昨天太摸鱼啦~不过蛮开心的哈哈
今天主要是把积累的ddl都清理一下!!!第一项就是我和舍友一起读的论文嘿嘿!!
一、RAGA
(零)总结(仅模型)
作为数据挖掘顶会2021年的论文,感觉这篇文章比较干净简洁,读起来舒服,值得学习模仿。【emmm…是不是顶会也没那么难呀hhh】
由于过于缺少背景知识,而且要讲解这篇文章,所以在粗览后,进行顺序阅读。
(一)摘要&intro
—0847大致读了摘要和intro。
1、该文章主要想解决实体对齐的两个问题:
(1)难以利用多条边提供的信息
提出了Relation-aware GAN
(2)两个KG双向进行对齐时会产生矛盾
提出了deferred acceptance algorithm(延迟接受算法)
查了一下这个词,搜到了一篇Stanford2007年的论文,下载下来看看,有需要就看看~
“盖尔-沙普利算法(Gale-Shapley algorithm)简称 “GS算法”,也称为 “延迟接受算法”(deferred-acceptance algorithm),,是盖尔和沙普利为了寻找一个稳定匹配而设计出的市场机制。”
** 约会匹配算法**
参考链接:
https://blog.csdn.net/lc_miao/article/details/78114127
https://www.cnblogs.com/jesse123/p/6008595.html
https://zhuanlan.zhihu.com/p/356907926
2、开源代码
Link:
https://github.com/zhurboo/RAGA
去fork & clone一下好啦
—0914休息的时候报名了蓝桥(氪金)杯,还是报python组叭~虽然很想学学c++,但估计还是不会有时间叭
