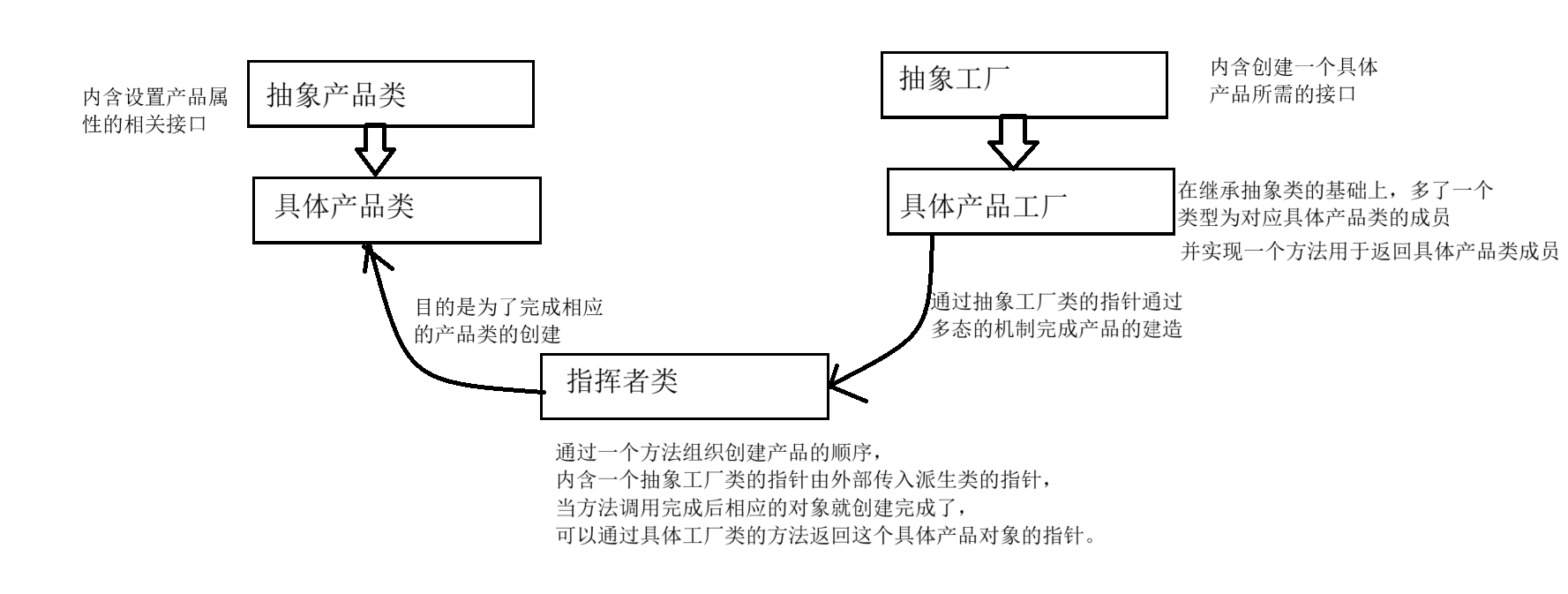
编程中优秀大模型推荐:特点与应用场景深度分析
- 编程中优秀大模型推荐:特点与应用场景深度分析
- GPT系列模型
- 模型概述
- 技术特点
- 编程应用场景
- DeepSeek系列模型
- 模型概述
- 技术特点
- 编程应用场景
- Claude系列模型
- 模型概述
- 技术特点
- 编程应用场景
- Llama系列模型
- 模型概述
- 技术特点
- 编程应用场景
- 文心一言系列
- 模型概述
- 技术特点
- 编程应用场景
- 通义千问系列
- 模型概述
- 技术特点
- 编程应用场景
- 智谱清言/Kimi系列
- 模型概述
- 技术特点
- 编程应用场景
- 总结与推荐
- 各大模型优劣势对比
- 不同编程场景推荐模型
- 推荐组合策略
编程中优秀大模型推荐:特点与应用场景深度分析
在当今快速发展的AI领域,大语言模型(Large Language Models, LLMs)已经成为软件开发和编程中的重要工具。这些模型通过自然语言交互,帮助开发者进行代码生成、调试、文档分析等多种任务。本报告将深入分析当前编程中最优秀的几个大模型,包括它们的技术特点、性能优势以及适用场景,为开发者提供全面的参考。
GPT系列模型
模型概述
OpenAI的GPT系列模型一直是大语言模型领域的标杆。最新版本包括GPT-4o和GPT-4.1等,它们在编程能力方面表现出色。
技术特点
- GPT-4o追求速度与性能的平衡,适合需要流畅用户体验的应用场景
- GPT-4.1最显著的特点是其100万tokens的超长上下文窗口,远超GPT-4.5的12.8万tokens。这不仅是数量上的提升,更带来了质的变化,能够一次性处理约1500页书籍内容
- GPT-4o在语言理解、生成能力和多模态处理方面均有显著提升,响应速度更快
- 图像生成能力强大,支持吉卜力风格等特定艺术风格的图像生成
编程应用场景
- 代码生成与优化:能够根据自然语言描述生成多种编程语言的代码,并进行优化建议
- 代码调试与解释:帮助分析代码错误并提供修复建议
- API设计与文档生成:根据功能需求自动生成API接口和相关文档
- 代码审查:提供代码风格、安全性和效率的自动审查
DeepSeek系列模型
模型概述
DeepSeek是由中国公司开发的大语言模型,在2025年表现出色,已成为全球领先的模型之一。
技术特点
- DeepSeek-R1利用专家混合架构(MoE)和优化算法,与许多美国模型相比,运营成本降低了多达50倍
- DeepSeek V3在逻辑推理能力方面表现最佳,不仅完成了基础推理,还正确推断出复杂问题,展现了更强的逻辑推理能力和问题理解能力
- 成本效率:打破了"堆算力"的传统路径,凭借较少算力资源实现了和全球顶尖AI模型相当的效果
编程应用场景
- 代码生成与优化:擅长多种编程语言的代码生成和性能优化
- 数据分析与算法设计:能够根据需求设计高效的算法
- 系统架构设计:提供软件系统架构建议和设计文档
- 技术学习与培训:通过交互式方式教授编程和技术知识
Claude系列模型
模型概述
Claude是美国公司Anthropic开发的系列模型,最新版本包括Claude Opus 4和Claude Sonnet 4。
技术特点
- 混合推理:扩展思考模式带来深度推理能力,同时保留即时响应的灵活性
