在使用 OpenAI、Claude、Gemini 等大语言模型 API 构建对话系统时,开发者普遍面临成本不断上升的挑战。无论是基于检索增强生成(RAG)的应用还是独立的对话系统,这些系统都需要维护对话历史以确保上下文的连贯性,类似于 ChatGPT 对历史对话的记忆机制。
这种历史记忆机制虽然提升了对话质量,但同时导致了 Token 消耗的指数级增长。本文提出一种内存高效算法,通过智能化的内存管理策略,将 Token 使用量减少高达 40%,从而显著降低 LLM 推理的运营成本。
该方法的核心原理基于一个关键洞察:LLM 并非需要对每次用户输入都生成回复,而应当区分用户的信息陈述和实际查询请求,仅在后者情况下生成响应。
下图展示了内存高效算法与传统方法的性能对比:
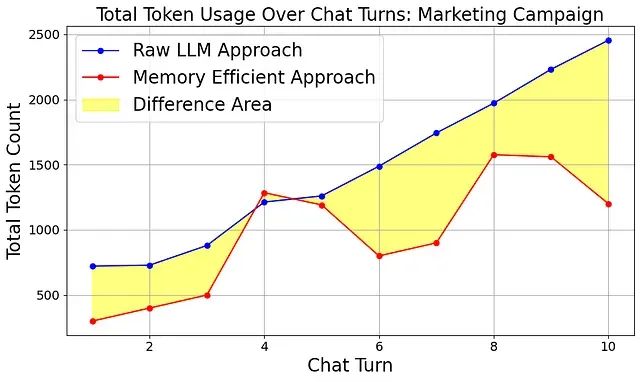
随着对话轮次的增加,两种方法的 Token 消耗差异呈现持续扩大的趋势。内存高效算法的 Token 增长保持相对稳定,图中红线的峰值对应 LLM 生成响应的时刻,其他数据点则表示知识库更新操作。
随着对话深度的增加,这种差异将愈发显著,详细的比较分析将在后续章节中展示。
环境准备与依赖库配置
实现本方案需要导入以下核心库,这些库在大语言模型应用开发中较为常见:
# 导入所需的标准库和第三方库,用于内存、LLM 和数据处理
importos # 操作系统交互(此处未直接使用)
importjson # 用于 JSON 解析/生成(LLM 输出)
importtime # 用于 API 调用之间的延迟
importuuid # 用于唯一的内存项 ID
fromdatetimeimportdatetime # 用于时间戳
importnumpyasnp # 用于嵌入向量
importpandasaspd # 用于 DataFrame/表格分析
fromopenaiimportOpenAI # 用于 OpenAI 兼容的 LLM/嵌入 API
fromsklearn.metrics.pairwiseimportcosine_similarity # 用于嵌入相似度
问题分析:Token 消耗的根本原因
本文采用 NebiusAI API 作为演示平台,该 API 基于 OpenAI 接口标准,提供开源 LLM 的访问能力。开发者可根据需要选择其他 LLM 服务提供商,但需确保响应中包含 Token 使用统计信息以便进行分析。
首先,我们初始化 LLM 客户端并配置基础的系统消息:
# 使用 Nebius API 初始化 OpenAI 客户端
client=OpenAI(
base_url="YOUR_BASE_URL_API", # 替换为你的实际基础 URL
api_key="YOU_LLM_API_KEY" # 安全地替换为你的实际密钥
)
# 聊天历史缓冲区(消息列表)
chat_history= [
{"role": "system", "content": "You are a helpful assistant."}
]
为了深入理解 Token 消耗模式,我们实现一个集成聊天历史功能的函数。该函数在每次查询后输出 LLM 响应和详细的 Token 使用统计信息:
defchat_with_history(user_input, max_length=100):
# 将用户输入添加到历史记录
chat_history.append({"role": "user", "content": user_input})
# 向模型发送请求
response=client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
temperature=0.7,
messages=chat_history
)
# 获取助手消息
assistant_message=response.choices[0].message.content
truncated_response= (assistant_message[:max_length] +'...') iflen(assistant_message) >max_lengthelseassistant_message
# 将助手响应添加到聊天记录
chat_history.append({"role": "assistant", "content": assistant_message})
# 打印所需信息
print(truncated_response)
print(f"Prompt tokens: {response.usage.prompt_tokens}")
print(f"Completion tokens: {response.usage.completion_tokens}")
使用 LLaMA 3.2 1B 模型进行测试,观察典型的用户交互模式:
# 向我们的 LLM 连续问两个问题
chat_with_history("Hello, who won the last FIFA World Cup?")
chat_with_history("And who was the top scorer?")
