一、说明
数字人(Digital Human) 是指通过人工智能(AI)、计算机图形学、语音合成、动作捕捉等技术创建的虚拟人物。它们具备高度拟人化的外观、语言、表情和动作,能够与人类进行交互,甚至承担特定社会角色。数字人是元宇宙、虚拟现实(VR)和人工智能领域的重要产物,正在娱乐、教育、医疗、商业等领域广泛应用。
核心特征
- 拟人化
外观、声音、动作接近真人,部分数字人基于真人扫描建模,部分完全由计算机生成。
- 智能化
依赖自然语言处理(NLP)、深度学习等技术,实现对话、决策、情感表达等功能。
- 交互性
通过语音、文字、手势等多模态方式与人类互动,部分搭载传感器实现实时反馈。
核心技术
- 人工智能(AI)
驱动对话、学习和决策能力(如GPT模型)。
- 计算机图形学(CGI)
构建高精度3D模型,渲染皮肤、毛发等细节。
- 语音合成(TTS)
生成自然流畅的语音(如WaveNet、VITS)。
- 动作捕捉与驱动
通过光学/惯性动捕设备或算法生成逼真动作。
应用场景
- 娱乐与媒体
虚拟偶像/主播:如中国的“翎_Ling”、日本的“初音未来”。
影视特效:替代真人演员完成高危或奇幻场景。
- 教育与培训
