前前处理,把后台需要的参数都读出来。写进name.txt
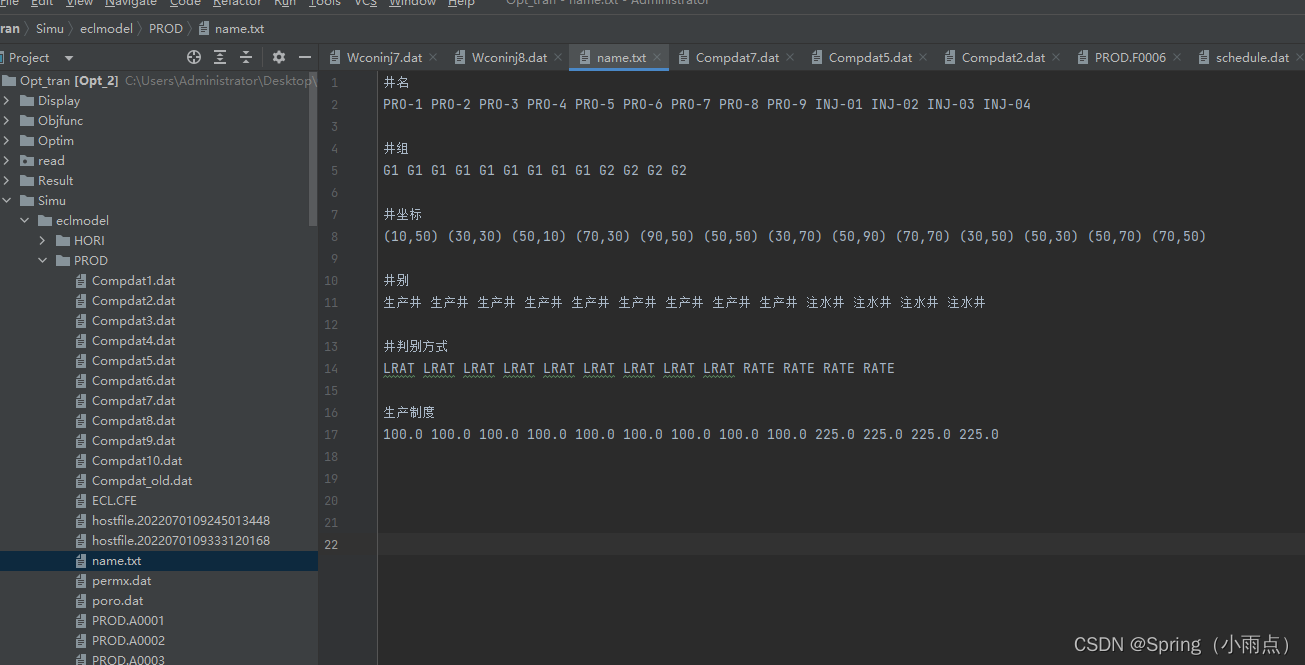
生成新的sch文件,需要在data里追加新sch名字
没改变的井就不用重新卸载关键字里了。
重启动模型:制作出来是空的,得自己加别的东西
模型要准确,否则不好和历史模型对比,历史模型就是从优化开始的那个时间步全都不处理,按照原来的进行。
sch关键字随便加
跑到几月算几月。不改变就按照之前的井跑。软件加载到sch的时间步,未计算就是灰色的。
最好直接利用别人建立好的重启动模型去做,自己不要轻易做模型,一定保证模型不能出错,不能自己乱加,这样结果也好对比。
也可以不用重启动模型,直接使用命令重启动原来的模型。
不管是eclipse还是tnavigater他们的结果几乎是相同的。
1设置在solution关键字,RESTARTDATE可以设置日期,而不是时间步
- 要和已有的历史制度对比
从十月优化,十月以后就都是按照原有进行,利用好别人给的重启动模型
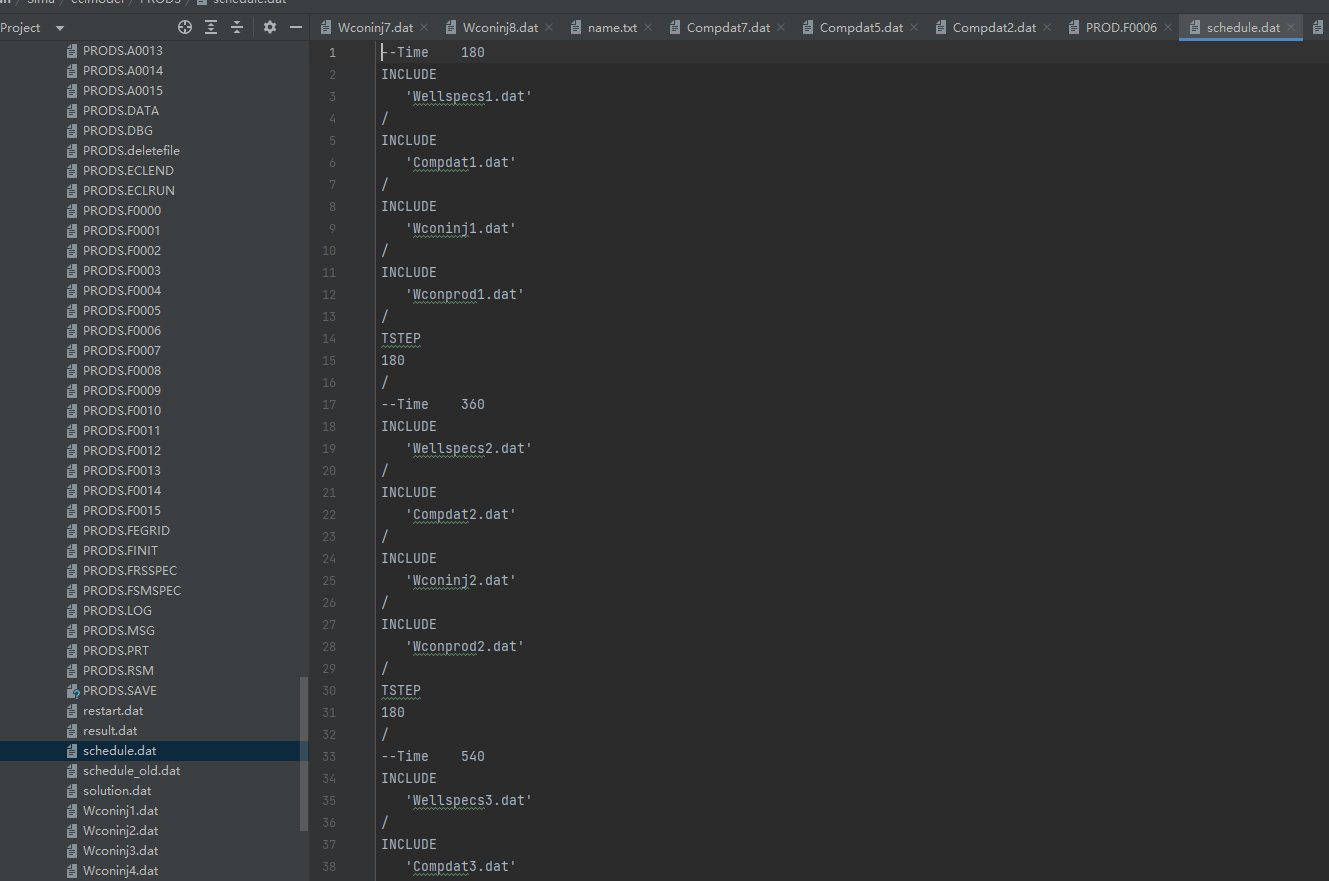
3.重启后的sch时间步都要删掉,否则会重复跑出多出自己设置的时间步数。
RESTARTDATE
‘…/HM_FINAL/HM_FINAL’ 1* 01 SEP 2022
/
模型里追加新sch重启动文件,直接跑即可
输出格式转换,按照时间步输出
RPTRST
‘BASIC=3’ ‘FREQ=1’ /
F:\\tNavigator-con-Win-64\\tNavigator-con-Win-64\\tNavigator-con --use-gpu -e -i -s -r -u –m --server-url=http://103.90.189.57:5805/tnav_cgi1/tnav_license_server.cgi D:\\moxing\\HM_FINAL_RESTART_CASE5_1\\HM_FINAL_RESTART_CASE5_1.data
for %%i in (D:\Injection_production_optimization\item\HM_FINAL_RESTART_CASE5_1\RESULTS\*.S*) do (
F:\\tNavigator-con-Win-64\\tNavigator-con-Win-64\\tNavigator-con --use-gpu --server-url=http://103.90.189.57:5805/tnav_cgi1/tnav_license_server.cgi --convert-ecl-bin-to-text %%i
)
for %%i in (D:\Injection_production_optimization\item\HM_FINAL_RESTART_CASE5_1\RESULTS\*.X0*) do (
F:\\tNavigator-con-Win-64\\tNavigator-con-Win-64\\tNavigator-con --use-gpu --server-url=http://103.90.189.57:5805/tnav_cgi1/tnav_license_server.cgi --convert-ecl-bin-to-text %%i
)
降维方法
每个时间步的变量进行统计,都加起来就是最后的维数。
1.按照井组优化。
2.转注前变量不优化,专注后才算维数。
在随机生成种子的时候就200次130维度。130=10*13口井。根据上下限和拉丁分布算法生成种子。也可以根据变异生成种子,局部效果好,二次规划。
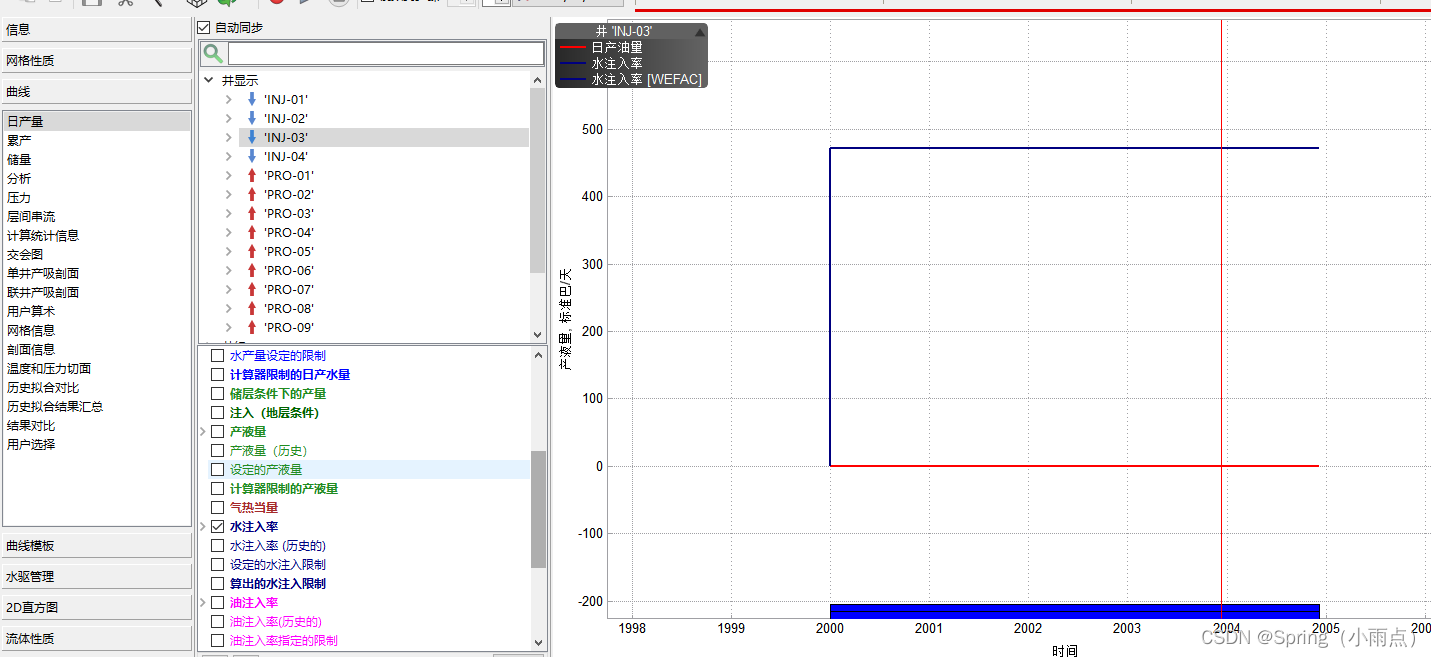
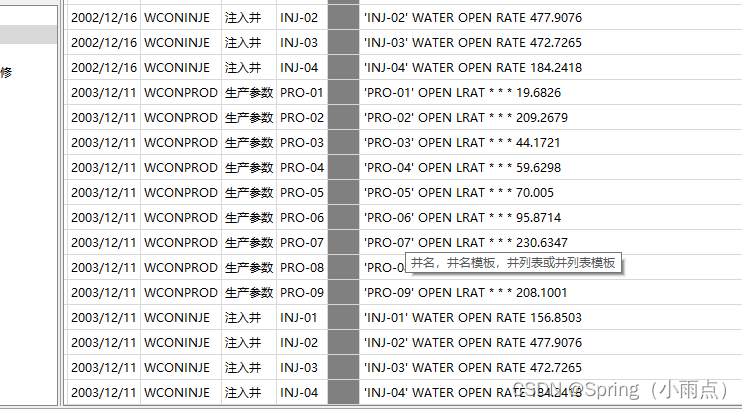
注水井的注水量
只有注水井有
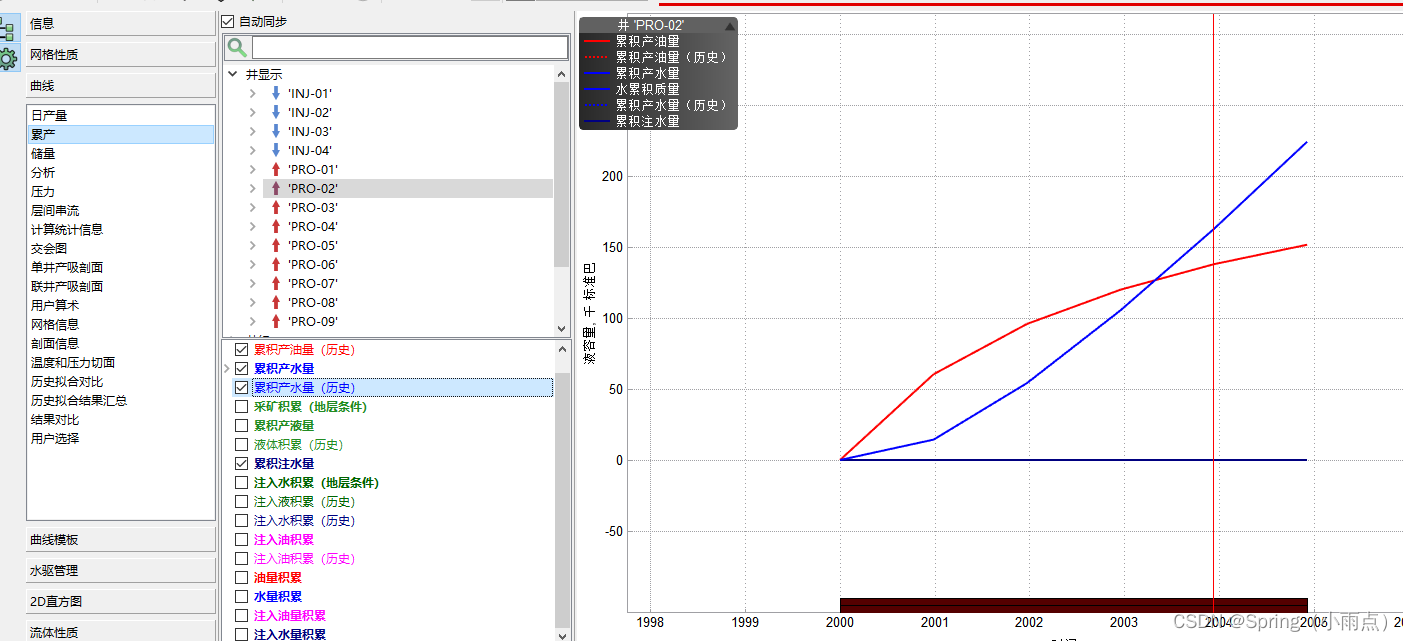
生产井的累积产量
生产井可以产水和产油
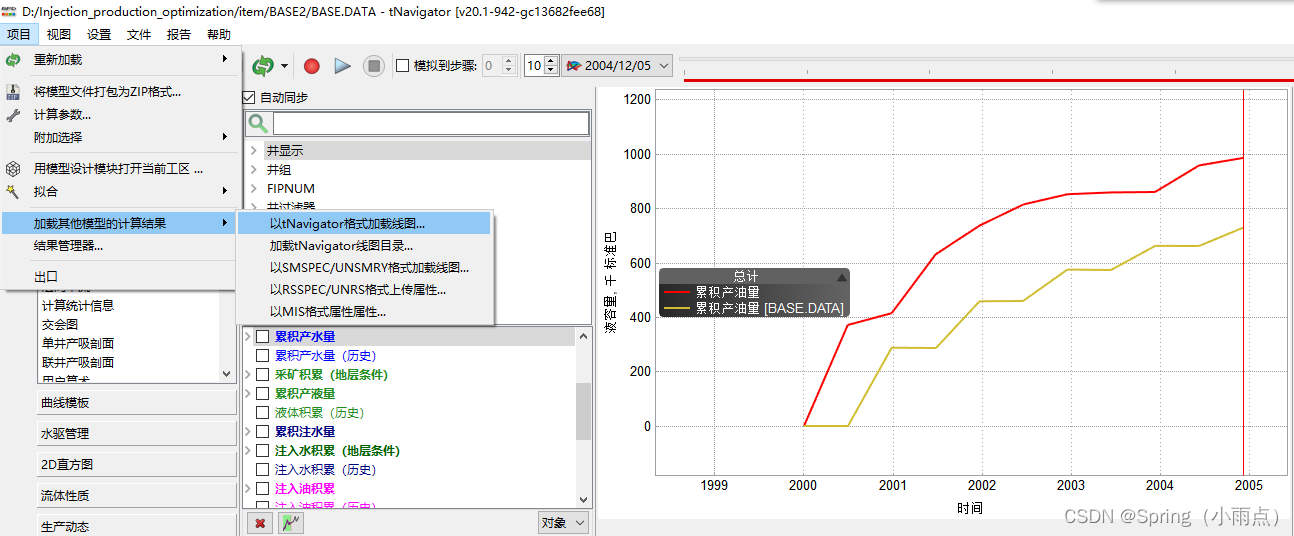
对比两个模型的累计产油量
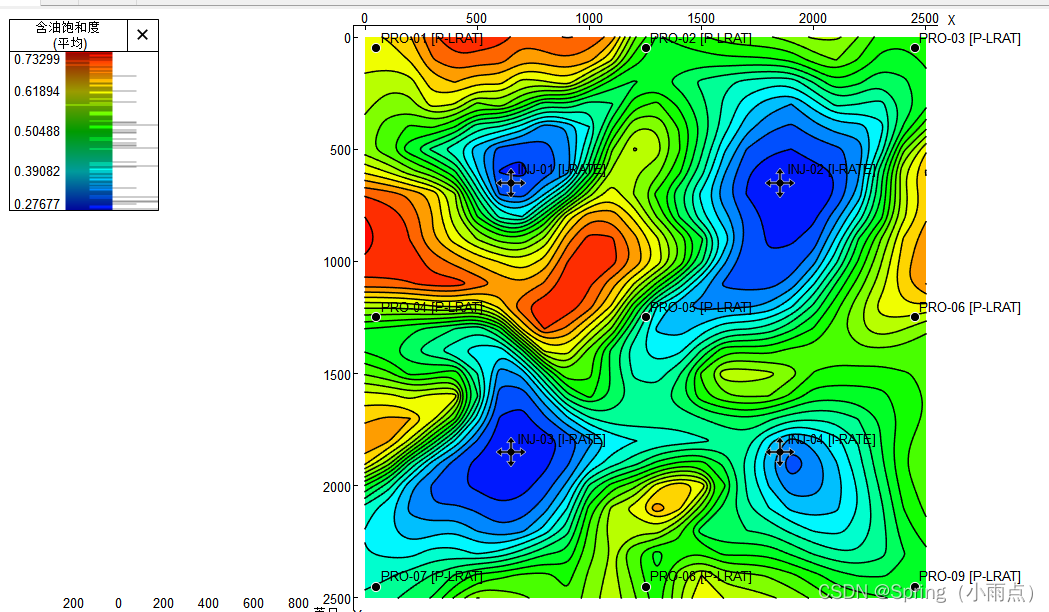
含油饱和度图
是重要指标
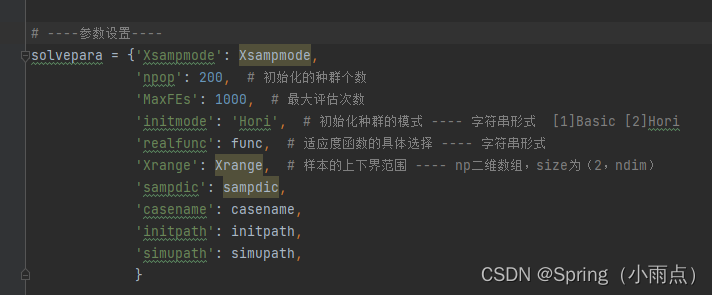
所有模式都带入输出变量维度,并装入字典,相当于java map
装入字典map中
if horimode != 'None':
#
initialmode= 'process_needed'
sampdic['hw_new_well_name'] = hw_new_well_name
sampdic['hw_new_group_name'] = hw_new_group_name
sampdic['hw_new_well_r'] = hw_new_well_r
