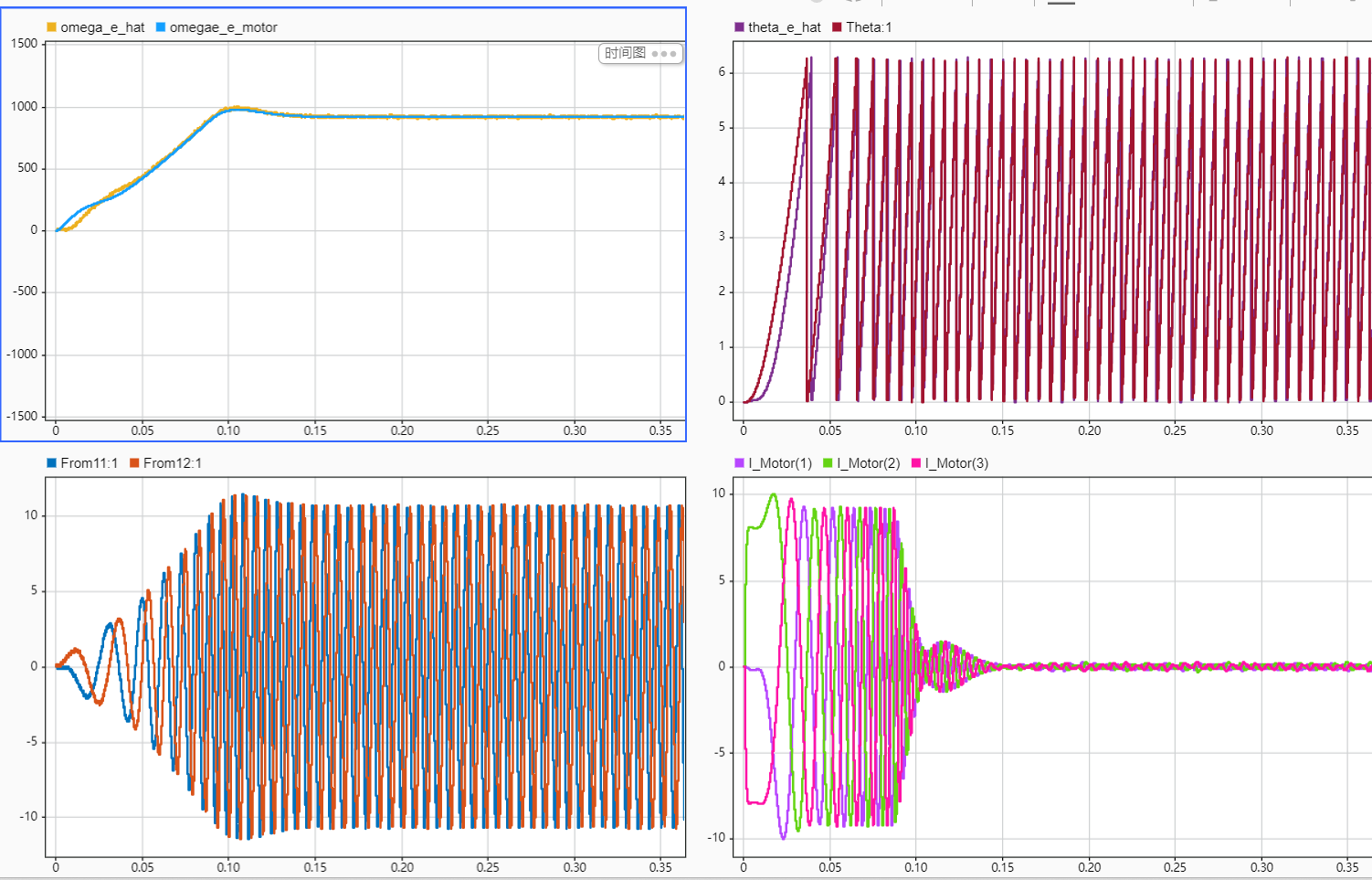
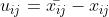前言
以<深入理解计算机系统>(以下称“本书”)内容为基础,对程序的整个过程进行梳理。本书内容对整个计算机系统做了系统性导引,每部分内容都是单独的一门课.学习深度根据自己需要来定
引入
接续理解计算机系统_并发编程(10)_线程(七):基于预线程化的并发服务器-CSDN博客,理解并行
