基础篇
基础语法
添加数据
-- 完整语法
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);
-- 示例
insert into employee(id,workno,name,gender,age,idcard,entrydate)
values(1,'1','Itcast','男',10,'123456789012345678','2000-01-01')修改数据
-- 完整语法
UPDATE 表名 SET 字段名1 = 值1 , 字段名2 = 值2 , .... [ WHERE 条件 ] ;
-- 示例
update employee set name = '小昭' , gender = '女' where id = 1;删除数据
-- 完整语法
DELETE FROM 表名 [ WHERE 条件 ] ;
--示例
delete from employee where gender = '女';查询语句
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
ORDER BY
排序字段列表
LIMIT
分页参数聚合函数查询
-- 完整语法
SELECT 聚合函数(字段列表) FROM 表名 ;
-- 示例
select count(*) from emp; -- 统计的是总记录数
select count(idcard) from emp; -- 统计的是idcard字段不为null的记录数
select sum(age) from emp where workaddress = '西安'; -- 统计西安地区员工的年龄之和聚合函数是对表中一列数据的操作
分组查询
-- 完整语法
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组
后过滤条件 ];
--示例
select gender, count(*) from emp group by gender ; -- 根据性别分组 , 统计男性员工 和 女性员工的数量
select workaddress, count(*) address_count from emp where age < 45 group by workaddress having address_count >= 3; -- 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址排序查询
-- 完整语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;
-- 示例
-- 根据年龄对公司的员工进行升序排序
select * from emp order by age asc;
select * from emp order by age;
-- 根据入职时间进行降序排序
select * from emp order by entrydate desc;分页查询
-- 完整语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数 ;
-- 示例
select * from emp limit 0,10; -- 查询第1页员工数据, 每页展示10条记录
select * from emp limit 10,10; --查询第2页员工数据, 每页展示10条记录DCL常用语法
创建用户
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ;删除用户
DROP USER '用户名'@'主机名' ;查询权限
SHOW GRANTS FOR '用户名'@'主机名' ;赋予权限
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';函数
常用字符串函数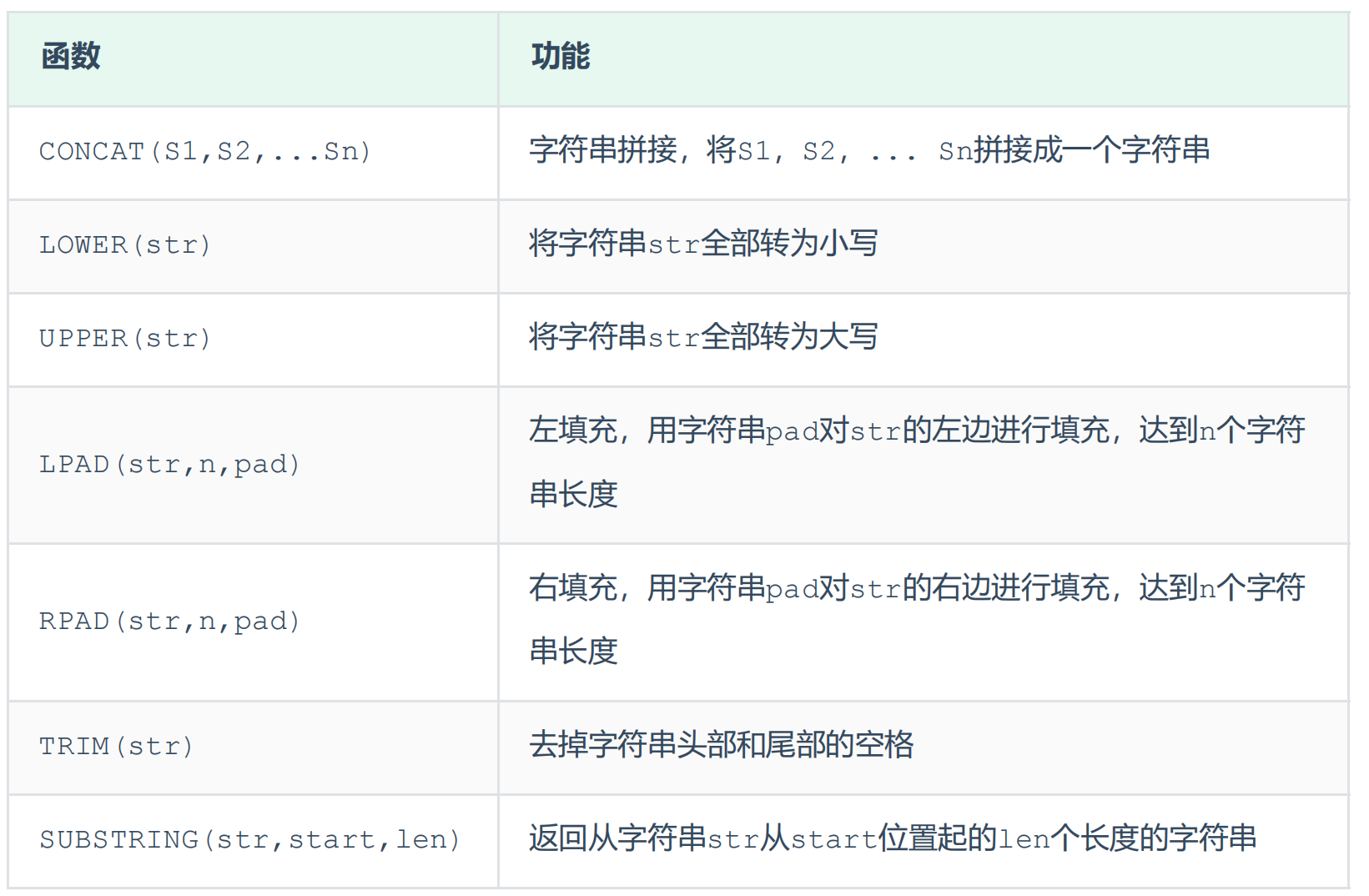
常用数值函数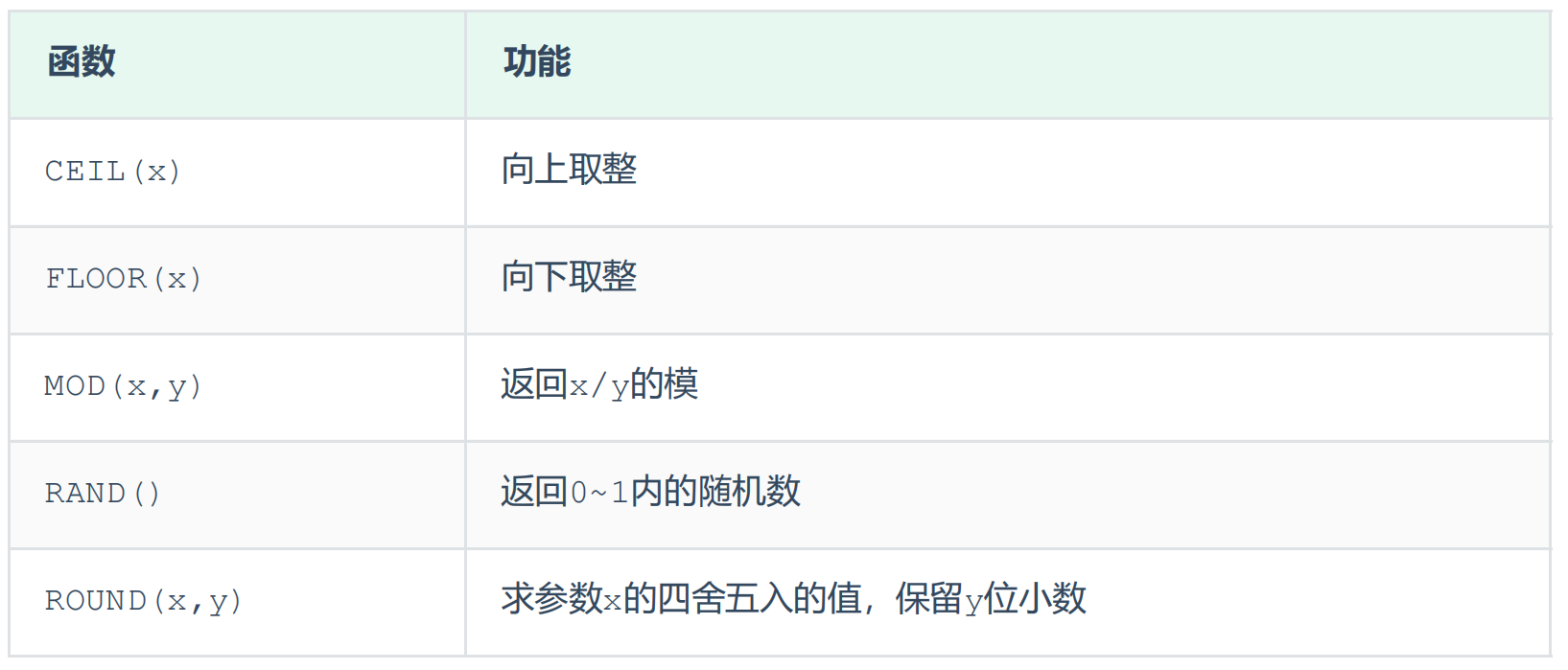 常用日期函数
常用日期函数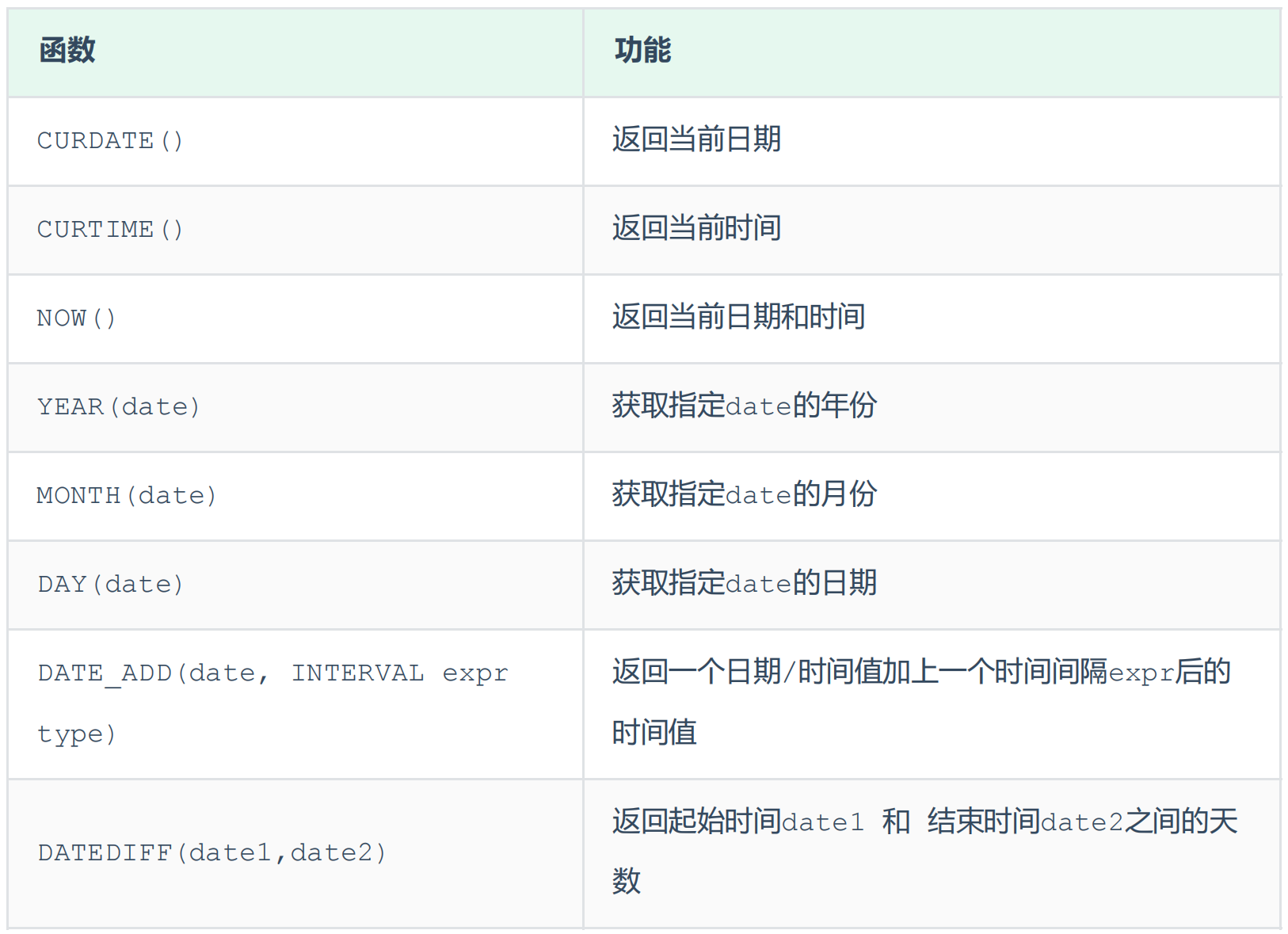
流程函数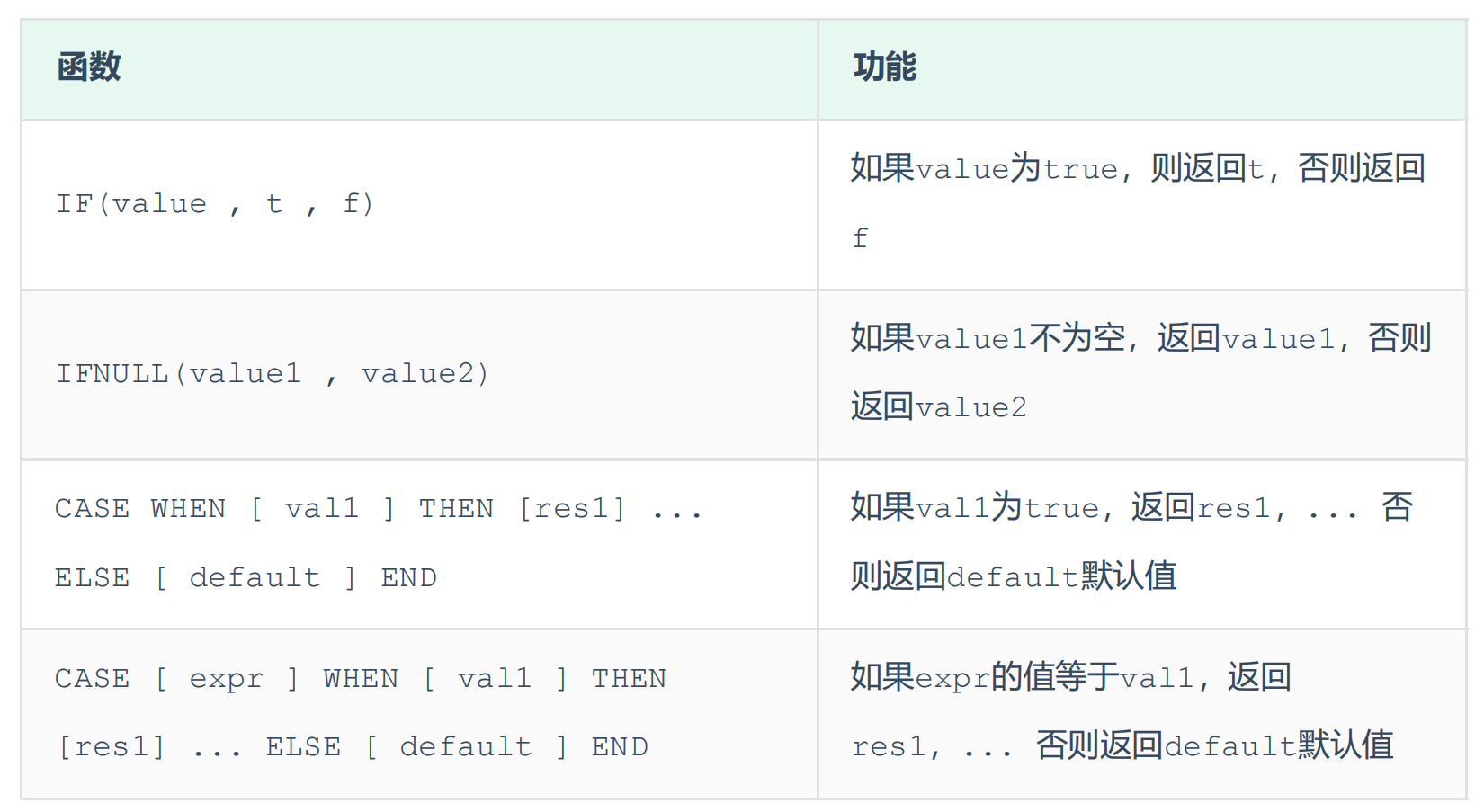
约束
常见的约束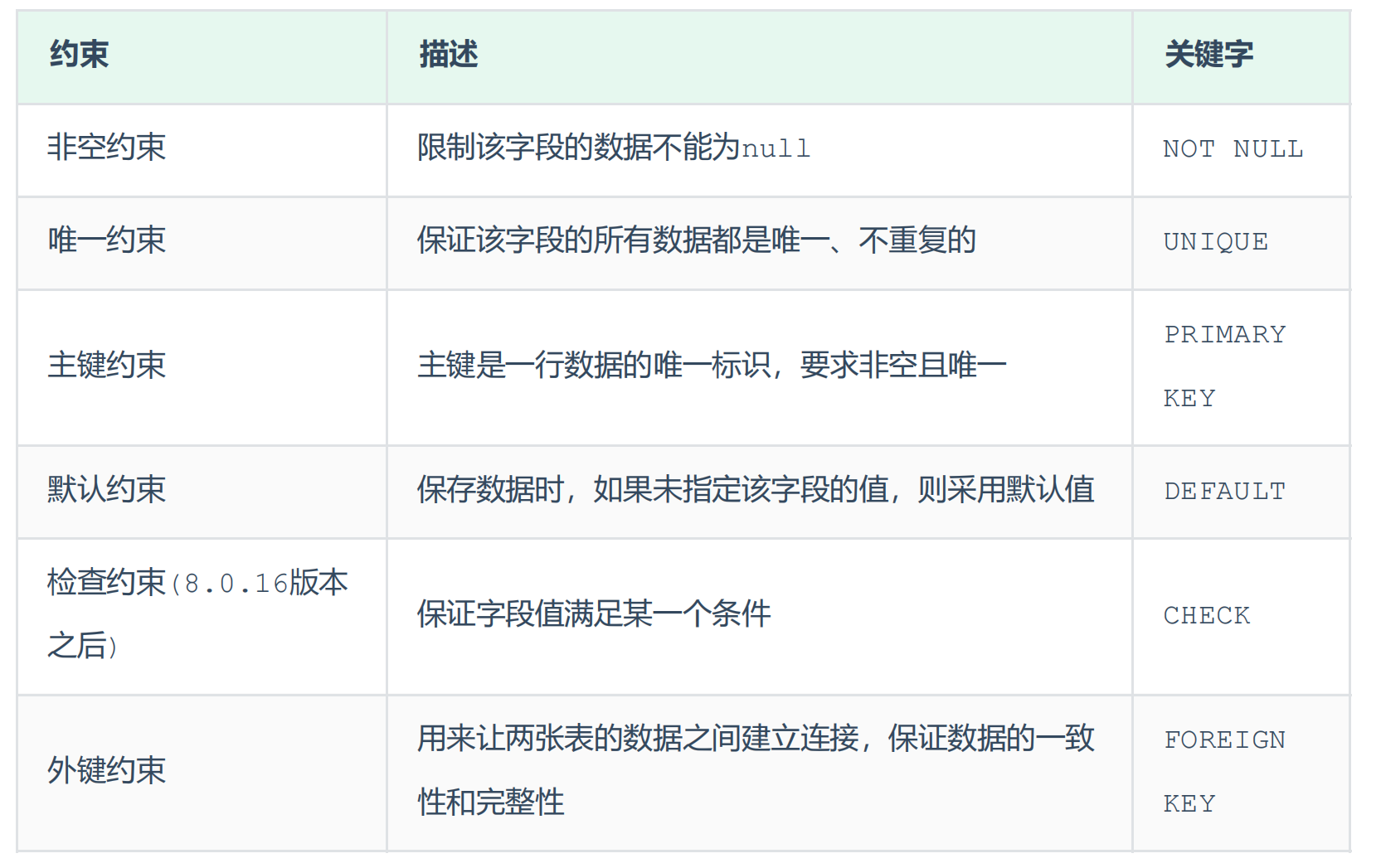
可以在创建或者修改表时添加约束
-- 具体示例