输出结果显示了 Token 消耗的累积效应:
#### 输出 ####
=== AI 响应(截断)===
The last FIFA World Cup was held in 2022, and the winning ...
=== Token 用量 ===
提示 Token:50
完成 Token:64
===============================
=== AI 响应(截断)===
The top scorer at the 2022 FIFA World Cup was Ciro Immobile ...
=== Token 用量 ===
提示 Token:130
完成 Token:29
===============================
关键观察:第二条消息"谁是最佳射手?"依赖于前一条消息的上下文,否则 LLM 无法确定用户询问的具体运动项目和时间范围。第二条消息的提示 Token 总数为 130(包含 50 个先前用户 Token + 64 个先前回复 Token + 16 个当前查询 Token)。
这一现象揭示了传统对话系统的核心问题:对话深度与 Token 消耗呈正相关关系,随着交互轮次的增加,每次调用所需的 Token 数量持续累积。
下图展示了在儿童故事创建场景中的 Token 消耗模式,该场景特别适合展示历史上下文的重要性:
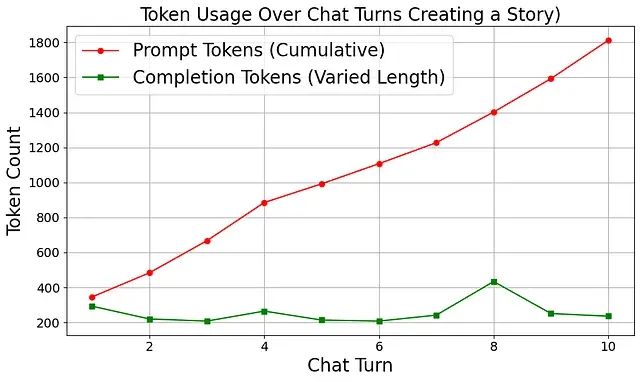
数据表明,提示 Token 随每条消息快速递增,到第 10 条消息时已包含前 9 条消息的完整上下文。这种累积效应是导致成本快速上升的根本原因。
内存高效算法的设计原理
针对上述问题,我们提出内存高效策略作为解决方案。该策略旨在通过智能化的 Token 管理机制减少不必要的计算开销。
算法的工作流程如下图所示:
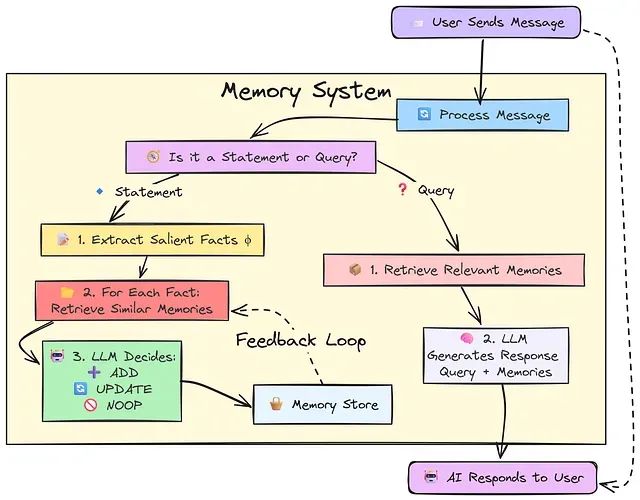
内存系统的核心逻辑包含以下步骤:
- 用户向 AI 系统发送消息
- 系统接收并分析消息类型:陈述或查询
- 根据消息类型执行相应的处理流程
对于陈述类型的消息,系统执行以下操作:从消息中提取关键事实信息,在内存存储中检索语义相似的现有信息,基于相似度分析决定操作类型(添加新信息、更新现有信息或无操作),将处理结果存储到内存系统中。
对于查询类型的消息,系统执行以下操作:根据查询内容在内存存储中搜索相关信息,结合查询和检索到的信息生成上下文相关的响应,将最终答案返回给用户。
该方法的核心创新在于认识到并非所有用户输入都需要 LLM 生成响应。大多数情况下,用户的输入是需要存储的陈述性信息,只有相关的陈述内容才应在响应生成时被检索和使用。这种方法不仅减少了 LLM 的内存占用,还显著提高了交互效率。
应用场景设计
为了验证算法的实际效果,我们选择营销活动策略场景作为测试用例。该场景贴近实际应用需求,模拟了 RAG 或独立聊天机器人处理营销活动相关查询的真实情况。
测试对话脚本定义如下:
conversation_script= [
{"role": "user", "content": "Hi, let's start planning the 'New Marketing Campaign'. My primary goal is to increase brand awareness by 20%."},
{"role": "user", "content": "For this campaign, the target audience is young adults aged 18-25."},
{"role": "user", "content": "I want to allocate a budget of $5000 for social media ads for the New Marketing Campaign."},
{"role": "user", "content": "What's the main goal for the New Marketing Campaign?"},
{"role": "user", "content": "Who are we targeting for this campaign?"},
{"role": "user", "content": "Let's also consider influencers. Add a task: 'Research potential influencers for the 18-25 demographic' for the New Marketing Campaign."},
{"role": "user", "content": "Actually, let's increase the social media ad budget for the New Marketing Campaign to $7500."},
{"role": "user", "content": "What's the current budget for social media ads for the New Marketing Campaign?"},
{"role": "user", "content": "What tasks do I have pending for this campaign?"},
{"role": "user", "content": "Also, for the New Marketing Campaign, I prefer visual content for this demographic, like short videos and infographics."}