顺序、并发和并行的概念(联系与区别)
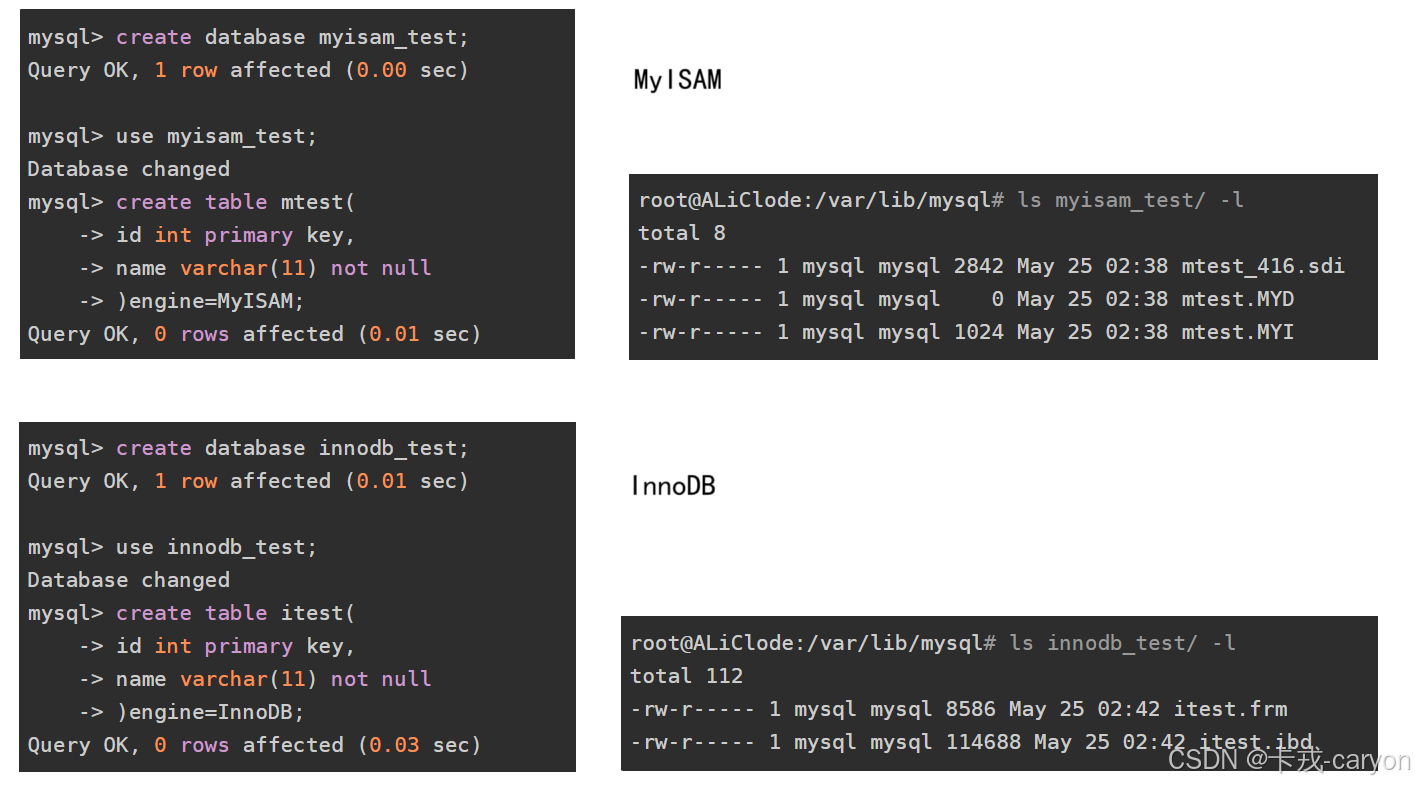
本书P711图12-30

本书原话:所有程序的集合能够被划分成不相交的顺序程序集合和并发程序的集合.写顺序程序只有一条逻辑流.写并发程序有多条并发流.并行程序是一个运行在多个处理器上的并发程序.因此,并行程序的集合是并发程序集合的真子集.
