目录
第一题
为什么答案是103而不是104?
第二题
为什么必须按长度排序?
第三题
易错点总结
第四题
逻辑问题:
可能超过时间复杂度的代码示例
1. 暴力枚举所有可能的子串
2. 递归回溯
第五题
1. 暴力枚举法
2. 优化枚举
3.数学优化(数论 + 前缀和)
第六题
1. 暴力枚举法(Brute Force)
2. 动态规划 (O (n²))
第七题
代码 1(使用index()查找目标位置)
代码 2(直接计算目标位置)
第八题
第一题
P12170 [蓝桥杯 2025 省 Python B] 攻击次数 - 洛谷
题目描述
小蓝正在玩一个游戏,游戏中小蓝要控制自己的三个英雄来攻击一个敌人。敌人初始的血量为 2025。
小蓝的第一个英雄攻击力恒定,每回合攻击 5 的血量。
小蓝的第二个英雄拥有一些技能,奇数回合触发,攻击 15 的血量,偶数回合攻击 2 的血量。
小蓝的第三个英雄拥有一些道具,当回合数除以 3 的余数为 1 时攻击 2 的血量;当回合数除以 3 的余数为 2 时攻击 10 的血量;当回合数除以 3 的余数为 0 时攻击 7 的血量。
游戏从第 1 回合开始。不考虑敌人对小蓝英雄的攻击,敌人的血量也仅受攻击的影响。如果敌人的血量小于等于零,则游戏结束。
请问到第几回合游戏结束?
输入格式
无
输出格式
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只需要编写一个程序输出这个整数,输出多余的内容将无法得分。
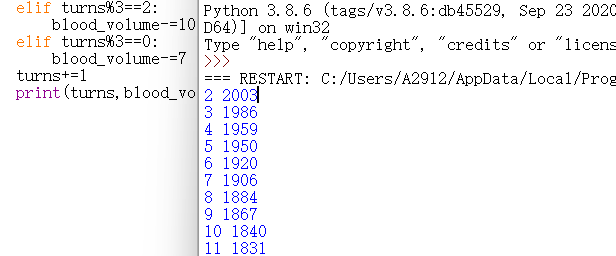
blood_volume=2025
turns=1
while blood_volume>0:
blood_volume-=5
if turns%2==1:
blood_volume-=15
elif turns%2==0:
blood_volume-=2
if turns%3==1:
blood_volume-=2
elif turns%3==2:
blood_volume-=10
elif turns%3==0:
blood_volume-=7
print(turns,blood_volume)
# 如果将turns错误写在前面,那就应该检查一下答案
turns+=1
可以看到第102回合敌人血量大于0而第103回合敌人血量小于0,所以正确答案为103。
为什么答案是103而不是104?
如果将turns错误写在前面,那就应该检查一下答案,发现是从2开始计数
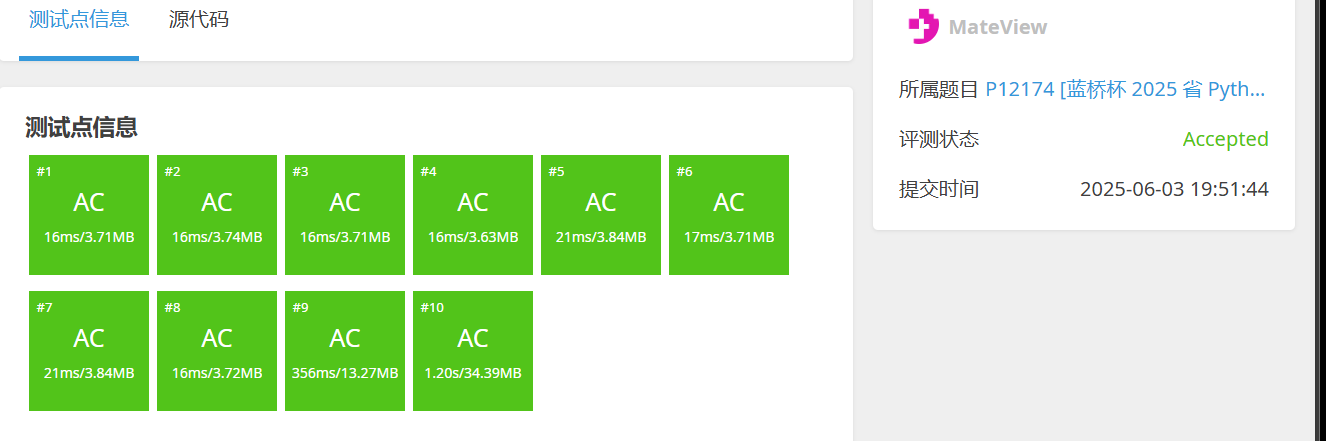
第二题
P12171 [蓝桥杯 2025 省 Python B] 最长字符串 - 洛谷
题目描述
小蓝手里有一个单词本,上面记录了一些单词,保存在 words.txt 中,其中每一行包含一个仅有小写英文字母组成的单词。
小蓝想要找到一个最长的优美字符串。
一个长度为 n 的字符串 s=c1c2⋯cn 是优美字符串,必须满足 s 在单词本中,且满足以下两个条件之一:
n=1;
n>1,且存在一个优美字符串 s′,s′ 的长度为 n−1,s′ 的字符调整顺序后与 c1c2⋯cn−1 一致。
示例,假设 words.txt 文件中的单词如下:b、bc、cbd、dbca,那么:
s1=b,长度 1,是优美字符串;
s2=bc,s′=b 在单词本中出现过,并且是优美字符串,所以 s2 是优美字符串;
s3=cbd,s′=bc 在单词本中出现过,并且是优美字符串,所以 s3 是优美字符串;
s4=dbca,s′=cbd 在单词本中出现过,并且是优美字符串,所以 s4 是优美字符串;
现在请你帮助小蓝从单词本 words.txt 中找出长度最大的优美字符串,如果存在多个答案,优先使用字典序最小的那一个作为答案。
输入格式
输出格式
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个字符串,在提交答案时只需要编写一个程序输出这个字符串,输出多余的内容将无法得分。
输入输出样例
无
附件下载
words.txt(293.46KB)
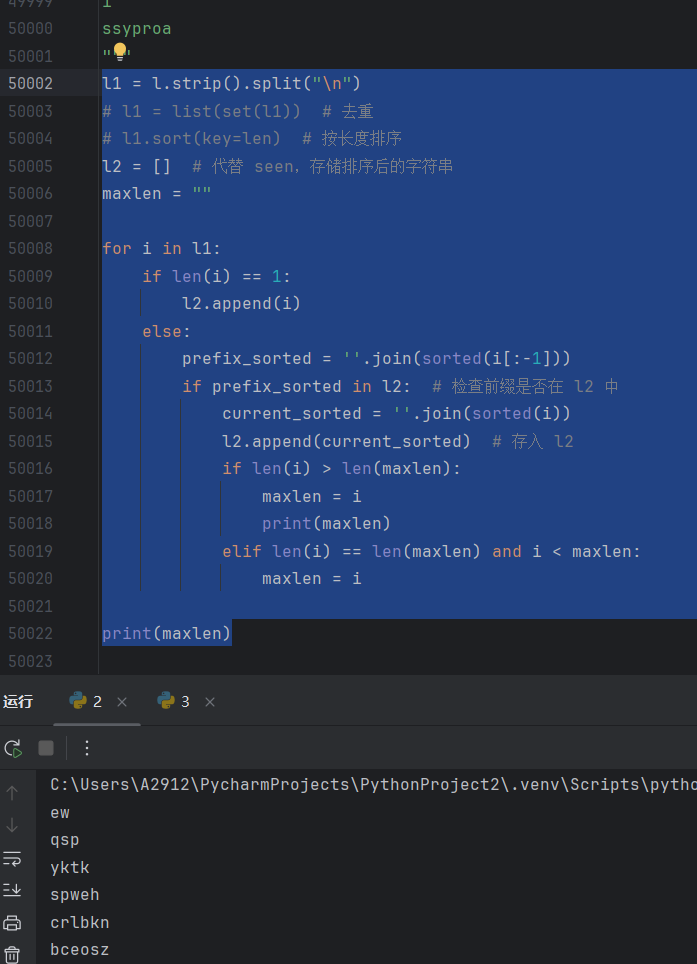
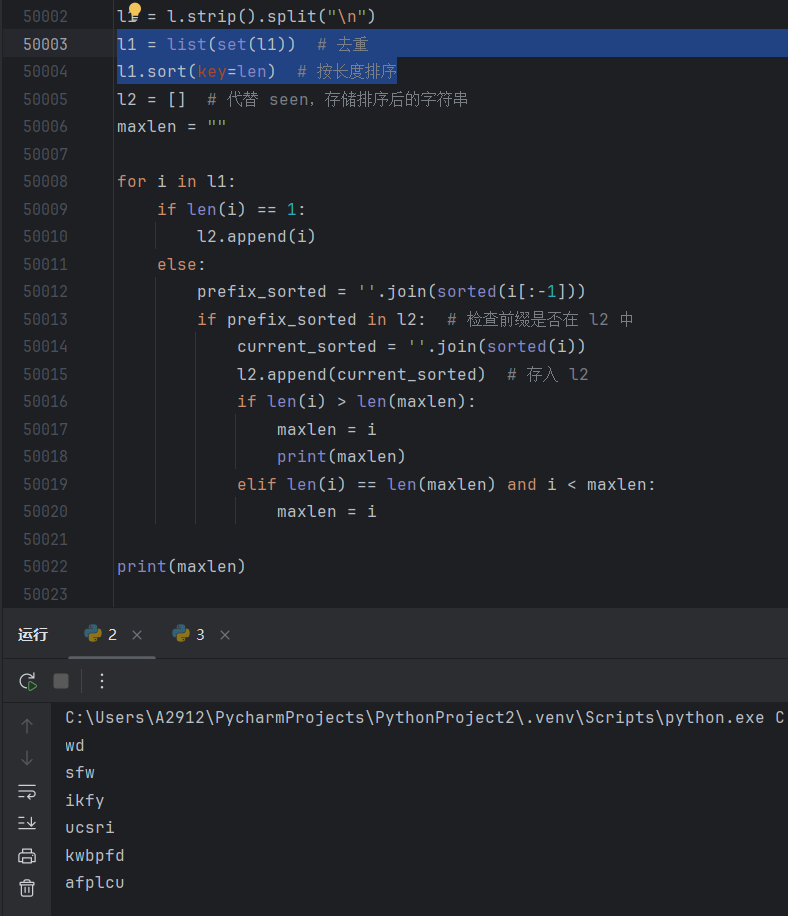
l1 = l.strip().split("\n")
l1 = list(set(l1)) # 去重
l1.sort(key=len) # 按长度排序
seen = set() # 存储排序后的字符串
maxlen = ""
for i in l1:
if len(i) == 1:
seen.add(i)
else:
prefix_sorted = ''.join(sorted(i[:-1]))
if prefix_sorted in seen:
current_sorted = ''.join(sorted(i))
seen.add(current_sorted)
if len(i) > len(maxlen):
maxlen = i
print(maxlen)
elif len(i) == len(maxlen) and i < maxlen:
maxlen = i
print(maxlen)
-
长度为1的字符串:
- 直接加入
seen(因为长度为1的字符串一定是优美的)。
- 直接加入
-
长度>1的字符串:
prefix_sorted = ''.join(sorted(i[:-1])):- 取当前字符串
i的前缀(去掉最后一个字符)。 - 对前缀进行排序。
- 取当前字符串
- 检查前缀是否在
seen中:- 如果在,说明当前字符串
i是优美的。 current_sorted = ''.join(sorted(i)):- 对当前字符串
i进行排序,并加入seen(用于后续判断)。
- 对当前字符串
- 如果在,说明当前字符串
- 更新
maxlen:- 如果
i比maxlen更长,更新maxlen。 - 如果长度相同但字典序更小,也更新
maxlen。
- 如果
为什么必须按长度排序?
