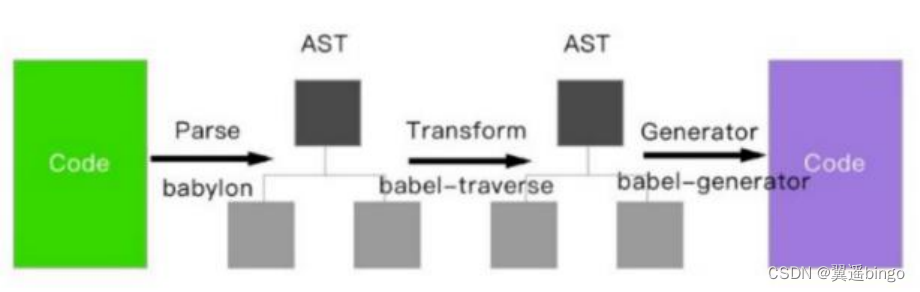
BARTSCORE: Evaluating Generated Text as Text Generation
这篇文章是用生成模型解决问题,根据生成模型中输入和输出的差别,代表不同的评测方面。
不足:针对不同的任务选择bart score的输入和输出?different input and output contents
weight 为什么等权重?
摘要部分
One of big challenge of the these applications is how to evaluate the genertated texts are actually flent, accruate, or effective.
The general idea is that models trained to convert the gererated text to a reference output or the source text will achieve higher scores when the gererated text is better.
在introduction中,介绍背景和research community jobs之后,转到现在的问题上,however …This lead to potential under-utilization of the pretrain model.
然后,新的一段,介绍自己的工作.In this paper we ....
新的一段,介绍result 。Experimentally,we evaluate ....
方法
问题定义:
In this work, we focus on
conditional text generation (e.g., machine translation), where the goal is to generate a hypothesis
(h = h1, · · · , hm) based on a given source text (s = s1, · · · , sn). Commonly, one or multiple
human-created references (r = r1, · · · , rl) are provided to aid this evaluation
人类是怎么评价相关工作的?
- 信息性(INFO)。生成的假设在多大程度上抓住了源文本的关键思想[18]。
- 相关性(REL)。生成的假说与源文本的一致性如何[19]。
- 流畅性(FLU)。文本是否有格式问题、大小写错误或明显不符合语法的句子(如片段、缺失的成分)而导致文本难以阅读[13]。
- 连贯性(COH)。文本是否从一个句子到另一个句子建立起一个关于主题的连贯的信息体[7]。
- 事实性(FAC)。生成的假说是否只包含源文本所包含的语句[30]。
- 语义覆盖率(COV)。生成的假说覆盖了多少参考文本的语义内容单元[50]。
- 适当性(ADE)。输出是否传达了与输入句子相同的意思,而且没有任何信息被丢失、添加或扭曲[29]。
前人工作——使用不用的模型评价
T1: Unsupervised Matching. Unsupervised matching metrics aim to measure the semantic equivalence between the reference and hypothesis by using a token-level match
BERTScore [76], MoverScore [77] or discrete string space like ROUGE [35], BLEU [51], CHRF [53]
T2: Supervised Regression. Regression-based models introduce a parameterized regression layer
BLEURT [63], COMET [57] and traditional metrics like S
[52], VRM [21].
T3: Supervised Ranking. Evaluation can also be conceived as a ranking problem, where the main
idea is to learn a scoring function that assigns a higher score to better hypotheses than to worse ones
COMET [57] and BEER [65]
T4: Text Generation. In this work, we formulate evaluating generated text as a text generation task
from pre-trained language models. The basic idea is that a high-quality hypothesis will be easily
generated based on source or reference text or vice-versa.
