随着开源大模型如 LLaMA、Qwen 和 Baichuan 的广泛应用,其基于通用数据的训练方式在特定下游任务和垂直领域中的表现仍存在提升空间,因此衍生出针对具体场景的微调训练需求。这些训练涵盖预训练(PT)、指令微调(SFT)以及基于人工反馈的对齐技术(如 RLHF)等完整链路。然而,大模型训练对显存和算力要求较高,且需要开发者具备一定的专业知识,存在一定技术门槛。
为此,LLaMA-Factory 项目应运而生,旨在整合主流的高效微调训练技术,兼容市面上多数开源模型,打造一个功能全面、适配性强的训练框架。该项目提供多阶段训练、推理测试、Benchmark 评测、API Server 等高层接口,实现开箱即用。同时,参考 Stable Diffusion WebUI 的设计理念,项目还集成了基于 Gradio 的网页工作台,帮助新手快速入门,轻松训练出属于自己的定制化模型。

-
模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。 -
训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。 -
运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。 -
优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。 -
加速算子:FlashAttention-2 和 Unsloth。 -
推理引擎:Transformers 和 vLLM。 -
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
1.前置准备
cuda/torch等安装参考:
-
Linux和Windows系统下:安装Anaconda、Paddle、tensorflow、pytorch,GPU[cuda12.4、cudnn]、CPU安装教学,多版本cuda11.2 自由切换
-
LLaMA-Factory 安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
如果出现环境冲突,请尝试使用 pip install --no-deps -e . 解决
完成安装后,可以通过使用 llamafactory-cli version 来快速校验安装是否成功
如果您能成功看到类似下面的界面,就说明安装成功了。

模型下载与可用性校验
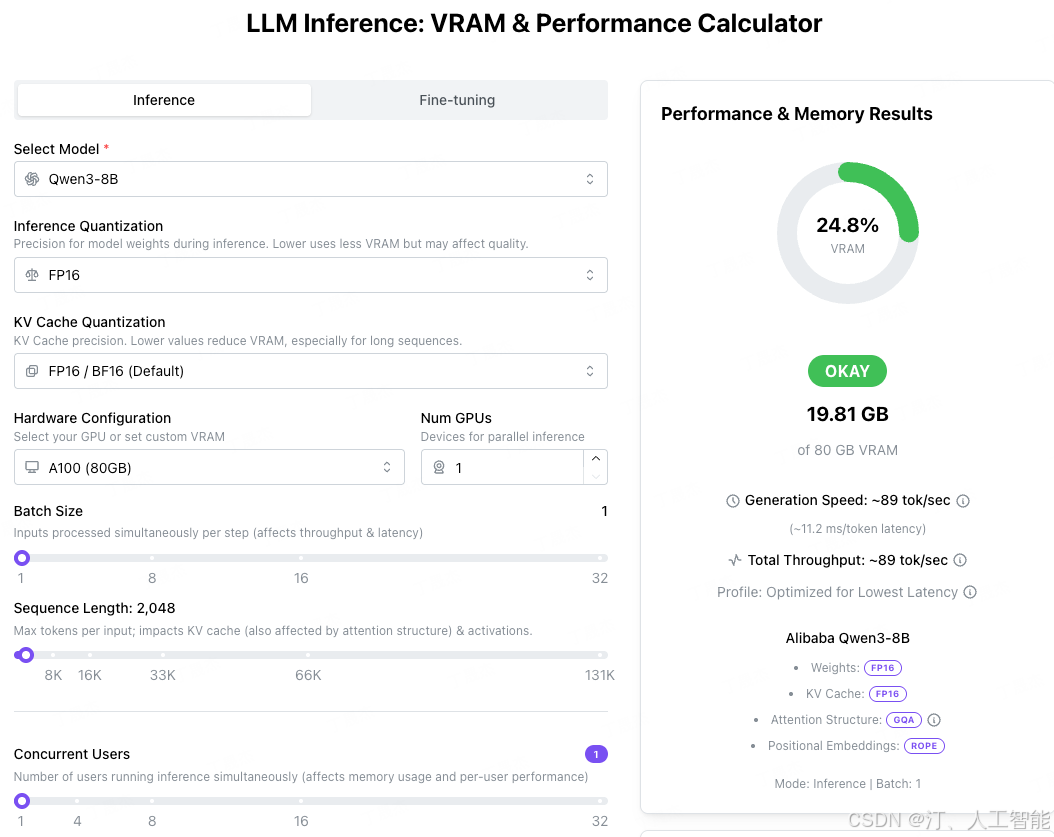
估算一下你的GPU可以支持多大模型训练部署
LLM Inference: VRAM & Performance Calculator
-
推理内存占用大小
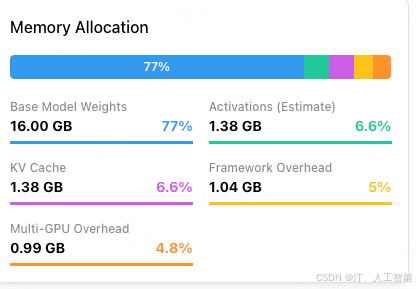
-
训练占用大小
-
全参训率
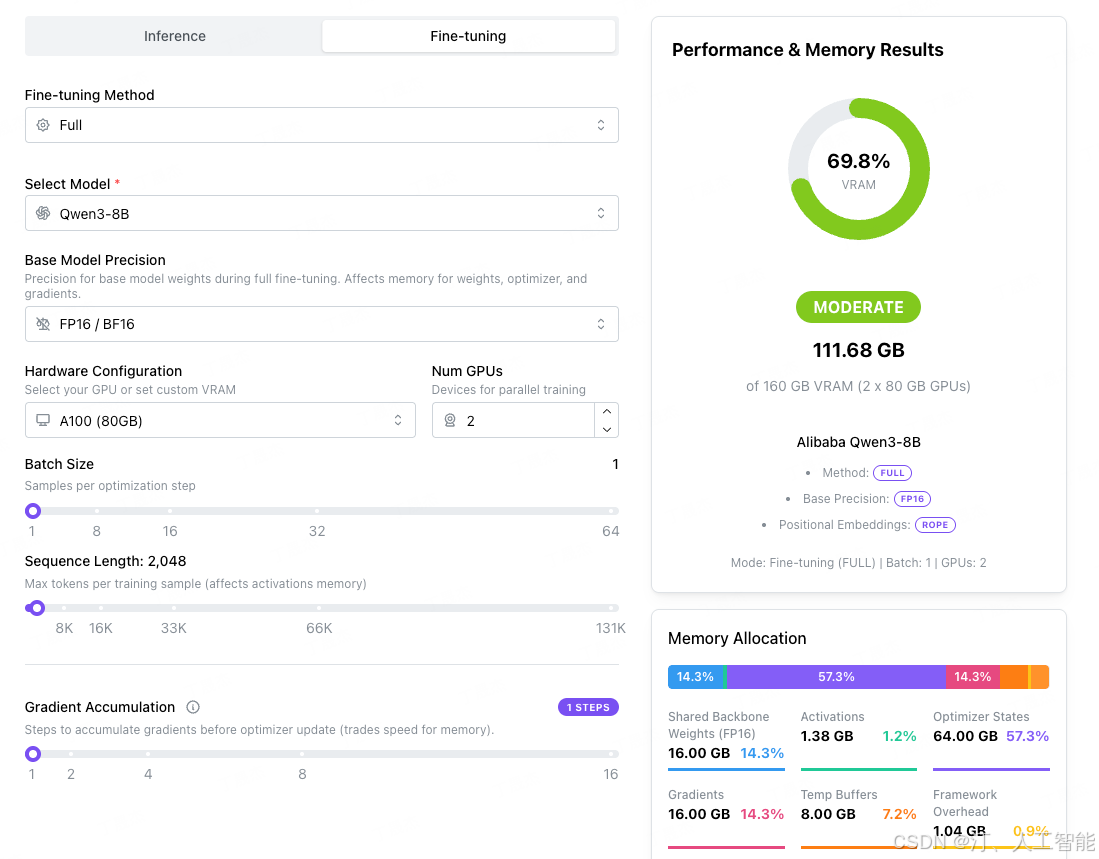
-
QLoRA
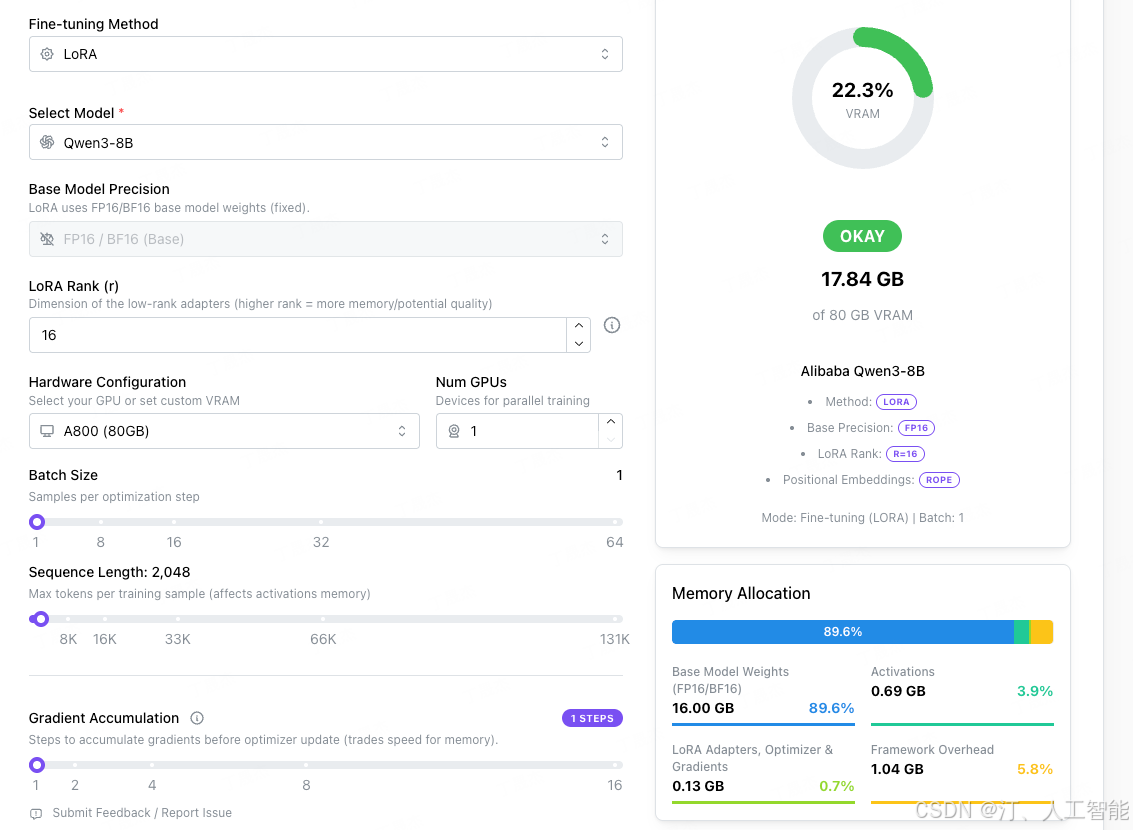
-
-
模型占用资源速算:
速算:大模型训练和推理的显存占用计算
模型下载
项目支持通过模型名称直接从 huggingface镜像 和 modelscope 下载模型,但这样不容易对模型文件进行统一管理,所以这里笔者建议使用手动下载,然后后续使用时使用绝对路径来控制使用哪个模型。
以 Qwen3-8B-Instruct 为例,通过 huggingface 下载(可能需要先提交申请通过)
- https://hf-mirror.com/Qwen/Qwen3-8B/tree/main
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
git clone https://hf-mirror.com/Qwen/Qwen3-8B
- modelscope 下载(适合中国大陆网络环境)
https://www.modelscope.cn/models/Qwen/Qwen3-8B/files
pip install modelscope
modelscope download --model Qwen/Qwen3-8B
#下载单个文件到指定本地文件夹
#modelscope download --model Qwen/Qwen3-8B README.md --local_dir ./dir
modelscope download --model Qwen/Qwen3-4B --local_dir /mnt/LLM/models/qwen3-4b
or
#模型下载-SDK下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-8B')
or
#Git下载
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen3-8B.git
#如果您希望跳过 lfs 大文件下载,可以使用如下命令
GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-8B.git
2. 数据集构建
更多内容参考:数据处理
2.1 数据集格式支持
dataset_info.json 包含了所有经过预处理的 本地数据集 以及 在线数据集。如果您希望使用自定义数据集,请 务必 在 dataset_info.json 文件中添加对数据集及其内容的定义。
支持 Alpaca 格式和 ShareGPT 格式的数据集。
2.1.1 Alpaca
针对不同任务,数据集格式要求如下:
-
指令监督微调
-
预训练
-
偏好训练
-
KTO
-
多模态
指令监督微调数据集
样例数据集: 指令监督微调样例数据集
指令监督微调 (Instruct Tuning) 通过让模型学习详细的指令以及对应的回答来优化模型在特定指令下的表现。
instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。下面是一个例子
"alpaca_zh_demo.json"
{
"instruction": "计算这些物品的总费用。 ",
"input": "输入:汽车 - $3000,衣服 - $100,书 - $20。",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},
