这篇博客涉及两个知识点,一个是动态采样,另一个是 DAS 执行。
用户的问题和相关结论
我们看看用户在OceanBase 社区论坛发帖中提出的疑问及其所得出的结论。
问题:收集统计信息之前,为什么会出现计划不稳定的情况?
原帖详见:索引和统计信息问题咨询 - OceanBase - 社区问答- OceanBase社区-分布式数据库
结论:若尚未收集过统计信息,为了创建更优的执行计划,优化器会对表数据进行动态采样。动态采样是在计划生成阶段对数据库对象进行的采样,通过此方式估算行数,并将这些估算值用于代价计算模型中。由于动态采样过程中每次所选的样本数据块具有一定的随机性质,即便表中的数据保持不变,动态采样的结果也可能有所不同,因此可能导致生成不同的执行计划。
用户反馈的问题
下面是这个用户给的计划不稳定的例子,感兴趣的同学可以继续往下看:
第一个问题
用户问的第一个问题就是:为什么收集统计信息前,计划不稳定?
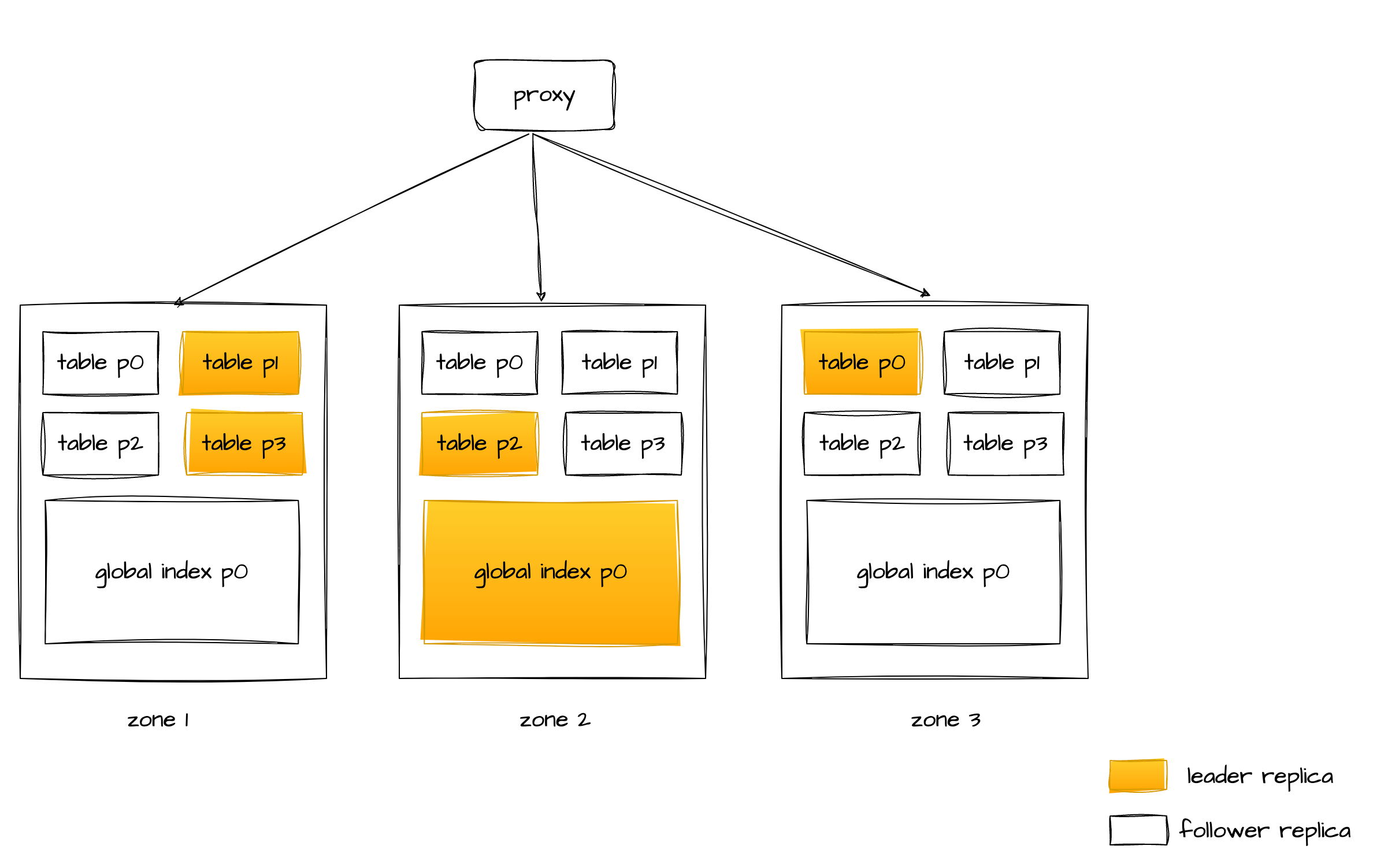
用户的环境信息:三 zone 三副本,各个副本的 leader 打散在三个分区上。
表定义长这样:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`did` varchar(64) DEFAULT NULL COMMENT 'did',
`dxm_uuid` varchar(64) DEFAULT NULL COMMENT 'uuid',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `unique_did_uuid` (`did`, `uuid`) BLOCK_SIZE 16384 GLOBAL,
KEY `I_create_time` (`create_time`) BLOCK_SIZE 16384 LOCAL,
KEY `I_update_time` (`update_time`) BLOCK_SIZE 16384 LOCAL
) REPLICA_NUM = 3
partition by hash(id) PARTITIONS 30;一张三十个分区的分区表,上面有三个索引,一个没有分区的 global index,两个和主表一样有三十个分区的 local index。
执行的 SQL 长这样,十分简单:
SELECT
uuid
FROM
test
WHERE
did = ?
