文章目录
- 9.1. 门控循环单元(GRU)
- 9.1.1. 门控隐状态
- 9.1.1.1. 重置门和更新门
- 9.1.1.2. 候选隐状态
- 9.1.1.3. 隐状态
- 9.1.2. 从零开始实现
- 9.1.2.1. 初始化模型参数
- 9.1.2.2. 定义模型
- 9.1.3. 简洁实现
- 9.1.4. 小结
- 9.2. 长短期记忆网络(LSTM)
- 9.2.1. 门控记忆元
- 9.2.1.1. 输入门、忘记门和输出门
- 9.2.1.2. 候选记忆元
- 9.2.1.3. 记忆元
- 9.2.1.4. 隐状态
- 9.2.2. 从零开始实现
- 9.2.2.1. 初始化模型参数
- 9.2.2.2. 定义模型
- 9.2.3. 简洁实现
- 9.2.4. 小结
- 9.3. 深度循环神经网络
- 9.3.1. 函数依赖关系
- 9.3.2. 简洁实现
- 9.4. 双向循环神经网络
- 9.4.1. 隐马尔可夫模型中的动态规划
- 9.4.2. 双向模型
- 9.4.2.1. 定义
- 9.4.2.2. 模型的计算代价及其应用
- 9.4.3. 双向循环神经网络的错误应用
- 9.4.4. 小结
- 9.5. 机器翻译与数据集
- 9.6. 编码器-解码器架构
- 9.6.1. 编码器
- 9.6.2. 解码器
- 9.6.3. 合并编码器和解码器
- 9.6.4. 小结
- 9.7. 序列到序列学习(seq2seq)
- 9.7.1. 编码器
- 9.7.2. 解码器
- 9.7.3. 损失函数
- 9.7.4. 训练
- 9.7.5. 预测
- 9.7.6. 预测序列的评估
- 9.7.7. 小结
- 9.8. 束搜索
循环神经网络在实践中一个常见问题是数值不稳定性。 尽管我们已经应用了梯度裁剪等技巧来缓解这个问题, 但是仍需要通过设计更复杂的序列模型来进一步处理它。 具体来说,我们将引入两个广泛使用的网络, 即**门控循环单元(gated recurrent units,GRU)**和 长短期记忆网络(long short-term memory,LSTM)。 然后,我们将基于一个单向隐藏层来扩展循环神经网络架构。 我们将描述具有多个隐藏层的深层架构, 并讨论基于前向和后向循环计算的双向设计。 现代循环网络经常采用这种扩展。 在解释这些循环神经网络的变体时, 我们将继续考虑 8节中的语言建模问题。
事实上,语言建模只揭示了序列学习能力的冰山一角。 在各种序列学习问题中,如自动语音识别、文本到语音转换和机器翻译, 输入和输出都是任意长度的序列。 为了阐述如何拟合这种类型的数据, 我们将以机器翻译为例介绍基于循环神经网络的 “编码器-解码器”架构和束搜索,并用它们来生成序列。
9.1. 门控循环单元(GRU)
9.1.1. 门控隐状态
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。 这些机制是可学习的,并且能够解决了上面列出的问题。 例如,如果第一个词元非常重要, 模型将学会在第一次观测之后不更新隐状态。 同样,模型也可以学会跳过不相关的临时观测。 最后,模型还将学会在需要的时候重置隐状态。
9.1.1.1. 重置门和更新门
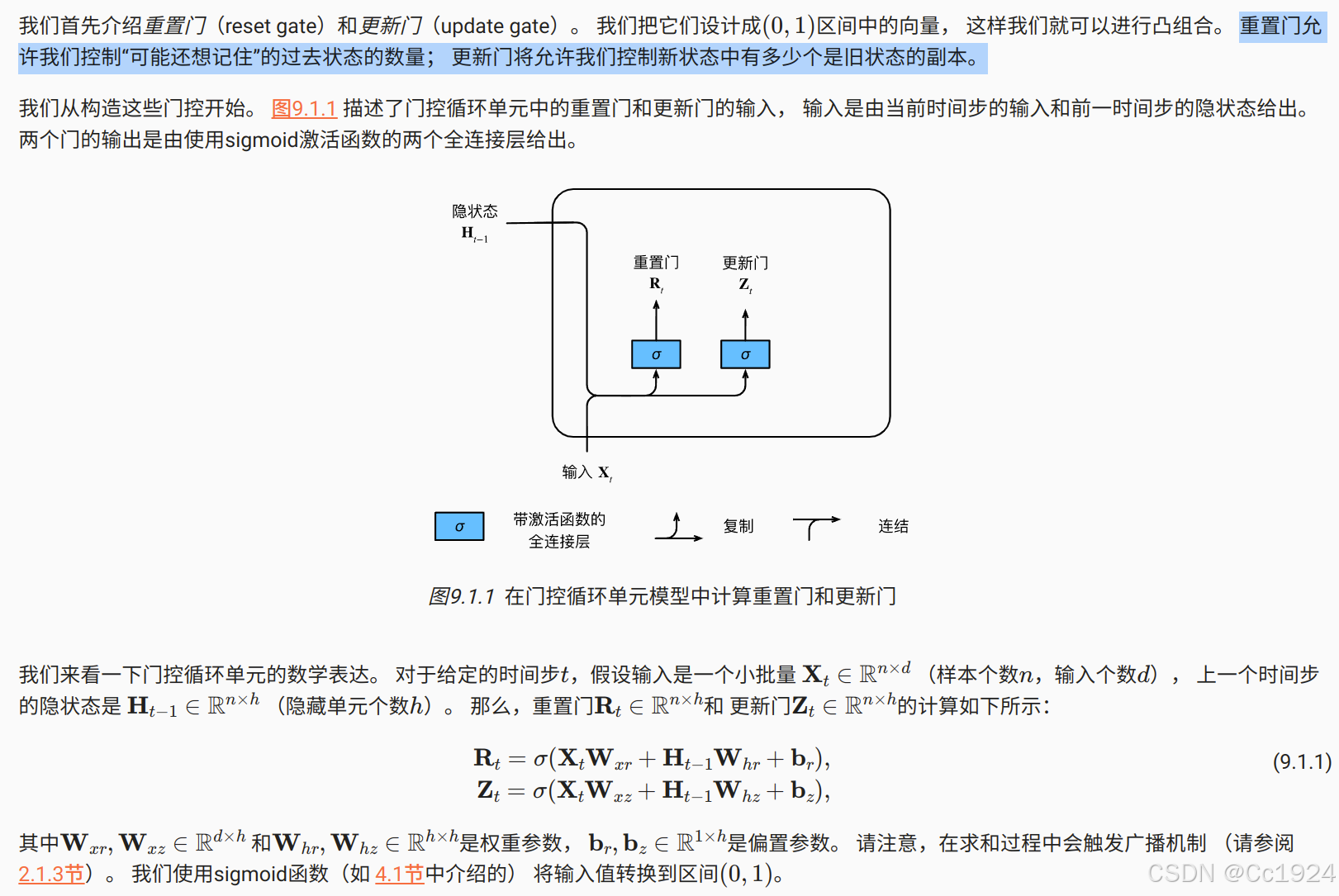
9.1.1.2. 候选隐状态
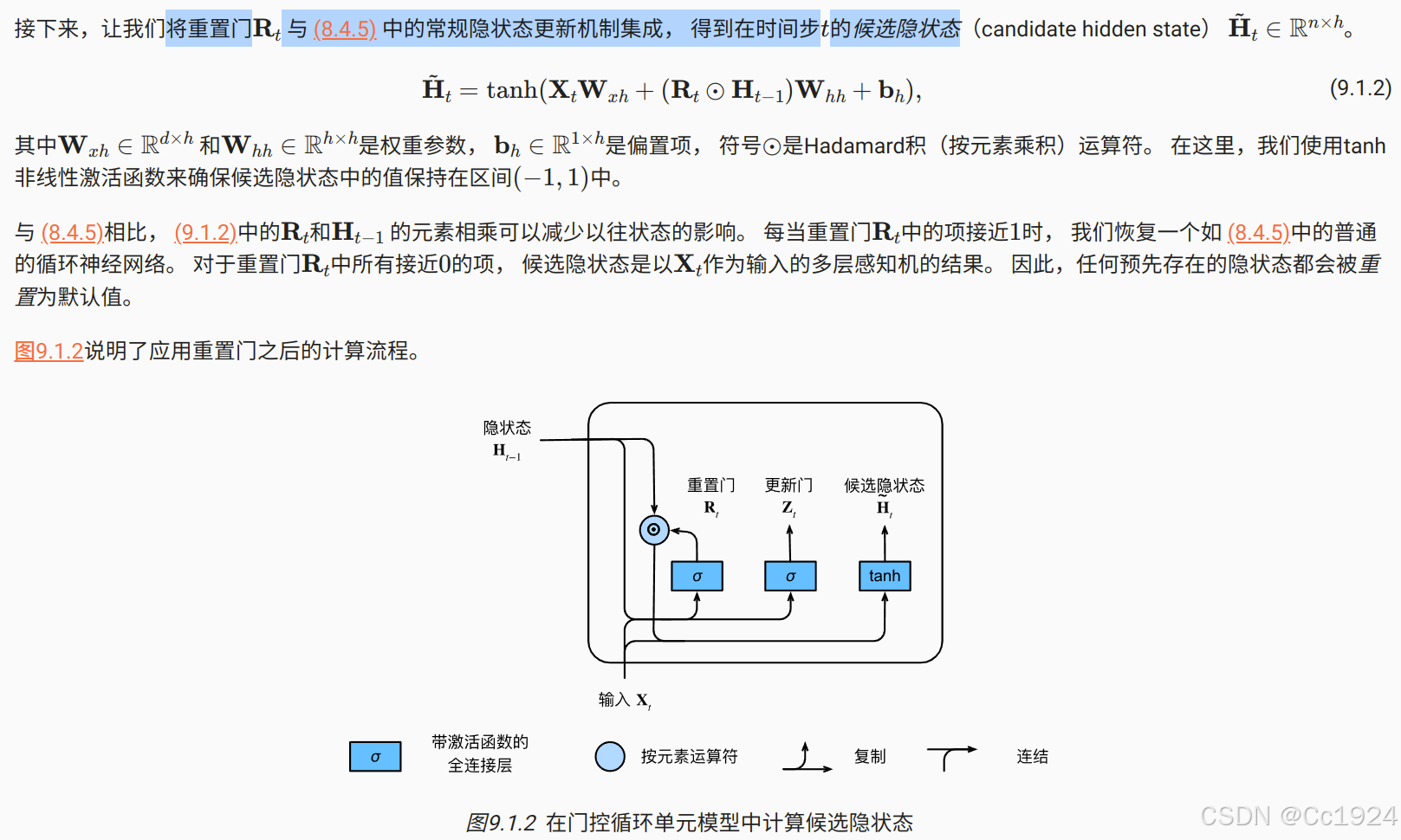
9.1.1.3. 隐状态
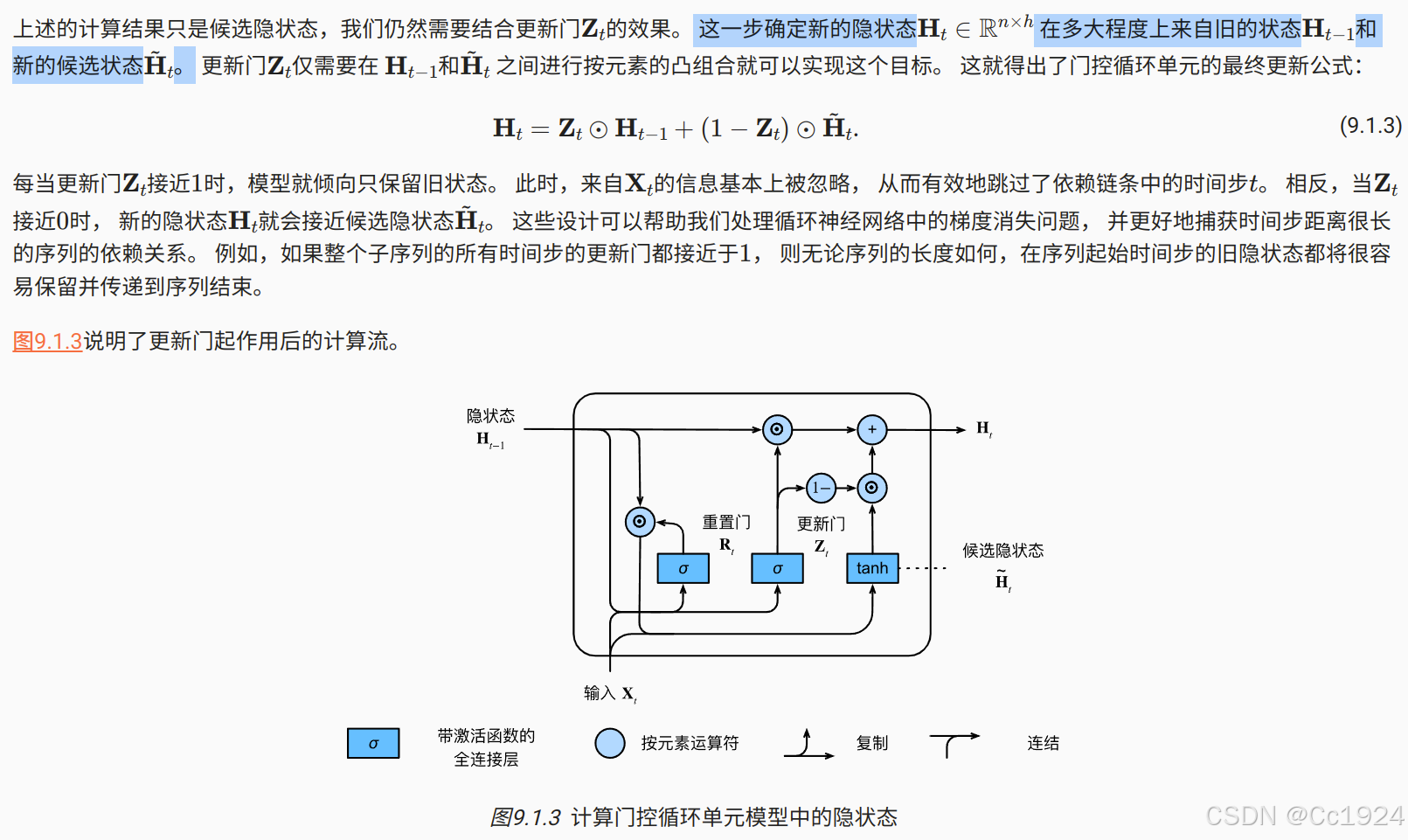
总之,门控循环单元具有以下两个显著特征:
- 重置门有助于捕获序列中的短期依赖关系;
- 更新门有助于捕获序列中的长期依赖关系。
9.1.2. 从零开始实现
9.1.2.1. 初始化模型参数