虚拟教师:提供个性化教学,如语言陪练、医学模拟训练。
- 商业服务
客服/导购:银行、电商中的24小时智能助手。
- 医疗与健康
心理疏导:AI数字人提供情感支持。
- 元宇宙
虚拟分身:用户在虚拟世界的数字化身份。
最核心的三个算法部分(这里暂不考虑跨模态的大模型):
1. ASR (Automatic Speech Recognition) 语音识别,现实世界中,我们和数字人的交互基本都是通过对话的方式,所以算法驱动的第一步就是语音识别,这一步将用户的音频数据转化为文字,之所以要这样做是因为我们的大模型输入都是文字。
2. AI Agent,充当了数字人的大脑,这里也可以直接接一个大语言模型,强调Agent的概念是为了让数字人拥有记忆模块等更加真实。
3. TTS (Text to Speech) 文字转语音,大语言模型的输出也是文字,但是数字人的交互输出是通过说话的方式,所以需要将文字转换为语音。
基于 Dify 应用我们可以快速实现数字人灵魂的编排和运维,在需要修改三个组件中任一部分时,只需要编辑 Dify 应用更新即可,无需任何代码上的修改部署。同时依托于Dify强大的 AI workflow 编排、RAG 检索、模型管理、丰富的工具库使用等能力可以帮助开发者在实际应用场景中快速验证和调试,给数字人的探索发展提供了无限的可能性!
