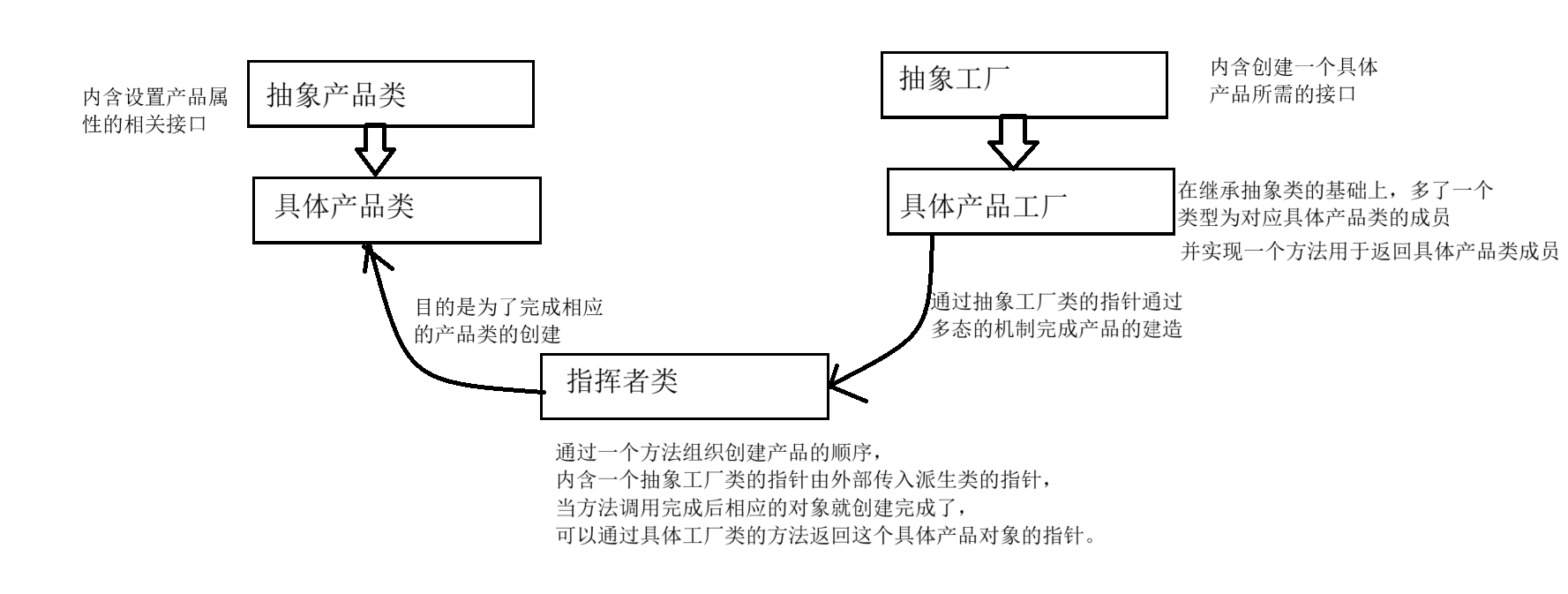
本文介绍一篇Radar 3D目标检测模型:RadarDistill。雷达数据固有的噪声和稀疏性给3D目标检测带来了巨大挑战。在本文中,作者提出了一种新的知识蒸馏(KD)方法RadarDistill,它可以通过利用激光雷达数据来提高雷达数据的表征。RadarDistill利用三个关键组件将激光雷达特征的特征转移到雷达特征中: 模态对齐(CMA)、基于激活的特征蒸馏(AFD)和基于Proposal的特征蒸馏(PFD)。
- CMA通过多层膨胀操作增强了雷达特征的密度,有效地解决了从激光雷达到雷达的知识迁移效率不足的挑战。
- AFD 旨在将知识从 LiDAR 特征的重要区域迁移,特别是那些激活强度超过预定阈值的区域。
- PFD引导雷达网络在Proposal中模拟LiDAR网络特征,以准确地检测结果,同时调节误检测的Proposal的特征。
在nuScenes数据集上进行的实验表明,RadarDistill在纯雷达目标检测任务中达到了最先进的性能(SOTA),mAP为20.5%,NDS为43.7%。此外,RadarDistill还提高了相机-雷达融合模型的性能。
项目地址:https://github.com/geonhobang/RadarDistill
文章目录
- Introduction && Related Work
- Method
- Preliminary
- Cross-Modality Alignment
- Activation-based Feature Distillation
- Proposal-based Feature Distillation
- Experiments
Introduction && Related Work
本文引言和相关工作这里就简单介绍下(本文的写作可以学习下)。本文目标时利用深度神经网络提高雷达的三维目标检测的性能。考虑到雷达测量的稀疏和噪声性质,雷达的有限性能主要是由于寻找有效表示的挑战。受LiDAR 点云的深度模型的显著成功的启发,我们的目标是迁移从基于 LiDAR 的模型中提取的知识以增强基于雷达的模型。
最近,知识蒸馏 (KD) 技术在将知识从一种传感器模态转移到另一种传感器模态方面取得了成功,从而优化目标模型的表示质量。基于所使用的学生模型的模态,跨模态知识蒸馏可以大致分为两种方法。当使用相机作为学生模型时,深度和形状信息都从教师模型转移到学生模型。BEVDistill将 LiDAR 和相机特征转换为 BEV 形式,从而能够将空间知识从 LiDAR 特征转移到相机特征。DistillBEV利用LiDAR或LiDAR-camera融合模型的预测结果来区分前景和背景,引导学生模型聚焦于重要区域的KD。S2M2-SSD根据学生模型的预测确定关键区域,并传输从关键区域的LiDAR-camera融合模型获得的信息。除了这些方法之外,UniDistill采用了一个通用的跨模态框架,可以实现不同模态之间的知识转移。该框架适用于不同的模态配对,包括相机到激光雷达、激光雷达到相机、(相机+激光雷达)到相机。
在本文中,我们提出了一种新的KD框架RadarDistill,该框架旨在增强雷达数据的表示。我们的研究表明,通过使用雷达编码网络作为学生网络和LiDAR编码网络作为教师网络,我们的KD框架有效地产生了类似于从LiDAR数据的密集和语义丰富的特征的特征,以更好地检测目标。
本文主要贡献有:
- 我们的研究是第一个证明在训练过程中使用 LiDAR 数据可以显着提高雷达目标检测的工作。我们在图1中的定性结果强调了通过 RadarDistill 获得的雷达特征成功地模仿了 LiDAR 的特征,从而提高了目标检测。
