一、基础概念
1. 什么是ONNX Runtime?
- 定位:由微软开发的跨平台推理引擎,专为优化ONNX(Open Neural Network Exchange)模型的推理性能设计。
- 目标:提供高效、可扩展的推理能力,支持从云到边缘的多硬件部署。
- 核心优势:
- 支持多框架模型转换为ONNX后统一推理(如PyTorch、TensorFlow、MXNet等)。
- 深度优化硬件加速(CPU/GPU/TPU/NPU等),内置自动优化技术。
- 跨平台(Windows/Linux/macOS/嵌入式系统)和编程语言(Python/C++/C#/Java等)。
2. 与其他推理引擎的对比
| 特性 | ONNX Runtime | TensorRT | OpenVINO |
|---|---|---|---|
| 框架兼容性 | 多框架(ONNX统一) | NVIDIA生态优先 | Intel硬件优先 |
| 硬件支持 | 通用(CPU/GPU/TPU等) | NVIDIA GPU | Intel CPU/GPU |
| 量化支持 | 动态/静态量化 | 静态量化为主 | 支持多种量化 |
| 部署场景 | 云、边缘、嵌入式 | 数据中心、边缘 | 边缘推理 |
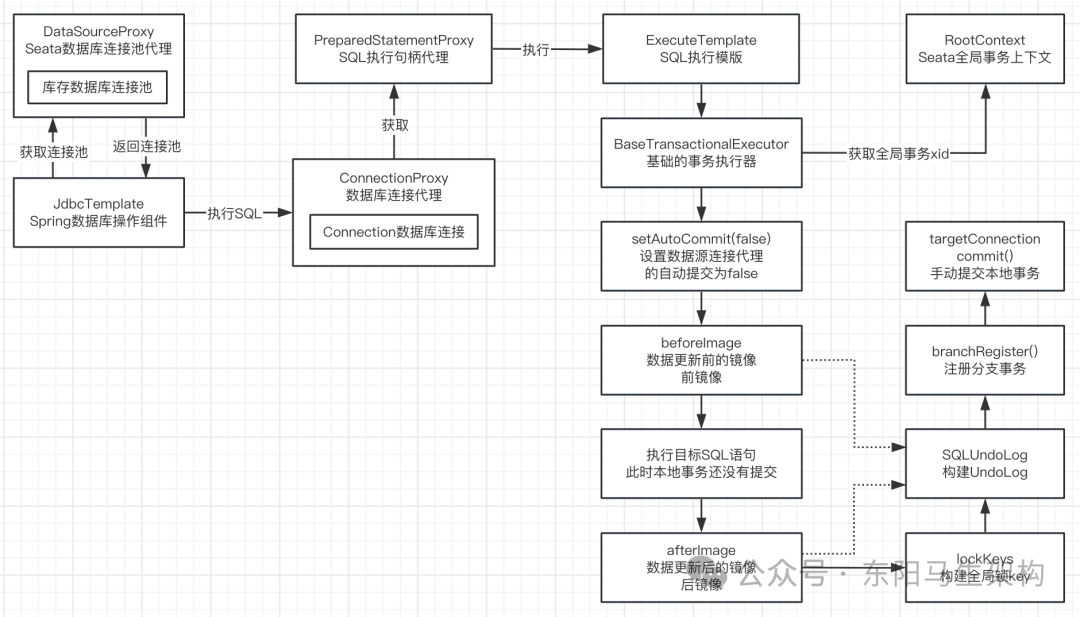
二、架构与核心组件
1. 整体架构

- 前端(Frontend):解析ONNX模型,验证模型结构合法性。
- 优化器(Optimizer):
- 图形优化:算子融合(如Conv+BN+ReLU合并)、常量折叠、死代码消除等。
- 硬件感知优化:根据目标设备生成最优计算图(如CPU上使用MKL-DNN,GPU上使用CUDA/CUDNN)。
- 执行提供器(Execution Providers, EP):
- 负责底层硬件的计算调度,支持多EP(如CPU EP、CUDA EP、TensorRT EP等),可配置优先级。
- 支持异构执行(如CPU+GPU协同计算)。
- 运行时(Runtime):管理内存分配、线程调度、输入输出绑定等。
2. 关键技术模块
- 模型序列化与反序列化:支持模型加载时的动态形状推理。
- 内存管理:基于Arena的内存池技术,减少动态分配开销。
- 并行执行:利用OpenMP/线程池实现算子级并行,支持多会话并发。
三、安装与环境配置
1. 安装方式
- pip安装(推荐):
# CPU版本 pip install onnxruntime # GPU版本(需提前安装CUDA/CUDNN) pip install onnxruntime-gpu - 源码编译:支持自定义硬件后端(如ROCM、DirectML),需配置CMake和依赖库。
- Docker镜像:微软官方提供
mcr.microsoft.com/onnxruntime镜像,含预编译环境。
2. 环境验证
import onnxruntime as ort
print(ort.get_device()) # 输出"CPU"或"GPU"
print(ort.get_available_providers()) # 查看支持的执行提供器
四、模型加载与推理流程
1. 基本流程
import numpy as np
import onnxruntime as ort
# 1. 加载模型
model_path = "model.onnx"
ort_session = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"]) # 可指定EP优先级
# 2. 准备输入数据(需匹配模型输入形状和类型)
input_name = ort_session.get_inputs()[0].name
input_data = np.random.randn(1, 3, 224, 224).astype(np.float32) # 示例输入(如ImageNet格式)
# 3. 执行推理
outputs = ort_session.run(None, {input_name: input_data}) # None表示获取所有输出
# 4. 处理输出
print(outputs[0].shape) # 输出形状
2. 动态形状处理
- 模型导出时需指定动态轴(如
dynamic_axes={"input": {0: "batch_size"}})。 - 推理时支持动态batch_size,但需确保输入维度与模型定义一致。
3. 输入输出绑定
- 预绑定内存以提升性能:
ort_session.bind_input(0, input_data) # 直接绑定numpy数组内存 ort_session.run_with_iobinding() # 高效执行
五、模型优化技术
1. 内置优化选项
- 图形优化级别:
ort_session = ort.InferenceSession( model_path, providers=["CPUExecutionProvider"], sess_options=ort.SessionOptions( graph_optimization_level=ort.GraphOptimizationLevel.ORT_ENABLE_ALL # 开启全优化 ) )ORT_DISABLE_ALL:关闭优化。ORT_ENABLE_BASIC:基础优化(算子融合、常量折叠)。ORT_ENABLE_EXTENDED:扩展优化(如层融合、形状推理)。ORT_ENABLE_ALL:全优化(含硬件特定优化)。
2. 量化(Quantization)