emmm要认证身份,还要等几天emm希望不要忘了
欸嘿,一天就通过了,快报名!!!
----0918继续看论文啦!!!
(二)模型
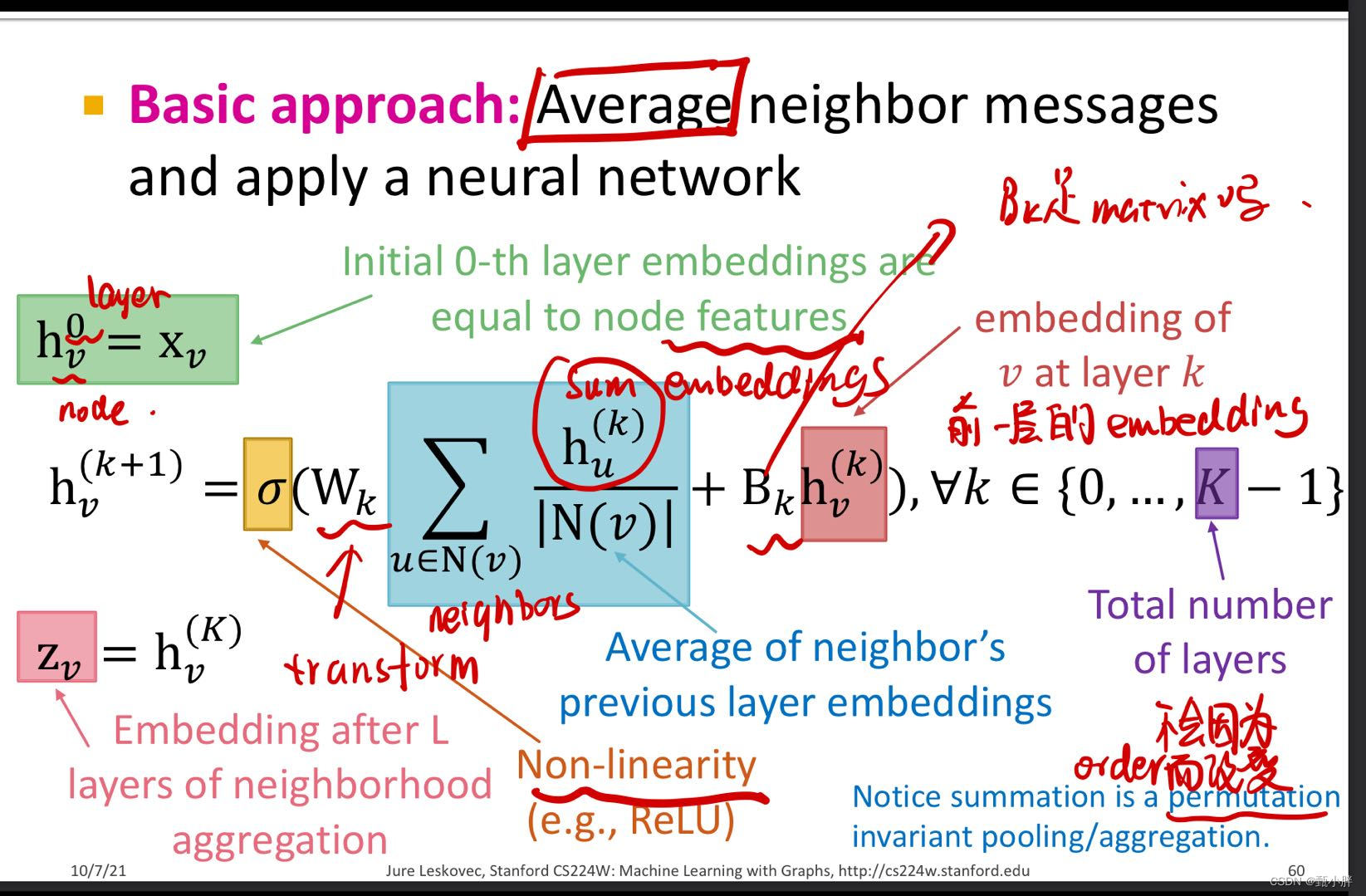
1、GCN
(1)Intuition
Every node defines a computation graph based on its neighborhood!
(2) Deep Model
A. nodes have embeddings at each layer
B. Layer-0 embedding of node v is its input feature, xv
C. Layer-k embedding gets information from nodes that are k hops away
(3)Neighborhood Aggregation
**KEY DISTINCTIONS:
how different approaches aggregate info across the layers
A. basic approach
(a) average
(b) apply nn
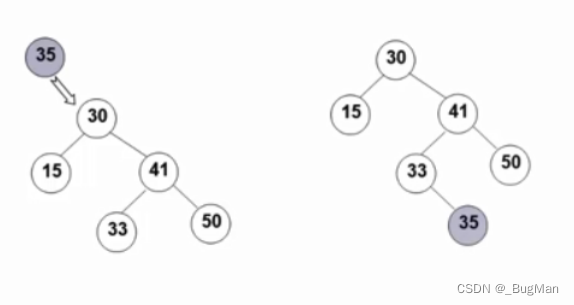
(4)Training model
将hv(最后的embedding)放入任何一个Loss function 学习Wk和Bk就好啦
其中Wk用来聚合neibors;Bk用来transform自己
(5)Matrix Formulation
矩阵形式表达transformation,这样就可以coding啦!