CREATE TABLE tb_user(
id int AUTO_INCREMENT PRIMARY KEY COMMENT 'ID唯一标识',
name varchar(10) NOT NULL UNIQUE COMMENT '姓名' ,
age int check (age > 0 && age <= 120) COMMENT '年龄' ,
status char(1) default '1' COMMENT '状态',
gender char(1) COMMENT '性别'
);添加外键约束
-- 创建时指定
CREATE TABLE 表名(
字段名 数据类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY (外键字段名) REFERENCES 主表 (主表列名)
);
-- 修改时指定
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名)
REFERENCES 主表 (主表列名) ;
-- 示例 为emp表的dept_id字段添加外键约束,关联dept表的主键id
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称;删除/更新行为
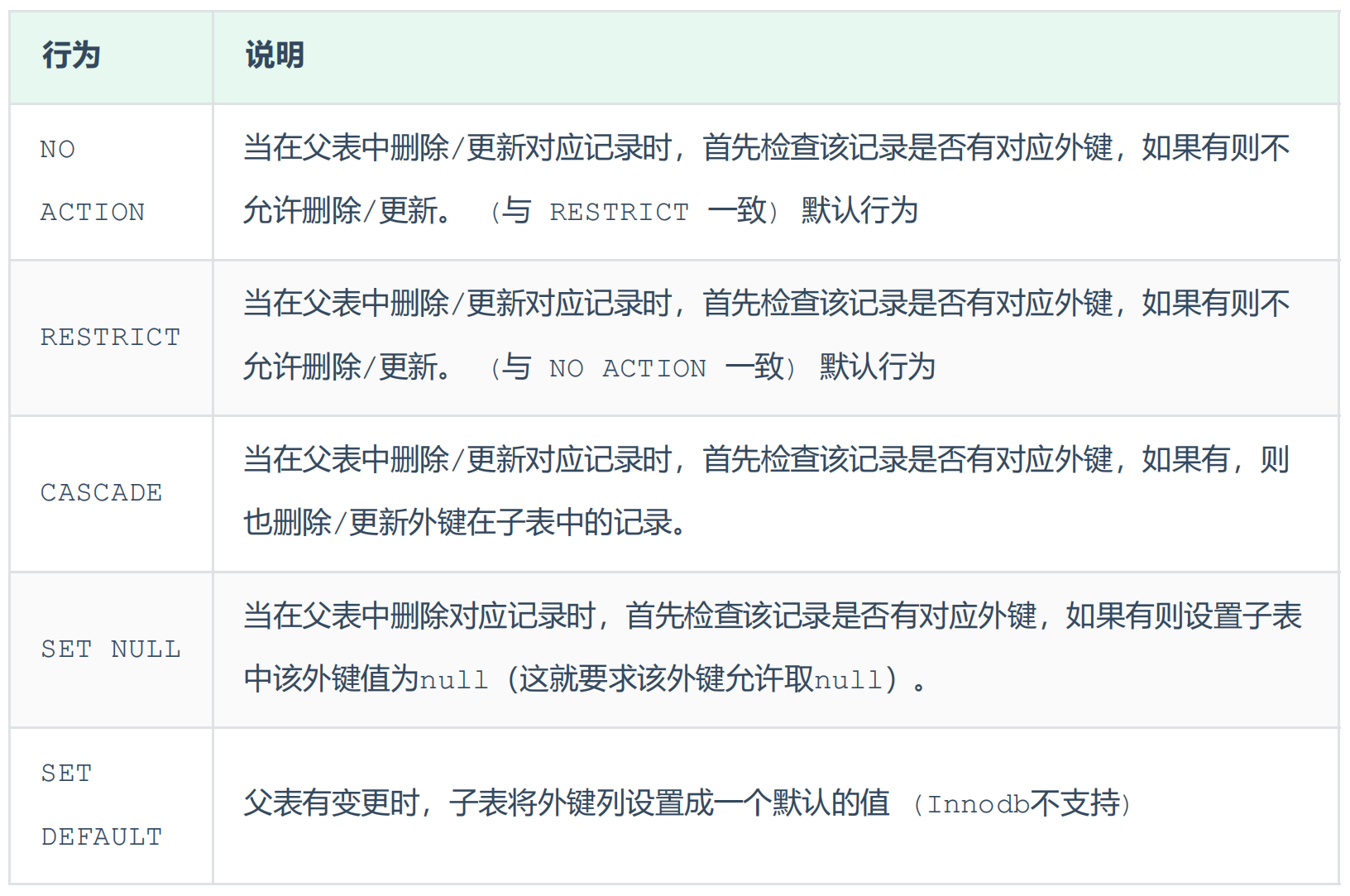
具体语法:
-- 完整语法
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段) REFERENCES 主表名 (主表字段名) ON UPDATE CASCADE ON DELETE CASCADE;
-- 示例
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id) on update cascade on delete cascade ;当对id为1的记录进行修改时:

多表查询
数据库的多表关系:
- 一对一
- 一对多
- 多对多
连接查询的分类:
- 内连接:相当于查询A、B交集部分数据
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
内连接
-- 隐式内连接
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
-- 显式内连接
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;
-- 示例
select e.name,d.name from emp e , dept d where e.dept_id = d.id; -- 查询每一个员工的姓名 , 及关联的部门的名称 (隐式内连接实现)
select e.name, d.name from emp e join dept d on e.dept_id = d.id; -- 查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接实现)外连接
-- 左外连接
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;
-- 右外连接
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;
-- 示例
select e.*, d.name from emp e left join dept d on e.dept_id = d.id; -- 查询emp表的所有数据, 和对应的部门信息
select d.*, e.* from emp e right join dept d on e.dept_id = d.id; -- 查询dept表的所有数据, 和对应的员工信息(右外连接)自连接查询
-- 全部语法
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;
-- 示例
select a.name , b.name from emp a , emp b where a.managerid = b.id; -- 查询员工 及其 所属领导的名字
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id; -- 查询所有员工 emp 及其领导的名字 emp , 如果员工没有领导, 也需要查询出来在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段。
