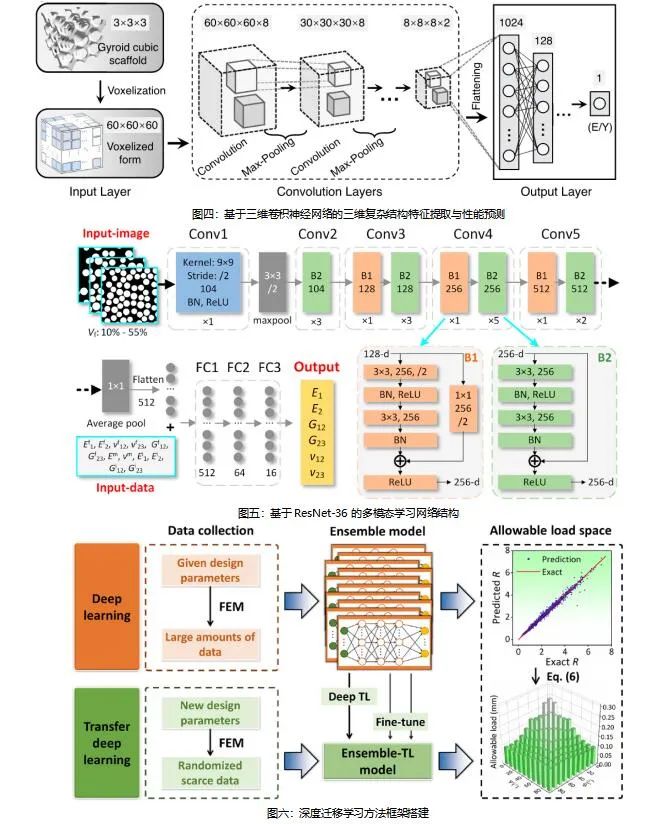
引言
图像分割是计算机视觉领域中的一项基础技术,其目标是将数字图像划分为多个图像子区域(像素的集合),以简化图像表示,便于后续分析和理解。在医学影像、遥感图像分析、自动驾驶、工业检测等众多领域,图像分割都发挥着至关重要的作用。本文将深入探讨几种经典的图像分割算法,包括阈值分割、边缘检测、分水岭算法和K-means聚类分割,并通过Python实现这些算法,对比分析它们的性能和适用场景。
图像分割的理论基础
图像分割的本质是根据图像的某些特征(如颜色、纹理、强度等)将图像划分为不同的区域。理想的分割结果应该使得同一区域内的像素具有相似的特征,而不同区域之间的像素则具有明显的差异。根据实现方式的不同,图像分割算法可以大致分为以下几类:
1. 基于阈值的分割:通过设定一个或多个阈值,将图像像素分为不同类别。
2. 基于边缘的分割:通过检测图像中的边缘(即像素值急剧变化的区域)来确定区域边界。
3. *于区域的分割:如分水岭算法,将图像视为地形图,通过模拟"淹没"过程来划分区域。
4. 基于聚类的分割:如K-means聚类,根据像素特征的相似性将它们分组。
我们选择了一张包含丰富细节和多种纹理的图像作为测试对象,以便全面评估不同分割算法的性能。

阈值分割
阈值分割是最简单也是应用最广泛的图像分割方法之一。其基本原理是选择一个阈值,将图像中的像素分为两类:大于阈值的像素被分为一类(通常设为白色),小于阈值的像素被分为另一类(通常设为黑色)。
阈值分割的实现
def threshold_segmentation(image, threshold=127, max_value=255):
"""
基于阈值的图像分割
"""
# 转为灰度图
if len(image.shape) == 3:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
else:
gray = image
# 应用阈值分割
_, thresh = cv2.threshold(gray, threshold, max_value, cv2.THRESH_BINARY)
return thresh阈值的选择对分割结果有着决定性的影响。为了研究不同阈值对分割效果的影响,我们尝试了多个阈值(50、100、127、150、200),并比较了它们的分割结果。

从上图可以看出,较低的阈值(如50)会导致更多的像素被分类为白色,而较高的阈值(如200)则会导致更多的像素被分类为黑色。阈值的选择应根据具体的应用场景和图像特性来确定。在本例中,阈值127似乎提供了较为平衡的分割结果,既保留了主要结构,又去除了一些细节噪声。
边缘检测分割
边缘检测是另一种常用的图像分割方法,它通过识别图像中像素值急剧变化的区域(即边缘)来划分不同的区域。在本实验中,我们使用了Canny边缘检测算法,这是一种广泛使用的边缘检测方法。
边缘检测的实现
def edge_based_segmentation(image, low_threshold=50, high_threshold=150):
"""
基于边缘检测的图像分割
"""
# 转为灰度图
if len(image.shape) == 3:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
else:
gray = image
# 高斯模糊
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# Canny边缘检测
edges = cv2.Canny(blurred, low_threshold, high_threshold)
return edgesCanny算法有两个重要参数:低阈值和高阈值。它们共同决定了哪些梯度变化会被识别为边缘。我们尝试了四组不同的参数组合:(30, 100)、(50, 150)、(80, 200)和(100, 250),以观察它们对边缘检测结果的影响。