- 我们的研究结果表明,CMA 是 RadarDistill 中的一个关键模块。在缺少CMA的情况下,我们观察到性能提升显着下降。根据我们的消融研究,CMA在解决雷达和LiDAR点云密度不同造成的低效知识转移方面起着关键作用。
- 我们提出了两种新的 KD 方法 AFD 和 PFD。这些方法弥合了雷达和激光雷达特征之间的差异,分别在在两个独立的特征层面工作,并专门为每个级别设计了KD损失。
- RadarDistill 在 nuScenes 基准测试中的 radar-only 目标检测器类别中实现了最先进的性能。它还为 camera-radar 融合场景实现了显著的性能提升。

Method
Preliminary

本文使用PillarNet作为激光雷达检测器和雷达检测器的baseline。激光雷达和雷达的稀疏2D pillar特征分别为
F
l
d
r
2
D
F^{2D}_{ldr}
Fldr2D、
F
r
d
r
2
D
F^{2D}_{rdr}
Frdr2D,通过2D稀疏卷积编码器得到低级BEV特征为
F
r
d
r
l
F^{l}_{rdr}
Frdrl、
F
r
d
r
l
F^{l}_{rdr}
Frdrl为,然后使用2D密集卷积编码器得到高级BEV特征
F
r
d
r
h
F^{h}_{rdr}
Frdrh、
F
r
d
r
h
F^{h}_{rdr}
Frdrh。最后高级BEV特征使用CenterHead进行处理,得到分类热力图,回归热力图,IoU热力图:
H mod cls , H mod reg , H mod IoU = CenterHead ( F mod h ) H_{\text{mod}}^{\text{cls}}, H_{\text{mod}}^{\text{reg}}, H_{\text{mod}}^{\text{IoU}} = \text{CenterHead}(F_{\text{mod}}^h) Hmodcls,Hmodreg,HmodIoU=CenterHead(Fmodh)
Cross-Modality Alignment
我们的目标是通过CMA减少雷达和激光雷达之间的差异。PillarNet使用SPConv仅从非空pillar生成低级特征。在比较非空pillar的数量时,雷达的非空pillar仅占激光雷达非空pillar总数的11%。非空pillar数量的显著差异需要两种模式进行对齐,特别是由于激光雷达非空pillar的信息不能直接转移到雷达数据中的相应空pillar中。CMA模块如下图所示,下采样模块应用可变形卷积在下采样过程中提取必要特征,然后使用ConvNeXt V2块聚合这些特征。在上采样模块中,使用2D转置卷积应用膨胀以致密周围区域的特征。包含连接和1×1卷积层的聚合模块结合了不同的特征,操作类似于跳跃连接。

具体代码如下:
def forward(self, data_dict):
"""
Args:
data_dict:
spatial_features
Returns:
"""
spatial_features = data_dict['radar_multi_scale_2d_features']['x_conv4']
ups = []
ret_dict = {}
en_16x = self.encoder_1(spatial_features) #(B, 256, 90, 90)
de_8x = torch.cat((self.decoder_1(en_16x), spatial_features), dim=1)#(B,512,180,180)
de_8x = self.agg_1(de_8x)#(B,256,180,180)
en_32x = self.encoder_2(en_16x)#(B,256,45,45)
de_16x = torch.cat((self.decoder_2(en_32x), self.encoder_3(de_8x)), dim=1)#(B,512,90,90)