我们从标准差为0.01的高斯分布中提取权重, 并将偏置项设为0,超参数num_hiddens定义隐藏单元的数量, 实例化与更新门、重置门、候选隐状态和输出层相关的所有权重和偏置。
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
# 更新门参数,最后对隐状态和候选隐状态进行加权
W_xz, W_hz, b_z = three()
# 重置门参数
W_xr, W_hr, b_r = three()
# 候选隐状态参数,生成候选隐状态
W_xh, W_hh, b_h = three()
# 输出层参数,由当前步骤的输入和隐状态,生成当前步骤的输出
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
9.1.2.2. 定义模型
现在我们将定义隐状态的初始化函数init_gru_state。 与 8.5节中定义的init_rnn_state函数一样, 此函数返回一个形状为**(批量大小,隐藏单元个数)**的张量,张量的值全部为零。
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
现在我们准备定义门控循环单元模型, 模型的架构与基本的循环神经网络单元是相同的, 只是权重更新公式更为复杂。
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
9.1.3. 简洁实现
num_inputs = vocab_size
# 参数:(输入维度, 输出的隐藏层维度)
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
注意:nnn.GRU 输出的和上面我们手写的一样,是一个 tuple,返回(所有时间步的输出,最后一个时间步的隐状态)。
num_steps, batch_size, input_dim, hidden_dim = 35, 2, 10, 256
net = nn.GRU(input_dim, hidden_dim)
input = torch.rand(num_steps, batch_size, input_dim)
output = net(input)
Y, hidden_state = output
print(Y.shape) # (num_steps, batch_size, hidden_dim)
print(hidden_state.shape) # (1, batch_size, hidden_dim)
9.1.4. 小结
- 门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系。
- 重置门有助于捕获序列中的短期依赖关系。
- 更新门有助于捕获序列中的长期依赖关系。
- 重置门打开时,门控循环单元包含基本循环神经网络;更新门打开时,门控循环单元可以跳过子序列。
9.2. 长短期记忆网络(LSTM)
长期以来,隐变量模型存在着长期信息保存和短期输入缺失的问题。 解决这一问题的最早方法之一是长短期存储器(long short-term memory,LSTM) (Hochreiter and Schmidhuber, 1997)。 它有许多与门控循环单元( 9.1节)一样的属性。 有趣的是,长短期记忆网络的设计比门控循环单元稍微复杂一些, 却比门控循环单元早诞生了近20年。
9.2.1. 门控记忆元
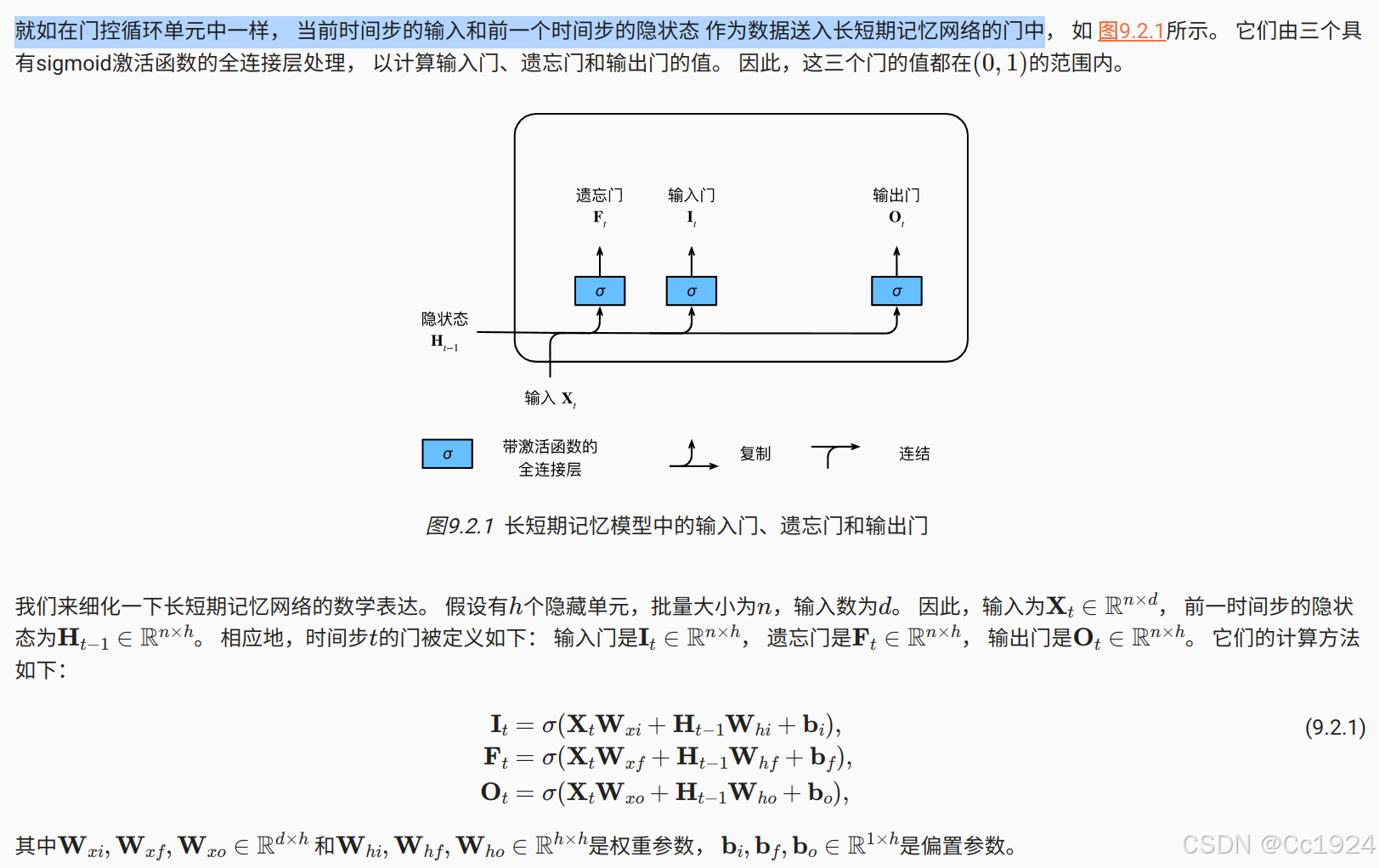
可以说,长短期记忆网络的设计灵感来自于计算机的逻辑门。 长短期记忆网络引入了记忆元(memory cell),或简称为单元(cell)。 有些文献认为记忆元是隐状态的一种特殊类型, 它们与隐状态具有相同的形状,其设计目的是用于记录附加的信息。 为了控制记忆元,我们需要许多门。