在进行指令监督微调时, instruction 列对应的内容会与 input 列对应的内容拼接后作为最终的人类输入,即人类输入为 instruction\ninput。而 output 列对应的内容为模型回答。 在上面的例子中,人类的最终输入是:
计算这些物品的总费用。
输入:汽车 - $3000,衣服 - $100,书 - $20。
模型的回答是:
汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。
如果指定, system 列对应的内容将被作为系统提示词。
history 列是由多个字符串二元组构成的列表,分别代表历史消息中每轮对话的指令和回答。注意在指令监督微调时,历史消息中的回答内容也会被用于模型学习。
指令监督微调数据集 格式要求 如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
下面提供一个 alpaca 格式 多轮 对话的例子,对于单轮对话只需省略 history 列即可。
[
{
"instruction": "今天的天气怎么样?",
"input": "",
"output": "今天的天气不错,是晴天。",
"history": [
[
"今天会下雨吗?",
"今天不会下雨,是个好天气。"
],
[
"今天适合出去玩吗?",
"非常适合,空气质量很好。"
]
]
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
预训练数据集
样例数据集: 预训练样例数据集
大语言模型通过学习未被标记的文本进行预训练,从而学习语言的表征。通常,预训练数据集从互联网上获得,因为互联网上提供了大量的不同领域的文本信息,有助于提升模型的泛化能力。 预训练数据集文本描述格式如下:
[
{"text": "document"},
{"text": "document"}
]
在预训练时,只有 text 列中的 内容 (即 document)会用于模型学习。
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "text"
}
}
偏好数据集
偏好数据集用于奖励模型训练、DPO 训练和 ORPO 训练。对于系统指令和人类输入,偏好数据集给出了一个更优的回答和一个更差的回答。
一些研究 表明通过让模型学习 “什么更好” 可以使得模型更加迎合人类的需求。 甚至可以使得参数相对较少的模型的表现优于参数更多的模型。
偏好数据集需要在 chosen 列中提供更优的回答,并在 rejected 列中提供更差的回答,在一轮问答中其格式如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"chosen": "优质回答(必填)",
"rejected": "劣质回答(必填)"
}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"ranking": true,
"columns": {
"prompt": "instruction",
"query": "input",
"chosen": "chosen",
"rejected": "rejected"
}
}
KTO 数据集
KTO 数据集与偏好数据集类似,但不同于给出一个更优的回答和一个更差的回答,KTO 数据集对每一轮问答只给出一个 true/false 的 label。 除了 instruction 以及 input 组成的人类最终输入和模型回答 output ,KTO 数据集还需要额外添加一个 kto_tag 列(true/false)来表示人类的反馈。
在一轮问答中其格式如下:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"kto_tag": "人类反馈 [true/false](必填)"
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"kto_tag": "kto_tag"
}
}
多模态数据集
图像数据集
多模态图像数据集需要额外添加一个 images 列,包含输入图像的路径。 注意图片的数量必须与文本中所有 标记的数量严格一致。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"images": [
"图像路径(必填)"
]
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"images": "images"
}
}
视频数据集
多模态视频数据集需要额外添加一个 videos 列,包含输入视频的路径。 注意视频的数量必须与文本中所有 标记的数量严格一致。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"videos": [
"视频路径(必填)"
]
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"videos": "videos"
}
}
音频数据集
多模态音频数据集需要额外添加一个 audio 列,包含输入图像的路径。 注意音频的数量必须与文本中所有 标记的数量严格一致。
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"audios": [
"音频路径(必填)"
]
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"audios": "audios"
}
}
2.1.2 ShareGPT
针对不同任务,数据集格式要求如下:
-
指令监督微调
-
偏好训练
-
OpenAI 格式
备注
-
ShareGPT 格式中的 KTO 数据集 (样例) 和多模态数据集 (样例) 与 Alpaca 格式的类似。
-
预训练数据集不支持 ShareGPT 格式。
指令监督微调数据集
样例数据集: 指令监督微调样例数据集
相比 alpaca 格式的数据集, sharegpt 格式支持 更多 的角色种类,例如 human、gpt、observation、function 等等。它们构成一个对象列表呈现在 conversations 列中。 下面是 sharegpt 格式的一个例子:
{
"conversations": [
{
"from": "human",
"value": "你好,我出生于1990年5月15日。你能告诉我我今天几岁了吗?"
