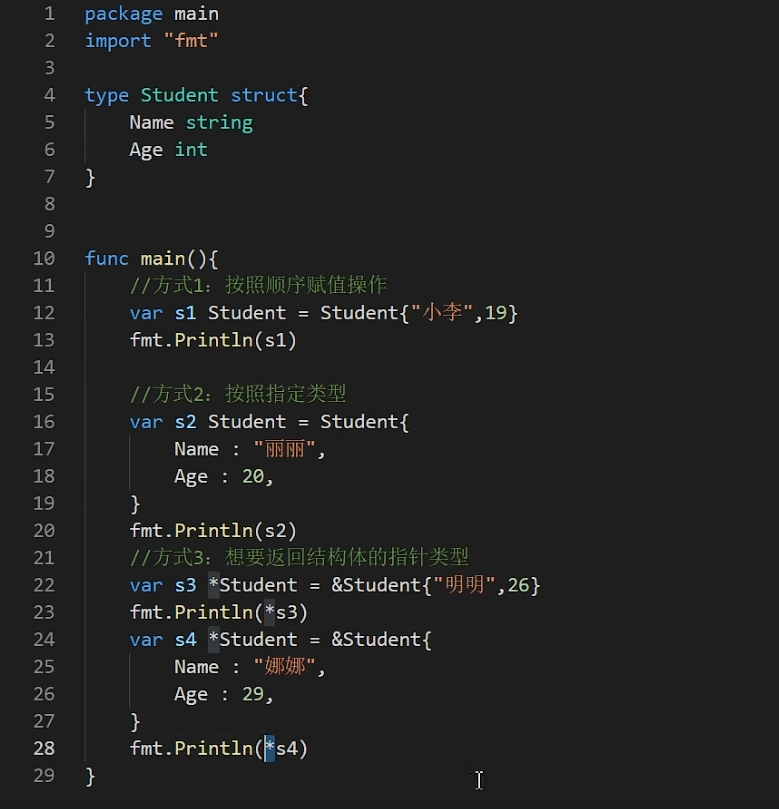
Embedding (模型嵌入)是 AI 领域的一个核心概念
一、Embedding(嵌入)的含义
Embedding 是一种将
非结构化数据(如文本、图像、音频、视频)转换为
数值向量的技术。
其核心是通过
嵌入模型(Embedding Model)将数据的语义信息转化为高维空间中的点,使得:
- 语义相似的物体在向量空间中距离相近(如"狗"和"犬",猫和老虎这样的向量接近)。
- 语义不同的物体在向量空间中距离较远(如"汽车"和"苹果"的向量远离)。
关键点:
- 向量化表示:原始数据(如一段文字) → 固定长度的数值数组(现在已经支持1024维向量)。
- 保留语义:转换后的向量能反映数据的内在含义(如近义词、相似主题的文本向量相似)。
- 非直接搜索:解决传统关键词搜索无法捕捉语义的问题(例如搜索"自动驾驶车辆"也能匹配到"无人驾驶汽车")。
例如Qwen3-Embedding 系列模型(Embedding 及 Reranker),专为文本表征、检索与排序任务设计,基于 Qwen3 基础模型进行训练。
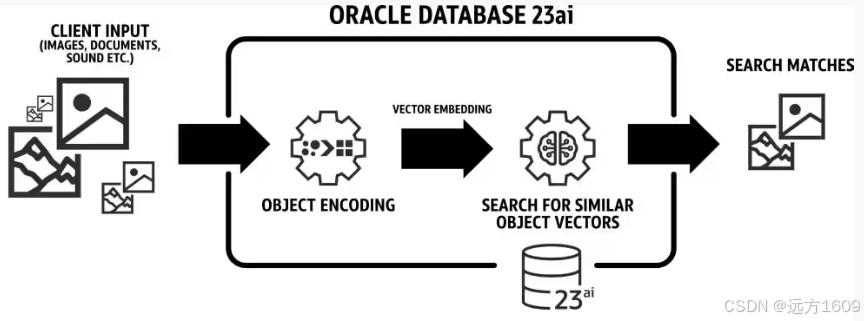
二、Oracle AI Vector Search Embedding 的使用途径
在 Oracle AI Vector Search 中,Embedding 主要服务于以下场景:
1. 相似性搜索(Similarity Search)
- 原理:将用户查询(如自然语言问题)通过嵌入模型转换为向量,并在数据库中搜索与之最接近的向量。
- 应用场景:
- 文档语义搜索(输入问题 → 匹配相关文档)
- 图像/视频内容检索(输入描述 → 匹配相似媒体)
- 推荐系统(根据用户行为向量推荐相似商品)
- 欺诈检测(识别异常模式向量)
2. 检索增强生成(RAG, Retrieval-Augmented Generation)
- 工作流程:
- 生成Embedding:将用户提问(如"公司Q3财报亮点?")转换为向量。
- 相似性搜索:在私有业务数据中查找相关向量(如存储的财报文档向量)。
- 增强LLM提示:将匹配结果作为上下文输入给大语言模型(如GPT)。
- 生成精准回答:LLM基于业务数据生成准确回复,减少"幻觉"。
- 价值:
- 无需重新训练LLM即可利用私有数据(比如企业内部的作业指导书、企业合同、客服、质量追溯记录)。
- 提升聊天ROBOT、智能问答系统的准确性,Agent回答的准确度。
3. 多模态数据融合
- 支持将文本、图像、JSON等异构数据统一转换为向量,在单一数据库中执行跨模态搜索(如用文字搜索图片)。
三、Oracle AI Vector Search 中 Embedding 的实现方式
- 向量生成:
- 使用开源或商业嵌入模型(如BERT、CLIP)生成向量。支持第三方
- 支持通过 ONNX 框架导入自定义模型。
- 可在数据库内生成向量,或直接导入外部生成的向量。
- 向量存储:
- 使用新增的 VECTOR 数据类型在 Oracle Database 23ai 中存储向量。
- 向量与业务数据共存储,确保数据变更时向量同步更新。
- 向量索引与查询:
- 高效索引:使用内存图索引(如HNSW)或分区索引加速搜索。
- SQL 扩展:通过 VECTOR_DISTANCE() 等函数直接执行相似性查询。
- 精度控制:允许指定目标搜索精度(如召回率95%),而非手动调参。
- GPU 加速:利用 GPU 加速向量生成和索引构建(如处理大规模图像/视频嵌入)。
四、Oracle Embedding 的核心特性
1. 原生向量存储与处理
- VECTOR 数据类型:Oracle Database 23ai 新增原生数据类型,直接存储高维向量(如1024维)。
- 优势:无需额外数据库或中间件,与企业业务数据(关系表、JSON、空间数据)统一存储。
- 支持动态更新:业务数据变更时,关联向量自动同步(如文档内容修改后重新生成向量)。
- 维度灵活性:支持不同维数的向量(如文本向量512维、图像向量2048维),适应多模态场。
2. 向量生成自由度高
双路径支持:
- 库内生成:在数据库中直接调用嵌入模型生成向量(需导入ONNX模型)。
- 外部导入:允许从第三方工具(如Python训练脚本)生成向量后导入。
- 模型无关性:支持任意嵌入模型(开源如BERT、CLIP或商业私有模型),无和厂商绑定。
