这里写目录标题
- 采用的技术
- 1. Python编程语言
- 2. 网络爬虫库
- 技术点对比与区别
- 项目技术栈的协同工作流程
- 代码解析
- 1. 导入头文件
- 2. 读取原始数据
- 3. 清洗数据
- 4. 数据分割
- 4.1 统计房屋信息的分段数量
- 4.2 将房屋信息拆分为独立列
- 4.3 处理面积字段
- 4.4 删除原始房屋信息列
- 5. 可视化分析
- 5.1 房屋户型数量统计
- 5.2 房源面积与总价
- 5.3 各区二手房平均单价的热力图
- 5.4 不同户型的占比分布
- 5.5 **不同行政区的修类型分布情况**
- 聚类分析
- 数据准备与标准化
- 确定最佳聚类数量(肘部法则)
- 结论
- 后记
采用的技术
链家网有反爬机制,频繁请求可能会被封IP
1. Python编程语言
作用:Python是一种高级、解释型、通用的编程语言,以其简洁的语法和强大的生态系统著称。
特点:
易读性:Python代码接近自然语言,适合快速开发和维护。
丰富的库支持:拥有大量第三方库(如aiohttp、requests、parsel),适合各种应用场景。
跨平台:可在Windows、Linux、macOS等系统上运行。
适用场景:数据抓取、数据分析、Web开发、自动化脚本等。
2. 网络爬虫库
网络爬虫库是专门用于从网页上提取数据的工具。本项目使用了以下库:
- a) aiohttp
作用:基于asyncio的异步HTTP客户端/服务器框架,用于高效发送HTTP请求和处理响应。
特点:
异步非阻塞:支持高并发请求,适合大规模爬取。
轻量级:比requests更高效,但学习曲线稍陡。
支持WebSocket:可用于实时数据抓取。
适用场景:需要高并发、高性能的爬虫项目。 - b) requests
作用:简单易用的HTTP库,用于发送同步HTTP请求。
特点:
同步阻塞:每次请求需等待响应,不适合高并发。
API友好:代码简洁直观,适合初学者。
功能全面:支持会话(Session)、Cookie、代理等。
适用场景:小规模爬取或简单API调用。 - c) parsel
作用:基于lxml和cssselect的HTML/XML解析库,用于从网页中提取结构化数据。
特点: - CSS选择器/XPath:支持两种方式定位元素,灵活性强。
高性能:底层依赖lxml,解析速度快。
Scrapy兼容:与Scrapy框架的Selector API一致。
适用场景:需要精确提取网页数据的场景。
技术点对比与区别
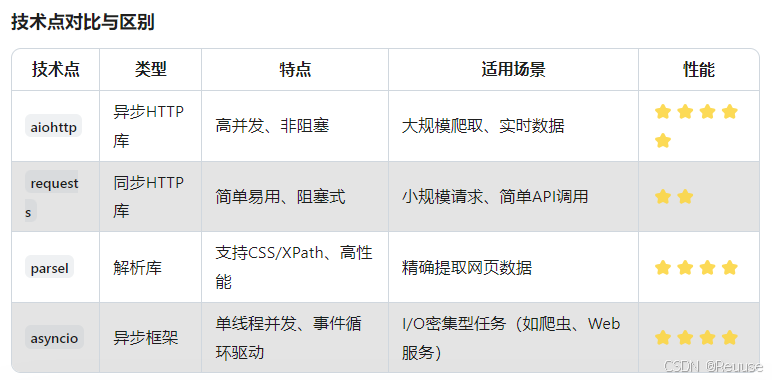
项目技术栈的协同工作流程
发起请求:
使用aiohttp(异步)或requests(同步)获取网页HTML。
解析数据:
通过parsel的CSS选择器/XPath提取目标数据。
并发控制:
利用asyncio管理多个爬取任务,避免阻塞。
数据处理:
将提取的数据存储到列表或数据库(如Pandas、SQLite)。

代码解析

1. 导入头文件
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置matplotlib的字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
- %matplotlib inline:魔术命令,用于在
Notebook中内嵌显示 matplotlib 图形。 - pandas:数据处理库(通常用于数据清洗和分析)。
- matplotlib.pyplot:Python 最基础的绘图库,plt 是约定俗成的别名。
- seaborn:基于