ORDER BY
update_time DESC
LIMIT
?如果没有统计信息,根据不同的动态采样结果,显而易见,可能会出现两种计划。
第一种是走 I_update_time 这个 local index,好处是可以利用这个索引的有序性,优化 ORDER BY update_time DESC 这个排序的动作,消除了各个分区内的排序(个人理解三号算子的 top n sort 不需要真正进行 sort,只需要做 top n 就够了),计划长这样:
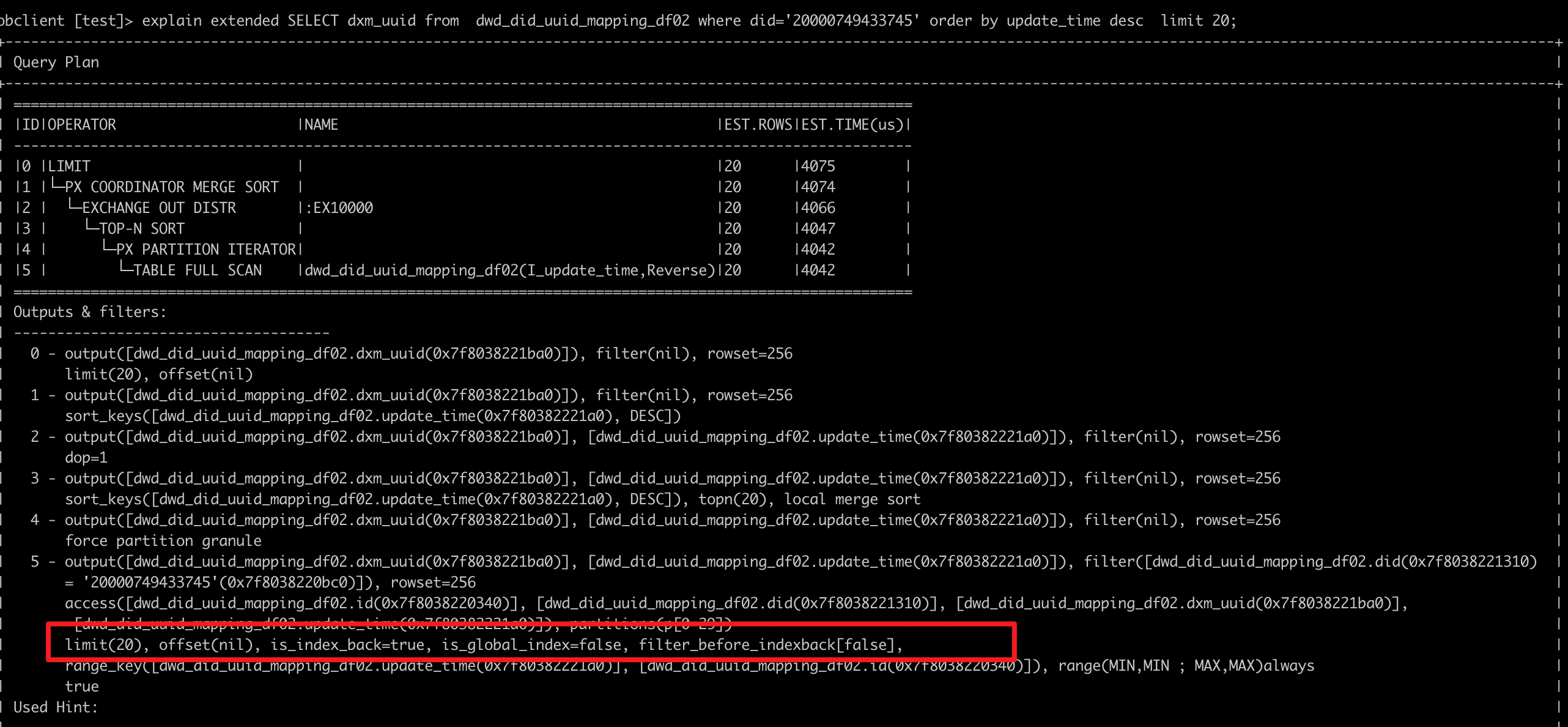
第二种是走 unique_did_uuid 这个 global index,好处是满足 did = ? 这个过滤条件的数据,可以在索引上被快速定位,计划长这样:
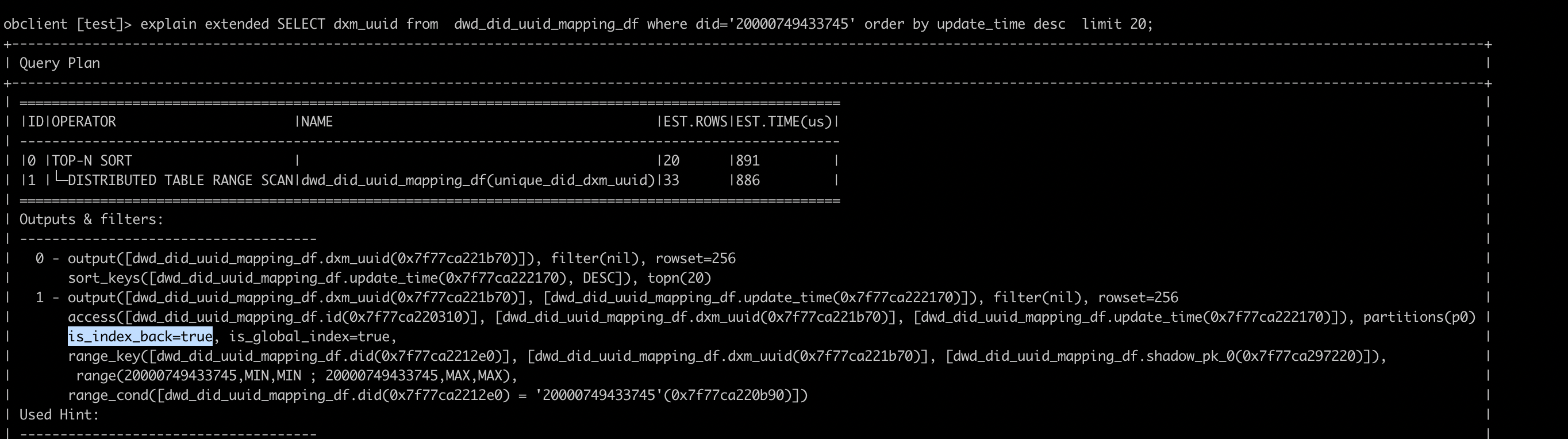
这里用户反馈的是:如果生成第一种走 I_update_time 这个 local index 的计划,就会慢。
如果生成第二种走 unique_did_uuid 这个 global index 的计划,就会快。
因为没有统计信息,所以优化器只能根据动态采样得来的部分数据,算出这两种计划的代价,然后生成代价更低的计划。
即使表中的数据没有发生过变化,因为每次动态采样的数据因为有一定的随机性,会采样到不同的数据,所以可能导致生成的计划不稳定。如果采样到一批比较极端的不能代表整体数据特征的数据,就会导致生成不优的计划。
动态采样的介绍,详见官网链接:https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000822131,咱们这里不多啰嗦。
第二个问题
用户问的第二个问题是:收集了统计信息之后,为什么就能稳定生成第二种更优的本地计划了?
这也是个有意思的问题,需要咱们再来重新回顾一遍问题的背景。
用户的环境信息:三 zone 三副本,各个副本的 leader 打散在三个分区上。
表定义长这样:
CREATE TABLE `test` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`did` varchar(64) DEFAULT NULL COMMENT 'did',
`dxm_uuid` varchar(64) DEFAULT NULL COMMENT 'uuid',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `unique_did_uuid` (`did`, `uuid`) BLOCK_SIZE 16384 GLOBAL,
KEY `I_create_time` (`create_time`) BLOCK_SIZE 16384 LOCAL,
KEY `I_update_time` (`update_time`) BLOCK_SIZE 16384 LOCAL
) REPLICA_NUM = 3
partition by hash(id) PARTITIONS 30;一张三十个分区的分区表,上面有三个索引,一个没有分区的 global index,两个和主表一样有三十个分区的 local index。
执行的 SQL 长这样,十分简单:
SELECT
uuid
FROM
test
WHERE
did = ?