- 编程能力:Claude Opus 4成为世界最强编程模型,能够持续工作数小时完成复杂任务
- 深度推理:通过在推理和工具使用之间建立动态循环,能够更智能地处理问题
- 多模态能力:支持多种功能,包括Projects、联网功能、上传文件、数据分析、AI画图、上传图片自动识别等
编程应用场景
- 长时间编码任务:能够持续工作数小时完成复杂编程任务
- 代码分析与重构:分析现有代码并提供重构建议
- 项目规划与管理:协助制定软件开发项目计划
- 技术文档编写:根据代码生成高质量的技术文档
Llama系列模型
模型概述
Llama系列是Meta开发的开源大模型,最新版本包括Llama 4 Scout、Maverick和Behemoth。
技术特点
- 多模态能力:作为原生多模态模型,Llama 4采用了早期融合(Early Fusion)技术,可以用海量的无标签文本、图片和视频数据进行训练
- MoE架构:Llama 4系列采用MoE(混合专家)架构,Llama 4 Scout拥有109B模型参数和17B激活参数
- 性能特点:Llama 4 Maverick被认为与DeepSeek-V3同等代码能力但参数减一半
- 社区争议:在发布初期有报道称Meta可能使用了特供版进行性能评测,导致实际性能与宣传有差距
编程应用场景
- 多语言编程支持:支持多种编程语言的代码生成和分析
- 代码注释与文档生成:自动为代码添加注释并生成文档
- 代码审查与质量控制:提供代码质量评估和改进建议
- 开源项目贡献:帮助开发者理解和贡献开源项目
文心一言系列
模型概述
文心一言是百度开发的大语言模型,最新版本包括文心一言4.5 Turbo和文心X1 Turbo。
技术特点
- 多模态能力:实现多模态输入与输出,支持同时处理上百个多种格式文件
- 文档分析能力:支持一键关联百度网盘,在线读取网盘中海量文件资料、书籍报告,提升阅读效率
- 多语言能力:具备出色的多语言理解和翻译能力,适应多语种工作环境
- 图像理解能力:通过图片检索增强技术的升级,用户可以上传参考图进行绘画,提升生图精准度
编程应用场景
- 代码生成与解释:根据自然语言描述生成代码并提供详细解释
- 技术文档创作:协助撰写技术文档、白皮书等技术材料
- 项目管理:提供项目规划、进度跟踪和报告生成
- 技术学习:通过交互式方式教授编程和技术知识
通义千问系列
模型概述
通义千问是阿里巴巴推出的大语言模型系列,最新版本包括Qwen2.5-Max。
技术特点
- 大规模训练数据:通义千问-Max预训练数据超过20万亿tokens,在多项公开主流模型评测基准上录得高分,位列全球第七名
- 多模态输入:支持文本/图片/视频链接输入,文本输出,32k上下文长度,支持流式输出和联网搜索
- 成本优势:输入价格为0.0024元/千Token,输出价格为0.0096元/千Token,具有成本优势
- 开源模型:阿里云开源通义千问720亿参数模型Qwen-72B和18亿参数模型Qwen-1B
编程应用场景
- 代码生成与优化:根据需求生成多种编程语言的代码并进行优化
- 系统设计与架构:提供软件系统架构建议和设计文档
- 数据分析与处理:协助进行数据分析和数据处理任务
- 技术咨询与支持:提供技术问题解答和解决方案
智谱清言/Kimi系列
模型概述
智谱清言是由清华大学与智谱AI联合研发的对话模型,而Kimi是另一款国产大模型,两者在长文本处理方面有突出表现。
