YOLOv1:开启实时目标检测的新篇章
在深度学习目标检测领域,YOLO(You Only Look Once)系列算法无疑占据着重要地位。其中,YOLOv1作为开山之作,以其独特的设计理念和高效的检测速度,为后续的目标检测发展奠定了坚实基础。今天,就让我们深入探索YOLOv1的奥秘。
一、YOLOv1诞生的背景
在YOLOv1出现之前,传统目标检测算法如R-CNN系列,采用多阶段处理方式,先生成候选框,再对候选框进行分类和回归。这种方式虽然在准确率上有一定保障,但检测速度较慢,难以满足实时检测的需求。随着深度学习的快速发展,研究者们开始探索更高效的目标检测方法,YOLOv1应运而生。它由Joseph Redmon等人于2016年提出,创新性地将目标检测问题转化为一个回归问题,通过一个神经网络直接预测目标的类别和位置,极大地提高了检测速度。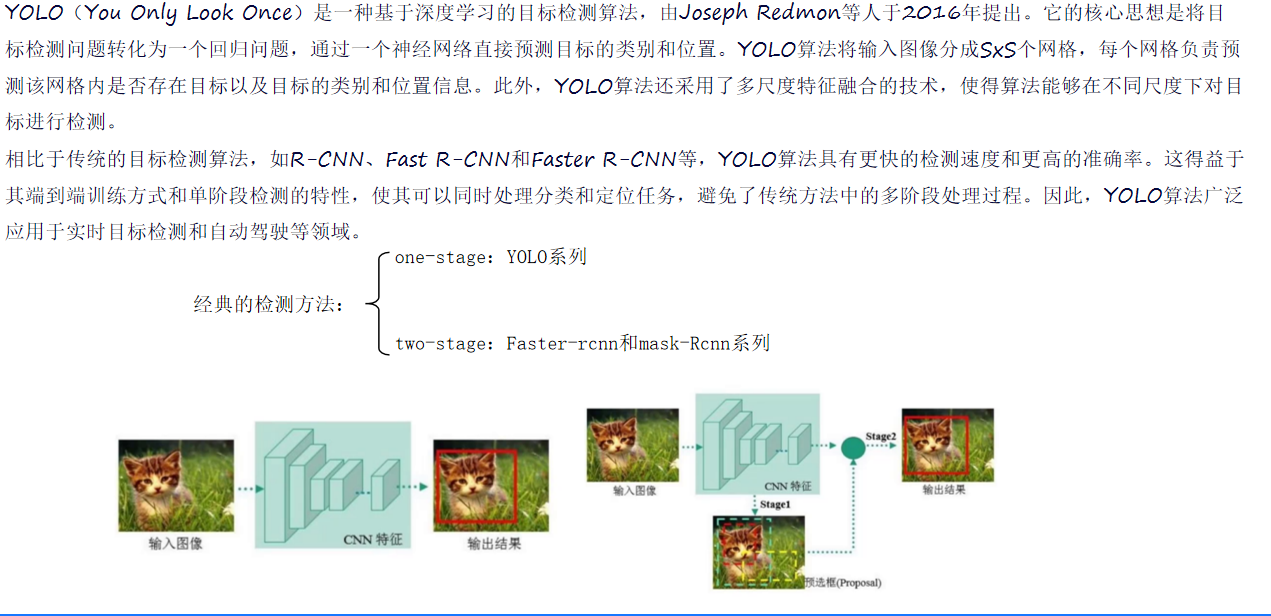

