用于跨场景分类的集成对齐子空间自适应方法
摘要:本文提出了一种用于跨场景分类的集成对齐子空间自适应(EASA)方法,它可以解决同谱异物和异谱同物的问题。该算法将集成学习的思想与域自适应(DA)算法相结合。考虑到原始数据(OD)的样本不均衡问题,通过按照一定规则对原始数据进行多次随机采样得到源数据(SD),并将其作为输入。然后,对源数据和目标数据(TD)进行几何对齐和统计对齐,构建公共子空间,进而对目标数据进行分类。最后,通过对多次分类结果进行计数并保留有效信息,对分类标签进行集成。该技术能够降低生成子空间投影的不确定性和随机性。在两个真实数据集上的实验结果表明,与传统机器学习和域自适应方法相比,该算法在准确率上有显著提升。
关键词:跨场景分类;域自适应(DA);集成学习;高光谱;迁移学习
一、引言
高光谱图像(HSI)的跨场景分类由于其高维数和少样本的问题,一直是一个挑战。当目标域需要实时处理且不能用于重新训练时,有必要仅在源域上训练模型,并直接将模型迁移到目标域。域自适应(DA)是转导迁移学习的一种情况,它可以在特征层面减少光谱偏移,并学习域不变模型,这在跨场景分类中已被证明是成功的。
通常情况下,训练集被假定与测试集具有相同的分布。然而,在实际情况中,测试环境往往差异很大,这可能会导致过拟合。因此,为了解决源数据(SD)和目标数据(TD)之间的不一致性问题,提出了基于域自适应的迁移学习技术。通过该技术,在源域上训练的目标函数被迁移到目标域,以提高预测的准确性。
最近,人们提出了几种方法来提高分类性能。Pan等人提出了一种迁移成分分析(TCA)算法,该算法将两个域的信息映射到一个高维再生核希尔伯特空间中。为了同时利用边际分布和条件分布,联合分布自适应(JDA)算法被提出。如果源数据和目标数据之间的差异很大,很难找到一个能同时实现两个数据投影的空间。投影空间受随机因素影响,如果没有选择合适的基作为空间向量,可能会出现错误分布。因此,Tzeng等人提出了深度域混淆(DDC)算法。在DDC之后,深度自适应网络(DANs)被提出用于进一步探索。DAN增加了一层自适应层和一个域混淆损失函数,使网络能够学习如何进行分类。这种方法减少了源域和目标域之间的分布差异。DAN最突出的方面体现在两个点:多层和多核。对于无监督域自适应中的分类问题,Sun和Yang提出了相关对齐(CORAL)算法,该算法使用线性变换对齐源域和目标域的二阶统计量。为了更好地利用类内特征,Wang等人提出了分层迁移学习(STL)算法。STL使用类内迁移计算每个类的最大平均差异(MMD)距离,以实现更好的变换效果。
在集成学习中,多个分类器结果的适当组合所得到的判断比任何单个分类器的判断都要好。提升算法(Boosting)和自训练聚合算法(Bagging)是主要的集成学习方法。个体学习器之间的差异被认为是分类器组合中非常重要的一个特征。集成学习已成功应用于高光谱图像分类。
当源数据和目标数据差异很大时,很难找到一个包含两个域共享特征的公共子空间。以前大多数基于特征的域自适应方法并没有明确最小化域之间的分布距离。在本文中,采用集成学习来处理源数据的输入并整合每个结果。集成对齐子空间自适应(EASA)方法能够有效地提高识别准确率。在域自适应算法中使用了判别协同对齐(DCA)算法,该算法应用约束来对齐两个子空间,在保持全局几何属性的同时,控制投影数据的几何结构相似性。计算域间MMD和类间MMD,并进行数据重建以保留判别信息。集成学习可以汇集不同维度空间的优势。
本文的主要贡献总结如下:
- 通过集成多个结果,可以解决寻找包含共享特征子空间的困难。