matplotlib的高级统计可视化库,默认风格更美观。 - rcParams 是
matplotlib的全局参数配置字典。
2. 读取原始数据
data = pd.read_csv("./data/二手房数据.csv")
data.head()
这一部分就比较简单,所以就不多赘述 
3. 清洗数据
我们获取到的野生数据也会出现重复或者缺失值,所以在开始统计之前我们需要清洗数据
清洗前:
# 缺失值统计
data.isnull().sum()
# 重复值统计
data.duplicated().sum()
# 获取数值型数据的统计摘要(计数、均值、标准差、最小值、四分位数、最大值)
data.describe()

# 删除关键数值缺失的行
data = data.dropna(subset=['单价(元/平米)', '总价(万)'])
# 删除区和位置都缺失的行(地理位置信息很重要)
data = data.dropna(subset=['区', '位置'])
data = data.dropna(subset=['房屋信息'])
4. 数据分割
原始数据中某一列可能包含多个信息,将复杂或复合型数据拆解为结构化字段,以便后续分析和建模
4.1 统计房屋信息的分段数量
统计 房屋信息 列中每条记录通过 | 分割后的字段数量
# 统计房屋信息的分段数量
nrec = data.房屋信息.map(lambda x: len(x.split('|')))
print(nrec.value_counts())
- map(lambda x: …):对 房屋信息 列的每个元素应用函数。
- x.split(‘|’):按 | 分割字符串,返回列表。
- len():计算列表长度(即分段数量)。
- value_counts():统计不同分段数量的出现次数。
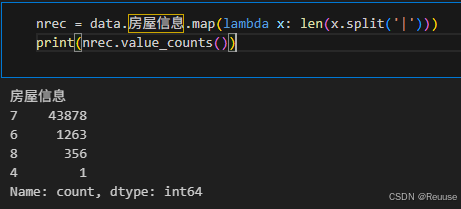
这里返回的意思是:分成7段的数据有43878条;分成6段的数据有1263条(可能缺失数据);以此类推。那么为了后续的统计,我们就只保留分成7段的所有数据即可
# 只保留字段书数量为7的数据行
data = data[nrec == 7]
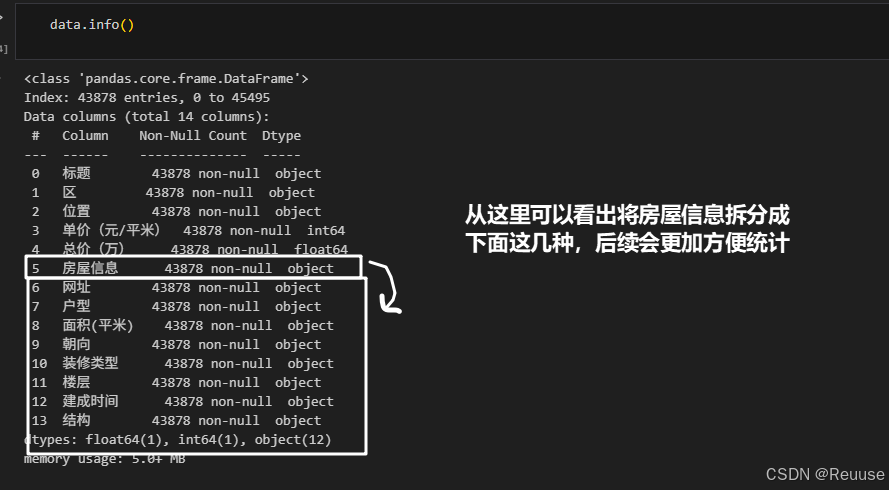
data.info()
4.2 将房屋信息拆分为独立列
将 房屋信息 列按 | 分割为7个独立字段,并赋值到新列
data['户型'] = data.房屋信息.map(lambda x: x.split(' | ')[0])
data['面积(平米)'] = data.房屋信息.map(lambda x: x.split(' | ')[1])
data['朝向'] = data.房屋信息.map(lambda x: x.split(' | ')[2])
data['装修类型'] = data.房屋信息.map(lambda x: x.split(' | ')[3])
data['楼层'] = data.房屋信息.map(lambda x: x.split(' | ')[4])
data['建成时间'] = data.房屋信息.map(lambda x: x.split(' | ')[5])
data['结构'] = data.房屋信息.map(lambda x: x.split(' | ')[6])
data.head()
4.3 处理面积字段
在后面制图表需要用到房屋面积的数值,但是有些数据里面会出现 xxx.xx平米 在后缀有中文的情况下是不能识别出来的,所以下一步需要将后缀的中文删除
