在人工智能浪潮席卷全球的今天,大语言模型正以前所未有的速度推动着科技进步和产业变革。从 ChatGPT 到各类行业应用,LLM 不仅重塑了人机交互的方式,更成为推动学术研究与产业创新的关键技术。
面对这一飞速演进的技术体系,如何系统理解其理论基础、掌握核心算法与工程实践,已成为每一位 AI 从业者、研究者、高校学子的必修课。
这些发现促使本书的作者“复旦大学NLP团队”张奇、桂韬、郑锐、黄萱菁几位老师对本书第 1 版进行修订升级,补充最新的研究成果和技术内容。
《大规模语言模型:从理论到实践(第2版)》的出版上市,希望可以让读者快速掌握大语言模型的研究与应用,更好地应对相关技术挑战,为推动这一领域的进步贡献力量。
这本《大规模语言模型:从理论到实践(第2版)》书已整理并打包好PDF了



目录:
第1章 绪论1
第2章 大语言模型基础13
第3章 大语言模型预训练数据52
第4章 分布式训练83
第5章 指令微调127
第6章 强化学习164
第7章 多模态大语言模型200
第8章 大模型智能体231
第9章 检索增强生成280
第10章 大语言模型效率优化330
第11章 大语言模型评估362
第12章 大语言模型应用开发401
参考文献422
索引451
第二版核心升级内容如下:
(1) 前沿技术聚焦:深度剖析MoE架构、多模态、智能体、RAG四大技术趋势
(2) 知识体系重构:覆盖预训练→微调→强化学习→应用开发→效率优化的全流程
(3) 实践价值提升:新增逾40%的前沿研究成果与技术案例,增设工程实践指南与评估体系模块
章节
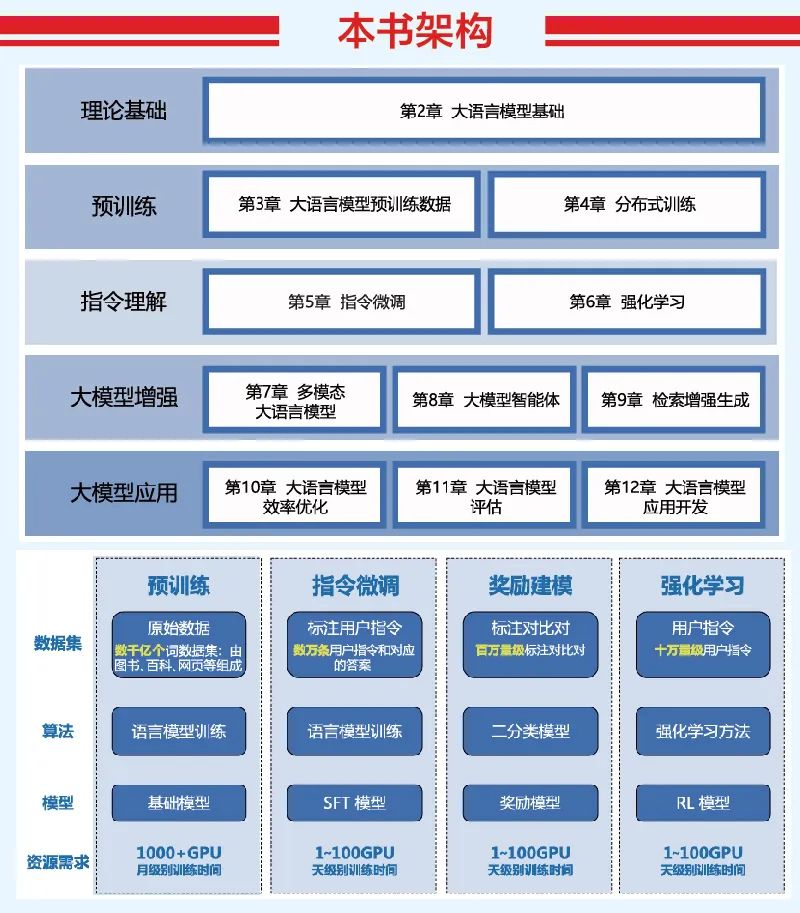
本书共分为12章,围绕大语言模型基础理论、预训练、指令理解、大模型增强和大模型应用五个部分展开。
第1章 绪论
简明介绍了大语言模型的基本概念、发展历史、构建流程,并说明了本书的结构安排,为读者建立起全局认知框架。
第2章 大语言模型基础
深入解析了 LLM 的核心结构——Transformer,包括嵌入、注意力、前馈网络等组成部分,并详解 GPT 模型、混合专家模型(MoE)等不同架构,帮助读者建立从基本结构到模型架构的技术认知。
第3章 预训练数据
介绍了预训练所需的大规模语料来源与数据处理方法(如清洗、去重、切词等),并探讨数据质量、规模、多样性对模型性能的影响。还列举了主流开源数据集,为实际预训练奠定数据基础。
第4章 分布式训练
详细讲解数据并行、模型并行、混合并行等策略及其内存优化技巧,结合实际框架(如 DeepSpeed)的实践,帮助读者理解如何高效训练大模型。
第5章 指令微调
系统介绍了指令微调的理念、数据构建与评估方法、LoRA 等高效微调技术,并辅以 DeepSpeed-Chat 的实践说明,面向实际应用强化模型指令理解与响应能力。
第6章 强化学习
聚焦于 RLHF(基于人类反馈的强化学习),介绍策略梯度、PPO 等算法在语言模型中的应用,结合 DeepSeek-R1、Kimi 等模型案例,展示 RL 在提升生成质量方面的重要作用。
第7章 多模态大语言模型
探讨语言模型与视觉、语音等模态融合的架构与挑战,并详细介绍 MiniGPT-4 的结构和训练方法,是理解 AI 从语言走向感知智能的关键章节。
第8章 大模型智能体
围绕“智能体”概念,讲述其模块化架构(感知、记忆、工具等),并以 LangChain 与 Coze 平台为实践例,说明如何基于 LLM 构建具备规划与行动能力的智能体系统。
第9章 检索增强生成(RAG)
系统介绍 RAG 的整体架构、模块化设计、优化策略与评估方法,适用于提升 LLM 在开放知识任务中的能力。也包括构建与优化 RAG 系统的工程实践。
第10章 效率优化
讨论 LLM 的训练与推理效率,包括模型压缩、低精度训练、稀疏化、知识蒸馏等方法,并以 vLLM 推理框架为实践案例,为部署与落地提供技术方案。
第11章 模型评估
构建了评估 LLM 的系统框架,涵盖知识能力、伦理安全与垂直领域,结合具体评估指标和数据集,为模型开发与应用提供反馈机制与质量保障。
第12章 应用开发
介绍 LLM 在多个场景的应用(如聊天、代码、搜索、教育等),并包含实际开发案例与本地部署实践(如 llama.cpp、Ollama),为开发者提供从原理到落地的全链路指南。
总结:
这本书构建了一个由理论基础 → 数据处理 → 模型训练 → 微调与强化 → 多模态 → 智能体 → 应用开发与部署组成的完整技术闭环,是面向工程实践和科研学习的全景式 LLM 教程。既适合新手入门,也适合有经验的开发者系统提升。
本书架构
围绕 LLM 理论基础、预训练、指令理解、大模型增强、大模型应用五大部分展开。
这本《大规模语言模型:从理论到实践(第2版)》书已整理并打包好PDF了


![[Java恶补day8] 3. 无重复字符的最长子串](https://i-blog.csdnimg.cn/direct/00dfe46415c648d1b664b2e5cd5c4afc.png)