2、文中GCN model
查了一下与上述公式不同的原因。
“ 改进三:Symmetric normalization
上述归一化只考虑了聚合节点 𝑖 的度的情况,但没有考虑到邻居 𝑗 (其节点的情况),即未对邻居 𝑗 所传播的信息进行归一化。(此处默认每个节点通过边对外发送相同量的信息, 边越多的节点,每条边发送出去的信息量就越小, 类似均摊. ) (要理解这个问题得先知道矩阵左乘和右乘的概念,参考《矩阵的左乘和右乘》)”
参考:https://www.cnblogs.com/BlairGrowing/p/15826824.html
我的理解是,在这种方法中,即归一化了别人传来的表示向量;也为下一步将表示向量传出做准备——归一化传出的向量。
----1404
xswl中午惊闻这个csdn被同班同学默默关注着…emmm希望对大家有点帮助叭~继续读论文啦
3、α
不太理解这里的α,再看看后面的,实在不行就去看看代码啦~
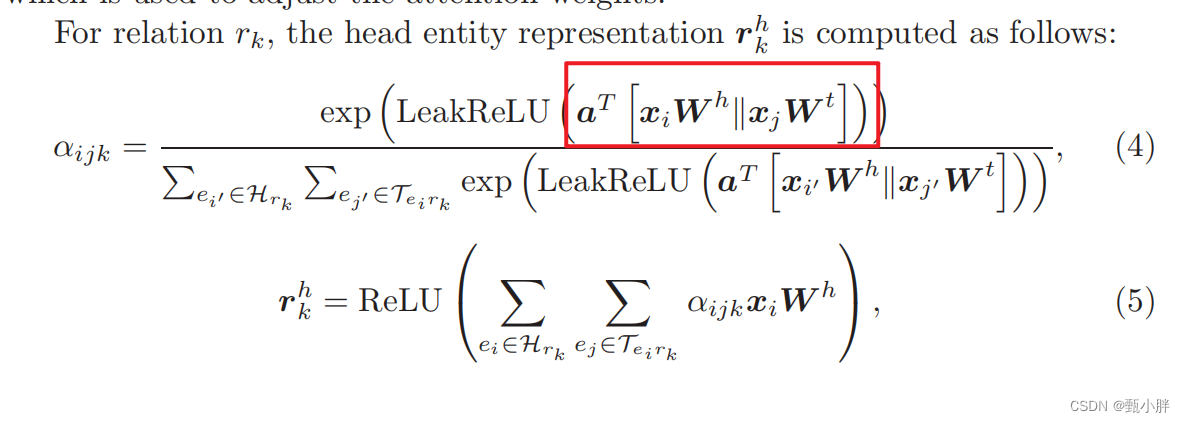
感觉像是只是一个相似度的分值,没有说具体计算相似度的方法,看一下代码。
两个||好像是concat的意思。
4、思路
还是图清晰hhh
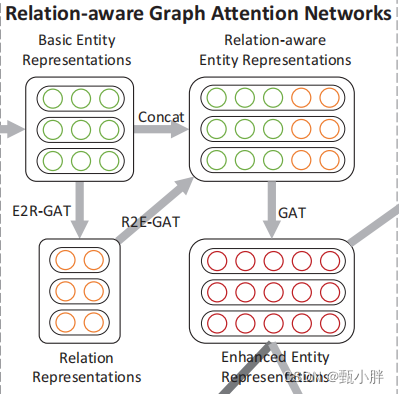
(1)先用GCN计算初始的结点向量
结点的初始特征如何选取呢???
在Implementation Details看到用的是Glove
(2)用节点表示,对边进行表示
在代码里写了些注释,但明显维度不太对,有机会debug一下看看(虽然我还不太会)。
总之,这个东西看起确实就是一个相似度分值,具体计算方法就是用learnable 的a分别计算对头节点和尾结点的相似度分数,然后二者相加,作为整体的边的分数。有二者融合的感觉,没有传统的查询的感觉hhh【不知道我理解的对不对,懒得翻其他帖子了,之后有时间再看】
def forward(self, x_e, edge_index, rel):
edge_index_h, edge_index_t = edge_index
# 头结点transform后表示
# (#e,r_hidden) = (#e,e_hidden)*(e_hidden, r_hidden)
x_r_h = self.w_h(x_e)
# 尾结点transform后表示
# (#e,r_hidden) = (#e,e_hidden)*(e_hidden, r_hidden)
x_r_t = self.w_t(x_e)
# 头节点表示
# a_h1(x_r_h):头结点transform后表示后,放入a_h1做线性变换
# (#e,1) = (#e,r_hidden)*(r_hidden, 1)
# squeeze()------tensor变量进行维度压缩,去除维数为1的的维度。
##(#e,1).squeeze()---->(#e)
