一、Linux内核兼容多处理器要求
有多个 CPU 处理器 的 系统中 , Linux 内核需要处理的问题 :
1、公平共享 : CPU 的负载 , 需要公平地共享 , 不能出现某个CPU空闲 , 造成资源浪费。
2、可设置进程 与 CPU 亲和性 : 可以为 某些类型的 进程 与 指定的 处理器设置亲和性 , 可以针对性地匹配 进程与处理器 。
3、进程迁移 : Linux 内核可以将进程在不同的CPU处理器之间进行迁移 。
Linux 内核 的SMP对称多处理器结构调度,核心就是将进程迁移到合适的 处理器上 , 并且可以保持各个处理器的负载均衡。
二、UP
UP(Uni-Processor):系统只有一个处理器单元,即单核CPU系统。
三、SMP
3.1、概念
对称多处理器结构 , 英文名称为 " Symmetrical Multi-Processing " , 简称 SMP 。
SMP 又称为 UMA , 全称 " Uniform Memory Access " , 中文名称 " 统一内存访问架构 " 。
在 " 对称多处理器结构 " 的 系统中 , 所有的处理器单元的地位都是平等的 , 一般指的是服务器设备上 , 运行的 多个 CPU , 没有 主次/从属 关系,都是平等的。
这些处理器 共享 所有的设备资源 , 所有的资源对处理器单元具有相同的可访问性 , 如 : 磁盘 , 内存 , 总线等 ,多个CPU处理器共享相同的物理内存 , 每个 CPU 访问相同的物理地址 , 所消耗的时间是相同的 ;
要注意,这里提到的“处理器单元”是指“logic CPU”,而不是“physical CPU”。举个例子,如果一个“physical CPU”包含2个core,并且一个core包含2个hardware thread。则一个“处理器单元”就是一个hardware thread。
3.2、SMP的优势与缺陷
优点 :避免了 结构障碍 , 其最大的特点是 所有的资源共享。
缺点:SMP 架构的系统 , 扩展能力有限 , 有瓶颈限制。
如 : 内存瓶颈限制 , 每个 CPU 处理器必须通过 相同的总线 访问 相同的内存资源 , 如果 CPU 数量不断增加 , 使用同一条总线 , 就会导致 内存访问冲突 ; 这样就降低了 CPU 的性能 ;
通过实践证明 , SMP 架构的系统 , 使用2 ~ 4个 CPU , 可以达到利用率最高 , 如果 CPU 再多 , 其利用率就会降低 , 浪费处理器的性能 。
3.3、SMP启动
SMP结构中的CPU都是平等的,没有主次之分,这是基于系统中有多个进程的前提下说的。
在同一时间,一个进程只能由一个CPU执行。
系统启动对于SMP结构来说是一个特例,因为在这个阶段系统里只有一个CPU,也就是说在刚刚上电或者总清时只有一个CPU来执行系统引导和初始化。
这个CPU被称为“引导处理器”,即BP,其余的处理器处于暂停状态,称为“应用处理器”,即AP。


"引导处理器"完成整个系统的引导和初始化,并创建起多个进程,从而可以由多个处理器同时参与处理时,才启动所有的"应用处理器",让他们完成自身的初始化以后,投入运行。
1、BP先完成自身初始化,然后从start_kernel()调用smp_init()进行SMP结构初始化。
2、smp_init()的主体是smp_boot_cpus(),依次调用do_boot_cpu()启动各个AP。
3、AP通过执行trampoline.S的一段跳板程序进入startup_32()完成一些基本初始化。
4、AP进入start_secondary()做进一步初始化工作,进入自旋(全局变量smp_commenced是否变为1),等待一个统一的“起跑”命令。
5、BP完成所有AP启动后,调用smp_commence()发出该起跑命令。
6、每个CPU进入cpu_idle(),等待调度。
3.4、SMP拓扑关系构建
系统启动时开始构建CPU拓扑关系。

ARM中,4核处理器示意图如下所示:

上述4核处理器最后生成的调度域与调度组的拓扑关系图如下图如示:
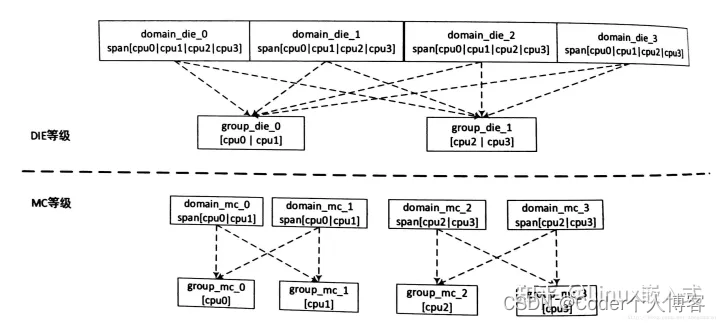
3.5、SMP调度机制分析
1、首先,load_balance()调用find_busiest_queue()来选出最忙的运行队列,在这个队列中具有最多的进程数。这个最忙的运行队列应该至少比当前的队列多出25%的进程数量。如果不存在具备这样条件的队列,find_busiest_queue()函数NULL,同时load_balance()也返回。如果存在,那么将返回这个最忙的运行时队列。
2、然后,load_balance()函数从这个最忙的运行时队列中选出将要进行负载平衡的优先级数组(priority array)。选取优先级数组原则是,首先考虑过期数组(expired array),因为这个数组中的进程相对来说已经很长时间没有运行了,所以它们极有可能不在处理器缓冲中。如果过期数组(expired priority array)为空,那就只能选择活跃数组(active array)。
3、下一步,load_balance()找出具有最高优先级(最小的数字)链表,因为把高优先级的进程分发出去比分发低优先级的更重要。
4、为了能够找出一个没有运行,可以迁移并且没有被缓冲的进程,函数将分析每一个该队列中的进程。如果有一个进程符合标准,pull_task()函数将把这个进程从最忙的运行时队列迁移到目前正在运行的队列。
5、只要这个运行时队列还处于不平衡的状态,函数将重复执行3和4,直到将多余进程从最忙的队列中迁移至目前正在运行的队列。最后,系统又处于平衡状态,当前运行队列解锁。load_balance()返回。
3.6、SMP调度时机
1、scheduler_tick
