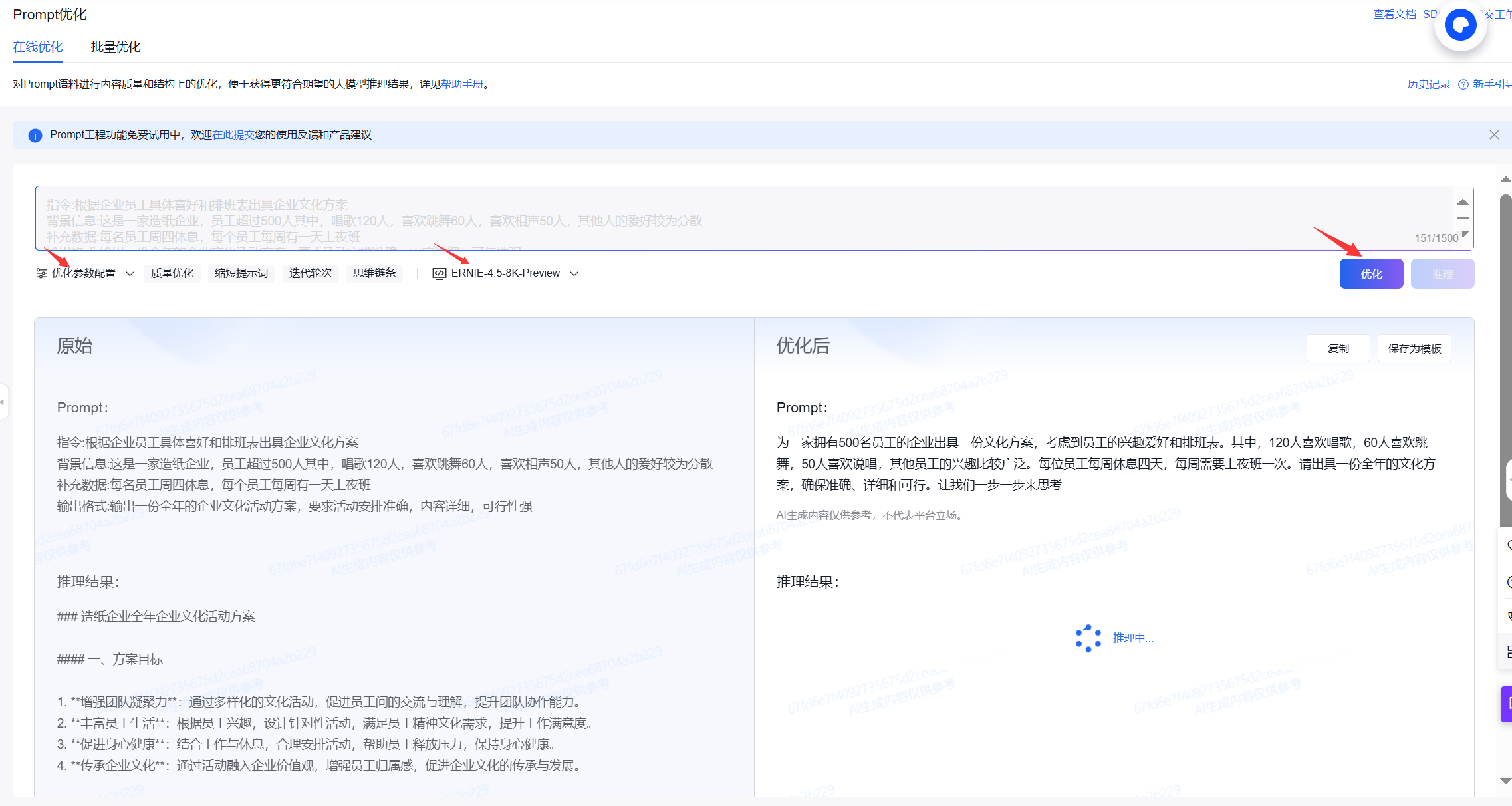
目录
一、前言
二、参数详解
optimizer_trace
optimizer_trace_features
optimizer_trace_max_mem_size
optimizer_trace_limit
optimizer_trace_offset
三、Optimizer Trace
join_preparation
join_optimization
condition_processing
substitute_generated_columns
table_dependencies
ref_optimizer_key_uses
rows_estimation
potential_range_indexes
setup_range_conditions
group_index_range
skip_scan_range
analyzing_range_alternatives
considered_execution_plans
attaching_conditions_to_tables
finalizing_table_conditions
refine_plan
join_execution
附件
一、前言
我们在日常维护数据库的时候,如果遇到慢语句查询的时候,我们一般会怎么做?执行EXPLAIN去查看它的执行计划?
是的。我们经常会这么做,然后看到执行计划展示给我们的一些信息,告诉我们MySQL是如何执行语句的。
但是执行计划往往只给我们带来了最基础的分析信息,比如是否有使用索引,还有一些其他供我们分析的信息,比如使用了临时表、排序等等。我们能从这些信息里面找一些优化点,这样就足够了吗?