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
-- 语法
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );
-- 示例
select * from emp where dept_id = (select id from dept where name = '销售部'); -- 查询 "销售部" 的所有员工信息
select * from emp where entrydate > (select entrydate from emp where name = '方东白'); -- 查询在 "方东白" 入职之后的员工信息列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
-- 示例
select * from emp where salary > all ( select salary from emp where dept_id = (select id from dept where name = '财务部') ); -- 查询比 财务部 所有人工资都高的员工信息
select * from emp where salary > any ( select salary from emp where dept_id = (select id from dept where name = '研发部') ); -- 查询比研发部其中任意一人工资高的员工信息行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
-- 示例
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = '张无忌'); -- 查询与 "张无忌" 的薪资及直属领导相同的员工信息 ;表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
-- 示例
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ; -- 查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息事务
事务 是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
-- 开启事务
start transaction
-- 1. 查询张三余额
select * from account where name = '张三';
-- 2. 张三的余额减少1000
update account set money = money - 1000 where name = '张三';
-- 3. 李四的余额增加1000
update account set money = money + 1000 where name = '李四';
-- 如果正常执行完毕, 则提交事务
commit;
-- 如果执行过程中报错, 则回滚事务
-- rollback;事务的四大特性(ACID)
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
并发事务问题
赃读:一个事务读到另外一个事务还没有提交的数据。
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读。
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了 "幻影"。
事务隔离级别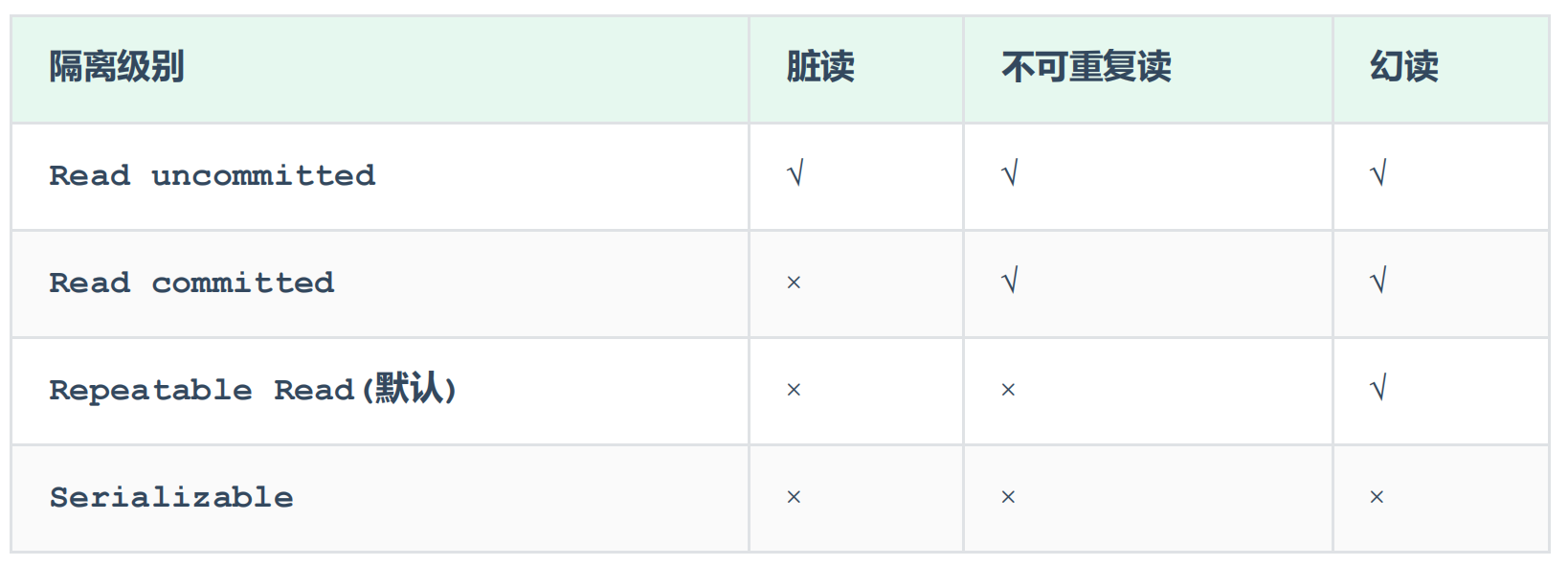
进阶篇
主要是MySQL索引、通过索引对SQL语句进行优化,事务底层原理和MVCC,之前都有专门的博客
MySQL索引:https://blog.csdn.net/Satoru000/article/details/147897956?spm=1001.2014.3001.5501![]() https://blog.csdn.net/Satoru000/article/details/147897956?spm=1001.2014.3001.5501 SQL优化:
https://blog.csdn.net/Satoru000/article/details/147897956?spm=1001.2014.3001.5501 SQL优化:
https://blog.csdn.net/Satoru000/article/details/147927247?spm=1001.2014.3001.5501![]() https://blog.csdn.net/Satoru000/article/details/147927247?spm=1001.2014.3001.5501 事务和MVCC详解: https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501
https://blog.csdn.net/Satoru000/article/details/147927247?spm=1001.2014.3001.5501 事务和MVCC详解: https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501![]() https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501
https://blog.csdn.net/Satoru000/article/details/148056317?spm=1001.2014.3001.5501
运维篇
二进制日志
binlog记录的是数据库所有的能影响数据库的语句(不包括select和show),可以用于主从复制时给从库做数据的拷贝
具体的数据格式:
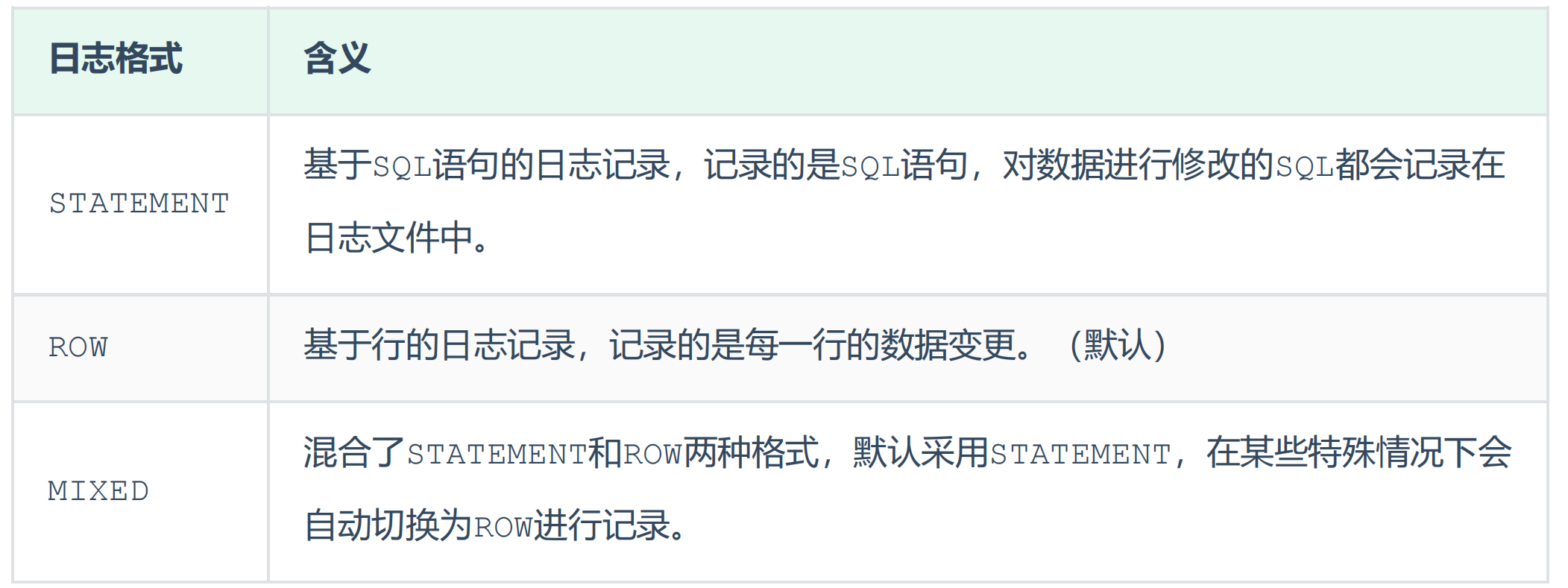
binlog如果数据量太大可以定期进行删除或者手动进行删除
慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为10秒,最小为 0, 精度可以到微秒。
开启慢查询日志需要再配置文件中进行配置
#慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2注意:这样配置的慢查询日志只会记录使用了索引并且超出范围的语句,也不会记录管理语句,所以要追加配置
#记录执行较慢的管理语句
log_slow_admin_statements =1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes = 1主从复制原理
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
主从复制的优点:
- 高可用,主库出现问题可以切换到从库
- 可以实现读写分离,减少数据库的访问压力
- 从库可以进行备份操作,提高效率
主从复制的原理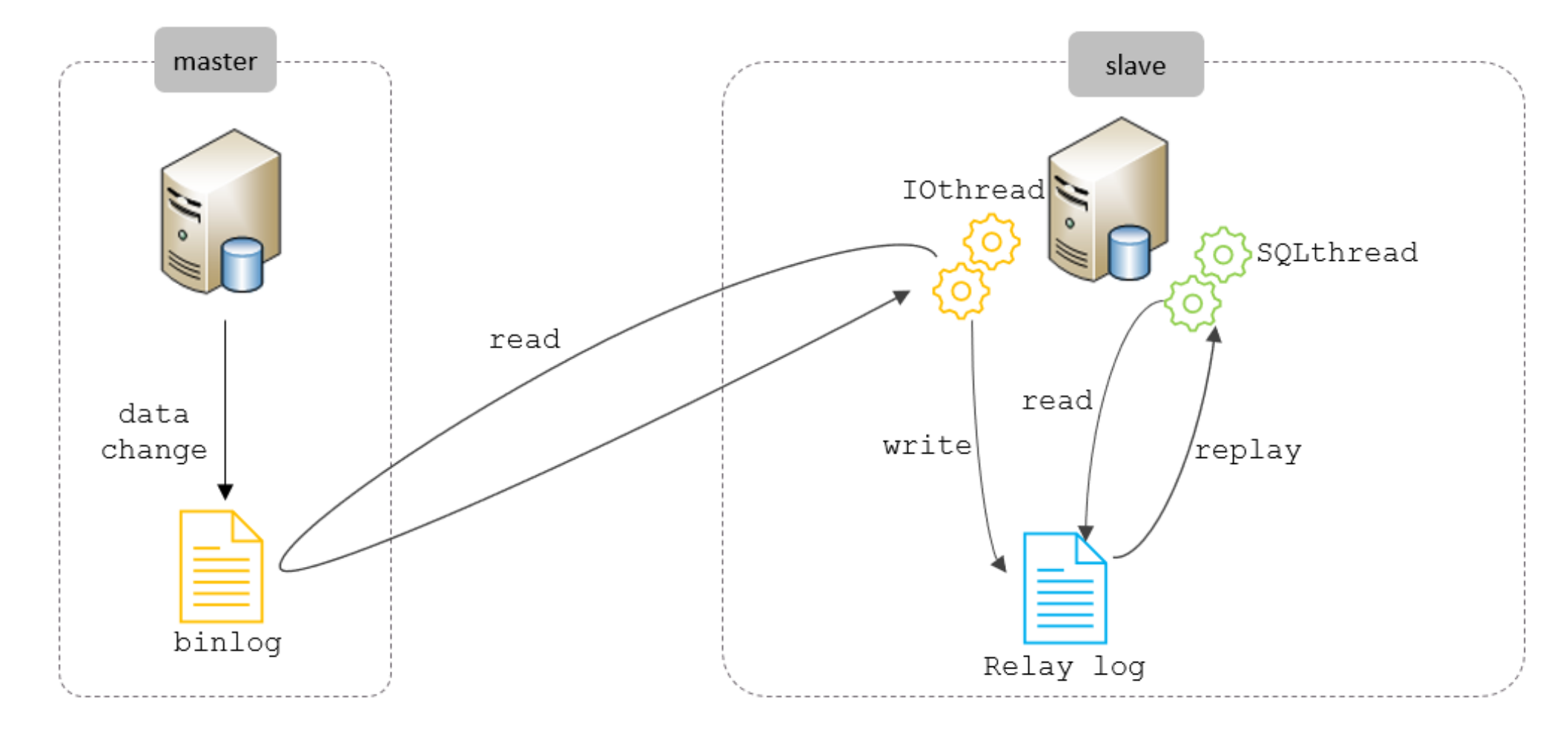
master将DDL和DML语句保存到binlog文件中,从库通过IO线程读取binlog文件到Relay log,再通过一个后台的SQL线程进行复制
主从复制搭建
主库的配置:
- 在配置文件中追加配置
- 重启MySQL服务
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01从库的配置:
- 在配置文件中追加配置
- 重启MySQL服务
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 – 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写
read-only=1建立主库和从库的链接
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='itcast',
SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000004',
SOURCE_LOG_POS=663;source_host:主库的ip地址
source_user:连接主库的用户名
source_password:连接主库的密码
source_log_file:主库同步到从库的binlog文件
source_log_pos:从binlog进行同步的位置
分库分表
垂直拆分
垂直分库: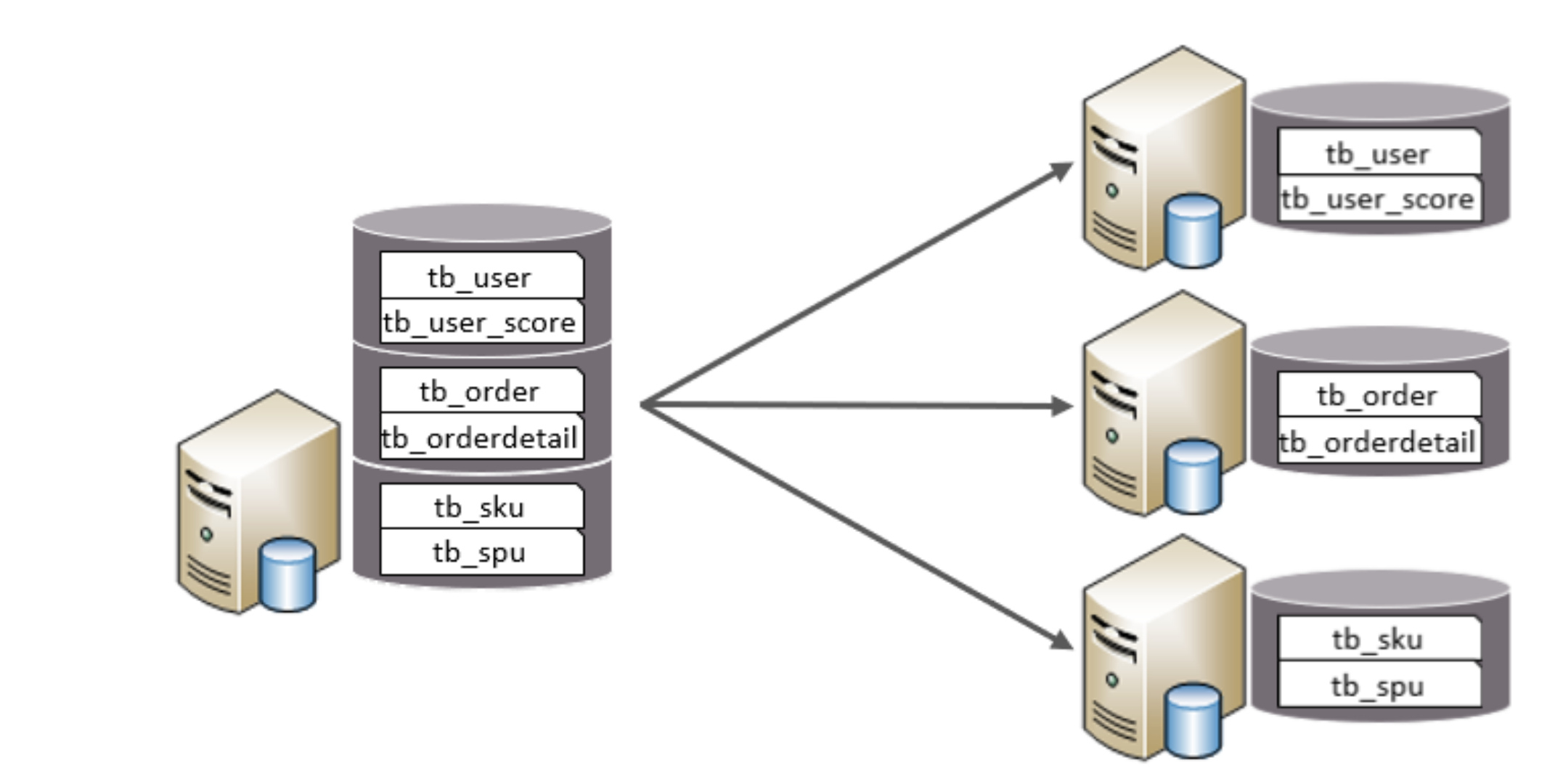
将一个数据库中的所有表都拆分到多个数据库中,若干个表分配到一个数据库中,这样每个数据库中的表就能代表不同的业务