二、准备工作
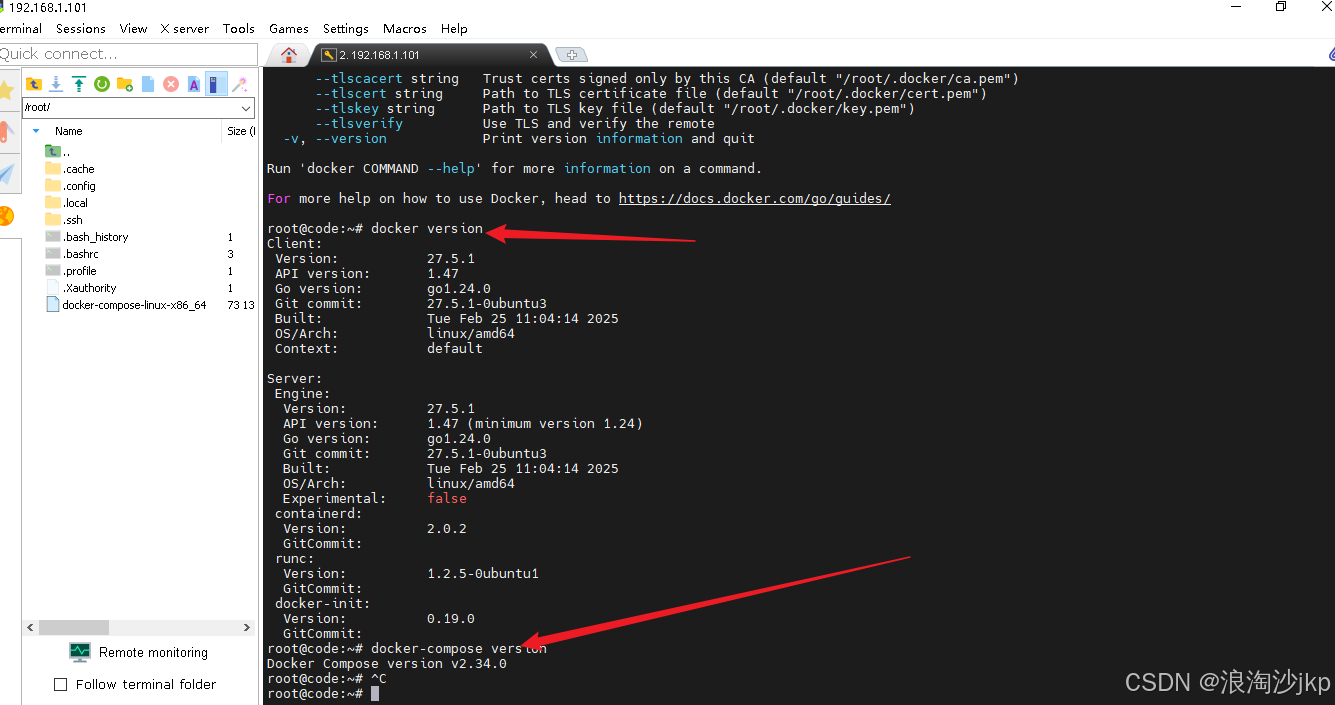
1、安装docker和docker-compose
参考以下文章
AI大模型学习二十三、在ubuntu 25.04 物理机docker-compose 安装code server 实现云IDE平台指南,并安装dify v1.3.1-CSDN博客![]() https://blog.csdn.net/jiangkp/article/details/147940632?spm=1011.2415.3001.5331
https://blog.csdn.net/jiangkp/article/details/147940632?spm=1011.2415.3001.5331
2、ollama 部署qwen3
ollama run qwen3:14b
# 后台运行
nohup ollama run qwen3:14b > output.log 2>&1 < /dev/null &