技术特点
- 长文本处理能力:Kimi在超长文本处理方面表现优异,能够处理200万字长文本[116]
- 信息检索与整理:Kimi在信息检索和资料整理方面表现突出
- 多领域知识问答:智谱清言具备多领域知识问答、信息检索、文本生成等主要功能
- 扩展性:智谱清言的扩展性较强,可以定制化开发
编程应用场景
- 长文档分析:处理和分析长篇技术文档和报告
- 代码注释与文档生成:自动为代码添加注释并生成文档
- 技术资料整理:整理和归纳技术资料,提取关键信息
- 学术研究支持:协助进行学术研究和论文撰写
总结与推荐
各大模型优劣势对比
| 模型 | 优势 | 劣势 |
|---|---|---|
| GPT系列 | 强大的多模态能力,特别是图像生成;长上下文窗口支持 | 商业闭源,API调用成本较高 |
| DeepSeek系列 | 极高的成本效率,运营成本降低多达50倍;强大的逻辑推理能力 | 国外用户访问可能受限 |
| Claude系列 | 世界最强编程能力,可连续工作数小时完成复杂任务;混合推理能力突出 | 商业闭源,API调用成本较高 |
| Llama系列 | 开源免费,多模态能力突出;参数效率高 | 社区测试显示性能与宣传有差距 |
| 文心一言系列 | 丰富的中文语境理解能力;多模态输入与处理能力 | 商业闭源,API调用成本较高 |
| 通义千问系列 | 成本优势明显,免费额度丰富;多模态输入与处理能力 | 商业闭源,API调用成本较高 |
| 智谱清言/Kimi系列 | 长文本处理能力突出;信息检索与整理能力强 | 技术迭代速度相对较慢 |
不同编程场景推荐模型
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 代码生成与优化 | Claude Opus 4、DeepSeek V3 | 强大的编程能力和代码优化能力 |
| 长文本处理与分析 | Kimi | 超长上下文窗口,适合处理长篇文档和报告 |
| 多模态开发 | Llama 4、GPT-4o | 原生多模态支持,处理文本、图片和视频数据 |
| 成本敏感项目 | Llama 4、通义千问 | 成本效率高,开源或API成本低 |
| 中文语境开发 | 文心一言、通义千问 | 优秀的中文语境理解和处理能力 |
| 长时间运行任务 | Claude Opus 4 | 能够持续工作数小时完成复杂任务 |
| 学术研究 | DeepSeek、智谱清言 | 强大的推理能力和知识检索能力 |
推荐组合策略
对于开发者和团队,我们建议采用以下组合策略:
- 核心开发:使用Claude Opus 4或DeepSeek V3作为主要开发助手,它们在代码生成和优化方面表现出色
- 长文本处理:使用Kimi处理长文档和报告
- 多模态开发:使用Llama 4或GPT-4o处理多模态内容
- 中文项目:使用文心一言或通义千问作为中文语境的主要助手
- 成本控制:对于成本敏感的项目,优先考虑Llama 4或通义千问
通过合理组合这些大模型,开发者可以根据具体项目需求选择最适合的工具,提高开发效率和质量。




![[crxjs]自己创建一个浏览器插件](https://i-blog.csdnimg.cn/direct/fcfef7d78be544228e9a751146990731.png)