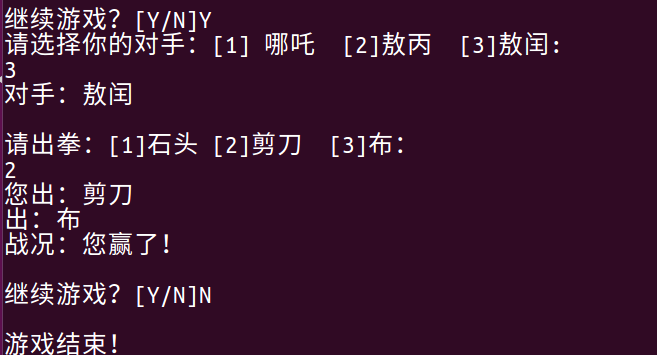
官方教程
官方案例
在上面的链接注册后,请确保设置您的环境变量以开始记录追踪
export LANGSMITH_TRACING="true"
export LANGSMITH_API_KEY="..."
或者,如果在笔记本中,您可以使用以下命令设置它们
import getpass
import os
os.environ["LANGSMITH_TRACING"] = "true"
os.environ["LANGSMITH_API_KEY"] = getpass.getpass()
使用语言模型
pip install -qU "langchain[openai]"
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain.chat_models import init_chat_model
model = init_chat_model("gpt-4o-mini", model_provider="openai")
让我们首先直接使用模型。ChatModels 是 LangChain Runnables 的实例,这意味着它们公开了一个用于与它们交互的标准接口。要简单地调用模型,我们可以将 消息 列表传递给 .invoke 方法。
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage("Translate the following from English into Italian"),
HumanMessage("hi!"),
]
model.invoke(messages)
AIMessage(content='Ciao!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 3, 'prompt_tokens': 20, 'total_tokens': 23, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_0705bf87c0', 'finish_reason': 'stop', 'logprobs': None}, id='run-32654a56-627c-40e1-a141-ad9350bbfd3e-0', usage_metadata={'input_tokens': 20, 'output_tokens': 3, 'total_tokens': 23, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})
huggingface 模型
因为gpt要花钱,所以换了一个模型
记得获取token
!pip install langchain
!pip install -U langchain-openai
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "hf_rxxxxxxxxxxxxxx"
import os
from langchain_huggingface import HuggingFaceEndpoint
# from langchain_community.chat_models import ChatHuggingFace
from langchain_core.messages import HumanMessage, SystemMessage
# 设置 Token
os.environ["HF_TOKEN"] = "hf_Xxxxxxxxxxxx"
# 模型 ID(使用 HuggingFace 上公开的模型)
repo_id = "HuggingFaceH4/zephyr-7b-beta"
# 初始化 LLM
llm = HuggingFaceEndpoint(
repo_id=repo_id,
max_new_tokens=512,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.01,
repetition_penalty=1.03,
huggingfacehub_api_token=os.environ["HF_TOKEN"]
)
# 封装成聊天模型
# chat_model = ChatHuggingFace(llm=llm)
# 构造消息
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="hi!")
]
# 调用模型
response = llm.invoke(messages)
print(response)
选择一个公开可访问的替代模型,例如:
HuggingFaceH4/zephyr-7b-beta ✅ 公开
mistralai/Mistral-7B-v0.1 ❌ 受限
tiiuae/falcon-7b ✅ 公开
google/gemma-7b ✅ 公开

# 1. 导入必要的模块
from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint
# HuggingFaceEndpoint是一个 LangChain 封装的类,用于连接 Hugging Face 的推理 API(也就是调用远程模型)。
# ChatHuggingFace:将 LLM 包装成“聊天模型”的适配器。它支持像 messages = [SystemMessage(), HumanMessage()] 这样的对话格式。
from langchain_core.messages import HumanMessage, SystemMessage
# SystemMessage:系统提示词,告诉模型应该做什么(如翻译、写诗等)。
# HumanMessage:用户输入的内容。
# 还有 AIMessage 是模型输出)
# 2. 创建 LLM 实例,创建了一个指向 Hugging Face 模型的客户端对象
llm = HuggingFaceEndpoint(
endpoint_url="https://api-inference.huggingface.co/models/HuggingFaceH4/zephyr-7b-beta", # 要调用的模型地址(即 API 地址)
huggingfacehub_api_token="hf_Xopuxxxxxxxxxxxxxxx", # 替换为你的 token
temperature=0.7, # 控制生成文本的随机性(越高越随机)
max_new_tokens=512, # 最多生成多少个新 token(控制输出长度)
top_k=50,
top_p=0.95,
repetition_penalty=1.03 # 防止重复输出相同内容
)
# 3. 用 ChatHuggingFace 封装成聊天模型
chat_model = ChatHuggingFace(llm=llm) # 这一步把原始的 LLM 封装成一个“聊天模型”,这样就可以使用类似 GPT 的接口(例如传入多个角色消息)。
# 4. 构造对话消息
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!")