#
sampdic['hw_new_ninj'] = hw_new_ninj
sampdic['hw_new_npro'] = hw_new_npro
sampdic['hw_new_nwell'] = sampdic['hw_new_ninj'] + sampdic['hw_new_npro']
#
sampdic['hw_consmethod'] = hw_consmethod # 约束处理方法
sampdic['hw_layermode'] = hw_layermode
#
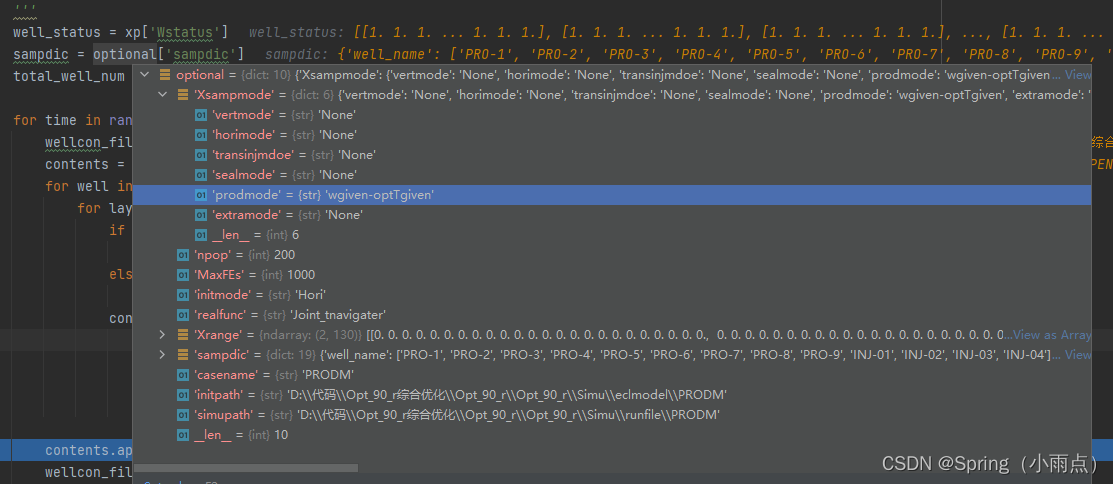
Xrange, varlen = preRan_Len(Xsampmode, sampdic)
目标函数为npv
python二维数组
井位优化spec
加井,spec里面加。
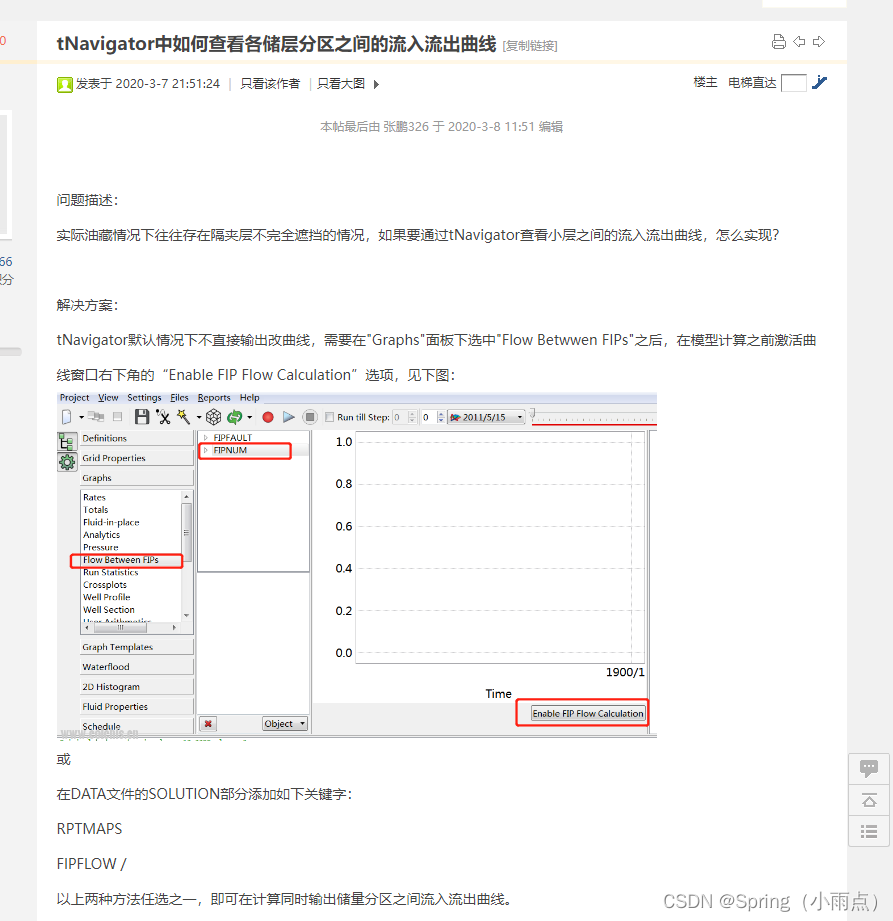
1.水平井井位优化参数输入,水平井范围
和直井井位优化的前处理区别,水平井优化过程
一口井有多个井位,在射孔那里看
射孔那里水平井多了很多层
整体优化里选择水平井井位优化模式
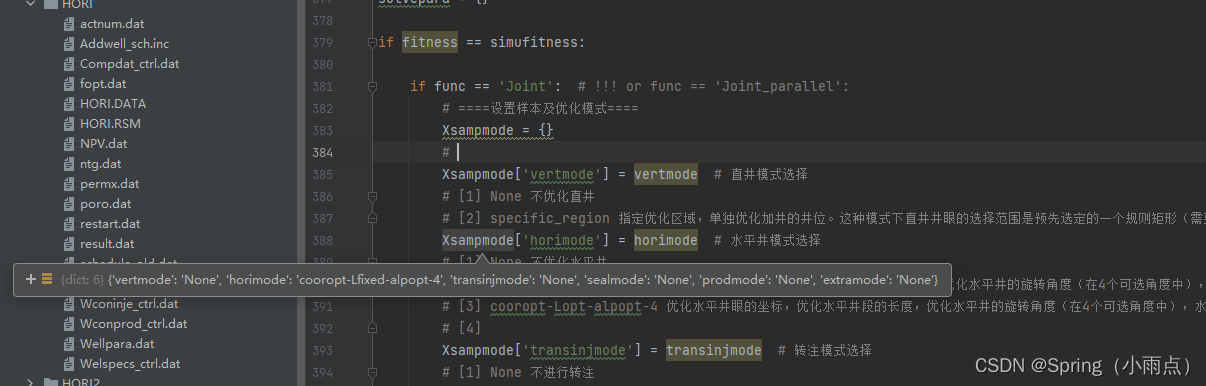
# ====================================================================
if func == 'Joint':
#
vertmode = 'None' # 直井模式选择
horimode = 'cooropt-Lfixed-alpopt-4' # 水平井模式选择
transinjmode = 'None' # 转注模式选择
sealmode = 'None' # 封堵模式选择
prodmode = 'None' # 注采模式选择
extramode = 'None' # 提液模式选择
#
水平井范围设置
if horimode != 'None':
#
hw_new_well_name = ['New-1', 'New-2', 'New-3']
hw_new_group_name = ['G1', 'G1', 'G1']
hw_new_well_r = [0.178, 0.178, 0.178]
hw_new_ninj = 1 # 新加水平井中注水井数
hw_new_npro = 2 # 新加水平井中产油井数
# ----与COMPDAT关键字写入时有关的接口(方便新加水平井井位与新加水平井的层位进行综合优化)----
hw_layermode = 'all-open'
# ----与WCONINJE和WCONPROD关键字写入时有关的接口(方便新加水平井井位与新加水平井的注采进行综合优化)----
hw_valuemode = 'allwell-opt'
# [1] allwell-same 所有井都是一样的注采量或者压力(此处输入为float数字,后面转化为list形式)
# [2] allwell-diff 所有井可以是不一样的注采量或者压力(可以①分井指定,list形式;也可以是②优化获取分井数据,如果与注采优化耦合需要选择[2]的②模式)
if hw_valuemode == 'allwell-same':
hw_injvalue = 0
hw_provalue = 900
elif hw_valuemode == 'allwell-opt':
hw_value_low = [10, 10, 10]
hw_value_up = [1000, 1000, 1000]
elif hw_valuemode == 'allwell-diff':
hw_injvalue = [100]
hw_provalue = [185, 200]
# ----与井的选取范围有关的关键字----
hw_regionmode = 'allwell-diff'
# [1] allwell_same 所有井都是在同一个选定的区域内进行位置优化(矩形区域、需在活网格内)
# [2] allwell_diff 每口井一个选的的区域进行位置优化,每口井的位置待选区域可以不同(矩形区域,需在活网格内)
if hw_regionmode == 'allwell-same':
hw_new_wxlow = 10 # 新加水平井井眼的X坐标范围的下限
hw_new_wxup = 80 # 新加水平井井眼的X坐标范围的上限
hw_new_wylow = 10
hw_new_wyup = 80
elif hw_regionmode == 'allwell-diff':
hw_new_wxlow = [10, 20, 30]
hw_new_wxup = [40, 50, 60]
hw_new_wylow = [35, 36, 37]
hw_new_wyup = [41, 42, 43]
2.封堵—层位优化参数
open shut关键字
#封堵优化用油藏模型参数 !!!!!!!!!!!!!
