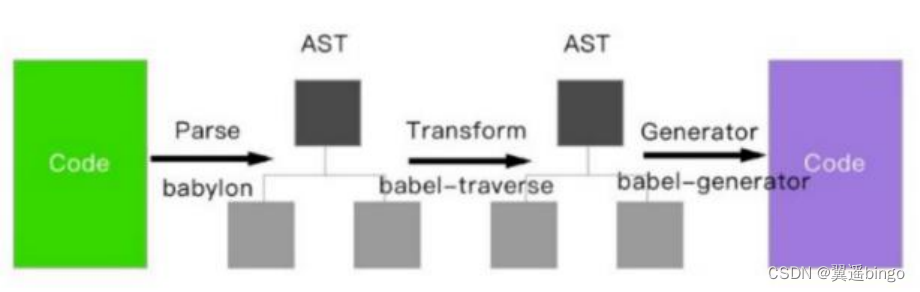
sheet : The worksheet to write to. Can be the worksheet index or name.
x: Object to be written. For classes supported look at the examples.
startCol :A vector specifying the starting column to write to.
startRow:A vector specifying the starting row to write to.
array: A bool if the function written is of type array
xy: An alternative to specifying startCol and startRow individually. A vector of the form c(startCol, startRow).
colNames: If TRUE, column names of x are written.
rowNames : If TRUE, data.frame row names of x are written.
headerStyle: Custom style to apply to column names.
borders: Either “none” (default), “surrounding”, “columns”, “rows” or respective abbreviations. If “surrounding”, a border is drawn around the data. If “rows”, a surrounding border is drawn with a border around each row. If “columns”, a surrounding border is drawn with a border between each column. If “all” all cell borders are drawn.
borderColour :Colour of cell border. A valid colour (belonging to colours() or a hex colour code, eg see here).
borderStyle: Border line style
withFilter: If TRUE or NA, add filters to the column name row. NOTE can only have one filter per worksheet.
keepNA : If TRUE, NA values are converted to #N/A (or na.string, if not NULL) in Excel, else NA cells will be empty.
na.string: If not NULL, and if keepNA is TRUE, NA values are converted to this string in Excel.
name :If not NULL, a named region is defined.
sep: Only applies to list columns. The separator used to collapse list columns to a character vector e.g. sapply(x$list_column, paste, collapse = sep).
row.names, col.names: Deprecated, please use rowNames, colNames instead
BARTSCORE: Evaluating Generated Text as Text Generation 这篇文章是用生成模型解决问题,根据生成模型中输入和输出的差别,代表不同的评测方面。 不足:针对不同的任务选择bart score的输入和输出?different input and output co…







![[数据结构]链表OJ题 (三) 链表的中间结点、链表中倒数第k个结点、合并两个有序链表、链表分割、链表的回文结构](https://img-blog.csdnimg.cn/c81419aa5c9c41bb81996303e1485337.png)