昨天帮朋友看一个系统异常卡顿的案例,在这里分享给大家
环境:Exadata X8M 数据库版本19.11
1.系统报错信息
表象为系统卡顿,页面无法刷出,登陆到主机上看到节点1 系统等待存在大量的 cursor: pin S wait on X等待
查看两个节点的alert log 看到有大量的ORA-04031报错
2025-04-15T14:43:53.522183+08:00 Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_m000_342669.trc: ORA-00604: error occurred at recursive SQL level 1 ORA-01000: maximum open cursors exceeded 2025-04-15T14:44:50.515707+08:00 DDE: Problem Key 'ORA 4031' was completely flood controlled (0x6) Further messages for this problem key will be suppressed for up to 10 minutes 2025-04-15T14:46:29.968518+08:00 Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_mz08_287162.trc: ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^2798","kglseshtTable") 2025-04-15T14:46:30.005517+08:00 Process MZ08 died, see its trace filetrace file信息 Trace file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_mz08_287162.trc Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.11.0.0.0 *** 2025-04-15T14:46:29.968405+08:00 (CDB$ROOT(1)) <error barrier> at 0x7ffceea153e8 placed ksv.c@7147 ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^2798","kglseshtTable") OPIRIP: Uncaught error 447. Error stack: *** 2025-04-15T14:46:29.969405+08:00 ORA-00447: fatal error in background process ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^2798","kglseshtTable")
MOS新加AI搜索能力
ORA-04031涉及到的bug非常多,遇到这类问题 优先查MOS,这里简单介绍一下MOS新推出的 AI搜索能力,可以根据你提供的报错 比较精准的给出搜索结果,并根据相关性将引用的文档列出来,这个功能非常好
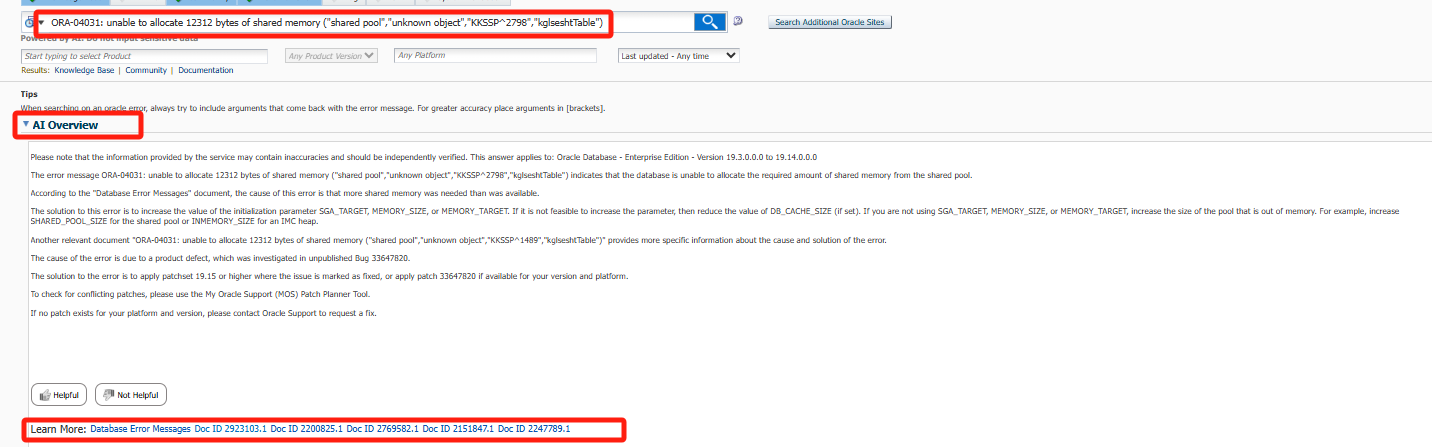
根据AI的提示 简单翻译一下
请注意:服务提供的信息可能存在不准确之处,应进行独立验证。本解答适用于:Oracle Database - Enterprise Edition - 版本19.3.0.0.0至19.14.0.0.0
错误消息ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^2798","kglseshtTable")表明数据库无法从共享池分配所需的共享内存。
根据《数据库错误消息》文档,该错误的成因是所需共享内存超过了当前可用量。
解决方案如下:
-
增加初始化参数SGA_TARGET、MEMORY_SIZE或MEMORY_TARGET的值
-
若无法增加上述参数,则降低DB_CACHE_SIZE的值(如已设置)
-
若未使用SGA_TARGET、MEMORY_SIZE或MEMORY_TARGET,则增加对应内存池的大小:
-
共享池不足时增加SHARED_POOL_SIZE
-
IMC堆不足时增加INMEMORY_SIZE
-
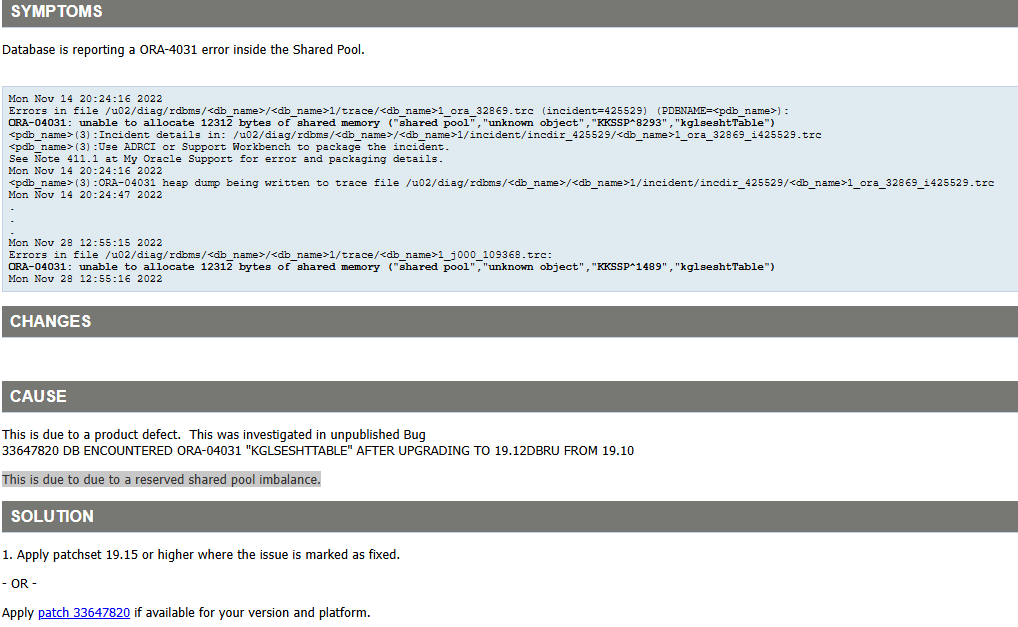
另一份相关文档《ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^1489","kglseshtTable")》提供了更具体的错误分析。
该错误由产品缺陷引起,已在未公开的Bug 33647820中记录。解决方案为:
-
应用19.15或更高版本的补丁集(该问题已标记为修复)
-
或应用适用于您版本和平台的补丁33647820(如存在)