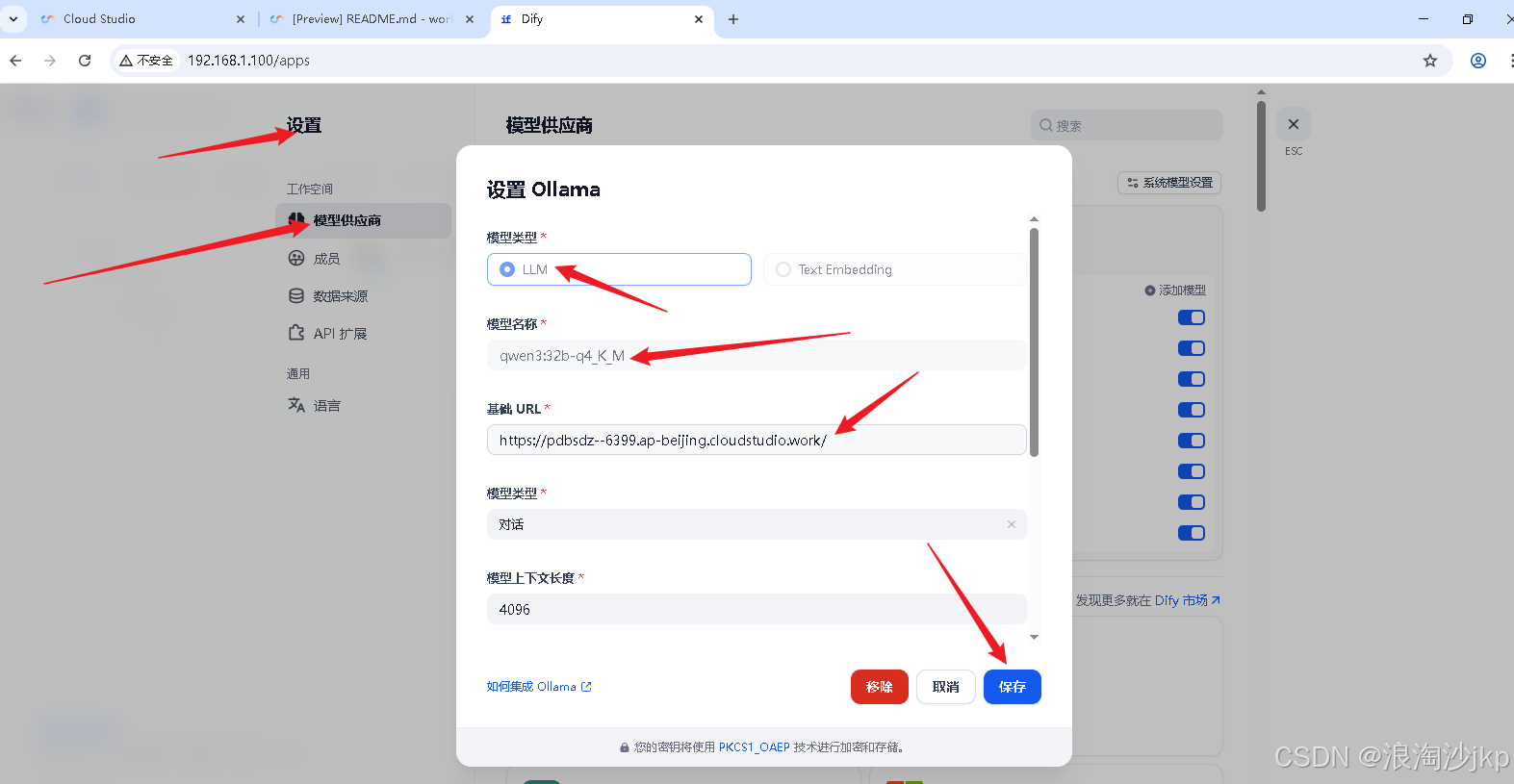
3、dify添加模型
安装自己安装的添加
三、部署awesome-digital-human-live2d
1、下载源码
git clone https://github.com/wan-h/awesome-digital-human-live2d.git2、配置 All in Dify
All in Dify 将数字人的三大基础组件(asr、tts、agent)均接入 Dify,要求 Dify构建的应用需要开启文字转语音以及语音转文字功能,启动时使用 Dify 的配置文件启动服务,config_all_in_dify.yaml 配置文件默认使用 DifyASR、DifyTTS、DifyAgent。
cp configs/config_all_in_dify.yaml config.yaml
3、镜像启动
docker-compose up --build -d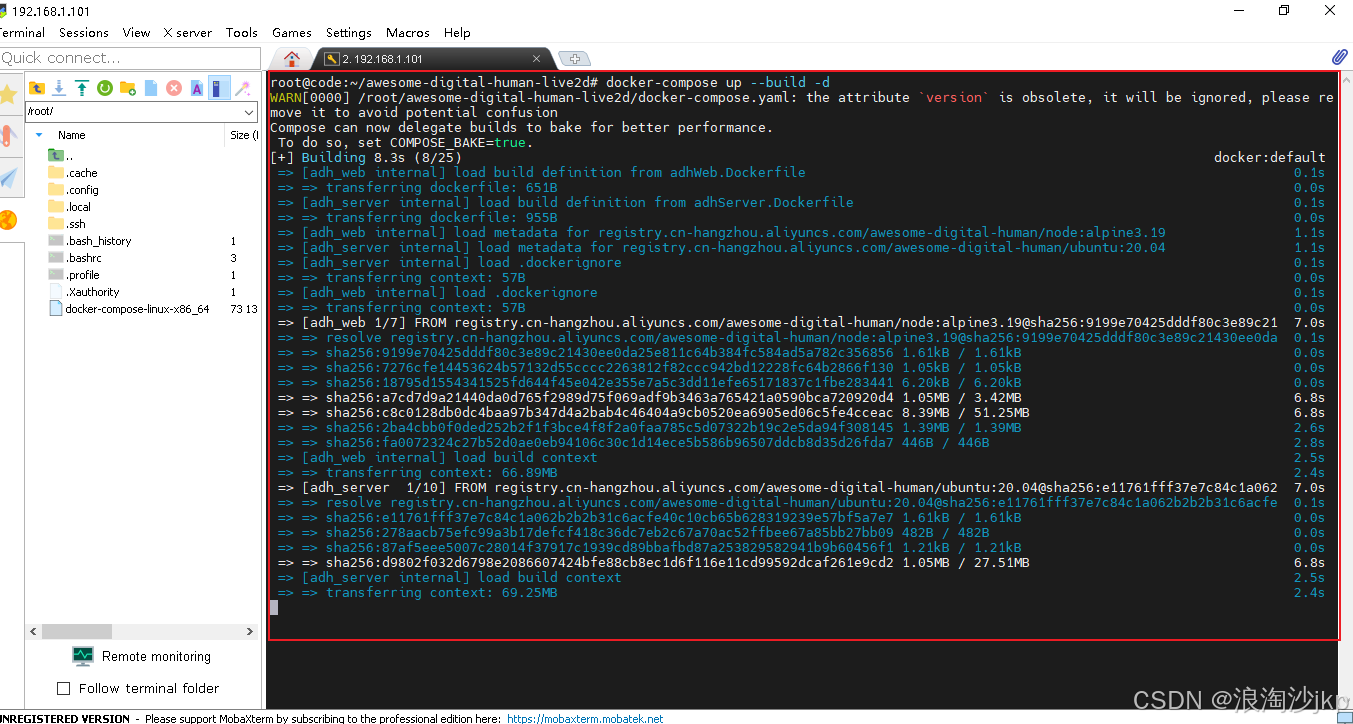
4、浏览访问
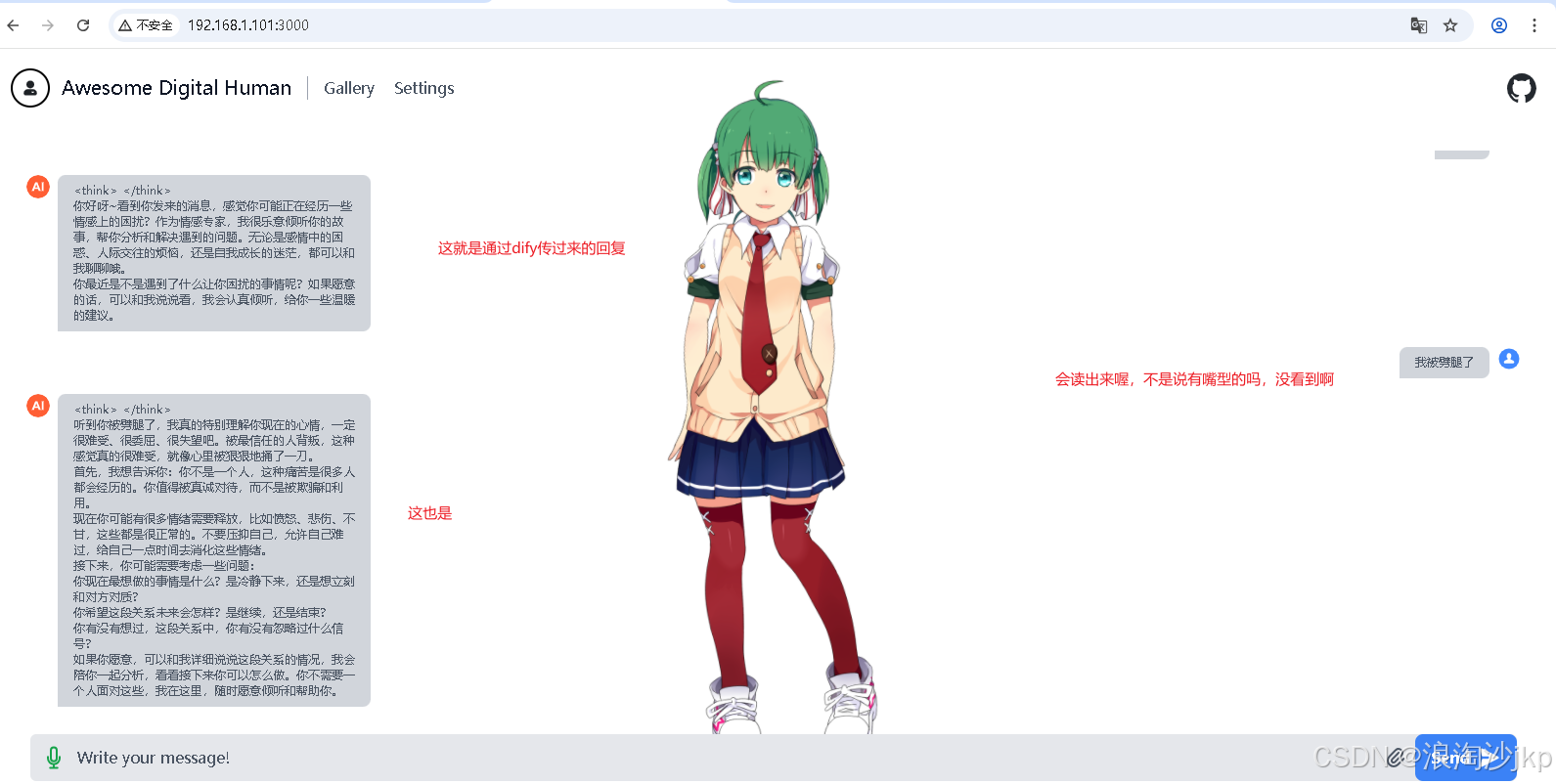