所以垂直分库中:
- 每个数据库的表结构都不同
- 每个数据库中的数据都不同
- 所有数据库全部加在一起就是全部的数据
垂直分表:
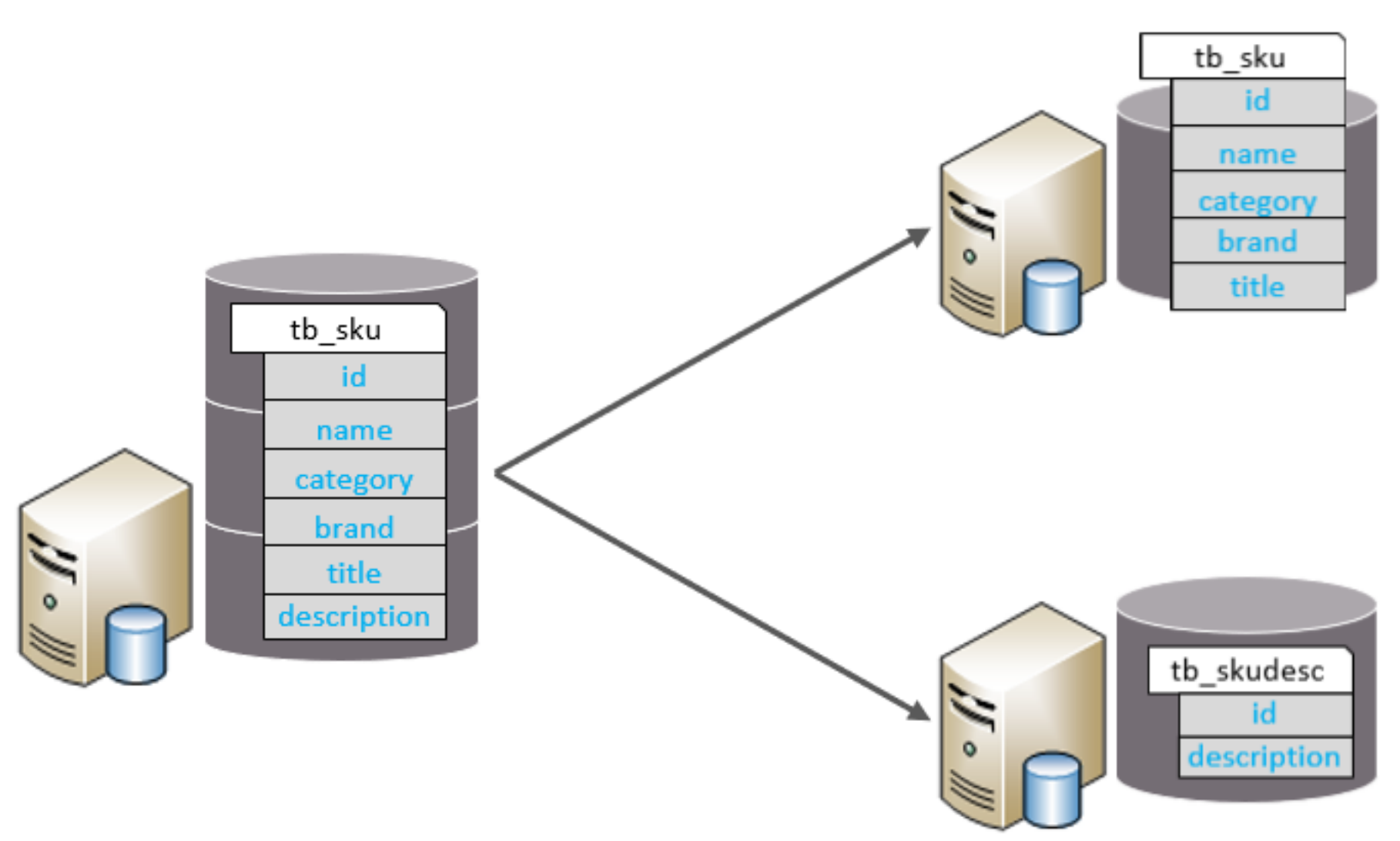
既然知道了垂直分库,那么垂直分表也差不多,只不过比数据库低了一级,就是将数据库中的字段拆分到不同的表中,然后再将这些表分配到不同的数据库中。
所以垂直分表的特点:
- 每个表的结构都不一样。
- 每个表的数据也不一样,一般通过一列(主键/外键)关联。
- 所有表的并集是全量数据。
水平拆分
水平分库: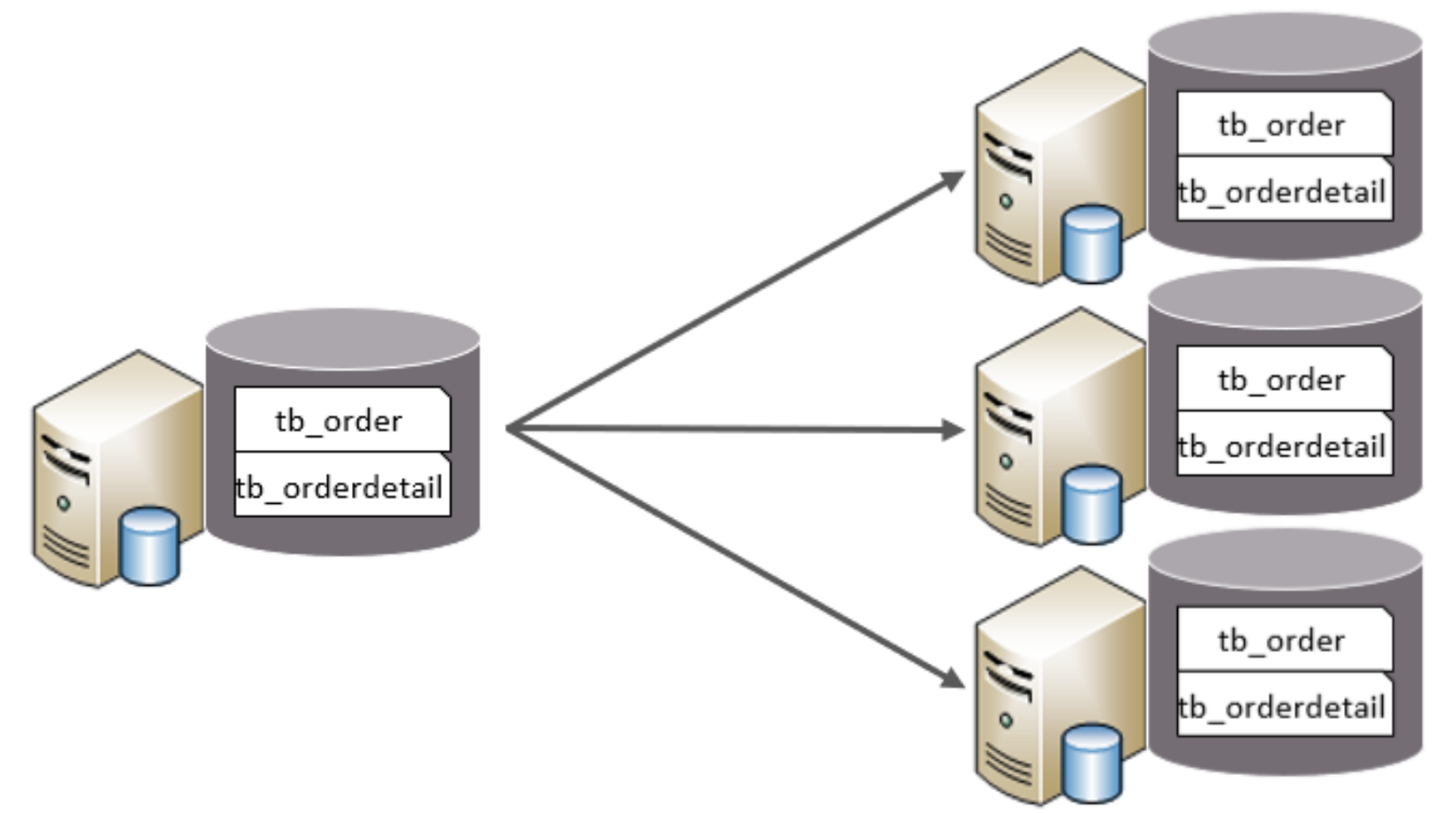
就是将数据库中表的数据分配到不同的数据库中,但是每个数据库中表的数据都只占原有表数据的一部分
所以水平分库的特点:
- 所有数据库表的结构都一样
- 每个数据库表中的数据都不一样
- 每个数据库表中的数据之和就是原来数据库表中的全部数据
水平分表: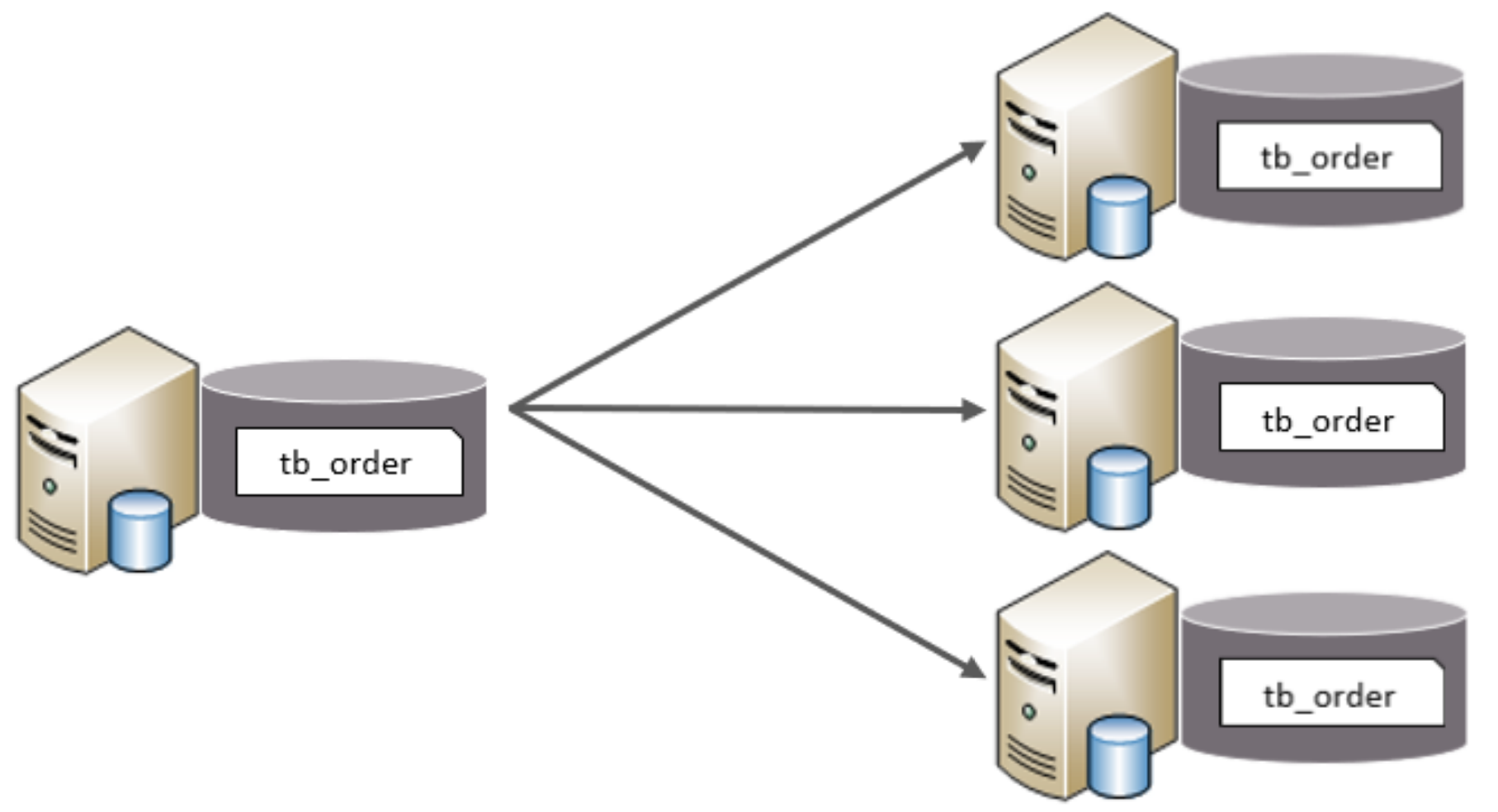
和水平分库同理,水平分库是将数据库中所有的表进行拆分,那么水平分表就是只将这张表的数据进行拆分,分配到各个数据库中
水平分表的特点:
- 每个表的表结构都一样。
- 每个表的数据都不一样。
- 所有表的并集是全量数据。
MyCat入门
MyCat概述
MyCat是一个数据库中间件,用户之前是直接访问MySQL,加入了MyCat后就是访问MyCat,再由MyCat路由到对应的MySQL服务。Mycat是开源的、活跃的、基于Java语言编写的MySQL数据库中间件。可以像使用mysql一样来使用mycat,对于开发人员来说根本感觉不到mycat的存在。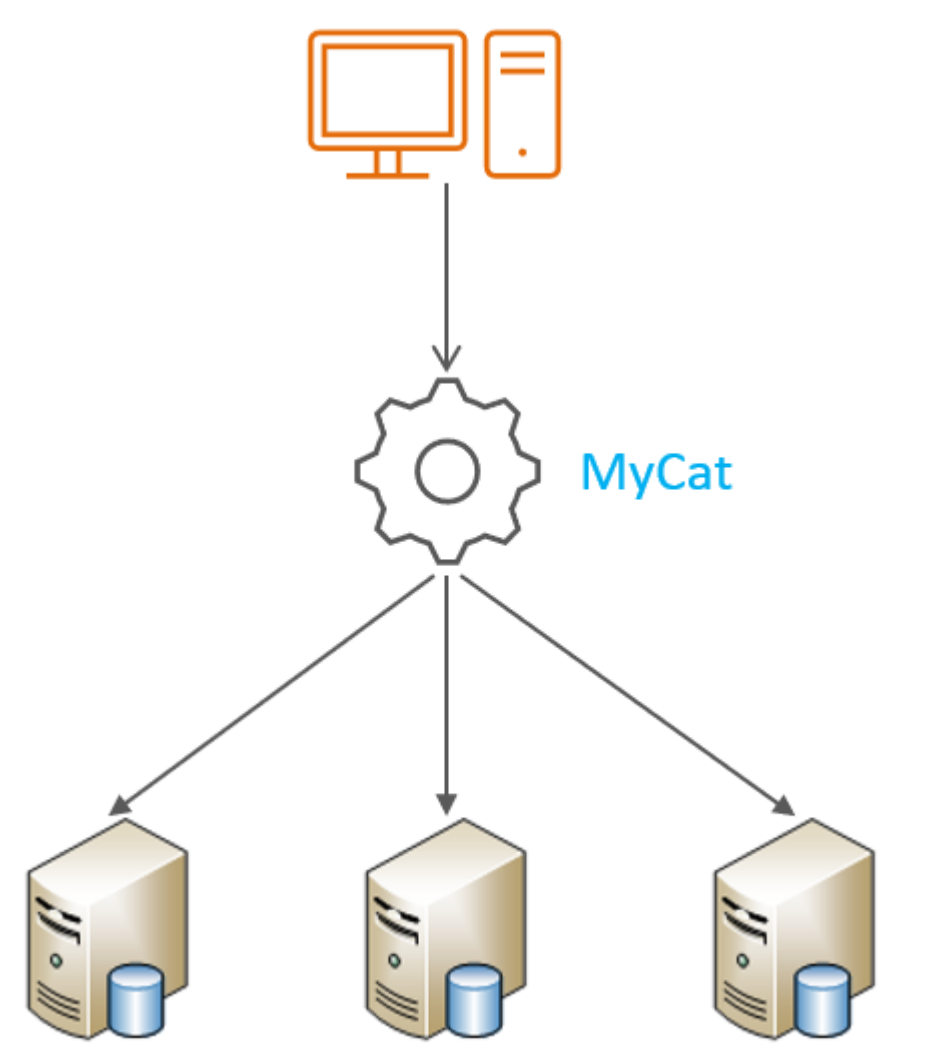
mycat的结构大致如下

MyCat配置
在schema.xml中配置逻辑库、逻辑表、数据节点、节点主机等相关信息。具体的配置如下:
table标签:逻辑表
dataNode标签:数据节点
rule:分片规则
dataHost:连接的MySQL主机的信息
writeHost:读写分离的标签,这里是标记主节是读主机,用于读写分离,这里只用于标记没有实现读写分离
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="DB01" checkSQLschema="true" sqlMaxLimit="100">
<table name="TB_ORDER" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="db01"/>
<dataNode name="dn2" dataHost="dhost2" database="db01"/>
<dataNode name="dn3" dataHost="dhost3" database="db01"/>
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>
</mycat:schema>需要在server.xml中配置用户名、密码,以及用户的访问权限信息,具体的配置如下:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">DB01</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="true">
<schema name="DB01" dml="0110">
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">DB01</property>
<property name="readOnly">true</property>
</user>MyCat实现垂直拆分
在业务系统中, 涉及以下表结构 ,但是由于用户与订单每天都会产生大量的数据, 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分, 原有的数据库表如下
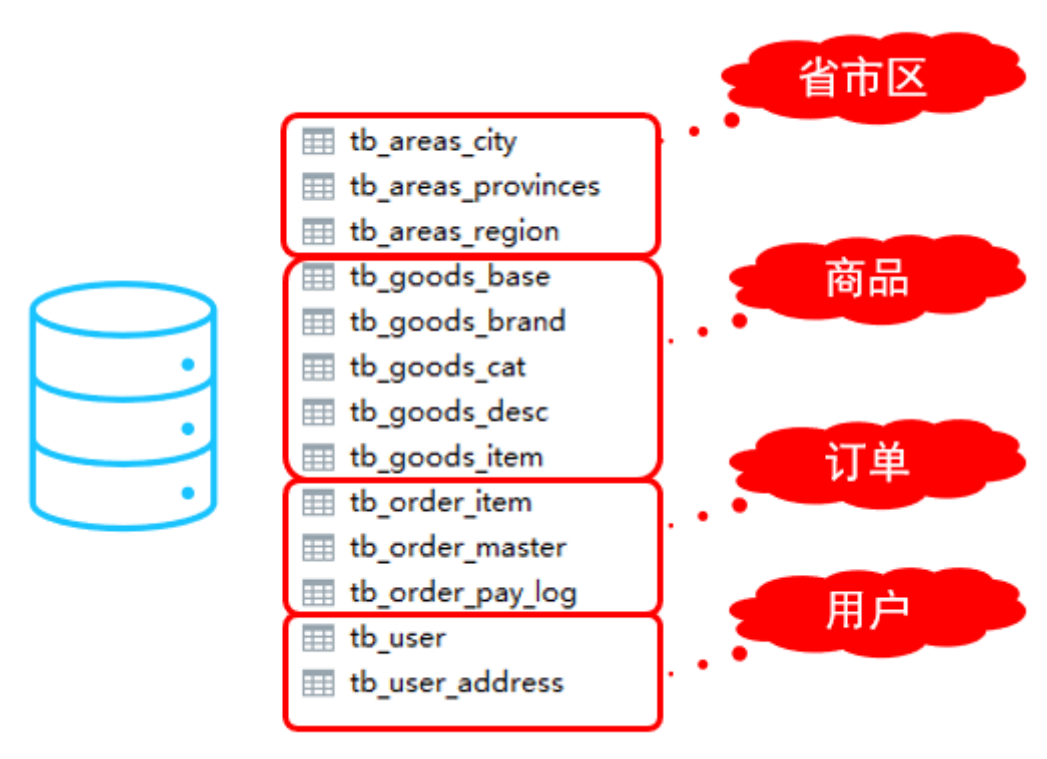
然后对数据库中的表进行垂直拆分得到以下的结构
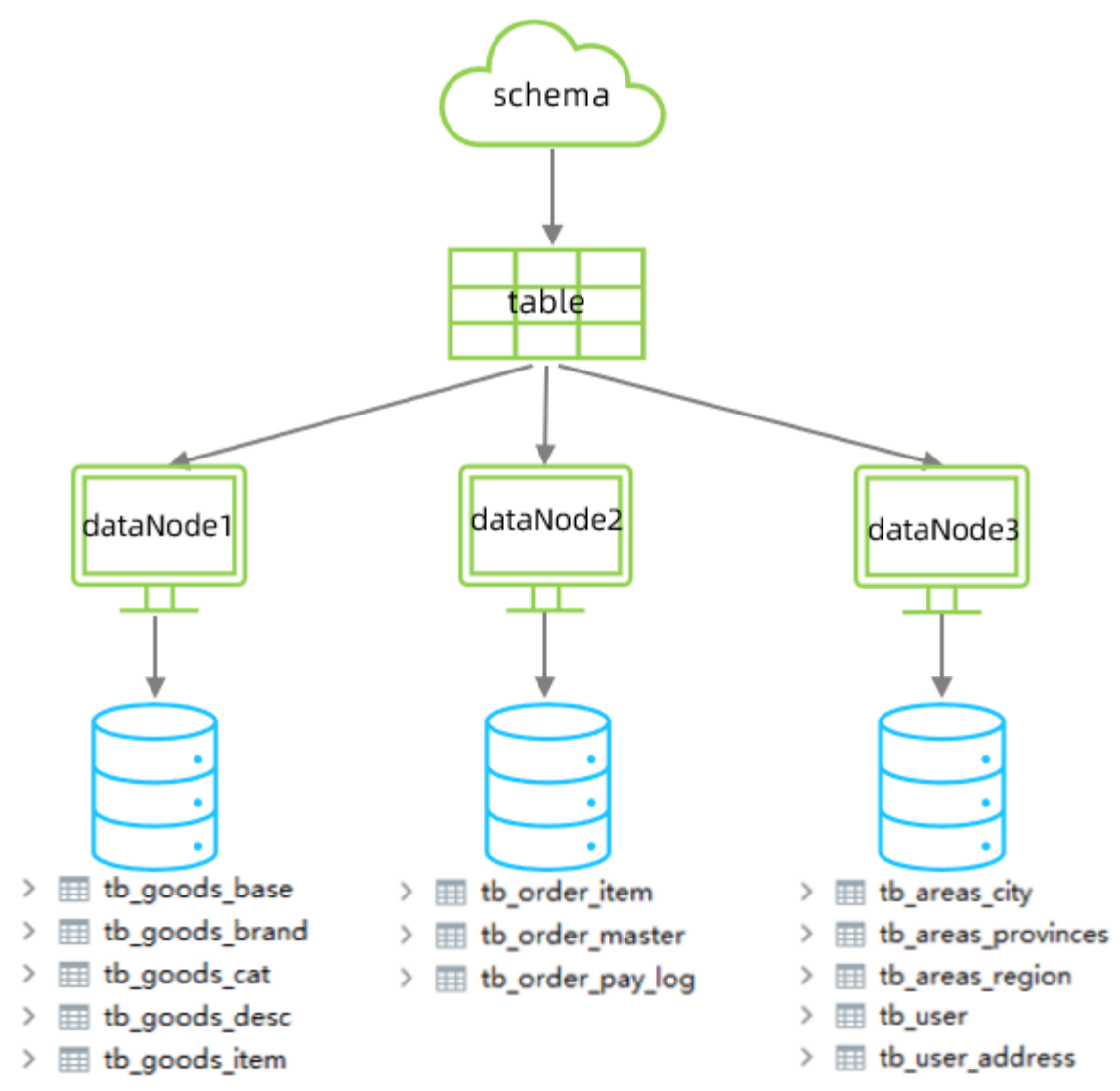
schema.xml的配置如下
1、在虚拟库中配置虚拟表
2、配置数据节点dn1、dn2、dn3
3、配置数据节点跟数据库的链接