看看这张图里的执行计划,我们可以提很多问题:为什么t1表上明明使用了索引在Extra列中还是能看到filesort?如果possible_keys列中有多个索引的话,优化器是基于什么选定使用的索引?这些问题,并不能非常直观地从执行计划中看出来更多的信息,这个时候,我们可以开启OPTIMIZER_TRACE,基于OPTIMIZER_TRACE捕获的信息,去做更细致的追踪分析。一起来看看吧~
二、参数详解

optimizer_trace
- enabled:启用/禁用optimizer_trace功能
- one_line:决定了跟踪信息的存储方式,为on表示使用单行存储,否则以json树的标准展示形式存储
optimizer_trace_features
该变量中存储了跟踪信息中可控的打印项,可以通过调整该变量,控制在INFORMATION_SCHEMA.OPTIMIZER_TRACE表中的trace列需要打印的JSON项和不需要打印的JSON项。默认打开该参数下的所有项。
- greedy_search: 对于有N个表的join操作,可能产生N的阶乘的查询计划路径。如果禁用,则不跟踪贪婪搜索
- range_optimizer: range优化,如果禁用,则不会跟踪范围优化器
- dynamic_range: dynamic range optimizer,如果关闭该选项的话,只有第一次调用JOIN_TAB::SQL_SELECT才被跟踪
- repeated_subselect :子查询,如果关闭的话,只有第一次调用Item_subselect才被跟踪
optimizer_trace_max_mem_size
- optimizer_trace内存的大小,如果跟踪信息超过这个大小,信息将会被截断
optimizer_trace_limit
- optimizer_trace_limit,约束跟踪信息存储的个数
optimizer_trace_offset
- optimizer_trace_offset,约束偏移量
三、Optimizer Trace
在Optimizer Trace的输出中,主要分为三个部分:
- join_preparation SQL的准备阶段
- join_optimization SQL优化阶段
- join_execution SQL执行阶段
join_preparation
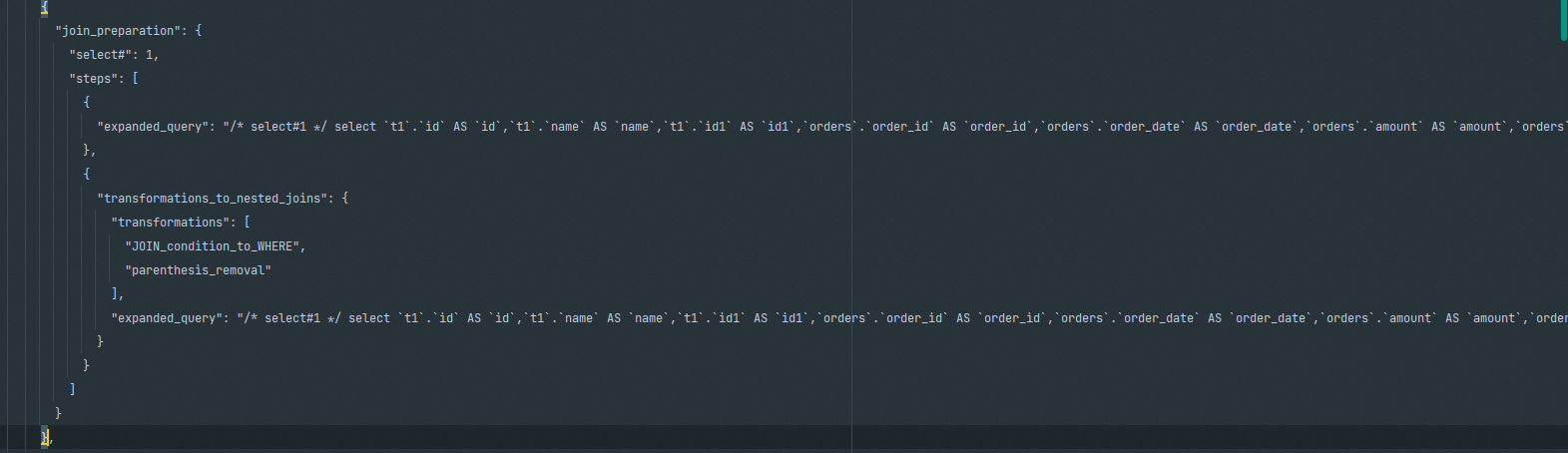
第一部分是完成SQL的准备工作。在这个阶段,SQL语句会被格式化输出,通配符*会被具体字段代替,但不会进行等价改写动作。如上图中传入的SQL语句是”select * from dept”的结果。在完成了语句的补充、格式化后,准备阶段结束并进入下一阶段。
join_optimization
第二部分,是完成SQL语句的逻辑与物理优化的过程,这其中的优化步骤比较多
在展开具体内容之前,先解释下”select #”的问题。在输出中经常会看到有”select#:N”的字样,它表示当前跟踪的结构体是属于第几个SELECT。
如果语句中使用多个SELECT语句拼接(如UNION)或者有嵌套子查询中有SELECT,会产生多个序号。
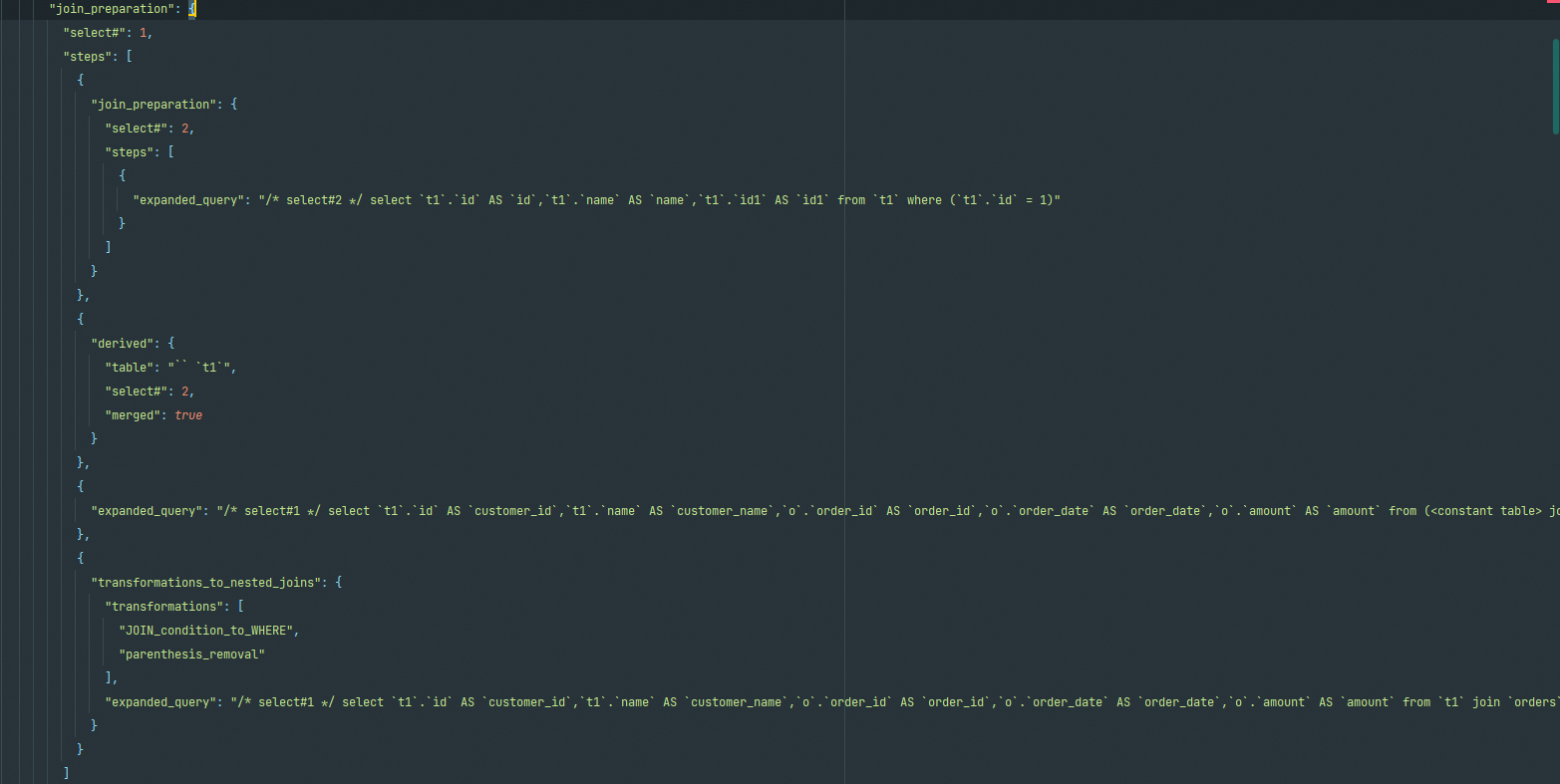
condition_processing
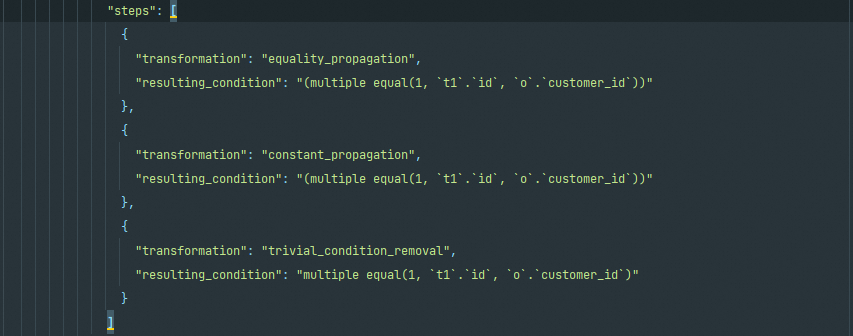
这一部分是完成对条件语句的优化,包括对WHERE子句或HAVING子句的优化。在后面的”condition”部分就标识出是对哪类子句的优化,如下图就是对WHERE子句的优化。

