细胞类型注释是分析scRNA-seq数据异质性的关键任务。尽管最近的基础模型实现了这一过程的自动化,但它们通常独立注释细胞,未考虑批次水平的细胞背景或提供解释性推理。相比之下,人类专家常基于领域知识为不同细胞簇注释不同的细胞类型。为模拟这一工作流程,作者引入了CellPuzzles任务,其目标是为一批细胞分配唯一的细胞类型。该基准涵盖多种组织、疾病和供体条件,要求跨批次水平的细胞背景进行推理以确保标签唯一性。现成的 LLMs 在CellPuzzles任务上表现不佳,最佳基线模型(OpenAI的o1)仅实现19.0%的批次水平准确率。为填补这一空白,提出Cell-o1,这是一个70亿参数的LLM,通过对蒸馏的推理轨迹进行监督微调,再结合批次水平奖励的强化学习进行训练。Cell-o1实现了最先进的性能,比o1高出73%以上,并且在不同背景下具有良好的泛化能力。对训练动态和推理行为的进一步分析为批次水平注释性能和新兴的专家级推理提供了见解。
Cell-o1: Training LLMs to Solve Single-Cell Reasoning Puzzles with Reinforcement Learning
https://github.com/ncbi-nlp/cell-o1
目录
- 背景概述
- CellPuzzles:用于细胞类型注释的批次级推理
- Cell-o1:用于批次注释的推理LLM
- 用于结构化推理的提示模板
- 推理蒸馏和冷启动
- 推理蒸馏和拒绝采样
- SFT
- GRPO强化学习
- 数据集和metrics
背景概述
为scRNA-seq图谱分配准确的细胞类型,是理解不同组织、疾病和个体间生物学异质性的基础。传统注释流程高度依赖专家知识,通常包括通过聚类将相似细胞分组,然后基于生物领域知识手动检查标记基因表达以分配细胞类型标签。尽管这种方法准确性高,但耗时费力,在大规模或新数据集上的可扩展性有限。
深度学习领域的最新进展通过开发单细胞基础模型,显著提升了自动化细胞类型注释的水平。这些模型利用大规模无监督预训练来捕捉复杂的基因表达模式,从而实现更优的表征学习,并在各种下游任务中提升性能。与此同时,大语言模型(LLMs)也被适配于单细胞应用场景,具体方式包括将基因表达谱转化为文本表示(C2S),或整合多模态基因嵌入(LangCell)。然而:
- 基础模型和大语言模型通常独立注释每个细胞,未考虑共享的生物学背景或批次水平的基因表达信息,这与专家注释实践存在根本差异。
- 大多数自动化方法直接预测细胞类型,却不阐明潜在的推理过程,导致其决策难以解释和验证。
为了弥补这一差距,作者首先引入了CellPuzzles,这是一个将细胞类型注释构建为批次级推理任务的新型基准,紧密模拟专家注释工作流程。如图1所示,与传统方法独立标记每个细胞不同,CellPuzzles要求利用批次中所有细胞的基因表达谱和共享上下文元数据,为每个细胞联合分配唯一标签。大量评估表明,最先进的大型语言模型(LLMs)在该任务中表现不佳,性能最佳的模型(OpenAI的o1)仅实现了19.0%的批次级准确率,反映了该任务的复杂性。
Cell-o1是一种经过两阶段训练的推理增强型大语言模型(如图1所示):首先对从前沿大语言模型中蒸馏出的专家级推理轨迹进行监督微调(SFT),以引导结构化和可解释的决策;随后通过带有批次级奖励的强化学习(RL)来促进一致的、上下文感知的标签分配。在CellPuzzles任务中,Cell-o1在细胞级和批次级准确率上均优于所有基线模型。对训练动态、推理行为和预测误差的进一步分析,揭示了模型的泛化能力、可解释性和推理能力。值得注意的是,Cell-o1表现出了诸如自我反思和课程推理等新兴行为——前者指模型重新审视并修正早期预测,后者指模型在处理难题前优先解决简单案例,这两种行为均与人类专家采用的策略相似。

