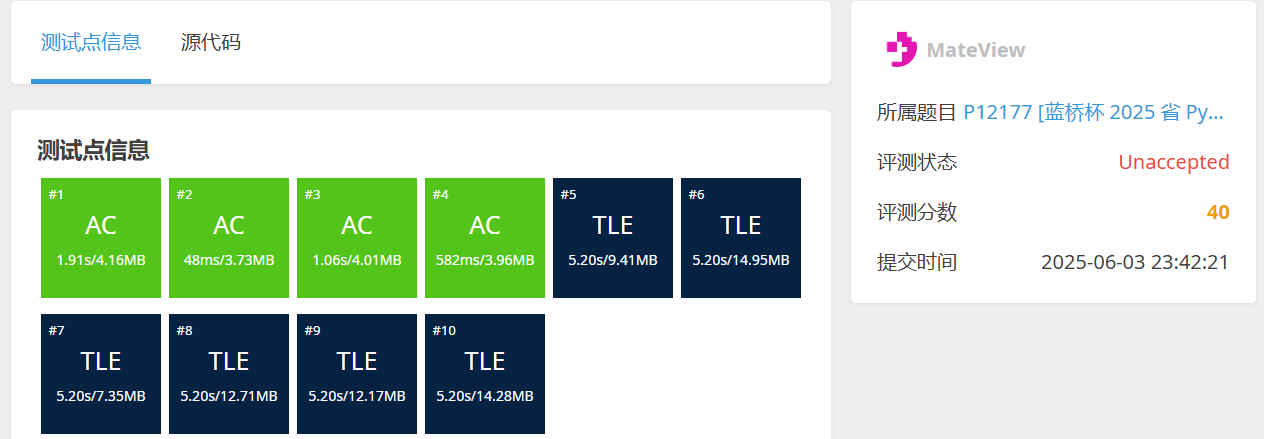
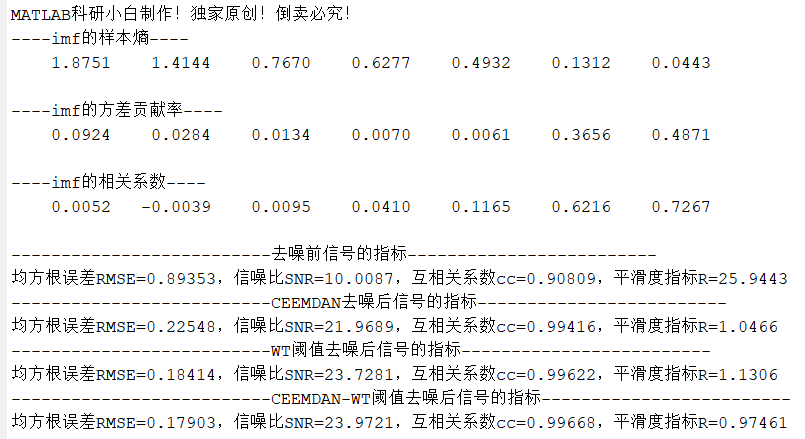
RetroMAE 预训练任务的具体步骤,围绕 编码(Encoding)、解码(Decoding)、增强解码(Enhanced decoding) 三个核心阶段展开,以下结合图中流程拆解:
一、阶段 A:编码(Encoding)
目标:对输入文本做适度掩码,生成句子级语义嵌入(用于后续重建依据)。
步骤:
- 输入处理:原始文本序列(如 [CLS],x1,x2,[M],x4 )中,按一定比例(“适度掩码”,如 15% - 30% )替换部分 token 为掩码标记 [M],得到掩码后序列 Xenc。
- 编码器编码:将 Xenc 输入 Transformer 编码器(Encoder),输出包含全局语义的句子嵌入 hX(绿色矩形,通常用 位置的隐向量表示 ),同时保留可见 token(如 x3 )的局部语义用于后续任务(如 MLM 辅助学习 )。
二、阶段 B:解码(Decoding)
目标:对输入文本做激进掩码,结合编码阶段的句子嵌入,重建掩码 token,强化模型语义理解。
步骤:
- 深度掩码输入:对原始文本序列做更 “激进” 的掩码(如 50% - 70% 比例),得到新的掩码序列(如 [x1,[M],x3,[M]] ),并拼接编码阶段的句子嵌入(绿色矩形),形成解码输入 HXdec。
- 解码器重建:将 HXdec 输入单层 Transformer 解码器(结构简化,聚焦重建),通过掩码语言建模(MLM)任务,学习从句子嵌入和少量可见 token(如 x1,x3 )中恢复原始掩码 token(如 x2,x4 ),迫使模型理解语义关联。
三、阶段 C:增强解码(Enhanced decoding)
目标:基于句子嵌入和每行可见上下文,对所有输入 token 做精细化重建,进一步挖掘语义依赖。
步骤:
- 构建注意力掩码矩阵:定义特殊的注意力掩码规则(Eq. 7 描述):
- 主对角线位置填充 −∞(灰色):表示 token 无法 “看到自己”(避免自依赖,强制模型从上下文学习 );
- 可见上下文位置填充 0(蓝色):允许 token 基于这些位置的语义做重建。
- 全局语义重建:输入完整 token 序列(如 x1,x2,x3,x4 ),结合编码阶段的句子嵌入(绿色矩形),通过 Transformer 结构和上述注意力掩码,让每个 token 依据独特的可见上下文重建自身(如 x1 参考 x2/x3/x4 语义,x2 参考 x1/x3/x4 等 ),强化模型对全局语义和局部依赖的捕捉能力。
核心逻辑总结
RetroMAE 通过 “适度编码生成语义底座 → 激进解码强化语义关联 → 增强解码细化语义依赖” 的三阶段流程,让模型在预训练中:
- 先学会提炼文本全局语义(编码阶段 );
- 再强制从极少信息中恢复内容(解码阶段,提升语义推理 );
- 最后精细化学习 token 间复杂依赖(增强解码阶段 )。
最终目标是让模型生成更优质的文本表示,尤其适配检索任务(如 dense retrieval ),为下游应用(如文本向量检索、问答系统 )打牢预训练基础。