},
{
"from": "function_call",
"value": "{\"name\": \"calculate_age\", \"arguments\": {\"birthdate\": \"1990-05-15\"}}"
},
{
"from": "observation",
"value": "{\"age\": 31}"
},
{
"from": "gpt",
"value": "根据我的计算,你今天31岁了。"
}
],
"tools": "[{\"name\": \"calculate_age\", \"description\": \"根据出生日期计算年龄\", \"parameters\": {\"type\": \"object\", \"properties\": {\"birthdate\": {\"type\": \"string\", \"description\": \"出生日期以YYYY-MM-DD格式表示\"}}, \"required\": [\"birthdate\"]}}]"
}
注意其中 human 和 observation 必须出现在奇数位置,gpt 和 function 必须出现在偶数位置。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}
偏好数据集
样例数据集: 偏好数据样例数据集
Sharegpt 格式的偏好数据集同样需要在 chosen 列中提供更优的消息,并在 rejected 列中提供更差的消息。 下面是一个例子:
{
"conversations": [
{
"from": "human",
"value": "老虎会吃哪一个,草还是树叶?"
}
],
"chosen": {
"from": "gpt",
"value": "我很高兴能帮助你解答问题!不过,我必须指出,这个问题本身可能没有意义。老虎是食肉动物,通常不吃草或树叶。它们的饮食主要包括大型有蹄动物、小型哺乳动物和鸟类。\n\n如果你提出这个问题是出于好奇或有特定原因,我很乐意帮助你找到更多关于老虎饮食习惯的信息,或者建议资源让你更多了解这些壮丽的生物。请告诉我如何进一步协助你!"
},
"rejected": {
"from": "gpt",
"value": "一只老虎是食肉动物,这意味着它的饮食主要是肉类。老虎主要猎捕和吃其他动物,如鹿和野猪。它们不会选择吃草或树叶,因为这些不是它们自然饮食的一部分。"
}
}
其格式为:
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "gpt",
"value": "模型回答"
},
{
"from": "human",
"value": "人类指令"
}
],
"chosen": {
"from": "gpt",
"value": "优质回答"
},
"rejected": {
"from": "gpt",
"value": "劣质回答"
}
}
]
对于上述格式的数据,dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"ranking": true,
"columns": {
"messages": "conversations",
"chosen": "chosen",
"rejected": "rejected"
}
}
OpenAI 格式
OpenAI 格式仅仅是 sharegpt 格式的一种特殊情况,其中第一条消息可能是系统提示词。
[
{
"messages": [
{
"role": "system",
"content": "系统提示词(选填)"
},
{
"role": "user",
"content": "人类指令"
},
{
"role": "assistant",
"content": "模型回答"
}
]
}
]
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant",
"system_tag": "system"
}
}
所以我们训练的数据最好也转换成这种格式,然后在 data/dataset_info.json 中进行注册(如果不做字段名称转换,则需要在注册的时候在 columns 字段中做两个数据的映射配置)
- demo快速实现
第一个是系统自带的 identity.json 数据集 (已默认在 data/dataset_info.json 注册为 identity),对应文件已经在 data 目录下,我们通过操作系统的文本编辑器的替换功能,可以替换其中的 NAME 和 AUTHOR ,换成我们需要的内容。如果是 linux 系统,可以使用 sed 完成快速替换。比如助手的名称修改为 AIBot, 由 LLaMA Factory 开发
sed -i 's/{{name}}/PonyBot/g' data/identity.json
sed -i 's/{{author}}/LLaMA Factory/g' data/identity.json
替换前
