1. 概述
离线强化学习是现在强化学习研究的一个重点。相比与传统的强化学习它不需要大量的实时交互数据,仅仅依赖历史交互日志就可以进行学习。本文就是将离线强化学习用于推荐系统的一篇文章。
这篇文章主要解决的核心问题有以下几个:
1)静态的奖励函数,现有基于模型的离线RL方法使用冻结的世界模型(world models,包括奖励函数和状态转移函数),这些模型基于稀疏的离线数据训练,奖励估计常存在偏差。在这种方法中,奖励函数一般是作为固定的查找表(look-up-tables)使用这种会导致在策略学习中传播不准确性。例如,高估的物品可能被优先推荐,但实际效果不佳。
2)静态的不确定性惩罚,现有的方法引入的不确定性惩罚(uncertainty penalties)是固定的,无法动态适应策略训练过程中的风险变化。
2.框架
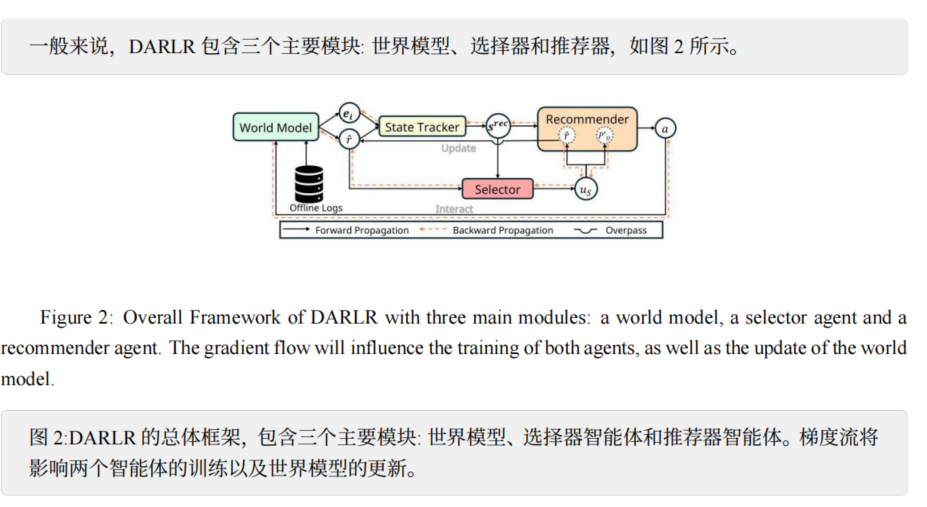
针对上面的问题,这篇文章提出了DARALR框架。
与传统静态方法不同,DARLR通过迭代更新奖励函数和不确定性惩罚,适应稀疏数据带来的挑战。
-
选择器智能体(Selector Agent):负责识别参考用户(reference users),通过平衡相似性(similarity)和多样性(diversity)选择一组用户。相似性确保参考用户与目标用户的偏好接近,多样性则覆盖更广泛的物品交互数据,弥补目标用户数据的稀疏性。
-
推荐器智能体(Recommender Agent):利用参考用户的信息,聚合其交互数据,迭代优化奖励估计(reward estimation),实现动态奖励塑造(dynamic reward shaping)。同时,根据所选用户的统计特征(如交互方差),动态调整不确定性惩罚(uncertainty penalty)
3. 技术细节
论文基于马尔可夫决策过程(MDP)描述任务,使用五元组 ![]() 来描述任务。
来描述任务。

1)选择参考用户,选择器根据目标用户U的特征选择一组相似但是多样化的参考用户。例如用户U喜欢动作电影,参考用户可能包括喜欢动作电影但是也涉猎其他电影类型的人。
2)奖励估计。推荐器聚合参考用户的交互数据,估计U对某个物品的奖励。若是参考用户对该物品的反应是一致性的高,则奖励估计更加可信,若是方差则增大,则不确定性增加。
3)动态调整。根据参考用户的统计特征(方差/值信度),调整不确定性的惩罚。
r = \tilde{r} - \lambda_U P_U \),其中 \( \tilde{r} \) 是估计奖励,\( P_U \) 是不确定性惩罚,\( \lambda_U \) 是动态系数。
4.代码实现
官方代码实现
https://github.com/ArronDZhang/DARLR
论文地址:
[2505.07257] DARLR: Dual-Agent Offline Reinforcement Learning for Recommender Systems with Dynamic Reward