history_timestep = 5
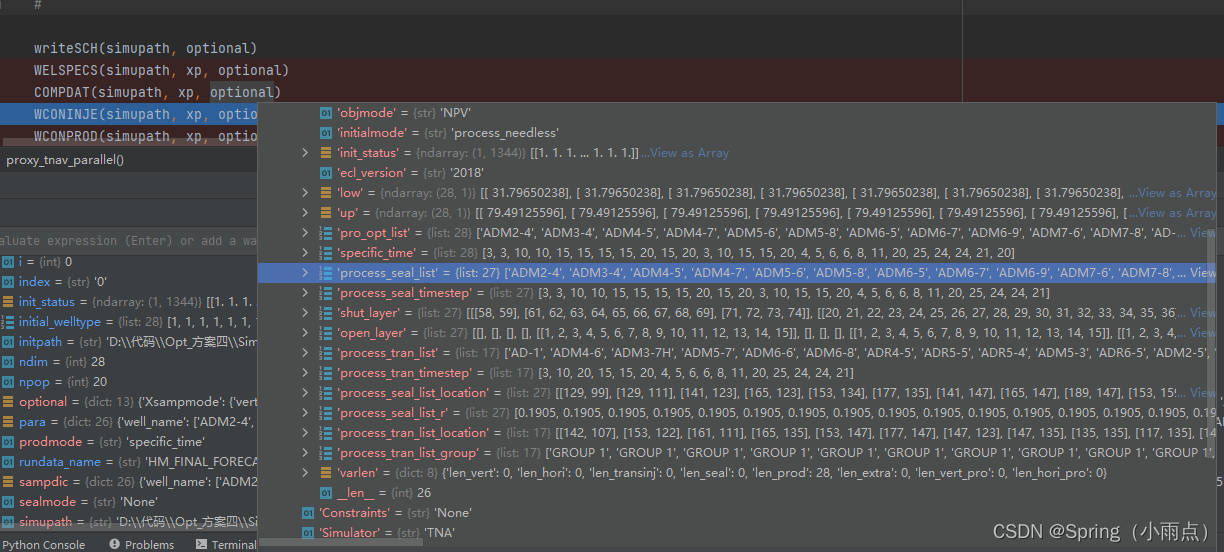
well_name = ['PRO-1', 'PRO-2', 'PRO-3', 'PRO-4', 'PRO-5', 'PRO-6', 'PRO-7', 'PRO-8', 'PRO-9', 'INJ-01', 'INJ-02',
'INJ-03', 'INJ-04']
井类型 1油井0水井
initial_welltype = [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
timestep = 10
max_layer = 12
seal_timestep = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
init_status = np.ones((1, max_layer * len(well_name)))
//封堵井组分组
seal_list = ['PRO-1', 'PRO-2', 'PRO-3', 'PRO-4', 'PRO-5', 'PRO-6', 'PRO-7', 'PRO-8', 'PRO-9', 'INJ-01', 'INJ-02'
, 'INJ-03', 'INJ-04']
seal_list_group = [['PRO-1', 'PRO-2'], ['PRO-3', 'PRO-4', 'PRO-5', 'PRO-6'], ['PRO-7', 'PRO-8', 'PRO-9'], ['INJ-01',
'INJ-02',
'INJ-03',
'INJ-04']]
seal_list_group_num = len(seal_list_group)
maxnum_seal = 2
well_group_name = ['G1', 'G1', 'G1', 'G1', 'G1', 'G1', 'G1', 'G1', 'G1', 'G2', 'G2', 'G2', 'G2']
well_r = [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]
井位
well_location = [[1, 1], [13, 1], [25, 1], [1, 13], [13, 13], [25, 13], [1, 25], [13, 25], [25, 25], [7, 7], [19, 7],
[7, 19], [19, 19]]
well_hori_location = np.tile(np.array(well_location), (1, max_layer))
transinj_list = ['PRO-1', 'PRO-2', 'PRO-3', 'PRO-4', 'PRO-5', 'PRO-6', 'PRO-7', 'PRO-8', 'PRO-9']
transinj_list_group = [['PRO-1', 'PRO-2', 'PRO-3', 'PRO-4'], ['PRO-5', 'PRO-6', 'PRO-7', 'PRO-8', 'PRO-9']]
pro_opt_list = ['PRO-1', 'PRO-2', 'PRO-3', 'PRO-4', 'INJ-01']
history_pro = np.ones((len(well_name)))*350 ##跟well_name对应,np
low = np.zeros((len(well_name)))
up = np.ones((len(well_name))) * 700
up[9] = 1500
up[10] = 1500
up[11] = 1500
up[12] = 1500
prod_low = 0 ##跟well_name对应,np
prod_up = 700
inj_low = 0
inj_up = 1500
extra_low = 50
extra_up = 100
//分为五层
segment = [[1, 2], [3, 4], [5], [6, 7, 8, 9, 10], [11, 12]]
specific_seal = [[[0, 0, 1, 1, 0], [1, 1, 0, 1, 0], [0, 1, 0, 1, 0]],
[[0, 0, 1, 1, 0], [1, 1, 0, 1, 0], [0, 1, 0, 1, 0]],
[[0, 0, 1, 1, 0], [1, 1, 0, 1, 0], [0, 1, 0, 1, 0]],
[[0, 0, 1, 1, 0], [1, 1, 0, 1, 0], [0, 1, 0, 1, 0]],
[[0, 0, 1, 1, 0], [1, 1, 0, 1, 0], [0, 1, 0, 1, 0]],
[[0, 0, 1, 1, 0], [0, 1, 0, 1, 0]],
[[0, 0, 1, 1, 0], [1, 1, 0, 1, 0]]]
segment_num = 5
timestep_len = 180
maxnum_tran = 2
objmode = 'NPV'
井位*层数


特殊封堵处理
if max_layer > 10:
for well_num in range(len(specific_seal)):
for i in range(len(specific_seal[well_num])):
temp_scheme = np.ones((max_layer))
count = 0
for l in range(segment_num):
for num in range(len(segment[l])):
temp_scheme[count] = specific_seal[well_num][i][l]
count = count + 1
specific_seal[well_num][i] = temp_scheme
3.转注优化过程参数输入
water oil关键字,采油井转为注水井
参数
if transinjmode == 'None':
transinj_list = []
if transinjmode == 'specific_max':
maxnum_tran = 3
转注+封堵一起操作
elif transinjmode == 'specific_joint':
specific_seal = [] #list,指定的封堵方案,与transinj_list的顺序对应
maxnum_tran = 2
seal_timestep = np.ones((len(well_name), 1))
大于10段,分段来减少维数
if max_layer > 10:
segment = [] #list,分段
segment_num = [] #段数
4.注采优化过程参数输入
BHP控制和液体控制

本示例为两个井设置控制。1043井处于注入速率控制,速率等于253.1。没有底部压力限制,所以模拟器将设置注入速率为253.1。如果用户指定的注入速率如此之高,以至于必要的底部孔压力超过默认极限(6801patm),该井将自动切换到必和必拓控制。1054井也有注入速率控制,速率等于253.1。该井的井底孔压力限制为400;因此,如果计算压力超过400,该井将自动切换到必和必拓控制。
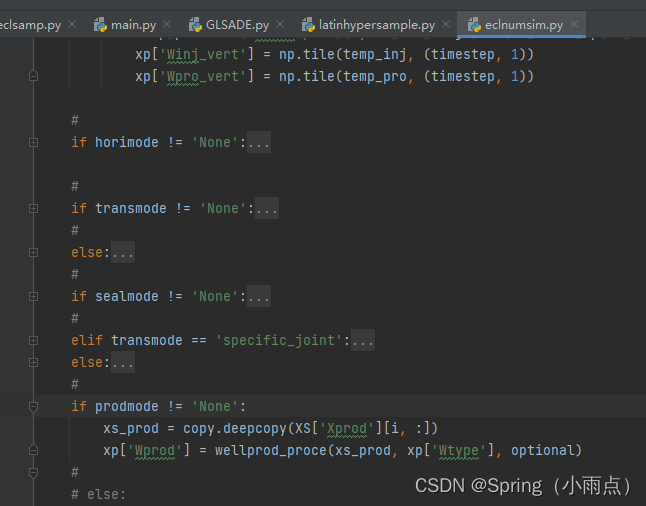
if prodmode != 'None':
low = [] # list,注采下界,与well_name顺序对应
up = [] # list,注采上界,与well_name顺序对应
if prodmode == 'specific':
history_pro = [] #历史注采量/压力,与well_name顺序对应
pro_opt_list = [] #进行注采优化的井
选择注采模式,层位和注采、转注等可以一起优化。
13口井10个时间步

生成变量

Xrange, varlen = preRan_Len(Xsampmode, sampdic)
sampdic['varlen'] = varlen
5.提液模式
注采上下限特殊处理,直接上限设置好就行
6. 直井井位优化参数输入
wellspec关键字,新加井就是井位优化
if vertmode != 'None':
#
vw_new_well_name = ['NEW-1', 'NEW-2', 'NEW-3']
vw_new_group_name = ['GROUP1', 'GROUP1', 'GROUP1']
vw_new_well_r = [0.178, 0.178, 0.178]
vw_new_ninj = 1 # 新加直井中注水井数
vw_new_npro = 2 # 新加直井中产油井数
# ----与COMPDAT关键字写入时有关的接口(方便新加直井井位与新加直井的层位进行综合优化)----
vw_layermode = 'all-open' # 选择不同模式,对应ecl_joint中的xp处的生成传递
# [1] all-open 默认新加井的所有层打开,从第1层到最后一层(max_layer)
# ----与WCONINJE和WCONPROD关键字写入时有关的接口(方便新加直井井位与新加直井的注采进行综合优化)----
vw_valuemode = 'allwell-same'
# [1] allwell-same 所有井都是一样的注采量或者压力(此处输入为float数字,后面转化为list形式)
# [2] allwell-diff 所有井可以是不一样的注采量或者压力(可以①分井指定,list形式;也可以是②优化获取分井数据,如果与注采优化耦合需要选择[2]的②模式)
#
if vw_valuemode == 'allwell-same':
vw_injvalue = 100
vw_provalue = 500
elif vw_valuemode == 'allwell-diff':
vw_injvalue = [100, 120, 300]
vw_provalue = [125, 185, 200]
#
vw_inj_controlmode = 'RATE' # 新加的注水直井的控制模式选择