二、YOLOv1的核心原理
(一)将检测问题转化为回归问题
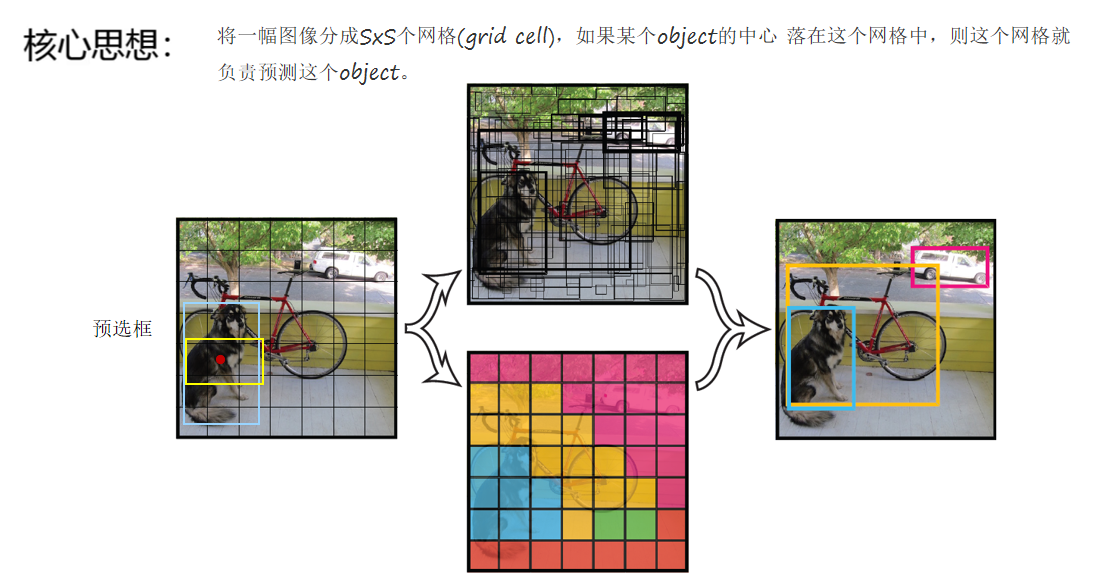
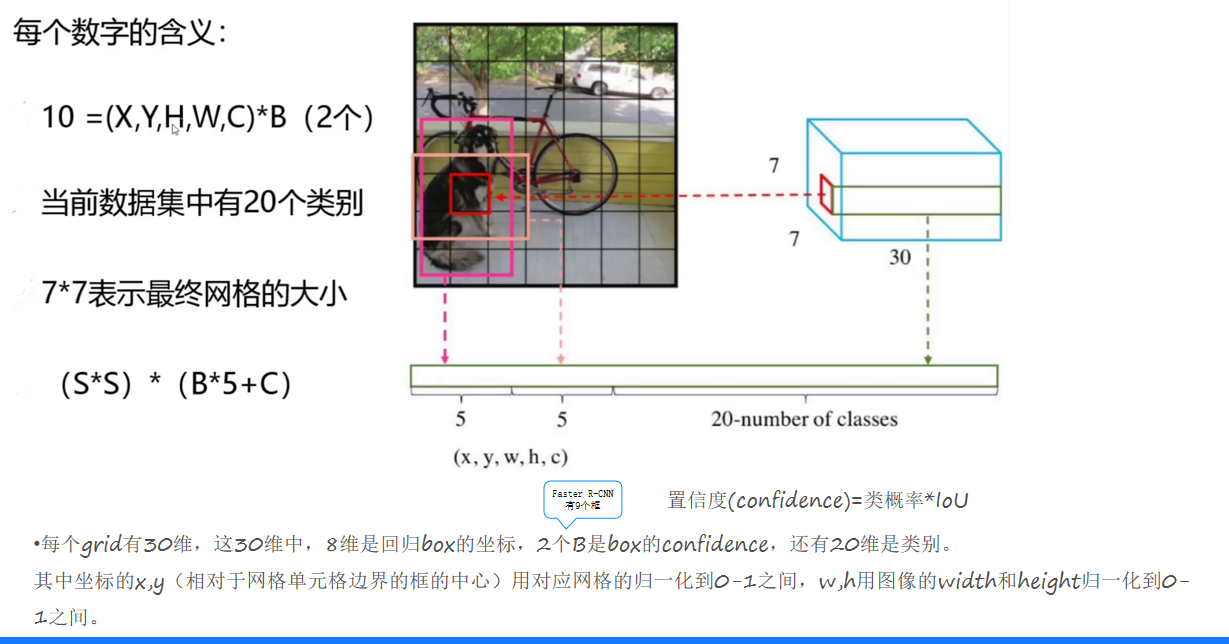
YOLOv1把输入图像分成SxS个网格(grid cell),如果某个物体的中心落在这个网格中,那么这个网格就负责预测这个物体。每个网格会预测B个边界框(bounding box)以及这些边界框中物体的类别概率。最终,网络输出的是SxSx(B*5 + C)的张量,其中B表示每个网格预测的边界框数量,5代表每个边界框包含的信息(中心坐标x、y,宽w,高h以及置信度c),C则是数据集中的类别数。
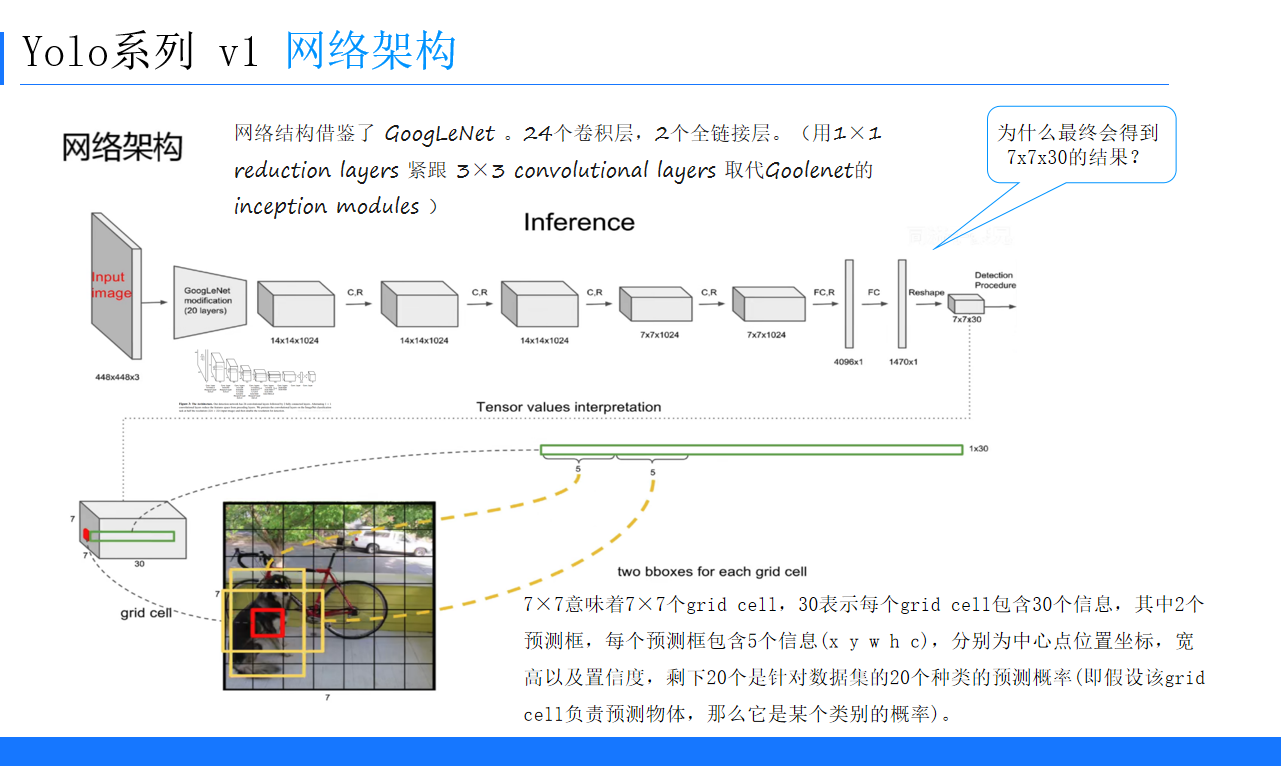
(二)网络架构