用白话来理解这几个概念:
首先通用部分:程序是任务,在机器层面是指令流.CPU是完成任务的工具.
CPU的运行机制:在多任务系统中(通常非单片机都属于多任务系统),CPU面对的是多个同时加载进内存的任务(进程),CPU按照"时间片+中断"在进程中做切换---一般情况下不是CPU执行完一整个任务再去执行下一个任务,而是每次执行任务的一部分,按照某种条件(比如时间已到,或者硬件中断,或者信号)转去执行下一个任务.
顺序程序:一条逻辑(指令)流
并发程序:多条并发(指令)流,通常指对应单个CPU
并行程序:多条并发(指令)流,通常指对应多个CPU
意义:将顺序程序转为并发(或并行)程序,可以提高效率.
=============================内容分割线↓===================================
思考:CPU调度算法如何实现?
笔者做了尝试.
第一步,调度要操作的是什么?线程.而线程抽象为函数Thread.
/*声明函数指针thread,将其设置为一个类型*/
typedef void* (*Thread)(void * arg);然后所有的函数都化成Thread对象.---可以做到,如果有多个形参,放到一个结构里,返回值的void*可以不用,也可以放到结构里,前面帖子有举例.
第二步,建立线程集合.选用什么样的数据结构?动态数组或者二叉树还是其他哪一种?这里需要经验或者代码验证了,不展开叙述.简单用动态数组.
//线程的集合
Thread* threads; //线程的动态数组
int n; //线程个数显然这里还需要增删查的算法,不展开了.
/*到每次写和数据结构有关算法的时候,就念起C++的好处来了,不用每次都重新写*/
第三步,写调度算法.
函数文字表达:从第一个线程开始,每当时间片到达或者信号到达或者硬件中断时,退出当前执行的线程,记录线程上下文并跳转到下一个线程.线程集合假设在执行完毕之后刷新
这里需要汇编语言,做一些假设:
假设程序计数器PC可以直接用,每个线程被编译成机器指令的集合.有一个机器指令的指针--假设为MP(类型和PC一样)指向当前线程,他是可以++的.每个线程的末尾有标识.
//调度算法,伪代码
void dispatch(int n,Thread* threads){
线程上下文回溯;
int time=当前时间; /*调用系统内核中计算current_time的函数*/
while(time==当前时间+时间片大小)||信号到达||硬件中断||PC没指向线程末尾){
PC=MP++; /*执行机器代码,如果while条件不成立,指针+1*/
}
if(信号)
执行信号函数;
if(硬件中断)
执行硬件中断函数;
if(线程未结束)
保存线程上下文;
添加进一个新的线程集合;
//不管线程有没有结束,都跳转并返回
dispatch(++n,threads); /*跳转执行线程集合中下一条*/
return;
}这是一个很简陋的算法,基本思路是一边执行线程,一边更新一个新的线程集合,把未执行完毕的线程放进去. 需要考虑的东西还很多,比如:
时间片大小是怎么确定?是否在不同场景采用不同的设置
信号,硬件中断的函数如何设计?可能还要考虑中断嵌套
线程优先级如何安排(线程排序)?---某些重要线程要排在前面,执行2次,其他非重要线程执行1次
新的线程集合threads什么时候更新?--添加新线程
在<操作系统概论>里,有专门的篇章介绍进程调度的算法---提出了多种模型(但未实现,需要系统级的汇编语言支持),进程调度在整个操作系统设计里,占的内容不少,这里只是做一些设想,并不做准确的保证.
以上内容是为锻炼思维的一点思考
=============================内容分割线↑===================================
并行程序分析
本书P711举了高斯数列的例子.本书P711第4段:将任务分配到不同线程的最直接方法是将序列划分为t个不相交的区域,然后给t个不同的线程每个分配一个区域.为了简单,假设n是t的倍数,这样每个区域有n/t个元素.
---解读:使用并发(并行)对程序效率的提高,对程序员来说很有吸引力.并发(并行)的前提是:各个线程之间是独立的,不存在因果关系(如线程A必须先于线程B完成,或者说线程B用到了线程A执行后的结果)
多线程解高斯数列求和
思路:有连续的n个数字,划分为t块,每块的数据为n/t个,每块用一个线程函数求解.