de_16x = self.agg_2(de_16x)#(B,256,90,90)
x = torch.cat((self.decoder_3(de_16x), de_8x), dim=1)#(B, 512, 180, 180)
x_conv4 = self.agg_3(x)
data_dict['radar_multi_scale_2d_features']['radar_spatial_features_8x_2'] = x_conv4
data_dict['radar_multi_scale_2d_features']['radar_spatial_features_8x_1'] = de_8x
x_conv5 = data_dict['radar_multi_scale_2d_features']['x_conv5']
ups = [x_conv4]
x = self.blocks[1](x_conv5)
ups.append(self.deblocks[0](x))
data_dict['radar_spatial_features_2d_8x'] = ups[-1]
x = torch.cat(ups, dim=1)
x = self.blocks[0](x)
data_dict['radar_spatial_features_2d'] = x
return data_dict
Activation-based Feature Distillation
AFD 通过激活感知特征匹配策略对齐雷达和 LiDAR 的低级特征。这个过程将雷达特征的激活模式与激光雷达的激活模式相匹配,从而弥合了它们在活动特征分布上的差距。蒸馏区域被自适应地划分为两类:一类是雷达和激光雷达(LiDAR)都处于活跃状态的活跃区域(AR),另一类是雷达处于活跃状态而激光雷达处于非活跃状态的非活跃区域(IR)。 由于雷达数据的稀疏性和噪声特性,AR和IR之间存在不平衡。这种不平衡可能会通过专注于模仿占主导地位的IR来干扰训练。因此,我们根据每个区域的像素数量应用相对自适应权重。具体代买如下:
def low_loss(self, lidar_bev, radar_bev):
B, _, H, W = radar_bev.shape
lidar_mask = (lidar_bev.sum(1).unsqueeze(1) > 0).float()
radar_mask = (radar_bev.sum(1).unsqueeze(1))
activate_map = (radar_mask > 0).float() + lidar_mask * 0.5
mask_radar_lidar = torch.zeros_like(activate_map, dtype=torch.float)
mask_radar_de_lidar = torch.zeros_like(activate_map, dtype=torch.float)
mask_radar_lidar[activate_map==1.5] = 1
mask_radar_de_lidar[activate_map==1.0] = 1
mask_radar_de_lidar *= (mask_radar_lidar.sum() / mask_radar_de_lidar.sum())
loss_radar_lidar = F.mse_loss(radar_bev, lidar_bev, reduction='none')
loss_radar_lidar = torch.sum(loss_radar_lidar * mask_radar_lidar) / B