- 优美字符串的定义:
- 长度为 1 的字符串一定是优美的。
- 长度 >1 的字符串,必须其前缀的某种排列已经存在于
l2或seen中。
- 必须先处理短字符串:
- 确保长字符串的前缀已经被处理过,否则无法正确判断。
- 期望:
'abc'是优美字符串(因为'ab'是它的前缀,且'ab'是优美字符串)。 - 但如果
'abc'先被处理:'abc'的前缀'ab'不在l2中(因为'a'和'ab'还没处理),所以'abc'不会被识别为优美字符串。
第三题
P12172 [蓝桥杯 2025 省 Python B] LQ 图形 - 洛谷
题目描述
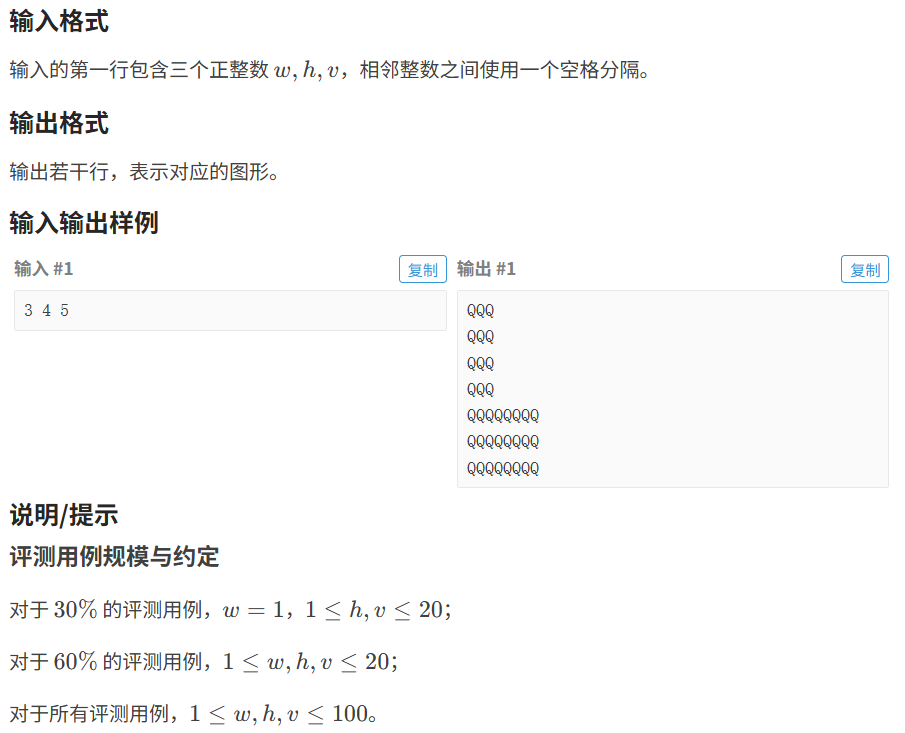
小蓝要为蓝桥画一个图形。由于小蓝的画图能力有限,他准备用大写字母 Q 画一个 L 形状的字符画。他希望 L 的粗细正好是 w 个字符宽,竖的笔划伸出 h 高(因此图形总共 h+w 高),横的笔划伸出 v 宽(因此图形总共 v+w 宽),要求每个笔划方方正正不能有多余内容。
例如,当 w=2,h=3,v=4 时,图形如下所示:
QQ QQ QQ QQQQQQ QQQQQQ给定 w,h,v,请帮助小蓝画出这个图形。
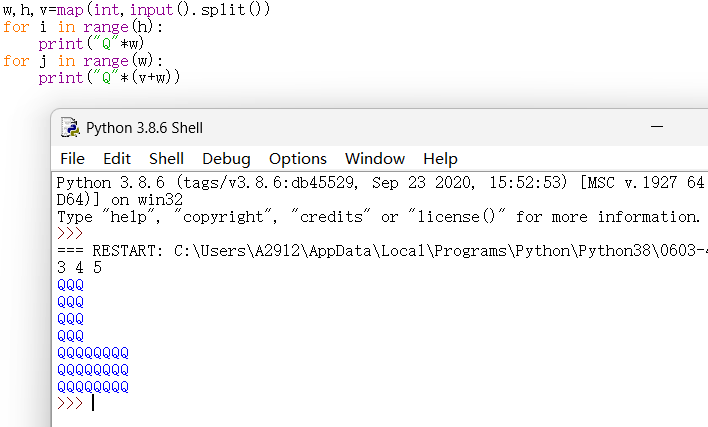
w,h,v=map(int,input().split())
for i in range(h):
print("Q"*w)
for j in range(w):
print("Q"*(v+w))
易错点总结
-
字符串表示:
- 必须用引号括起字符'Q',否则Python会将其视为变量
-
横笔划宽度计算:
- 容易忘记横笔划需要包含竖笔划的宽度(w)
- 正确的宽度应该是v + w
-
输出顺序:
- 必须先输出竖笔划(h行)
- 再输出横笔划(w行)
- 顺序颠倒会导致图形错误
-
输入处理:
- map+split
- 输入必须是三个用空格分隔的整数
第四题
题目描述
小蓝有一个字符串 s,他特别喜欢由以下三个字符组成的单词:l,q,b,任意顺序都可以,一共有 6 种可能:lqb、lbq、qlb、qbl、blq、bql。
现在他想从 s 中,尽可能切割出多个他喜欢的单词,请问最多能切割出多少个?单词指的是由若干个连续的字符组成的子字符串。
输入格式
输入一行包含一个字符串 s。
输出格式
输出一行包含一个整数表示答案。

s = input().strip()
count = 0
i = 0
n = len(s)
while i <= n - 3:
if {s[i], s[i+1], s[i+2]} == {'l', 'q', 'b'}:
count += 1