]
这些对话体现了实际应用中常见的交互模式:陈述与查询的交替进行。陈述消息为 LLM 提供上下文信息以改进响应质量,而查询消息则期望获得基于已提供信息的定制化回复。
传统方法的基准测试
在实施内存高效算法之前,我们需要建立传统方法的性能基准。通过脚本化对话模拟 10 轮交互,记录每轮的输入和响应数据:
# 通过 LLM 运行脚本化对话,存储每一轮的输入和响应
raw_conversation= []
forturninconversation_script:
user_input=turn["content"] # 从脚本中提取用户消息
response=chat_with_history(user_input) # 使用聊天历史获取 LLM 响应
raw_conversation.append(response) # 存储结果以供后续分析
测试结果显示最后一轮对话(第 10 条消息)的 Token 使用情况:
print(f"Prompt tokens used in the last turn: {raw_conversation[-1]['prompt_tokens']}")
print(f"Completion tokens used in the last turn: {raw_conversation[-1]['completion_tokens']}")
输出结果表明传统方法的 Token 消耗程度:
#### 输出 ####
最后一轮使用的提示 Token:4446
最后一轮使用的完成 Token:451
仅在 10 轮对话后,最后一条消息的提示 Token 就超过了 4000,这对于相对简短的对话序列而言是相当高的消耗水平。
下图可视化展示了这种不断增长的历史累积效应:
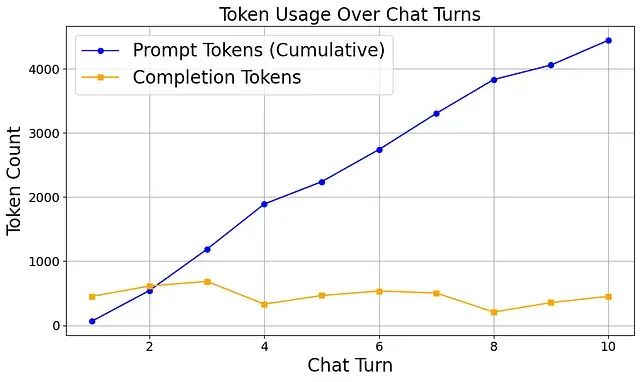
这些数据将作为评估内存高效算法性能改进的基准参考。
核心技术组件实现
嵌入向量生成与响应处理
在实现内存高效方法之前,需要构建若干辅助函数以提高代码的可维护性和复用性。
首先实现嵌入生成功能,该功能用于计算用户查询与存储内存状态之间的语义相似度:
# 嵌入模型名称
EMBEDDING_MODEL="BAAI/bge-multilingual-gemma2"
# 生成嵌入的函数
defget_embedding(text_to_embed):
"""
返回给定文本的嵌入向量。
参数:
- text_to_embed:要嵌入的输入文本。
返回:
- 包含嵌入的 NumPy 数组。
"""
response=client.embeddings.create(model=EMBEDDING_MODEL, input=text_to_embed)
returnnp.array(response.data[0].embedding)
其次实现 LLM 响应生成功能,负责处理模型响应的生成和 Token 统计:
defget_llm_chat_completion(messages):
"""
向语言模型发送聊天请求,并返回响应内容和 Token 使用情况。
参数:
- messages:聊天格式的消息列表(角色/内容)。
返回:
- content:生成的响应文本。
- prompt_tokens:输入中使用的 Token 数量。
- completion_tokens:输出中使用的 Token 数量。
"""
# 向聊天模型发送请求
response=client.chat.completions.create(
model=LLM_MODEL,
messages=messages
)
# 提取生成的文本
content=response.choices[0].message.content
# 获取 Token 使用信息(如果可用)
prompt_tokens=response.usage.prompt_tokens
completion_tokens=response.usage.completion_tokens
returncontent, prompt_tokens, completion_tokens
内存存储架构设计
虽然生产环境中通常采用向量数据库来实现高效的嵌入存储和相似性搜索,但为了保持实现的简洁性和教学目的,我们采用面向对象的设计模式来构建内存管理系统。
内存管理的核心概念包括:内存指用户提供的陈述性信息,这些信息用于增强 LLM 的理解能力而非触发即时响应;这些陈述可能为未来的查询提供重要的上下文信息,LLM 可以从中检索相关内容;为了有效管理这些信息,每个内存条目都需要具备唯一的标识符。
首先定义内存项的类结构:
classMemoryItem:
def__init__(self, text_content, source_turn_indices_list, verbose_embedding=False):
"""
初始化一个 MemoryItem 实例。
参数:
- text_content:要存储在内存中的文本。
- source_turn_indices_list:此项所基于的对话轮次索引列表。
- verbose_embedding:是否在嵌入过程中打印调试信息。
"""
self.id=str(uuid.uuid4()) # 内存项的唯一 ID
self.text=text_content # 内存的文本内容
self.embedding=get_embedding(text_content, verbose=verbose_embedding) # 文本的嵌入向量