在后面是三个优化过程,每步都写明了转换类型(transformation),明确转换做的事情,以及转换之后的结果语句(resulting_condition)。这三个转换分别是:
- equality_propagation(等值条件句转换)
- constant_propagation(常量条件句转换
- trivial_condition_removal(无效条件移除的转换)
substitute_generated_columns
用于替换虚拟生成列
![]()
table_dependencies
这部分是要找出表之间的相互依赖关系。如查询中存在多个表且之间是有依赖关系,会影响优化行为。这部分信息更多是提示作用,没有实质优化动作。
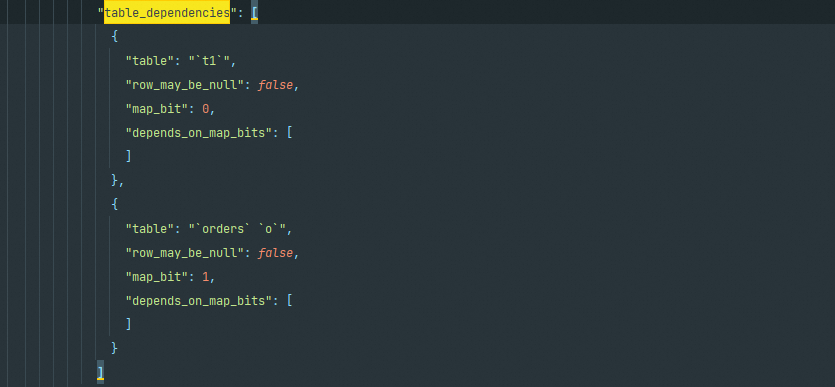
在具体字段含义上:
- table:涉及的表名(如果有别名,也会显示出来)
- row_may_be_null:列是否允许为NULL,这里并不是指表中的列属性是否允许为NULL,而是指JOIN操作之后的列是否为NULL。比如说原始语句中如果使用了LEFT JOIN,那么后一张表的row_may_be_null则会显示为true。
- map_bit:表的映射编号,从0开始递增。
- depends_on_map_bits:依赖的映射表,这里主要是在使用STRAIGHT_JOIN进行强制连接顺序或者是LEFT JOIN/RIGHT JOIN有顺序差别时,会在depends_on_map_bits中列出前置表的map_bit。
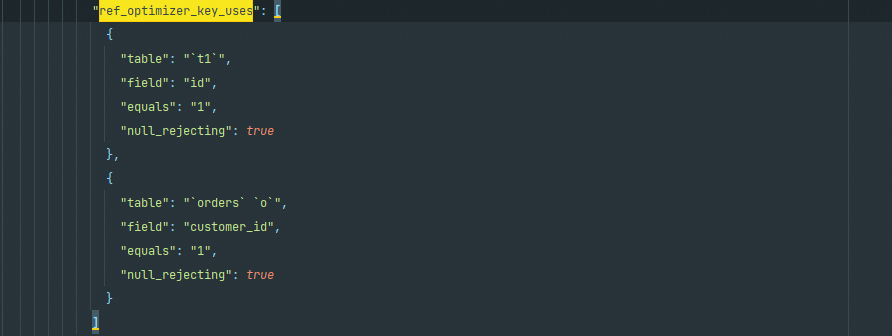
ref_optimizer_key_uses
列出了所有可用的ref类型的索引,在图中显示可过滤的字段
rows_estimation
在这一阶段会评估各种扫描方式的成本,包括全表扫描机索引扫描的代价估算。这一段以表对象作为结构体进行展开

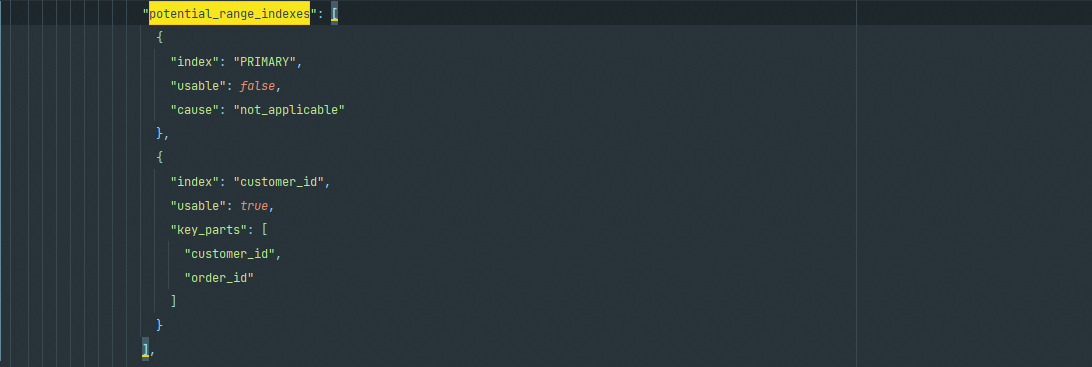
potential_range_indexes
该阶段会列出表中所有的索引并分析其是否可用,并且还会列出索引中可用的列字段;如果不可用,则列出不可用的原因
setup_range_conditions
如果有可下推的条件,则带条件考虑范围查询
![]()
group_index_range
评估在使用了GROUP BY或者是DISTINCT的时候是否有适合的索引可用

skip_scan_range
8.0新增,是否使用了skip scan

在 MySQL 中,skip_scan_range 是优化器跟踪输出中的一个元素,它表示优化器使用了跳过扫描(Skip Scan)访问方法。跳过扫描是一种范围访问方法,它在查询过程中跳过不满足条件的行,从而减少需要扫描的行数,提高查询效率
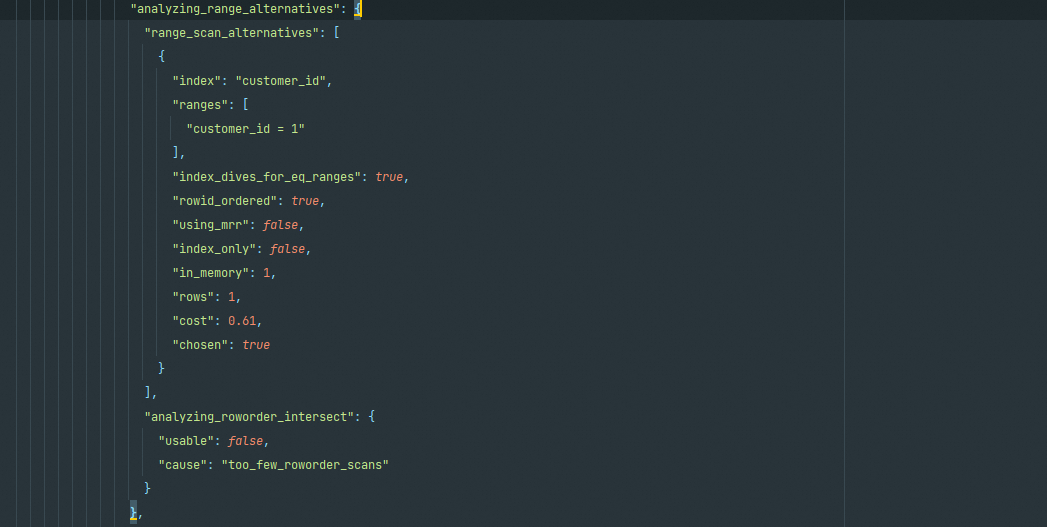
analyzing_range_alternatives
分析各索引使用成本,包括range_scan_alternatives(range扫描分析)、analyzing_roworder_intersect(index merge分析)两个阶段,分别针对不同的情况进行执行代价的分析,从中选择出更优的执行计划
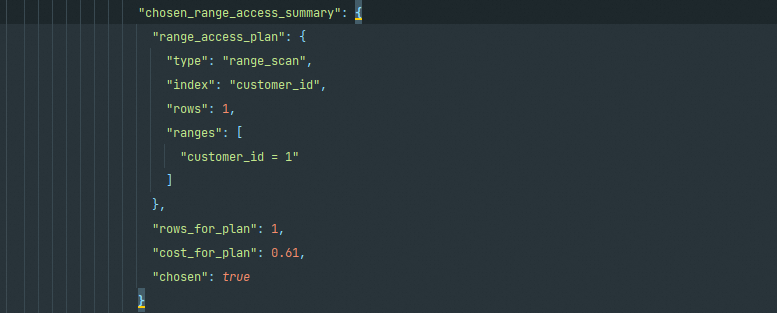