- 针对高光谱多维投影在低纬度产生判别信息损失的现象,利用约束进行全局信息保留。
- 该方法通过对原始数据进行多次随机重复采样,优化高光谱跨场景分类的效果,提高数据利用率。
二、方法论
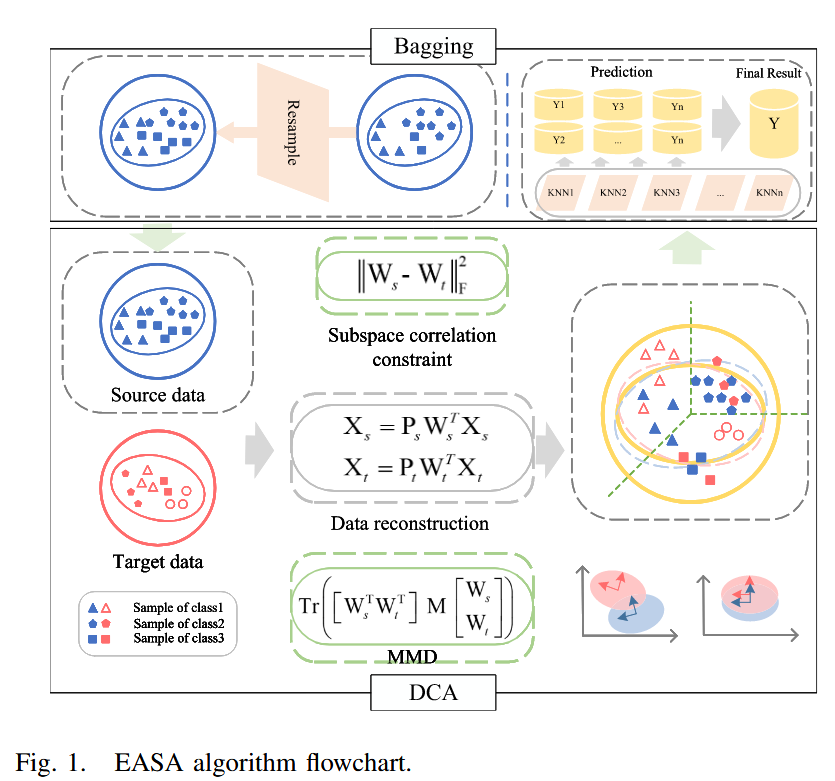
(A)判别协同对齐
DCA算法之前通过以下目标函数进行两个域投影的学习:
[min {W{s}, W_{t}}\left| W_{s}^{T} X_{s}-W_{t}^{T} X_{t}\right| {F}^{2}+\lambda{1}\left| W_{s}-W_{t}\right| {F}^{2}]
其中,(\lambda{1})是控制子空间对齐的正则化参数,(w_{s}) 、(W_{t} \in d ×k)分别是源子空间和目标子空间。k是子空间的维数。(w_{s}) 、(w_{s})可以通过公式(1)进行优化。
为了确保在低维子空间中对齐样本的判别信息不丢失,公式(1)中引入的数据重建公式为:
[\begin{aligned} & min {W{s}, W_{t}, P_{s}, P_{t}}\left| X_{s}-P_{s} W_{s}^{T} X_{s}\right| {F}^{2}+\left| X{t}-P_{t} W_{t}^{T} X_{t}\right| {F}^{2} \ &+\lambda{1}\left| W_{s}-W_{t}\right| {F}^{2} \ & s.t. P{s}^{T} P_{s}=I, P_{t}^{T} P_{t}=I . \end{aligned}]
(P_{s}) 、(P_{t} \in \mathbb{R}^{d ×k})是两个正交重建矩阵。此时,即使源数据和目标数据的光谱偏移很大,也能很好地完成重建。
MMD是迁移学习中应用最广泛的损失函数,尤其是在域自适应中。此外,MMD主要用于衡量两个不同但相关的随机变量分布之间的距离。其基本定义公式为:
[MMD[F, p, q]:=sup {f \in F}\left(E{p}[f(x)]-E_{q}[f(y)]\right)]
其中,f是映射关系,F是映射空间。
在DCA算法中,域间MMD(公式4)和类间MMD(公式5)被用作数据对齐的判别标准:
[M\left(X_{s}, X_{t}\right)=\left| \frac{1}{n_{s}} \sum_{i=1}^{n_{s}} W_{s}^{T} x_{i}-\frac{1}{n_{t}} \sum_{j=1}^{n_{t}} W_{t}^{T} x_{j}\right| {F}^{2}]
[C\left(X{s}, X_{t}\right)=\sum_{l=1}^{c}\left| \frac{1}{n_{s}^{l}} \sum_{i=1}{n_{s}{t}} W_{s}^{T} x_{i}-\frac{1}{n_{t}^{l}} \sum_{j=1}{n_{t}{t}} W_{t}^{T} x_{j}\right| _{F}^{2}]
分布位移优化项可以通过以下公式得到:
[min {W} Tr\left(W^{T} X M X^{T} W\right)]
在这个公式中,w是子空间矩阵,x是数据矩阵。M是一个线性变换。上述公式得出DCA的目标函数,可以表示为:
[\begin{aligned} min {W{s}, W{t}, P_{s}, P_{s}, P_{t}} & \left| X_{s}-P_{s} W_{s}^{T} X_{s}\right| {F}^{2}+\left| X{t}-P_{t} W_{t}^{T} X_{t}\right| {F}^{2} \ & +\lambda{1}\left| W_{s}-W_{t}\right| {F}^{2}+\lambda{2} min {W} Tr\left(W^{T} X M X^{T} W\right) \ s.t. & P{s}^{T} P_{s}=I, P_{t}^{T} P_{t}=I \end{aligned}]
其中,(\lambda_{2})是一个正则化参数,用于调整分布对齐的权重。经过对(w_{s}) 、(w_{s})的几次迭代计算后,使用对齐后的源样本训练KNN分类器,然后对目标数据进行分类。
(B)自训练聚合算法(Bagging)
Bagging算法在多次采样后得到一个包含N个序列的数据集。首先,从样本中随机抽取一个样本放入选取序列中,然后将该样本放回原始数据集,这样该样本在下次采样时仍能被选中。通过这种方式,经过m次随机采样操作后,可以得到一个包含m个样本的采样序列。原始数据集中的一些样本会出现多次,而有些样本则不会出现。
学习集由({(y_{n}, x_{n})})组成,(n = 1,2, …, N) ,其中x是输入,y是标签。使用这个数据集生成一个分类器(\varphi(x, L)),它可以预测y的结果。假设序列({L_{k}})由N个与c分布相同的独立集合组成。与单个集合训练的分类器相比,由这个序列训练的分类器具有更高的准确率。当没有复合数据集只有单个学习集c时,可以通过重复提取样本(\varphi(x, L{(B)}))生成({L{(B)}}) ,并形成一个投票(\varphi_{B}) 。对于类别数量差异较大的样本,Bagging算法表现出色。
(C)集成对齐子空间自适应
本文提出的EASA算法可以应用于样本不均衡的训练数据。数据不均衡会导致分类边界偏向较弱的类别,使样本更容易获得强标签。在数据层面使用重采样方法来平衡标记样本的数量,一种是构建弱类别样本以增加弱类别样本的数量(过采样),另一种是减少强类别样本的数量(欠采样)。在本算法中,选择随机重采样来获取采样后的源数据。
算法1 EASA算法
- 输入:源数据(X_s),目标数据(X_t),源标签(L_s),(\lambda_1),(\lambda_2),k,iter。
- 初始化:矩阵(W_s)、(W_t)赋随机值。
- 计算m的值。
- 当未达到最大迭代次数iter时:
- 为每个类别提取m个数据。
- 用KNN算法初始化(L_t)。
- 当未收敛或未达到最大迭代次数iter时:
- 计算重建矩阵(P_s)、(P_t),更新(W_s)、(W_t)。
- 用KNN算法预测(L_t)。
- 结束内循环。
- 集成每次的预测结果得到(Y)。
- 结束外循环。
- 输出:(Y)。
对原始数据进行多次随机放回采样,使每个类别获得相同数量的m个样本,并确保每次采样过程中获得的样本总数保持不变。每次采样结束时,得到一个用于训练的源数据集。假设学习集(L = {S_{1}, S_{2}, …, S_{n}})包含(II)个类别,(S_{max }) 、(S_{min })分别是数量最多和最少的类别,m的取值为:
[m=min \left(S_{max }, \frac{6}{5} S_{min }\right)]
每个数据集都有一个相应的分类器。整合多个分类器的结果,出现次数最多的数值即为最终答案。算法流程图如图1所示。