i += 3
else:
i += 1
print(count)
s=input()
num=0
l=["lqb","lbq","qlb","qbl","blq","bql"]
i=0
while i<=len(s)-3:
if s[i:i+3] in l:
num+=1
i+=3
else:
i+=1
print(num)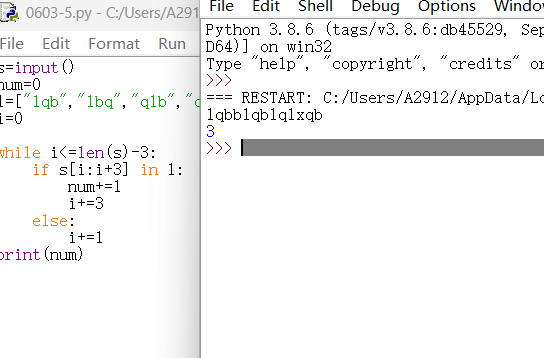
逻辑问题:
- 当
i接近字符串末尾时,i+3可能超出字符串长度,导致IndexError。 - 每次匹配成功后,应该跳过这三个字符(即
i += 3),否则会重复计算。
可能超过时间复杂度的代码示例
1. 暴力枚举所有可能的子串
s = input().strip()
valid_words = {"lqb", "lbq", "qlb", "qbl", "blq", "bql"}
max_count = 0
def backtrack(start, current_count):
global max_count
if start >= len(s):
max_count = max(max_count, current_count)
return
# 尝试切割长度为3的子串
if start + 3 <= len(s) and s[start:start+3] in valid_words:
backtrack(start + 3, current_count + 1)
# 不切割,直接跳过当前字符
backtrack(start + 1, current_count)
backtrack(0, 0)
print(max_count)
2. 递归回溯
s = input().strip()
valid_words = {"lqb", "lbq", "qlb", "qbl", "blq", "bql"}
memo = {}
def dp(start):
if start >= len(s):
return 0
if start in memo:
return memo[start]
max_cuts = 0
# 尝试切割当前位置开始的子串
if start + 3 <= len(s) and s[start:start+3] in valid_words:
max_cuts = 1 + dp(start + 3)
# 不切割,继续下一个位置
max_cuts = max(max_cuts, dp(start + 1))
memo[start] = max_cuts
return max_cuts
print(dp(0))
| 暴力枚举法 | O(2ⁿ) | O(n) | 递归遍历所有可能的切割组合,使用全局变量记录最大切割数 |
