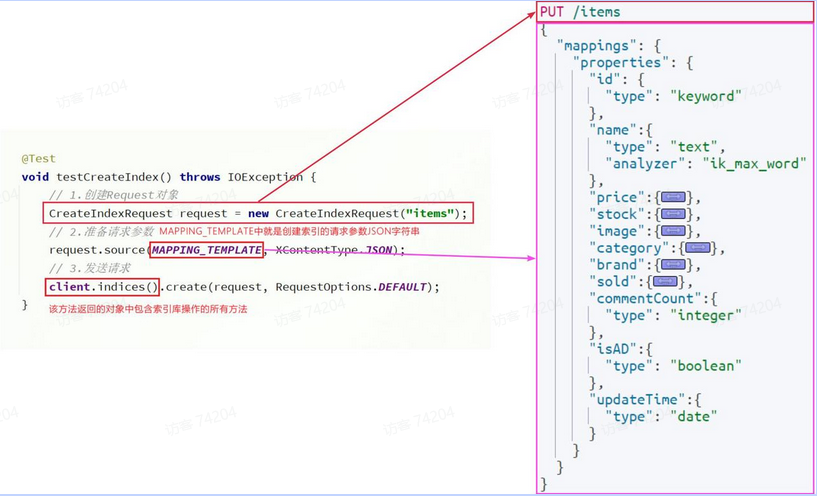
-
首先需要进行字段筛选,将需要索引的字段找出来,确定字段类型以及是否需要索引。
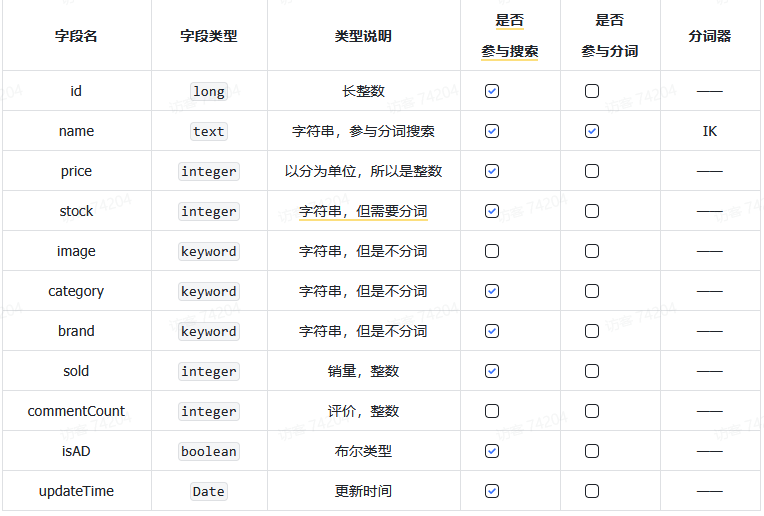
-
创建索引映射。就是索引语句。只需要mappings 部分
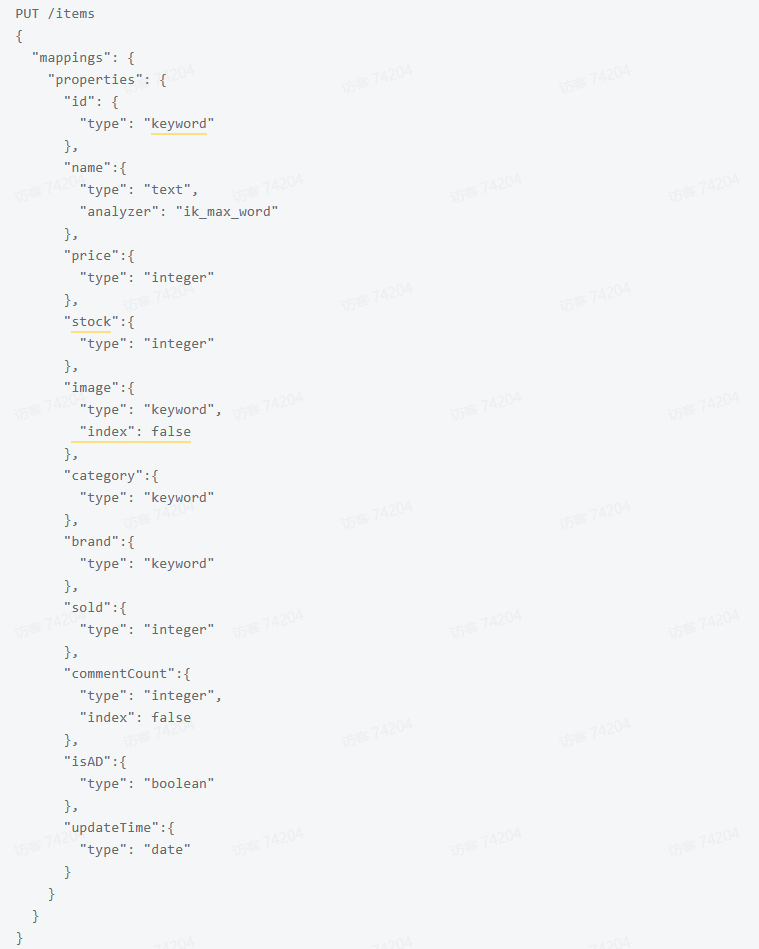
@Test
void testCreateIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("items");
// 2.准备请求参数
request.source("", XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
代码分为三步:
- 1)创建Request对象。因为是创建,所以使用CreateIndexRequest
- 2)添加请求参数:其实就是Json格式的Mapping映射参数。
- 3)发送请求
- client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。例如创建索引、删除索引、判断索引是否存在等
3.1.2 删除索引库
@Test
void testDeleteIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
3.1.3 查找索引库
@Test
void testExistsIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("items");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
3.2 文档操作
package com.hmall.item.es;
import com.hmall.item.service.IItemService;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest(properties = "spring.profiles.active=local")
public class DocumentTest {
private RestHighLevelClient client;
@Autowired
private IItemService itemService;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.1.1:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
3.2.1 新增文档
API语法为
POST /{索引库名}/_doc/1
{
"name": "Jack",
"age": 21
}
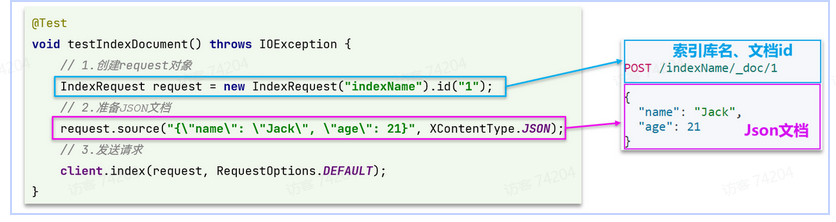
@Test
void testAddDocument() throws IOException {
// 1.根据id查询商品数据
Item item = itemService.getById(100002644680L);
// 2.转换为文档类型
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 3.将ItemDTO转json
String doc = JSONUtil.toJsonStr(itemDoc);
// 1.准备Request对象
IndexRequest request = new IndexRequest("items").id(itemDoc.getId());
// 2.准备Json文档
request.source(doc, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
3.2.2 查询文档
GET /{索引库名}/_doc/{id}
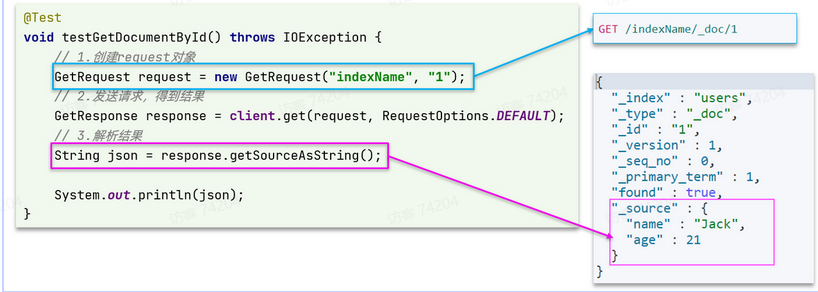
可以看到,响应结果是一个JSON,其中文档放在一个_source属性中,因此解析就是拿到_source,反序列化为Java对象即可。
@Test
void testGetDocumentById() throws IOException {
// 1.准备Request对象
GetRequest request = new GetRequest("items").id("100002644680");
// 2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.获取响应结果中的source