- 其中一个门用来从单元中输出条目,我们将其称为输出门(output gate)。
- 另外一个门用来决定何时将数据读入单元,我们将其称为输入门(input gate)。
- 我们还需要一种机制来重置单元的内容,由遗忘门(forget gate)来管理, 这种设计的动机与门控循环单元相同, 能够通过专用机制决定什么时候记忆或忽略隐状态中的输入。
9.2.1.1. 输入门、忘记门和输出门
9.2.1.2. 候选记忆元
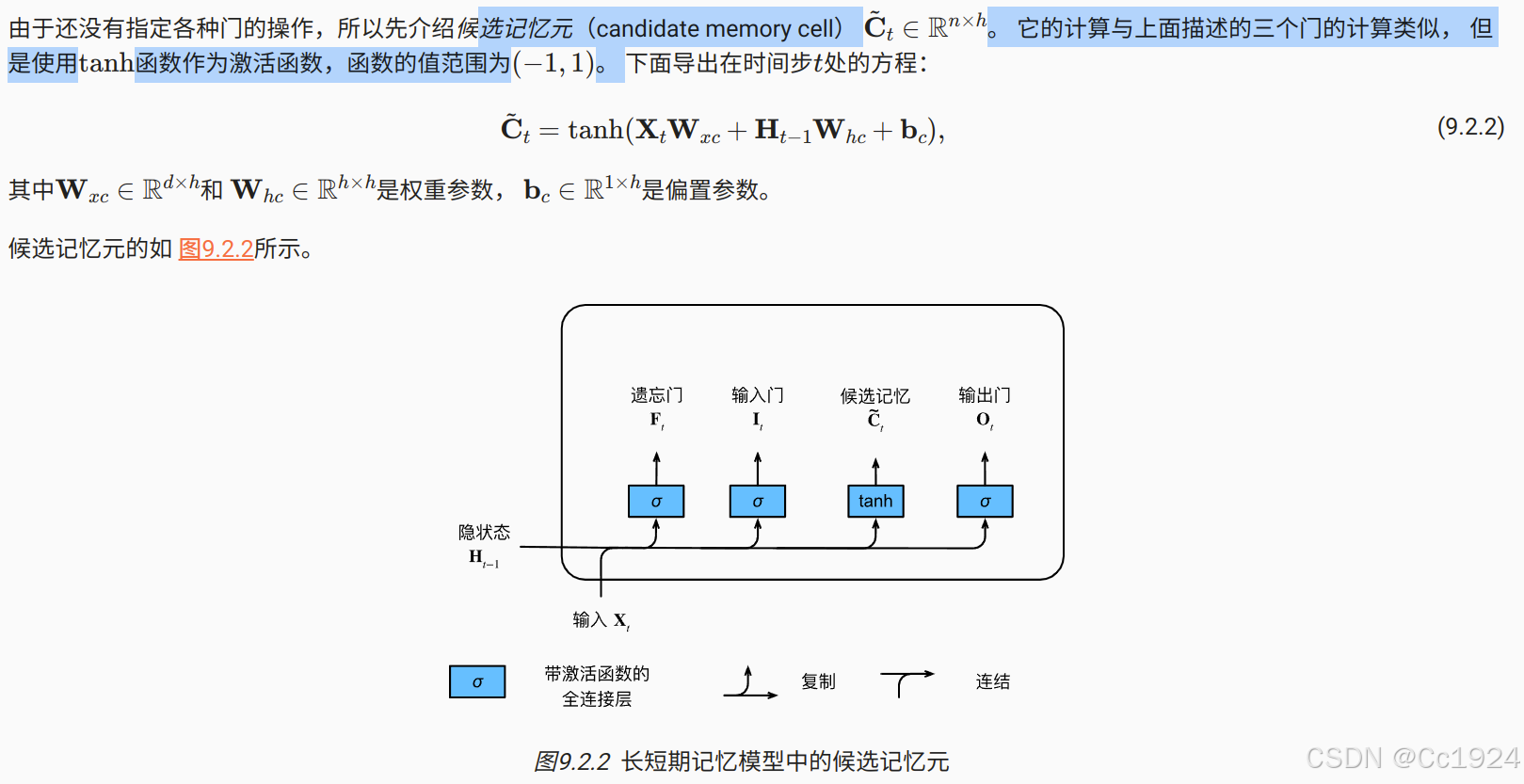
9.2.1.3. 记忆元
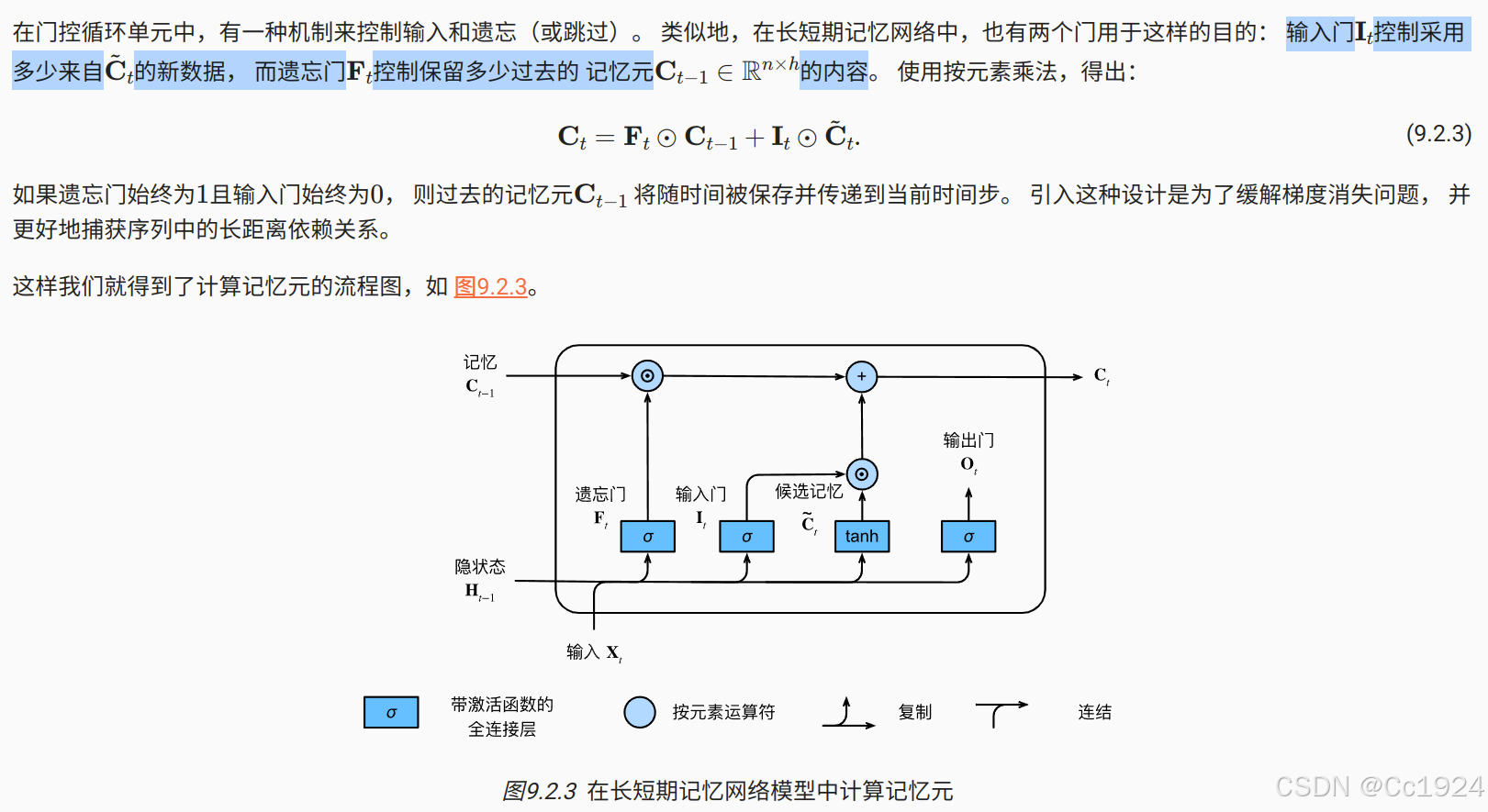
注意:这里可以看到,其实这里的记忆元就相当于 GRU 中的隐状态,候选记忆元就相当于 GRU 中的候选隐状态。
9.2.1.4. 隐状态
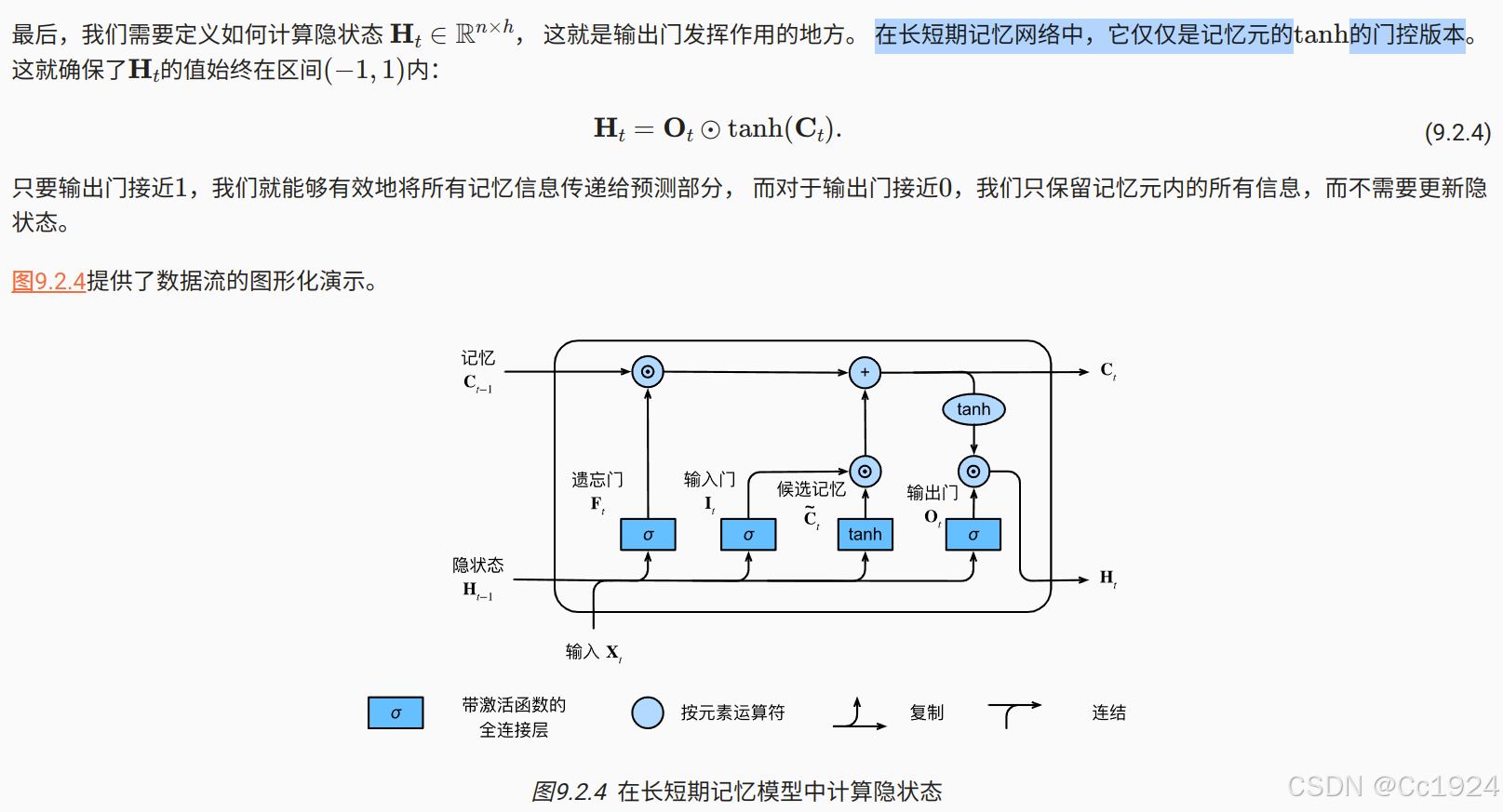
9.2.2. 从零开始实现
9.2.2.1. 初始化模型参数
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
9.2.2.2. 定义模型
在初始化函数中, 长短期记忆网络的隐状态需要返回一个额外的记忆元, 单元的值为0,形状为**(批量大小,隐藏单元数)**。 因此,我们得到以下的状态初始化。
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
实际模型的定义与我们前面讨论的一样: 提供三个门和一个额外的记忆元。 请注意,只有隐状态才会传递到输出层, 而记忆元不直接参与输出计算,它只是用来生成隐状态。
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params
(H, C) = state
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
9.2.3. 简洁实现
num_inputs = vocab_size
# 参数:(输入维度,隐藏层维度)
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
注意:nn.LSTM 输出的和上面我们手写的一样,是一个 tuple,返回(所有时间步的输出,(最后一个时间步的隐状态,最后一个时间步的记忆元))。
num_steps, batch_size, input_dim, hidden_dim = 35, 2, 10, 256
net = nn.LSTM(input_dim, hidden_dim)
input = torch.rand(num_steps, batch_size, input_dim)
output = net(input)
Y, (hidden_state, cell_state) = output
print(Y.shape) # (num_steps, batch_size, hidden_dim)
print(hidden_state.shape) # (1, batch_size, hidden_dim)
print(cell_state.shape) # (1, batch_size, hidden_dim)
9.2.4. 小结
- 长短期记忆网络有三种类型的门:输入门、遗忘门和输出门。
- 长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
- 长短期记忆网络可以缓解梯度消失和梯度爆炸。
9.3. 深度循环神经网络
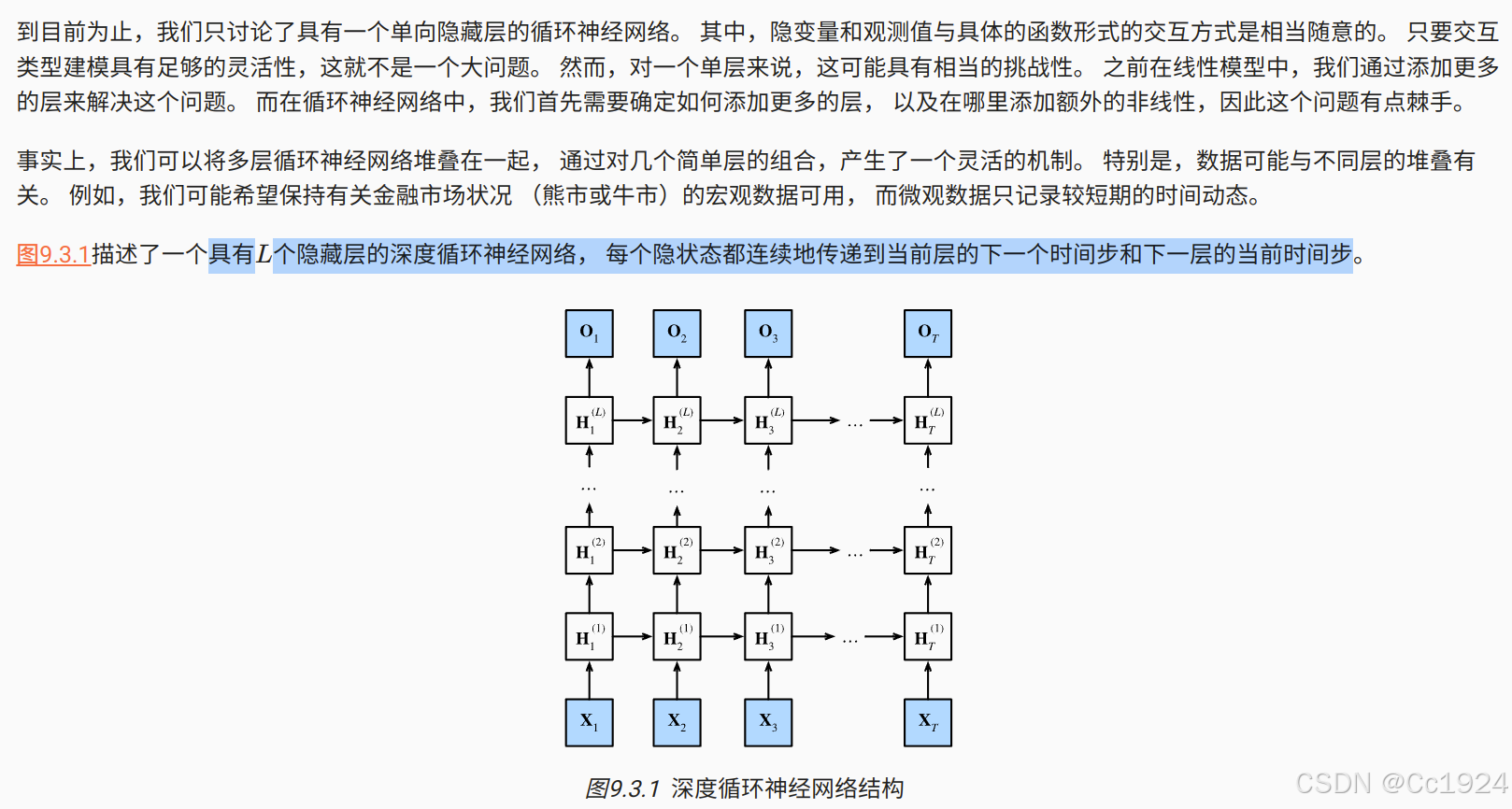
9.3.1. 函数依赖关系