| 递归回溯法 | O(n) | O(n) | 带记忆化的递归,避免重复计算,确保每个子问题只求解一次 |
| 贪心算法 | O(n) | O(1) | 线性扫描,遇到有效单词立即切割,直接跳过已使用字符,无需回溯 |
第五题
设有两个二维向量 A(XA,YA),B(XB,YB)。给定 L,求 (XA,YA),(XB,YB) 有多少种不同的取值,使得:
XA,YA,XB,YB 均为正整数;
A⋅B≤L,其中 A⋅B 表示 A,B 的内积,即 XA⋅XB+YA⋅YB。
输入格式
输入的第一行包含一个正整数 L,表示题目描述中的限制条件。
输出格式
输出一行包含一个整数表示答案。

1. 暴力枚举法
L = int(input())
count = 0
for xa in range(1, L + 1):
for ya in range(1, L + 1):
for xb in range(1, L + 1):
for yb in range(1, L + 1):
if xa * xb + ya * yb <= L:
count += 1
print(count)
2. 优化枚举
L = int(input())
count = 0
for xa in range(1, L + 1):
for ya in range(1, L + 1):
# 对于固定的 xa、ya,求满足 xb*xa + yb*ya <= L 的 (xb, yb) 正整数对数量
max_sum = L
for xb in range(1, L + 1):
# 计算当前 xb 下,yb 满足 ya*yb <= max_sum - xa*xb
remain = max_sum - xa * xb
if remain <= 0:
break
# yb 至少为 1,最多为 remain // ya
max_yb = remain // ya
if max_yb >= 1:
count += max_yb
print(count)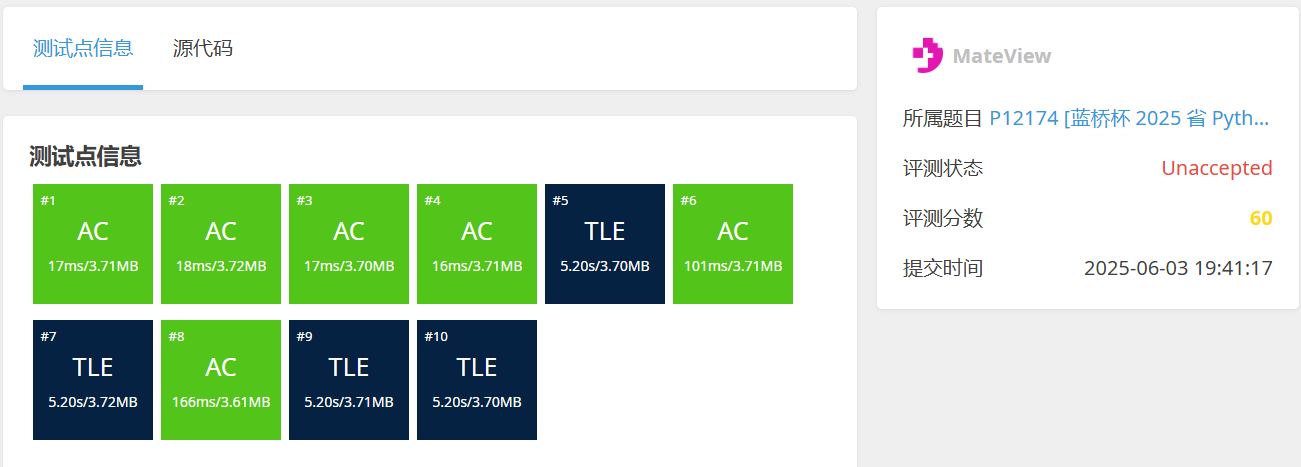
3.数学优化(数论 + 前缀和)
L = int(input())
ans = 0
a = [0] * (L + 1) # a[s] 表示 s 的约数个数(即 YA*YB=s 的对数)
b = [0] * (L + 1) # b[t] 表示前缀和 sum_{k=1}^t a[k](即 XA*XB≤t 的对数)
# 步骤1:计算每个数的约数个数(O(L log L))
for i in range(1, L + 1):
for j in range(i, L + 1, i):