检查补丁冲突请使用My Oracle Support (MOS)的Patch Planner工具。若对应平台和版本无可用补丁,请联系Oracle技术支持申请修复。
2.原因
很明显这个报错是因为触发了一个为 unpublished 的Bug ,根据文档 ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^1489","kglseshtTable") (Doc ID 2923103.1)
这个报错和文档中的描述完全一致,大概猜测是数据库实例运行太久 造成的share pool imbalance,该问题在19.15被解决,19.15之前版本BUG还是挺多的,如果有条件可以考虑升级到19.20+
话说Exadata稳定性还是非常强大的,这台机器从入场至今1387天(接近四年了),没有重启过,出问题这个实例也没有重启过, 如果不是这次遭遇BUG 应该还能跑很久。
![]()
3.解决方案
根据以上MOS的信息,有一下几种处理方式
紧急处理方式,强制刷新share pool
alter system flush shared_pool;或者重启数据库 很多内存相关的bug可以通过重启数据库来解决,毕竟打补丁现在来不及;我这里选择的处理方案是轮流重启两个节点;
然而因为这个实例已经运行了太久 shutdown用了好长时间,并有大量pid 都需要手动kill,一下报出几百个PID,还好现在AI比较强大直接将这部分log丢给deepseek,让它把pid筛选出来就好了。
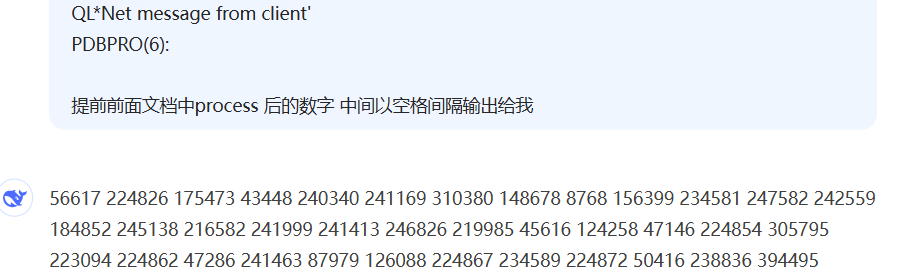
PDBPRO(6):Active process 279643 user 'grid' program 'oracle@test.com.cn', waiting for 'SQL*Net message from client'
PDBPRO(6):
PDBPRO(6):Active process 124660 user 'grid' program 'oracle@test.com.cn', waiting for 'SQL*Net message from client'
PDBPRO(6):
PDBPRO(6):Active process 246421 user 'grid' program 'oracle@test.com.cn', waiting for 'SQL*Net message from client'
PDBPRO(6):
PDBPRO(6):Active process 224818 user 'grid' program 'oracle@test.com.cn', waiting for 'read by other session'
PDBPRO(6):
PDBPRO(6):Active process 124650 user 'grid' program 'oracle@test.com.cn', waiting for 'SQL*Net message from client'
PDBPRO(6):4.重启再遇到BUG
节点2重启正常,但是在节点1重启时发现只能mount 无法OPEN 关键部分报错如下
ALTER DATABASE OPEN /* db agent *//* {0:4:346} */
2025-04-15T19:47:52.586367+08:00
CTWR started with pid=89, OS id=33744
Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_ctwr_33744.trc (incident=246935) (PDBNAME=CDB$ROOT):
ORA-04031: unable to allocate 52011112 bytes of shared memory ("large pool","unknown object","large pool","CTWR dba buffer")
Incident details in: /u01/app/oracle/diag/rdbms/test1/test11/incident/incdir_246935/test11_ctwr_33744_i246935.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
2025-04-15T19:47:53.513579+08:00
ORA-04031 heap dump being written to trace file /u01/app/oracle/diag/rdbms/test1/test11/incident/incdir_246935/test11_ctwr_33744_i246935.trc
2025-04-15T19:47:54.106979+08:00
Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_ctwr_33744.trc (incident=246936) (PDBNAME=CDB$ROOT):