{
"instruction": "Who are you?",
"input": "",
"output": "Hello! I am {{name}}, an AI assistant developed by {{author}}. How can I assist you today?"
}
替换后
{
"instruction": "Who are you?",
"input": "",
"output": "I am AIBot, an AI assistant developed by LLaMA Factory. How can I assist you today?"
}
2.2 Easy Dataset便捷构建数据集
Easy Dataset 是一个专为创建大型语言模型(LLM)微调数据集而设计的应用程序。它提供了直观的界面,用于上传特定领域的文件,智能分割内容,生成问题,并为模型微调生成高质量的训练数据。
通过 Easy Dataset,您可以将领域知识转化为结构化数据集,兼容所有遵循 OpenAI 格式的 LLM API,使微调过程变得简单高效。
一句话理解:“给它一堆文档,直接生成你想要的微调Alpaca数据集。”
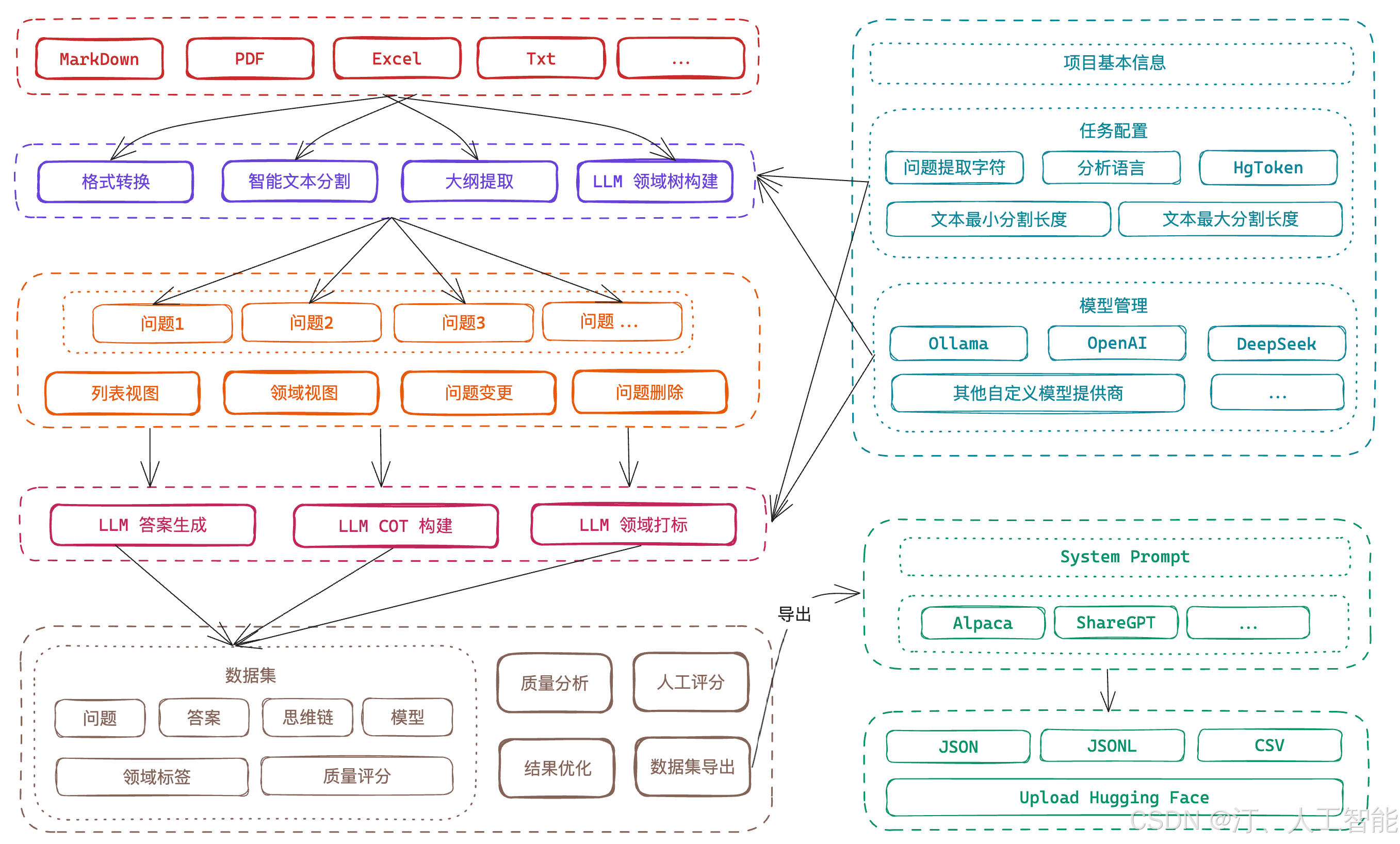

2.2.1安装
- GPU 显存:大于等于 12 GB
- CUDA 版本:高于 11.6
- Python 版本:3.10
-
方法一:使用安装包
如果操作系统为 Windows、Mac 或 ARM 架构的 Unix 系统,可以直接前往 Easy Dataset 仓库下载安装包:https://github.com/ConardLi/easy-dataset/releases/latest -
方法二:使用 NPM 安装
下载 Node.js 和 pnpm,前往 Node.js 和 pnpm 官网安装环境:https://nodejs.org/en/download | https://pnpm.io/,使用以下代码检查 Node.js 版本是否高于 18.0
node -v
- 克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
- 安装依赖:
npm install
- 启动开发服务器:
npm run build
npm run start
#控制台如果出现以下输出,则说明启动成功。打开浏览器访问对应网址,即可看到 Easy Dataset 的界面。
> easy-dataset@1.2.3 start
> next start -p 1717
▲ Next.js 14.2.25
- Local: http://localhost:1717
✓ Ready in 295ms
- 打开浏览器并访问
http://localhost:1717
- 方法三:使用本地 Dockerfile
如果你想自行构建镜像,可以使用项目根目录中的 Dockerfile:
-
克隆仓库:
git clone https://github.com/ConardLi/easy-dataset.git cd easy-dataset -
构建 Docker 镜像:
docker build -t easy-dataset . -
运行容器:
docker run -d -p 3336:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset注意: 请将
{YOUR_LOCAL_DB_PATH}替换为你希望存储本地数据库的实际路径。注意:/mnt/data -
打开浏览器,访问
http://localhost:3336
- 项目结构
easy-dataset/
├── app/ # Next.js 应用目录
│ ├── api/ # API 路由
│ │ ├── llm/ # LLM API 集成
│ │ │ ├── ollama/ # Ollama API 集成
│ │ │ └── openai/ # OpenAI API 集成
│ │ ├── projects/ # 项目管理 API
│ │ │ ├── [projectId]/ # 项目特定操作
│ │ │ │ ├── chunks/ # 文本块操作
│ │ │ │ ├── datasets/ # 数据集生成和管理
│ │ │ │ ├── generate-questions/ # 批量问题生成
│ │ │ │ ├── questions/ # 问题管理
│ │ │ │ └── split/ # 文本分割操作
│ │ │ └── user/ # 用户特定项目操作
│ ├── projects/ # 前端项目页面
│ │ └── [projectId]/ # 项目特定页面
│ │ ├── datasets/ # 数据集管理 UI
│ │ ├── questions/ # 问题管理 UI
│ │ ├── settings/ # 项目设置 UI
│ │ └── text-split/ # 文本处理 UI
│ └── page.js # 主页