loss_radar_de_lidar = F.mse_loss(radar_bev, lidar_bev, reduction='none')
loss_radar_de_lidar = torch.sum(loss_radar_de_lidar * mask_radar_de_lidar) / B
# breakpoint()
feature_loss = 3e-4 * loss_radar_lidar + 5e-5 * loss_radar_de_lidar
loss = nn.L1Loss()
mask_loss = loss(radar_mask.sigmoid(), lidar_mask)
return feature_loss, mask_loss
Proposal-based Feature Distillation
PDF损失函数如下所示。
def high_loss(self, radar_bev,radar_bev2, lidar_bev,lidar_bev2, heatmaps, radar_preds):
thres = 0.1
gt_thres = 0.1
gt_batch_hm = torch.cat(heatmaps, dim=1)
gt_batch_hm_max = torch.max(gt_batch_hm, dim=1, keepdim=True)[0]
#[1, 2, 2, 1, 2, 2]
radar_batch_hm = [(clip_sigmoid(radar_pred_dict['hm'])) for radar_pred_dict in radar_preds]
radar_batch_hm = torch.cat(radar_batch_hm, dim=1)
radar_batch_hm_max = torch.max(radar_batch_hm, dim=1, keepdim=True)[0]
radar_fp_mask = torch.logical_and(gt_batch_hm_max < gt_thres, radar_batch_hm_max > thres)
radar_fn_mask = torch.logical_and(gt_batch_hm_max > gt_thres, radar_batch_hm_max < thres)
radar_tp_mask = torch.logical_and(gt_batch_hm_max > gt_thres, radar_batch_hm_max > thres)
# radar_tn_mask = torch.logical_and(gt_batch_hm_max < gt_thres, radar_batch_hm_max < thres)
wegiht = torch.zeros_like(radar_batch_hm_max)
wegiht[radar_tp_mask + radar_fn_mask] = 5 /(radar_tp_mask + radar_fn_mask).sum()
wegiht[radar_fp_mask] = 1 / (radar_fp_mask).sum()
scaled_radar_bev = radar_bev.softmax(1)
scaled_lidar_bev = lidar_bev.softmax(1)
scaled_radar_bev2 = radar_bev2.softmax(1)
scaled_lidar_bev2 = lidar_bev2.softmax(1)
high_loss = F.l1_loss(scaled_radar_bev, scaled_lidar_bev, reduction='none') * wegiht
high_loss = high_loss.sum()