注意:红框中的公式相比之前单层的循环神经网络,就是把当前层的上一个时间步的隐状态作为单层RNN的输入隐状态H,当前时间步的上一层的隐状态作为单层RNN的输入X。
9.3.2. 简洁实现
实现多层循环神经网络所需的许多逻辑细节在高级API中都是现成的。 简单起见,我们仅示范使用此类内置函数的实现方式。 以长短期记忆网络模型为例, 该代码与之前在 9.2节中使用的代码非常相似, 实际上唯一的区别是我们指定了层的数量, 而不是使用单一层这个默认值。
像选择超参数这类架构决策也跟 9.2节中的决策非常相似。 因为我们有不同的词元,所以输入和输出都选择相同数量,即vocab_size。 隐藏单元的数量仍然是
。 唯一的区别是,我们现在通过num_layers的值来设定隐藏层数。
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
# 参数:(输入维度,输出维度,隐藏层个数),其中隐藏层个数默认=1
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
注意:nn.LSTM 本身就支持多个隐藏层,输出参数是**(输入维度,输出维度,隐藏层个数)**,其中隐藏层个数默认=1。
num_steps, batch_size, input_dim, hidden_dim, hidden_layer = 35, 2, 10, 256, 3
net = nn.LSTM(input_dim, hidden_dim, hidden_layer)
input = torch.rand(num_steps, batch_size, input_dim)
output = net(input)
Y, (hidden_state, cell_state) = output
print(Y.shape) # (num_steps, batch_size, hidden_dim),所有时间步最后一个隐藏层之后的输出
print(hidden_state.shape) # (hidden_layer, batch_size, hidden_dim),所有隐藏层最后一个时间步的隐藏状态
print(cell_state.shape) # (hidden_layer, batch_size, hidden_dim),所有隐藏层最后一个时间步的单元状态
9.4. 双向循环神经网络

9.4.1. 隐马尔可夫模型中的动态规划
理论推导太多,可以去看原文:https://zh.d2l.ai/chapter_recurrent-modern/bi-rnn.html
9.4.2. 双向模型
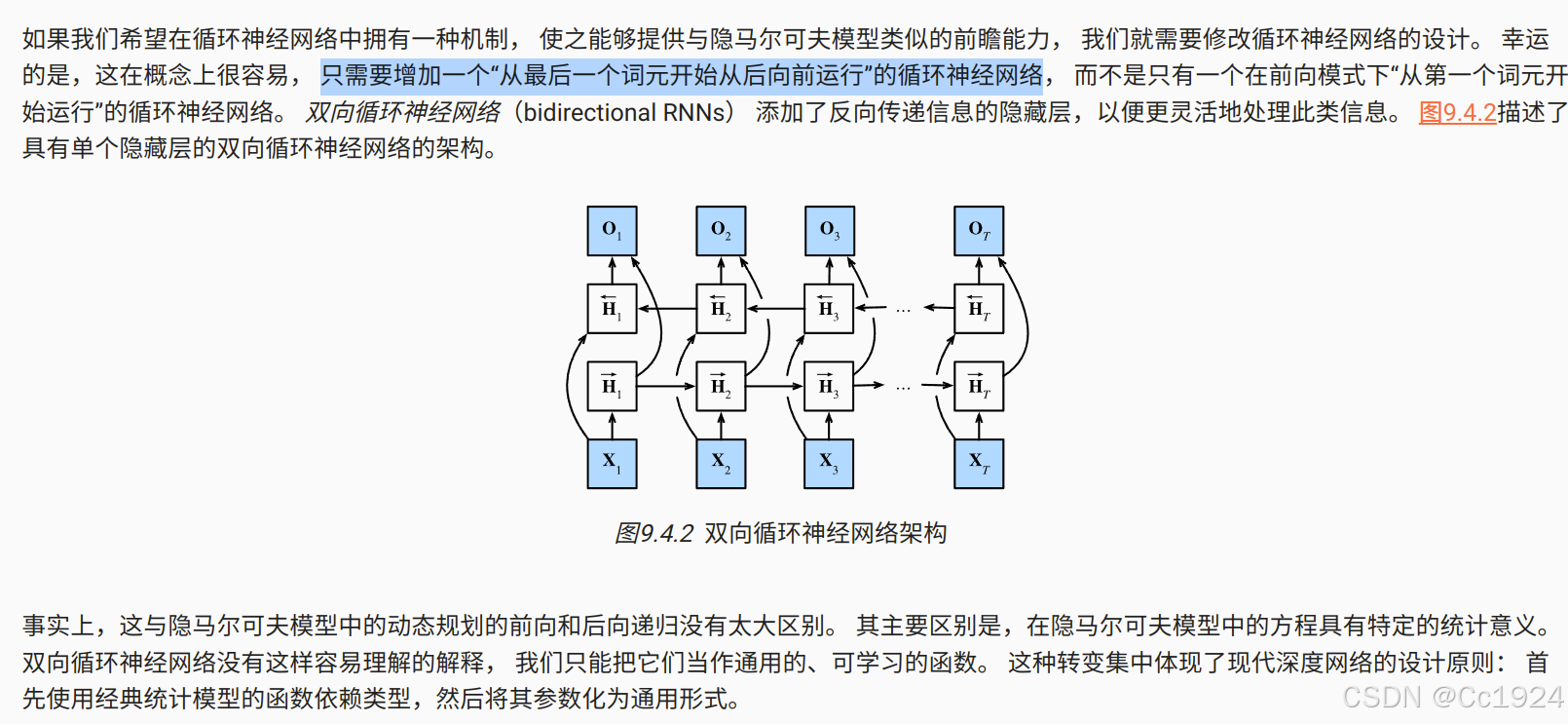
9.4.2.1. 定义

9.4.2.2. 模型的计算代价及其应用
双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出。 也就是说,我们使用来自过去和未来的观测信息来预测当前的观测。 但是在对下一个词元进行预测的情况中,这样的模型并不是我们所需的。 因为在预测下一个词元时,我们终究无法知道下一个词元的下文是什么, 所以将不会得到很好的精度。 具体地说,在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词; 而在测试期间,我们只有过去的数据,因此精度将会很差。 下面的实验将说明这一点。
另一个严重问题是,双向循环神经网络的计算速度非常慢。 其主要原因是网络的前向传播需要在双向层中进行前向和后向递归, 并且网络的反向传播还依赖于前向传播的结果。 因此,梯度求解将有一个非常长的链。
