生成模型:从数据分布到样本创造
生成模型(Generative Model) 是机器学习中一类能够学习数据整体概率分布,并生成新样本的模型。其核心目标是建模输入数据 x 和标签 y 的联合概率分布 P(x,y),即回答 “数据是如何产生的”。
生成模型的核心能力
- 数据生成:通过学习数据分布,生成与训练集相似的新样本(如图像生成、文本生成)。
- 概率推断:计算数据的联合概率,用于异常检测、密度估计等任务。
- 因果建模:探索数据间的因果关系(如通过因果结构生成符合逻辑的样本)。
典型生成模型举例
- 变分自编码器(VAE):通过隐变量建模数据分布,将样本编码为潜在向量后解码生成新样本。
- 生成对抗网络(GAN):通过生成器与判别器的对抗训练,使生成样本接近真实数据分布。
- 自回归模型(如 GPT 系列):基于序列数据的历史信息,预测下一个 token 的概率分布,逐步生成完整序列。
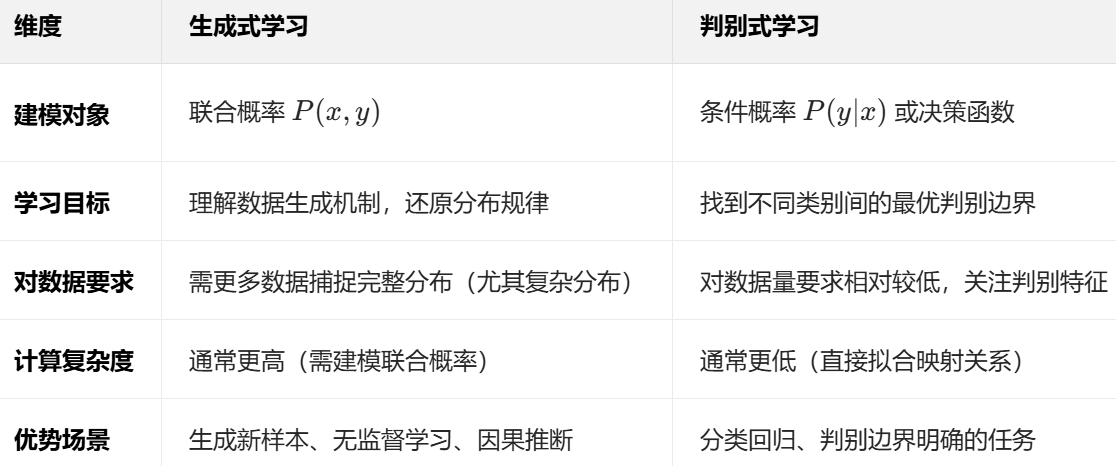
两种机器学习范式:生成式 vs. 判别式
机器学习的核心范式可分为生成式(Generative) 和判别式(Discriminative),二者在建模目标、应用场景上有本质区别:
一、生成式学习(Generative Learning)
- 建模目标:学习联合概率分布 P(x,y),即 “输入 x 和标签 y 同时出现的概率”。
- 核心逻辑:先理解数据如何生成,再通过生成过程进行预测。
- 数学表达:P(y∣x)=P(x)P(x,y),通过联合概率和边缘概率推导条件概率。
- 典型算法:隐马尔可夫模型(HMM)、朴素贝叶斯、VAE、GAN。
- 应用场景:
- 样本生成(如图像、文本、语音合成);
- 小样本学习(通过生成模型扩充数据);
- 无监督 / 半监督学习(探索数据分布)。
二、判别式学习(Discriminative Learning)
- 建模目标:直接学习条件概率分布 P(y∣x) 或决策函数 f(x),即 “给定输入 x,预测标签 y 的概率”。
- 核心逻辑:不关心数据生成过程,只关注不同类别间的边界和区分特征。
- 数学表达:直接建模输入到输出的映射关系,无需计算联合概率。
- 典型算法:逻辑回归、支持向量机(SVM)、决策树、神经网络(如 CNN、RNN)。
- 应用场景:
- 分类与回归(如图像分类、房价预测);
- 目标检测、语义分割等需要精准判别边界的任务;
- 实时预测(模型推理速度通常更快)。




![[特殊字符] 深入理解 Linux 内核进程管理:架构、核心函数与调度机制](https://i-blog.csdnimg.cn/direct/5a1d6f8c5cba4467ad891a42ad177176.png)

![[AI绘画]sd学习记录(二)文生图参数进阶](https://i-blog.csdnimg.cn/img_convert/15061a8f446d09b56ab8ba527d98e766.png)