RNN(循环神经网络)是一种专门处理序列数据的神经网络架构,在自然语言处理(NLP)、语音识别、时间序列分析等领域有广泛应用。其核心作用是捕捉序列中的时序依赖关系,即当前输出不仅取决于当前输入,还与过去的状态有关。
1. RNN 的核心功能
(1)处理变长序列
传统神经网络(如 MLP、CNN)要求输入维度固定,而 RNN 可以处理不同长度的序列(如句子、时间序列)。
(2)记忆过去信息
通过隐藏状态(hidden state)的传递,RNN 能够 “记住” 序列中的历史信息。例如在语言模型中,预测下一个词时会参考前文语境。
(3)共享参数
RNN 在序列的每个时间步使用相同的权重参数,这使得模型能够处理任意长度的序列,并减少了参数数量。
2. RNN 的结构与工作原理
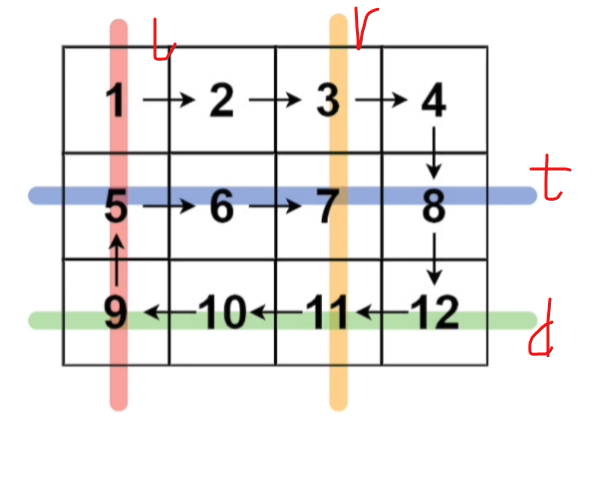
RNN 的基本结构包含一个循环单元,在每个时间步t:
- 接收当前输入\(x_t\)和上一时间步的隐藏状态\(h_{t-1}\)
- 计算新的隐藏状态\(h_t = \sigma(W_{hh}h_{t-1} + W_{xh}x_t + b)\)
- 生成输出\(y_t = W_{hy}h_t + c\)
其中\(\sigma\)是激活函数(如 tanh 或 ReLU),W和b是可学习的参数。
这种结构使得 RNN 能够建立起序列中不同时间步之间的依赖关系。
3. RNN 的典型应用场景
(1)自然语言处理(NLP)
- 语言模型:预测下一个词的概率(如 GPT 系列)。
- 机器翻译:将一种语言翻译成另一种语言(如 seq2seq 模型)。
- 文本生成:生成连贯的文本段落。
- 情感分析:判断文本的情感倾向。
(2)语音识别
将语音信号转换为文本(如 DeepSpeech 模型)。
(3)时间序列预测
- 股票价格预测
- 天气预测
- 电力负荷预测
(4)视频分析
- 动作识别
- 视频帧预测
4. RNN 的局限性与改进
(1)梯度消失 / 爆炸问题
传统 RNN 在处理长序列时,梯度在反向传播过程中会指数级衰减或增长,导致模型难以学习长期依赖关系。
(2)改进方案:LSTM 和 GRU
- LSTM(长短期记忆网络):引入门控机制(输入门、遗忘门、输出门),有效缓解了梯度消失问题,能捕捉更长距离的依赖关系。
- GRU(门控循环单元):简化了 LSTM 的结构,计算效率更高,同样擅长处理长序列。
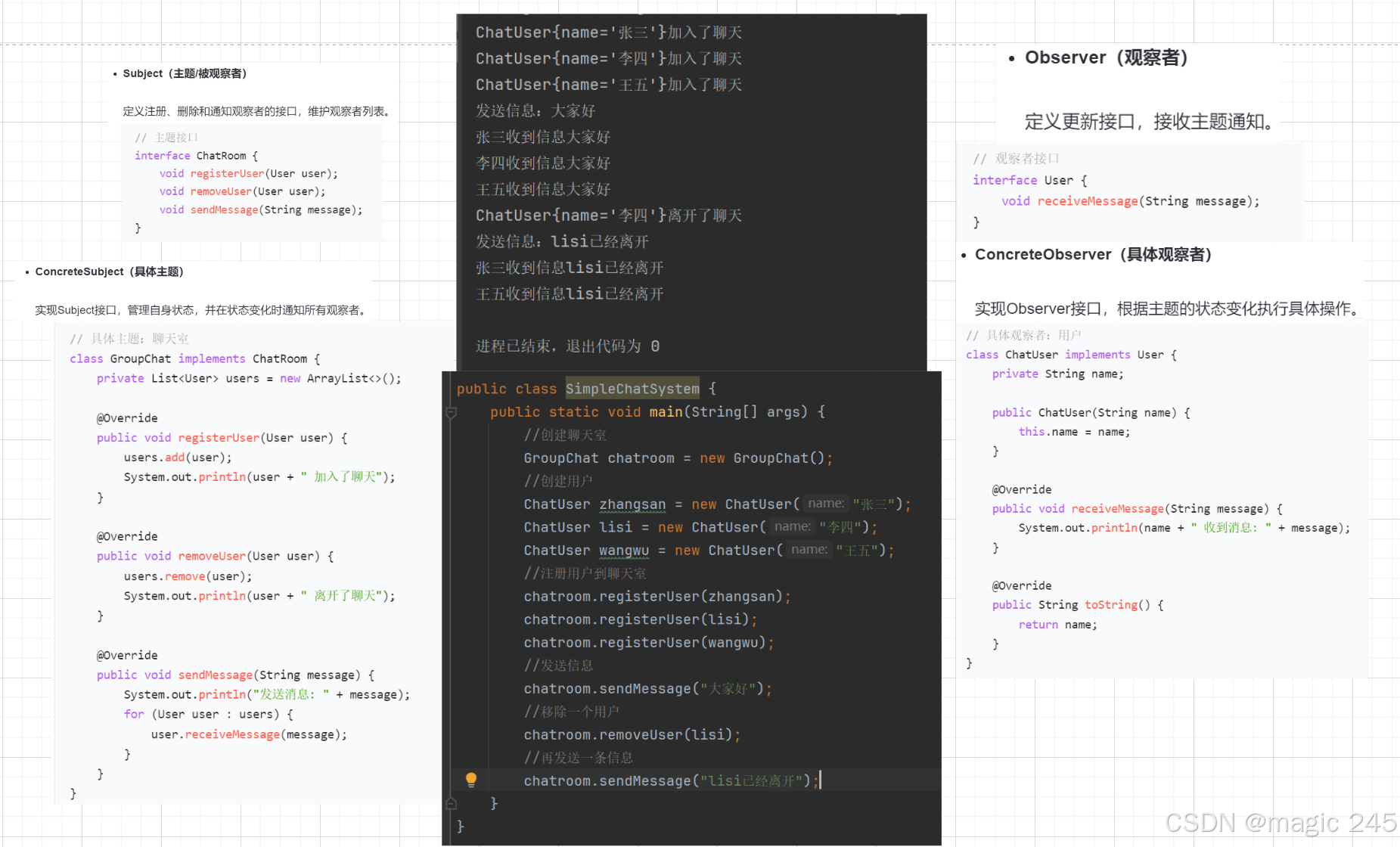
5. 示例:使用 RNN 进行情感分析
下面是一个简化的 RNN 用于情感分析的示意图:
plaintext
输入序列(单词) → [我, 喜欢, 这部, 电影]
↓
嵌入层(词向量) → [w1, w2, w3, w4]
↓
RNN层(隐藏状态传递):
h1 = f(W·h0 + U·w1)
h2 = f(W·h1 + U·w2)
h3 = f(W·h2 + U·w3)
h4 = f(W·h3 + U·w4)
↓
输出层 → 情感分类(积极/消极)
在这个例子中,RNN 通过隐藏状态\(h_t\)依次处理每个词向量,最终根据整个序列的信息做出分类决策。