- 图1:Cell-o1整体概述。
CellPuzzles:用于细胞类型注释的批次级推理
在实际的单细胞分析中,细胞类型注释很少孤立地对单个细胞进行。相反,它通常在批次水平上进行,即对来自同一供体或样本的细胞群体进行联合分析。专家通常会根据基因表达谱对细胞进行聚类,为每个聚类确定代表性的标记基因,并通过整合表达模式和组织来源、疾病状态等背景元数据来分配标签。
为了模拟这一专家驱动的过程,引入了CellPuzzles——如图2所示的全新基准,该基准将细胞类型注释定义为批次级推理任务。从形式上讲,每个任务实例包含一批 N N N个细胞 C = c 1 , c 2 , . . . , c N C={c_{1}, c_{2}, ..., c_{N}} C=c1,c2,...,cN,每个细胞均取自同一供体和实验批次中的不同细胞类型。每个细胞 c i c_{i} ci作为聚类质心的代表,由其前 M M M个高表达基因的排序列表 g i = [ g i 1 , g i 2 , . . . , g i M ] g_{i}=[g_{i 1}, g_{i 2}, ..., g_{i M}] gi=[gi1,gi2,...,giM]表示,这些基因近似于专家用于定义和注释单细胞聚类的差异表达基因。
整个细胞批次关联有一个上下文描述 m m m,该描述源自供体水平的元数据,例如组织类型、疾病状态、性别、发育阶段以及其他可用的生物学相关属性。此外,还提供一个候选标签集 Y = y 1 , y 2 , … , y N Y = {y_1, y_2, …, y_N} Y=y1,y2,…,yN,其中包含该批次中N个细胞的真实细胞类型,并经过随机打乱以消除位置偏差。这种设置模拟了专家注释场景——细胞类型从生物学合理的候选池中选择,而非自由生成。目标是学习一个映射 f : C → Y f: C → Y f:C→Y,通过联合考虑基因表达谱和上下文元数据,将每个细胞分配到 Y Y Y中的唯一标签,同时生成可解释的推理轨迹以证明标签分配的合理性。

- 图2:CellPuzzles 从专家实际注释细胞的方式中获得启发,将细胞类型注释构建为整合基因表达和背景元数据的批次级推理任务。
如图3所示,CellPuzzles基于Cell×Gene网站中的人类单细胞数据集构建,涵盖多种组织、疾病状态和供体特征。