PRISM
bart score
根究文本生成的顺序,或者可以描述为参考句子和生成句子,判断bart score描述的是哪个方面。

- - 忠实度(s → h):从源文件到假设的p(h|s,θ)。这个方向衡量的是基于源文本产生假设的可能性有多大。潜在的应用场景是§2.2中介绍的事实性和相关性。这个衡量标准也可用于估计只衡量目标文本的质量,如连贯性和流畅性(§2.2)。
- - 精度(r→h):从参考文本到系统生成的文本p(h|r, θ)。这个方向评估了根据黄金参考文献构建假设的可能性,适用于**以精度为重点**的情况。
- - 召回率(h→r):从系统生成的文本到参考文本p(r|h,θ)。这个版本量化了假设生成黄金参考文献的难易程度,适用于总结任务中基于金字塔的评估(即第2.2节中介绍的语义覆盖率),因为金字塔得分衡量了系统生成的文本所覆盖的细粒度语义内容单位(SCU)[50]。
- - F得分(r ↔ h)。考虑到两个方向,并使用精度和召回率的算术平均数。该版本可广泛用于评估参考文本和生成文本之间的语义重叠(信息量、充分性,详见第2.2节)。
变体
加不加prompt,在哪加?
- 在生成文本还是在原始输入文本中加prompt
- prompt制作的问题,是采用hard craft 方法还是soft prompt 方法。——
人为制作的方式,在种子prompts的基础上,收集其他的prompts.
- prompt数量的问题

测评
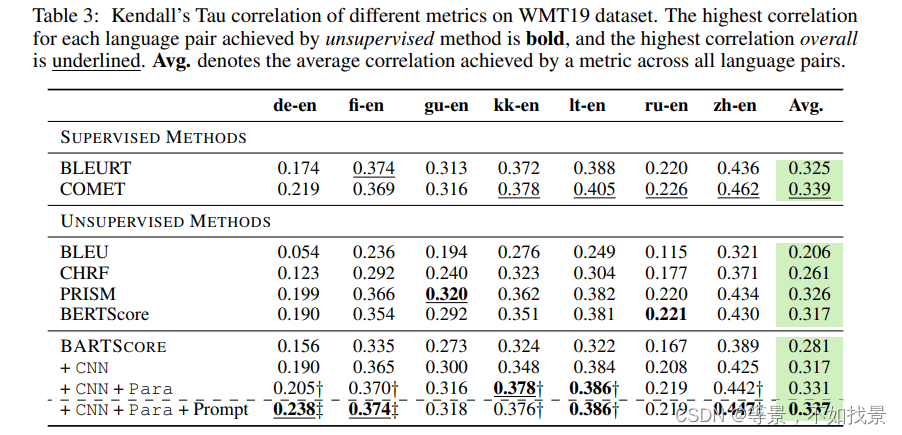
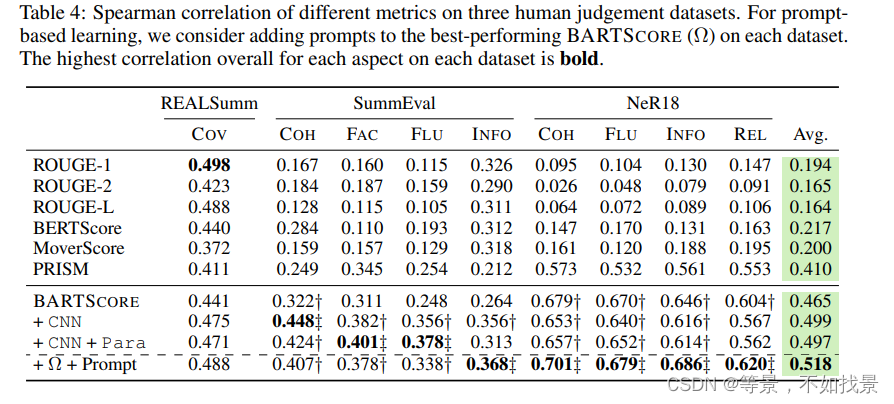