形象的举个例子
咱们用 **“修复破损的故事书”** 来类比 RetroMAE 的预训练流程,把文本理解成故事书的内容,token 是书中的文字 / 段落,模型是 “修复师”,帮你直观看懂三阶段逻辑:
阶段 A:编码(Encoding)—— 提取故事 “核心大纲”
-
场景:你拿到一本缺了几页(适度掩码) 的旧故事书(原始文本),比如《小红帽》里 “小红帽遇到狼” 的段落被挖掉几句(掩码 token),变成:
小红帽带着 [M] ,走在 [M] 的路上,遇到了 [M] ……
-
模型操作:
修复师(编码器)快速翻书,跳过挖掉的部分,先总结出故事的核心大纲(句子嵌入,绿色矩形):“一个女孩带东西去外婆家,路上遇到危险角色” 。
同时,记住书里没被挖掉的关键句子(如 “小红帽”“路” ),辅助理解故事背景。
阶段 B:解码(Decoding)—— 用大纲猜 “挖掉的内容”
-
场景:现在修复师拿到一本被挖掉大半内容(激进掩码) 的书,比如《小红帽》只剩:
小红帽 [M] ,[M] 外婆 [M] ……
-
模型操作:
修复师拿着阶段 A 总结的核心大纲(“女孩带东西去外婆家遇危险” ),结合仅存的只言片语(如 “小红帽”“外婆” ),开始猜挖掉的内容:- 第一处 [M] 可能是 “带着蛋糕”(因为去外婆家常带食物 );
- 第二处 [M] 可能是 “去”(逻辑补全动作 );
- 第三处 [M] 可能是 “家”(补全 “外婆家” )。
这个过程就是用大纲(句子嵌入) + 少量残留文字(可见 token),重建大量缺失内容(掩码 token),强迫修复师(模型)理解 “小红帽→外婆家→带东西” 的语义关联。
阶段 C:增强解码(Enhanced decoding)—— 精细修复每一句话
-
场景:现在有一本完整但 “每句话都被做了特殊标记” 的书(所有 token 都要重建),规则是:
- 每句话里,不能参考自己的文字(主对角线填 −∞,灰色,比如 “小红帽” 这句话,不能直接用 “小红帽” 三个字猜,得看上下文 );
- 只能参考其他句子的信息(可见上下文填 0,蓝色,比如用 “路很长”“太阳很晒” 猜 “小红帽走得很慢” )。
-
模型操作:
修复师需要逐句修复,但每修一句话时,不能用这句话自己的词,必须看其他句子的内容推理:- 修 “小红帽带着蛋糕” 时,得参考 “路很远”→ 推测 “蛋糕用篮子装”(因为路远需要容器 );
- 修 “狼很狡猾” 时,得参考 “小红帽天真”→ 推测 “狼假装成外婆”(因为角色性格对比 )。
这个过程就是让模型学习句子间的深层依赖,比如 “人物性格→行为逻辑”“场景描述→物品细节” 的关联,最终精细修复整个故事(重建所有 token )。
类比总结:RetroMAE 预训练像 “分阶段修复故事书”
- 编码(A):先抓故事核心(全局语义),记住关键碎片(可见 token );
- 解码(B):用核心 + 碎片,猜大量缺失内容(强化语义推理 );
- 增强解码(C):精细修复每处细节,但强制参考其他部分(学习复杂依赖 )。
最终,模型(修复师)学会了 “从全局到局部、从碎片到完整” 理解文本的能力,预训练完成后,就能更好处理检索任务(比如找 “小红帽遇狼” 相关的故事片段 ),或者文本生成(比如续写故事 )啦~