# e1是LeakReLU里面的一大坨,即最终相似度分值,用来生成对于x_r_h的注意力分值,learnable a_h1和a_h2
e1 = self.a_h1(x_r_h).squeeze()[edge_index_h]+self.a_h2(x_r_t).squeeze()[edge_index_t]
# e2用来生成对x_r_t的注意力分值,用了另外两个learnable a
# 其实e1和e2目前看,完全对称,只是后续操作略有不同而已
e2 = self.a_t1(x_r_h).squeeze()[edge_index_h]+self.a_t2(x_r_t).squeeze()[edge_index_t]
# -----------------------生成基于头节点的关系表示
# 生成头节点,注意力分值
alpha = softmax(F.leaky_relu(e1).float(), rel)
# 基于头节点的关系表示
x_r_h = spmm(torch.cat([rel.view(1, -1), edge_index_h.view(1, -1)], dim=0), alpha, rel.max()+1, x_e.size(0), x_r_h)
# -----------------------生成基于头节点的关系表示
alpha = softmax(F.leaky_relu(e2).float(), rel)
x_r_t = spmm(torch.cat([rel.view(1, -1), edge_index_t.view(1, -1)], dim=0), alpha, rel.max()+1, x_e.size(0), x_r_t)
x_r = x_r_h+x_r_t
return x_r
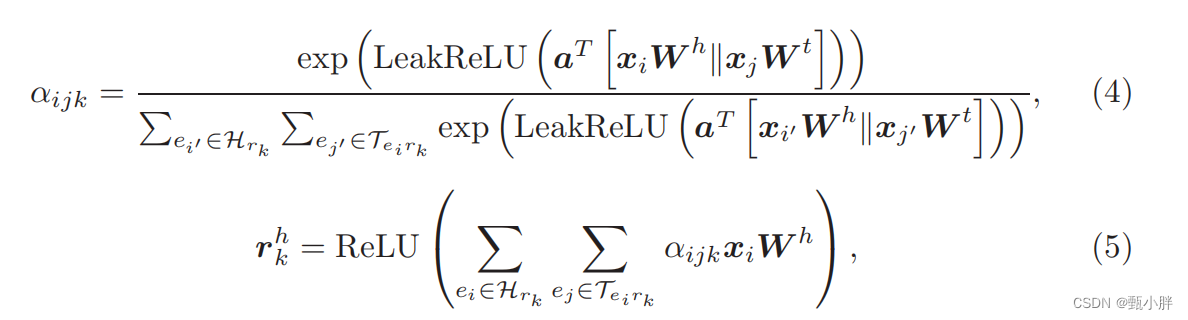
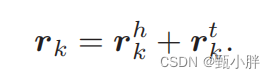
(3)用边表示更新结点的表示@Relation-aware Entity Representations
xhi:ei作为head的边的融合表示;
xti文中没说,但应该同理
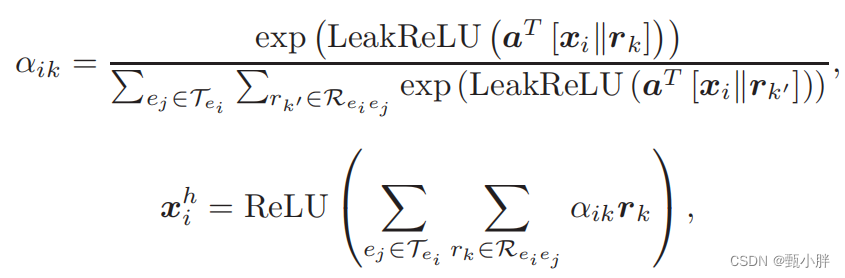
更新后的结点表示包含了结点本身信息(GCN学得的关于邻居的信息);x作为头节点、尾结点的关系的信息。
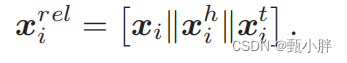
(4)enhanced entity representation
考虑到relation-aware entity只有一跳的关系,所以又加了一层注意力机制,变成两跳【记得之前看课的时候看到,加深gnn的深度,其实是扩大它的视野,我忘了具体叫什么域来的,和cnn那个名字差不多】
这里好像写错了??感觉像是Xj???