self.creation_timestamp=datetime.now() # 此项创建的时间
self.last_accessed_timestamp=self.creation_timestamp # 上次访问此项的时间
self.access_count=0 # 此内存被访问的次数
self.source_turn_indices=list(source_turn_indices_list) # 对话轮次的引用
def__repr__(self):
"""
字符串表示形式,显示内存项的简要摘要。
"""
return (f"MemoryItem(id={self.id}, text='{self.text[:60]}...', "
f"created={self.creation_timestamp.strftime('%H:%M:%S')}, accessed={self.access_count})")
defmark_accessed(self):
"""
在访问内存时更新访问时间和计数。
"""
self.last_accessed_timestamp=datetime.now()
self.access_count+=1
接下来实现内存存储管理类,提供内存条目的增删查改功能:
classMemoryStore:
def__init__(self, verbose=False):
self.memories= {} # 按 ID 存储内存项的字典
defadd_memory_item(self, item):
self.memories[item.id] =item
defget_memory_item_by_id(self, memory_id):
item=self.memories.get(memory_id)
ifitem:
item.mark_accessed()
returnitem
defupdate_existing_memory_item(self, memory_id, new_text, turn_indices):
item=self.memories.get(memory_id)
ifnotitem:
ifself.verbose:
print(f"[MemoryStore] UPDATE FAILED: ID {memory_id} not found.")
returnFalse
item.text=new_text
item.embedding=get_embedding(new_text, verbose=self.verbose)
item.creation_timestamp=datetime.now()
item.source_turn_indices=list(set(item.source_turn_indices+turn_indices))
item.mark_accessed()
returnTrue
deffind_semantically_similar_memories(self, query_embedding, top_k=3, threshold=0.5):
# 过滤掉具有无效嵌入的内存项
candidates= [
(mid, mem.embedding) formid, meminself.memories.items()
ifmem.embeddingisnotNoneandmem.embedding.size>0andnp.any(mem.embedding)
]
# 将嵌入堆叠成矩阵以进行相似性比较
ids, embeddings=zip(*candidates)
embeddings=np.vstack(embeddings)
query_embedding=query_embedding.reshape(1, -1)
# 计算余弦相似度并对结果进行排序
similarities=cosine_similarity(query_embedding, embeddings)[0]
sorted_indices=np.argsort(similarities)[::-1]
# 返回高于阈值的 top-k 结果
return [
(self.memories[ids[i]], similarities[i])
foriinsorted_indices[:top_k]
ifsimilarities[i] >=threshold
]
该内存存储类实现了四个核心功能:添加新的内存项(如果不存在)、更新现有内存项的内容、根据 ID 检索特定的内存项、使用嵌入向量查找语义相似的内存条目。开发者还可以根据需要添加删除功能来移除未使用的内存,以进一步优化内存使用效率。
输入分类机制
在处理用户输入之前,系统需要准确判断输入的性质:陈述还是查询。这一分类决定了后续的处理流程。我们利用 LLM 的自然语言理解能力来实现这一功能:
defclassify_input(user_input):
"""
将用户输入分类为"查询"或"陈述"。
参数:
- user_input:用户的文本输入。
返回:
- 字符串: "查询"或"陈述"。
"""
# 指示 LLM 充当分类器
system_prompt= (
"You are a classifier. "
"A 'query' is a question or request for information. "
"A 'statement' is a declaration, instruction, or information that is not a question. "
"Respond with only one word: either 'query' or 'statement'."