data['面积(平米)'] = data['面积(平米)'].apply(lambda x: float(x.split('平米')[0]))
- x.split(‘平米’)[0]:按 “平米” 分割字符串,取第一部分(数字)。
- float():将字符串转为数值类型。
4.4 删除原始房屋信息列
删除已拆分完毕的原始列 房屋信息,避免数据冗余。
data.drop(labels='房屋信息', axis=1, inplace=True)
- labels=‘房屋信息’:指定要删除的列名。
- axis=1:表示按列删除(axis=0 为行)。
- inplace=True:直接修改原DataFrame,不返回新对象。
5. 可视化分析
- plt.figure() 用于创建一个新的图形/画布
- figsize=(10, 6) 设置图形的宽度为10英寸,高度为6英寸
- dpi=150 设置图形分辨率为150 dots per inch (每英寸点数)
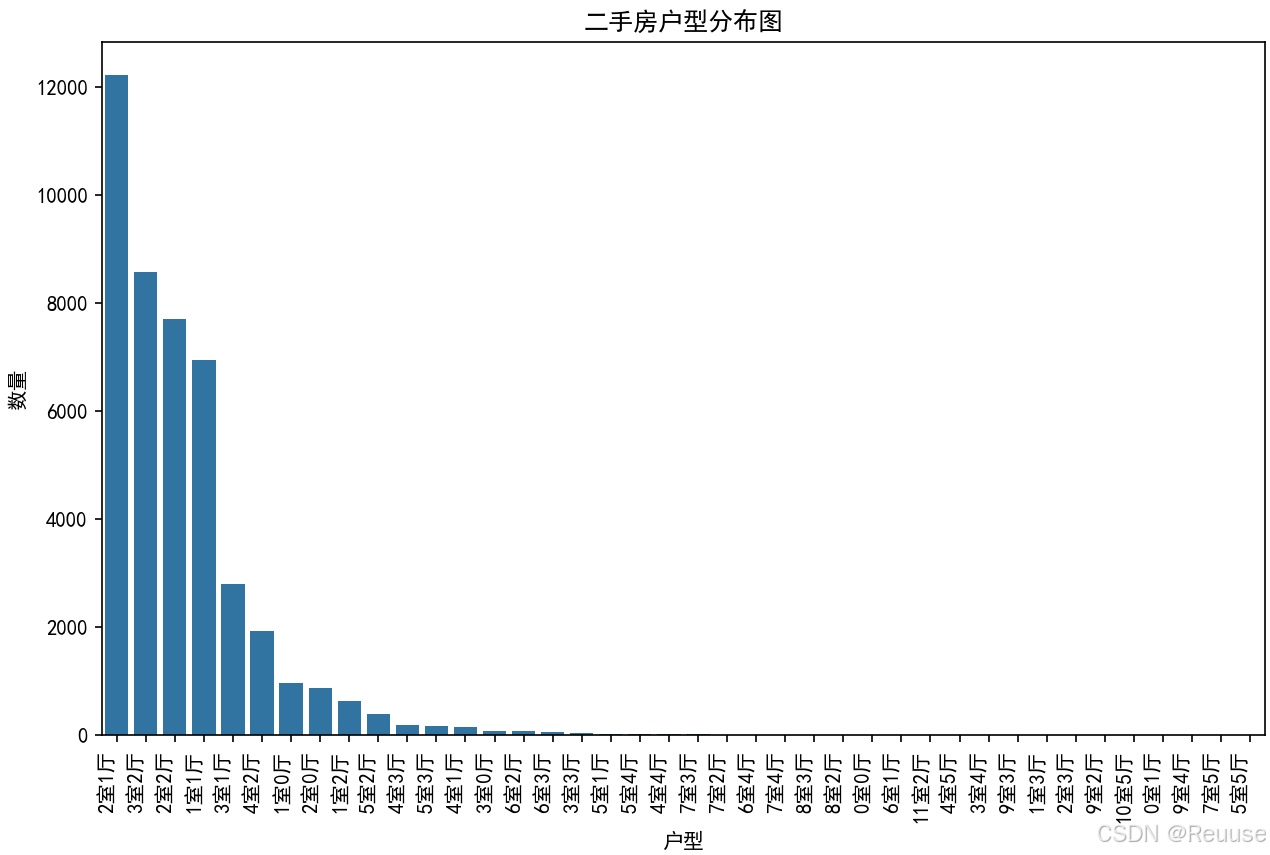
5.1 房屋户型数量统计
👉条形图绘制
sns.barplot(x=house_layout_counts.index, y=house_layout_counts.values)
- sns.barplot() 是 seaborn 库中绘制条形图的函数
- x 参数指定条形图的x轴数据(户型类别)
- y 参数指定条形图的高度(各户型数量)
- seaborn 是基于 matplotlib 的高级可视化库,提供更美观的默认样式和更简洁的API
👉坐标轴调整
✈当x轴标签较长或较多时,旋转可以避免标签重叠
plt.xticks(rotation=90, horizontalalignment='right')
- plt.xticks() 用于自定义x轴刻度标签
- rotation=90 将x轴标签旋转90度(垂直显示)
- horizontalalignment=‘right’ 设置标签右对齐,使显示更整齐
👉 图表保存
plt.savefig('./image/house_layout_distribution.png', dpi=300, bbox_inches='tight')
- plt.savefig() 用于将图表保存为图像文件
- dpi=300 设置保存图像的分辨率为300dpi(高于显示分辨率)
- bbox_inches=‘tight’ 自动调整边界框,避免标签被截断
给出的图片显示如下:
5.2 房源面积与总价
这段代码主要用于处理和分析二手房数据中的面积与总价关系,并通过散点图进行可视化展示
👉数据类型转换
data['面积(平米)'] = pd.to_numeric(data['面积(平米)'], errors='coerce')
data['总价(万)'] = pd.to_numeric(data['总价(万)'], errors='coerce')
- pd.to_numeric() 是 pandas 中将数据转换为数值类型的函数
- errors=‘coerce’ 参数表示当转换失败时(如遇到非数字字符串),将值设为
NaN(Not a Number)
👉 散点图绘制
sns.scatterplot(x='面积(平米)', y='总价(万)', data=data)
- sns.scatterplot() 是 seaborn 中绘制散点图的函数
5.3 各区二手房平均单价的热力图
👉数据聚合计算
average_price_by_district = data.groupby('区')['单价(元/平米)'].mean().reset_index()