http://192.168.1.101:3000
四、在XInference上部署ChatTTS为Dify提供本地TTS服务
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
apt-get update
apt-get install ffmpeg
conda create --name xinference python=3.12
#conda remove --name xinference --all
conda activate xinference
# 根据自己的cuda选择,我的是12.0,但是没有cu120 所以我们用cu121 这里安装不好,会导致错误
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install xxhash -i https://pypi.tuna.tsinghua.edu.cn/simple
conda install ffmpeg -c pytorch -y
pip install ChatTTS xinference -i https://pypi.tuna.tsinghua.edu.cn/simple
# pip install xinference -i https://pypi.tuna.tsinghua.edu.cn/simple
#安装成功后,只需要输入如下命令,就可以在服务上启动 Xinference 服务:
xinference-local -H 0.0.0.0安装成功后,只需要输入如下命令,就可以在服务上启动 Xinference 服务:
xinference-local -H 0.0.0.0Xinference 默认会在本地启动服务,端口默认为 9997。因为这里配置了-H 0.0.0.0参数,非本地客户端也可以通过机器的 IP 地址来访问 Xinference 服务。
启动成功后,我们可以通过地址 http://localhost:9777来访问 Xinference 的 WebGUI 界面了。
我们是在腾讯cloud studio 在线ide上安装的
地址为
https://******--9997.ap-beijing.cloudstudio.work/ 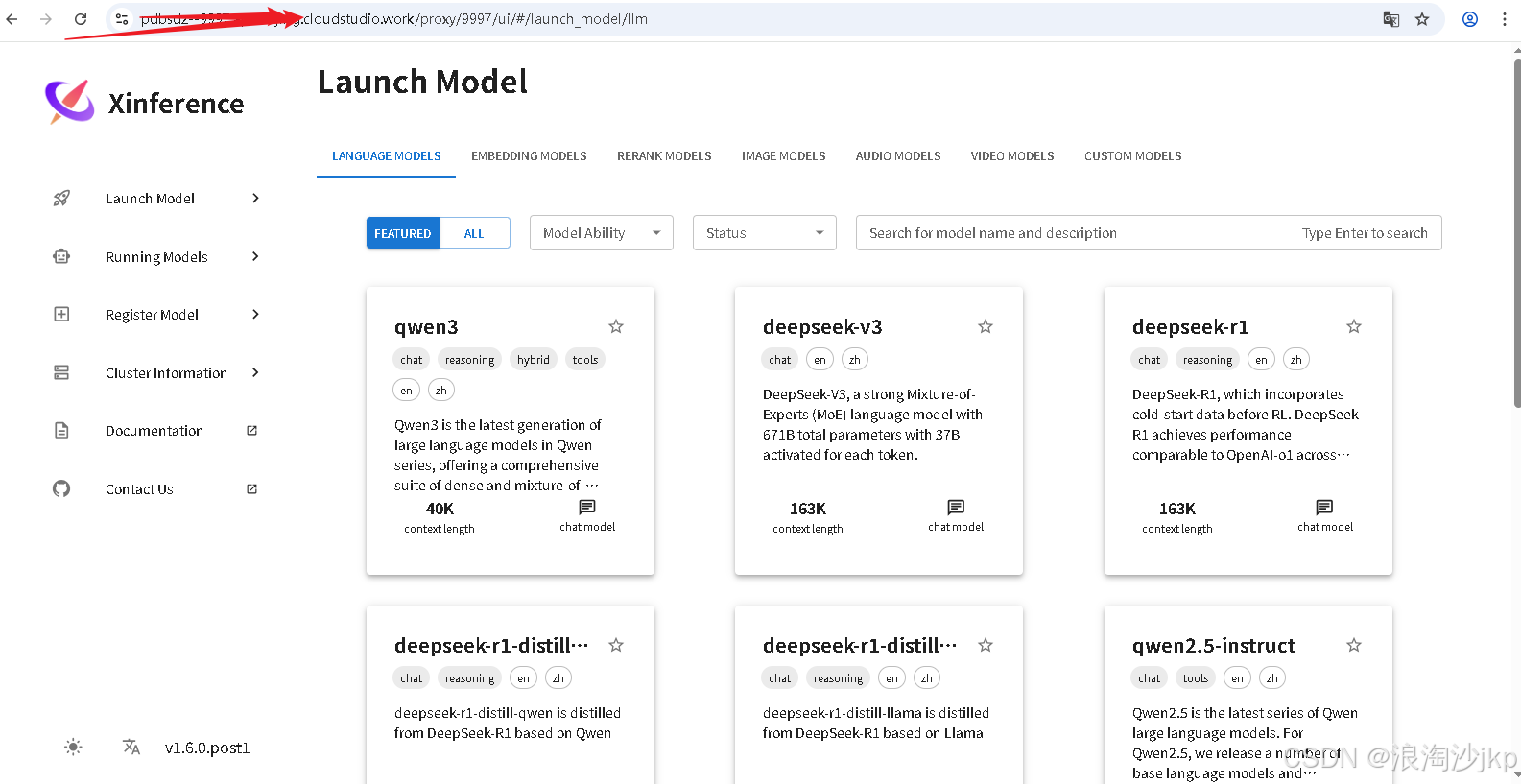