)
# 向模型发送分类请求
response=client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"Classify this: {user_input}"}
]
)
# 返回分类结果(小写)
returnresponse.choices[0].message.content.strip().lower()
该分类函数在生产环境中会对每个用户查询实时执行。为了演示目的,我们对预定义的对话场景进行批量分类处理:
# 我们将把这个分类添加到我们的 conversation_script 项中
forturninconversation_script:
classification=classify_input(turn["content"])
turn["type"] =classification
验证分类结果的准确性:
# 打印第一项
conversation_script[0]
输出显示分类结果:
#### 输出 ####
{
'role': 'user',
'content': "Hi, let's start planning the 'New Marketing ... ",
'type': 'statement'
}
第一个用户查询被正确分类为"陈述",因为它提供信息而非请求回答,其目的是为 LLM 提供上下文信息。
事实提取机制
确定输入类型后,系统需要执行相应的处理逻辑:对于查询类型的输入,LLM 将生成响应;对于陈述类型的输入,系统需要从中提取关键事实并存储到内存系统中。
事实提取需要一个精心设计的提示模板来指导 LLM 识别和抽取关键信息:
fact_prompt=f"""
Extract concise, declarative facts from the 'New User Statement' based on the 'Recent Conversation Context'.
Focus on user's goals, plans, preferences, decisions, and key entities.
Ignore questions, acknowledgements, fluff, or inference.
Context:
---BEGIN---
{recent_turns_window_textor"(No prior context)"}
---END---
Statement: "{current_user_statement_text}"
Output ONLY a JSON list of strings (facts). Return [] if none.
"""
该模板专门针对营销活动场景进行了优化,开发者可以根据具体应用领域调整模板内容以获得更好的提取效果。
实现事实提取的核心函数:
defmem0_extract_salient_facts_from_turn(current_user_statement_text, recent_turns_window_text, current_turn_index_in_script):
"""
从当前用户陈述和最近的对话轮次中提取显著事实。
参数:
- current_user_statement_text:当前用户陈述的文本。
- recent_turns_window_text:用于上下文的最近对话轮次的文本。
- current_turn_index_in_script:当前轮次在整个脚本中的索引。
返回:
- facts:提取的事实列表(从 JSON 解析)。
"""
messages= [
{"role": "system", "content": "Expert extraction AI. Output ONLY valid JSON list of facts."},
{"role": "user", "content": fact_prompt}
]
# 调用 LLM 聊天完成函数
response_text, prompt_tokens, completion_tokens=get_llm_chat_completion(
messages
)
# 从响应文本中安全地提取 JSON 数组
start=response_text.find('[')
end=response_text.rfind(']')
json_candidate=response_text[start:end+1]
# 解析 JSON 以获取事实列表
facts=json.loads(json_candidate)
returnfacts
该函数将以 JSON 数组格式返回从陈述中提取的事实。提取的事实随后将与现有内存进行比较,以决定是作为新条目添加还是更新现有条目。
内存更新策略
提取的事实需要与现有内存系统建立适当的关联。系统需要评估新事实与已存储信息的关系,并决定采取相应的操作策略。
定义内存操作决策的提示模板:
prompt=f"""
You manage a memory store. Decide how to handle this new fact:
"{candidate_fact_text}"
{similar_segment}
Choose ONE:
- ADD: New info.
- UPDATE: Improves one existing memory (give memory ID and new text).
- NOOP: Redundant.
Respond with JSON:
{{"operation": "ADD"}} or
{{"operation": "UPDATE", "target_memory_id": "ID", "updated_memory_text": "Text"}} or
{{"operation": "NOOP"}}
Decision:
"""
该模板指导 LLM 在添加新内存、更新现有内存或忽略冗余信息之间做出决策。
实现内存操作决策的函数:
S_SIMILAR_MEMORIES_FOR_UPDATE_DECISION=3 # 要考虑的相似内存数量
defmem0_decide_memory_operation_with_llm(candidate_fact_text, similar_existing_memories_list):
"""
使用 LLM 来决定一个候选事实是否应该:
- 作为新内存添加,
- 更新现有内存,
- 或者被忽略(无操作)。
参数:
- candidate_fact_text:要评估的新事实。
- similar_existing_memories_list:(MemoryItem,similarity_score)元组列表。
返回:
- 具有以下格式之一的字典:
{"operation": "ADD"}
{"operation": "UPDATE", "target_memory_id": "ID", "updated_memory_text": "Text"}
{"operation": "NOOP"}
"""
# 为提示格式化相似内存部分
similar_segment="No similar memories."