- 动态量化:无需校准数据,直接对模型权重进行量化(适用于快速部署)。
from onnxruntime.quantization import quantize_dynamic quantized_model = quantize_dynamic(model_path, "quantized_model.onnx") - 静态量化:使用校准数据集优化量化精度(推荐用于生产环境):
from onnxruntime.quantization import quantize_static, CalibrationDataReader class MyDataReader(CalibrationDataReader): def get_next(self): # 生成校准数据(如numpy数组) return {"input": np.random.randn(1, 3, 224, 224).astype(np.float32)} quantize_static(model_path, "quantized_model.onnx", data_reader=MyDataReader()) - 量化优势:模型体积减小75%+,CPU推理速度提升2-5倍(需硬件支持INT8计算)。
3. 算子融合(Operator Fusion)
- 合并连续算子(如Conv+BN+ReLU→FusedConv),减少内存访问开销。
- 支持自定义融合规则(通过
onnxruntime.transformers库扩展)。
4. 模型转换与简化
- 使用
onnxoptimizer工具简化模型:from onnxoptimizer import optimize optimized_model = optimize(onnx.load(model_path), ["fuse_bn_into_conv"])
六、硬件支持与性能调优
1. 执行提供器(EP)列表
| 硬件类型 | 执行提供器名称 | 依赖库/驱动 | 优化场景 |
|---|---|---|---|
| CPU | CPUExecutionProvider | MKL-DNN/OpenBLAS | 通用CPU推理 |
| NVIDIA GPU | CUDAExecutionProvider | CUDA/CUDNN | 高性能GPU推理 |
| AMD GPU | ROCMExecutionProvider | ROCm/HIP | AMD显卡推理 |
| Intel GPU | OpenVINOExecutionProvider | OpenVINO Runtime | Intel集成显卡推理 |
| TensorRT | TensorRTExecutionProvider | TensorRT | NVIDIA GPU深度优化 |
| DirectML | DirectMLExecutionProvider | DirectML(Windows) | Windows机器学习加速 |
| 边缘设备(ARM) | CoreMLExecutionProvider | CoreML(macOS/iOS) | Apple设备推理 |
2. GPU性能调优关键参数
sess_options = ort.SessionOptions()
sess_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
sess_options.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL # 顺序执行或并行
sess_options.intra_op_num_threads = 8 # 单算子内部线程数
sess_options.inter_op_num_threads = 4 # 算子间并行线程数
# CUDA特定配置
cuda_provider_options = {
"device_id": "0", # 指定GPU设备ID
"arena_extend_strategy": "kSameAsRequested", # 内存分配策略
"cudnn_conv_algo_search": "EXHAUSTIVE", # 搜索最优卷积算法
}
ort_session = ort.InferenceSession(model_path, providers=["CUDAExecutionProvider"], provider_options=[cuda_provider_options])
3. 混合精度推理(FP16)
- GPU支持FP16计算,需模型中包含FP16权重或动态转换输入为FP16:
input_data = input_data.astype(np.float16) # 转换为半精度
4. 性能分析工具
- ORT Profiler:生成JSON格式的性能分析报告,定位瓶颈算子:
sess_options.enable_profiling = True ort_session.run(None, {input_name: input_data}) with open("profile.json", "w") as f: f.write(ort_session.end_profiling()) - TensorBoard集成:通过
onnxruntime.transformers库可视化计算图和性能数据。
七、高级主题
1. 自定义算子(Custom Operators)
- 场景:模型包含ONNX不支持的算子(如特定框架的私有算子)。
- 实现步骤:
