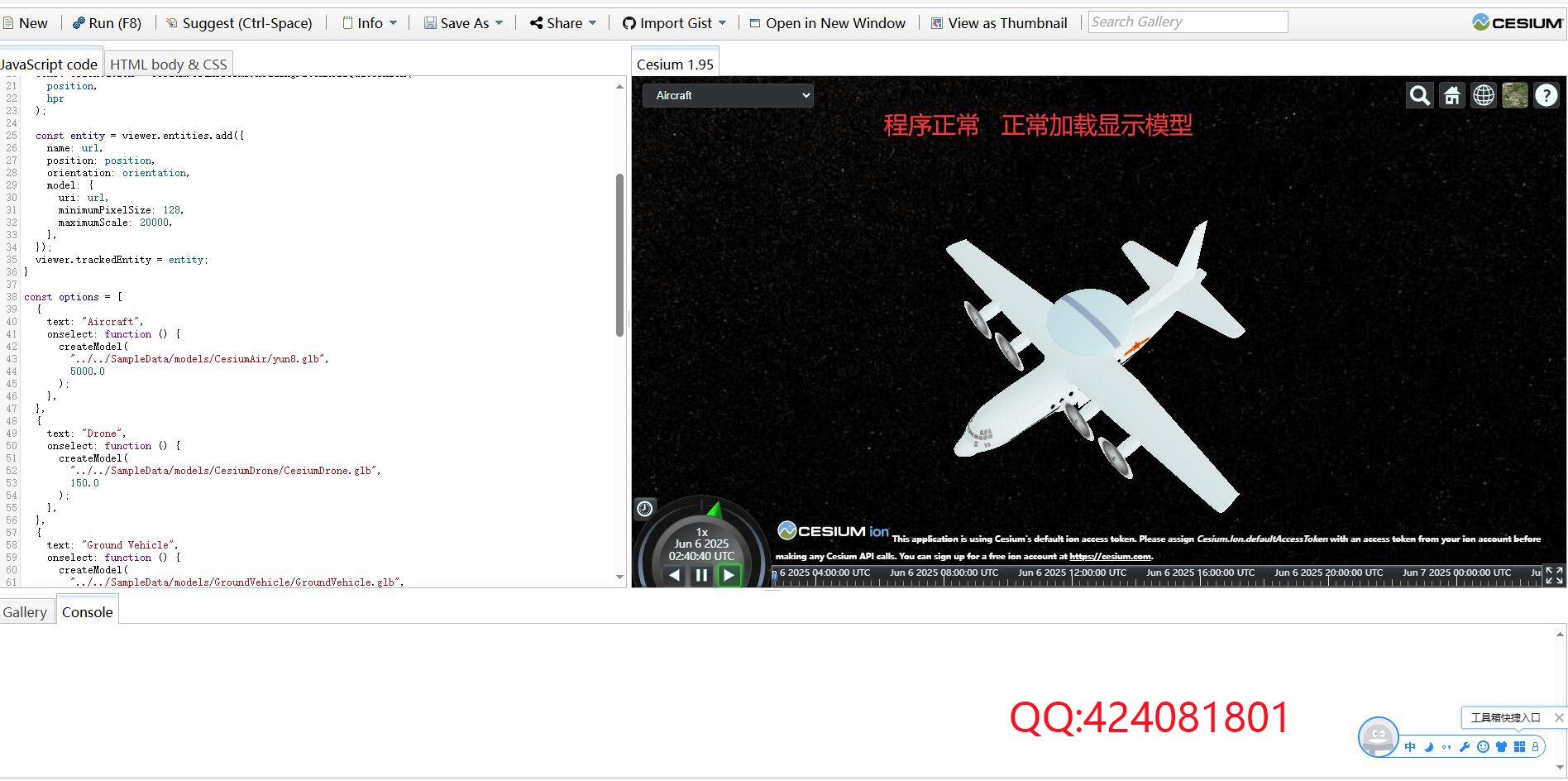
在自然语言处理(NLP)领域,词向量(Word Embedding)是基石般的存在。它将离散的符号——词语——转化为连续的、富含语义信息的向量表示,使得计算机能够“理解”语言。而在众多词向量模型中,FastText 凭借其独特的设计理念和卓越性能,尤其是在处理形态丰富的语言和罕见词方面,成为不可或缺的利器。本文将深入探讨词向量的核心概念、FastText的创新原理、技术优势、实现细节以及实际应用。
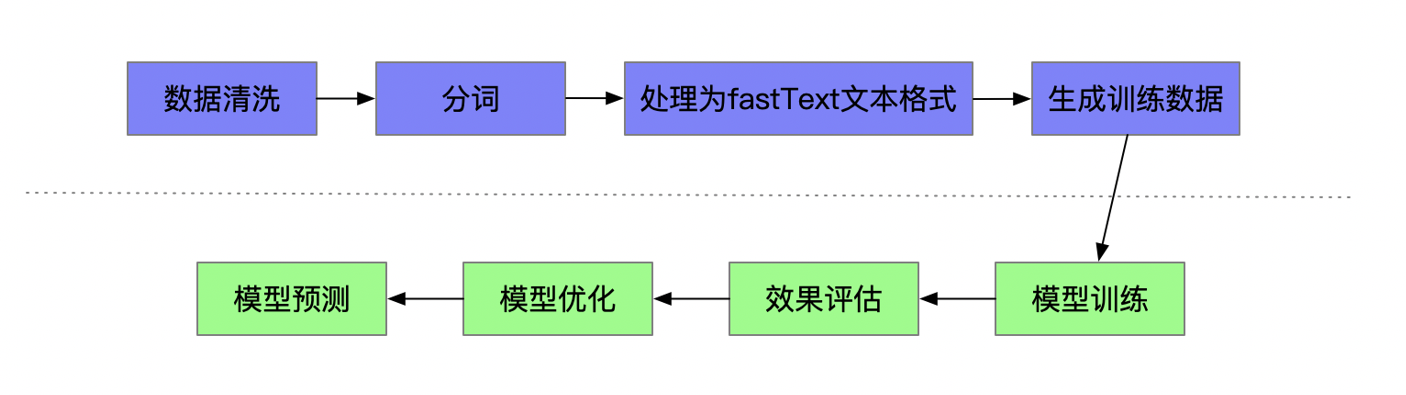
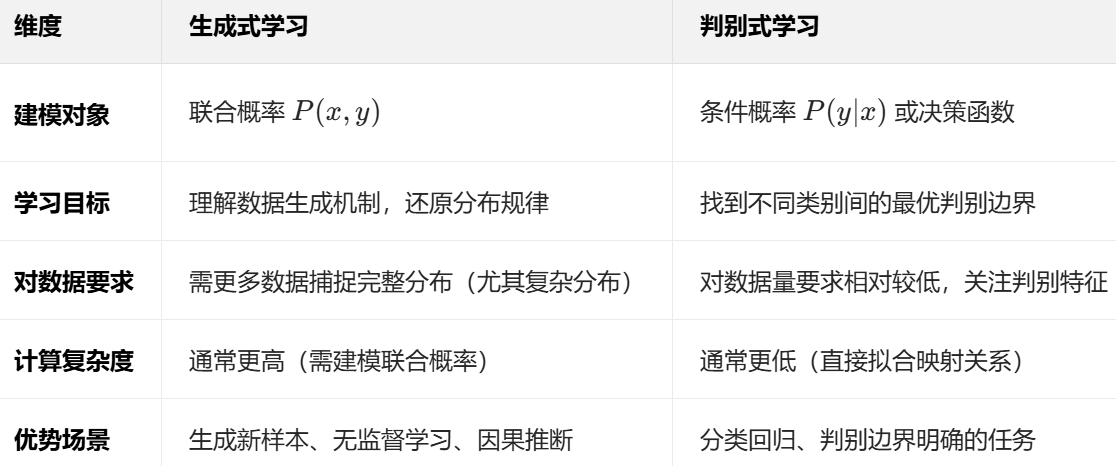
一、词向量:语言的数学化身
-
从离散到连续:One-Hot 的困境
-
传统方法(如 One-Hot Encoding)将每个词表示为一个巨大的稀疏向量(维度等于词汇表大小 V),其中只有对应词索引的位置为 1,其余为 0。
-
问题:
-
维度灾难 (Dimensionality Curse): V 可能极大(数万甚至数百万),计算和存储效率低下。
-
-






![[特殊字符] 深入理解 Linux 内核进程管理:架构、核心函数与调度机制](https://i-blog.csdnimg.cn/direct/5a1d6f8c5cba4467ad891a42ad177176.png)

![[AI绘画]sd学习记录(二)文生图参数进阶](https://i-blog.csdnimg.cn/img_convert/15061a8f446d09b56ab8ba527d98e766.png)