ifsimilar_existing_memories_list:
formatted= [
f"{i+1}. ID: {mem.id}, Sim: {sim_score:.4f}, Text: '{mem.text}'"
fori, (mem, sim_score) inenumerate(similar_existing_memories_list)
]
similar_segment="Similar Memories:\n"+"\n".join(formatted)
# 为 LLM 构建消息
messages= [
{"role": "system", "content": "Decide memory action. Output ONLY valid JSON."},
{"role": "user", "content": prompt}
]
# 获取 LLM 的响应
response_text, p_tokens, c_tokens=get_llm_chat_completion(
messages
)
# 跟踪 Token 使用情况
total_prompt_tokens_mem0_update+=p_tokens
total_completion_tokens_mem0_update+=c_tokens
# 从响应中提取并解析 JSON
start=response_text.find('{')
end=response_text.rfind('}')
json_candidate=response_text[start:end+1]
returnjson.loads(json_candidate)
该函数通过分析新事实与现有内存的相似性,返回结构化的 JSON 响应,明确指定需要执行的操作类型和相关参数。
查询响应的检索机制
当用户提交查询时,系统需要从内存中检索相关信息以辅助 LLM 生成准确的响应。这一过程与检索增强生成(RAG)的机制相似。
实现内存检索和格式化的函数:
# 要检索的顶部相似内存的默认数量
K_MEMORIES_TO_RETRIEVE_FOR_QUERY=3
defmem0_retrieve_and_format_memories_for_llm_query(user_query_text, memory_store_instance, turn_log_entry, top_k_results=K_MEMORIES_TO_RETRIEVE_FOR_QUERY):
"""
为给定的用户查询从存储中检索并格式化 top-k 相关内存。
参数:
- user_query_text:当前用户查询。
- memory_store_instance:要在其中搜索的 MemoryStore 实例。
- turn_log_entry:用于存储内存检索信息以进行日志记录的字典。
- top_k_results:要检索的顶部相似内存的数量。
返回:
- 相关内存的格式化字符串或回退消息。
"""
turn_log_entry['retrieved_memories_for_query'] = []
# 获取用户查询的嵌入
query_embedding=get_embedding(user_query_text)
# 根据查询嵌入查找 top-k 相似内存
retrieved=memory_store_instance.find_semantically_similar_memories(query_embedding, top_k=top_k_results)
# 构建格式化的内存列表
output="Relevant memories:\n"
fori, (mem, score) inenumerate(retrieved):
memory_store_instance.get_memory_item_by_id(mem.id) # 标记为已访问
output+=f"{i+1}. {mem.text} (Similarity: {score:.3f})\n"
# 记录检索详细信息
turn_log_entry['retrieved_memories_for_query'].append({
'id': mem.id,
'text': mem.text,
'similarity': score
})
returnoutput.strip()
该函数根据用户查询的语义相似性检索最相关的内存条目,并将其格式化为结构化的上下文信息,供 LLM 在生成响应时参考。
算法实现与执行
整个内存高效算法的核心逻辑通过主循环实现,该循环处理对话场景中的每条消息,并根据消息类型执行相应的操作:
# 遍历脚本中的每一轮
forturn_index, turn_datainenumerate(script):
user_msg=turn_data['content'] # 用户输入文本
turn_type=turn_data['type'] # 类型:"陈述"、"陈述更新"或"查询"
# 此轮的日志
turn_log_entry= {
"turn": turn_index+1,
"type": turn_type,
"user_content": user_msg
}
assistant_response="(Ack/Internal Processing)" # 默认占位符
# 处理陈述和更新
ifturn_typein ('statement', 'statement_update'):
# 收集最近的用户-助手原始对话日志以获取上下文
recent="\n".join(raw_conversation_log_for_extraction_context[-M_RECENT_RAW_TURNS_FOR_EXTRACTION_CONTEXT:])
# 处理用户消息以进行事实提取和内存更新
mem0_process_user_statement_for_memory(
user_msg, recent, memory_store_instance, turn_index, turn_log_entry, verbose=VERBOSE_MEM0_RUN
)
# 助手的响应取决于陈述类型
assistant_response="Okay, noted."ifturn_type=='statement'else"Okay, updated."
