一、TL;DR
- BPE通过替换相邻最频繁的字符和持续迭代来实现压缩
- CLIP对text进行标准化和预分词后,对每一个单词进行BPE编码和查表,完成token_id的转换
二、BPE算法
2.1 核心思想和原理
paper:Neural Machine Translation of Rare Words with Subword Units
地址:https://arxiv.org/pdf/1508.07909
核心思想:
从字符级别开始,通过统计频率最高的字符对或子词对,通过逐步迭代构建一个的词汇表,用于表示文本中的单词或子词单元。
优势:
简单高效,保留词的语义信息,又能灵活处理未见过的新词(out-of-vocabulary, OOV)
原理(paper思路):
通过迭代地将序列中出现最频繁的一对字节替换为一个未使用的字节来实现压缩
- 用字符词汇表初始化符号词汇表,并将每个单词表示为字符序列,加上一个特殊的单词结束符号“·”,这使我们能够在翻译后恢复原始的分词。
- 迭代地统计所有符号对,并将出现最频繁的符号对(“A”,“B”)替换为一个新的符号“AB”。
- 每次合并操作都会产生一个新的符号,该符号代表一个字符n-gram。频繁的字符n-gram(或整个单词)最终会被合并为一个符号,
- 合并操作的次数是唯一的超参数。
2.2 伪代码和说人话
说人话:
2.2.1 训练阶段-构建词汇表:
- 假设对一个大规模语料库进行统计,先按照空格和标点符号进行切分,得到各种单词,并在单词的末尾加上</w>
-
"low": l o w </w>, 5次 "lower": l o w e r </w>, 3次 "new": n e w </w>, 4次
-
- 统计字符对的频率
-
l o: 8次(5次来自 "low",3次来自 "lower") o w: 8次(5次来自 "low",3次来自 "lower") w </w>: 9次(5次来自 "low",4次来自 "new")
-
-
合并频率最高的字符对
-
"low": lo w </w>, 5次 "lower": lo w e r </w>, 3次 "new": n e w </w>, 4次
-
-
迭代执行,则词汇表就包括lo等词汇,假设第二次迭代发现low也是一个高频词,则将其放入词汇表
-
[l, o, w, e, r, n, </w>, lo, low, new, ...]
-
- 输出词汇表:
- 训练完成后,得到一个包含字符和子词的词汇表,用于后续的分词。
2.2.2 应用阶段-分词器分词
BPE 使用训练好的词汇表将新输入的文本进行分词:
- 单词拆分成字符
- 对于输入单词(如 “lowest”),先将其拆分为字符序列并添加词尾标记:
l o w e s t </w>。
- 对于输入单词(如 “lowest”),先将其拆分为字符序列并添加词尾标记:
- 贪心合并
-
根据训练阶段生成的词汇表,依次尝试合并字符对,优先选择词汇表中最长的子词单元。例如:
检查 l o,发现 lo 在词汇表中,合并为 lo w e s t </w>。
检查 lo w,发现 low 在词汇表中,合并为 low e s t </w>。
检查 e s,不在词汇表中,继续检查 e s t,不在词汇表中,最终结果可能是 low e s t </w>。
-
-
输出子词序列:
- 最终输出分词结果:
[low, e, s, t],作为模型的输入 token。
- 最终输出分词结果:
伪代码:

三、CLIP的应用
3.1 CLIP的框架图
如题,CLIP的分词器通常使用的是Byte Pair Encoding(BPE)算法。下图中clip的文本预处理就是使用的BPE分词器,将完整的文本转化为一个一个的token_id
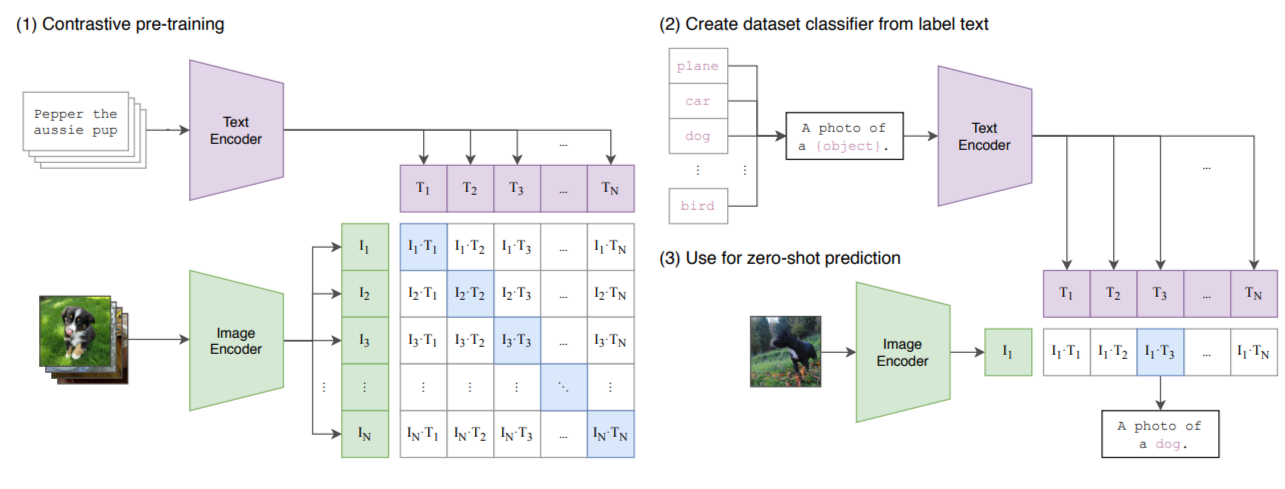
3.2 应用编码细节
说人话:先做文本预处理,变成自己想要关注的标准文本,然后使用正则表达式变成单词list,对list里面的每一个单词进行BPE编码,按照频率最高的进行合并,最后反查对应的token_id
编码的过程大致分为4步:
- 将文本进行标准化normalization。主要是对文本的一些空白剔除、所有大写转换成小写,其实还可以做一些你不想要的字符剔除,使得变成一个标准的文本
-
Before: Electric Power is Everywhere Present In Unlimited Quantities, It Can Drive The World's Machinery Without The Need Of Coal, Oil, Gas Or Any Other Fuel. After: electric power is everywhere present in unlimited quantities, it can drive the world's machinery without the need of coal, oil, gas or any other fuel.
-
- 将标准化后的文本进行预分词,pre tokenization,变成字符串列表。
-
electric power is everywhere present in unlimited quantities , it can drive the world 's machinery without the need of coal , oil , gas or any other fuel .
-
-
对列表里面的每一个字符串进行BPE编码,然后按照高频子串的出现规律进行合并
-
比如(e l) (l e) (e c) (c t) (t r) (r i) (i c</w>),通过查表后le是最靠前的,在查表里面是第24行,则变成e le c t r i c</w>
-
然后重复执行,持续查表,直到没有办法在合并词字典中找到任何可以合并的内容或者直到没有任何内容可以拆分为止
-

-
- 按照顺序查出上面拆分在合并的所有子字符串对应的ID,即为转换为token_id,对应的文件是vocab.json