思路图

最简单也最直接的选择是将线程的和放入一个共享全局变量中,用互斥锁保护这个变量.
---解读:第一种方案:一个共享全局变量.
第一种方案的代码解读
主函数第21~25行
nthreads=atoi(argv[1]); //传入线程个数
log_nelems=atoi(argv[2]); //传入幂
nelems=(1L<<log_nelems); //元素总个数
nelems_per_thread=nelems/nthreads; //每线程元素个数
sem_init(&mutex,0,1); //信号量初始化
注意:这里计算的总个数,是自己定的,始终保持2的n次幂,传入的log_nelems就是幂的值.这样做的目的前面讲了是为了方便计算.实际情况不能自己定计算个数,就算是1000这种非2的n次幂值,问题也不大.
主函数第27~33行
线程建立及线程完毕后资源回收

线程函数 
---每次迭代都更新共享全局变量gsum.注意,我们很小心地用P和V互斥操作来保护每次更新
注意:第5行求出每线程首个元素的大小.元素大小和块序号myid有关.而myid来自主函数第29行.这里得到的启示是:当需要的数据没找到时,在全局变量或者main函数的局部变量中声明,再行定义.代码中从前到后是这样写的:
主函数中:
第13行声明:long myid[MAXTHREADS];---声明一个long数组,存放序号
第29行,每生成一个线程,就把序号放到myid数组中
第30行,将序号传入线程函数:Pthread_create的第4个参数:&myid[i]
线程函数中:
第4行:取出序号
第5行:使用序号得到每个线程首元素的值.
=============================内容分割线↓===================================
写代码的时候,常常有这种情况:找不到想要的数据.例如笔者初始不知道怎么得到每线程首元素值.解决办法可以参照本书代码:从前面声明,用产生数据的逻辑放到应该的位置.
思路清晰,总是能找到解决办法.
=============================内容分割线↑===================================
第一种方案失败原因分析
本书P713的图,第一种方案的结论:运行时间很长,性能差,而且使用核数越多,性能越差.
本书原话:造成性能差的原因是相对于内存更新操作的开销,同步操作(P和V)代价太大.这突显了并行编程的一项重要教训:同步开销巨大,要尽可能避免.如果无可避免,必须要用尽可能多的有用计算弥补这个开销.
第二种方案:避开同步
本书P713第3段:一种避免同步的方法是让每个对等线程在一个私有变量中计算他自己的部分和,这个私有变量不与其他任何线程共享,主线程定义一个全局数组psum,每个对等线程i把他的部分和累积在psum[i]中.因为小心地给了每个对等线程一个不同地内存位置来更新,所以不需要用互斥锁来保护这些更新.唯一需要同步的地方是主线程必须等待所有的子线程完成.在对等线程结束后,主线程把psum向量的元素加起来,得到最终的结果.
---代码如图

全局数组psum定义在第10行之前:
long psum[MAXTHREADS];与之对应:
第21行的nthreads,传入的线程数必须少于MAXTHREADS.
主函数的最后要用一个for循环把psum数组的值加起来得到结果.
第二种方案的优化
本书原话:第5章中,我们学习到了如何使用局部变量来消除不必要的内存引用.
---技巧:即使是在函数内部中要使用全局变量,也尽量不要频繁使用.代码如图

计算后的结果赋值给全局变量psum[myid],而不是第二种方案优化前的for循环中每次都访问他
并行效率等问题
作为程序员来说,并行肯定能用则用,效率问题主要集中在选几个核参加并行得到的效果更好.笔者认为这些内容太底层了暂不考虑.本书原话:数十年来,并行编程一直是一个很活跃的研究领域.随着商用多核机器的出现,这些机器的核数每几年就翻一番,并行编程会继续是一个深入、苦难而活跃的研究领域.
小结
用本书中高斯数列求和的例子,理解了并行编程."挑战"了调度算法;总结编程时"找数据"的思路.
并发(并行)编程的前提条件:线程之间不相交.尽量使用并发(并行)提高运行效率.
![[Windows] 游戏常用运行库- Game Runtime Libraries Package(6.2.25.0409)](https://i-blog.csdnimg.cn/img_convert/55ca519964b01db8e0d3b2a1e7961c42.webp?x-oss-process=image/format,png)