# 记录零 Token,因为此路径不调用 LLM 进行响应
turn_log_entry.update({
'assistant_response_conversational': assistant_response,
'prompt_tokens_conversational_turn': 0,
'completion_tokens_conversational_turn': 0
})
# 处理查询(例如,问题)
elifturn_type=='query':
# 根据与查询的语义相似性检索相关内存
retrieved=mem0_retrieve_and_format_memories_for_llm_query(user_msg, memory_store_instance, turn_log_entry)
# 使用内存上下文和查询为 LLM 创建提示
messages=list(current_short_term_llm_chat_history) + [{
"role": "user",
"content": f"User Query: '{user_msg}'\n\nRelevant Info from Memory:\n{retrieved}"
}]
# 获取 LLM 响应
assistant_response, p_tokens, c_tokens=get_llm_chat_completion(
messages, max_tokens=120, verbose=VERBOSE_MEM0_RUN
)
# 跟踪此查询的 Token 使用情况
total_prompt_tokens_mem0_conversation+=p_tokens
total_completion_tokens_mem0_conversation+=c_tokens
# 使用 LLM 输出和 Token 信息更新轮次日志
turn_log_entry.update({
'assistant_response_conversational': assistant_response,
'prompt_tokens_conversational_turn': p_tokens,
'completion_tokens_conversational_turn': c_tokens
})
# 更新用于内存提取上下文的原始日志
raw_conversation_log_for_extraction_context+= [
f"T{turn_index+1} U: {user_msg}",
f"T{turn_index+1} A: {assistant_response}"
]
# 更新短期历史以供将来 LLM 上下文使用
current_short_term_llm_chat_history+= [
{"role": "user", "content": user_msg},
{"role": "assistant", "content": assistant_response}
]
# 仅保留滑动窗口内最新的聊天历史
iflen(current_short_term_llm_chat_history) > (1+SHORT_TERM_CHAT_HISTORY_WINDOW*2):
current_short_term_llm_chat_history= [current_short_term_llm_chat_history[0]] + \
current_short_term_llm_chat_history[-(SHORT_TERM_CHAT_HISTORY_WINDOW*2):]
# 处理此轮后记录内存存储大小
turn_log_entry['mem_store_size_after_turn'] =len(memory_store_instance.memories)
在生产环境中,该循环会实时处理用户输入,对每条消息执行分类、检索或更新操作,并在必要时生成响应。
算法执行的日志输出展示了工作流程:
#### 我们的 MEMO 算法输出 ####
--- Mem0 第 1/10 轮 (陈述) ---
用户:嗨,让我们开始规划新的营销活动。我的主要目标是增加...
[提取器 LLM] 解析了 2 个事实。
[内存协调器] 提取了 2 个事实。
[内存协调器] 事实 用户想要开始规划...:LLM 决策 -> 添加
[内存协调器] 事实 用户的主要目标是...:LLM 决策 -> 添加
助手 (确认):好的,已记录。
--- Mem0 第 2/10 轮 (陈述) ---
用户:对于这个活动,目标受众是 18-25 岁的年轻人....
[提取器 LLM] 解析了 1 个事实。
[内存协调器] 提取了 1 个事实。
[内存协调器] 事实 N 的目标受众是...:LLM 决策 -> 添加
助手 (确认):好的,已记录。
--- Mem0 第 3/10 轮 (陈述) ---
用户:我想为新营销活动的社交媒体广告分配 5000 美元的预算...
[提取器 LLM] 解析了 1 个事实。
[内存协调器] 提取了 1 个事实。
[内存协调器] 事实 用户想要分配一个 b...:LLM 决策 -> 添加
助手 (确认):好的,已记录。
--- Mem0 第 4/10 轮 (查询) ---
用户:新营销活动的主要目标是什么?...
助手:新营销活动的主要目标是**将品牌知名度提高...