3. 企业级性能优化
- GPU 加速:利用 GPU 加速向量生成(如大规模文本/图像嵌入)和索引构建。
- 用例:处理百万级参数的医疗影像PACS数据的嵌入生成时间从小时级降至分钟级。
- Exadata 专属优化:Exadata 24ai 的软硬件协同优化向量搜索,索引创建速度提升10倍+,高净值用户独享。
4. 精准控制与易用性
- 目标精度导向:创建索引时直接指定目标召回率(如 ACCURACY 95%),而非手动调整HNSW参数。
- 价值:开发者无需理解底层索引算法,降低使用门槛。
- SQL 原生扩展:通过新增SQL函数(如 VECTOR_DISTANCE())执行相似性搜索,与业务查询无缝融合。
- 示例:
-
SELECT doc_id, content FROM documents ORDER BY VECTOR_DISTANCE(embedding, :query_vector) FETCH FIRST 10 ROWS ONLY; -- 返回最相似的10个文档五、Oracle ONNX基本概念
4.1 ONNX(Open Neural Network Exchange)
- ONNX是Open Neural Network Exchange的缩写,即开放神经网络交换。
- ONNX是一种用于存储和交换机器学习模型的开放标准格式,旨在实现不同深度学习框架(如PyTorch、TensorFlow、MXNet等)之间的互操作性。
- ONNX的主要功能和用途是使得AI模型可以在不同的框架和环境下交互使用,同时硬件和软件厂商可以基于ONNX标准优化模型性能,让所有兼容ONNX标准的框架受益。
- ONNX就像是不同深度学习框架之间的”翻译官”,让模型可以在不同框架间自由转换。
- 例如用PyTorch训练了的模型(model.pt),可以转换成ONNX格式的模型(model.onnx),然后部署运行。
4.2 ONNX Runtime 在Oracle数据库中的集成
- Oracle Database 23ai集成了AI Vector Search等功能,支持VECTOR 数据类型,可以直接在 Oracle Database 23ai 中存储向量。如果想使用AI Vector Search等功能,首先将文本等信息转换成vector,这就需要embedding模型。作为最为全能和强大的数据库,Oracle提供了各种支持,当其他数据库还需要各种插件支持的时候,
- Oracle 23ai数据库对ONNX Runtime 进行了集成,允许导入包括embedding模型等ONNX格式的AI模型到数据库中使用。提供了Python实用程序包帮助用户把其他预训练模型转换为ONNX格式的模型。
六、ONNX 框架在 Oracle Embedding 中的关键作用
1. 统一模型部署接口
- ONNX支持跨框架模型互操作(如PyTorch → TensorFlow → ONNX)。
- Oracle 集成:
- 将训练好的嵌入模型(如PyTorch训练的文本编码器)导出为ONNX格式。
- 直接导入ONNX模型至Oracle数据库,注册为可调用函数。
2. 嵌入模型的生命周期管理
- 模型库管理:
BEGIN DBMS_VECTOR.IMPORT_MODEL( model_name => 'my_embedding_model', format => 'ONNX', location => 'DIR_MODELS', file_name => 'bert_text_encoder.onnx' ); END; -
调用生成向量:使用SQL函数调用模型,实时生成嵌入:
UPDATE documents SET embedding = VECTOR_EMBED( model => 'my_embedding_model', text => content -- 对content字段生成向量 );
3. 关键优势
- 避免跨系统调用:传统方案需部署独立模型服务(如Python API),Oracle通过ONNX在数据库内完成推理,减少网络延迟与运维成本。
- 企业级安全:模型与数据均在数据库内运行,满足隐私合规要求(如GDPR、HIPAA)。
- 动态更新模型:替换ONNX模型文件即可升级嵌入算法,无需停服。








![[Spring]-AOP](https://i-blog.csdnimg.cn/img_convert/424ef38752088e5d3161f4799257dfb4.png)