双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如,用于命名实体识别) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)。 在 14.8节和 15.2节中, 我们将介绍如何使用双向循环神经网络编码文本序列。
9.4.3. 双向循环神经网络的错误应用
由于双向循环神经网络使用了过去的和未来的数据, 所以我们不能盲目地将这一语言模型应用于任何预测任务。 尽管模型产出的困惑度是合理的, 该模型预测未来词元的能力却可能存在严重缺陷。 我们用下面的示例代码引以为戒,以防在错误的环境中使用它们。
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
# 通过设置“bidirective=True”来定义双向LSTM模型
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
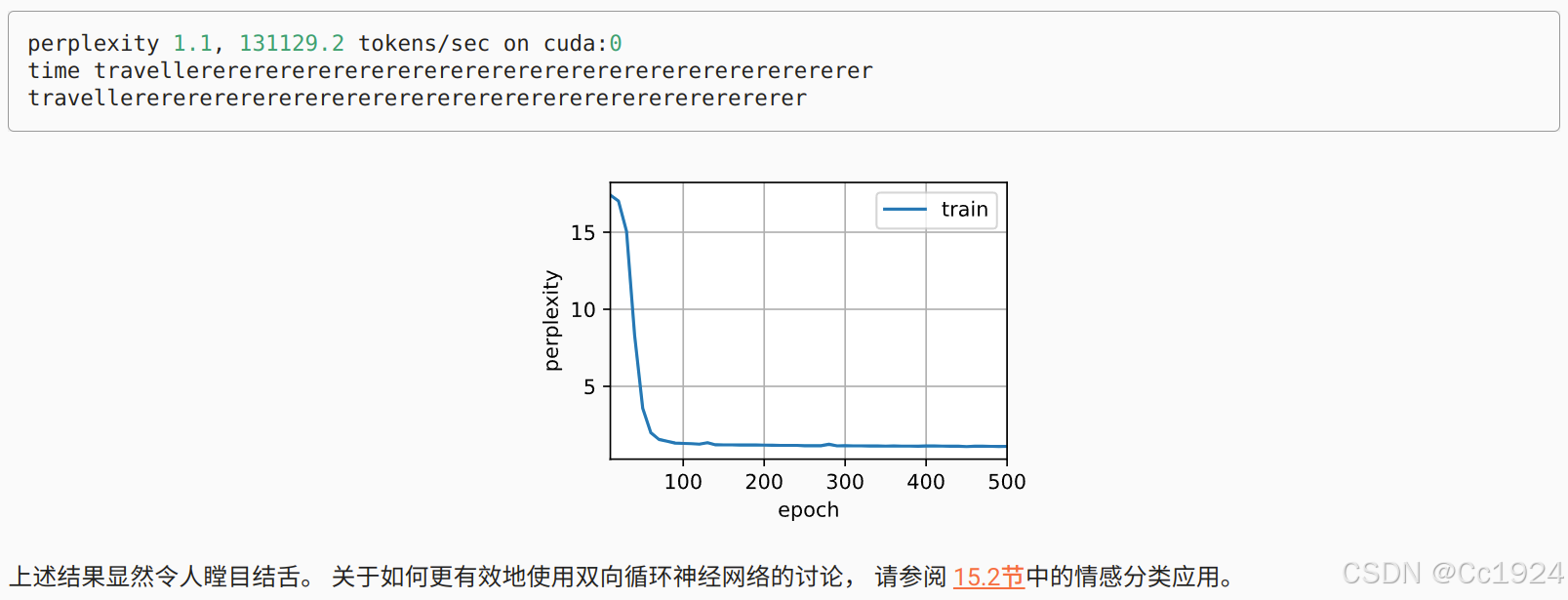
9.4.4. 小结
- 在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
- 双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性。
- 双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
- 由于梯度链更长,因此双向循环神经网络的训练代价非常高。
9.5. 机器翻译与数据集
没有和网络相关的,可以直接去看原文:https://zh.d2l.ai/chapter_recurrent-modern/machine-translation-and-dataset.html
9.6. 编码器-解码器架构
正如我们在 9.5节中所讨论的, 机器翻译是序列转换模型的一个核心问题, 其输入和输出都是长度可变的序列。 为了处理这种类型的输入和输出, 我们可以设计一个包含两个主要组件的架构:
- 第一个组件是一个编码器(encoder): 它接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。
- 第二个组件是解码器(decoder): 它将固定形状的编码状态映射到长度可变的序列。
这被称为编码器-解码器(encoder-decoder)架构, 如 图9.6.1 所示。
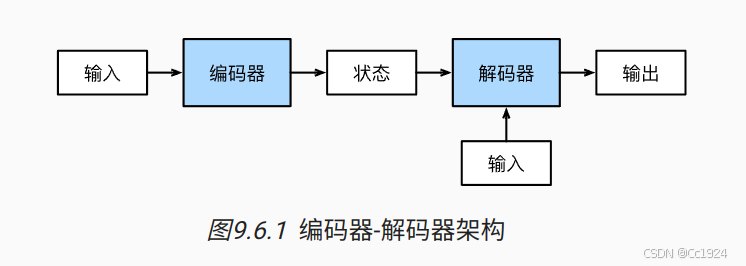
我们以英语到法语的机器翻译为例: 给定一个英文的输入序列:“They”“are”“watching”“.”。 首先,这种“编码器-解码器”架构将长度可变的输入序列编码成一个“状态”, 然后对该状态进行解码, 一个词元接着一个词元地生成翻译后的序列作为输出: “Ils”“regordent”“.”。 由于“编码器-解码器”架构是形成后续章节中不同序列转换模型的基础, 因此本节将把这个架构转换为接口方便后面的代码实现。
9.6.1. 编码器
在编码器接口中,我们只指定长度可变的序列作为编码器的输入X。 任何继承这个Encoder基类的模型将完成代码实现。
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
9.6.2. 解码器
在下面的解码器接口中,我们新增一个init_state函数, 用于将编码器的输出(enc_outputs)转换为编码后的状态。 注意,此步骤可能需要额外的输入,例如:输入序列的有效长度, 这在 9.5.4节中进行了解释。 为了逐个地生成长度可变的词元序列, 解码器在每个时间步都会将输入 (例如:在前一时间步生成的词元)和编码后的状态 映射成当前时间步的输出词元。
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