]
# 调用模型
response = chat_model.invoke(messages)
print(response.content)

有的时候,import错误、不兼容,也会报错,例如
import os
from langchain_huggingface import HuggingFaceEndpoint
from langchain_community.llms import HuggingFaceEndpoint # 这里重复引用,会引发错误
from langchain_community.chat_models import ChatHuggingFace # 这里新旧版本不兼容
# from langchain_huggingface import ChatHuggingFace, HuggingFaceEndpoint 正确的
from langchain_core.messages import HumanMessage, SystemMessage
# 设置 Token
os.environ["HF_TOKEN"] = "hf_XXXXXXXXXXXXXXXX"
# 使用公开可访问的模型
repo_id = "HuggingFaceH4/zephyr-7b-beta" # 替换为你想用的公开模型
llm = HuggingFaceEndpoint(
repo_id=repo_id,
max_new_tokens=512,
top_k=10,
top_p=0.95,
typical_p=0.95,
temperature=0.01,
repetition_penalty=1.03,
huggingfacehub_api_token=os.environ["HF_TOKEN"]
)
# 封装成聊天模型
chat_model = ChatHuggingFace(llm=llm)
# 构造消息
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!")
]
# 调用模型
response = chat_model.invoke(messages)
print(response.content)
你使用了 langchain_community.chat_models.ChatHuggingFace,但是它只接受 langchain_community.llms 中的 LLM 实例(比如旧的 HuggingFaceEndpoint),而你现在用的是新的 langchain_huggingface 中的 HuggingFaceEndpoint,所以 类型不兼容。
其他token方法:
from huggingface_hub import login
login(token="hf_XXXXXXXXXXXXXXXX") #这里替换为自己的API Token
或者:
!huggingface-cli login
其他参数
- repo_id: 这是模型在 Hugging Face Hub 上的唯一标识符。它通常由用户名(或组织名)和模型名组成,例如 “microsoft/Phi-3-mini-4k-instruct”。这种方式更适合于本地运行或者通过 Hugging Face Inference API 直接访问公开模型。
- task: 指定你想要执行的任务类型,比如 “text-generation”、“translation” 等等。
- endpoint_url: 这是指向 Hugging Face Inference API 的具体URL,用于直接调用远程部署的模型服务。例如 “https://api-inference.huggingface.co/models/HuggingFaceH4/zephyr-7b-beta”。
| 场景 | 是否需要 API Token |
|---|---|
使用 repo_id 加载公开模型 | 不需要 |
使用 repo_id 加载私有或受限模型 | 需要 |
使用 endpoint_url 访问 Hugging Face Inference API | 大多数情况下需要 |
你可以从 Hugging Face 设置页面 获取或生成新的API token。
如何扩展
✅ 1. 换一个模型(只需修改 endpoint_url)
你可以访问 Hugging Face 上任意公开模型页面,复制它的推理地址。
🔁 示例:换成 TinyLlama/TinyLlama-1.1B-Chat-v1.0
这个模型很小,速度快,适合测试。
llm = HuggingFaceEndpoint(
endpoint_url="https://api-inference.huggingface.co/models/TinyLlama/TinyLlama-1.1B-Chat-v1.0",
huggingfacehub_api_token="你的token",
temperature=0.7,
max_new_tokens=512
)
🔁 示例:换成中文模型 Qwen/Qwen2-0.5B-Instruct
如果你想要中文模型:
llm = HuggingFaceEndpoint(
endpoint_url="https://api-inference.huggingface.co/models/Qwen/Qwen2-0.5B-Instruct",
huggingfacehub_api_token="你的token",
temperature=0.7,
max_new_tokens=512
)
⚠️ 注意:有些模型需要申请权限才能使用(会报错
GatedRepoError),请前往对应模型页面点击 “Request Access”。
✅ 2. 改变任务(只需修改 SystemMessage)
比如你想让模型写一首诗:
messages = [
SystemMessage(content="You are a poet. Write a short poem about the moon in Chinese."),
HumanMessage(content="Please write a poem.")
]
或者你想让它做 QA:
messages = [
SystemMessage(content="Answer the question briefly and accurately."),
HumanMessage(content="What is the capital of France?")
]
📌 三、推荐常用公开模型(可直接替换)
| 模型名称 | 描述 | 是否需要申请 |
|---|---|---|
HuggingFaceH4/zephyr-7b-beta | 英文聊天模型 | ❌ 不需要 |
TinyLlama/TinyLlama-1.1B-Chat-v1.0 | 很小的英文聊天模型 | ❌ 不需要 |
Qwen/Qwen2-0.5B-Instruct | 阿里通义千问系列,中文友好 | ❌ 不需要 |
google/gemma-7b-it | Google 推出的指令微调模型 | ❌ 不需要 |
mistralai/Mistral-7B-Instruct-v0.2 | Mistral 系列指令模型 | ✅ 需要申请 |
📝 总结
| 功能 | 修改位置 | 示例 |
|---|---|---|
| 换模型 | 修改 endpoint_url | https://api-inference.huggingface.co/models/用户名/模型名 |
| 控制输出 | 修改参数 | temperature=0.1, max_new_tokens=256 |
| 更换任务 | 修改 SystemMessage 和 HumanMessage 内容 | “你是谁?”、“帮我翻译”、“写一篇作文”等 |
| 使用中文模型 | 选择支持中文的模型 | 如 Qwen2-0.5B-Instruct |