ORA-00600: internal error code, arguments: [krcpasb_initial_alloc_failure], [3250176], [], [], [], [], [], [], [], [], [], []
ORA-04031: unable to allocate 52011112 bytes of shared memory ("large pool","unknown object","large pool","CTWR dba buffer")
Incident details in: /u01/app/oracle/diag/rdbms/test1/test11/incident/incdir_246936/test11_ctwr_33744_i246936.trc
Use ADRCI or Support Workbench to package the incident.
See Note 411.1 at My Oracle Support for error and packaging details.
2025-04-15T19:47:54.598420+08:00
Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_ctwr_33744.trc:
ORA-00600: internal error code, arguments: [krcpasb_initial_alloc_failure], [3250176], [], [], [], [], [], [], [], [], [], []
ORA-04031: unable to allocate 52011112 bytes of shared memory ("large pool","unknown object","large pool","CTWR dba buffer")
2025-04-15T19:47:54.598589+08:00
The change tracking error 600.
2025-04-15T19:47:54.598742+08:00
Stopping background process CTWR
2025-04-15T19:47:54.599120+08:00
Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_ctwr_33744.trc:
ORA-00600: internal error code, arguments: [krcpasb_initial_alloc_failure], [3250176], [], [], [], [], [], [], [], [], [], []
ORA-04031: unable to allocate 52011112 bytes of shared memory ("large pool","unknown object","large pool","CTWR dba buffer")
2025-04-15T19:47:54.600494+08:00
Dumping diagnostic data in directory=[cdmp_20250415194754], requested by (instance=1, osid=33744 (CTWR)), summary=[incident=246936].
Errors in file /u01/app/oracle/diag/rdbms/test1/test11/trace/test11_ctwr_33744.trc (incident=246937) (PDBNAME=CDB$ROOT):
ORA-487 [] [] [] [] [] [] [] [] [] [] [] []
Incident details in: /u01/app/oracle/diag/rdbms/test1/test11/incident/incdir_246937/test11_ctwr_33744_i246937.trc
错误发生在启动 CTWR(Change Tracking Writer)进程时,最终导致 实例终止(instance crash)
4.1 CTWR 进程启动失败
CTWR 是 Change Tracking Writer,用于实现 增量备份变更跟踪(Block Change Tracking) 功能。它启动时尝试在 large pool 中分配大块内存失败,引发了 ORA-4031:
"large pool", "CTWR dba buffer"
4.2 ORA-00600 + ORA-4031 的组合说明这是一个严重的系统级错误
-
ORA-00600
[krcpasb_initial_alloc_failure]是 内部内存分配失败 -
错误位置在 Oracle kernel 模块
krcp*系列,属于 change tracking 内部模块 -
后续的 进程中止、系统状态转储、实例终止 都是级联故障结果
4.3是否命中 Oracle 官方 Bug?
查MOS 很快找到和这个报错和BUG Bug 32428097 高度一致!