# [1] RATE 流量控制
# [2] BHP 井底流压控制
vw_pro_controlmode = 'LRAT' # 新加的采油直井的控制模式选择
# [1] LRAT 液量控制
# [2] BHP 井底流压控制
指定了一个矩形范围内优化
if vertmode == 'specific_region':
# specific_region 指定优化区域,单独优化加井的井位。这种模式下直井井眼的选择范围是预先选定的一个规则矩形(需要在活网格内)
vw_new_wxlow = 1 # 新加直井的X坐标范围的下限
vw_new_wxup = 50 # 新加直井的X坐标范围的上限
vw_new_wylow = 20
vw_new_wyup = 100
新加水平井
#
hw_consmethod = 'notcons-del-relhsget' # 约束处理方法
# [1] notcons-del-relhsget 不满足约束的样本删除,并利用拉丁超立方生成
horimode = 'cooropt-Lfixed-alpopt-4'
if horimode == 'cooropt-Lfixed-alpopt-4':
#
hw_new_wxlow = 25 # 新加水平井井眼的X坐标范围的下限
hw_new_wxup = 55 # 新加水平井井眼的X坐标范围的上限
hw_new_wylow = 35
hw_new_wyup = 65
#
hw_new_wdim = 3 # 单口井的优化维数
hw_new_wL = 500 / 100 # 水平段长度
hw_new_walplow = 0.51 # 1
hw_new_walpup = 4.49 # 4
#
elif horimode == 'cooropt-Lopt-alpopt-4':
#
hw_new_wxlow = 25 # 新加水平井井眼的X坐标范围的下限
hw_new_wxup = 55 # 新加水平井井眼的X坐标范围的上限
hw_new_wylow = 35
hw_new_wyup = 65
hw_new_wdim = 4 # 单口井的优化维数
hw_new_wLlow = 251 / 100 # 3
hw_new_wLup = 549 / 100 # 5
hw_new_walplow = 0.51 # 1
hw_new_walpup = 4.49 # 4
python 报错
策略优化模式选择:优化主要分类6类
除了公共参数输入,还有各种模式的自己的参数。井的参数都随着时间步变化。
# ====================================================================
if func == 'Joint':
#
vertmode = 'None' # 直井井位优化
horimode = 'cooropt-Lfixed-alpopt-4' # 水平井井位优化
transinjmode = 'None' # 转注模式选择
sealmode = 'None' # 层位封堵模式选择
prodmode = 'None' # 注采模式选择
extramode = 'None' # 提液模式选择
#
if vertmode != 'None':
#
每种模式的变量数,注采是一起的
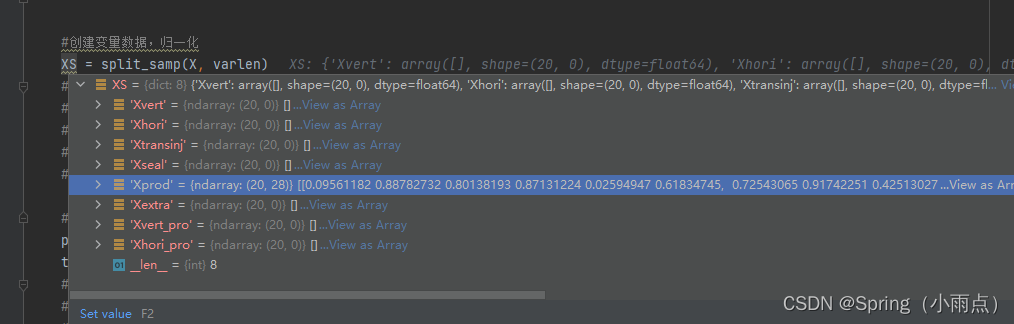
油藏参数处理:面向井对象,井单位(井位(xy上下限)、井类型(01就是上下限)、注采量(上下限)、射孔(井数总层数01上下限))+分优化模式(针对不同的井组)+是否随时间步变(井数时间步)
优化必有上下界,一个上下界确定一个变量
如果不涉及优化就给定一个固定值特殊处理,或者不操作。
一般不根据时间步优化,维数太大,调控一次即可。specific_time和这是specific的差别
目标函数,公共参数和各种模式的参数,算法
map
所有要优化的变量都是输入参数
timestep_history要历史注采量干嘛,水平井的模式,
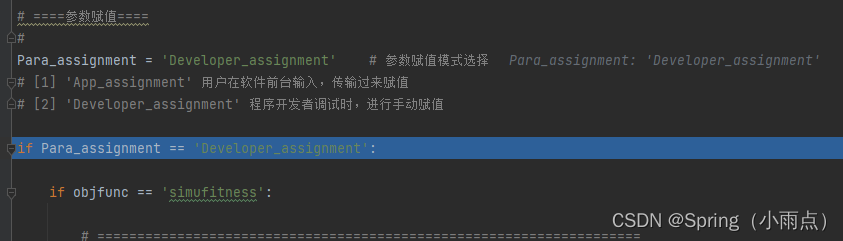
1.先选目标函数
分为模拟和函数,模拟里面有水平井,联合优化,tnavigater优化
2.选输入公共参数和各种模式的参数赋值
直井综合优化里面有油藏模型基本信息和很多模式,每个模式的输入参数不同
timestep_history = 0
well_name = [‘PRO-1’, ‘PRO-2’, ‘PRO-3’, ‘PRO-4’, ‘PRO-5’, ‘PRO-6’, ‘PRO-7’, ‘PRO-8’, ‘PRO-9’, ‘INJ-1’, ‘INJ-2’,
‘INJ-3’, ‘INJ-4’]
1是油井
initial_welltype = [1, 1, 1, 1, 1, 1, 1, 1, 1,0, 0, 0, 0]
max_layer = 1
init_status = np.ones((1, max_layer * len(well_name)))
well_group_name = [‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’, ‘G1’]
well_r = [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.5, 0.5, 0.5, 0.5]
well_location = [[1, 1], [1, 51], [1, 101], [51, 1], [51, 51], [51, 101], [101, 1], [101, 51], [101, 101],
[77, 81], [74, 18],
[23, 94], [71, 5]]
up = np.ones((len(well_name), 1)) * 1800
low = np.ones((len(well_name), 1)) * 10
up[9] = 4050
up[10] = 4050
up[11] = 4050
up[12] = 4050
# ----优化的信息----时间步变量
timestep = 10
timestep_len = 180
objmode = 'NPV'
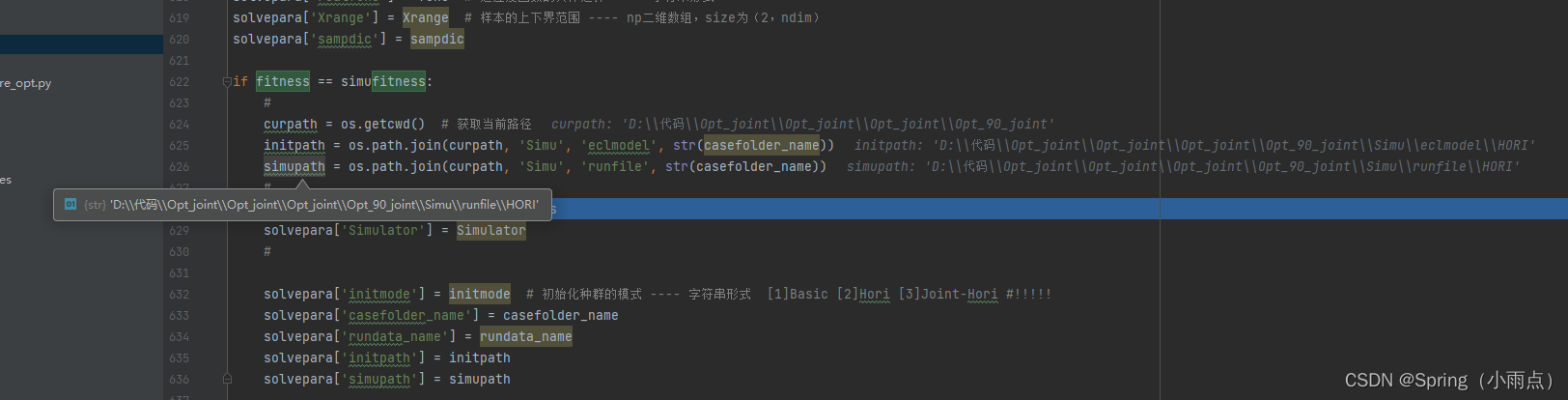
# ----路径设置有关----
casefolder_name = 'HORI'
rundata_name = 'HORI'
字典套字典Xrange
solvepara[‘realfunc’] = func # 适应度函数的具体选择 ---- 字符串形式
solvepara[‘Xrange’] = Xrange # 样本的上下界范围 ---- np二维数组,size为(2,ndim)
solvepara[‘sampdic’] = sampdic
综合优化和tnavigater优化的直井输入一样。
3.选择算法
优化变量处理 1.确定上下界2.变量归一化0-1之间的随机值 2.(上界-下界)*归一随机值
明确要优化的变量是谁
拉丁分布前处理
#上下限确定,维数长度确定
Xrange, varlen = preRan_Len(Xsampmode, sampdic)
sampdic['varlen'] = varlen
根据时间步变化和不根据时间步变化
elif prodmode == 'specific':
pro_opt_list = sampdic['pro_opt_list']
len_prod = len(pro_opt_list) * timestep
ran_prod = np.vstack([np.zeros((1, len_prod)), np.ones((1, len_prod))])
elif prodmode == 'specific_time':
specific_time = sampdic['specific_time']
len_prod = len(specific_time)
ran_prod = np.vstack([np.zeros((1, len_prod)), np.ones((1, len_prod))])
归一化
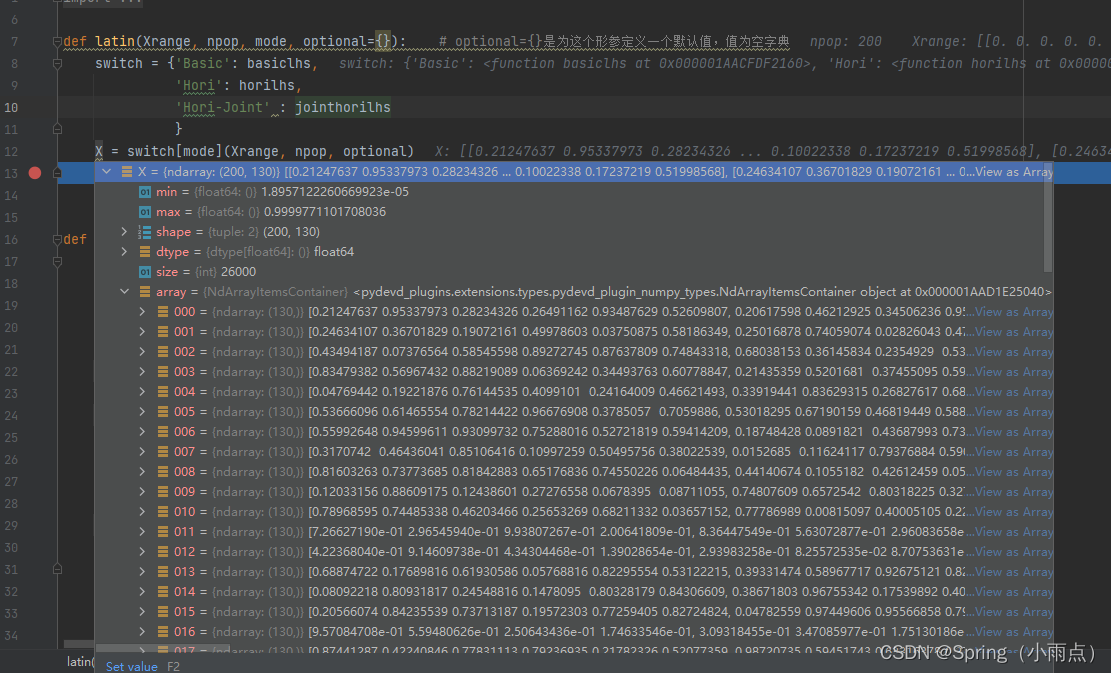
乘以上界减去下界
预计算:计算各个模式加起来的总共维度、上下限

统计各个模式加起来的总共维度
if prodmode == 'None':
len_prod = 0
ran_prod = np.zeros((2, len_prod))
elif prodmode == 'wgiven-optTgiven':
len_prod = nwell * timestep
ran_prod = np.vstack([np.zeros((1, len_prod)), np.ones((1, len_prod))])
elif prodmode == 'specific':
pro_opt_list = sampdic['pro_opt_list']
len_prod = len(pro_opt_list) * timestep
ran_prod = np.vstack([np.zeros((1, len_prod)), np.ones((1, len_prod))])
# ----提液相关----
#!!!!!!!!!!!!!!!这一部分还没写
#
varlen = {'len_vert' : len_vert,
'len_hori' : len_hori,
'len_transinj' : len_transinj,
'len_seal' : len_seal,
'len_prod' : len_prod
# 'len_extra' : len_extra
}
#
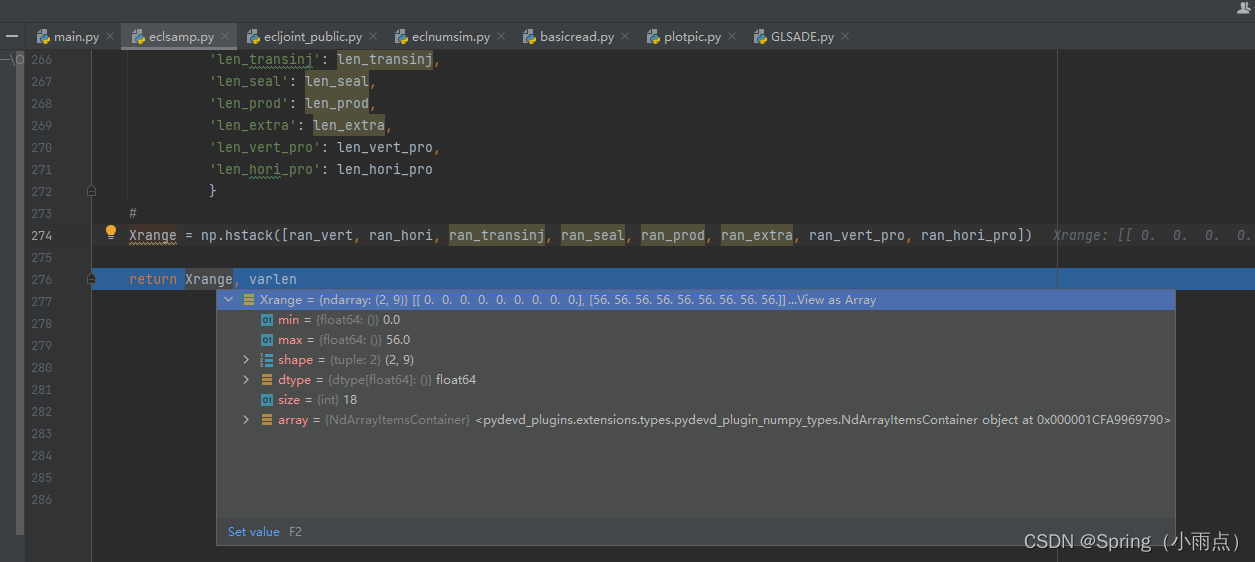
Xrange = np.hstack([ran_vert, ran_hori, ran_transinj, ran_seal, ran_prod])
# Xrange = np.hstack([ran_vert, ran_hori, ran_transinj, ran_seal, ran_prod, ran_extra])
return Xrange, varlen
#生成随机值0-1
Xrange, varlen = preRan_Len(Xsampmode, sampdic)