a[j] += 1 # 约数个数计数器 +1
# 步骤2:计算约数个数的前缀和(O(L))
for i in range(1, L + 1):
b[i] = b[i-1] + a[i] # 前缀和数组
# 步骤3:统计答案(O(L))
for i in range(1, L + 1):
ans += a[i] * b[L-i] # 统计答案
print(ans)步骤1:计算约数个数:
- 使用类似筛法的方式,遍历每个数
i的倍数j,统计j的约数个数。时间复杂度为O(L log L)。
步骤2:计算前缀和:
- 计算
a数组的前缀和b,使得b[t]表示sum_{k=1}^t a[k]。时间复杂度为O(L)。
步骤3:统计答案:
- 对于每个
i,a[i]是YA * YB = i的对数,b[L - i]是XA * XB ≤ L - i的对数。将两者相乘并累加得到最终答案。时间复杂度为O(L)。
第六题
P12175 [蓝桥杯 2025 省 Python B] 园艺 - 洛谷
小蓝从左到右种了 n 棵小树,第 i 棵树的高度为 hi,相邻树的间隔相同。小蓝想挪走一些树使得剩下的树等间隔分布,且从左到右高度逐渐上升(相邻两棵树高度满足右边的比左边的高),小蓝想知道最多能留下多少棵树。
输入格式
输入的第一行包含一个正整数 n。
第二行包含 n 个正整数 h1,h2,⋯,hn,相邻整数之间使用一个空格分隔。
输出格式
输出一行包含一个整数表示答案。

1. 暴力枚举法(Brute Force)
- 枚举所有可能的起点
i和间隔d,从起点开始按固定间隔d遍历数组,统计满足严格递增条件的最长子序列长度。 - 关键逻辑:对于每个
i和d,逐个检查后续元素是否递增,若不满足则终止当前检查。
n = int(input())
h = list(map(int, input().split()))
if n == 0:
print(0)
max_len = 1 # 至少保留1棵树
for i in range(n):
for d in range(1, n): # 间隔d从1到n-1(至少间隔1个位置)
current_pos = i
current_len = 1 # 初始包含起点
prev_height = h[current_pos]
next_pos = current_pos + d
while next_pos < n:
if h[next_pos] > prev_height:
current_len += 1
prev_height = h[next_pos]
current_pos = next_pos
next_pos = current_pos + d
else:
break # 不满足递增,提前终止
# 即使循环提前终止,current_len至少为1(起点),但有效子序列需至少2个元素
if current_len >= 2: # 确保子序列长度≥2
if current_len > max_len:
max_len = current_len
print(max_len)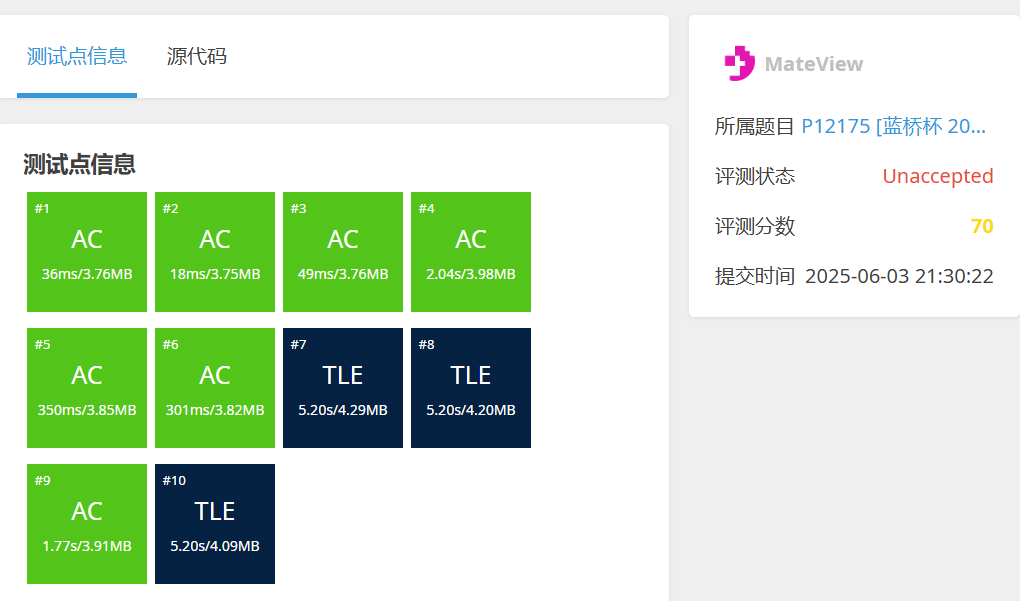
2. 动态规划 (O (n²))
思路:用 dp[i][d] 表示以第 i 棵树结尾、间隔为 d 的最长序列长度。
n = int(input())
a = list(map(int, input().split()))
dp = [[1] * (n + 1) for i in range(n)]
for i in range(n):
for j in range(i):
if a[i] > a[j]: # 满足高度递增
d = i - j # d为两树之间间隔
dp[i][d] = max(dp[i][d], dp[j][d] + 1)
ans = 0
for row in dp:
if max(row) > ans: # 找最大值
ans = max(row)
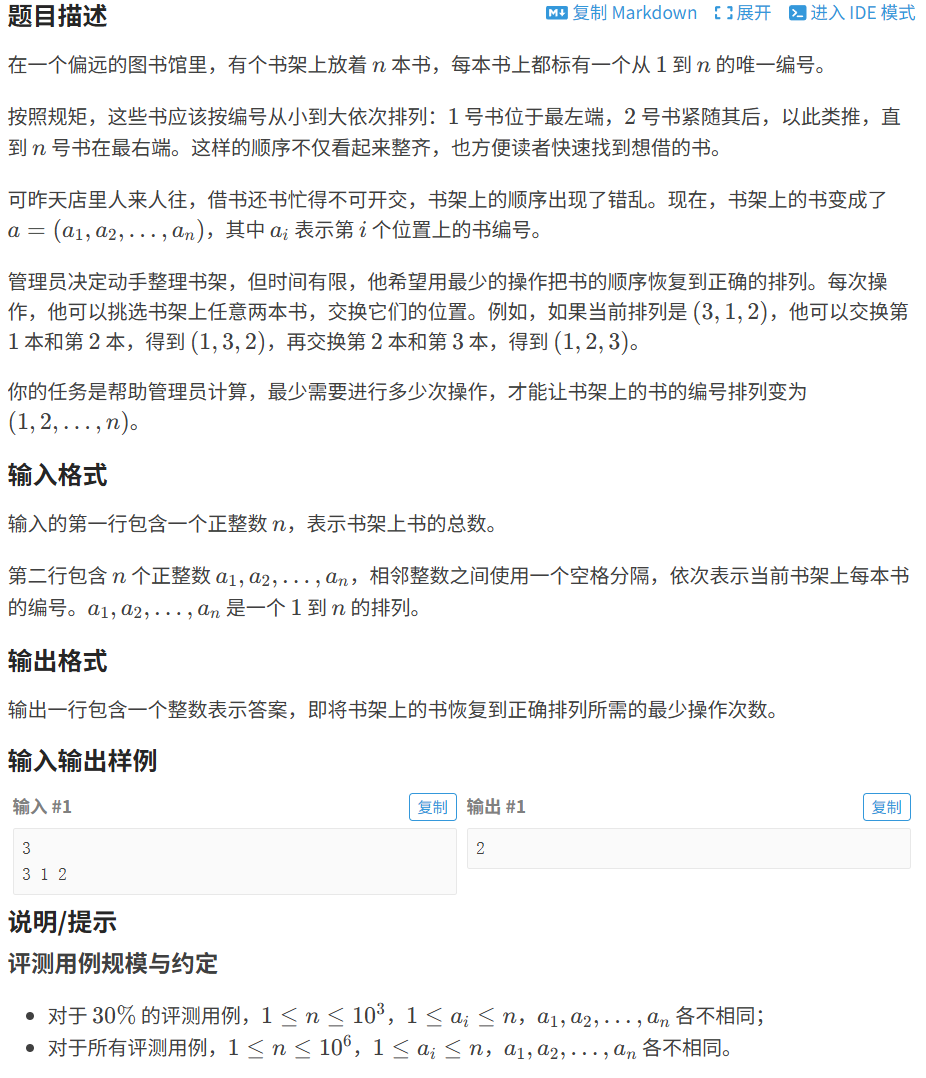
print(ans)第七题
P12176 [蓝桥杯 2025 省 Python B] 书架还原 - 洛谷
题目描述
在一个偏远的图书馆里,有个书架上放着 n 本书,每本书上都标有一个从 1 到 n 的唯一编号。
按照规矩,这些书应该按编号从小到大依次排列:1 号书位于最左端,2 号书紧随其后,以此类推,直到 n 号书在最右端。这样的顺序不仅看起来整齐,也方便读者快速找到想借的书。
可昨天店里人来人往,借书还书忙得不可开交,书架上的顺序出现了错乱。现在,书架上的书变成了 a=(a1,a2,…,an),其中 ai 表示第 i 个位置上的书编号。
管理员决定动手整理书架,但时间有限,他希望用最少的操作把书的顺序恢复到正确的排列。每次操作,他可以挑选书架上任意两本书,交换它们的位置。例如,如果当前排列是 (3,1,2),他可以交换第 1 本和第 2 本,得到 (1,3,2),再交换第 2 本和第 3 本,得到 (1,2,3)。
你的任务是帮助管理员计算,最少需要进行多少次操作,才能让书架上的书的编号排列变为 (1,2,…,n)。
代码 1(使用index()查找目标位置)
- 遍历每个位置
i:检查当前位置的元素是否等于i+1(即是否在正确位置)。 - 查找目标位置:若不在正确位置,使用
index()方法找到值为i+1的元素的当前位置j。 - 交换元素:将位置