6. 与其他模型的对比
| 模型 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| RNN | 短序列建模 | 结构简单,处理序列数据 | 长序列时梯度消失 / 爆炸 |
| LSTM/GRU | 长序列建模 | 解决长期依赖问题 | 参数多,计算成本较高 |
| Transformer | 并行计算能力强,长序列建模 | 自注意力机制,全局信息捕捉 | 缺乏显式的时序建模能力 |
总结
RNN 的核心作用是建模序列数据中的时序依赖关系,但传统 RNN 在处理长序列时存在局限性。现代深度学习中,LSTM 和 GRU 已基本取代了传统 RNN,而 Transformer 架构则在许多场景下成为了更优选择。不过,RNN 及其变体仍然是序列建模的基础工具之一。
大模型相关经验 和NLP CNN RNN神经网络 关系
大模型(如 GPT、BERT、Llama 等)与传统神经网络(NLP、CNN、RNN)的关系可以概括为:大模型是基于传统神经网络架构的扩展与创新。理解它们的联系与区别,对求职和技术发展方向至关重要。
1. 技术演进关系
(1)基础架构继承
- NLP 任务:大模型本质上是处理自然语言的神经网络,继承了传统 NLP 的目标(如文本生成、分类、翻译)。
- Transformer 架构:大模型普遍基于 Transformer(2017 年提出),而 Transformer 中的 Self-Attention 机制可视为 RNN 的替代方案,解决了长序列依赖问题。
- CNN 的局部特征提取:虽然大模型以 Transformer 为主流,但某些任务(如图文多模态)仍会融合 CNN 提取图像特征(如 CLIP 模型)。
(2)核心创新
- 大规模预训练:通过百亿至万亿参数的模型和海量无标注数据(如互联网文本)进行预训练,学习通用语言表示。
- 微调(Fine-tuning)范式:预训练后,通过少量特定任务数据微调模型,大幅降低了传统 NLP 任务的开发成本。
- 涌现能力(Emergent Abilities):模型规模达到一定阈值后,表现出超出训练数据范围的推理、创作等能力。
2. 岗位需求对比
| 岗位技能 | 传统 NLP/RNN/CNN | 大模型相关 |
|---|---|---|
| 核心算法 | RNN/LSTM/GRU、CNN、Seq2Seq、注意力机制 | Transformer、Self-Attention、LoRA、QLoRA |
| 数据规模 | 中小规模标注数据(万级样本) | 大规模无标注数据(亿级文本) |
| 训练资源 | 单卡 / 多卡 GPU(如 RTX 3090) | 集群训练(如 8×A100、TPU) |
| 典型任务 | 文本分类、命名实体识别、机器翻译 | 聊天机器人、知识问答、多模态生成(文生图) |
| 工具链 | PyTorch/TensorFlow 基础库 | Transformers、LangChain、DeepSpeed、FastChat |
| 落地场景 | 垂直领域模型(如医疗、金融) | 通用 AI 应用(如智能助手、内容生成平台) |
3. 大模型岗位的核心能力要求