2、try_to_wake_up(优先选择在唤醒的CPU上运行)。
3、exec系统调用启动一个新进程时。
3.6.1、scheduler_tick
系统的软中断触发会周期性的调度scheduler_tick函数,每个cpu都有一个时钟中断,都会被周期性的调度到scheduler_tick函数。
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
struct rq_flags rf;
sched_clock_tick();
rq_lock(rq, &rf);
walt_set_window_start(rq, &rf);
walt_update_task_ravg(rq->curr, rq, TASK_UPDATE,
walt_ktime_clock(), 0);
update_rq_clock(rq);
curr->sched_class->task_tick(rq, curr, 0);
cpu_load_update_active(rq);
calc_global_load_tick(rq);
psi_task_tick(rq);
rq_unlock(rq, &rf);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
if (curr->sched_class == &fair_sched_class)
check_for_migration(rq, curr);
}scheduler_tick主要完成的任务如下:
1、更新WALT统计的。
2、更新系统时钟。
3、更新PELT方式统计的cpu级别的负载统计。
4、更新系统级的负载统计。
5、触发负载均衡trigger_load_balance。
/*
* Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing.
*/
void trigger_load_balance(struct rq *rq)
{
/* Don't need to rebalance while attached to NULL domain */
if (unlikely(on_null_domain(rq)))
return;
/*
#define time_after_eq(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(a) - (long)(b) >= 0))
在宏中,参数 a 是 jiffies 在某个时刻的快照,如果 a 所代表的时间比 b 靠后或者相等,那么返回真
*/
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
#ifdef CONFIG_NO_HZ_COMMON
if (nohz_kick_needed(rq, false))
nohz_balancer_kick(false);
#endif
}绑定的软中断的处理函数run_rebalance_domains。CONFIG_NO_HZ_COMMON这个宏是已经定义的。
/*
* run_rebalance_domains is triggered when needed from the scheduler tick.
* Also triggered for nohz idle balancing (with nohz_balancing_kick set).
*/
static __latent_entropy void run_rebalance_domains(struct softirq_action *h)
{
struct rq *this_rq = this_rq();
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;
/*
* If this cpu has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle cpus whose ticks are
* stopped. Do nohz_idle_balance *before* rebalance_domains to
* give the idle cpus a chance to load balance. Else we may
* load balance only within the local sched_domain hierarchy
* and abort nohz_idle_balance altogether if we pull some load.
*/
nohz_idle_balance(this_rq, idle);
update_blocked_averages(this_rq->cpu);
#ifdef CONFIG_NO_HZ_COMMON
if (!test_bit(NOHZ_STATS_KICK, nohz_flags(this_rq->cpu)))
rebalance_domains(this_rq, idle);
clear_bit(NOHZ_STATS_KICK, nohz_flags(this_rq->cpu));
#else
rebalance_domains(this_rq, idle);
#endif
}/*
* It checks each scheduling domain to see if it is due to be balanced,
* and initiates a balancing operation if so.
*
* Balancing parameters are set up in init_sched_domains.