在有了上述对比之后,在下面chosen_range_access_summary给出这部分的最终结论,使用了"index": "customer_id"
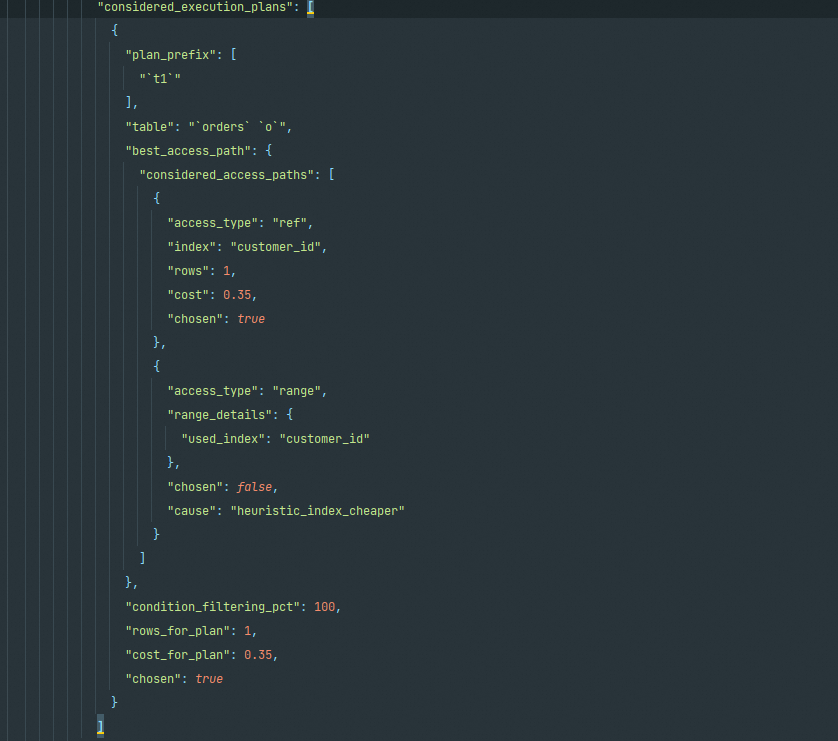
considered_execution_plans
对比实际的不同路径的成本。如果是多表关联,且有存在执行顺序(如left/right join或straight_join来强制指定顺序),则在plan_prefix部分会有前置条件;否则,就按照所有可能性评估
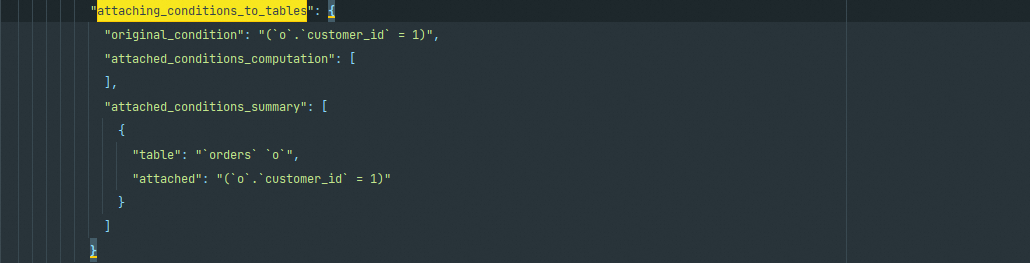
attaching_conditions_to_tables
这一步是在上面的基础上,尽量通过绑定条件到对应表上来获取更好的数据筛选。如果能做ICP(索引条件推入)则更佳
finalizing_table_conditions

refine_plan
最后的优化后的结果,如果只是展示对应的表对象没有其他字段,则说明之前已经确定的执行计划已经是最优的结果

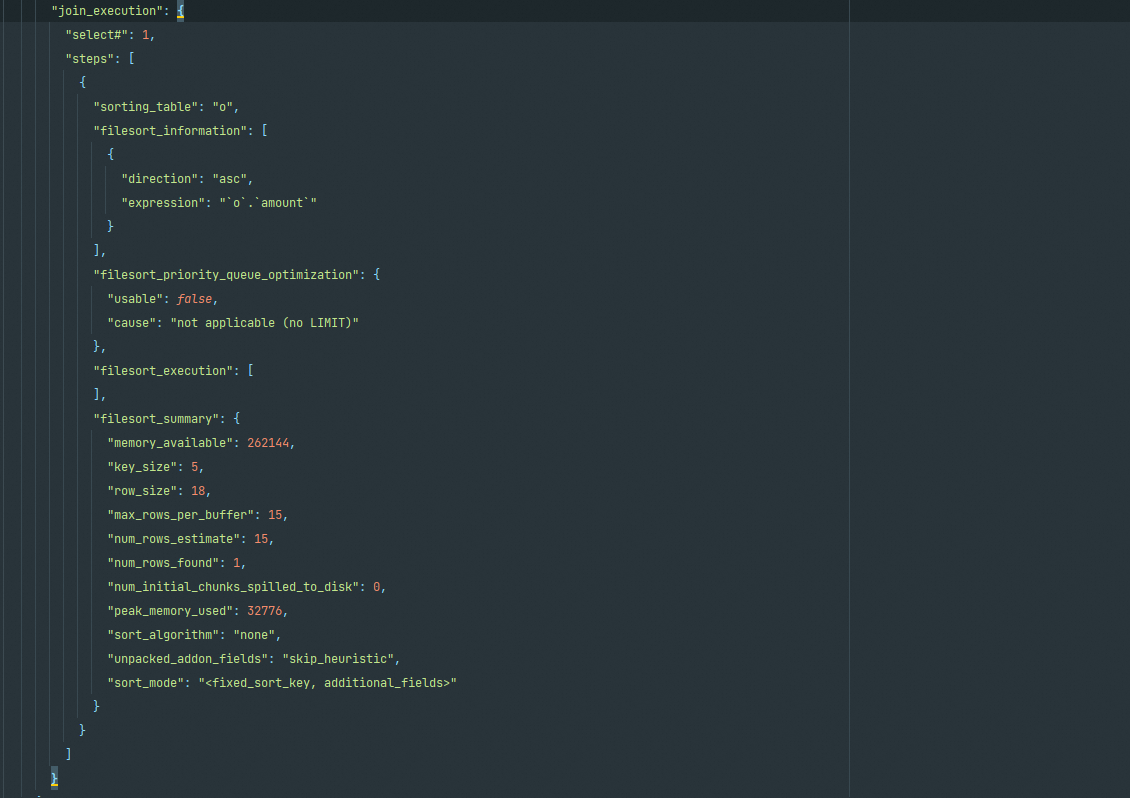
join_execution
在SQL在阶段,大部分都是空白的

只有当语句中包含有排序等操作时,才会在此部分显示
附件
CREATE TABLE `t1` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`id1` INT DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO t1 (name, id1) VALUES
('Alice', 101),
('Bob', 102),
('Charlie', 103),
('David', 104),
('Eve', 105),
('Frank', 106),
('George', 107),
('Hannah', 108),
('Ivan', 109),
('Jack', 110),
('Kevin', 111);INSERT INTO orders (order_date, amount, customer_id) VALUES
('2023-01-01', 100.00, 1),
('2023-01-02', 200.50, 2),
('2023-01-03', 300.75, 3),
('2023-01-04', 400.00, 4),
('2023-01-05', 500.00, 5),
('2023-01-06', 600.25, 6),
('2023-01-07', 700.50, 7),
('2023-01-08', 800.00, 8),
('2023-01-09', 900.75, 9),
('2023-01-10', 1000.00, 10);SELECT
t1.id AS customer_id,
t1.name AS customer_name,
GROUP_CONCAT(o.amount ORDER BY o.amount SEPARATOR ',') AS grouped_amount, -- 使用 GROUP_CONCAT() 函数并确保它在 SELECT 列表中
COUNT(o.order_id) AS order_count
FROM
(SELECT * FROM t1 WHERE id = 1) AS t1
JOIN
orders AS o ON t1.id = o.customer_id
GROUP BY
amount; SELECT