从前四轮的执行结果可以观察到:前三个输入被正确识别为陈述类型,系统仅进行了事实提取和内存存储操作,未生成 LLM 响应;第四个输入被识别为查询类型,系统检索了相关内存并生成了基于上下文的响应。这证实了算法能够准确区分不同类型的输入并执行相应的处理逻辑。
性能评估与对比分析
为了量化内存高效算法的性能改进,我们对传统方法和新算法的 Token 使用情况进行了详细的比较分析。
首先构建比较数据的 DataFrame 结构:
# 准备原始方法和 Mem0 方法之间的比较数据
data= {
'Metric': [
'Prompt Tokens', # 使用的总提示 Token
'Completion Tokens', # 使用的总完成 Token
'Total Tokens', # 提示 + 完成的总和
'', # 用于间隔的空行
# Mem0 方法的 Token 使用明细
'Mem0: Conv Prompt', # 对话轮次的提示 Token
'Mem0: Conv Completion', # 对话轮次的完成 Token
'Mem0: Extract Prompt', # 内存提取的提示 Token
'Mem0: Extract Completion', # 内存提取的完成 Token
'Mem0: Update Prompt', # 内存更新的提示 Token
'Mem0: Update Completion' # 内存更新的完成 Token
],
'Raw Approach': [
final_raw_prompt_tokens, # 原始提示 Token
final_raw_completion_tokens, # 原始完成 Token
final_raw_total_tokens, # 原始总 Token
'', # 间隔行的空值
'-', '-', '-', '-', '-', '-' # 原始方法没有可用的明细
],
'Mem0 Approach': [
final_mem0_overall_prompt_tokens, # Mem0 中的总提示 Token
final_mem0_overall_completion_tokens, # Mem0 中的总完成 Token
final_mem0_overall_total_tokens, # Mem0 中的总 Token
'', # 间隔符
final_mem0_conv_prompt_tokens, # 对话的提示 Token
final_mem0_conv_completion_tokens, # 对话的完成 Token
final_mem0_extr_prompt_tokens, # 提取的提示 Token
final_mem0_extr_completion_tokens, # 提取的完成 Token
final_mem0_upd_prompt_tokens, # 更新的提示 Token
final_mem0_upd_completion_tokens # 更新的完成 Token
]
}
# 创建一个用于显示和分析的 DataFrame
comparison_df=pd.DataFrame(data)
在仅包含 10 轮对话的测试中,内存高效算法就实现了高达 40% 的提示 Token 减少。下图展示了两种方法的性能对比:
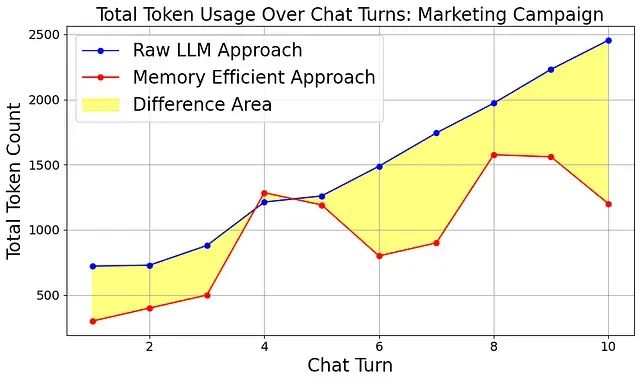
图中红线代表内存高效算法的 Token 使用模式,仅在用户实际请求响应时(第 4、5、8、9 轮)出现显著的增长,而在其他陈述轮次中,总 Token 数量(提示+完成)保持相对稳定,避免了传统方法中的快速累积现象。
黄色区域表示两种方法之间的差异,随着对话轮次的增加,这一差异呈现持续扩大的趋势。为了进一步验证算法的长期效果,我们进行了 100 轮对话的扩展测试:
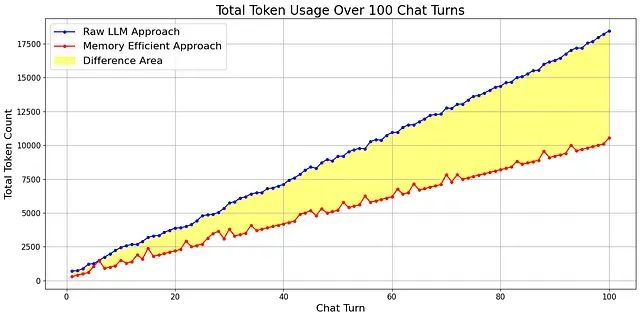
在 100 轮对话后,性能差异变得极为显著,内存高效算法实现了超过 60% 的 Token 节省。这种显著的改进直接转化为成本节约,这对于大规模生产环境具有重要的经济价值。
总结
内存高效算法在 Token 使用优化方面展现了显著的性能优势,能够在保持对话质量的同时大幅降低 LLM API 的使用成本。该方法的核心创新在于区分用户输入的类型,并针对不同类型采用差异化的处理策略。
开发者可以基于提供的实现进一步优化算法性能,包括开发更精确的提示模板、增加内存管理功能以提高检索速度和存储效率、集成评估机制以量化响应质量、实现动态内存清理以维护系统性能等方面。
此外,结合响应质量评估技术来比较两种方法的输出质量将为算法的进一步改进提供重要参考。基于这些评估结果,可以持续优化算法的效率和准确性,以适应更广泛的应用场景需求。
未来的研究方向可以包括探索更高效的向量存储和检索机制、开发适应性更强的事实提取算法、以及研究多模态内容的内存管理策略等领域。
https://avoid.overfit.cn/post/5feb4f4f31ed41d1850a01e6d7a78e6a
作者:Fareed Khan


![[神经网络]使用olivettiface数据集进行训练并优化,观察对比loss结果](https://i-blog.csdnimg.cn/direct/d3f9b3ecf99f4846a6417d79091f3908.png#pic_center)