*/
/*
根据domain级别,从下往上扫描每一级sched_domain。
如果这个domain balance之间间隔时间到了,就进行load_balance操作,
不同级别的domain时间间隔不同,而且级别越高,间隔越长,因为迁移task代价越来越大。
*/
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
int continue_balancing = 1;
int cpu = rq->cpu;
unsigned long interval;
struct sched_domain *sd;
/* Earliest time when we have to do rebalance again */
/* 默认本cpu rq下一次的balance时间为60 tick以后 */
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
int need_serialize, need_decay = 0;
u64 max_cost = 0;
rcu_read_lock();
/* (2) 对本cpu每个层次的schedule_domain进行扫描 */
for_each_domain(cpu, sd) {//遍历该cpu的所有调度域,从最低一级到最高一级。
/*
* Decay the newidle max times here because this is a regular
* visit to all the domains. Decay ~1% per second.
*/
// max_newidle_lb_cost 是做load balance所花时间。如上面注释所说,max_newidle_lb_cost每个1s衰减1%
// next_decay_max_lb_cost 是下一次进行衰减的时间
// 老化公式: new = old * (253/256)
if (time_after(jiffies, sd->next_decay_max_lb_cost)) {
sd->max_newidle_lb_cost =
(sd->max_newidle_lb_cost * 253) / 256;
sd->next_decay_max_lb_cost = jiffies + HZ;
need_decay = 1;
}
max_cost += sd->max_newidle_lb_cost;
if (energy_aware() && !sd_overutilized(sd) && !sd->parent)
continue;
if (!(sd->flags & SD_LOAD_BALANCE)) {//该调度域被指定不进行负载均衡
if (time_after_eq(jiffies,
sd->groups->sgc->next_update))
update_group_capacity(sd, cpu);
continue;
}
/*
* Stop the load balance at this level. There is another
* CPU in our sched group which is doing load balancing more
* actively.
*/
/* (4) 如果continue_balancing = 0,指示停止当前层级的load balance
因为shed_group中其他的cpu正在这个层次做load_balance*/
if (!continue_balancing) {
if (need_decay)
continue;
break;
}
/* (5) 计算当前层次schedule_domain的balance间隔时间 */
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
/* (6) 如果需要串行化(SD_SERIALIZE),做balance之前需要持锁 */
need_serialize = sd->flags & SD_SERIALIZE;
if (need_serialize) {
if (!spin_trylock(&balancing))
goto out;
}
/* (7) 如果本sd的balance间隔时间已到,进行实际的load_balance() */
//load_balance检查该cpu在这一层的调度域中是否存在负载不平衡的情况,如果存在该cpu会分担负载最重的那个cpu的一些任务
if (time_after_eq(jiffies, sd->last_balance + interval)) {
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
}
sd->last_balance = jiffies;
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
}
if (need_serialize)
spin_unlock(&balancing);
out:
//到达执行load balance的时间
if (time_after(next_balance, sd->last_balance + interval)) {
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
if (need_decay) {
/*
* Ensure the rq-wide value also decays but keep it at a
* reasonable floor to avoid funnies with rq->avg_idle.
*/
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
rcu_read_unlock();
/*
* next_balance will be updated only when there is a need.
* When the cpu is attached to null domain for ex, it will not be
* updated.
*/
/* (8.1) 更新rq的balance时间 */
if (likely(update_next_balance)) {
rq->next_balance = next_balance;
#ifdef CONFIG_NO_HZ_COMMON
/*
* If this CPU has been elected to perform the nohz idle
* balance. Other idle CPUs have already rebalanced with
* nohz_idle_balance() and nohz.next_balance has been
* updated accordingly. This CPU is now running the idle load
* balance for itself and we need to update the
* nohz.next_balance accordingly.
*/
if ((idle == CPU_IDLE) && time_after(nohz.next_balance, rq->next_balance))
nohz.next_balance = rq->next_balance;
#endif
}
}四、常用命令
4.1、查看逻辑CPU个数
方法一:cat /proc/cpuinfo
processor : 11
vendor_id : GenuineIntel
cpu family : 6
model : 62
model name : Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz
stepping : 4
microcode : 1064
cpu MHz : 2100.170
cache size : 15360 KB
physical id : 0
siblings : 12
core id : 5
cpu cores : 6
apicid : 11
initial apicid : 11
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good xtopology nonstop_tsc aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm ida arat xsaveopt pln pts dts tpr_shadow vnmi flexpriority ept vpid fsgsbase smep erms
bogomips : 4200.34
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:可以看出有12个逻辑CPU。因为processor从0开始,到11结束,说明有12个。
方法二:cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
[root@localhost ~]# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
12 Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz4.2、查看每个CPU核心数
cat /proc/cpuinfo |grep “cores”
[root@localhost ~]# cat /proc/cpuinfo |grep "cores"
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6
cpu cores : 6可以看到,12个逻辑CPU中,每个CPU都是6核。其实在查看CPU基本信息里,有个cpu cores:6,直接就显示是6个。








![[附源码]Python计算机毕业设计电子工厂进销存管理系统](https://img-blog.csdnimg.cn/7e12547693b945d4af1fe0d6525e3aa4.png)