├── components/ # React 组件
│ ├── datasets/ # 数据集相关组件
│ ├── home/ # 主页组件
│ ├── projects/ # 项目管理组件
│ ├── questions/ # 问题管理组件
│ └── text-split/ # 文本处理组件
├── lib/ # 核心库和工具
│ ├── db/ # 数据库操作
│ ├── i18n/ # 国际化
│ ├── llm/ # LLM 集成
│ │ ├── common/ # 通用 LLM 工具
│ │ ├── core/ # 核心 LLM 客户端
│ │ └── prompts/ # 提示词模板
│ │ ├── answer.js # 答案生成提示词(中文)
│ │ ├── answerEn.js # 答案生成提示词(英文)
│ │ ├── question.js # 问题生成提示词(中文)
│ │ ├── questionEn.js # 问题生成提示词(英文)
│ │ └── ... 其他提示词
│ └── text-splitter/ # 文本分割工具
├── locales/ # 国际化资源
│ ├── en/ # 英文翻译
│ └── zh-CN/ # 中文翻译
├── public/ # 静态资源
│ └── imgs/ # 图片资源
└── local-db/ # 本地文件数据库
└── projects/ # 项目数据存储
2.2.2示例数据
本教程准备了一批互联网公司财报作为示例数据,包含五篇国内互联网公司 2024 年二季度的财报,格式包括 txt 和 markdown。可以使用 git 命令或者直接访问仓库链接下载
https://github.com/llm-factory/FinancialData-SecondQuarter-2024
数据均为纯文本数据,如下为节选内容示例。
# 腾讯:二季度数实收入504亿元
腾讯控股8月14日发布2024年第二季度财报,公司三大主业收入齐升,连续7个季度毛利和经营利润增速高于营收增长,持续实现高质量增长模型。
2024年第二季度腾讯实现营收1611.17亿元,毛利858.95亿元,经营利润584.43亿元,毛利和经营利润增速分别达到21%和27%,连续跑赢营收增速,反映出收入结构的优化和盈利质量的提升。
视频号、小程序、AI大模型、SaaS等多个“新芽”业务茁壮成长,为三大主营业务持续注入新的高质量收入。在大模型技术等驱动下,腾讯金融科技与企业服务板块为代表的数实收入二季度达到504亿元,同比增长4%;受益于视频号广告、AI提效等因素,腾讯广告收入二季度为299亿元,同比增长19%;增值服务板块本季收入788亿元,同比增长6%,受益于本土及海外市场游戏收入双双实现正增长,多部优质爆款剧集也带动社交网络收入实现增长。
公司董事会主席兼首席执行官马化腾表示,本季业绩展现了公司平台与内容结合战略的优势。本土市场游戏收入恢复增长,国际市场游戏收入加速增长,得益于数款长青游戏用户参与度的提升,以及若干新游戏的成功发布。通过改编自阅文IP的自制电视剧,腾讯视频实现了观众和付费会员数的显著增长。展望未来,腾讯将持续投资于平台和包括AI在内的技术,以创造新的商业价值和更好地服务用户需求。
2.2.3微调数据生成
- 创建项目并配置参数
- 在浏览器进入 Easy Dataset 主页后,点击创建项目
- 填写项目名称(必填),其他两项可留空,点击确认创建项目

- 项目创建后会跳转到项目设置页面,打开模型配置,选择数据生成时需要调用的大模型 API 接口
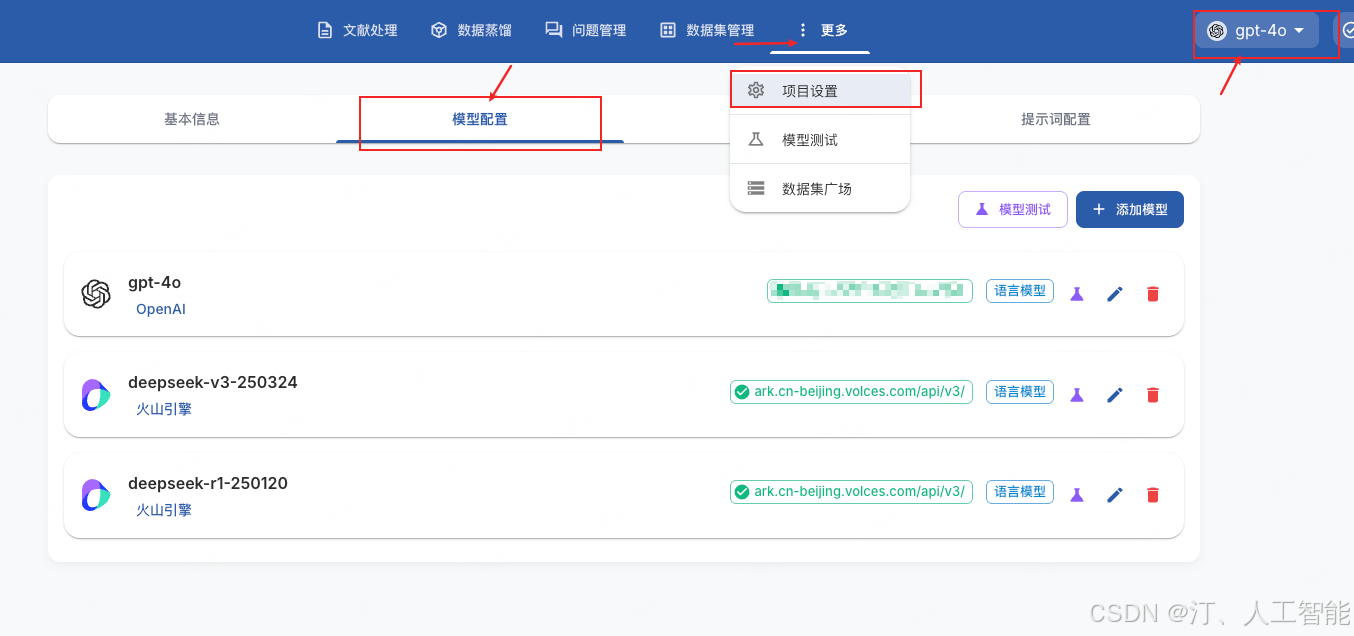
这里选择模型,不需要推理模型,文本的分拆和处理,使用Deepseek-chat模型效果会更好一些,配置好模型后,可以利用模型测试功能测一下API的接口连通性和可用性。
- 这里以 DeepSeek 模型为例,修改模型提供商和模型名称,填写 API 密钥,点击保存后将数据保存到本地,在右上角选择配置好的模型
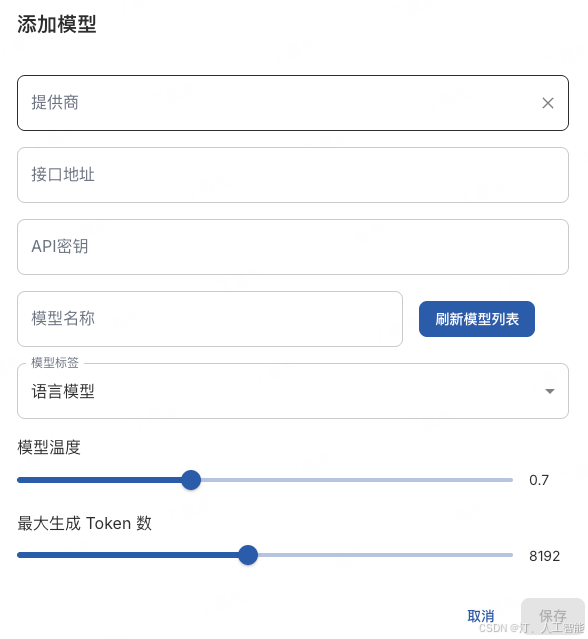
5. 打开任务配置页面,设置文本分割长度为最小 500 字符,最大 1000 字符。在问题生成设置中,修改为每 10 个字符生成一个问题,修改后在页面最下方保存任务配置
- 处理数据文件
打开文献处理页面,选择并上传示例数据文件,选择文件后点击上传并处理文件
上传后会调用大模型解析文件内容并分块,耐心等待文件处理完成,示例数据通常需要 1-2 分钟左右
- 生成微调数据
待文件处理结束后,可以看到文本分割后的文本段,选择全部文本段,点击批量生成问题
- 待文件处理结束后,可以看到文本分割后的文本段,选择全部文本段,点击批量生成问题
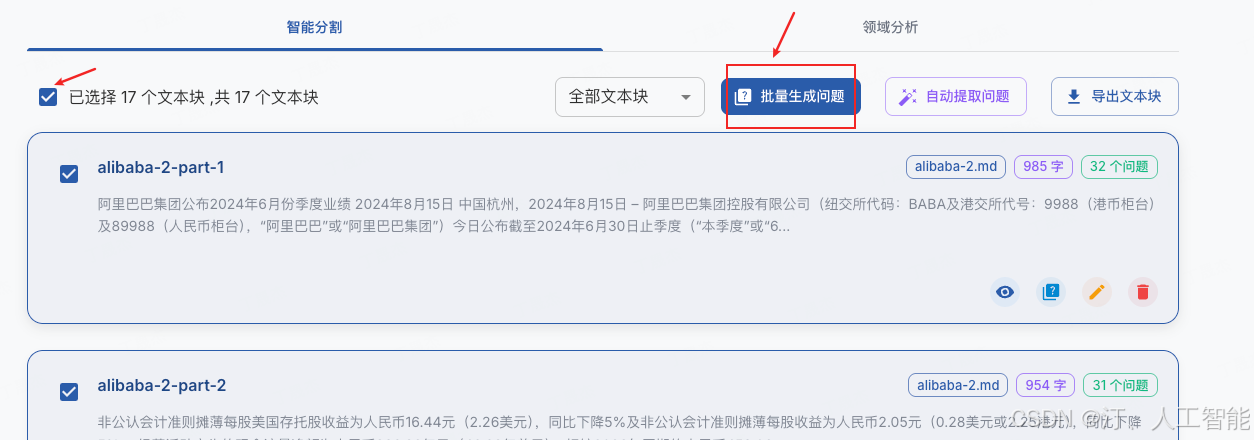
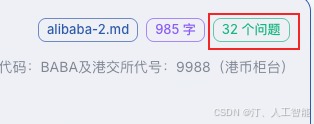
- 点击后会调用大模型根据文本块来构建问题,耐心等待处理完成。视 API 速度,处理时间可能在 15 分钟不等