print(average_price_by_district)
districts = average_price_by_district['区'].tolist()
average_prices = average_price_by_district['单价(元/平米)'].tolist()
- groupby() 是 pandas 的分组聚合函数,按’区’列分组
- mean() 计算每个分组的平均值
- reset_index() 将分组结果转换回DataFrame格式
- tolist() 将Series转换为Python列表,便于后续使用
DataFrame是Python中Pandas库的核心数据结构,是一种二维的、表格型的数据结构,类似于Excel表格或SQL数据库中的表
👉数据重构
pd.DataFrame(average_prices, index=districts, columns=['Average Price (Yuan/M^2)'])
- 将列表数据重新构建为DataFrame
- 使用行政区名作为索引(index)
- 单列数据,列名为
Average Price (Yuan/M^2) - 这种结构适合热力图输入要求
👉热力图绘制
✈ 热力图适合展示单变量在不同类别上的数值分布
sns.heatmap(
data=..., # 数据源
annot=True, # 显示数值
fmt=".0f", # 数值格式化为整数
cmap="Reds", # 红色系颜色映射
cbar_kws={'label': 'Average Price (元/平米)'} # 颜色条标签
)
- annot=True 在每个单元格中显示数值
- fmt=“.0f” 控制数值显示格式(0位小数)
- cmap=“Reds” 使用红色渐变表示数值大小
- cbar_kws 自定义颜色条属性
5.4 不同户型的占比分布
👉数据统计
house_type_counts = data['户型'].value_counts(normalize=True)
- value_counts() 是 pandas 中统计唯一值出现次数的方法
- normalize=True 参数返回的是比例而非绝对计数
- 结果是一个 Series,索引是户型类别,值是对应的占比(0-1之间)
- 这种统计方式适合展示类别数据的分布比例
👉饼图绘制
plt.pie(
house_type_counts, # 数据
labels=house_type_counts.index, # 标签
autopct='%1.1f%%', # 百分比格式
startangle=140, # 起始角度
colors=plt.cm.tab20.colors # 颜色方案
)
- house_type_counts:占比数据
- labels:每个扇区对应的标签(户型名称)
- autopct=‘%1.1f%%’:在扇区上显示百分比,保留1位小数
- startangle=140:从140度开始绘制第一个扇区(顺时针方向)
- colors=plt.cm.tab20.colors:使用tab20色板的颜色
5.5 不同行政区的修类型分布情况
👉数据统计与透视
total_by_district = data.groupby('区')['装修类型'].value_counts(normalize=True) * 100
pivot_table = total_by_district.unstack(fill_value=0).fillna(0)
- groupby(‘区’)[‘装修类型’] 按行政区对装修类型分组