<schema name="SHOPPING" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_goods_base" dataNode="dn1" primaryKey="id"/>
<table name="tb_goods_brand" dataNode="dn1" primaryKey="id"/>
<table name="tb_goods_cat" dataNode="dn1" primaryKey="id"/>
<table name="tb_goods_desc" dataNode="dn1" primaryKey="goods_id"/>
<table name="tb_goods_item" dataNode="dn1" primaryKey="id"/>
<table name="tb_order_item" dataNode="dn2" primaryKey="id"/>
<table name="tb_order_master" dataNode="dn2" primaryKey="order_id"/>
<table name="tb_order_pay_log" dataNode="dn2" primaryKey="out_trade_no"/>
<table name="tb_user" dataNode="dn3" primaryKey="id"/>
<table name="tb_user_address" dataNode="dn3" primaryKey="id"/>
<table name="tb_areas_provinces" dataNode="dn3" primaryKey="id"/>
<table name="tb_areas_city" dataNode="dn3" primaryKey="id"/>
<table name="tb_areas_region" dataNode="dn3" primaryKey="id"/>
</schema>
<dataNode name="dn1" dataHost="dhost1" database="shopping"/>
<dataNode name="dn2" dataHost="dhost2" database="shopping"/>
<dataNode name="dn3" dataHost="dhost3" database="shopping"/>
<dataHost name="dhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.210:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>
<dataHost name="dhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>
<dataHost name="dhost3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</dataHost>server.xml的配置,赋予root用户操作虚拟库的能力
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">SHOPPING</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="true">
<schema name="DB01" dml="0110">
<table name="TB_ORDER" dml="1110"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">SHOPPING</property>
<property name="readOnly">true</property>
</user>最终的效果
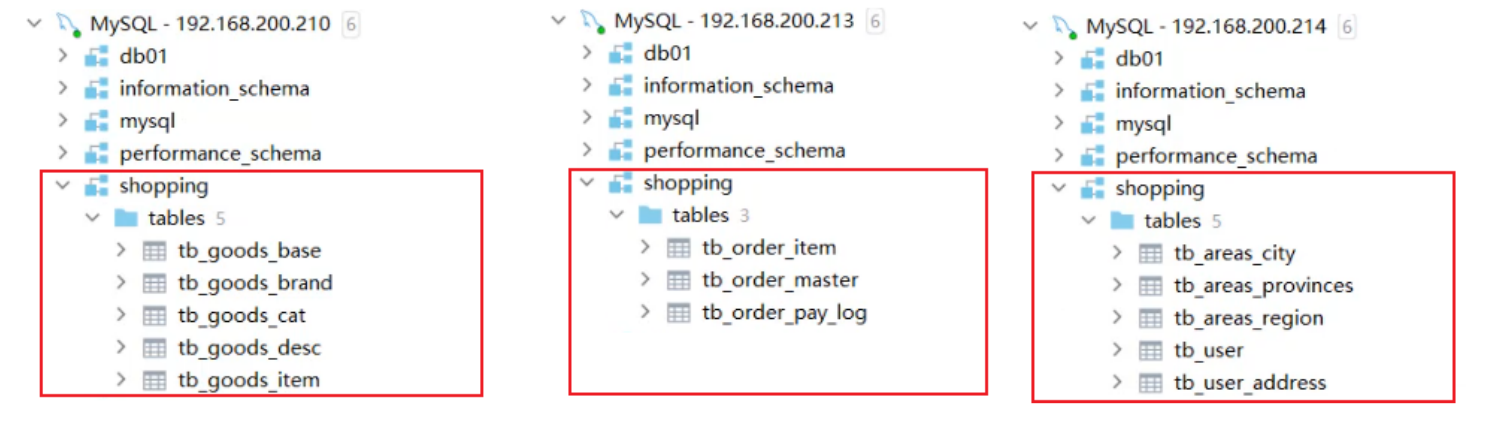
每个数据库进行多表联查是没问题的,但是如果涉及不同库之间的多表联查就不行了,所以可以将一些公共的表抽取成为全局表,改schema.xml中的逻辑表的配置增加 type 属性,配置为global,就代表该表是全局表,就会在所涉及到的dataNode中创建给表。