测评是采用Pearson Correlation[15]测量两组数据之间的线性相关。Spearman Correlation [73] 评估两个变量之间的单调关系。Kendall’s Tau[27]测量两个测量量之间的顺序关联。准确度,在我们的实验中,衡量事实性文本和非事实性文本之间正确排名的百分比。
实验
机器翻译实验
data2 text 实验
文本总结实验
细粒度分析
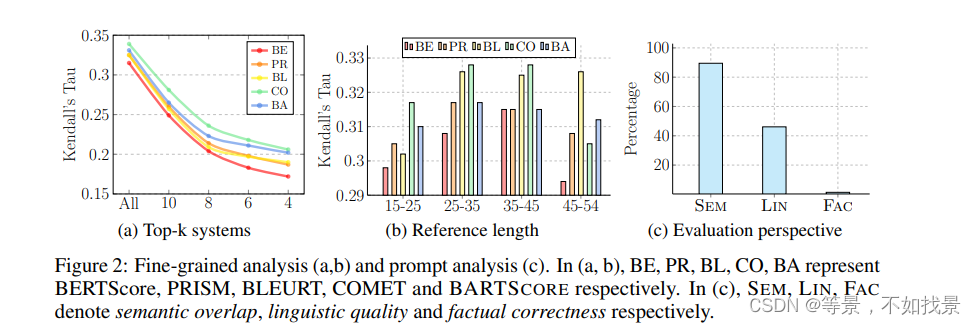
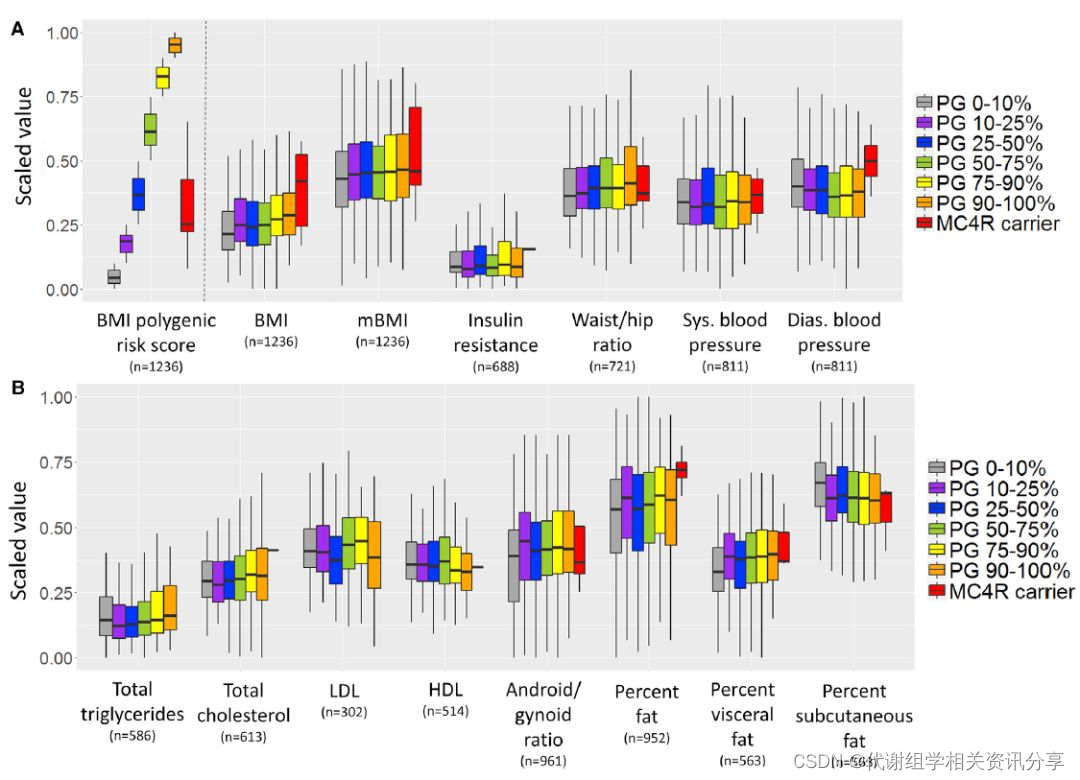
第一张图片是在不同top-k的机器翻译系统下,不同metric的性能变化趋势。可以发现,当k增加的时候,BA下降趋势是较为平稳的。BA的相关性也是优于几个模型的。
(折线图分析的是下降趋势和整体性能)
第二张图是分析,在不同的reference length条件下的模型性能。整体来看,BA平稳。但性能上,用了tie with other unsupervied models.
第三张图是分析prompt的影响,分为了三种。分别测评的。
bias分析

BARTScore is less effective at distinguishing the quality of extractive summarization systems while much better at distinguishing the quality of abstractive summarization systems.

![[数据结构]链表OJ题 (三) 链表的中间结点、链表中倒数第k个结点、合并两个有序链表、链表分割、链表的回文结构](https://img-blog.csdnimg.cn/c81419aa5c9c41bb81996303e1485337.png)