- value_counts(normalize=True) 计算每种装修类型的占比(0-1)
- *100 将比例转换为百分比(0-100)
- unstack() 将多级索引的Series转换为DataFrame(装修类型变为列)
- fill_value=0和fillna(0)确保没有数据的组合显示为0%
👉折线图绘制
for column in pivot_table:
plt.plot(pivot_table.index, pivot_table[column], marker='o', label=column)
- 遍历DataFrame的每一列(每种装修类型)
- plt.plot()绘制折线图,参数包括:
- x轴数据:区域名称(pivot_table.index)
- y轴数据:装修占比(pivot_table[column])
- marker='o’在数据点显示圆形标记
- label=column设置图例标签
聚类分析
为了自动分类相似属性的房源,揭示市场细分结构,帮助理解不同群体的住房需求,评估房价合理性,为买家、卖家及投资者提供定制化信息和策略指导,同时也能洞察市场趋势,优化资源配置,提升决策效率与服务质量。我们对上海市的二手房数据进行聚类分析。
我们使用sklearn库中的KMeans聚类方法来对数据进行聚类工作。Scikit-learn(通常简称为sklearn)是一个开源的机器学习库,它构建于Python编程语言之上,是Python中最广泛使用的机器学习框架之一。
我们选取单价、总价、面积这三个数值型字段进行作为特征。在这之前,我们还需要对这三个字段的数据进行标准化操作。K-means等基于距离的聚类算法依赖于数据点间的距离计算。如果没有标准化,不同特征的量纲和大小可能导致计算出的距离失去实际意义。
数据准备与标准化
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
features = ['单价(元/平米)', '总价(万)', '面积(平米)']
X = data[features]
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
- 数据标准化:使用
StandardScaler对数据进行标准化处理(均值为0,方差为1) - 消除不同特征量纲的影响
- 使各特征对聚类结果的贡献度相同
- fit_transform():计算均值和标准差并立即应用转换
确定最佳聚类数量(肘部法则)
inertias = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', random_state=42)
kmeans.fit(X_scaled)
inertias.append(kmeans.inertia_)
K-means参数:
- n_clusters:尝试1到10个聚类
- init=‘k-means++’:智能初始化聚类中心,加速收敛
- random_state=42:统一随机值,确保结果可复现
结论
本数据分析报告通过深入挖掘上海市二手房市场中的户型、单价、面积、总价以及区域分布,并结合聚类分析,揭示了市场的主要特征和潜在趋势。分析结果显示,上海市二手房市场呈现出明显的层次化和差异化特征,主要可分为三类群体:低价小户型、中价中型房、以及高价大户型,且这些群体在地理位置上也表现出特有的分布规律。
后记
本博客主要的代码参考原csdn付费文章——上海二手房数据分析
加上临近期末,于是把这个项目拆开总结成知识点共初学者学习
可以更好的加深对这门课的理解
所需源代码还请支持原作者!
原创不易,还请大家多多支持!