- 图3:CellPuzzles的数据分布。A) 按性别划分的年龄组分布。B) 不同疾病条件下的样本分布。C) 不同组织中观察到的细胞类型数量。为清晰起见,B)和C)中仅显示前20项。
Cell-o1:用于批次注释的推理LLM
基于CellPuzzles,引入Cell-o1,其模拟专家在批次级单细胞分析中的注释策略。该模型对高表达基因和共享生物学背景进行推理,以从给定的候选集中分配唯一的细胞类型标签。
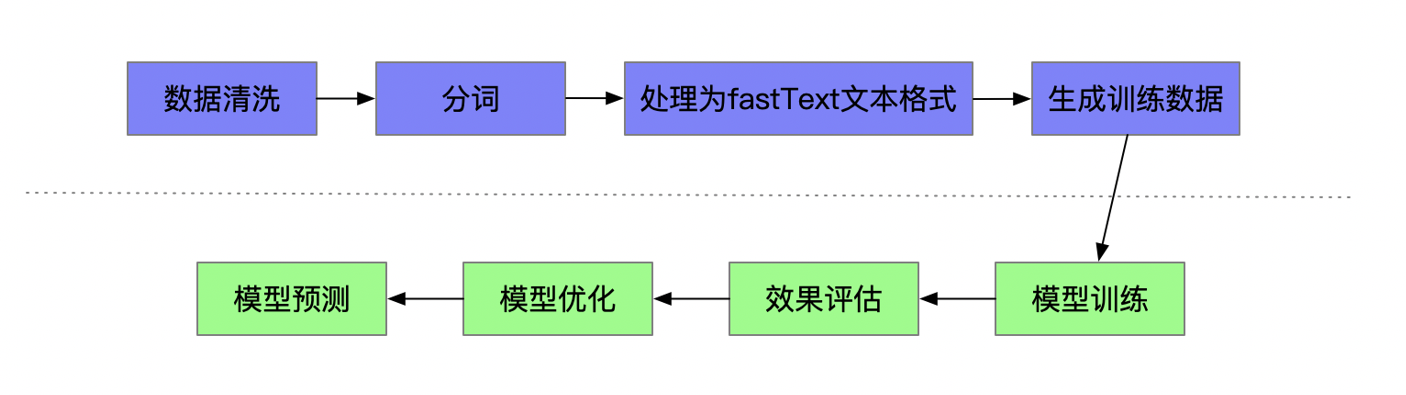
图1展示了训练策略。首先引入统一的提示模板,以标准化模型输出并在各个训练阶段保持格式一致。接下来,通过拒绝采样进行推理蒸馏,构建高质量的生物学解释数据集,随后进行监督微调(SFT)以实现冷启动初始化。最后,在批次级奖励信号的引导下,应用基于组相对策略优化(GRPO)的强化学习(RL)对模型进行进一步优化。
用于结构化推理的提示模板
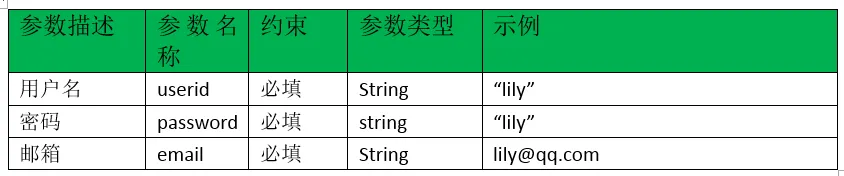
为确保各训练阶段的输出格式统一,作者设计了一个标准化提示模板,该模板适用于蒸馏、监督微调(SFT)和强化学习(RL)的整个过程。如表1所示,此模板通过指示模型整合背景信息并从候选集中为所有细胞联合分配细胞类型,推动对整个细胞批次的全局推理。