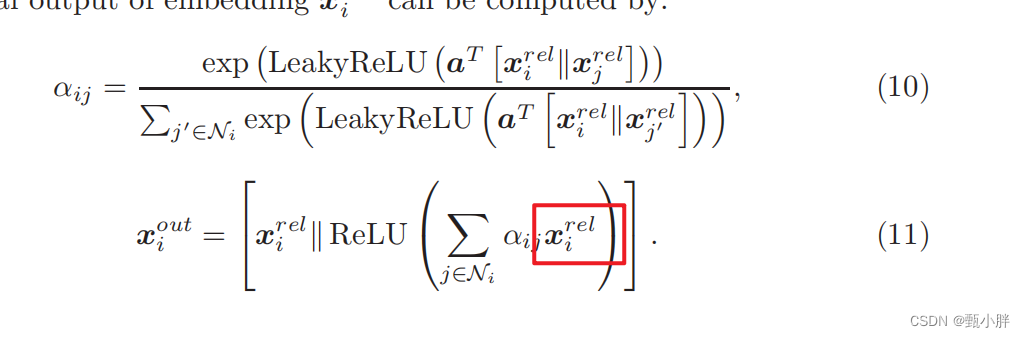
5、Hinge Loss
在svm的视频里听过这个函数,但是还没看到那里hhh
大概就是在边界外,损失为0,越靠近0,损失越大。

希望dis1小,dis2大,所以希望整体越小越好,实验中设置λ为3,也就是前者最好是小于-3

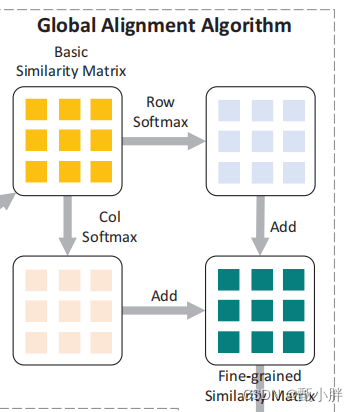
6、fine-grained similarity
这里感觉理解的很牵强。
通过softmax,达到如下目的:
(1)标准化相似度
(2)加入双向相似度,达到全局的view
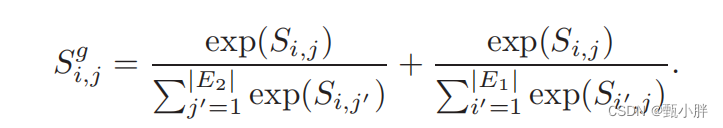
7、DAA算法&&&Hungarian Algorithm匈牙利算法
DAA不太熟,但是匈牙利算法,不得不想起y神了!
https://blog.csdn.net/lc_miao/article/details/78114127
不过,我看人家例子里都是两个矩阵,这里咋就相似度矩阵呢?
可能转置一下就好了???
emm总之感觉差不多,找让两个实体彼此尽可能相似
n、安装pytorch
为了泡泡程序,安一个pytorch叭~正好想试试hhh
https://blog.csdn.net/a850565178/article/details/107316006
好像有点麻烦,那之后再试试~
(三)实验
—1710草草过了一眼,想去跑步啦
不过值得一说的是seed entity pairs其实就是the ground truth of entity alignment
二、AttacKG
–1939跑完步歇了一会,打算看看这个代码,毕竟还有课程作业要写~可怜。
(一)复习–问题
先复习一下昨天的内容,啥也记不得了~
1、instance的含义
2、technique文件中type='example’的含义
3、根据report更新template的module在哪里
4、好像一直没有往template里面加入内容呀呀???
N、Tools
(一)Visio
修改默认主题颜色:
https://blog.csdn.net/Zhu4010/article/details/105375920
(二)cuda
emmcuda居然装的是11.8,明明记得自己下的是10.0.emm,pytorch目前只支持到11.7,先下载试试叭~ anyway,先看代码!!!抓紧时间啦!