sampdic['varlen'] = varlen
# ----拉丁超立方初始种群模式initmode产生方式---- #!!!!!
if initialmode == 'process_needless':
initmode = 'Basic'
elif initialmode == 'process_needed':
# 如果lhs生成的初始解需要进行进一步处理(删除、重新生成等),这个时候需要根据不同的特定模式执行不同的处理操作
if horimode != 'None':
initmode = 'Joint-Hori'
# elif #!!! 【留的接口】
# 如果有其他模式(比如直井不规则的四个点判断井位区域、实际油藏活死网格不规则边界判断等),在这个接口后面加入elif,定义新的initmode,并在latin函数中增加与新定义的initmode对应的新模块
生成随机值
def wellprod_proce(X, well_type, optional):
mode = optional['Xsampmode']
sampdic = optional['sampdic']
xp = copy.deepcopy(X)
if mode['prodmode'] == 'wgiven-optTgiven':
xp = xp.reshape(-1, len(sampdic['well_name']))
for time in range(sampdic['timestep']):
for well in range(len(sampdic['well_name'])):
xp[time, well] = sampdic['low'][well] + xp[time, well] * (sampdic['up'][well] - sampdic['low'][well])
elif mode['prodmode'] == 'specific':
history_pro = sampdic['history_pro']
pro_opt_list = sampdic['pro_opt_list']
xp = xp.reshape(-1, len(sampdic['pro_opt_list']))
temp = np.ones((sampdic['timestep'], len(sampdic['well_name'])))
for time in range(sampdic['timestep']):
for well in range(len(sampdic['well_name'])):
for opt_well in range(len(pro_opt_list)):
if pro_opt_list[opt_well] == sampdic['well_name'][well]:
temp[time, well] = xp[time, opt_well]
xp = temp
for time in range(sampdic['timestep']):
for well in range(len(sampdic['well_name'])):
flag = 0
for opt_well in range(len(pro_opt_list)):
if pro_opt_list[opt_well] == sampdic['well_name'][well]:
flag = 1
break
if flag == 1:
xp[time, well] = sampdic['low'][well] + xp[time, well] * (sampdic['up'][well] - sampdic['low'][well])
else:
xp[time, well] = history_pro[well]
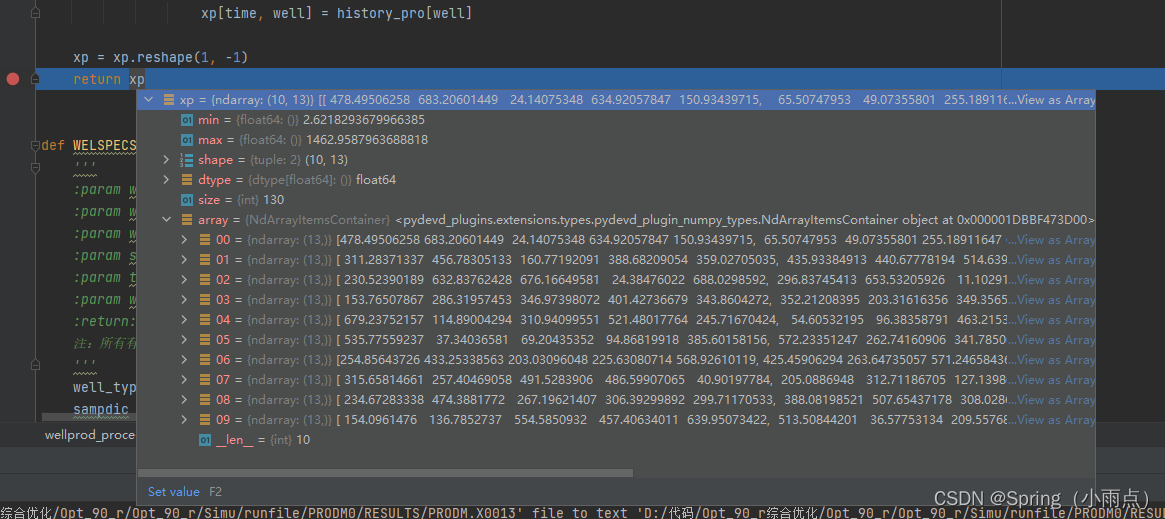
xp = xp.reshape(1, -1)
return xp
设置初始位置和优化位置,不同
在这里插入图片描述](https://img-blog.csdnimg.cn/7977d85e1b744a2db1afcb47b9518394.png)
选择算法,并行,跑单次
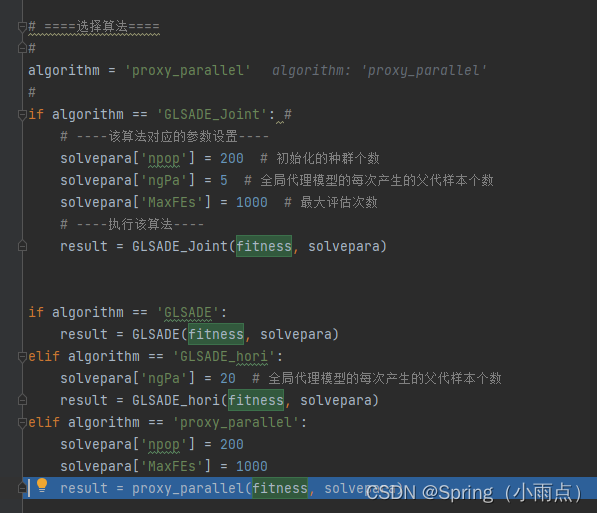
并行代码,i为并行的次序
def tnav_joint(X, optional, i, index=''):
X = latin(Xrange, npop, initmode, solvepara)
#
Y = Parallel(n_jobs=1)(delayed(ecl_joint_parallel)(X, solvepara, i, str(i % (2 * cpu_count()))) for i in range(npop))