t1.id AS customer_id,
t1.name AS customer_name,
GROUP_CONCAT(DISTINCT o.amount ORDER BY o.amount SEPARATOR ',') AS grouped_amount, -- 使用 GROUP_CONCAT() 函数并确保它在 SELECT 列表中,添加 DISTINCT 以去重
COUNT(o.order_id) AS order_count
FROM
(SELECT * FROM t1 WHERE id = 1) AS t1
JOIN
orders AS o ON t1.id = o.customer_id
GROUP BY
amount;QUERY | SELECT
t1.id AS customer_id,
t1.name AS customer_name,
GROUP_CONCAT(DISTINCT o.amount ORDER BY o.amount SEPARATOR ',') AS grouped_amount, -- 使用 GROUP_CONCAT() 函数并确保它在 SELECT 列表中,添加 DISTINCT 以去重
COUNT(o.order_id) AS order_count
FROM
(SELECT * FROM t1 WHERE id = 1) AS t1 -- 子查询,先从 t1 表中选出 id 为 1 的记录
JOIN
orders AS o ON t1.id = o.customer_id -- 将子查询的结果与 orders 表进行连接
GROUP BY
amount
TRACE | {
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"join_preparation": {
"select#": 2,
"steps": [
{
"expanded_query": "/* select#2 */ select `t1`.`id` AS `id`,`t1`.`name` AS `name`,`t1`.`id1` AS `id1` from `t1` where (`t1`.`id` = 1)"
}
]
}
},
{
"derived": {
"table": "`` `t1`",
"select#": 2,
"merged": true
}
},
{
"expanded_query": "/* select#1 */ select `t1`.`id` AS `customer_id`,`t1`.`name` AS `customer_name`,group_concat(distinct `o`.`amount` order by `o`.`amount` ASC separator ',') AS `grouped_amount`,count(`o`.`order_id`) AS `order_count` from (<constant table> join (`t1`) on((`t1`.`id` = 1)) join `orders` `o` on((`t1`.`id` = `o`.`customer_id`))) group by `o`.`amount`"
},
{
"transformations_to_nested_joins": {
"transformations": [
"JOIN_condition_to_WHERE",
"parenthesis_removal"
],