- 继承
onnxruntime.CustomOp类,实现Compute方法。 - 使用
onnxruntime.InferenceSession注册自定义算子:class MyCustomOp(ort.CustomOp): def __init__(self, op_type, op_version, domain): super().__init__(op_type, op_version, domain) def Compute(self, inputs, outputs): # 自定义算子逻辑(如Python/C++实现) outputs[0].copy_from(inputs[0] * 2) # 示例:双倍输入 # 注册算子并创建会话 custom_ops = [MyCustomOp("MyOp", 1, "my_domain")] ort_session = ort.InferenceSession(model_path, providers=["CPUExecutionProvider"], custom_ops=custom_ops)
- 继承
2. 扩展ONNX Runtime
- 自定义执行提供器:为新硬件(如ASIC/NPU)开发EP,需实现
IExecutionProvider接口(C++)。 - Python扩展:通过
c_extension模块加载C++自定义算子,提升性能。
3. 与其他框架集成
- PyTorch:直接使用
torch.onnx.export导出模型为ONNX,无需中间转换。 - TensorFlow:通过
tf2onnx工具转换TensorFlow模型:pip install tf2onnx python -m tf2onnx.convert --saved-model saved_model_dir --output model.onnx - Keras/TensorFlow Lite:先转换为TF模型,再通过
tf2onnx转ONNX。
4. 模型加密与安全
- 使用加密工具(如AES)对ONNX模型文件加密,推理时动态解密加载。
- 限制执行提供器权限(如仅允许CPU执行,禁止GPU)。
八、部署场景与最佳实践
1. 服务器端推理
- 场景:高吞吐量API服务(如图像分类、自然语言处理)。
- 优化策略:
- 使用GPU EP+FP16混合精度,提升吞吐量。
- 启用模型量化(静态量化优先),减少内存占用。
- 多会话并行(
inter_op_num_threads设为CPU核心数)。
2. 边缘设备推理
- 场景:智能摄像头、移动设备、嵌入式系统(如Raspberry Pi)。
- 优化策略:
- 使用轻量级模型(如MobileNet、BERT-Lite)+动态量化。
- 选择对应硬件EP(如CoreML for iOS,NCNN for ARM)。
- 启用内存优化(
arena_extend_strategy=kMinimal)。
3. 分布式推理
- 通过ONNX Runtime Server(ORT Server)实现分布式部署:
# 安装ORT Server docker pull mcr.microsoft.com/onnxruntime/server:latest docker run -p 8080:8080 -v /models:/models onnxruntime/server --model_path /models/resnet50.onnx - 支持gRPC/REST API,负载均衡和动态批处理。
九、故障排除与常见问题
1. 算子不支持
- 原因:模型包含ONNX或ORT不支持的算子(如PyTorch的
torch.nn.InstanceNorm2d)。 - 解决方案:
- 使用
onnxsim简化模型,或手动替换算子。 - 开发自定义算子(见上文)。
- 检查ONNX版本兼容性(ORT支持ONNX 1.2+,建议使用最新版)。
- 使用
2. 性能未达标
- 排查步骤:
- 确认是否启用对应EP(如GPU未被识别)。
- 使用Profiler定位瓶颈算子,检查是否未优化(如未融合的Conv+BN)。
- 调整线程数和内存分配策略(如
intra_op_num_threads设为CPU物理核心数)。
3. 内存泄漏
- 原因:多会话共享内存时未正确释放,或自定义算子未管理内存。
- 解决方案:
- 使用
ORT_SESSIONS_CACHE管理会话缓存,避免重复创建。 - 确保自定义算子正确释放输出内存(如Python中使用
torch.no_grad())。
- 使用
十、生态与未来发展
1. 社区生态
- 工具链:ONNX Model Zoo(预训练模型库)、Netron(模型可视化)。
- 扩展库:
onnxruntime-transformers:优化NLP模型(如BERT、GPT)推理。onnxruntime-training:实验性训练支持(与PyTorch集成)。
2. 未来趋势
- 新硬件支持:持续优化对ARM架构、TPU、边缘NPU的支持。
- 自动化优化:基于AI的自动模型压缩与硬件适配(如AutoQuantization)。
- 云原生集成:与Kubernetes、AWS Lambda等云服务深度整合。
总结
ONNX Runtime是当前最通用的推理引擎之一,其核心竞争力在于跨框架兼容性、硬件无关优化和工程化部署能力。掌握其原理与调优技巧,可显著提升模型在不同场景下的推理效率。建议开发者结合官方文档(ONNX Runtime Documentation)和实际项目需求,深入实践模型优化与部署。