i和j的元素交换,使i位置的元素归位。 - 重复循环:直到当前位置
i的元素正确。
n = int(input())
a = list(map(int, input().split()))
count = 0
for i in range(n):
while a[i] != i + 1:
# 找到正确位置的书的当前索引
j = a.index(i + 1)
a[i], a[j] = a[j], a[i]
count += 1
print(count)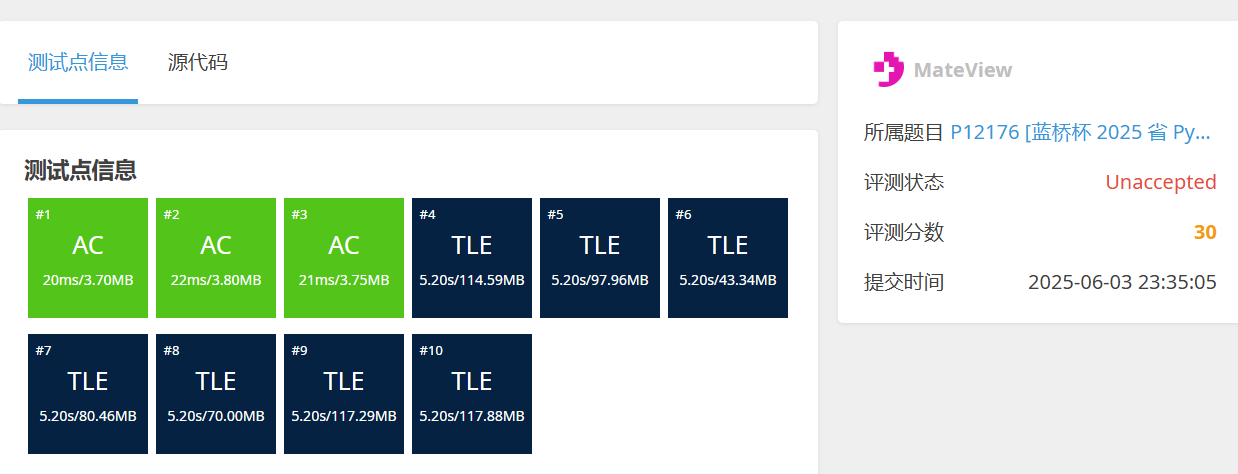
代码 2(直接计算目标位置)
- 遍历每个位置
i:检查当前位置的元素是否满足nums[i] == i+1。 - 计算目标位置:若不满足,直接计算当前元素
nums[i]应该在的位置ans-1(即nums[i]-1)。 - 交换元素:将当前位置
i的元素与目标位置ans-1的元素交换。 - 重复循环:直到当前位置
i的元素正确。
n = int(input())
nums = list(map(int, input().split()))
count = 0
for i in range(n):
while i != nums[i] - 1:
ans = nums[i] # 当前元素的值
nums[i] = nums[ans - 1] # 将目标位置的元素放到i位置
nums[ans - 1] = ans # 当前元素放到目标位置
count += 1
print(count)代码 1(index()) | 代码 2(直接计算) |
|---|---|
使用index()查找目标位置 | 直接通过值计算目标位置 |
| 时间复杂度 O (n²) | 时间复杂度 O (n) |
第八题
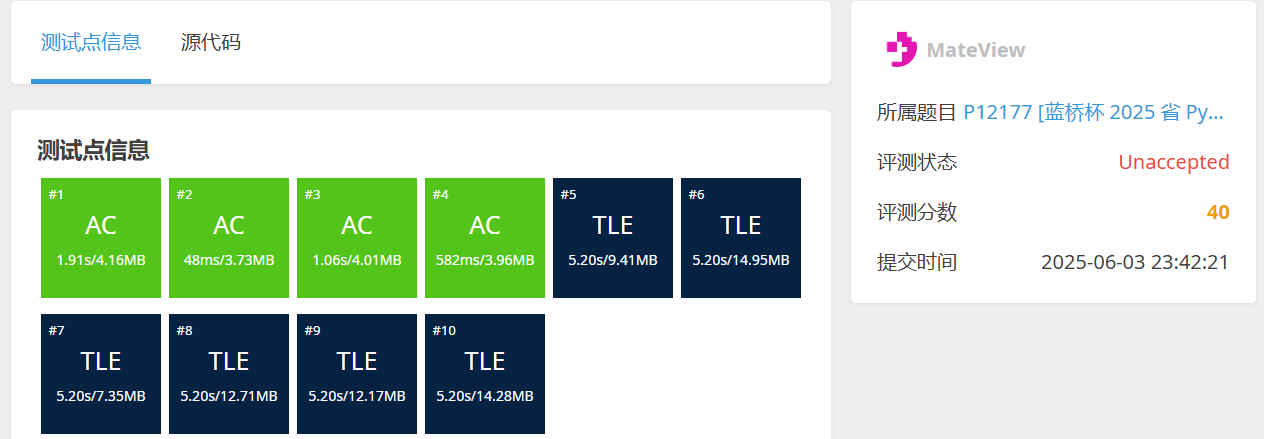
P12177 [蓝桥杯 2025 省 Python B] 异或和 - 洛谷
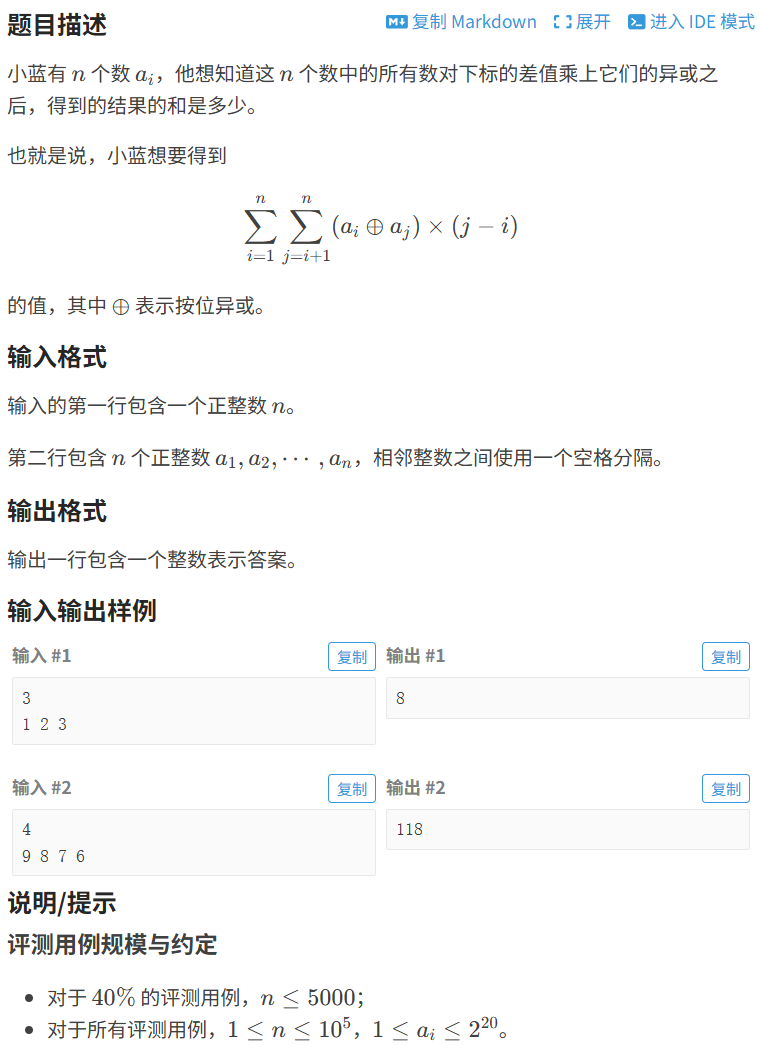
- 对于每对数
(nums[i], nums[j]),计算它们的异或值nums[i] ^ nums[j]。
n = int(input())
nums = list(map(int, input().split()))
ans = 0
for i in range(n):
for j in range(i+1, n):
x = j - i # 计算下标差
ans += (nums[i] ^ nums[j]) * x # 异或结果乘以坐标差,累加到答案中
print(ans)如果只想拿“省一”的话,考试时候写能写对这样的暴力算法就很“厉害”了🤧。