从结果可以看出,较低的阈值组合(如30,100)会检测出更多的边缘,包括一些可能是噪声的细节;而较高的阈值组合(如100,250)则只会检测出图像中最显著的边缘。在实际应用中,需要根据具体需求在边缘检测的敏感度和抗噪声能力之间找到平衡。
分水岭算法
分水岭算法是一种基于区域的分割方法,它将图像视为地形图,像素值表示高度。算法模拟水从低处向高处"淹没"的过程,当来自不同"盆地"的水即将汇合时,就会建立"堤坝",这些"堤坝"就构成了分割的边界。
分水岭算法的实现
def watershed_segmentation(image):
"""
基于分水岭算法的图像分割
"""
# 转为BGR格式(如果是灰度图)
if len(image.shape) == 2:
image = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
# 转为灰度图并进行阈值处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 噪声去除
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 确定背景区域
sure_bg = cv2.dilate(opening, kernel, iterations=3)
# 确定前景区域
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
_, sure_fg = cv2.threshold(dist_transform, 0.7 * dist_transform.max(), 255, 0)
# 找到未知区域
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg, sure_fg)
# 标记
_, markers = cv2.connectedComponents(sure_fg)
markers = markers + 1
markers[unknown == 255] = 0
# 应用分水岭算法
markers = cv2.watershed(image, markers)
# 标记边界
result = image.copy()
result[markers == -1] = [0, 0, 255] # 边界标记为红色
return result分水岭算法的一个显著特点是它能够生成闭合的边界,这在某些应用场景中非常有用。下图展示了分水岭算法的分割结果:

从结果可以看出,分水岭算法能够有效地识别图像中的区域,并用红色线条标记出区域之间的边界。然而,分水岭算法也容易受到噪声的影响,导致过度分割。在实际应用中,通常需要进行预处理(如滤波、形态学操作等)来减轻这种影响。
K-means聚类分割
K-means聚类是一种基于聚类的分割方法,它将图像中的像素按照其特征(如颜色)分为K个类别。算法通过迭代优化,使得同一类别内的像素尽可能相似,而不同类别之间的像素尽可能不同。
K-means聚类的实现
def kmeans_segmentation(image, n_clusters=3):
"""
基于K-means聚类的图像分割
"""
# 将图像转换为二维数组
if len(image.shape) == 3:
pixel_values = image.reshape((-1, 3)).astype(np.float32)
else:
pixel_values = image.reshape((-1, 1)).astype(np.float32)
# 定义停止条件
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 100, 0.2)
# 应用K-means
_, labels, centers = cv2.kmeans(pixel_values, n_clusters, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# 将结果转换回uint8
centers = np.uint8(centers)
segmented_data = centers[labels.flatten()]
# 重塑为原始图像维度
segmented_image = segmented_data.reshape(image.shape)
return segmented_imageK-means聚类的一个关键参数是聚类的数量K。为了研究不同K值对分割结果的影响,我们尝试了多个K值(2、3、5、7、10),并比较了它们的分割效果。

从结果可以看出,随着K值的增加,分割的细节也越来越丰富。当K=2时,图像只被分为两个主要区域;而当K=10时,图像中的许多细节都被分割出来。在实际应用中,需要根据具体需求选择合适的K值,以在分割细节和计算复杂度之间取得平衡。
不同分割方法的比较
为了全面评估不同分割方法的性能,我们选择了每种方法的最佳参数设置,并将它们的分割结果进行了对比。

从上图可以看出,不同的分割方法各有优缺点:
1.阈值分割:实现简单,计算效率高,但只能基于像素强度进行二分类,难以处理复杂的图像。
2. 边缘检测:能够有效地识别图像中的边缘,但可能产生不闭合的边界,需要后续处理。
3. 分水岭算法:能够生成闭合的边界,适合分割相互接触的物体,但容易受噪声影响,导致过度分割。
4. K-means聚类:能够基于颜色特征进行多类别分割,效果较为自然,但计算复杂度较高,且结果受初始聚类中心的影响。
结论与展望
本文详细介绍了四种经典的图像分割算法,并通过Python实现和实验比较了它们的性能。实验结果表明,不同的分割方法适用于不同的场景,没有一种方法能够在所有情况下都表现最佳。在实际应用中,应根据具体需求选择合适的分割方法,或者将多种方法结合使用,以获得更好的分割效果。
未来的研究方向可能包括:
1. 探索更先进的图像分割算法,如基于深度学习的方法(如U-Net、Mask R-CNN等)。
2. 研究如何自适应地选择分割参数,以适应不同的图像特性。
3. 开发混合分割方法,结合多种算法的优点,以提高分割的准确性和鲁棒性。
4. 将图像分割技术应用于更广泛的领域,如医学影像分析、遥感图像处理、自动驾驶等。
参考文献
1. Gonzalez, R. C., & Woods, R. E. (2018). Digital Image Processing (4th ed.). Pearson.
2. Szeliski, R. (2010). Computer Vision: Algorithms and Applications. Springer.
3. Shapiro, L. G., & Stockman, G. C. (2001). Computer Vision. Prentice Hall.
4. OpenCV Documentation. https://docs.opencv.org/
5. Beucher, S., & Meyer, F. (1993). The morphological approach to segmentation: the watershed transformation. Mathematical morphology in image processing, 34, 433-481.
6. MacQueen, J. (1967). Some methods for classification and analysis of multivariate observations. Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, 1(14), 281-297.









![BUUCTF [ZJCTF 2019]EasyHeap](https://i-blog.csdnimg.cn/img_convert/add4ad74a78508bb834bb00b5c929764.png)