Y = np.array(Y).reshape(-1, 1)
调用ecl_joint_parallel跑单次模拟
单次模拟:前处理 处理 后处理
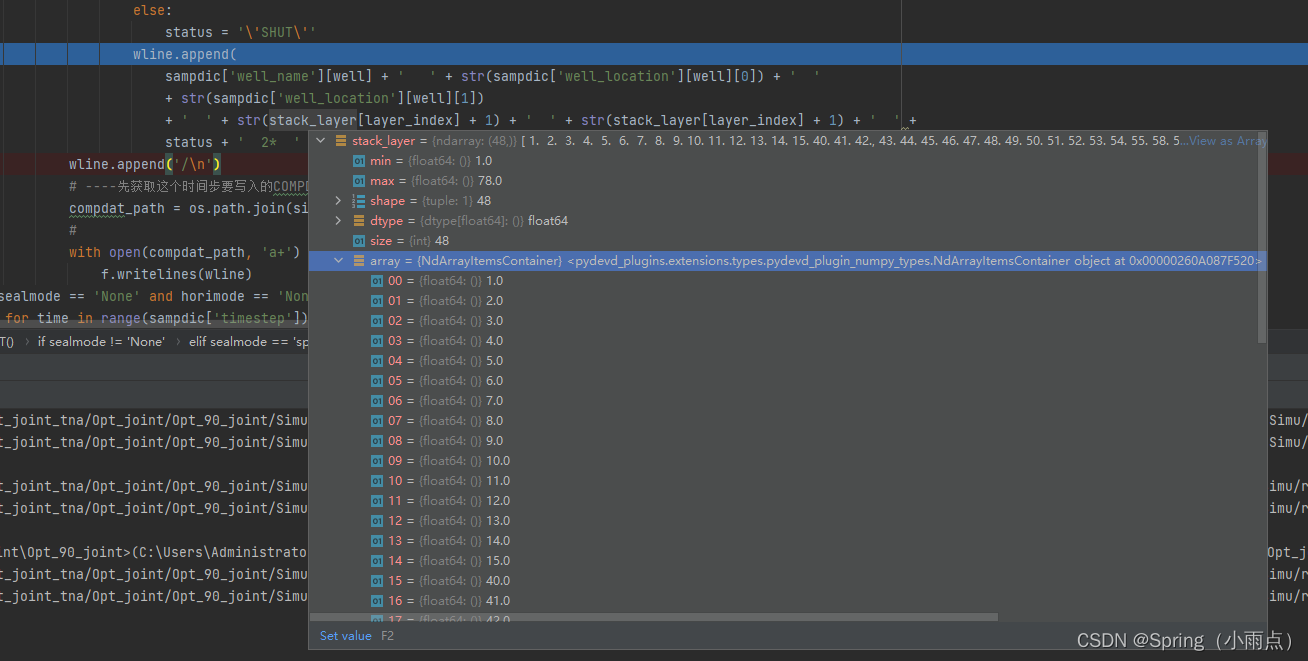
循环写入井控关键字
复制文件夹,制作xp,写入文件夹。跑data、读结果、算npv。
para = optional['sampdic']
timestep = para['timestep']
if os.path.exists(simupath): # 判断括号里的文件夹路径或文件路径是否存在,存在返回Ture,不存在返回False
rmtree(simupath) # 递归删除一个目录以及目录内的所有内容
copytree(initpath,simupath) # shutil.copytree( olddir, newdir, True/Flase) #把olddir拷贝一份newdir,如果第3个参数是True,则复制目录时将保持文件夹下的符号连接,如果第3个参数是False,则将在复制的目录下生成物理副本来替代符号连接
#
xp = {}
#
if vertmode != 'None':
xs_vert = copy.deepcopy(XS['Xvert'][i, :])
wvert = wellvert_proce(xs_vert, optional)
xp['WX_vert'] = wvert['wx_vert']
xp['WY_vert'] = wvert['wy_vert']
xp['Wstatus_vert'] = wvert['wstatus_vert']
xp['Wpro_vert'] = wvert['wpro_vert']
xp['Winj_vert'] = wvert['winj_vert']
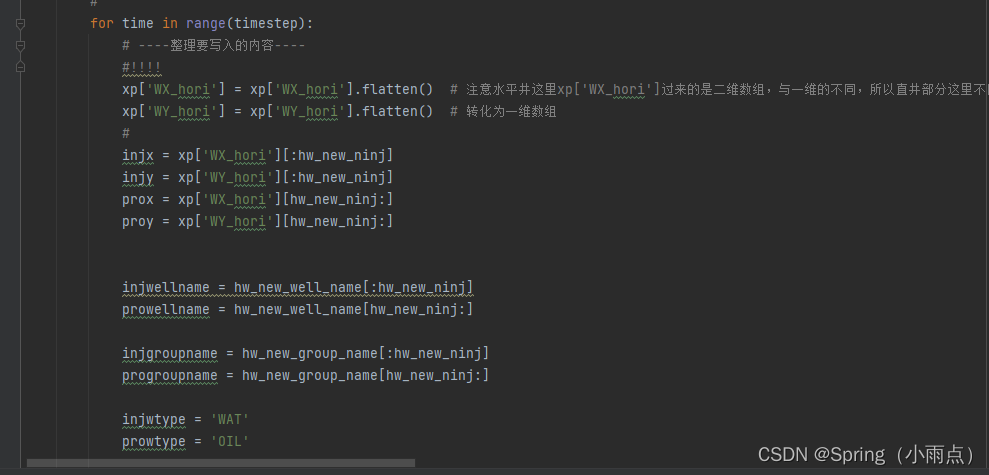
分时间步写
writeSCH(simupath, optional)
井位优化
WELSPECS(simupath, xp, optional)
层位优化(封堵)
COMPDAT(simupath, xp, optional)
转注和注采优化、提液模式
WCONINJE(simupath, xp, optional)
WCONPROD(simupath, xp, optional)
根据时间步写入每个文件sch文件
判断开始时间步是否写入,判断井类型写油水井。
每个时间步用多个循环写。
6直井井位优化模式,优化xy变量,
每个井都有个x和y位置,可随着时间步变化。
前处理,数据格式的解释,二维数组的处理(三维数组)
井类型数组是13*10,13口井和10个时间步,每个时间步的值对应好了
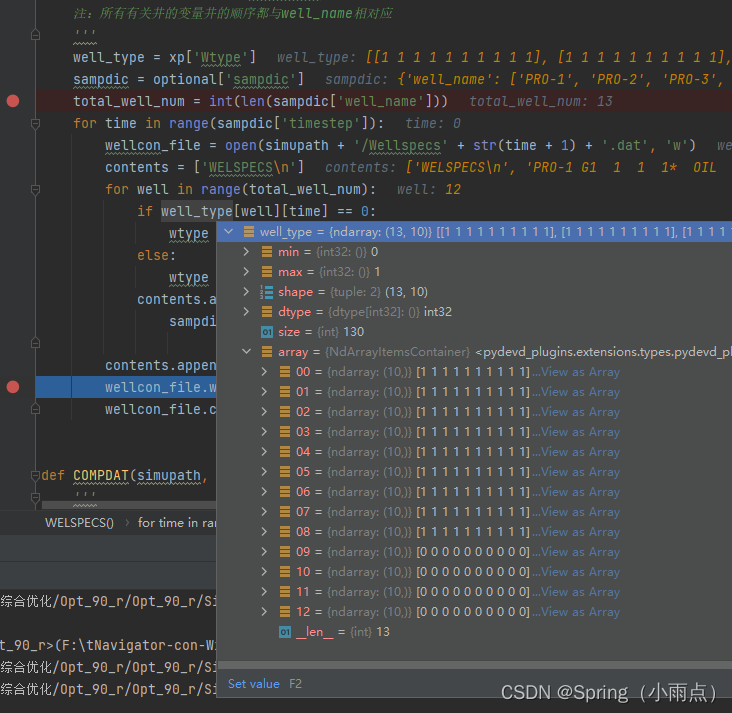
循环写入井定义文件
这是一个时间步的,井类型根据时间步变化,其他不变
只写include文件,时间步在sch文件里面写了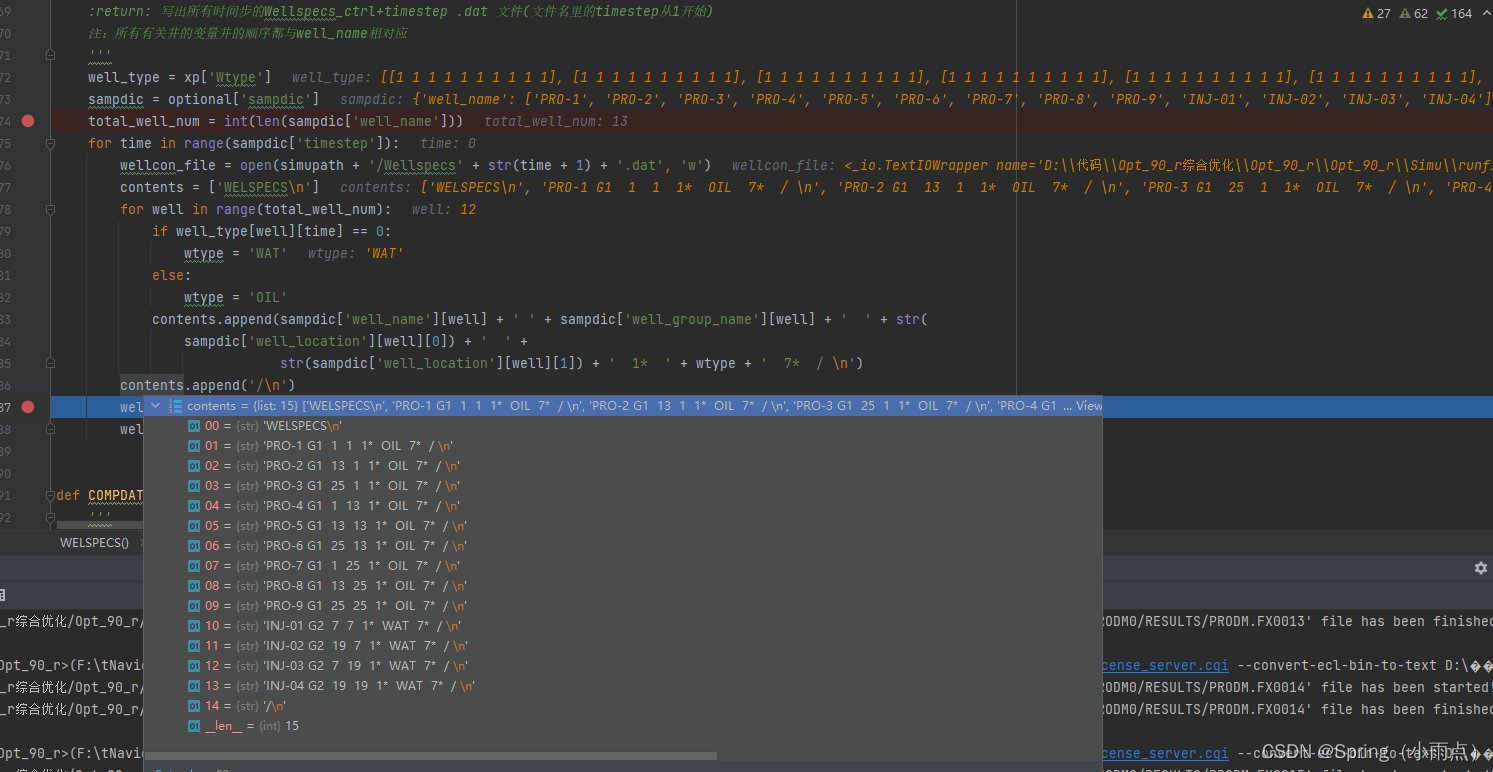
2.封堵射孔(层位优化模式原理)优化well_status变量,每个井的每一层都有个状态,随着时间步变化,也可以不变化。
前处理三重循环:时间步、井名、层数
优化well_status变量,每个井的每一层都有个状态,随着时间步变化,也可以不变化。
首先,在重启动sch中,手动把data里面写进去新得sch文件,手动改summary
层位优化模式分为两种,按照时间步优化和不按照时间步优化。
在这56个方案里面随机选择层位方案。0-56方案就是上下限。有了上下限就可以生成具体的值了(单次维数*种群数)
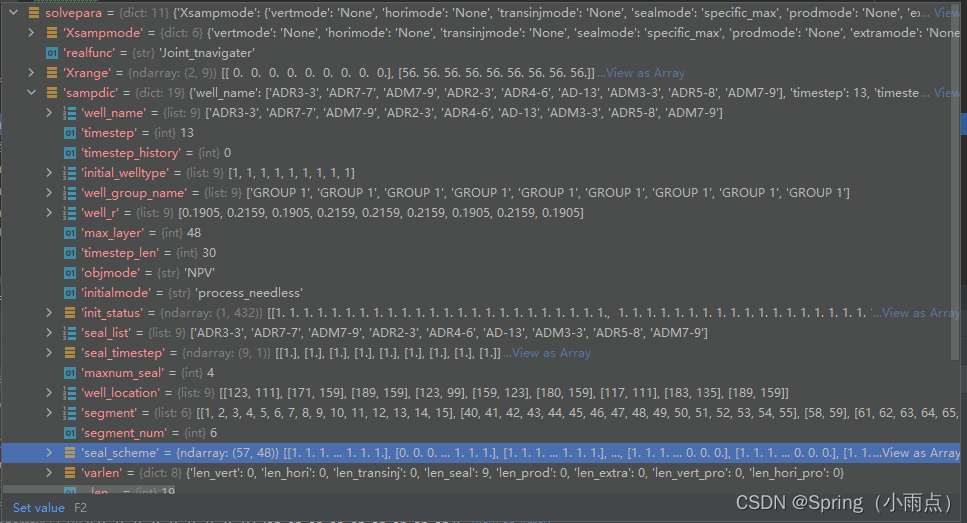
种群*井数
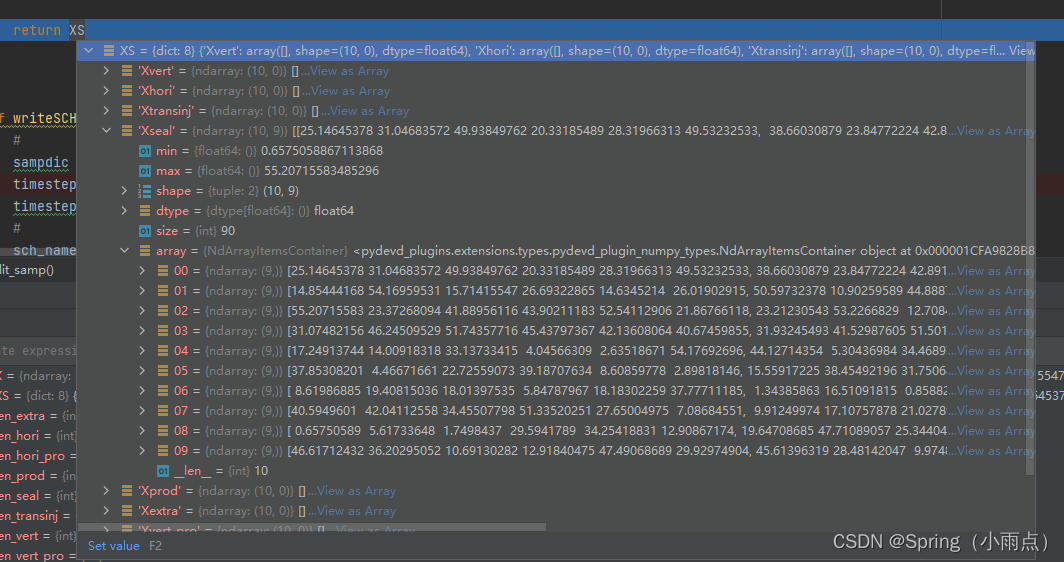
井状态
well_status井状态随着时间步变化,其他的不变
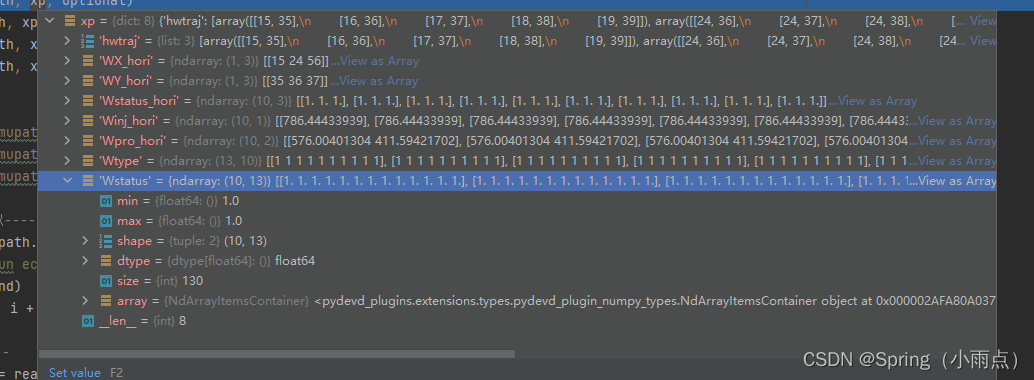
well_status = xp[‘Wstatus’] Wstatus就是选中的方案
没有层位优化则默认全打开
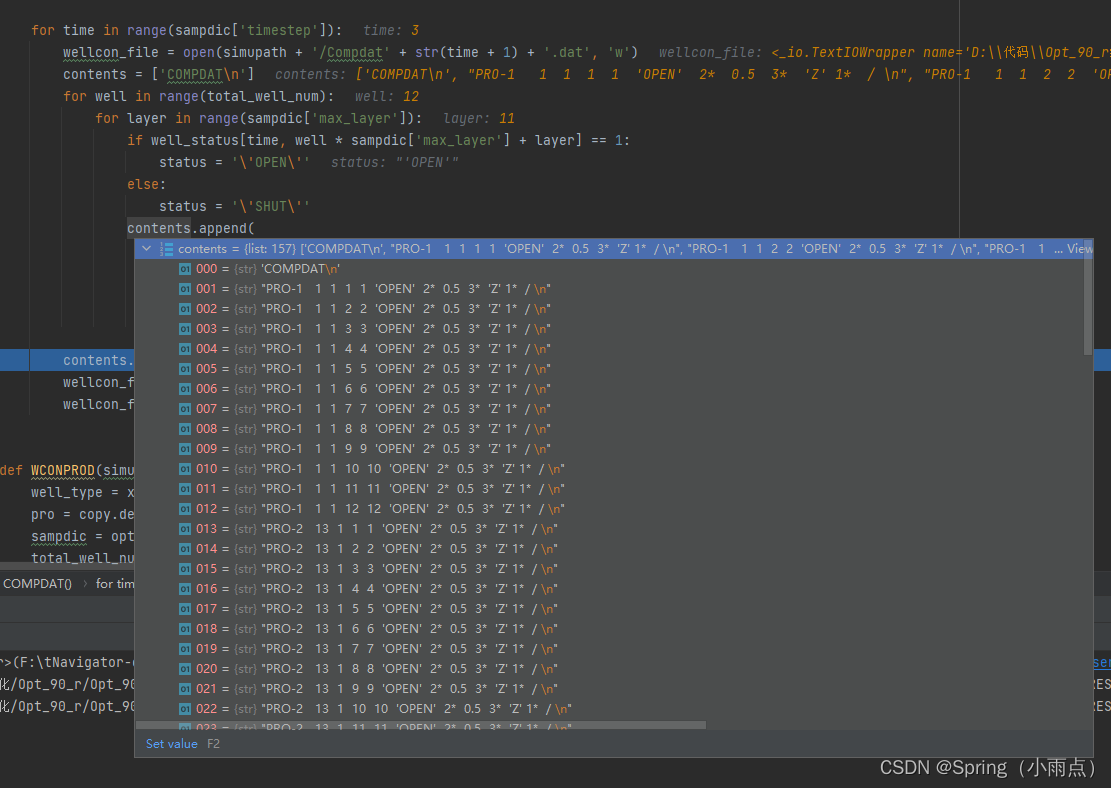
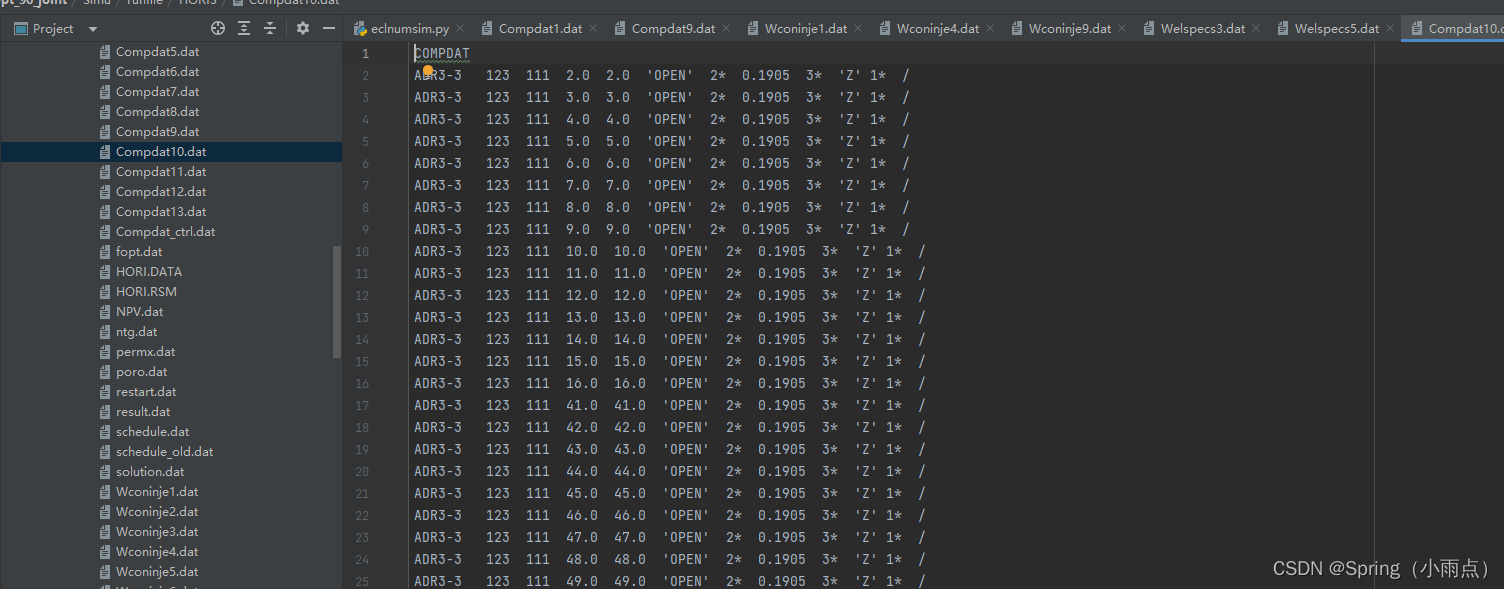
def COMPDAT(simupath, xp, optional):
'''
:param well_hor_location: numpy,
dim:井数*(最大层数*2)
第一行为:[第一个井在第一层的横坐标,第一个井在第一层的纵坐标,第一个井在第二层的横坐标,第一个井在第二层的纵坐标,....]