"expanded_query": "/* select#1 */ select `t1`.`id` AS `customer_id`,`t1`.`name` AS `customer_name`,group_concat(distinct `o`.`amount` order by `o`.`amount` ASC separator ',') AS `grouped_amount`,count(`o`.`order_id`) AS `order_count` from `t1` join `orders` `o` where ((`t1`.`id` = `o`.`customer_id`) and (`t1`.`id` = 1)) group by `o`.`amount`"
}
},
{
"functional_dependencies_of_GROUP_columns": {
"all_columns_of_table_map_bits": [
0
],
"columns": [
"demo3.o.amount",
"demo3.t1.id"
]
}
}
]
}
},
{
"join_optimization": {
"select#": 1,
"steps": [
{
"condition_processing": {
"condition": "WHERE",
"original_condition": "((`t1`.`id` = `o`.`customer_id`) and (`t1`.`id` = 1))",
"steps": [
{
"transformation": "equality_propagation",
"resulting_condition": "(multiple equal(1, `t1`.`id`, `o`.`customer_id`))"
},
{
"transformation": "constant_propagation",
"resulting_condition": "(multiple equal(1, `t1`.`id`, `o`.`customer_id`))"
},
{
"transformation": "trivial_condition_removal",
"resulting_condition": "multiple equal(1, `t1`.`id`, `o`.`customer_id`)"
}
]
}
},
{
"substitute_generated_columns": {
}
},
{
"table_dependencies": [
{
"table": "`t1`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
]
},
{
"table": "`orders` `o`",
"row_may_be_null": false,
"map_bit": 1,
"depends_on_map_bits": [
]
}
]
},
{
"ref_optimizer_key_uses": [
{
"table": "`t1`",
"field": "id",
"equals": "1",
"null_rejecting": true
},
{
"table": "`orders` `o`",
"field": "customer_id",
"equals": "1",
"null_rejecting": true
}
]
},
{
"rows_estimation": [
{
"table": "`t1`",