- 你是专门从事细胞类型注释的专家助理。将为你提供来自同一供体的N个细胞的批次,其中每个细胞代表一种独特的细胞类型。对于每个细胞,将按表达降序提供其高表达基因。请利用基因表达数据和供体信息,确定每个细胞的正确细胞类型。你还将收到一个包含N个候选细胞类型的列表,每个候选类型必须恰好分配给一个细胞。请确保综合考虑所有细胞和候选类型,而非单独注释每个细胞。请在
<thinking>和</thinking>标签内包含你的详细推理,并在<answer>和</answer>标签内提供最终答案。最终答案应为按顺序列出分配的细胞类型的单个字符串,以“ | ”分隔。
推理蒸馏和冷启动
基准测试中引入的批次级推理任务对模型训练提出了重大挑战。与传统分类任务不同,模型必须同时分析一组细胞,比较基因表达模式,纳入共享元数据,并生成一致的标签分配。输入和输出之间的高度相关性使得生成有效且正确的预测变得困难,尤其是在训练早期阶段。首先使用OpenAI的o1(一种具有强大多步推理能力的前沿大型语言模型)进行推理蒸馏,以构建高质量推理轨迹和预测的合成数据集。然后,该蒸馏数据集用于监督微调(SFT),作为后续强化学习(RL)的冷启动初始化。
推理蒸馏和拒绝采样
作者使用o1模型为CellPuzzles中的10,155个实例生成推理轨迹和预测结果。每个输入均搭配表1所示的标准化提示模板。对于每个实例,生成8条候选response。随后应用拒绝采样过滤低质量输出,仅当response满足以下条件时才被接受:(1)符合预期格式;(2)生成的细胞类型分配与真实标签完全一致。这一过程最终形成包含3,912个可接受示例的蒸馏数据集,对应38.52%的接受率。
收集的推理轨迹展现出引导模型学习专家注释行为的若干理想特性,并为监督微调(SFT)奠定了坚实基础:首先,它们通过引用已知基因marker和生物学关联,体现了领域特定知识;其次,它们展示了全局推理行为,即联合考虑多个细胞和候选标签以确保标签分配的一致性;第三,推理过程结构化且可解释,与最终预测分离,并以标准化的提示-响应格式呈现。
SFT
在进行强化学习(RL)之前,作者对蒸馏数据集应用监督微调(SFT)以初始化模型。尽管最终的训练目标涉及优化奖励信号,但作者发现,仅从纯预训练的大型语言模型开始无法实现有意义的学习进展。如果模型事先未接触过任务特定的推理格式和预测结构,它将难以生成有效的输出。在实践中,这会导致早期训练阶段持续出现格式错误和标签分配错误,进而导致奖励为零或负值,并使策略陷入停滞。
监督微调(SFT)作为一种冷启动机制,通过向模型提供结构化推理和正确预测的高质量示范来缓解这一问题。通过从蒸馏数据集中学习,模型获得了遵循指令、遵守所需响应格式以及对批次内多个实体进行推理的基本能力。这提高了响应的有效性,减少了奖励的稀疏性,并为强化学习(RL)阶段更稳定、高效的策略优化奠定了基础。
GRPO强化学习
为了减少RL的训练开销,使用GRPO。给定训练输入 x x x,GRPO从旧策略 π θ o l d \pi_{\theta_{old}} πθold中采样 G G G个候选响应 { y i } i = 1 G \left\{y_{i}\right\}_{i=1}^{G} {yi}i=1G。更新后的策略 π θ \pi_{\theta} πθ通过最大化进行优化:

其中,
r
i
r_{i}
ri为第
i
i
i个response的奖励值。
为了激励结构化推理并确保答案有效性,作者设计了一个基于规则的奖励函数,用于评估模型输出的格式和正确性。如表1所示,模型需要按照严格格式生成响应,其中必须包含一个由<thinking>...</thinking>标签包裹的推理段和一个由<answer>...</answer>标签包裹的答案段。标签错误或包含额外文本的响应将被视为无效,并受到惩罚。
为了验证response,作者提取预测的 answer
y
^
=
[
y
^
1
,
.
.
.
,
y
^
N
]
\widehat{\textbf{y}}=[\widehat{y}_{1},...,\widehat{y}_{N}]
y
=[y
1,...,y
N],与真实标签比较
y
=
[
y
1
,
.
.
.
,
y
N
]
\textbf{y}=[y_{1},...,y_{N}]
y=[y1,...,yN]:

1(·)是一个指示函数。此设置确保仅当批次中的所有细胞类型均被正确预测时才给予1的奖励;任何错误预测均导致奖励为0。
数据集和metrics
作者在提出的CellPuzzles基准上进行实验。每个任务实例包含 8 ≤N ≤15 个细胞,每个细胞由其排序的高表达基因列表和共享的供体水平上下文描述表示。在训练阶段,使用强推理模型进行推理蒸馏,生成3,912条高质量推理轨迹,用于监督微调(SFT)。此外,额外采样3,000个实例构建强化学习(RL)数据集,使GRPO阶段的总训练实例达到6,912个。最终评估使用包含1,095个细胞批次的预留测试集。
作者使用以下指标报告结果:(1)细胞级准确率:每个批次中正确预测标签的平均比例。(2)批次级准确率:所有预测标签与真实标签完全匹配的批次比例。(3)格式有效性:符合所需响应格式的输出比例。(4)答案唯一性:每个批次中唯一细胞类型预测的平均比例。








![[特殊字符] 深入理解 Linux 内核进程管理:架构、核心函数与调度机制](https://i-blog.csdnimg.cn/direct/5a1d6f8c5cba4467ad891a42ad177176.png)