<table name="tb_areas_provinces" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_city" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/>
<table name="tb_areas_region" dataNode="dn1,dn2,dn3" primaryKey="id"
type="global"/> 最终效果如下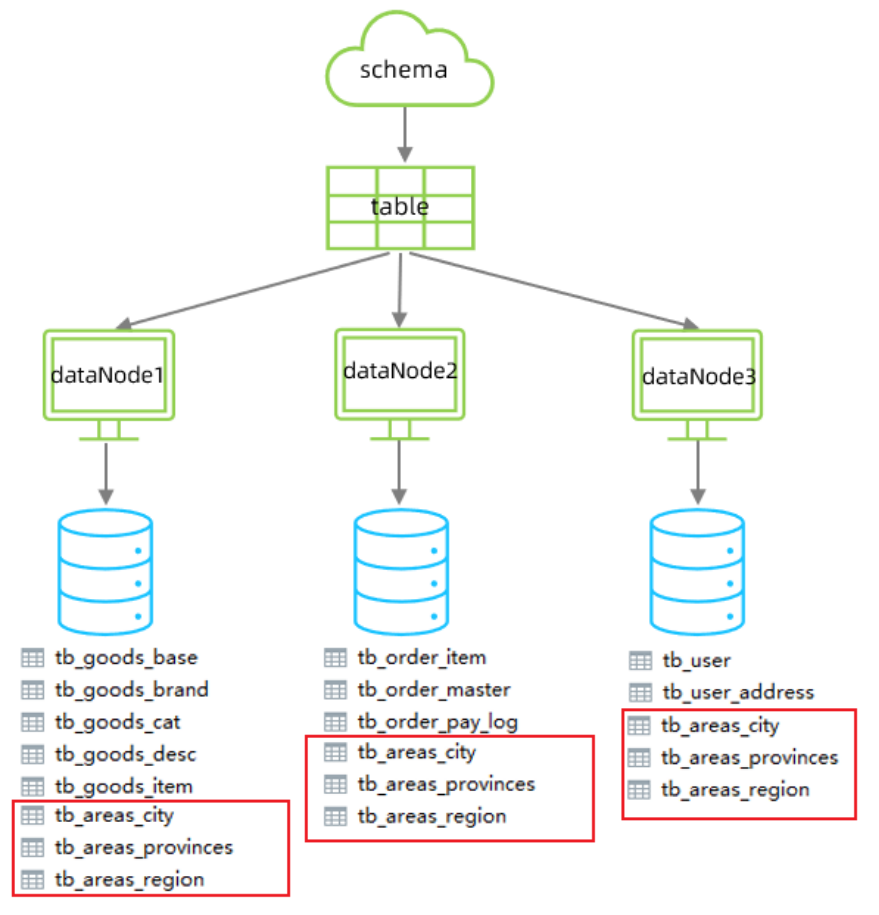
MyCat实现水平拆分
在业务系统中, 有一张表(日志表), 业务系统每天都会产生大量的日志数据 , 单台服务器的数据存储及处理能力是有限的, 可以对数据库表进行拆分
结构如图所示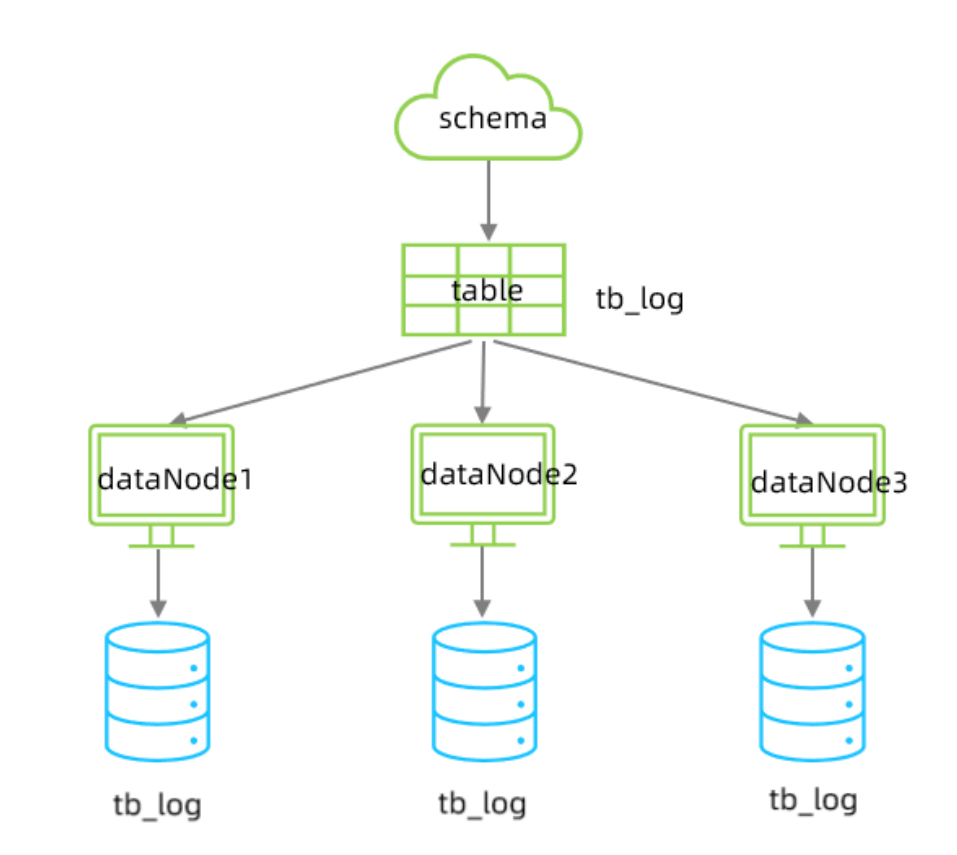
对应的schema.xml文件
<schema name="ITCAST" checkSQLschema="true" sqlMaxLimit="100">
<table name="tb_log" dataNode="dn4,dn5,dn6" primaryKey="id" rule="mod-long"/>
</schema>
<dataNode name="dn4" dataHost="dhost1" database="itcast"/>
<dataNode name="dn5" dataHost="dhost2" database="itcast"/>
<dataNode name="dn6" dataHost="dhost3" database="itcast"/>在将这张表的权限赋予给root用户在server.xml中配置
分片规则
分片规则就是决定你要操作哪个数据库的规则,可以在虚拟表中通过rule来指定,对应的规则可以在rule.xml中进行配置
范围分片
根据指定的字段及其配置的范围与数据节点的对应情况, 来决定该数据属于哪一个分片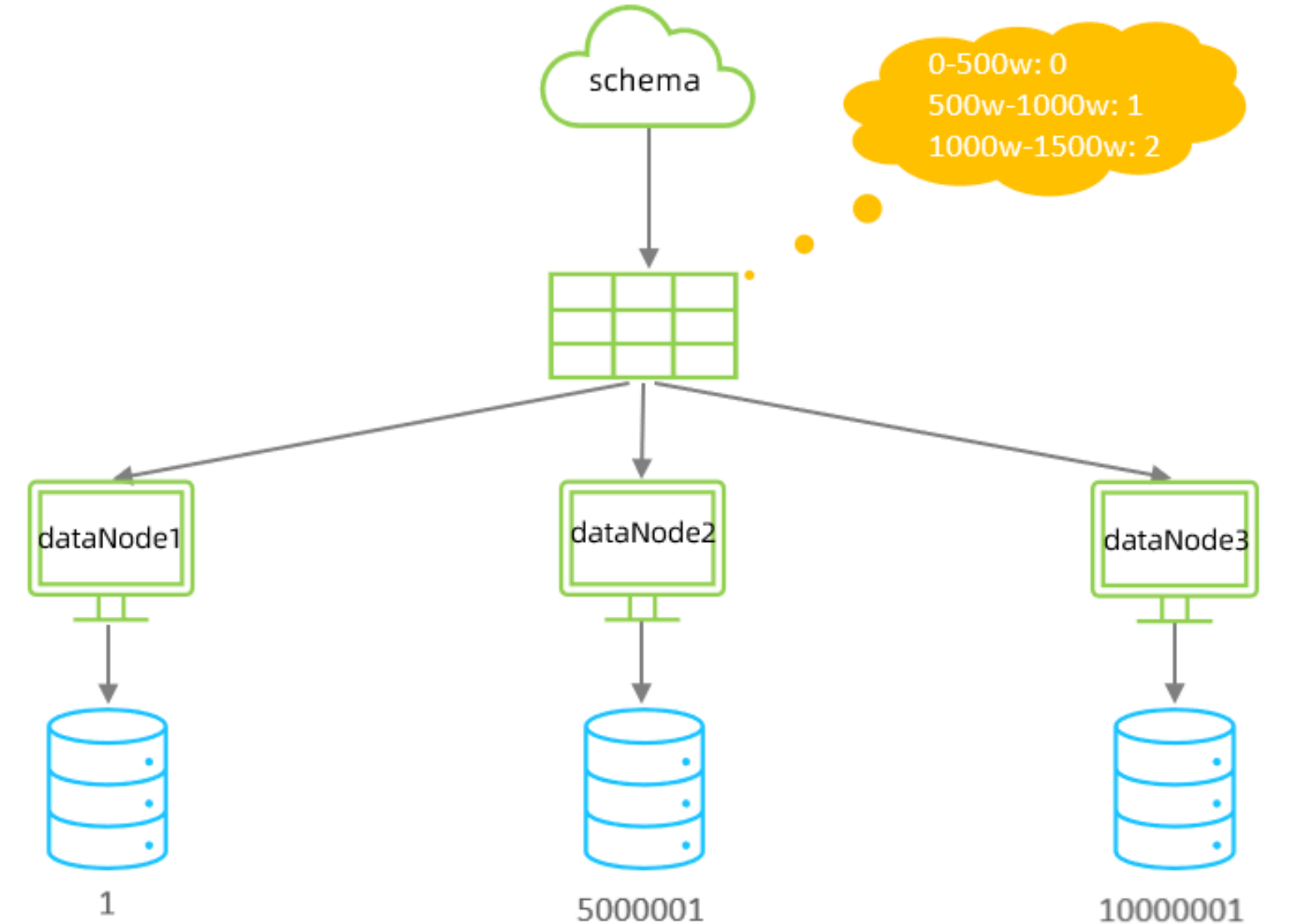
取模分片
根据指定的字段值与节点数量进行求模运算,根据运算结果, 来决定该数据属于哪一个分片。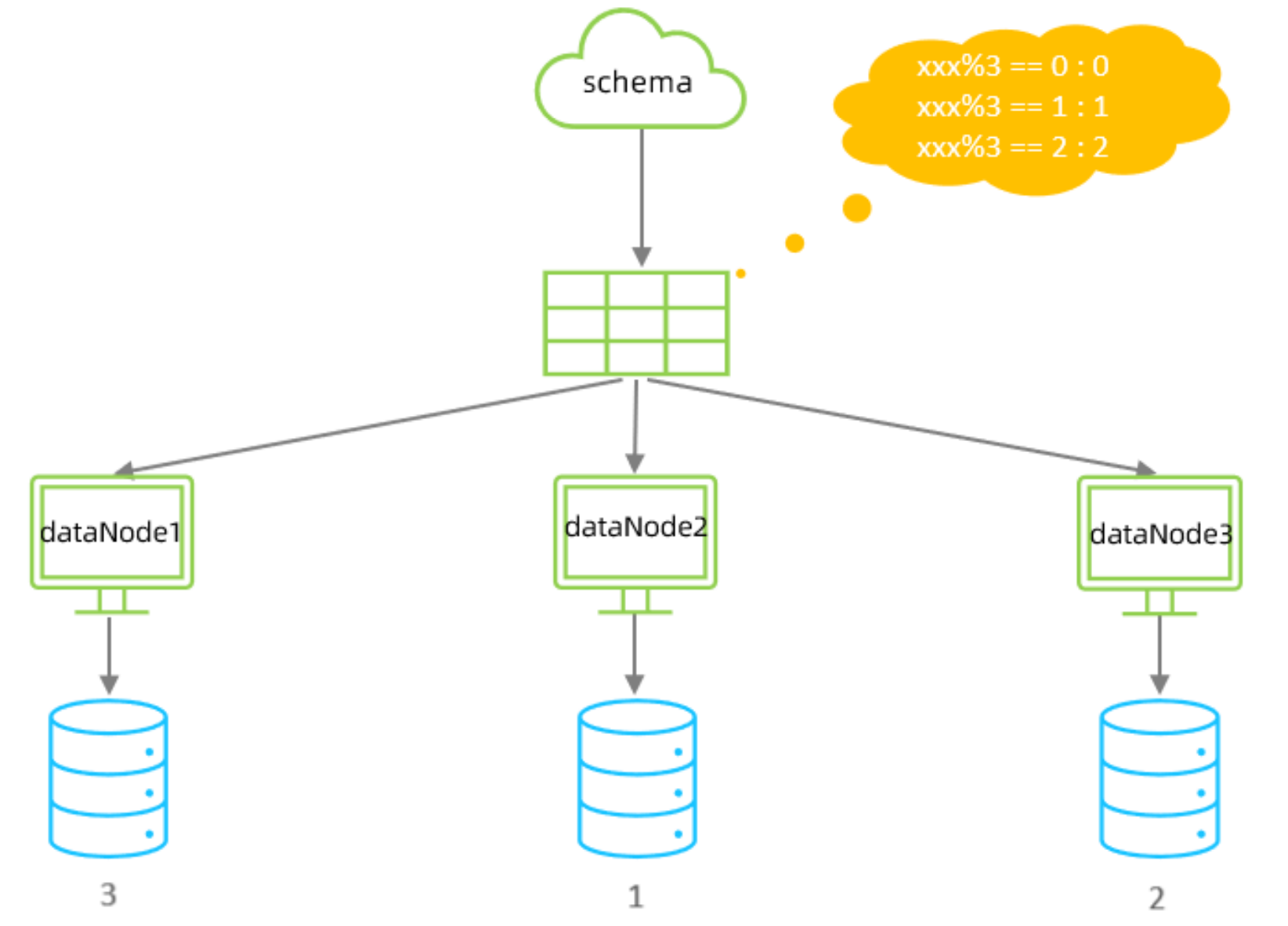
一致性hash分片
相同的哈希因子计算值总是被划分到相同的分区表中,不会因为分区节点的增加而改变原来数据的分区位置,有效的解决了分布式数据的拓容问题。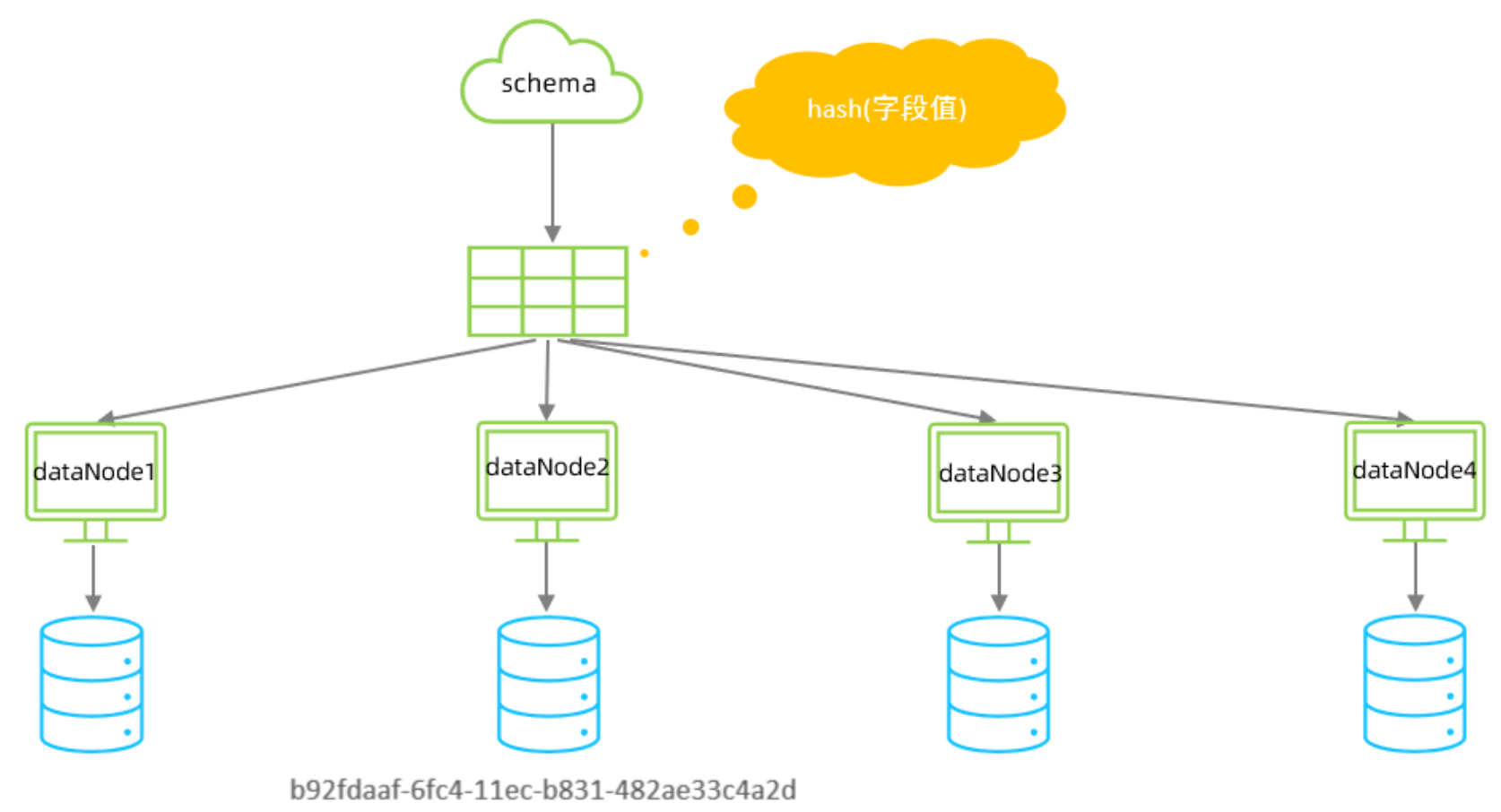
枚举分片
通过在配置文件中配置可能的枚举值, 指定数据分布到不同数据节点上, 主要适用于按照省份、性别、状态拆分数据等业务 。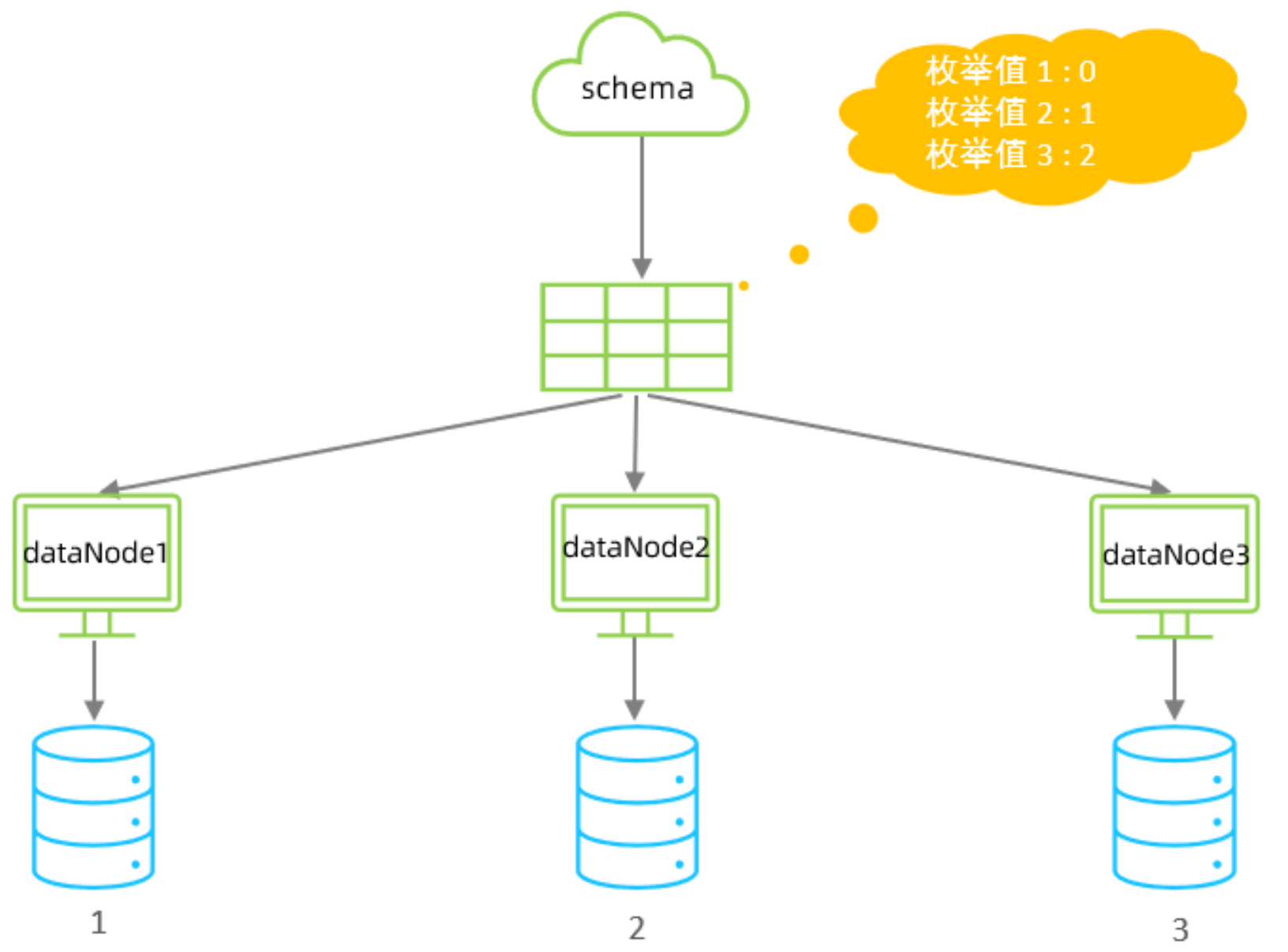
应用指定算法
运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号。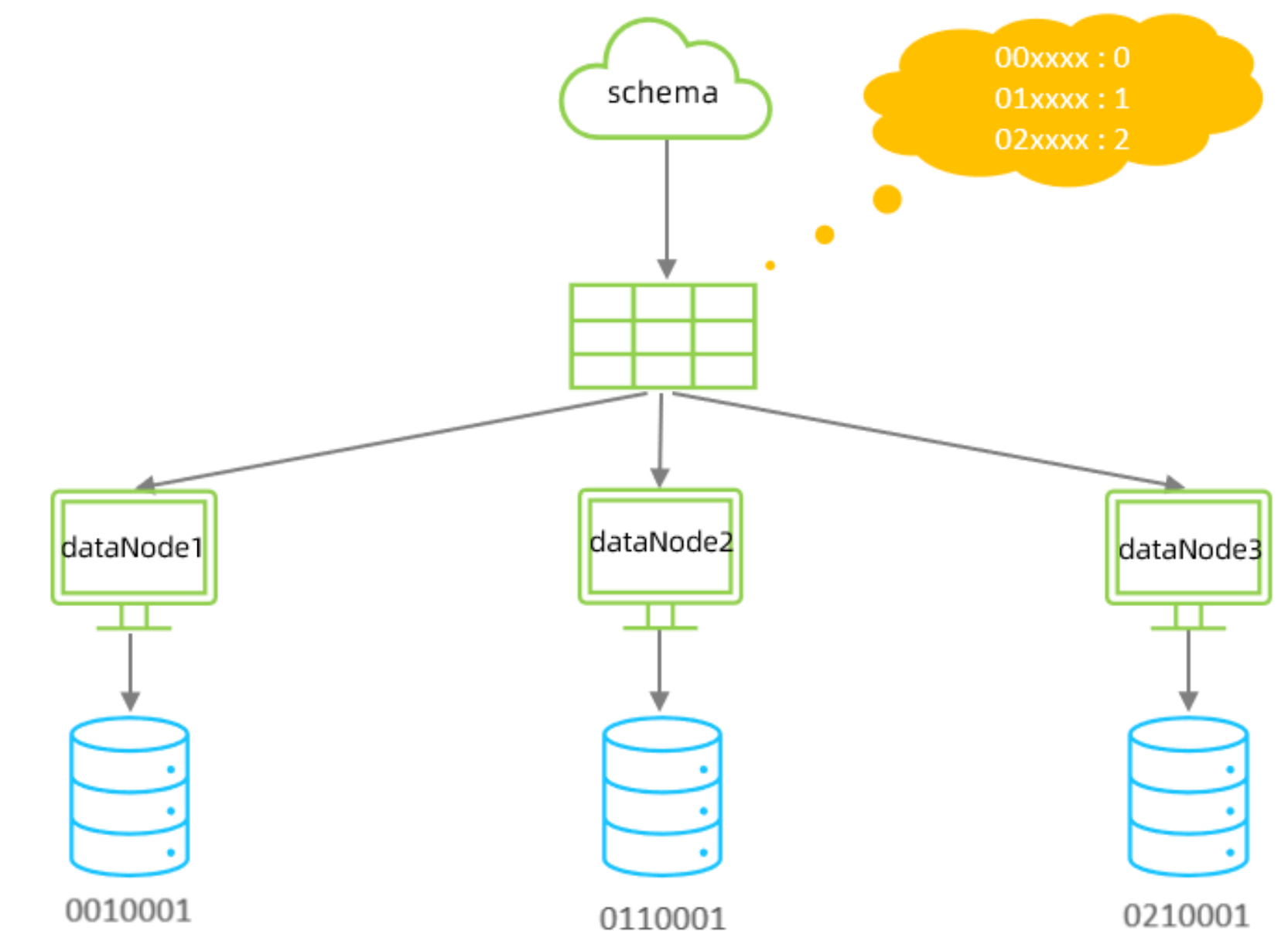
固定分片hash算法
该算法类似于十进制的求模运算,但是为二进制的操作,例如,取 id 的二进制低 10 位 与 1111111111 进行位 & 运算,位与运算最小值为 0000000000,最大值为1111111111,转换为十进制,也就是位于0-1023之间。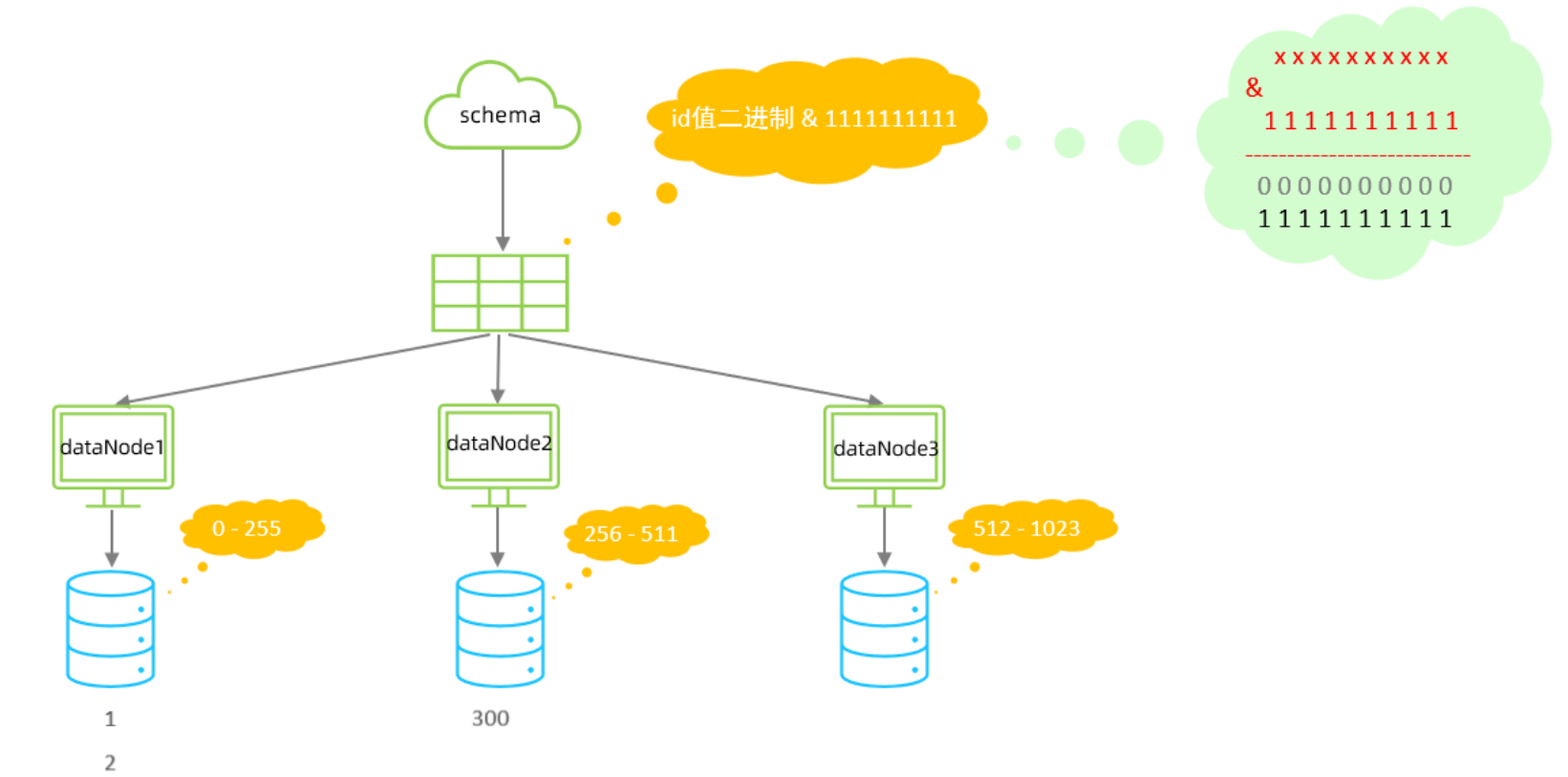
字符串hash解析算法
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片。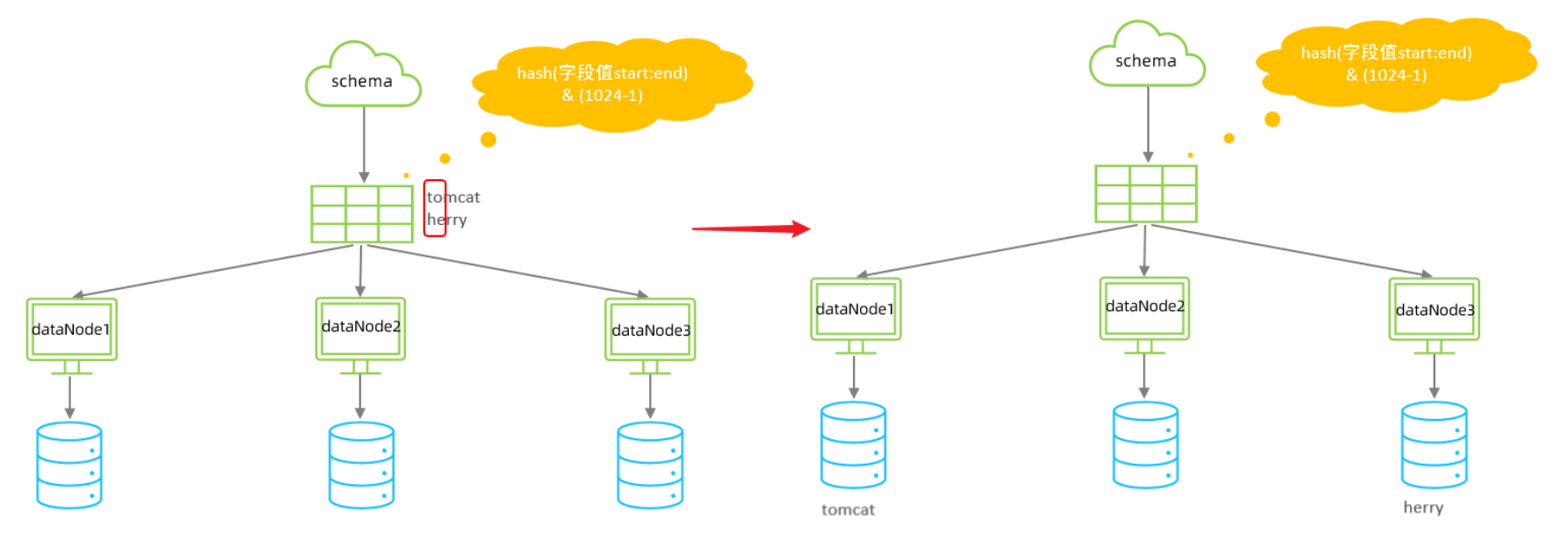
按天分片算法
按照日期及对应的时间周期来分片,如果超出了结束时间则重新计算并分配,例如2022-2-1就会被分配到dataNode1然后以此类推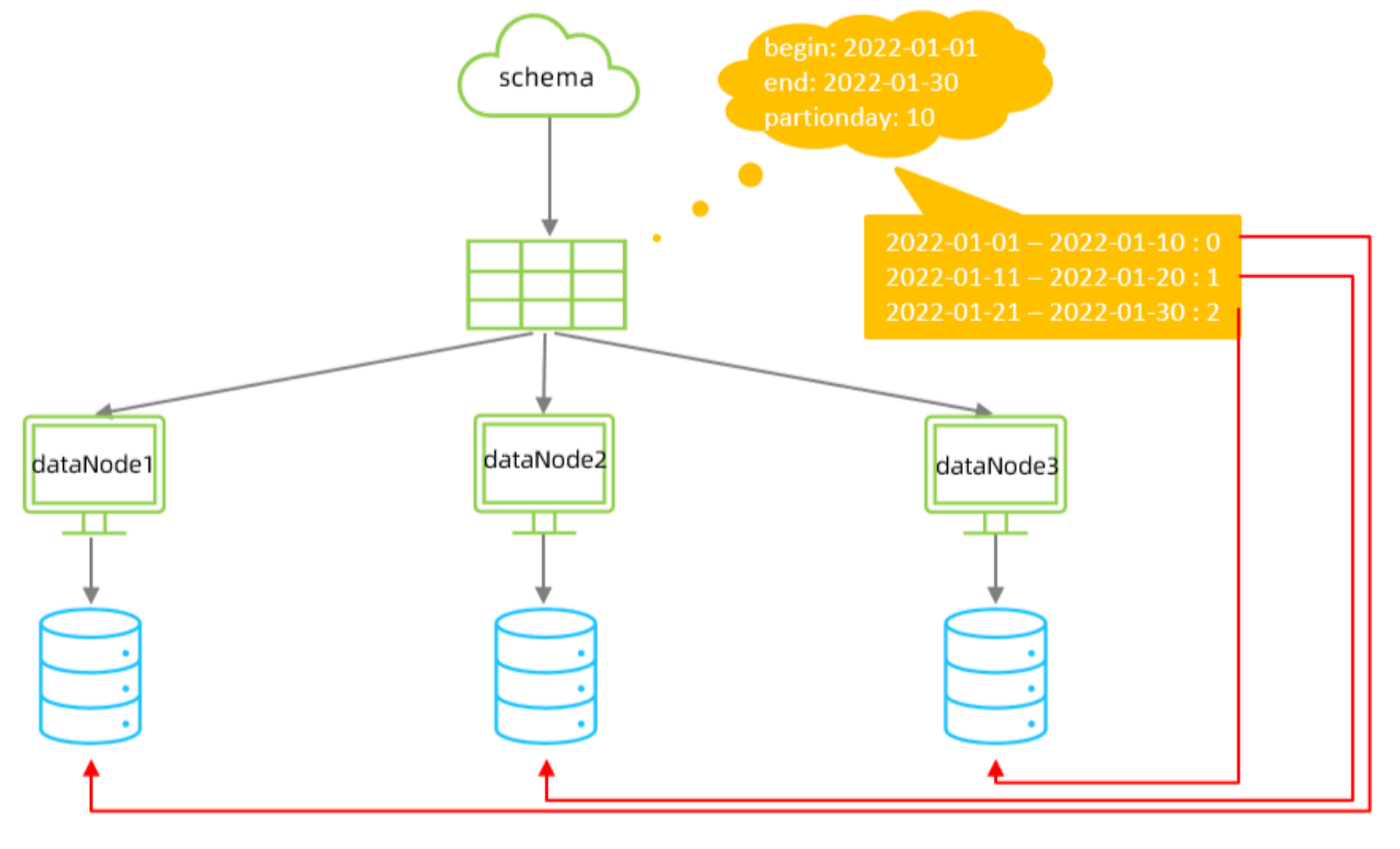
自然月分片
使用场景为按照月份来分片, 每个自然月为一个分片,并且分片的长度必须和数据库的长度一致例如 2022-01-01 到 2022-12-31 ,一共需要12个分片。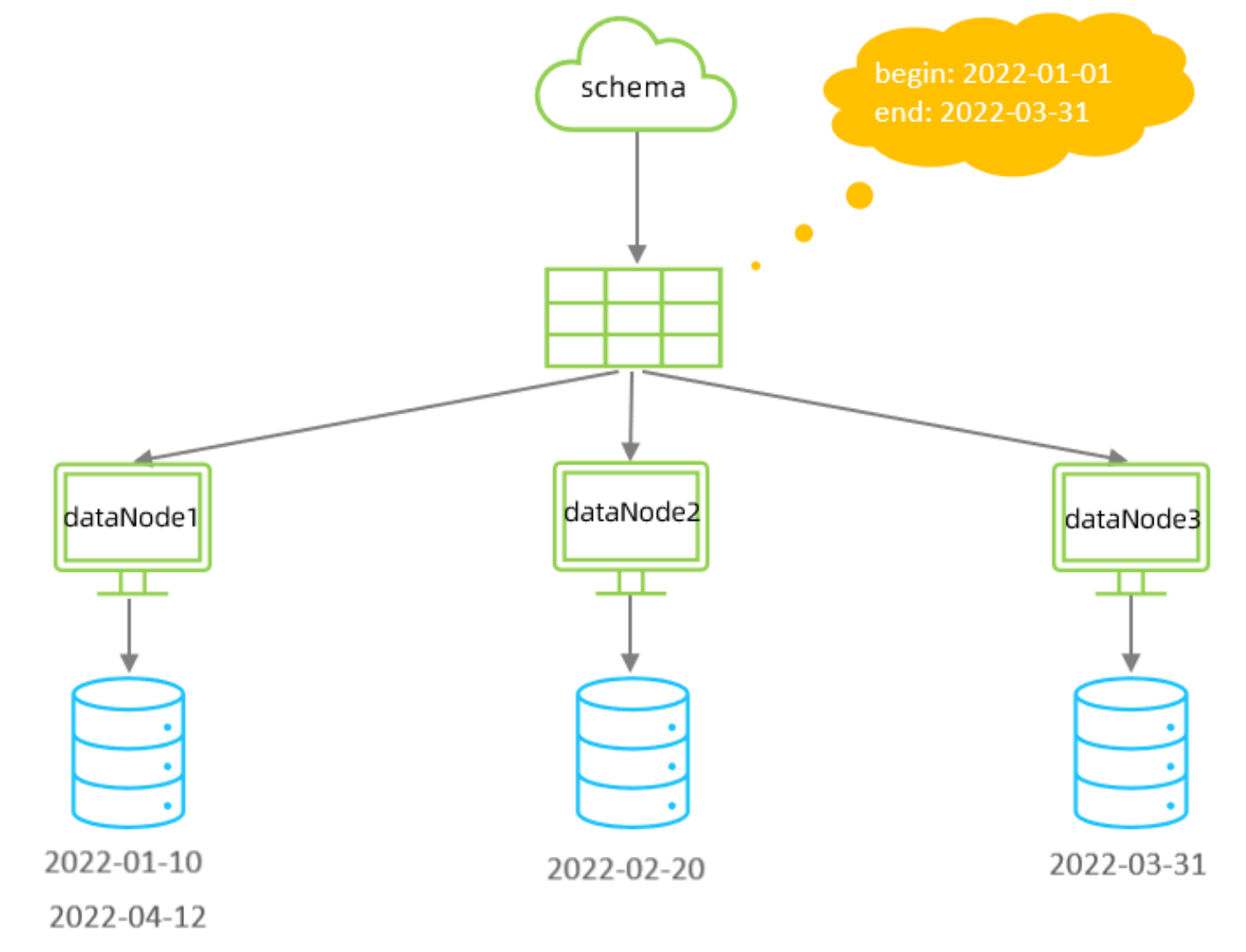
一主一从读写分离
读写分离就是在主从模式中,master节点专门负责写操作,slave节点专门负责读操作,这样能有效降低单台数据库的压力
先在schema,xml中进行配置
<!-- 配置逻辑库 -->