- 处理完成后,打开问题管理页面,选择全部问题,点击批量构造数据集,耐心等待数据生成。视 API 速度,处理时间可能在 30 分钟不等
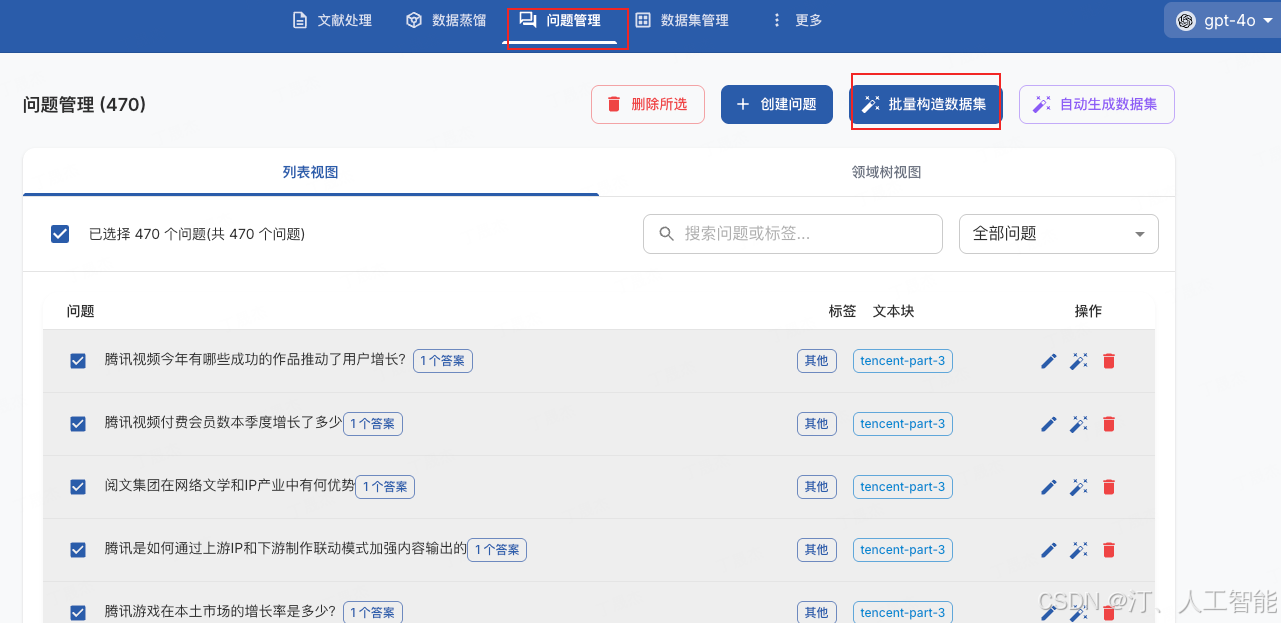
如果部分问题的答案生成失败,可以重复以上操作再次生成
- 导出数据集到 LLaMA Factory
- 答案全部生成结束后,打开数据集管理页面,点击导出数据集
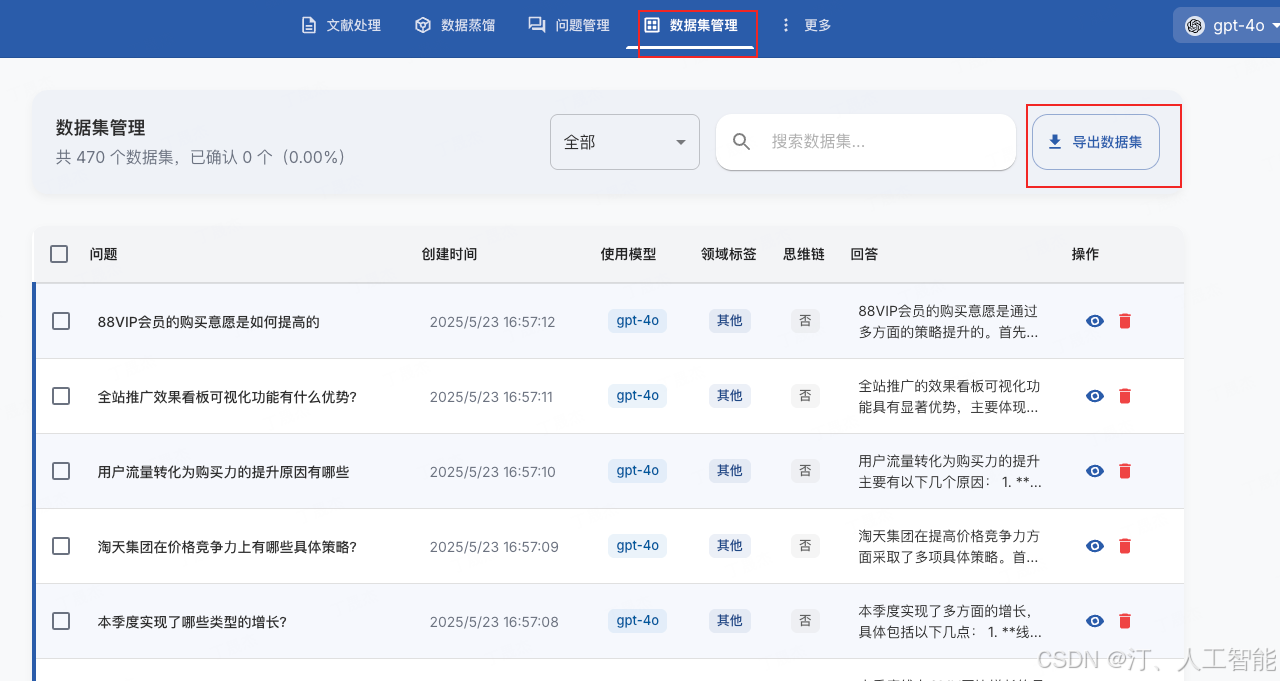
2. 在导出配置中选择在 LLaMA Factory 中使用,点击更新 LLaMA Factory 配置,即可在对应文件夹下生成配置文件,点击复制按钮可以将配置路径复制到粘贴板。
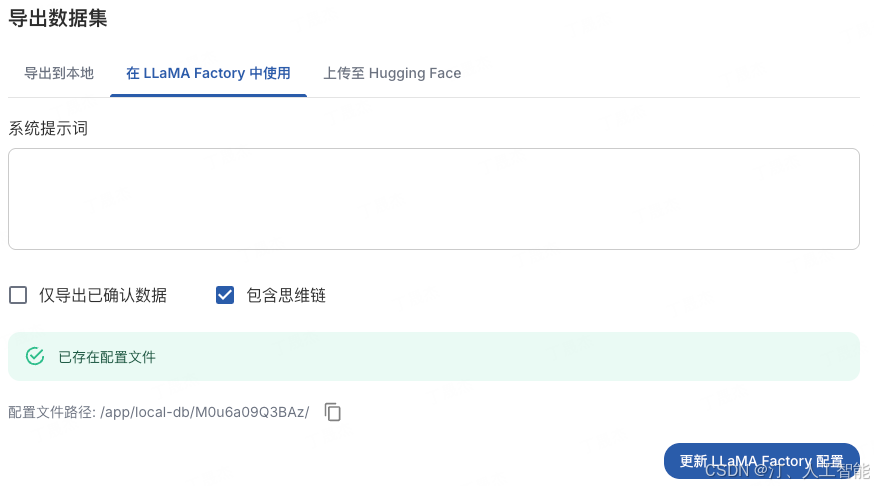
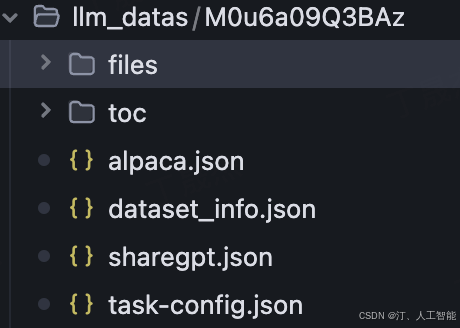
3. 在配置文件路径对应的文件夹中可以看到生成的数据文件,其中主要关注以下三个文件
- dataset_info.json:LLaMA Factory 所需的数据集配置文件
- alpaca.json:以 Alpaca 格式组织的数据集文件
- sharegpt.json:以 Sharegpt 格式组织的数据集文件
其中 alpaca 和 sharegpt 格式均可以用来微调,两个文件内容相同。
3.基于 LoRA 微调 Qwen3-4B
3.1 微调
运行以下指令启动 LLaMA Board
CUDA_VISIBLE_DEVICES=1,2 USE_MODELSCOPE_HUB=1 llamafactory-cli webui
环境变量解释:
- CUDA_VISIBLE_DEVICES:指定使用的显卡序号,默认全部使用
- USE_MODELSCOPE_HUB:使用国内魔搭社区加速模型下载,默认不使用
启动成功后,在控制台可以看到以下信息,在浏览器中输入 http://localhost:7860 进入 Web UI 界面。

-
将数据路径改为使用 Easy Dataset 导出的配置路径,选择 Alpaca 格式数据集

-
为了让模型更好地学习数据知识,将学习率改为 1e-4,训练轮数提高到 8 轮。批处理大小和梯度累计则根据设备显存大小调整,在显存允许的情况下提高批处理大小有助于加速训练,一般保持批处理大小×梯度累积×显卡数量等于 32 即可
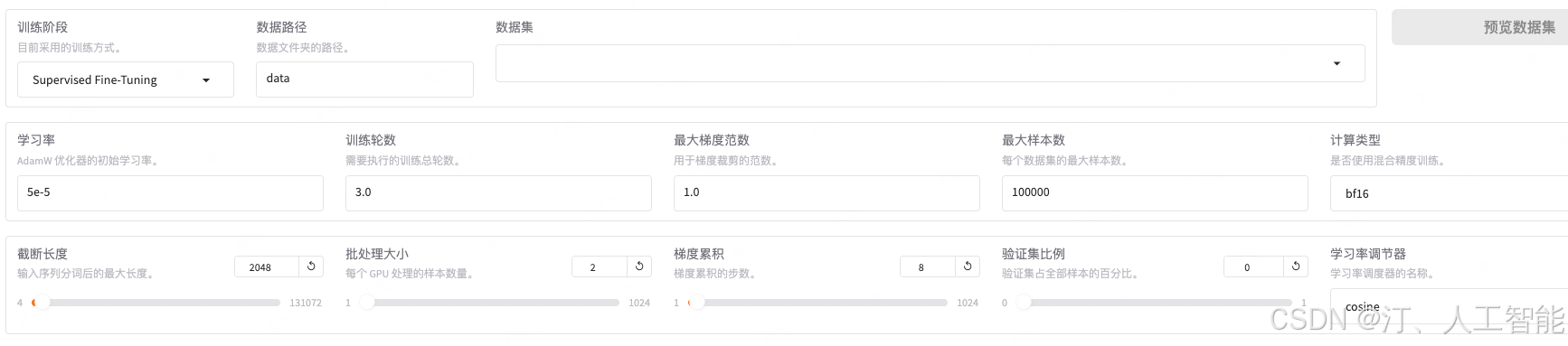
5. 点击其他参数设置,将保存间隔设置为 50,保存更多的检查点,有助于观察模型效果随训练轮数的变化

6. 点击 LoRA 参数设置,将 LoRA 秩设置为 16,并把 LoRA 缩放系数设置为 32

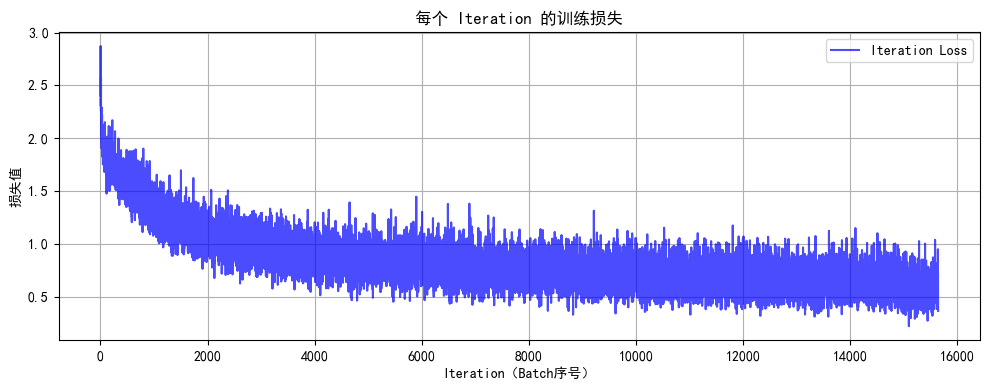
7. 点击开始按钮,等待模型下载,一段时间后应能观察到训练过程的损失曲线

直接预览命令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path Qwen/Qwen3-4B \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen3 \
--flash_attn auto \
--dataset_dir /mnt/newdisk/LLM/llm_datas/M0u6a09Q3BAz \
--dataset [Easy Dataset] [M0u6a09Q3BAz] Alpaca \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/Qwen3-4B-Instruct/lora/train_2025-05-27-19-35-42 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 16 \
--lora_alpha 32 \
--lora_dropout 0 \
--lora_target all
关于参数的完整列表和解释可以通过如下命令来获取
llamafactory-cli train -h
3.2 验证微调效果
- 动态合并 LoRA 的推理
本脚本参数改编自 LLaMA-Factory/examples/inference/llama3_lora_sft.yaml at main · hiyouga/LLaMA-Factory
当基于 LoRA 的训练进程结束后,我们如果想做一下动态验证,在网页端里与新模型对话,与步骤 4 的原始模型直接推理相比,唯一的区别是需要通过 finetuning_type 参数告诉系统,我们使用了 LoRA 训练,然后将 LoRA 的模型位置通过 adapter_name_or_path 参数即可。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /mnt/newdisk/LLM/models/qwen3-4b \