每个生成的子空间投影都有一定的随机性,这可能会导致训练生成的分类器存在一定偏差。此外,在降维步骤中可能会丢失少量信息。本文提出的算法可以更好地解决源 - 目标样本不均衡的问题,并且具有更强的鲁棒性。
三、实验结果与讨论
(A)实验数据与评估方法
准备了休斯顿(Houston)和HyRANK数据集进行实验。使用总体准确率(OA)、类别特异性准确率(CA)和Kappa系数来评估每种算法的性能。
- 休斯顿数据集包含2013年和2018年休斯顿地区的高光谱信息。2013年的数据包含144个波段、2.5米分辨率的15种特征类型;2018年的数据包含48个波段、1米分辨率的20种特征类型。在本实验中,选择了7种类型进行分类测试,将2013年的数据作为源数据,2018年的数据作为目标数据。使用的数据数量和类别如表1所示。假彩色图像和真实地图如图2所示。
- HyRANK数据集由Hyperion传感器获取。选择Dioni地区数据作为源数据,Loukia地区数据作为目标数据,选取12个常见类别和176个光谱波段进行测试。使用的数据数量和类别如表2所示。假彩色图像和真实地图如图3所示。
(B)实验参数设置
实验中考虑以下参数:DCA中的正则化参数(\lambda_{1}) 、(\lambda_{2}),子空间的维度k,Bagging中的迭代次数iter,以及每次从样本中采样的数量n。
(\lambda_{1}) 、(\lambda_{2})的取值范围是{ (1 e-4) , (1 e-3) , (1 e-2) 1 (1 e-1) , (1 e-0) , (5 e+0) , (1 e+1) , 1e 2, 5e 2 }。在图4中,休斯顿数据适合(1 e+2)和(1 e-1) ,HyRANK数据适合(1e+2)和(1 e+2) 。
通过多次实验发现,准确率随着iter的增加而提高。考虑到时间成本,将iter设置为200。对原始数据的每个类别进行相同数量的采样可以减少样本不均衡的影响。k适合设置为20。根据随机重采样算法,休斯顿数据集的m值为198,HyRANK数据集的m值为188,对源数据进行均衡化处理。
使用KNN、TCA、CORAL、MEDA和DCA作为对比算法。TCA中的维度参数设置为20,lambda设置为10,gamma设置为0.5,并使用线性核函数。整个过程在MATLAB中实现。
(C)结果展示与分析
表3和表4给出了上述方法在两个目标场景上的类别特异性分类性能,并报告了平均精度和标准差。
EASA使用KNN进行标签初始化和最终预测。与KNN的结果相比,EASA不受源数据样本不均衡问题的影响,对小样本量类别的分类仍然准确。此外,与TCA、CORAL、MEDA等算法相比,EASA减少了由光谱偏移和空间偏移带来的分类错误。
集成学习的原理使EASA不仅在重复实验的结果中表现稳定,而且与DCA算法相比,能够成功识别子空间类别分布边缘的一些点。在两次实验中,DCA都存在无法识别的类别,休斯顿数据集中的第4类,HyRANK数据集中的第2、4和5类都无法识别。由DCA改进而来的EASA仍然存在这个问题。然而,与MEDA相比,EASA能够识别的类别数量有了很大提高。
四、结论
本文针对跨场景情况下的高光谱图像分类问题,提出了EASA方法。首先,对源数据进行重采样,使每种类型的样本数据数量相同,以减少样本不均衡的干扰。使用域自适应算法DCA对源数据和目标数据进行子空间投影,在保留原始信息的同时,对源域和目标域应用重建约束。最后,利用投票分类器的思想,对源数据多次随机采样分类得到的目标数据分类信息进行统计,获取不同投影子空间携带的特征信息。在休斯顿和HyRANK数据集上的测试结果验证了EASA比以往算法表现更优。