String json = response.getSourceAsString();
ItemDoc itemDoc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println("itemDoc= " + ItemDoc);
}
3.2.3 删除文档
DELETE /hotel/_doc/{id}
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request,两个参数,第一个是索引库名,第二个是文档id
DeleteRequest request = new DeleteRequest("item", "100002644680");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
3.2.4 修改文档
修改我们讲过两种方式:
- 全量修改:本质是先根据id删除,再新增
- 局部修改:修改文档中的指定字段
POST /{索引库名}/_update/{id}
{
“doc”: {
“字段名”: “字段值”,
“字段名”: “字段值”
}
}
在RestClient的API中,全量修改与新增的API完全一致,判断依据是ID:
- 如果新增时,ID已经存在,则修改
- 如果新增时,ID不存在,则新增
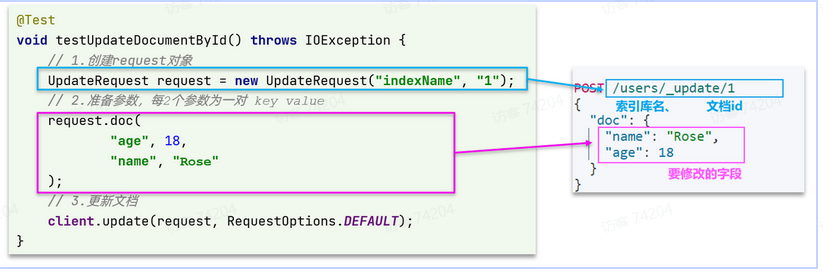
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("items", "100002644680");
// 2.准备请求参数
request.doc(
"price", 58800,
"commentCount", 1
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}
3.3 批量导入文档
我们如果要将这些数据导入索引库,肯定不能逐条导入,而是采用批处理方案。常见的方案有:
- 利用Logstash批量导入
- 需要安装Logstash
- 对数据的再加工能力较弱
- 无需编码
- 利用JavaAPI批量导入
- 需要编码
- 更加灵活
批处理与前面讲的文档的CRUD步骤基本一致:创建request,使用的是BulkRequest,准备参数,发送请求
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个IndexRequest请求,然后封装到BulkRequest中,一起发出。
- 批量删除,就是创建N个DeleteRequest请求,然后封装到BulkRequest,一起发出
- 因此BulkRequest中提供了add方法,用以添加其它CRUD的请求:
@Test
void testBulk() throws IOException {
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备请求参数
request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));
request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
@Test
void testLoadItemDocs() throws IOException {
// 分页查询商品数据
int pageNo = 1;
int size = 1000;
while (true) {
Page<Item> page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));
// 非空校验
List<Item> items = page.getRecords();
if (CollUtils.isEmpty(items)) {
return;
}
log.info("加载第{}页数据,共{}条", pageNo, items.size());
// 1.创建Request
BulkRequest request = new BulkRequest("items");
// 2.准备参数,添加多个新增的Request
for (Item item : items) {
// 2.1.转换为文档类型ItemDTO
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest()
.id(itemDoc.getId())
.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
// 翻页
pageNo++;
}
}