选择:Lauch Model->Audio Model->ChatTTS
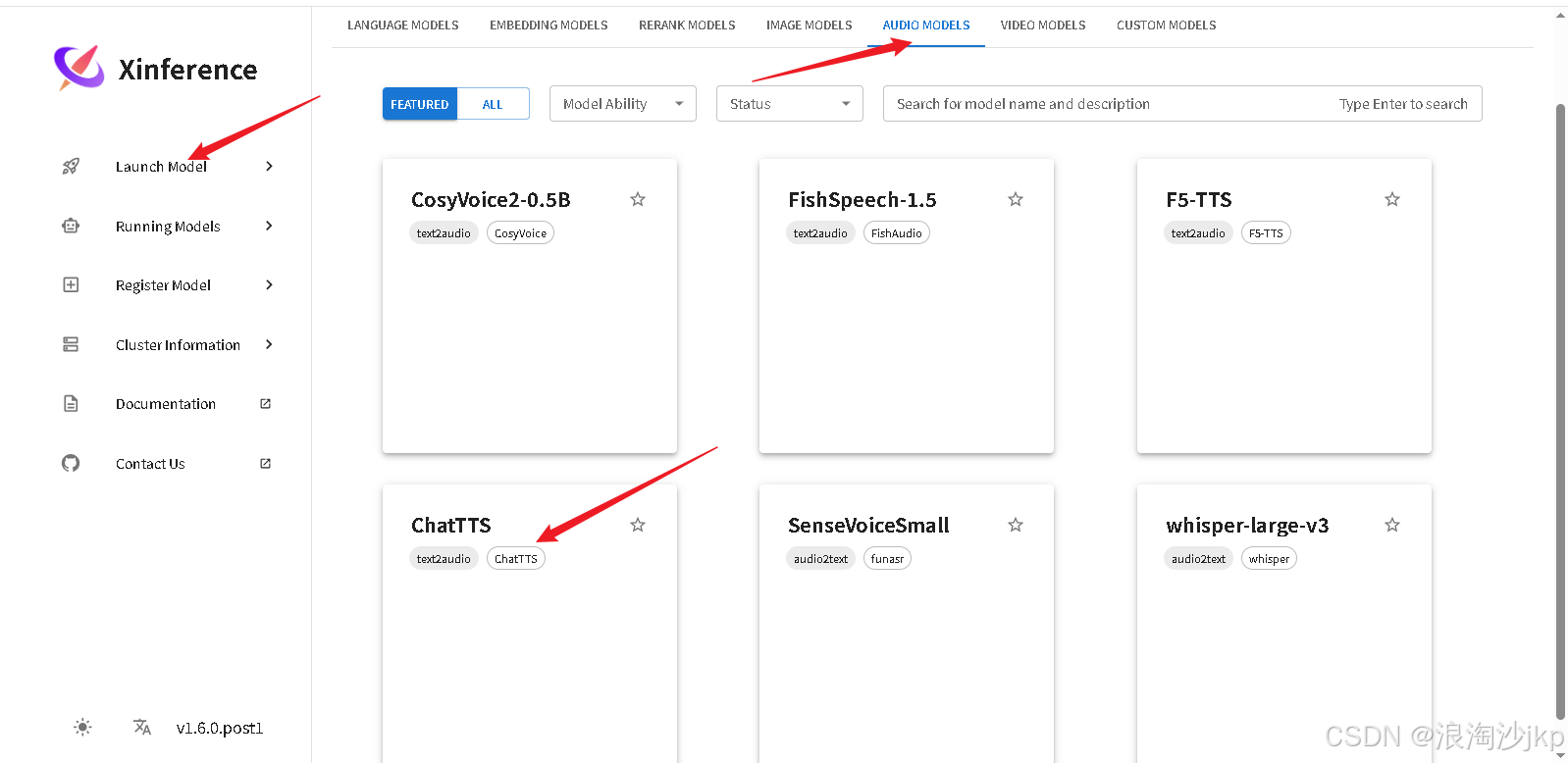
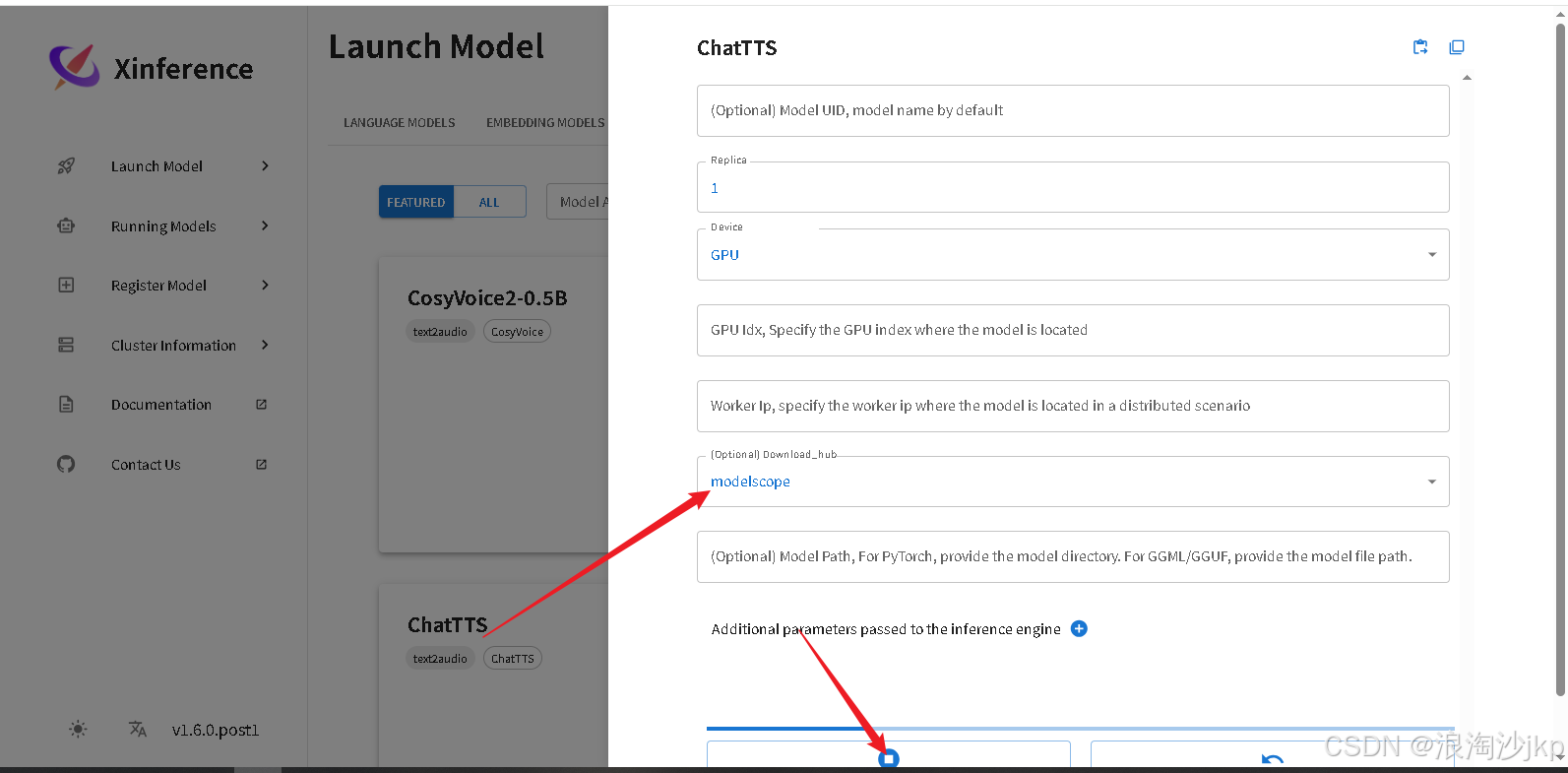
可以提前从ModelScope上下载,或者让XInference自动下载模型。然后就可以运行了。
成功后会在Running Models上看到部署成功的模型。
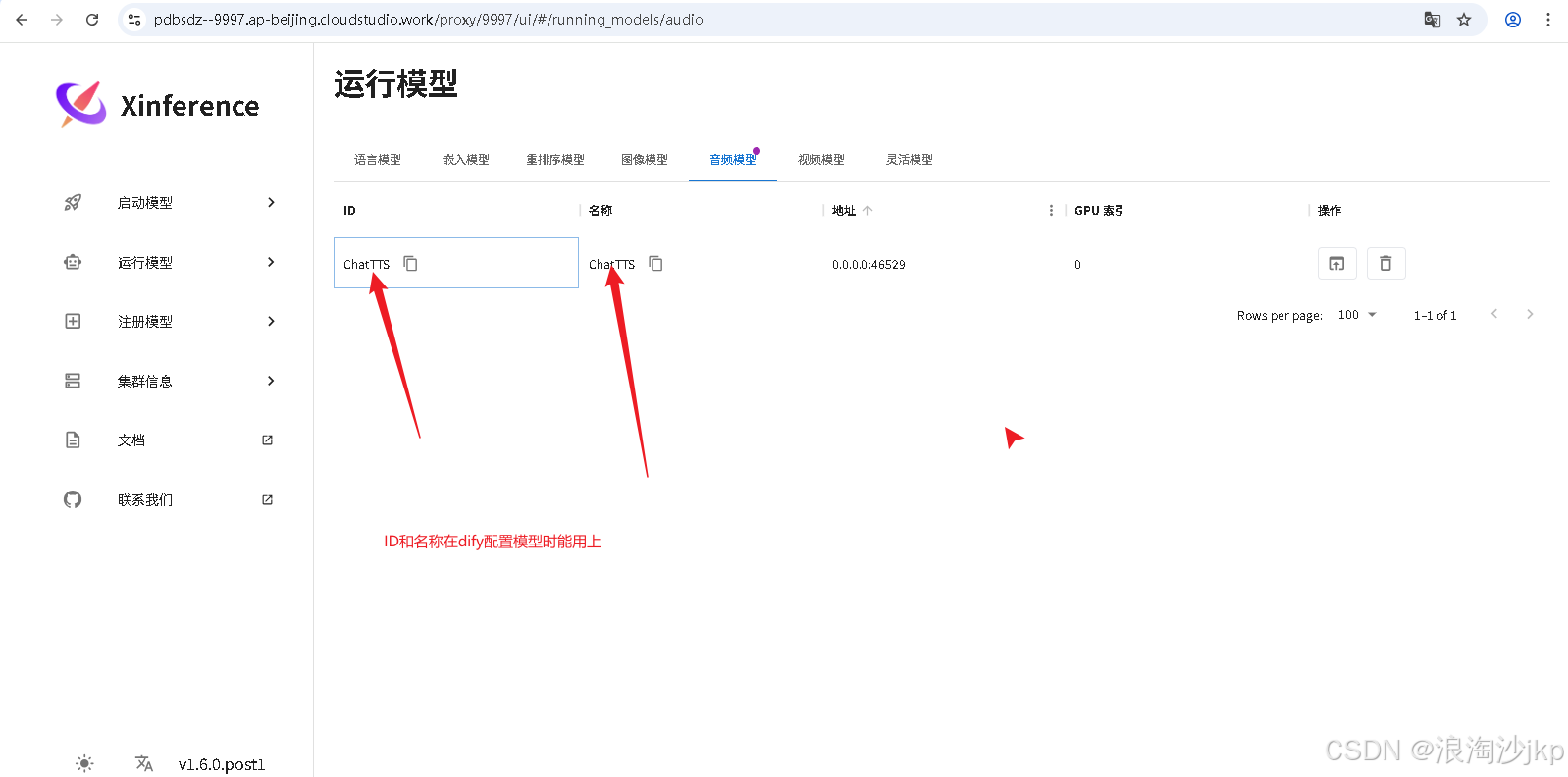
安装插件 Xorbits Inference 搜索时只能输入X才能出来,奇怪喔
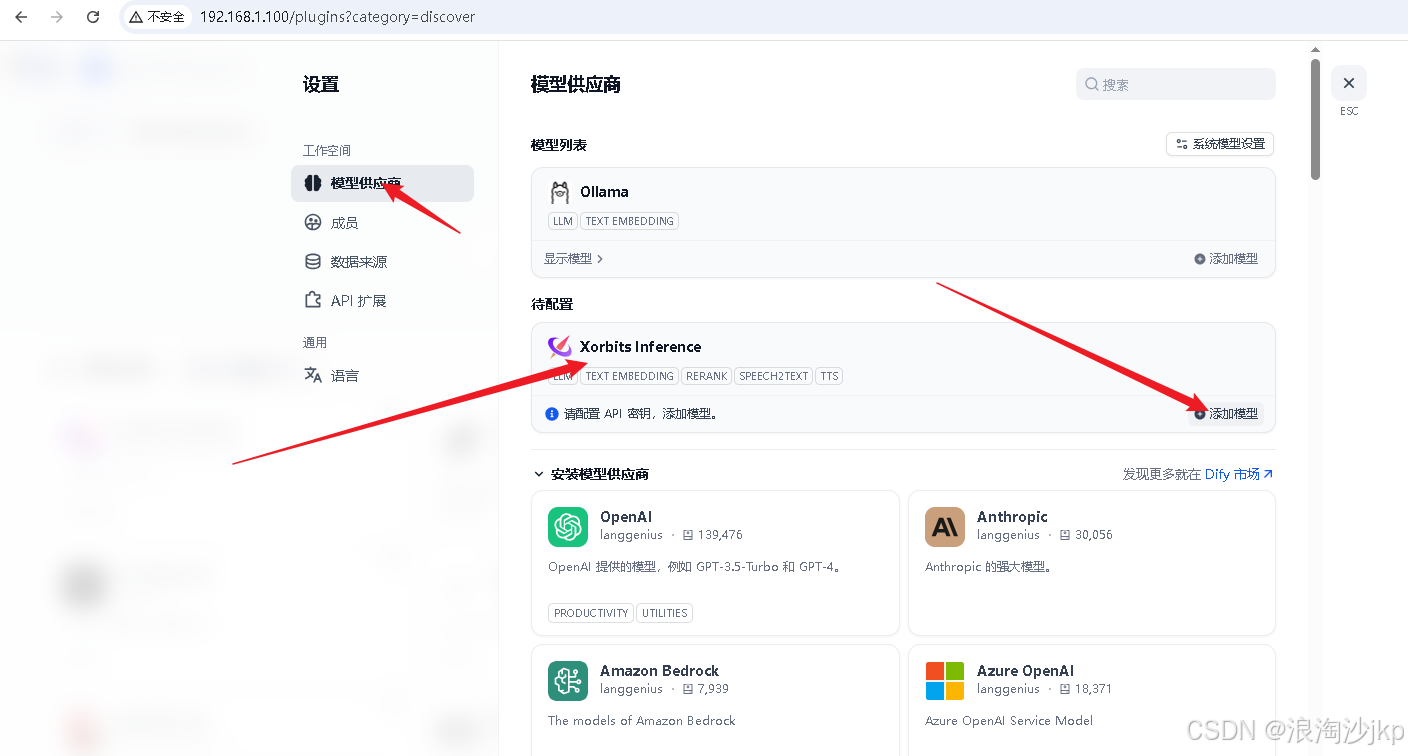
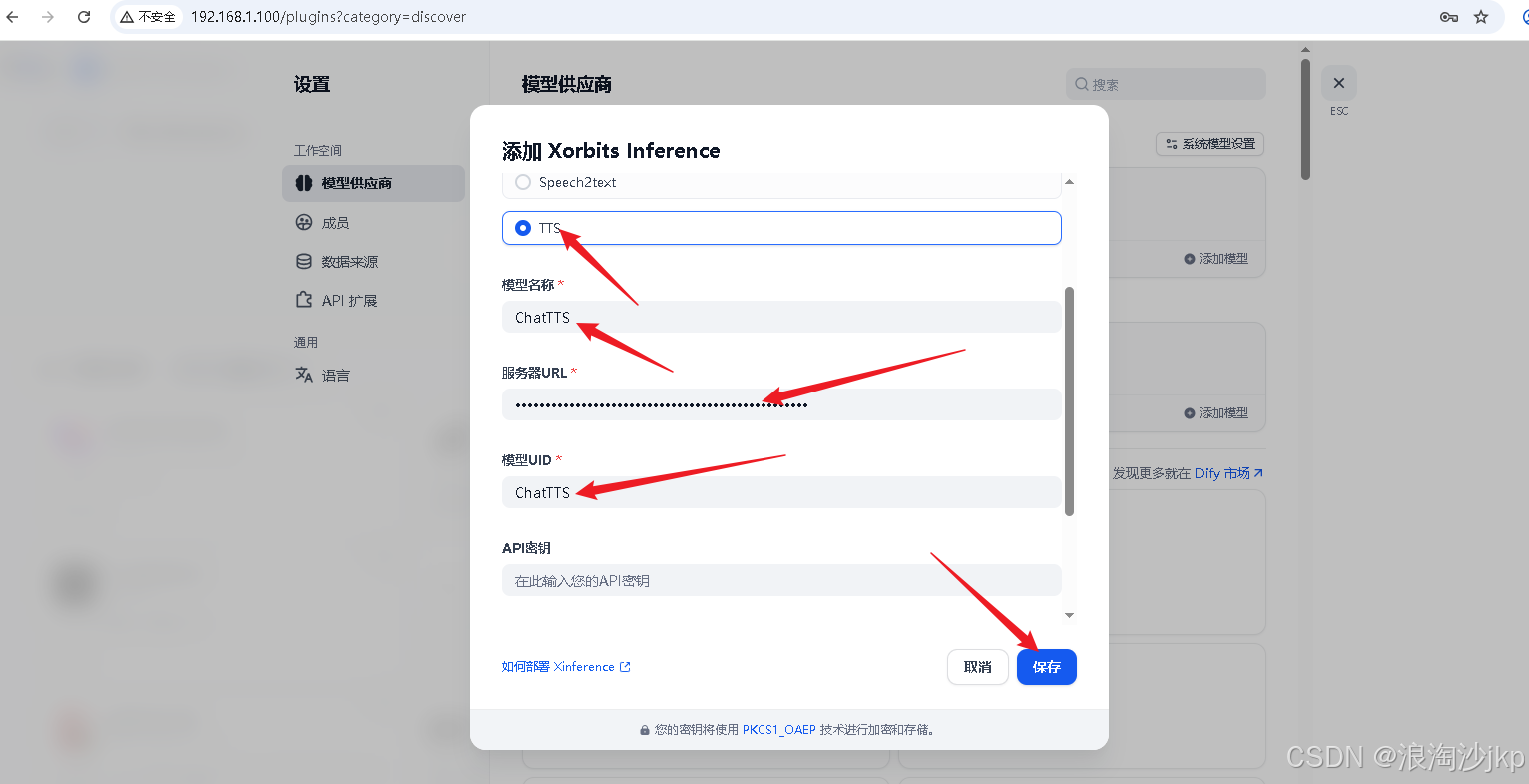
Dify上通过设置-》模型供应商-》Xorits Inference进行配置
五、dify打造数字人
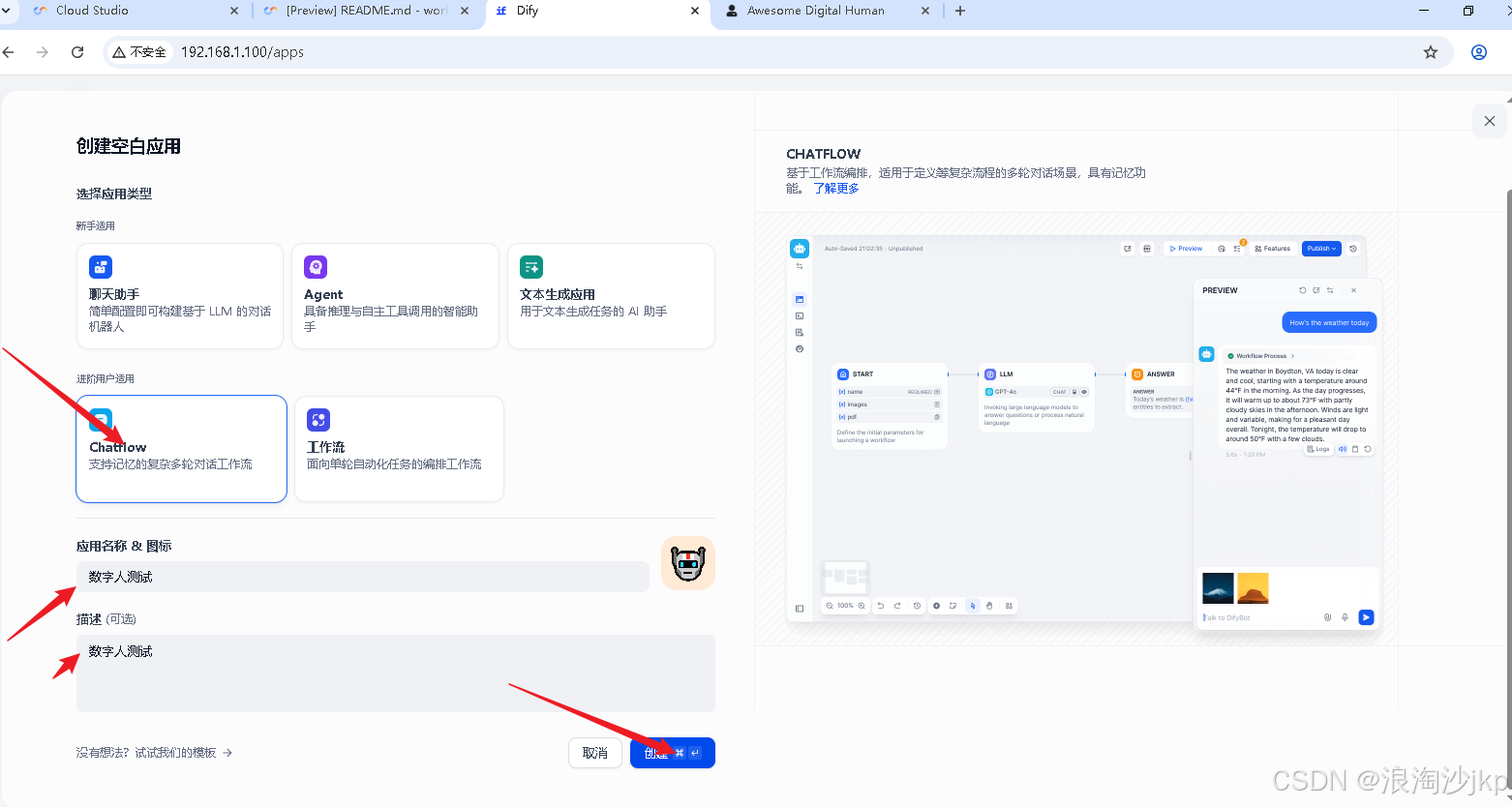
1、创建应用
2、添加LLM模型 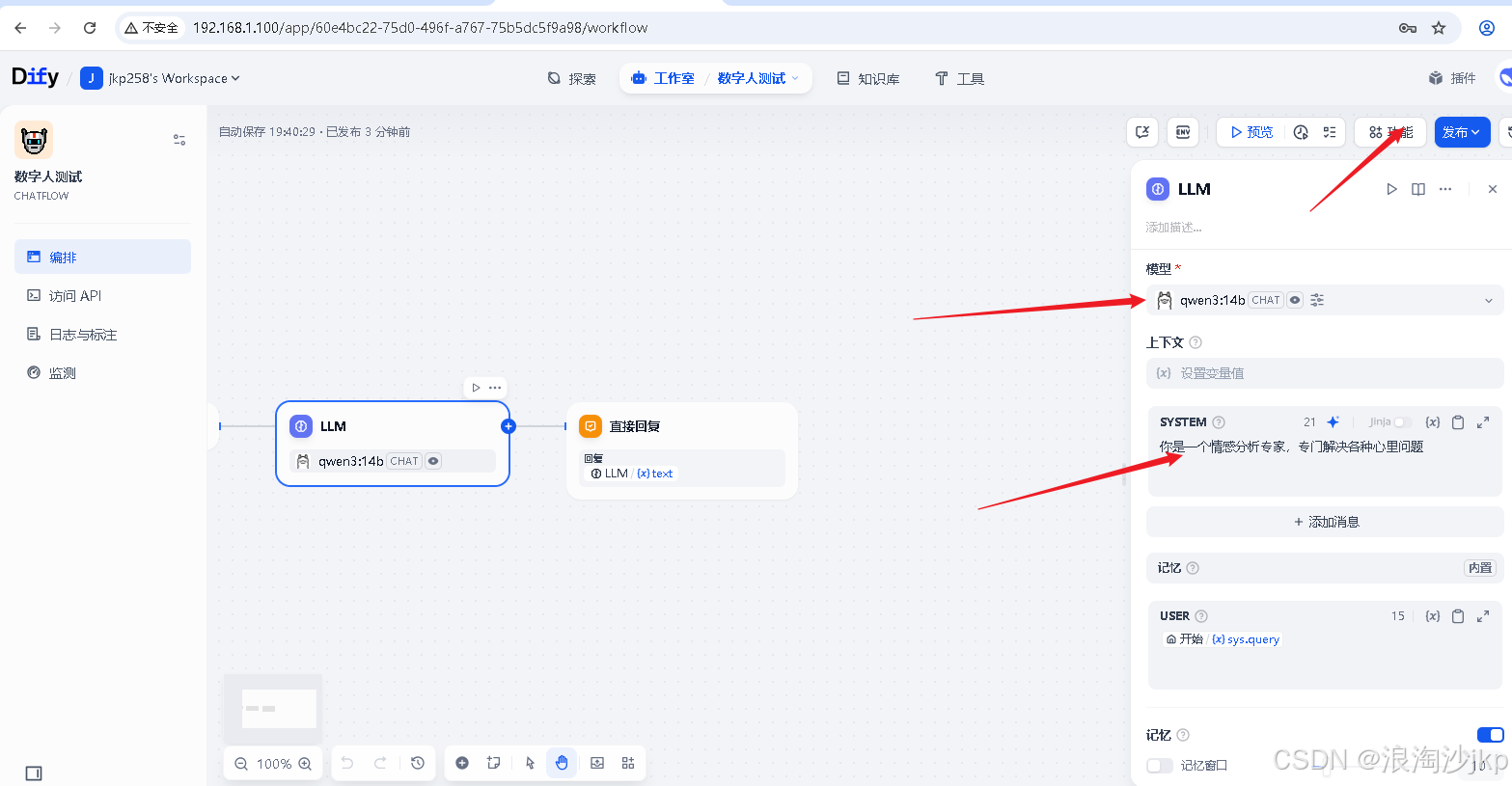