9.6.3. 合并编码器和解码器
总而言之,“编码器-解码器”架构包含了一个编码器和一个解码器, 并且还拥有可选的额外的参数。 在前向传播中,编码器的输出用于生成编码状态, 这个状态又被解码器作为其输入的一部分。
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
9.6.4. 小结
- “编码器-解码器”架构可以将长度可变的序列作为输入和输出,因此适用于机器翻译等序列转换问题。
- 编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
- 解码器将具有固定形状的编码状态映射为长度可变的序列。
9.7. 序列到序列学习(seq2seq)
如我们在 9.5节中看到的, 机器翻译中的输入序列和输出序列都是长度可变的。 为了解决这类问题,我们在 9.6节中 设计了一个通用的”编码器-解码器“架构。 本节,我们将使用两个循环神经网络的编码器和解码器, 并将其应用于序列到序列(sequence to sequence,seq2seq)类的学习任务 (Cho et al., 2014, Sutskever et al., 2014)。
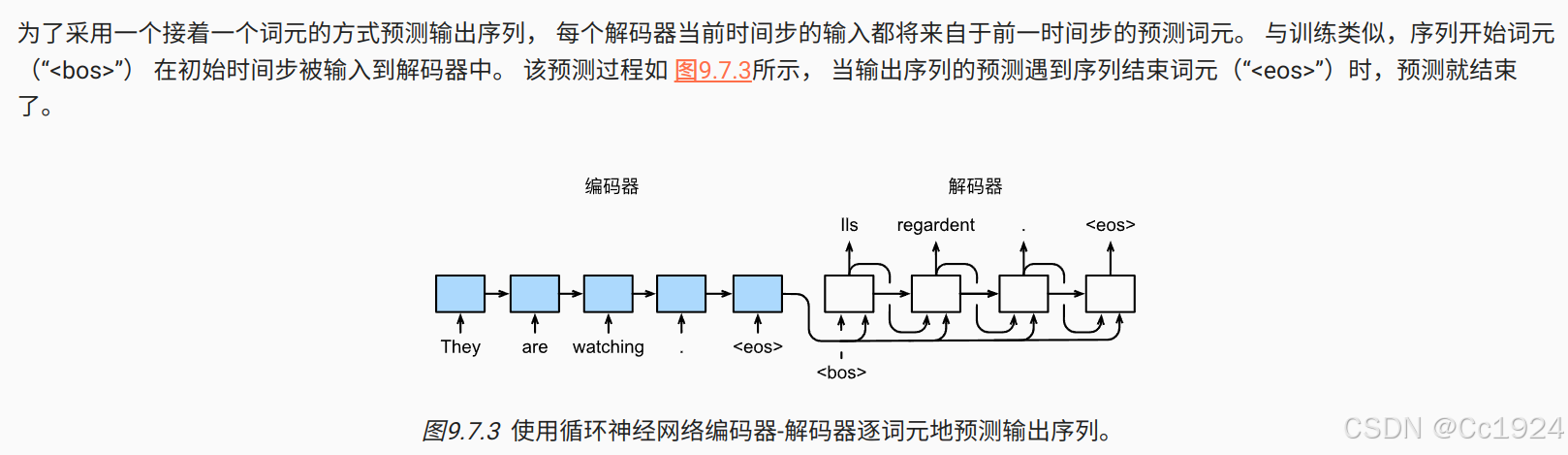
遵循编码器-解码器架构的设计原则, 循环神经网络编码器使用长度可变的序列作为输入, 将其转换为固定形状的隐状态。 换言之,输入序列的信息被编码到循环神经网络编码器的隐状态中。 为了连续生成输出序列的词元, 独立的循环神经网络解码器是基于输入序列的编码信息 和输出序列已经看见的或者生成的词元来预测下一个词元。 图9.7.1演示了 如何在机器翻译中使用两个循环神经网络进行序列到序列学习。
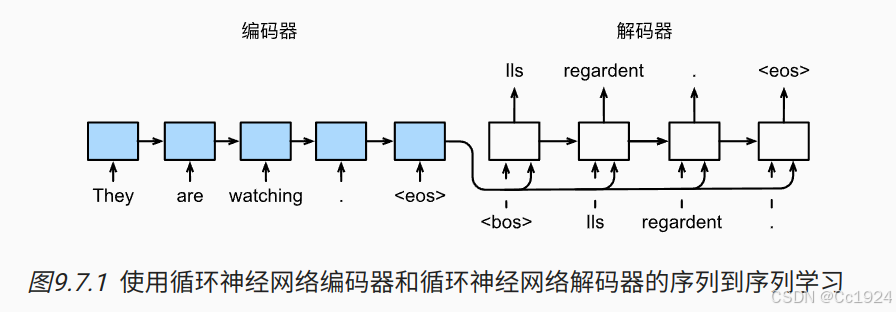
在 图9.7.1中, 特定的“”表示序列结束词元。 一旦输出序列生成此词元,模型就会停止预测。 在循环神经网络解码器的初始化时间步,有两个特定的设计决定: 首先,特定的“”表示序列开始词元,它是解码器的输入序列的第一个词元。 其次,使用循环神经网络编码器最终的隐状态来初始化解码器的隐状态。 例如,在 (Sutskever et al., 2014)的设计中, 正是基于这种设计将输入序列的编码信息送入到解码器中来生成输出序列的。 在其他一些设计中 (Cho et al., 2014), 如 图9.7.1所示, 编码器最终的隐状态在每一个时间步都作为解码器的输入序列的一部分。 类似于 8.3节中语言模型的训练, 可以允许标签成为原始的输出序列, 从源序列词元“”“Ils”“regardent”“.” 到新序列词元 “Ils”“regardent”“.”“”来移动预测的位置。
9.7.1. 编码器

现在,让我们实现循环神经网络编码器。 注意,我们使用了嵌入层(embedding layer) 来获得输入序列中每个词元的特征向量。 嵌入层的权重是一个矩阵, 其行数等于输入词表的大小(vocab_size), 其列数等于特征向量的维度(embed_size)。 对于任意输入词元的索引 i, 嵌入层获取权重矩阵的第 i 行(从 0 开始)以返回其特征向量。 另外,本文选择了一个多层门控循环单元来实现编码器。
#@save
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
注意:
-
调用 nn.Embedding 的forward得到的输出:注意 nn.Embedding 是一个 nn.Module,所以他有 forward 函数。