"rows": 1,
"cost": 1,
"table_type": "const",
"empty": false
},
{
"table": "`orders` `o`",
"range_analysis": {
"table_scan": {
"rows": 2,
"cost": 2.55
},
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "customer_id",
"usable": true,
"key_parts": [
"customer_id",
"order_id"
]
}
],
"setup_range_conditions": [
],
"group_index_range": {
"chosen": false,
"cause": "not_single_table"
},
"skip_scan_range": {
"chosen": false,
"cause": "not_single_table"
},
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "customer_id",
"ranges": [
"customer_id = 1"
],
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"in_memory": 1,
"rows": 1,
"cost": 0.61,
"chosen": true
}
],
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
}
},
"chosen_range_access_summary": {
"range_access_plan": {
"type": "range_scan",
"index": "customer_id",
"rows": 1,
"ranges": [
"customer_id = 1"
]
},
"rows_for_plan": 1,
"cost_for_plan": 0.61,
"chosen": true
}
}
}
]
},
{
"considered_execution_plans": [
{
"plan_prefix": [
"`t1`"
],
"table": "`orders` `o`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "customer_id",
"rows": 1,
"cost": 0.35,
"chosen": true
},
{
"access_type": "range",
"range_details": {
"used_index": "customer_id"
},
"chosen": false,
"cause": "heuristic_index_cheaper"
}
]
},
"condition_filtering_pct": 100,
"rows_for_plan": 1,
"cost_for_plan": 0.35,
"chosen": true
}
]
},
{
"attaching_conditions_to_tables": {
"original_condition": "(`o`.`customer_id` = 1)",
"attached_conditions_computation": [
],
"attached_conditions_summary": [