<schema name="ITCAST_RW" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema>
<dataNode name="dn7" dataHost="dhost7" database="itcast"/>
<dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234">
<readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</writeHost>
</dataHost> 关联情况如下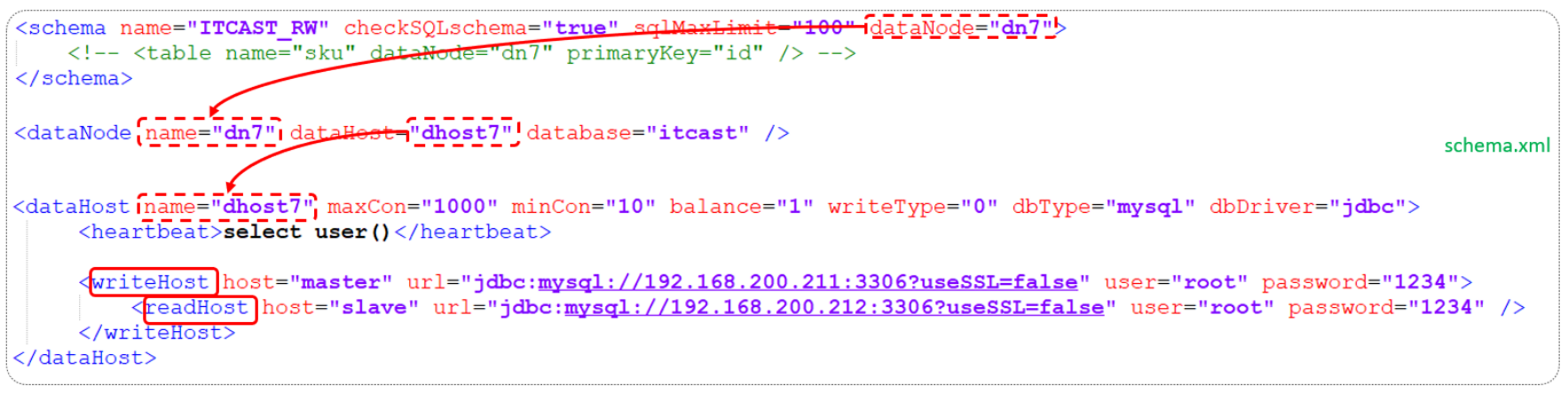
writeHost代表的是写操作对应的数据库,readHost代表的是读操作对应的数据库。 所以我们要想实现读写分离,就得配置writeHost关联的是主库,readHost关联的是从库
配置负载均衡策略balance,下面是对应参数的含义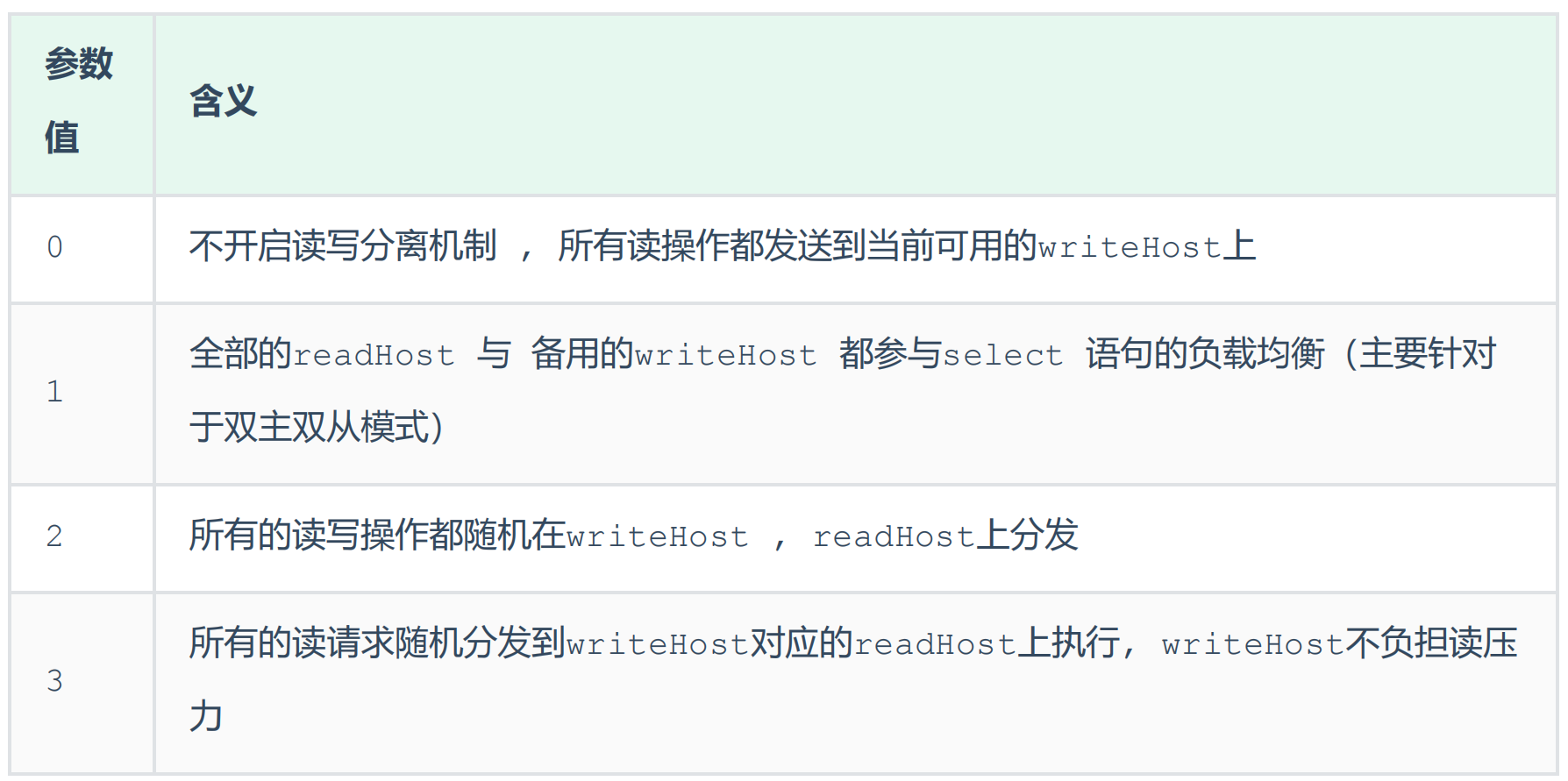
双主双从读写分离
对应的结构图就是这样的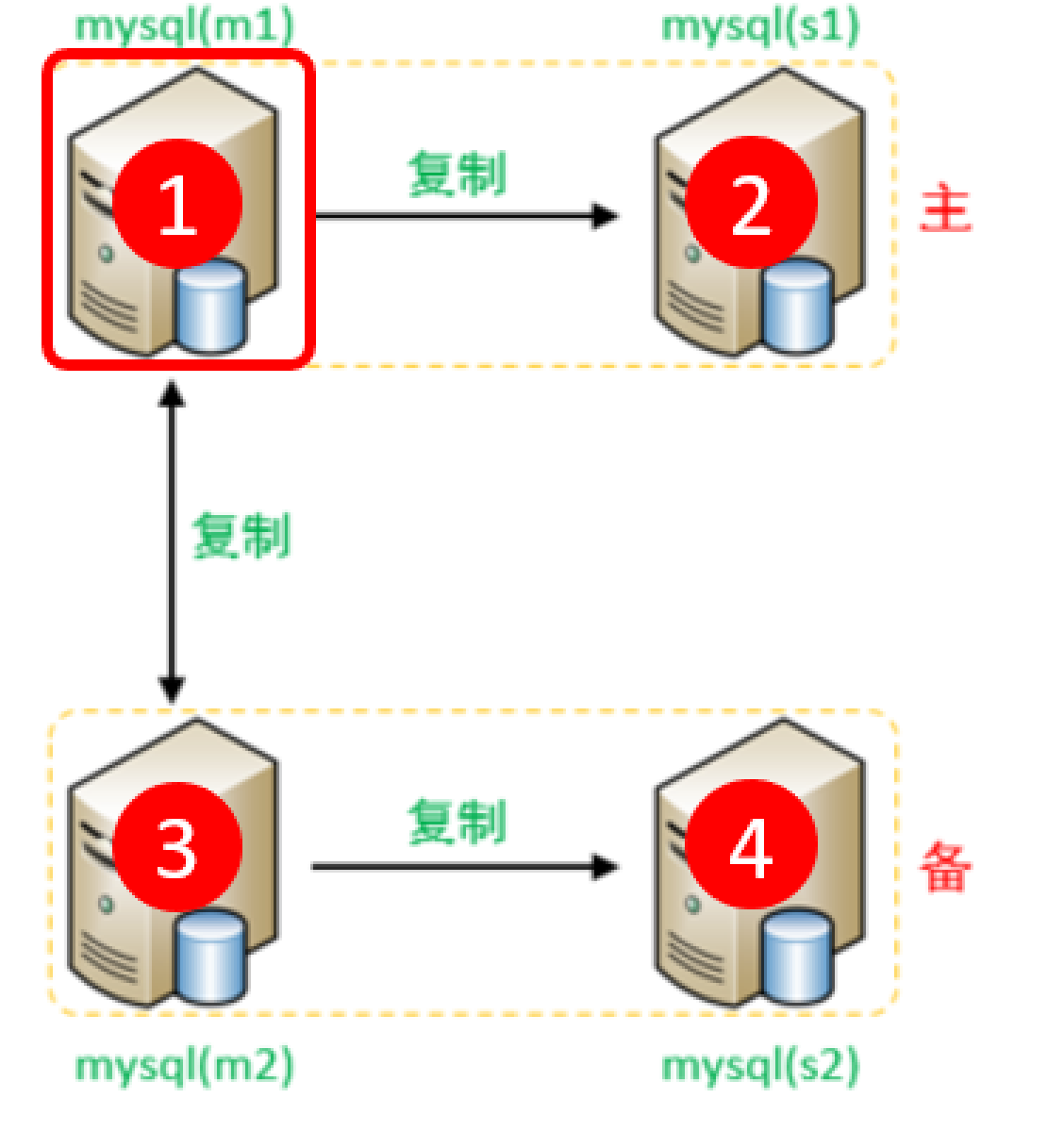
然后先要搭建两个一主一从的节点,按照上面提到的的主从复制的内容搭建
最后将两个主库互相复制,也就是互相成为对方的从库
在m1中执行
CHANGE MASTER TO MASTER_HOST='192.168.200.213', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000002',
MASTER_LOG_POS=663;在m2中执行
CHANGE MASTER TO MASTER_HOST='192.168.200.211', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000002',
MASTER_LOG_POS=663;这样就完成了主库直接的互相复制
然后就是实现读写分离对应的scema.xml
-- 配置逻辑库:
<schema name="ITCAST_RW2" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn7">
</schema>
-- 配置数据节点:
<dataNode name="dn7" dataHost="dhost7" database="db01" />
-- 配置节点主机:
<dataHost name="dhost7" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="jdbc:mysql://192.168.200.211:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234">
<readHost host="slave1" url="jdbc:mysql://192.168.200.212:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</writeHost>
<writeHost host="master2" url="jdbc:mysql://192.168.200.213:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234">
<readHost host="slave2" url="jdbc:mysql://192.168.200.214:3306?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf8" user="root" password="1234"/>
</writeHost>
</dataHost> 对应情况如下
balance="1":
代表全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2 互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡
writeType:
0 : 写操作都转发到第1台writeHost, writeHost1挂了, 会切换到writeHost2上;
1 : 所有的写操作都随机地发送到配置的writeHost上 ;
switchType
-1 : 不自动切换
1 : 自动切换