YOLOv1的网络结构借鉴了GoogLeNet,包含24个卷积层和2个全连接层。它使用1×1 reduction layers紧跟3×3 convolutional layers取代了GoogLeNet的inception modules。最终输出7x7x30的结果,7x7表示网格数量,30维中包含2个预测框(每个预测框5个信息)以及20个类别概率。
(三)置信度与预测框
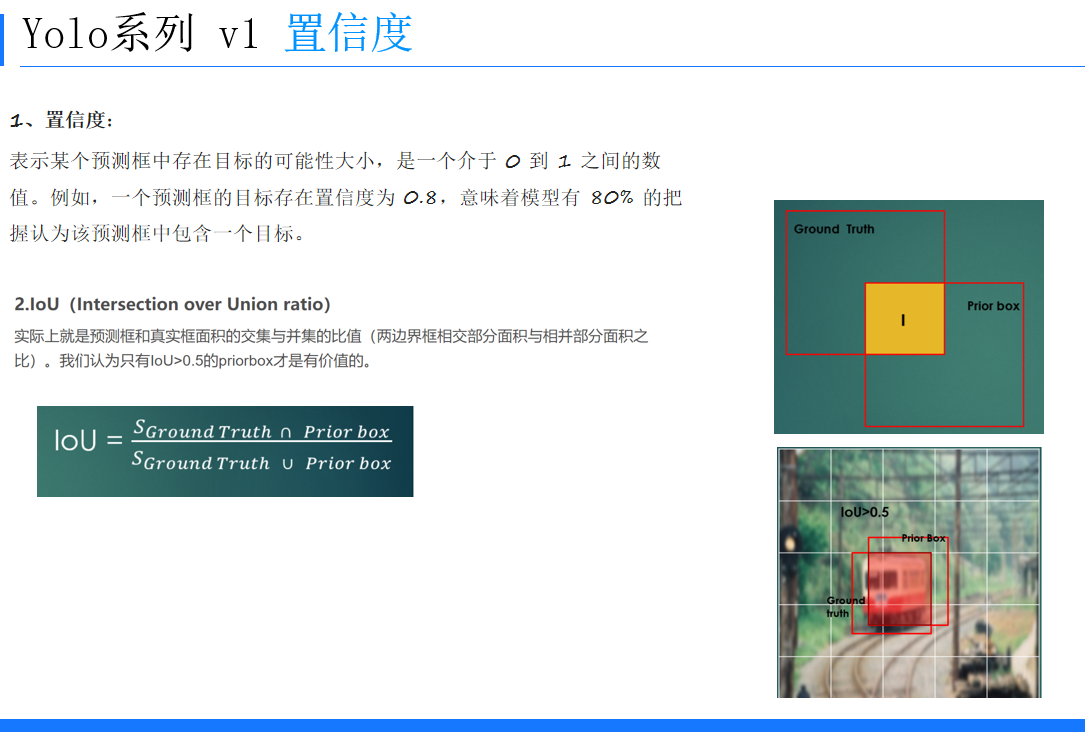
置信度表示某个预测框中存在目标的可能性大小,取值介于0到1之间。预测框的坐标(x, y, w, h)通过相对于网格单元格边界和图像的宽高进行归一化处理,使其在0 - 1之间。例如,坐标x、y是相对于网格单元格边界的框的中心位置,w、h是相对于图像width和height的比例。
(四)损失函数