--adapter_name_or_path /mnt/newdisk/LLM/LLaMA-Factory/saves/Qwen3-4B-Instruct/lora/train_2025-05-27-10-15-17/checkpoint-140 \
--template qwen3 \
--finetuning_type lora
- 选择检查点路径为刚才的输出目录,打开 Chat 页面,点击加载模型
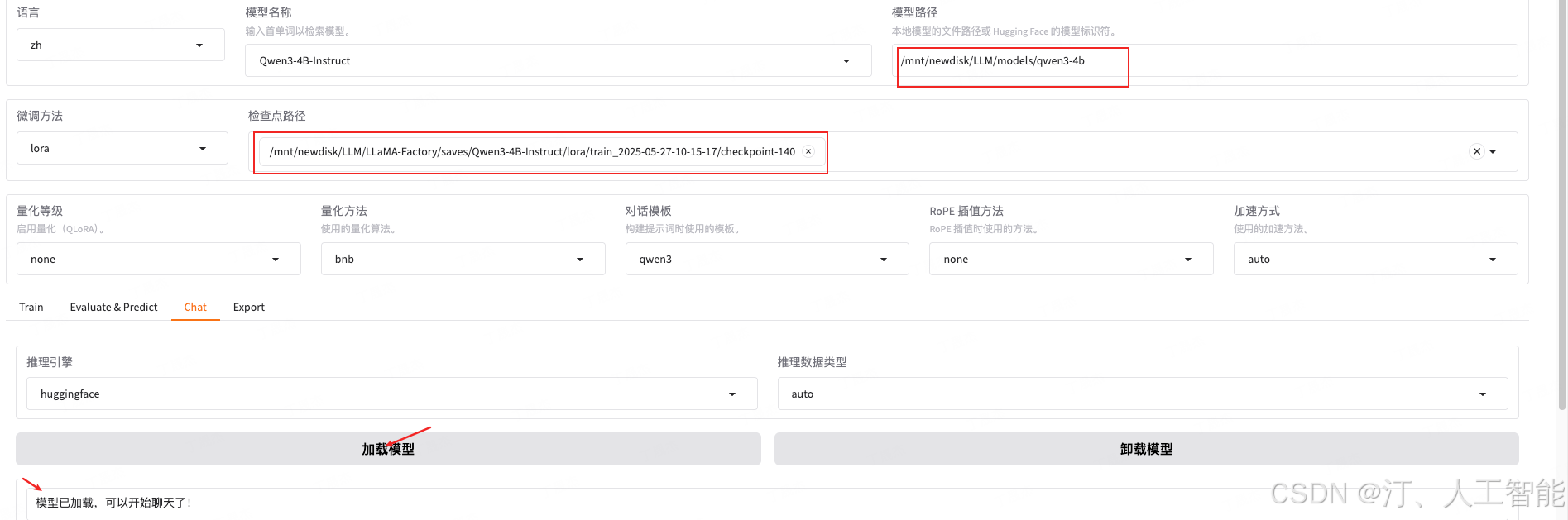
2. 在下方的对话框中输入问题后,点击提交与模型进行对话,经与原始数据比对发现微调后的模型回答正确
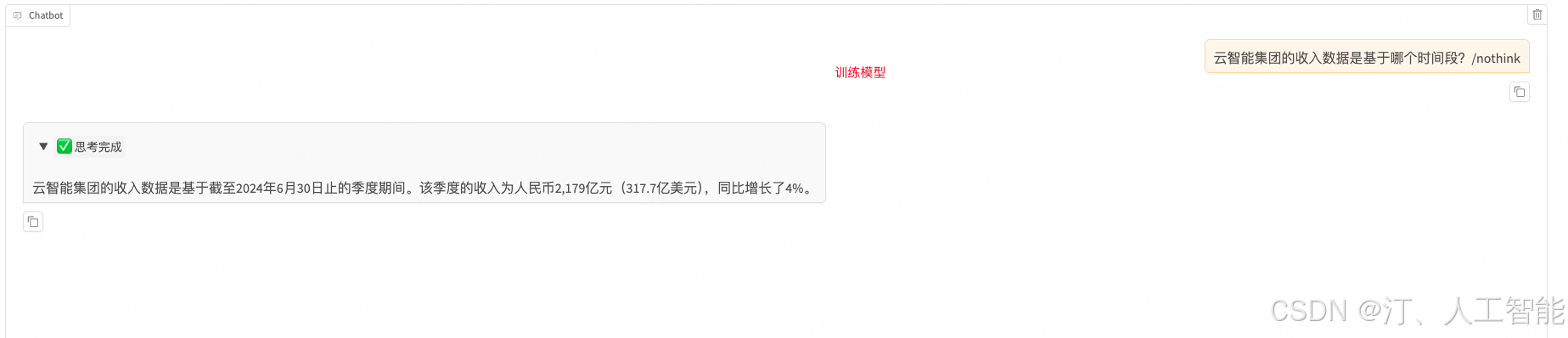
qwen3 会思考 不想要推理 输入加一个“/nothink”即可
-
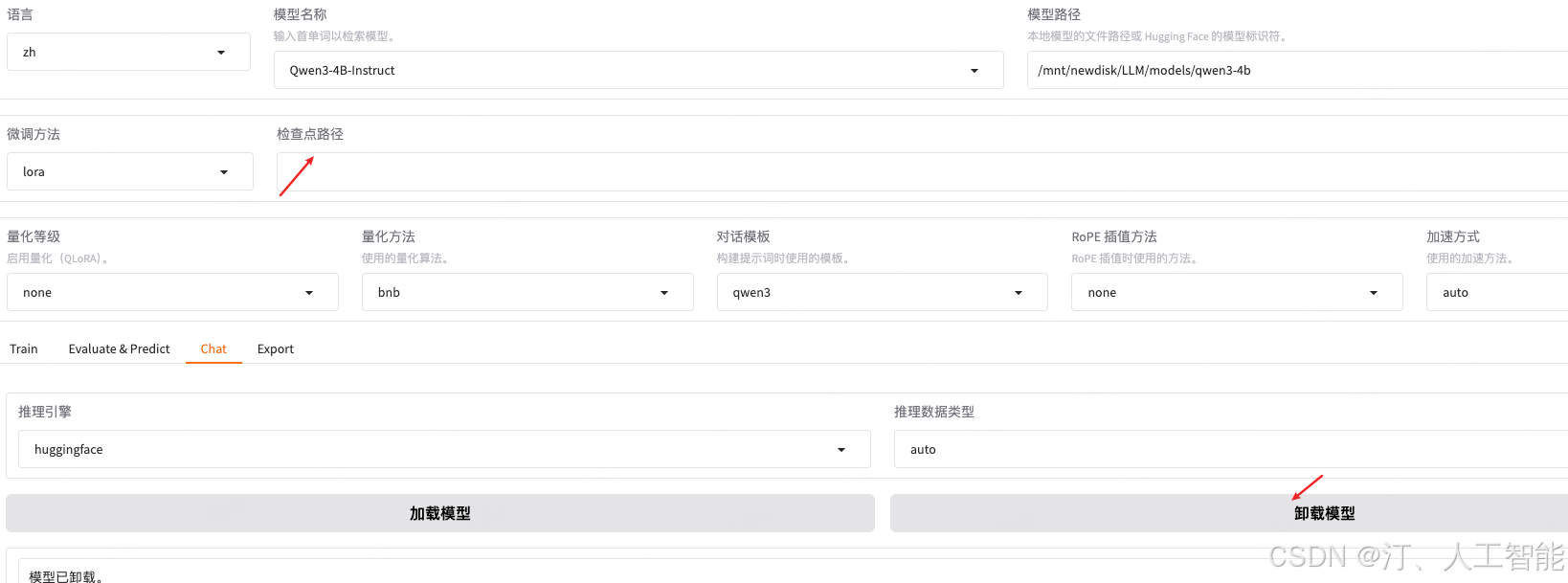
点击卸载模型将微调后的模型卸载,清空检查点路径,再点击加载模型加载微调前的原始模型
-
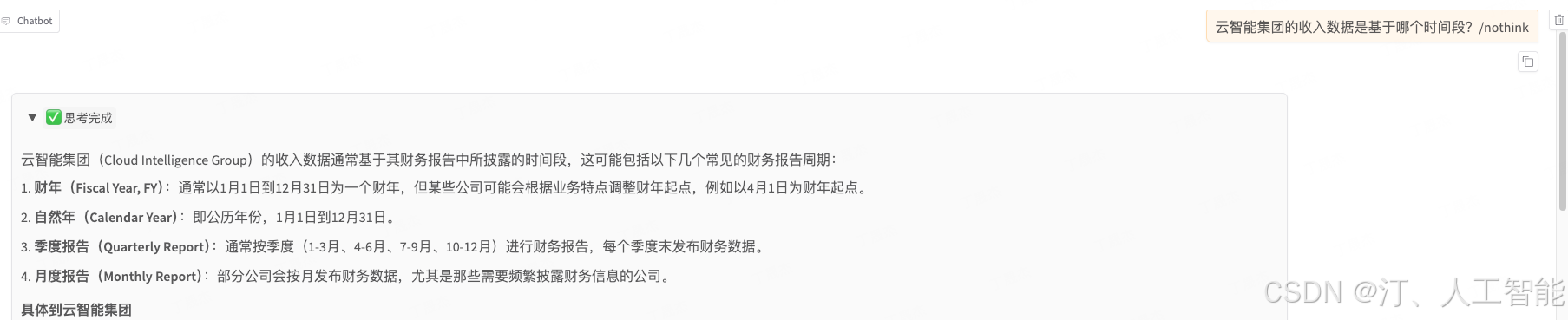
输入相同的问题与模型进行对话,发现原始模型无法回答,证明微调有效
3.3 LoRA 模型合并导出
参考:LoRA合并
当我们基于预训练模型训练好 LoRA 适配器后,我们不希望在每次推理的时候分别加载预训练模型和 LoRA 适配器,因此我们需要将预训练模型和 LoRA 适配器合并导出成一个模型,并根据需要选择是否量化。根据是否量化以及量化算法的不同,导出的配置文件也有所区别。
如果想把训练的 LoRA 和原始的大模型进行融合,输出一个完整的模型文件的话,可以使用如下命令。合并后的模型可以自由地像使用原始的模型一样应用到其他下游环节,当然也可以递归地继续用于训练。
模型 model_name_or_path 需要存在且与 template 相对应。 adapter_name_or_path 需要与微调中的适配器输出路径 output_dir 相对应。
合并 LoRA 适配器时,不要使用量化模型或指定量化位数。您可以使用本地或下载的未量化的预训练模型进行合并。
本脚本参数改编自 LLaMA-Factory/examples/merge_lora/llama3_lora_sft.yaml at main · hiyouga/LLaMA-Factory
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /mnt/newdisk/LLM/models/qwen3-4b \
--adapter_name_or_path /mnt/newdisk/LLM/LLaMA-Factory/saves/Qwen3-4B-Instruct/lora/train_2025-05-27-10-15-17/checkpoint-140 \
--template qwen3 \
--finetuning_type lora \
--export_dir megred-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False
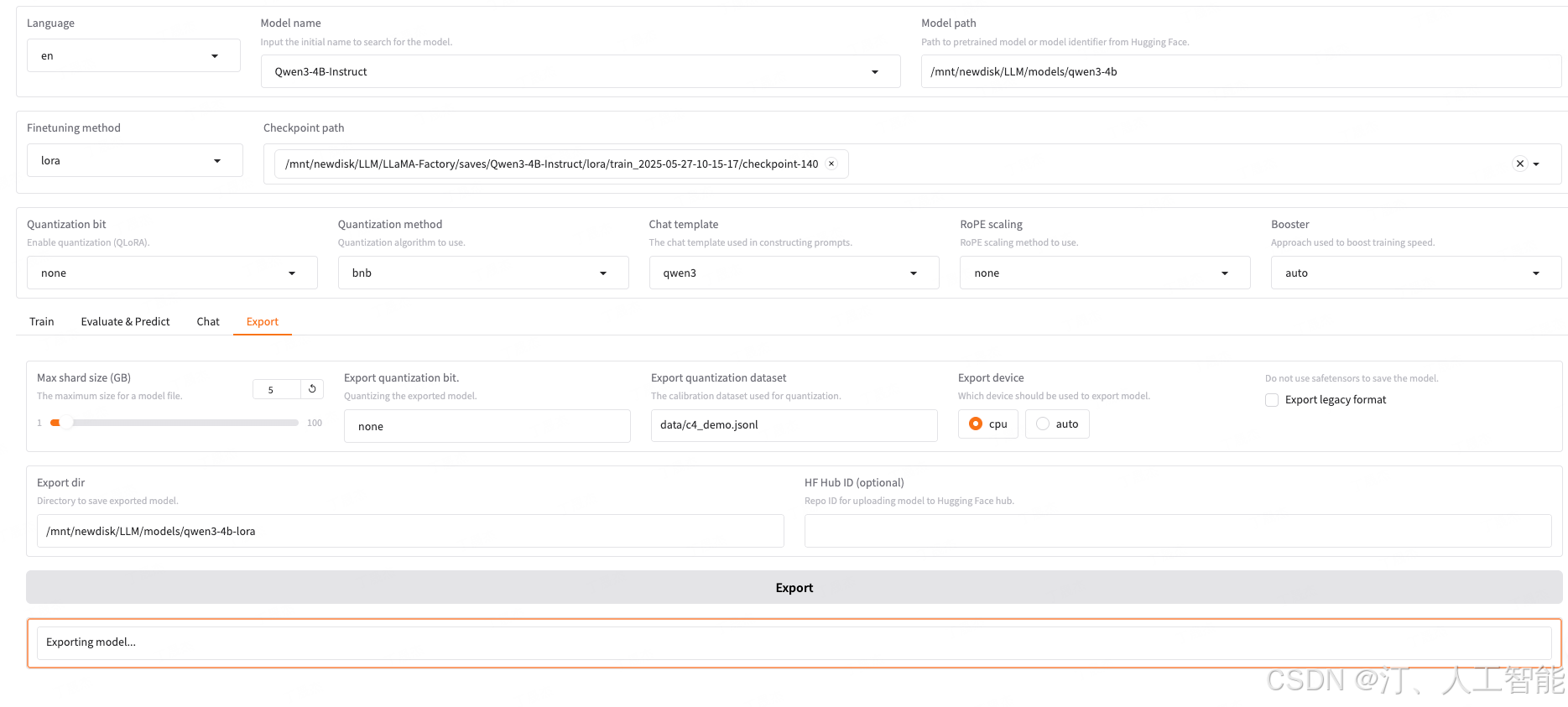
Model exported.
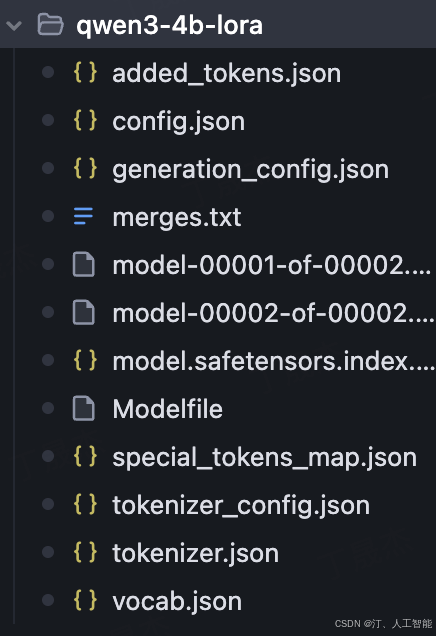
加载模型再测试一下

3.4 API Server 的启动与调用
参考:推理
LLaMA-Factory 支持多种推理方式。
您可以使用 llamafactory-cli chat inference_config.yaml 或 llamafactory-cli webchat inference_config.yaml 进行推理与模型对话。对话时配置文件只需指定原始模型 model_name_or_path 和 template ,并根据是否是微调模型指定 adapter_name_or_path 和 finetuning_type。
如果您希望向模型输入大量数据集并保存推理结果,您可以启动 vllm 推理引擎对大量数据集进行快速的批量推理。您也可以通过 部署 api 服务的形式通过 api 调用来进行批量推理。
API 实现的标准是参考了 OpenAI 的相关接口协议,基于 uvicorn 服务框架进行开发, 使用如下的方式启动
本脚本改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/inference/llama3_lora_sft.yaml
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora
项目也支持了基于 vllm 的推理后端,但是这里由于一些限制,需要提前将 LoRA 模型进行 merge,使用 merge 后的完整版模型目录或者训练前的模型原始目录都可。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path megred-model-path \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager
服务启动后,即可按照 openai 的 API 进行远程访问,主要的区别就是替换 其中的 base_url,指向所部署的机器 url 和端口号即可。
import os
from openai import OpenAI
from transformers.utils.versions import require_version
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
if __name__ == '__main__':
# change to your custom port
port = 8000
client = OpenAI(
api_key="0",
base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)),
)
messages = []
messages.append({"role": "user", "content": "hello, where is USA"})
result = client.chat.completions.create(messages=messages, model="test")
print(result.choices[0].message)
4. 大模型主流评测 benchmark
虽然大部分同学的主流需求是定制一个下游的垂直模型,但是在部分场景下,也可能有同学会使用本项目来做更高要求的模型训练,用于大模型刷榜单等,比如用于评测 mmlu 等任务。当然这类评测同样可以用于评估大模型二次微调之后,对于原来的通用知识的泛化能力是否有所下降。(因为一个好的微调,尽量是在具备垂直领域知识的同时,也保留了原始的通用能力)
本项目提供了 mmlu,cmmlu, ceval 三个常见数据集的自动评测脚本,按如下方式进行调用即可。
说明:task 目前支持 mmlu_test, ceval_validation, cmmlu_test
本脚本改编自 [https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_lora/llama3_lora_eval.yaml](https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_lora/llama3_lora_eval.yaml
### examples/train_lora/llama3_lora_eval.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft # 可选项
### method
finetuning_type: lora
### dataset
task: mmlu_test # mmlu_test, ceval_validation, cmmlu_test
template: fewshot
lang: en
n_shot: 5
### output
save_dir: saves/llama3-8b/lora/eval
### eval
batch_size: 4

如果是 chat 版本的模型
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--template llama3 \
--task mmlu_test \
--lang en \
--n_shot 5 \
--batch_size 1
输出如下, 具体任务的指标定义请参考 mmlu,cmmlu, ceval 等任务原始的相关资料, 和 llama3 的官方报告基本一致
Average: 63.64
STEM: 50.83
Social Sciences: 76.31
Humanities: 56.63
Other: 73.31
如果是 base 版本的模型,template 改为 fewshot 即可
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B \
--template fewshot \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1
参考链接:
- https://github.com/ConardLi/easy-dataset/blob/main
- https://buaa-act.feishu.cn/wiki/KY9xwTGs1iqHrRkjXBwcZP9WnL9
- https://llamafactory.readthedocs.io/zh-cn/latest/index.html
- https://github.com/hiyouga/LLaMA-Factory

![[ Qt ] | 与系统相关的操作(三):QFile介绍和使用](https://i-blog.csdnimg.cn/direct/b49e6bac2e2b4a47a980375e3a11e35e.png)