{
"table": "`orders` `o`",
"attached": "(`o`.`customer_id` = 1)"
}
]
}
},
{
"optimizing_distinct_group_by_order_by": {
"simplifying_group_by": {
"original_clause": "`o`.`amount`",
"items": [
{
"item": "`o`.`amount`"
}
],
"resulting_clause_is_simple": true,
"resulting_clause": "`o`.`amount`"
}
}
},
{
"finalizing_table_conditions": [
{
"table": "`orders` `o`",
"original_table_condition": "(`o`.`customer_id` = 1)",
"final_table_condition ": null
}
]
},
{
"refine_plan": [
{
"table": "`orders` `o`"
}
]
},
{
"considering_tmp_tables": [
{
"creating_tmp_table": {
"tmp_table_info": {
"table": "intermediate_tmp_table",
"columns": 1,
"row_length": 6,
"key_length": 0,
"unique_constraint": false,
"makes_grouped_rows": false,
"cannot_insert_duplicates": false,
"location": "TempTable"
}
}
},
{
"adding_sort_to_table": "o"
}
]
}
]
}
},
{
"join_execution": {
"select#": 1,
"steps": [
{
"sorting_table": "o",
"filesort_information": [
{
"direction": "asc",
"expression": "`o`.`amount`"
}
],
"filesort_priority_queue_optimization": {
"usable": false,
"cause": "not applicable (no LIMIT)"
},
"filesort_execution": [
],
"filesort_summary": {
"memory_available": 262144,
"key_size": 5,
"row_size": 18,
"max_rows_per_buffer": 15,
"num_rows_estimate": 15,
"num_rows_found": 1,
"num_initial_chunks_spilled_to_disk": 0,
"peak_memory_used": 32776,
"sort_algorithm": "none",
"unpacked_addon_fields": "skip_heuristic",
"sort_mode": "<fixed_sort_key, additional_fields>"
}
}
]
}
}
]
}
MISSING_BYTES_BEYOND_MAX_MEM_SIZE | 0
INSUFFICIENT_PRIVILEGES | 0