high_8x_loss = F.l1_loss(scaled_radar_bev2, scaled_lidar_bev2, reduction='none') * wegiht
high_8x_loss = high_8x_loss.sum()
high_loss = 0.5 * (high_loss + high_8x_loss)
return high_loss
Experiments
下面介绍本文实验部分。基线模型使用了PillarNet-18,即采用ResNet18作为骨干网络的PillarNet [23]。我们使用了Adam优化器,学习率设置为0.001,并采用单周期学习率策略。我们将权重衰减设置为0.01,并将动量在0.85和0.95之间进行调整。我们在4块NVIDIA RTX 3090 GPU上训练了基线模型,共训练了20个epoch,采用总批量大小为16的类别平衡分组与采样(Class-Balanced Grouping and Sampling,简称CBGS)策略。
本文提出的模型训练了40个epochs,其他所有训练过程都与基线模型完全相同。我们采用教师模型的权重来初始化学生模型。
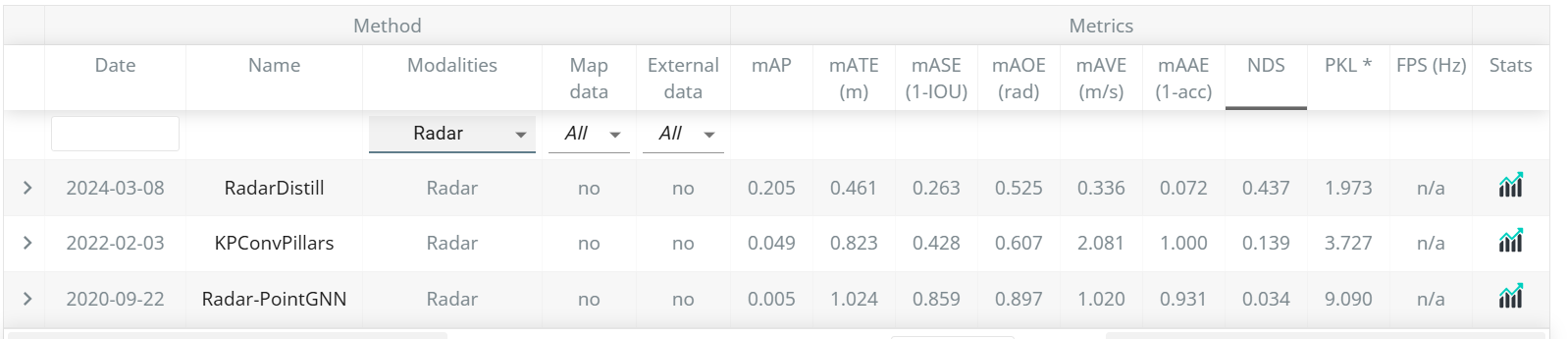
在NuScenes测试集上可以看到,在Radar-only模型中,我们的方法排到了第一名,并且比第二名KPConvPillars在mAP上提高了15.6个点,在NDS提高了29.8个点。
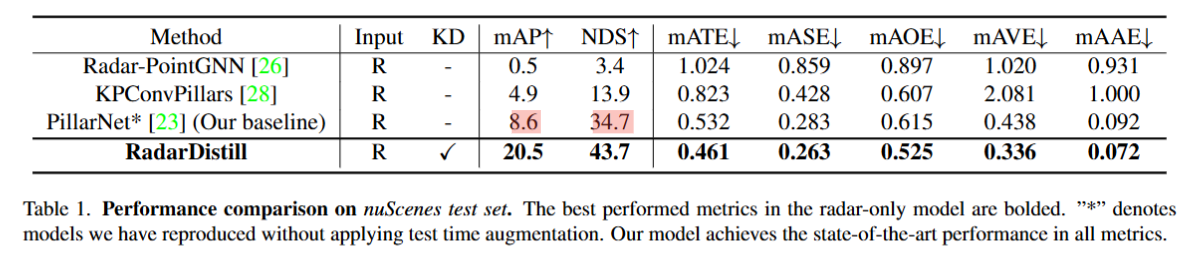
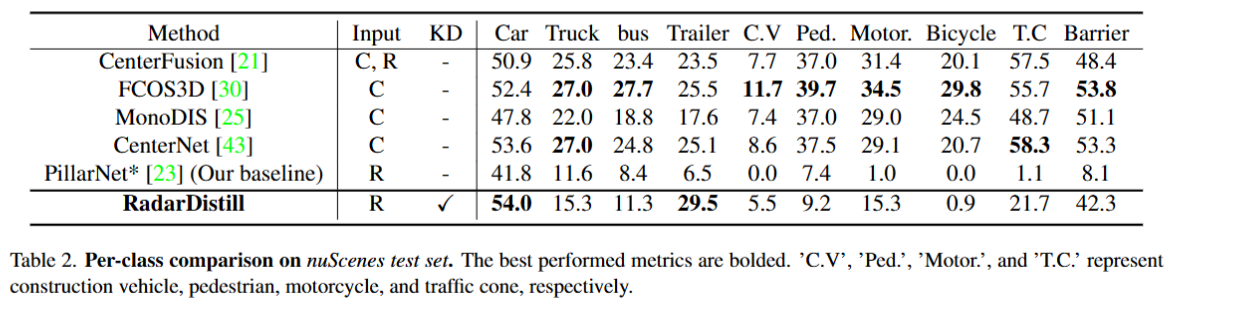
下面是具体每一类的目标AP对比,本文提出的方法比基线模型在所有类别上都有提高,特别是在Trailer、T.C和Barrier上都提高了20个点以上。在Car和Trailer类别上比纯视觉模型和融合模型还要高。但是在Ped和Bicycle等小目标上没有很大提高,因为它们的真值中有很少的雷达点。
下面是消融实验,作者做消融实验的时候使用了1/7的训练集进行训练,缩短开发时间。表3可以看到本文提出的三个模块对模型性能的影响。当CMA和AFD或PFD一起使用的话,比baseline模型都提高了不少。而AFD和PFD一起使用的话,性能提升则十分有限。这表明CMA模块扮演了十分重要的角色。

表4分析了AFD中选择不同特征区域的影响。
(1)在整个区域上进行蒸馏时,汽车平均精度(Car AP)提高了4.2%,平均精度(mAP)提高了2.2%,以及NDS提高了2.9%。
(2)将蒸馏应用于真值框(GT boxes)为中心的高斯热力图区域,与在整个区域上进行蒸馏相比,汽车平均精度和平均精度均有所提高,但NDS有所下降。
(3)将蒸馏分为前景区域和背景区域进行,与在整个区域上进行蒸馏相比,汽车平均精度和平均精度均有所提高,但NDS略有下降(31.7vs32.2)。
(4)相反,按照我们提出的激活区域划分特征蒸馏,与在整个区域上进行蒸馏相比,在所有指标上均取得了最佳性能,Car-AP提高了6.8%,mAP提高了2.3%,NDS提高了1.5%。

表5分析了PFD中选择不同特征区域的影响。可以看到无论是整个区域,还是真值中心热力图、或是LiDAR预测都没有太大的提升,而使用本文提出的Radar预测区域,相比baseline在NDS上提高了1个点。

最后作者在RC融合模型上验证本文提出的知识蒸馏方法的效果,使用的baseline是MIT版本的BEVFusion代码库,可以看到使用本文提出的方法后,mAP和NDS均有提升。




![[crxjs]自己创建一个浏览器插件](https://i-blog.csdnimg.cn/direct/fcfef7d78be544228e9a751146990731.png)