YOLOv1的损失函数包含三部分:位置误差、confidence误差和分类误差。通过对这三部分误差的加权求和,实现对网络的训练优化,使坐标、置信度和分类三个方面达到平衡。比如,对于负责检测物体的边界框,会计算其中心点定位误差和宽高定位误差,并且在计算宽高定位误差时,开根号操作能让小框对误差更敏感。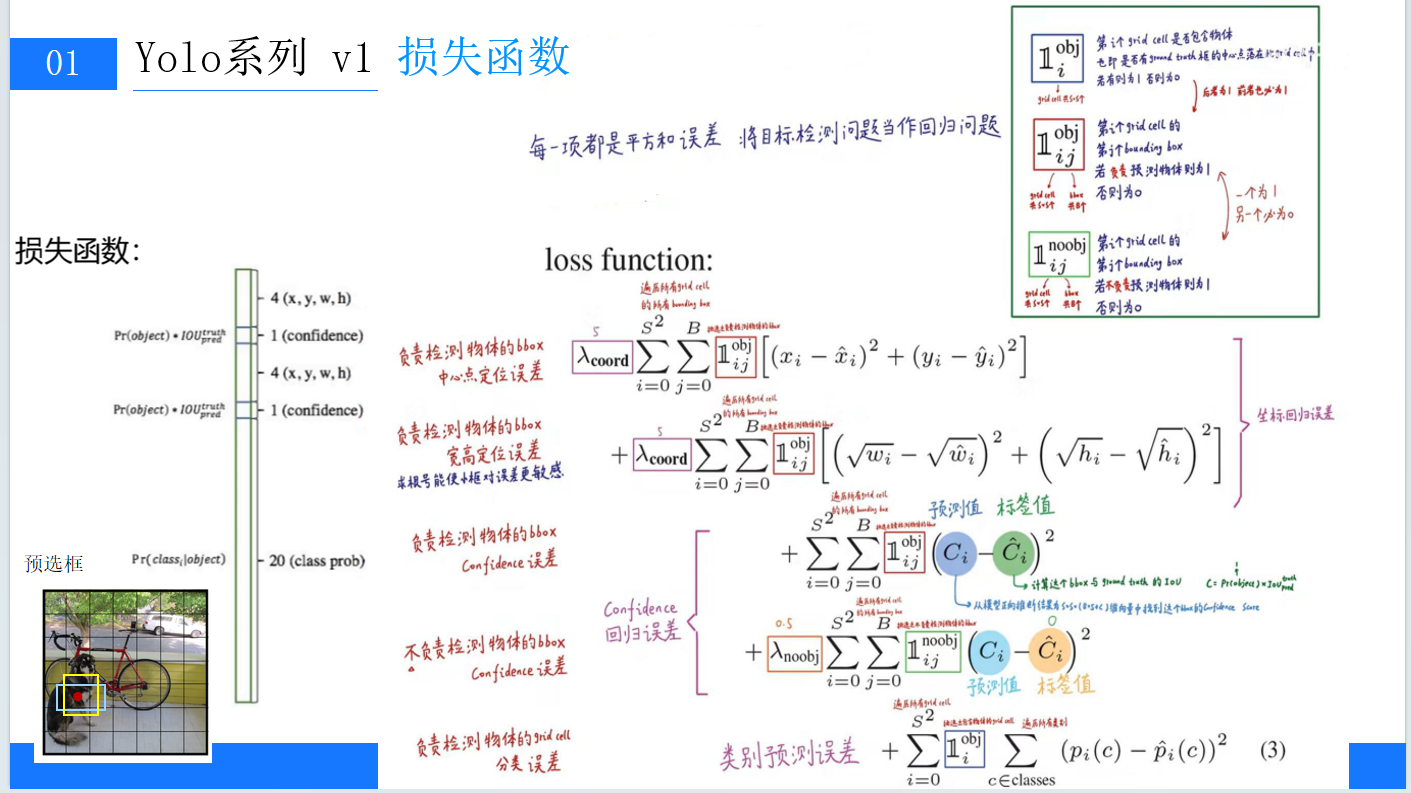
三、YOLOv1的优势与不足
(一)优势
- 检测速度快:将目标检测视为回归问题,避免了传统方法的多阶段处理,实现了端到端的训练和检测,能够对视频进行实时检测,在一些场景下检测速度可达45FPS。
- 简单高效:整体算法结构相对简单,易于理解和实现,为后续目标检测算法的发展提供了新思路。
(二)不足
- 类别预测局限性:每个网格只能预测1个类别,如果多个物体的中心落在同一个网格内且属于不同类别,无法很好地解决重叠物体的检测问题。
- 小物体检测效果不佳:对于小物体,由于其在图像中所占像素较少,YOLOv1的检测效果一般,且其先验框的长宽比可选但单一,不能很好地适应不同形状的小物体。
四、YOLOv1的应用领域
尽管YOLOv1存在一些不足,但凭借其快速的检测速度,在众多领域得到了广泛应用。在智能安防领域,可用于实时监控视频中的目标检测,如识别人员、车辆等;在自动驾驶领域,能够快速检测道路上的行人、车辆、交通标志等,为自动驾驶系统提供重要的决策依据;在工业检测中,也能对生产线上的产品进行实时检测,识别缺陷和异常。YOLOv1作为目标检测领域的经典算法,虽然有其局限性,但它开启了实时目标检测的新时代。它的创新思想和设计理念为后续YOLO系列算法以及其他目标检测算法的发展提供了宝贵经验。随着技术的不断进步,目标检测算法也在持续优化和改进,未来我们有望看到更高效、更精准的检测算法出现。