(1)Transformer 深度理解
- 掌握 Self-Attention 计算原理、位置编码、多头注意力机制。
- 熟悉 Decoder-only(如 GPT)、Encoder-only(如 BERT)、Encoder-Decoder(如 T5)的差异。
(2)模型训练与优化
- 分布式训练(Data Parallel、Model Parallel)。
- 参数高效微调(PEFT)技术:LoRA、QLoRA、Adapter。
- 量化与推理加速(INT8、FP16、LLM.int8 ())。
(3)工程化能力
- 基于 LangChain 构建应用(Prompt Engineering、向量数据库、代理工具调用)。
- 大模型部署(Triton Inference Server、vLLM)。
- 多模态融合(图像、语音、文本联合建模)。
(4)领域应用经验
- 垂直领域微调(如医疗知识问答、代码生成)。
- 指令调优(Instruction Tuning)与对齐技术(RLHF)。
4. 传统神经网络技能的价值
虽然大模型是当前热点,但传统技能仍是基础:
- 序列建模理解:RNN/LSTM 的时序处理思想有助于理解时间序列相关任务(如语音、视频)。
- 特征工程能力:传统 NLP 中的词法分析、句法分析在特定领域(如法律、医疗)仍有价值。
- 小模型优化:资源受限场景下,轻量级模型(如 BERT-base)仍需结合 CNN/RNN 进行优化。
- 多模态融合:CNN 在图像特征提取中的优势,可与大模型结合(如 BLIP-2、GPT-4V)。
5. 如何快速转型大模型领域
(1)学习路线
- 理论基础:Transformer 论文精读(Attention Is All You Need)。
- 工具链实践:
- 使用 Hugging Face Transformers 库微调 BERT/GPT。
- 实现 LoRA 微调(参考论文:LoRA: Low-Rank Adaptation of Large Language Models)。
- 基于 LangChain 开发简单应用(如知识库问答)。
- 实战项目:
- 垂直领域大模型微调(如金融新闻摘要)。
- 多模态模型部署(如 Stable Diffusion 文生图)。
(2)推荐资源
- 论文:Attention Is All You Need、LoRA、QLoRA、LLaMA。
- 开源库:Transformers、LangChain、DeepSpeed、vLLM。
- 课程:斯坦福 CS25: Large Language Models、吴恩达《ChatGPT Prompt Engineering for Developers》。
总结
大模型岗位要求在传统神经网络基础上,深入掌握 Transformer 架构、大规模训练与工程化部署能力。对于求职者来说:
- 有传统 NLP 经验:需补充大模型训练、微调、部署等工程化技能。
- 无 AI 背景:建议从 Transformer 基础学起,重点实践开源工具链。
- 领域专家:结合行业知识进行大模型微调(如医疗、法律)是优势方向。
技术演进中,传统神经网络不会被完全取代,而是作为底层技术融入大模型生态。