实际上就是 nn.Embedding 生成了一个 (R, C) 的二维矩阵,R是词表的长度,C是嵌入的向量空间的维度。然后传入一个 (B,N)的索引 Tensor,B是batch_size,N是在词表长度范围内的单词索引,然后从nn.Embedding 的二维矩阵中索引每个单词的嵌入向量。(在实际应用时N可以理解为时间步数)
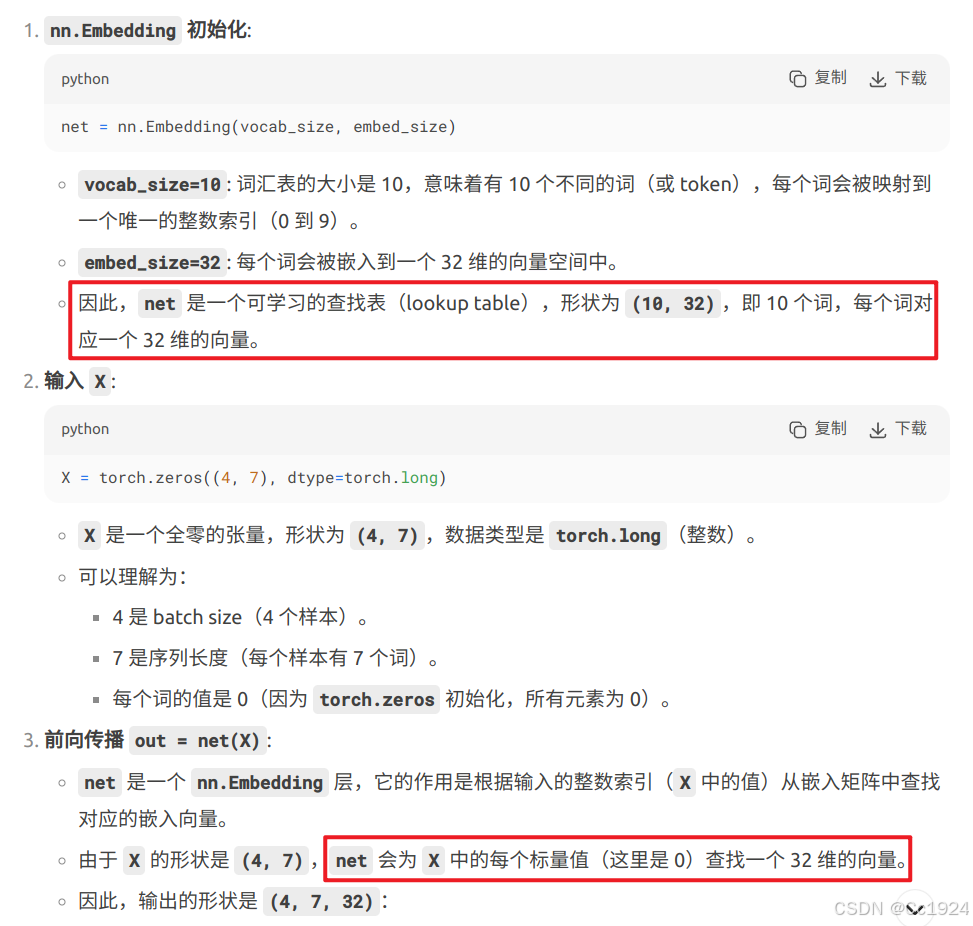
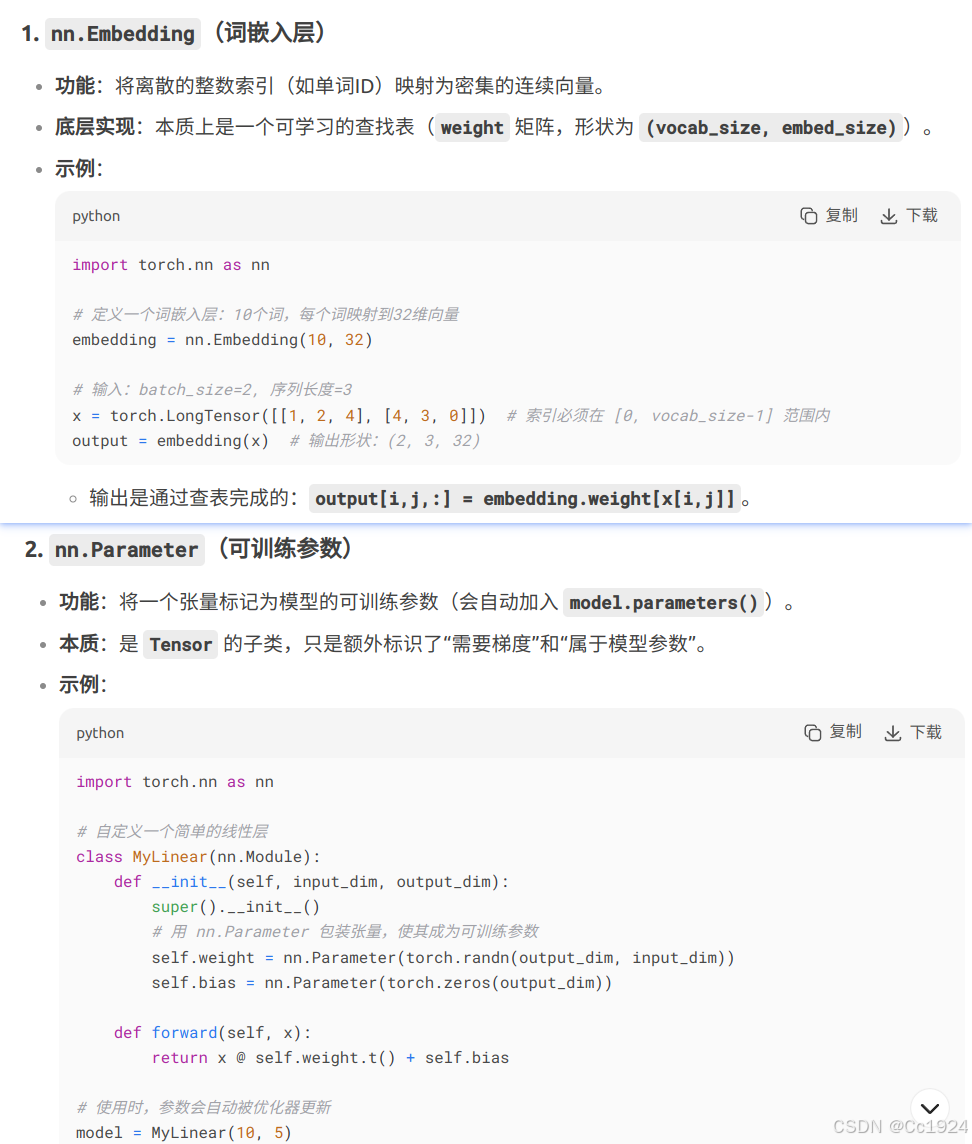
总结- nn.Embedding 的作用是将离散的词索引映射为连续的嵌入向量。
- 输入形状 (batch_size, sequence_length) 会转换为输出形状 (batch_size, sequence_length, embed_size)。
-
nn.Embedding 和 nn.Parameter 有什么区别?nn.Embedding 和 nn.Parameter 是 PyTorch 中两个完全不同的概念,它们的用途和功能有本质区别:


下面,我们实例化上述编码器的实现: 我们使用一个两层门控循环单元编码器,其隐藏单元数为16。 给定一小批量的输入序列X(批量大小为4,时间步为7)。 在完成所有时间步后, 最后一层的隐状态的输出是一个张量(output由编码器的循环层返回), 其形状为**(时间步数,批量大小,隐藏单元数)**。
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
output.shape # torch.Size([7, 4, 16])
由于这里使用的是门控循环单元, 所以在最后一个时间步的多层隐状态的形状是 (隐藏层的数量,批量大小,隐藏单元的数量)。 如果使用长短期记忆网络,state中还将包含记忆单元信息。
state.shape # torch.Size([2, 4, 16])
9.7.2. 解码器

class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(num_steps, batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state

9.7.3. 损失函数
在每个时间步,解码器预测了输出词元的概率分布。 类似于语言模型,可以使用softmax来获得分布, 并通过计算交叉熵损失函数来进行优化。 回想一下 9.5节中, 特定的填充词元被添加到序列的末尾, 因此不同长度的序列可以以相同形状的小批量加载。 但是,我们应该将填充词元的预测排除在损失函数的计算之外。
为此,我们可以使用下面的sequence_mask函数 通过零值化屏蔽不相关的项, 以便后面任何不相关预测的计算都是与零的乘积,结果都等于零。 例如,如果两个序列的有效长度(不包括填充词元)分别为1和2, 则第一个序列的第一项和第二个序列的前两项之后的剩余项将被清除为零。
#@save
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1) # shape[1]
# 这里用到了广播,利用第1维进行比较生成mask,然后对第1维后面的的所有维度赋值
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
# 输出:
# tensor([[1, 0, 0],
# [4, 5, 0]])
现在,我们可以通过扩展softmax交叉熵损失函数来遮蔽不相关的预测。 最初,所有预测词元的掩码都设置为1。 一旦给定了有效长度,与填充词元对应的掩码将被设置为0。 最后,将所有词元的损失乘以掩码,以过滤掉损失中填充词元产生的不相关预测。
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label) #(B, N)