:param simulatuon_folder: 文件路径
:param timestep: int,
总时间步,一个数
:param well_status: numpy,
所有时间步内所有井的状态;dim:总时间步*(总井数*总层数),
要求为numpy数组!
:param well_r: numpy,
所有井的井眼直径,油井在前水井在后;dim:1*总井数
:param well_name: list,
所有井的井名,与well_status和well_r相对应
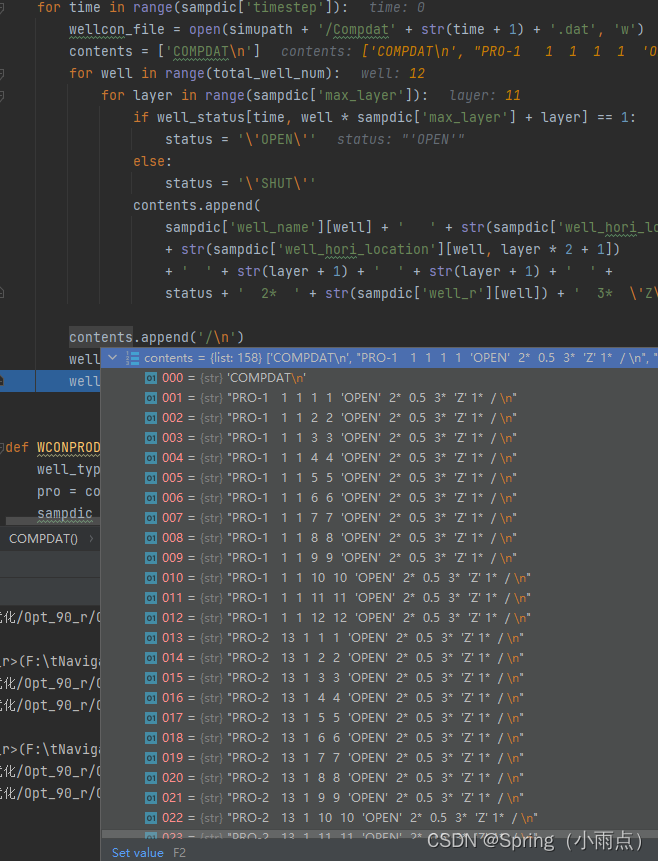
:return: 重新编写Compdat_ctrl+timestep .dat 文件(文件名里的timestep从1开始)
注:所有有关井的变量井的顺序都与well_name相对应
'''
well_status = xp['Wstatus']
sampdic = optional['sampdic']
total_well_num = len(sampdic['well_name'])
for time in range(sampdic['timestep']):
wellcon_file = open(simupath + '/Compdat' + str(time + 1) + '.dat', 'w')
contents = ['COMPDAT\n']
for well in range(total_well_num):
for layer in range(sampdic['max_layer']):
if well_status[time, well * sampdic['max_layer'] + layer] == 1:
status = '\'OPEN\''
else:
status = '\'SHUT\''
contents.append(
sampdic['well_name'][well] + ' ' + str(sampdic['well_hori_location'][well, layer * 2]) + ' '
+ str(sampdic['well_hori_location'][well, layer * 2 + 1])
+ ' ' + str(layer + 1) + ' ' + str(layer + 1) + ' ' +
status + ' 2* ' + str(sampdic['well_r'][well]) + ' 3* \'Z\' 1* / \n')
contents.append('/\n')
wellcon_file.writelines(contents)
wellcon_file.close()
井定义和注采啥都不写,按照原来的跑
只写个WCONINJE
if prodmode == 'None' and horimode == 'None' and vertmode == 'None':
for time in range(sampdic['timestep']):
iline = ['WCONINJE \n']
iline.append('/ \n')
# ----先获取这个时间步要写入的WCONPROD的地址----
wconinje_path = os.path.join(simupath, 'Wconinje' + str(time + 1) + '.dat')
#
with open(wconinje_path, 'a+') as f: # !!!!!!这里a+还是w+模式的选择
f.writelines(iline)
而射孔是按照大层分段层都写一遍
先根据层上下限随机生成数据,预处理得到01射孔矩阵
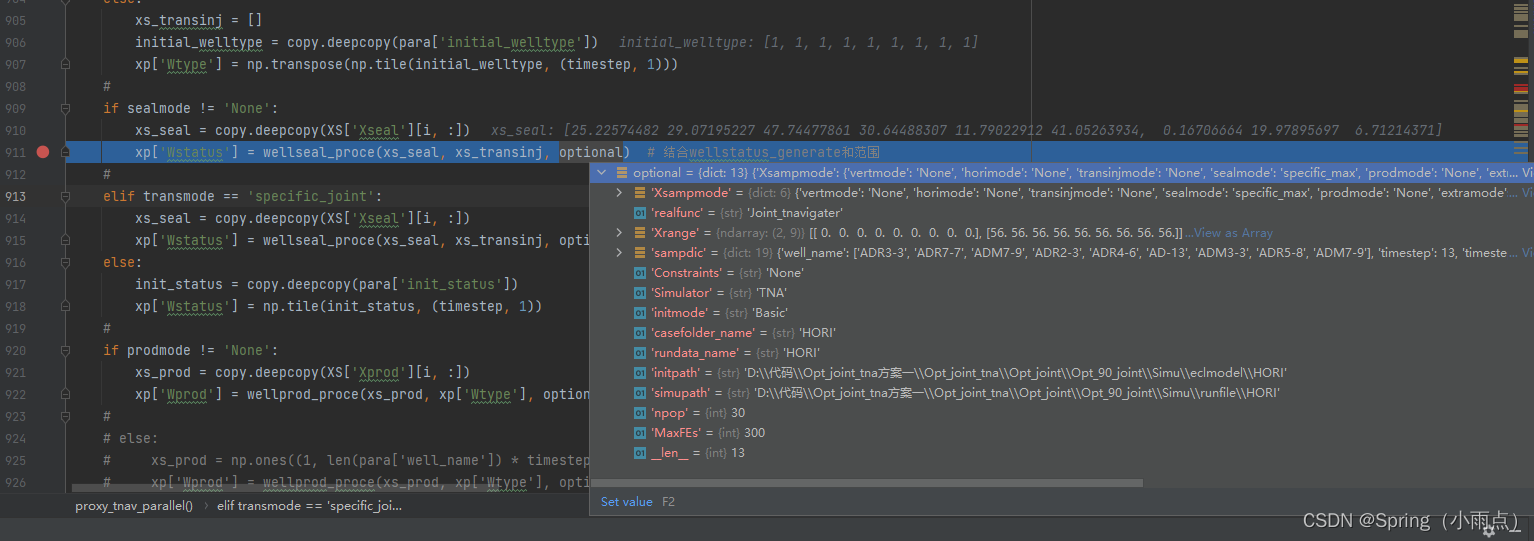
if sealmode != 'None':
xs_seal = copy.deepcopy(XS['Xseal'][i, :])
xp['Wstatus'] = wellseal_proce(xs_seal, xs_transinj, optional) # 结合wellstatus_generate和范围
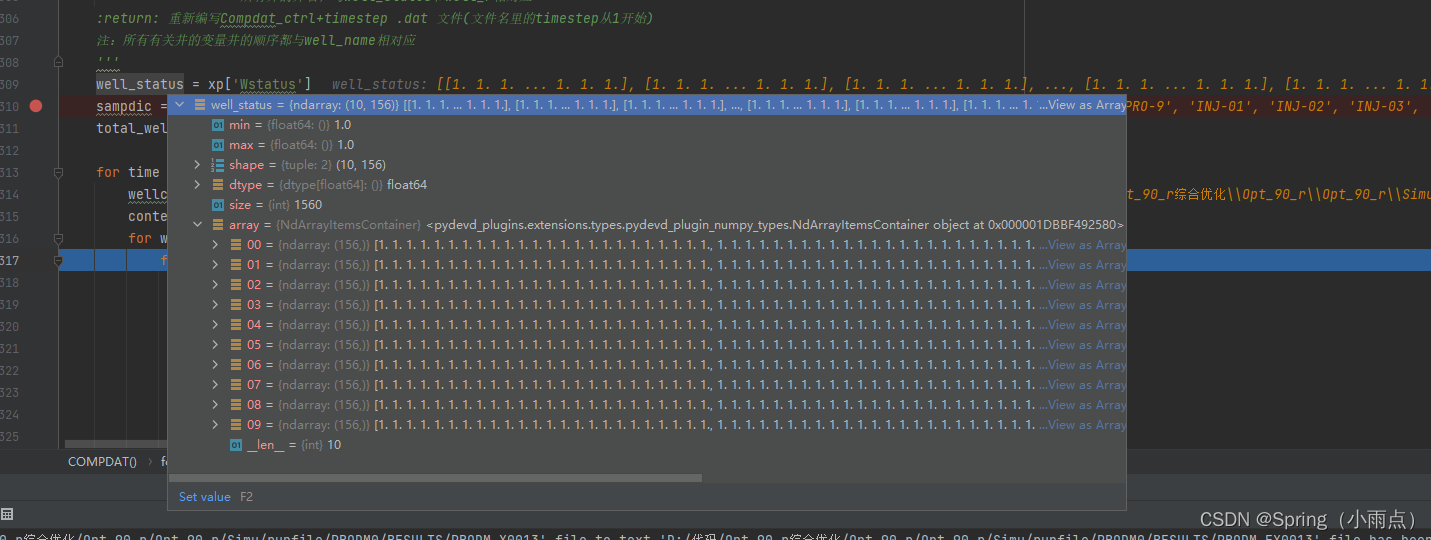
层状态wstaue表示,1是开open,10156,10是时间步,156=1312,一一对应了,这里可以写死。
init_status = np.ones((1, max_layer * len(well_name)))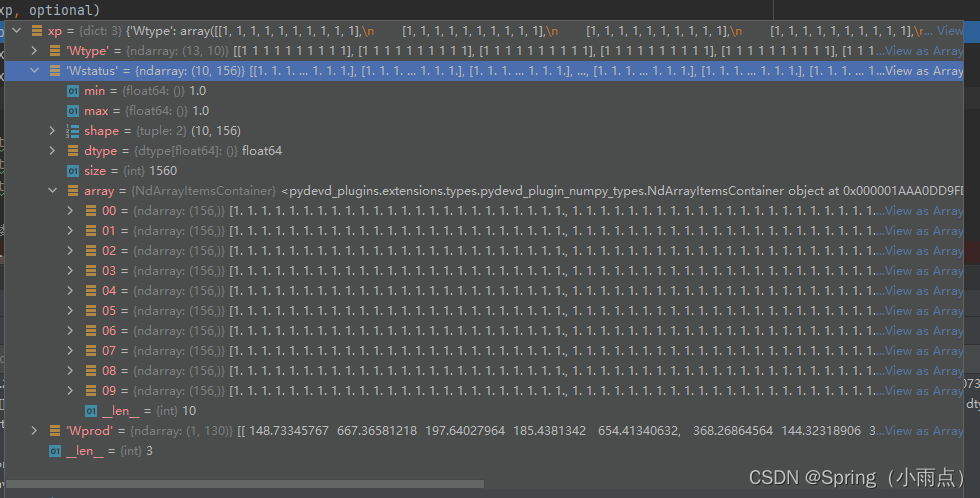
写入射孔文件中
特殊模式:不优化的写死的,27口井需要特殊处理,分别对应,每口井的关闭层和打开层。以井为研究对象。一口井就是一个对象,它的属性有处理时间步、定义、射孔、注采、井位等处理。
1水平井井位优化,xy,长度、角度,四个变量*井数的优化
水平井参数
转注(优化模式)优化注采变量,每个井都有井类型,随着时间步变化
4采油(注采优化模式)优化注采变量,每个井都有个主材量,随着时间步变化
前处理井两层循环:时间步、井名
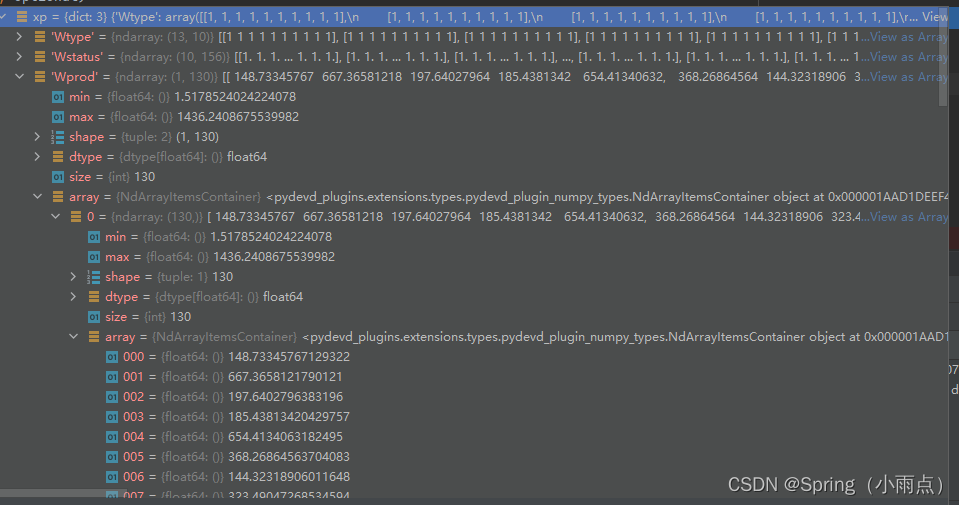
注采量Wprod维数是一维数组130=13口井*10个时间步,一一对应了。关键是上下界。
# ----注采相关----
if prodmode == 'None':
len_prod = 0
ran_prod = np.zeros((2, len_prod))
elif prodmode == 'wgiven-optTgiven':
len_prod = nwell * timestep
ran_prod = np.vstack([np.zeros((1, len_prod)), np.ones((1, len_prod))])
把各个模式的变量合在一起,先确定上下界。
varlen = {'len_vert' : len_vert,
'len_hori' : len_hori,
'len_transinj' : len_transinj,
'len_seal' : len_seal,
'len_prod' : len_prod
# 'len_extra' : len_extra
}
#
Xrange = np.hstack([ran_vert, ran_hori, ran_transinj, ran_seal, ran_prod])
# Xrange = np.hstack([ran_vert, ran_hori, ran_transinj, ran_seal, ran_prod, ran_extra])
return Xrange, varlen
根据上下界生产随机值wellprod_proce
def wellprod_proce(X, well_type, optional):
mode = optional['Xsampmode']
sampdic = optional['sampdic']
xp = copy.deepcopy(X)
if mode['prodmode'] == 'wgiven-optTgiven':
xp = xp.reshape(-1, len(sampdic['well_name']))
for time in range(sampdic['timestep']):
for well in range(len(sampdic['well_name'])):
xp[time, well] = sampdic['low'][well] + xp[time, well] * (sampdic['up'][well] - sampdic['low'][well])
只对特定井名进行优化
elif mode['prodmode'] == 'specific':
history_pro = sampdic['history_pro']
pro_opt_list = sampdic['pro_opt_list']
xp = xp.reshape(-1, len(sampdic['pro_opt_list']))
temp = np.ones((sampdic['timestep'], len(sampdic['well_name'])))
for time in range(sampdic['timestep']):
for well in range(len(sampdic['well_name'])):
for opt_well in range(len(pro_opt_list)):
if pro_opt_list[opt_well] == sampdic['well_name'][well]:
temp[time, well] = xp[time, opt_well]
xp = temp
for time in range(sampdic['timestep']):
for well in range(len(sampdic['well_name'])):
flag = 0
for opt_well in range(len(pro_opt_list)):
if pro_opt_list[opt_well] == sampdic['well_name'][well]:
flag = 1
break
if flag == 1:
xp[time, well] = sampdic['low'][well] + xp[time, well] * (sampdic['up'][well] - sampdic['low'][well])
else:
xp[time, well] = history_pro[well]
返回随机值=10时间步*井数
如果井类型是1油井
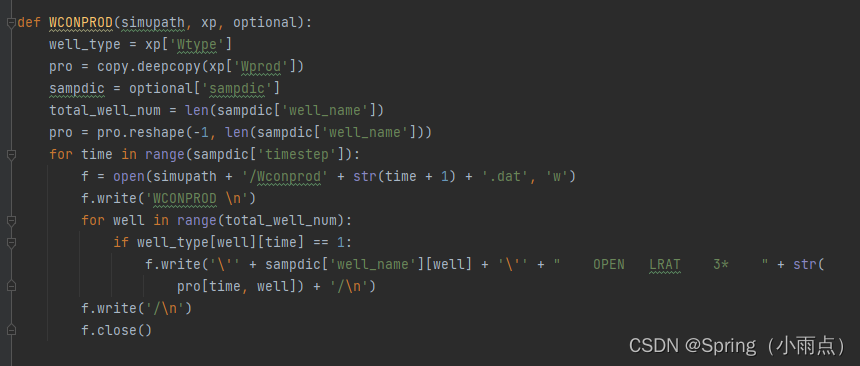
def WCONPROD(simupath, xp, optional):
well_type = xp['Wtype']
pro = copy.deepcopy(xp['Wprod'])
sampdic = optional['sampdic']
total_well_num = len(sampdic['well_name'])
pro = pro.reshape(-1, len(sampdic['well_name']))
for time in range(sampdic['timestep']):
f = open(simupath + '/Wconprod' + str(time + 1) + '.dat', 'w')
f.write('WCONPROD \n')
for well in range(total_well_num):
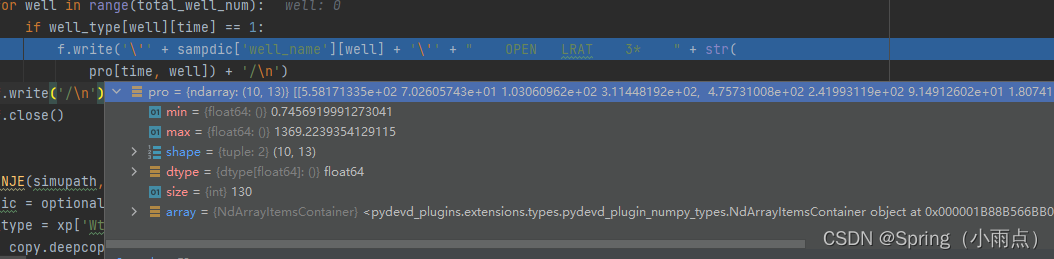
如果井类型是1油井
if well_type[well][time] == 1:
f.write('\'' + sampdic['well_name'][well] + '\'' + " OPEN LRAT 3* " + str(
pro[time, well]) + '/\n')
f.write('/\n')
f.close()
如果井类型是0水井
def WCONINJE(simupath, xp, optional):
sampdic = optional['sampdic']
well_type = xp['Wtype']
pro = copy.deepcopy(xp['Wprod'])
total_well_num = len(sampdic['well_name'])
pro = pro.reshape(-1, len(sampdic['well_name']))
for time in range(sampdic['timestep']):
f = open(simupath + '/Wconinj' + str(time + 1) + '.dat', 'w')
f.write('WCONINJE \n')
for well in range(total_well_num):
如果井类型是0水井
if well_type[well][time] == 0:
f.write('\'' + sampdic['well_name'][well] + '\'' + " WATER OPEN RATE " + str(
pro[time, well]) + '/\n')
f.write('/\n')
f.close()
数值模拟,换模拟器,要有模拟器位置。模拟器限制很多
tnavigater不一样就把他定死summary顺序。
最新破解版关键字必须有
MULTOUT它
RPTRST
‘BASIC=3’ ‘FREQ=1’ /
SUMMARY =============================================================
EXCEL
FWPR
FOPR
FWCT
FWIR
FOPT
FWPT
FWIT
FPR
/
# ----进行数值模拟----
DATA_path = os.path.join(simupath, rundata_name + '.DATA')
command = 'eclrun eclipse' + ' ' + DATA_path
os.system(command)
print('数值评估', i + 1, '次')
# ----读取结果----
output, outnum = read_sumkeywd(DATA_path) # 读取DATA文件SUMMARY部分关键字
SCH_path = fullfile(simupath, 'schedule.dat')
# steps = get_schsteps(SCH_path) # 查找schedule文件中的时间步数
'''
steps = para['timestep'] + para['history_timestep']
'''
#
# timestep_n = 30
# timesteplen = sampdic['timestep_len']
# tn = int(timesteplen/timestep_n)
# steps = para['timestep']*tn + para['history_timestep']
#
steps = para['timestep'] + para['timestep_history']
A_path = find_A(simupath, rundata_name, steps) # 确定要读取的结果的文件名称(A文件)
# 在确定的A文件中读取出相关结果(有两种思路,一种是和DATA文件读出类似,先全部读出来再查找和抽取,一种是利用指针,利用A文件特点,需要的结果在最后几行,直接指针到最后几行)
with open(A_path, 'rb') as f: # 要用seek()方法需要用二进制的读,所以用’rb‘而不是’r‘
outnum = outnum + 2 # 在A文件输出的关键字数目加2(前面还有天和年两个关键字)
# 计算需要将指针向前移动的字符距离
movecha = (outnum // 4) * (17 * 4 + 2) + (
outnum % 4) * 17 + 2 # //是取整符号,%是取余符号,计算的数目是根据A文件中每个SUMMARY关键字输出结果所占的字符数
f.seek(-movecha, 2) # seek(offset, whence),offset是文件指针偏移量,whence为0是文件开头,1是文件当前位置,2是文件末尾
outext = f.read().decode().split() # 二进制形式read()出来需要用decode()进行解码,并用split()进行分开
del outext[0:2] # 删去前两个元素(不是SUMMARY中规定的关键字结果)
outnum = outnum - 2 # 删去前两个元素的数量
for j in range(outnum):
order = output[j] + ' = ' + str(float(outext[j])) # 把结果用order命令逐个写入,并用exec运行
exec(order, globals()) # exec()函数的作用域问题,在自己定义的子函数里面使用exec()去define一个变量,后续再使用时会报错,需要加入globals()
#
objmode = para['objmode']
if objmode == 'FOPT':
SimRes[i] = FOPT
elif objmode == 'NPV':
#
oil_price = 100 # 油价(默认单位为美元/桶)
cost_prowat = 42 # 处理水成本(默认单位为美元/桶)
cost_injwat = 2 # 注水成本(默认单位为美元/桶)
#
units = 'METRIC' # Eclipse模型的单位进制
if units == 'FIELD':
npv = FOPT * oil_price - FWPT * cost_prowat - FWIT * cost_injwat
三种调用方式
conexe = "F:\\tNavigator-con-Win-64\\tNavigator-con-Win-64\\tNavigator-con.exe"
config = "F:\\tNavigator-con-Win-64\\tNavigator-con-Win-64\\license.conf"
conexe_sever = "C:\\Users\\Administrator\\AppData\\Local\\RFD\\tNavigator\\22.3\\tNavigator-con"
config_sever = 'http://103.90.189.57:5805/tnav_cgi1/tnav_license_server.cgi'
读取结果、历史时间步是为了读取到当前最后一个时间步
历史时间步是old里的时间步
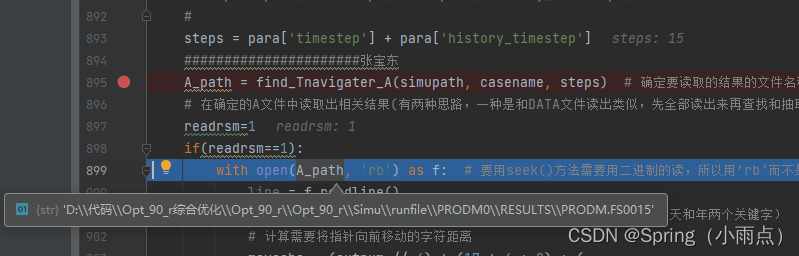
bug
mpi并行环境安装
算法
自适应代理
针对维度和问题鲁棒性的
多代理的组合混合,但是会选择
并行变异
两种思路可以结合:
1.利用DE和代理模型并行产生多种x结果,再从x中选择几个进行并行跑。
2.并行多代理(多代理不组合,各跑各的),同时采用多种代理模型,全局和局部、截断学习,等等。