在 User Prompt 或 System Prompt 中添加 /think 和 /no_think 来逐轮切换模型的思考模式
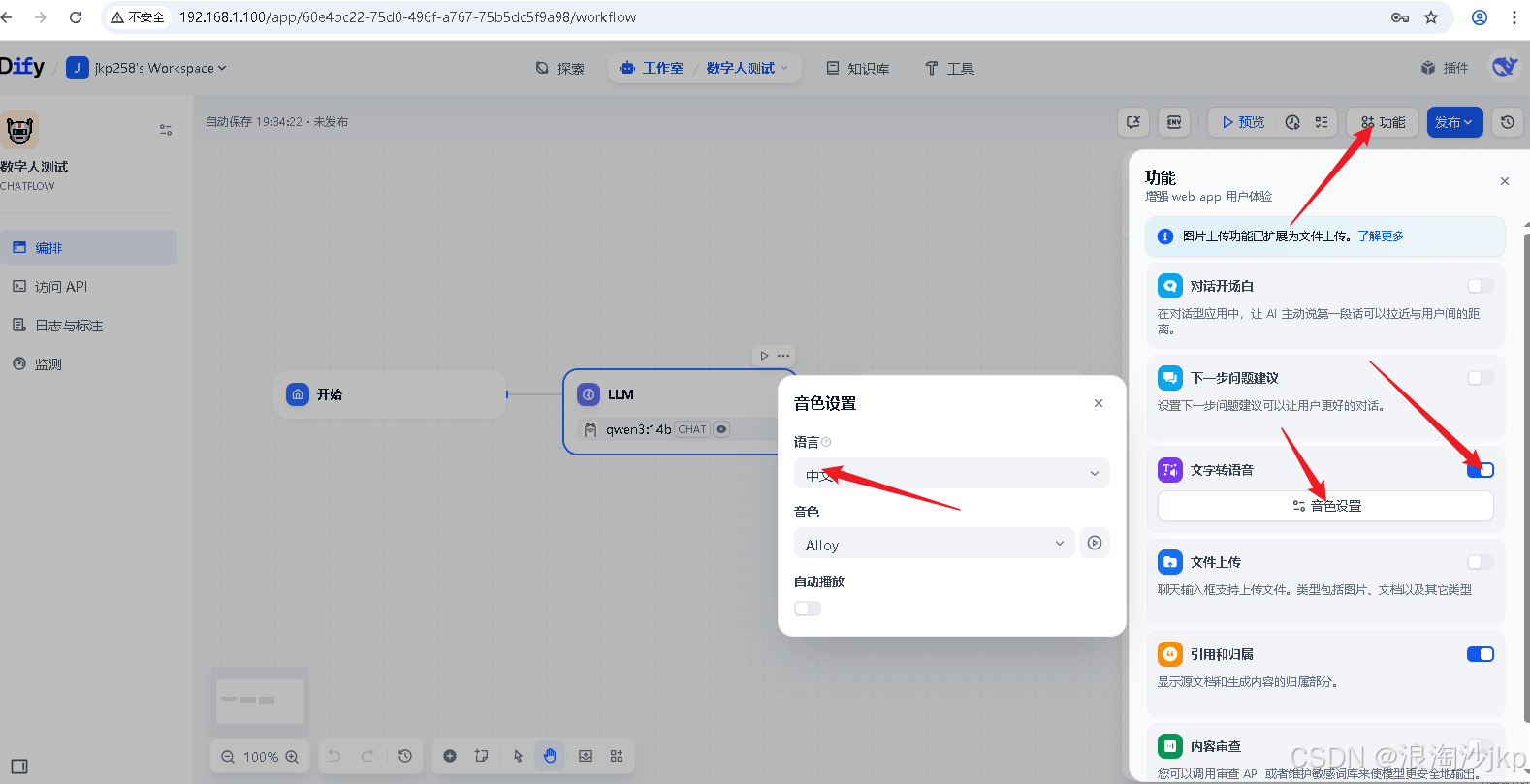
3、配置支持TTS、SPEECH2TEXT、LLM的供应商,或搭建开源API
点击上图功能
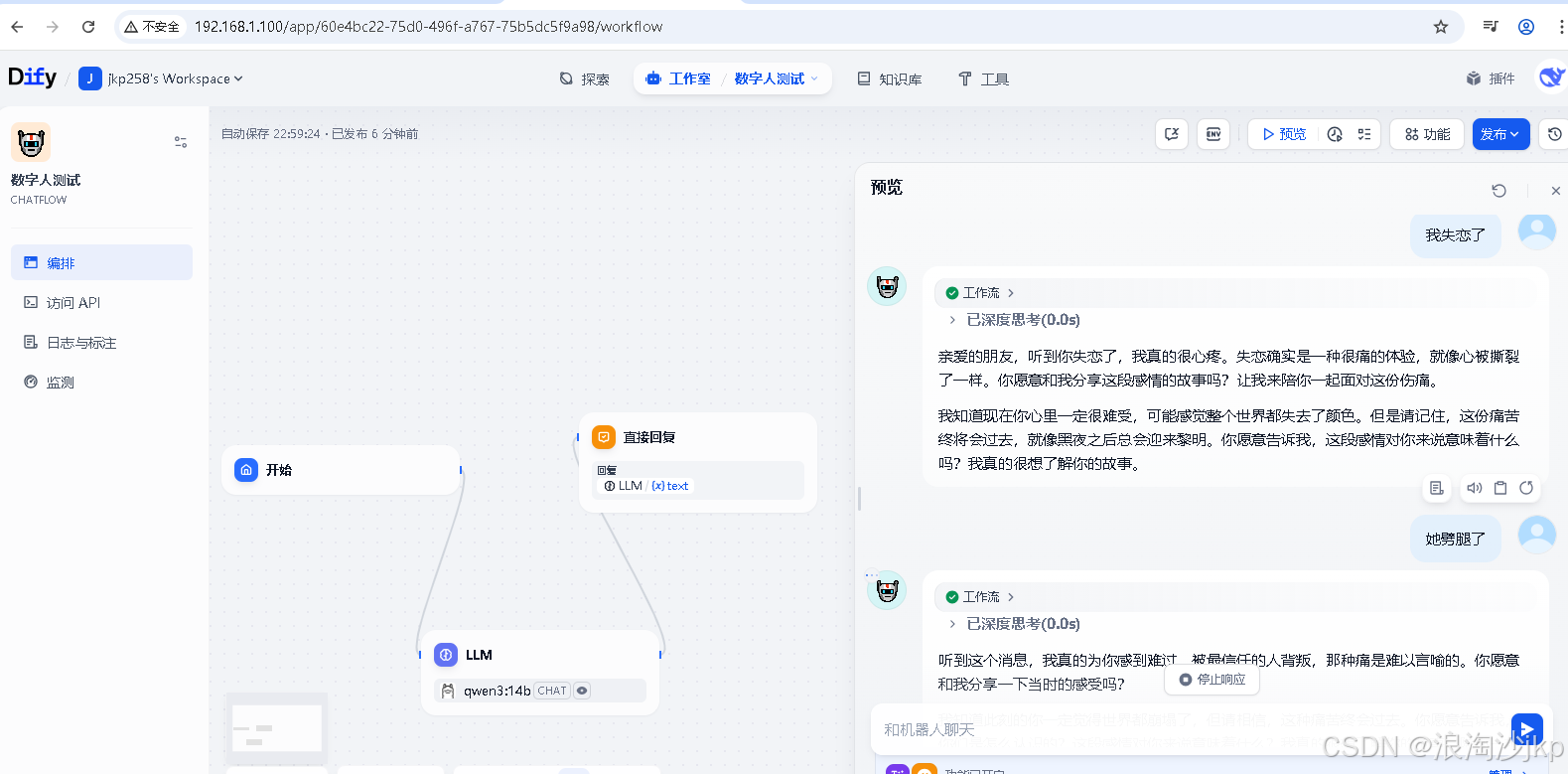
预览测试
4、配置awesome-digital-human-live2d
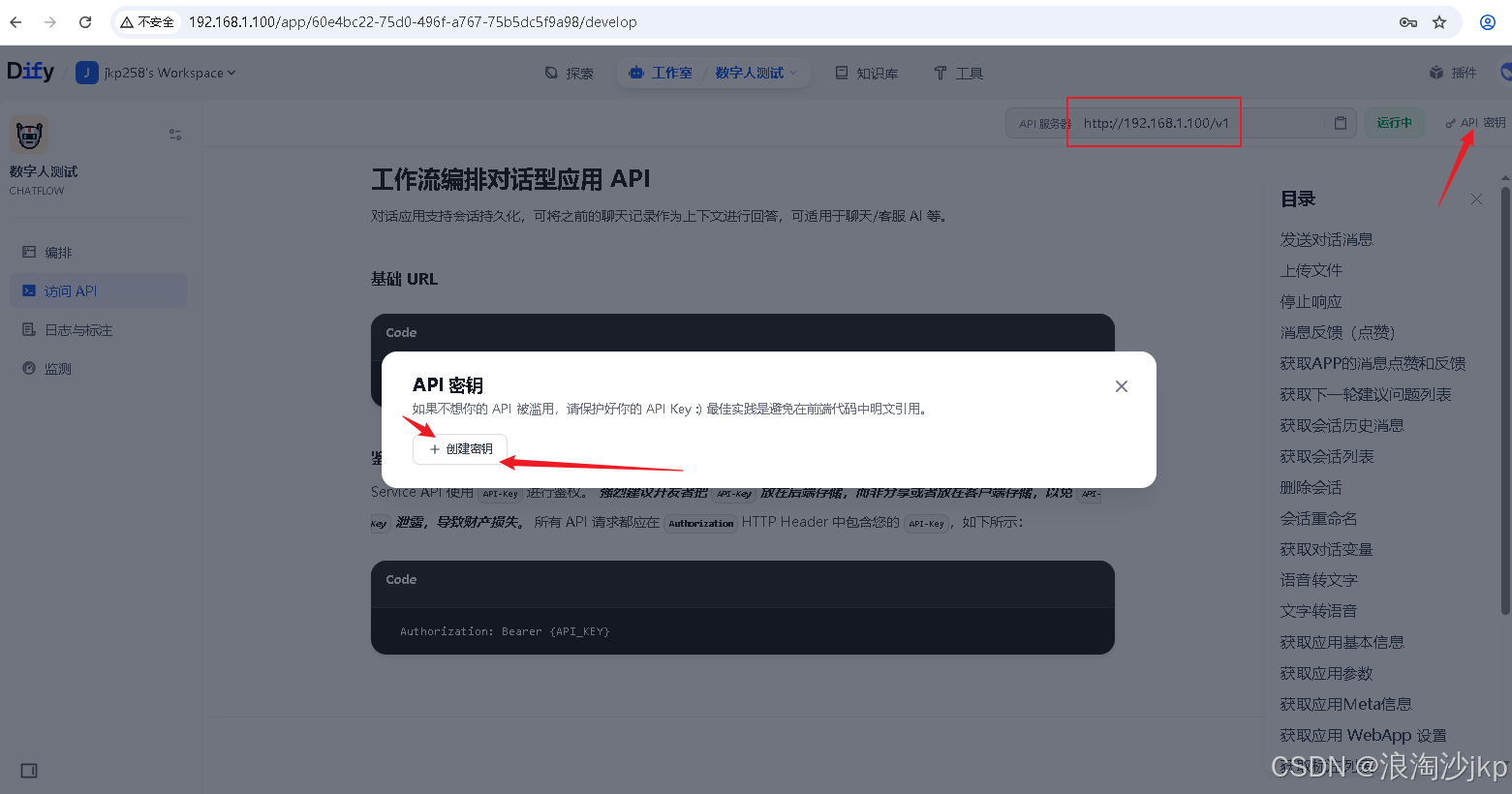
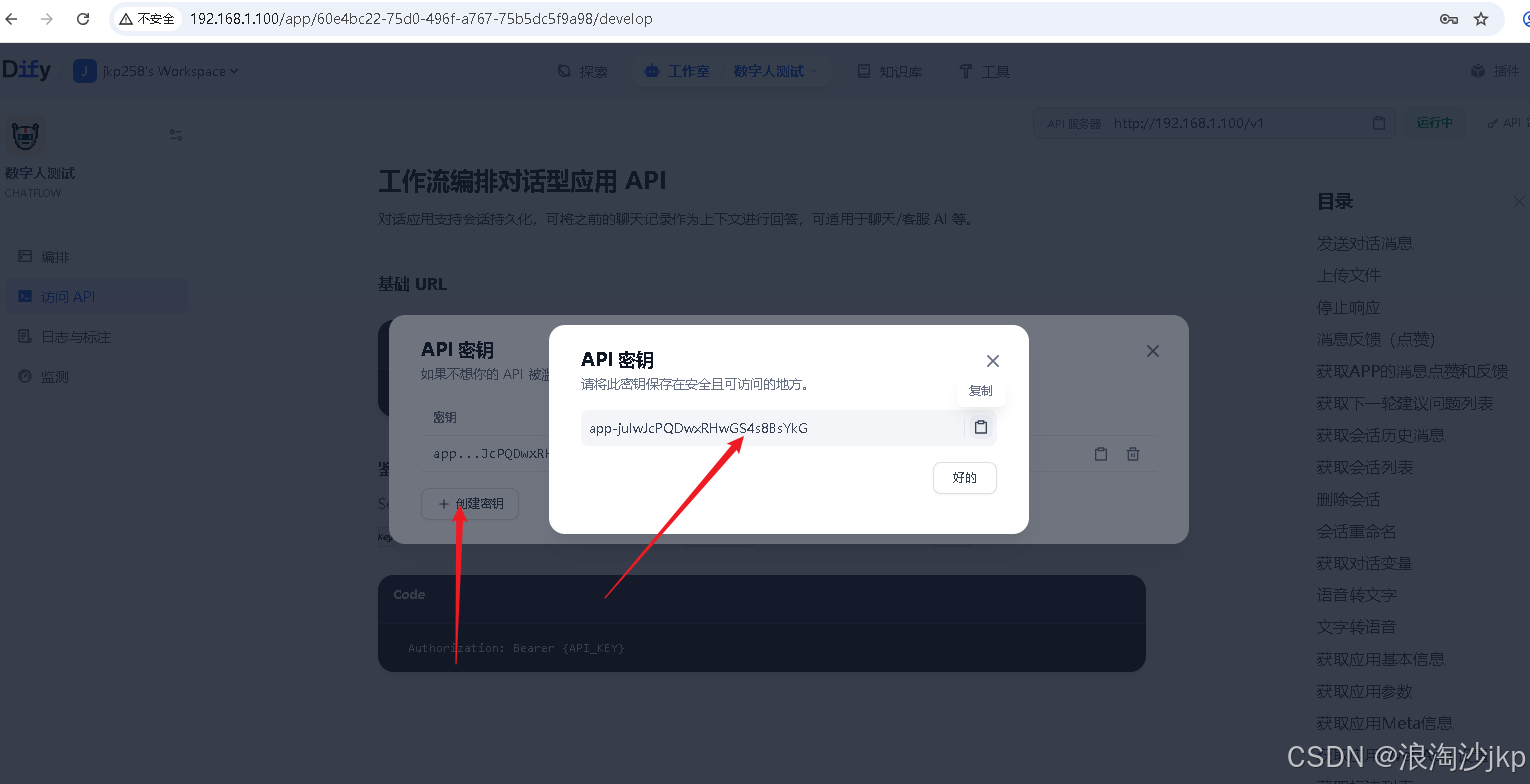
(1)获取 Dify API 的 URL 和 KEY
(2)数字人前端页面填入 Dify API 的 URL 和 KEY
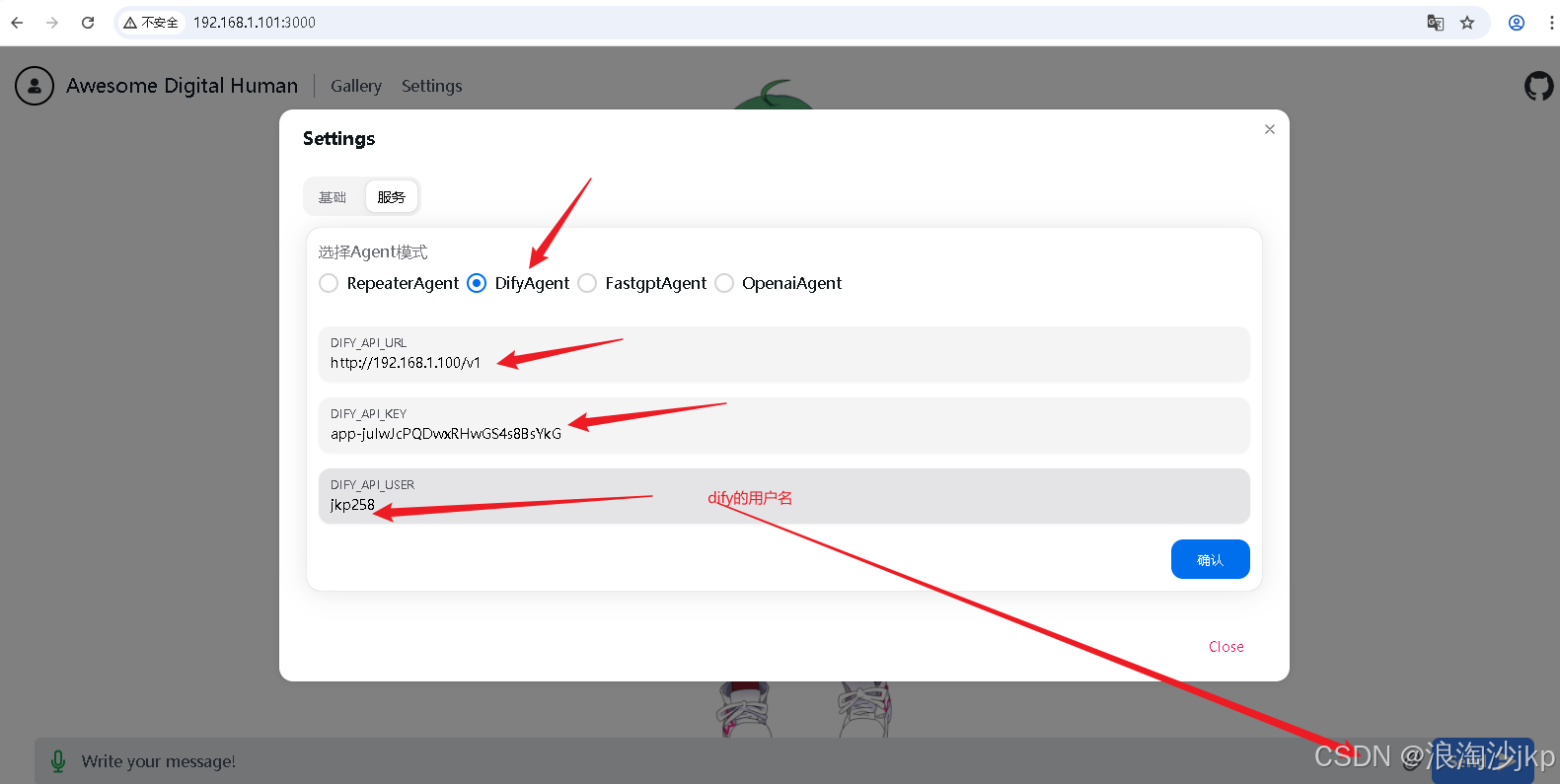
点击确认就成功了,不会直接关闭窗口,没有提示,close后再进来,如果换为difyagent选中,就是设置成功了
(3)聊天测试,数字人使用 Dify 提供的接口完成对话聊天