# (B, N), 会把valid_len每个长度后面的都设置为0
weights = sequence_mask(weights, valid_len)
self.reduction='none' # 设置基类的loss不平均
# 调用基类的损失函数
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
# (B, C, N), (B, N) -> (B, N)
pred.permute(0, 2, 1), label)
# (B, N)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
我们可以创建三个相同的序列来进行代码健全性检查, 然后分别指定这些序列的有效长度为4、2和0。 结果就是,第一个序列的损失应为第二个序列的两倍,而第三个序列的损失应为零。
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 2, 0]))
# 结果:tensor([2.3026, 1.1513, 0.0000])
9.7.4. 训练
在下面的循环训练过程中,如 图9.7.1所示, 特定的序列开始词元(“”)和 原始的输出序列(不包括序列结束词元“”) 拼接在一起作为解码器的输入。 这被称为强制教学(teacher forcing), 因为原始的输出序列(词元的标签)被送入解码器。 或者,将来自上一个时间步的预测得到的词元作为解码器的当前输入。
解释:输入解码器的包括输入和隐状态,这里就是再说输入是怎么来的,就是第0个时间步的开始词元 < bos > ,以及后面每个时间步的输入是上个时间步的输出。
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
# 就是拼接bos和每一个时间步的上一时间步输出,作为整体的输入
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
解释:for param in m._flat_weights_names:
m 是一个 PyTorch 模型(nn.Module 实例)。_flat_weights_names 是模型内部的一个属性(通常用于 RNN/LSTM/GRU 等模块),存储了所有扁平化(flattened)的权重名称列表。
例如,在 nn.LSTM 中,_flat_weights_names 可能包含:
['weight_ih_l0', 'weight_hh_l0', 'bias_ih_l0', 'bias_hh_l0', ...]
9.7.5. 预测
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X, enc_valid_len)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
9.7.6. 预测序列的评估

def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
9.7.7. 小结
- 根据“编码器-解码器”架构的设计, 我们可以使用两个循环神经网络来设计一个序列到序列学习的模型。
- 在实现编码器和解码器时,我们可以使用多层循环神经网络。
- 我们可以使用遮蔽来过滤不相关的计算,例如在计算损失时。
- 在“编码器-解码器”训练中,强制教学方法将原始输出序列(而非预测结果)输入解码器。
- BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的 n 元语法的匹配度来评估预测。
9.8. 束搜索
不涉及网络部分,直接去看原文:https://zh.d2l.ai/chapter_recurrent-modern/beam-search.html