Bug 32428097 - ORA-600 [krcpasb_initial_alloc_failure] during CTWR startup
说明:
-
Oracle 19.x 在使用 change tracking 时,CTWR 在启动期间分配内存失败,触发 ORA-04031 + ORA-00600 + 实例崩溃。
-
这是 Oracle 确认的回归问题(Regression Bug)在19.13修复。
-
常见于:
-
大量数据变更(如恢复、测试环境还原)
-
large pool 不足
-
某些版本升级后首次启用 change tracking
-
4.4解决方案
暂时关闭block change track
ALTER DATABASE DISABLE BLOCK CHANGE TRACKING;5.总结
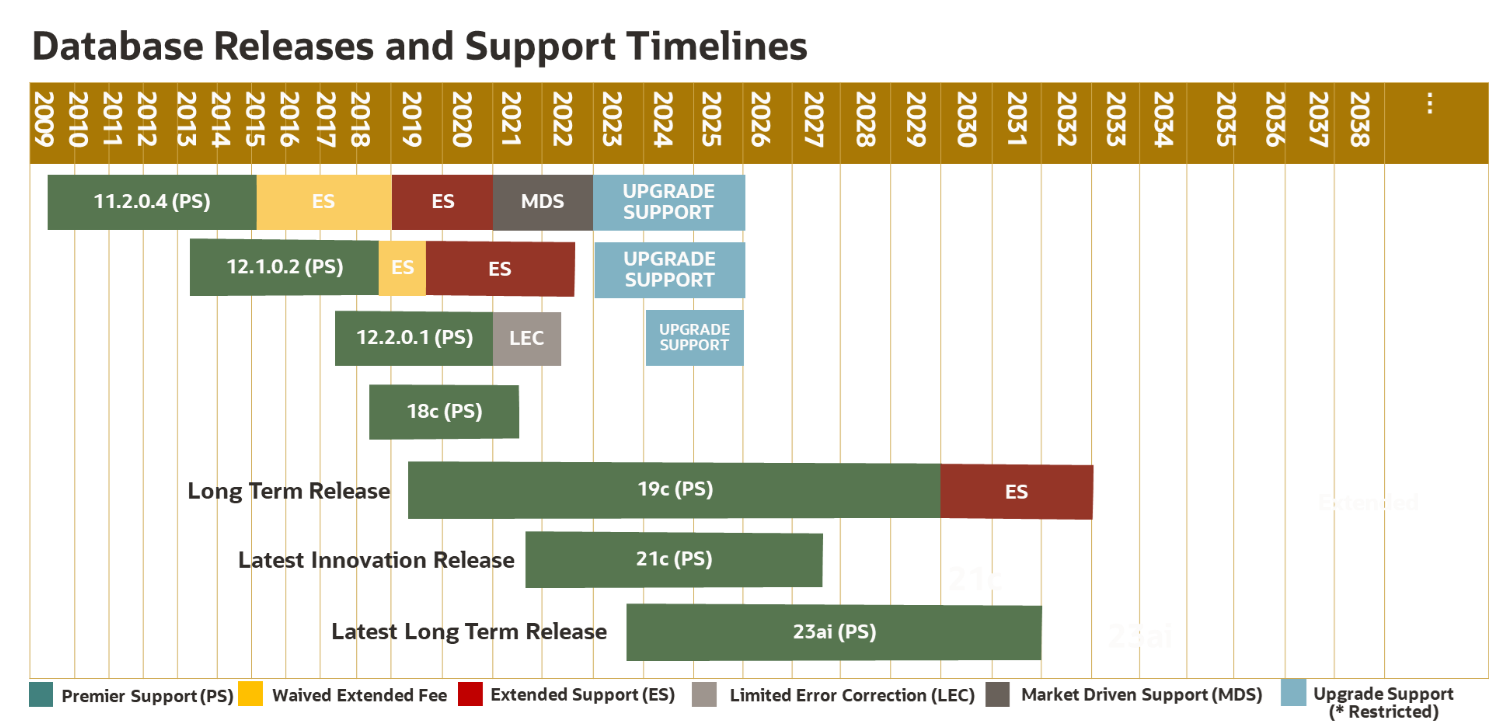
截止至2025年4月16日 Oracle19C已经更新至19.27,我认为至少在未来五年内,19c仍然会是主力版本;当然拉如果没有遭遇BUG,理论上可以不打补丁的,但是为了系统的稳定,仍然建议将19C升级至19.20+ (保守点19.15+)
附录oracle各版本支持时间线。
参考文档:
ORA-04031: unable to allocate 12312 bytes of shared memory ("shared pool","unknown object","KKSSP^1489","kglseshtTable") (Doc ID 2923103.1)
Bug 32428097 - BCT: CTWR crashes during "_bct_public_dba_buffer_size" reset with ORA-00600 [krcpasb_initial_alloc_failure] & ORA-4031 (Doc ID 32428097.8)
Release Schedule of Current Database Releases (Doc ID 742060.1)

![[Python] UV工具入门使用指南——小试牛刀](https://i-blog.csdnimg.cn/direct/71710a1474db47ae8e2f4c4542fd71a8.png)