ORDER BY
update_time DESC
LIMIT
?因为这条 SQL 涉及的表是分区表,各个分区的主副本都被打散在了不同的 zone 里,并且 SQL 的过滤条件又不包含分区键,所以 proxy 这个时候是没办法知道要怎么对这条 SQL 进行路由的。这时候 proxy 就会随机路由到任意一台节点上。
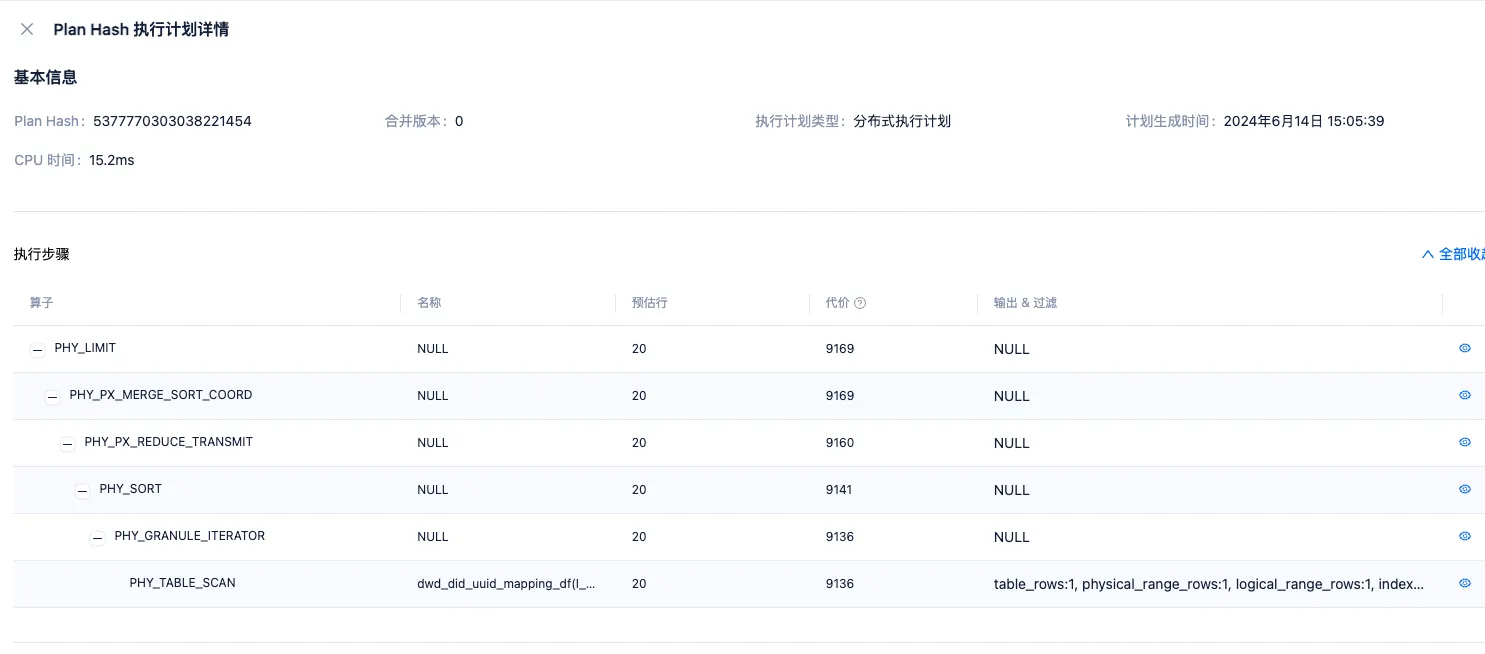
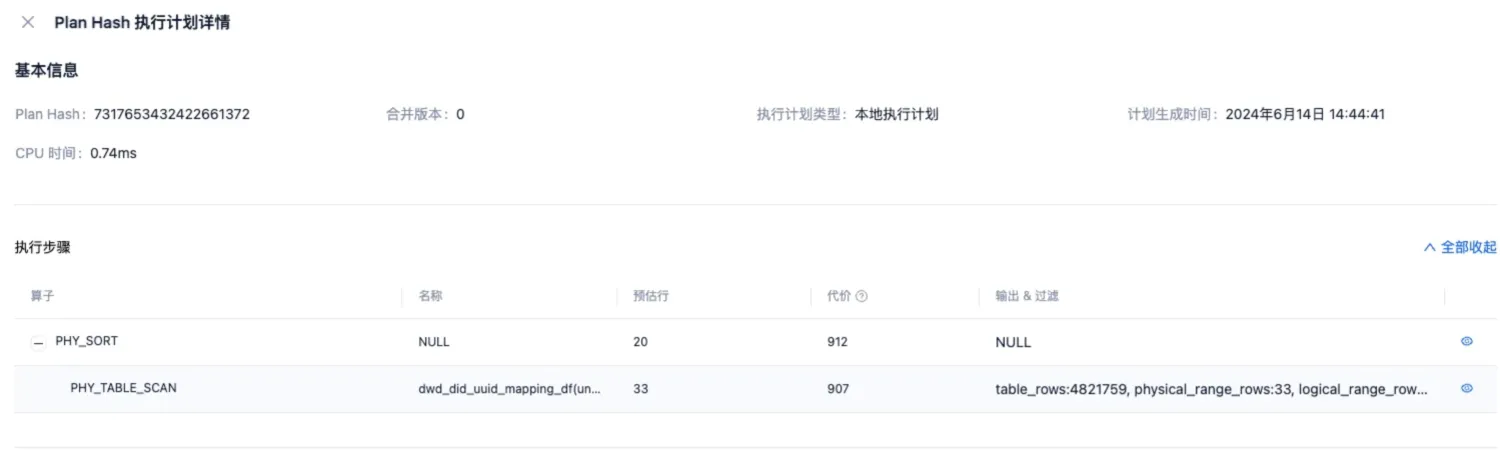
但是收集完统计信息之后,发现可以稳定选择走 unique_did_uuid 这个 global index,计划长这样:
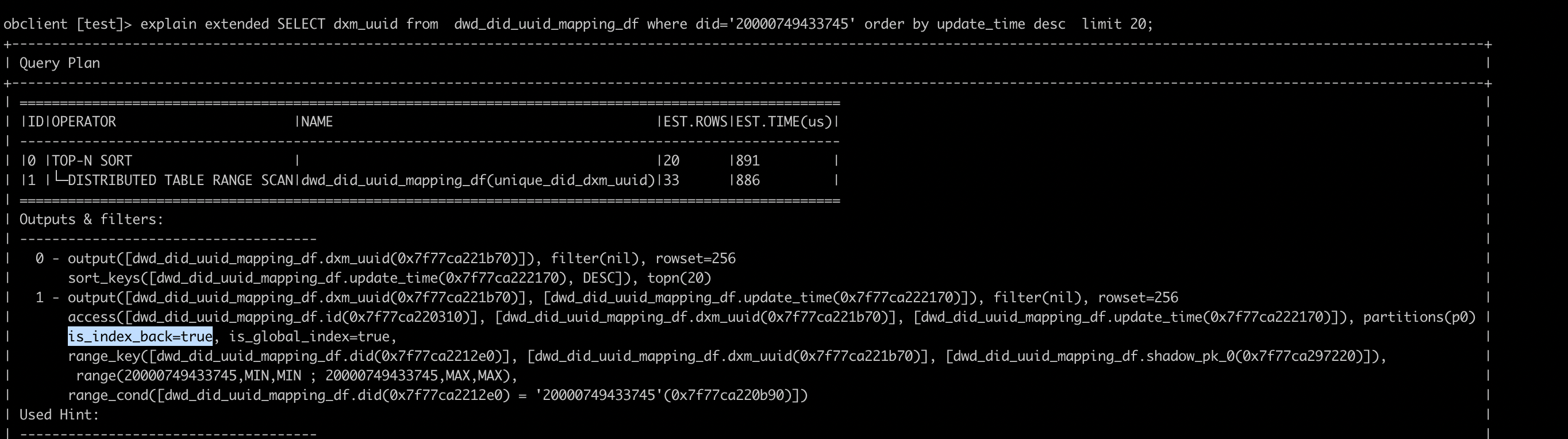
看上去没有 remote xxx 算子和 exchange xxx 算子,不是远程计划和分布式计划,那么这就是个本地计划。
这个计划虽然是本地计划,但是实际也有数据的网络传输。因为 SQL 需要根据 update_time 列进行排序,global index 中并没有这个列的数据,所以过滤完之后,肯定还需要回主表(计划里也可以看到 is_index_back = true)去拿 update_time 列的值,一定还是会走网络的。
不过这个本地计划里的网络传输,和上一个计划有明确的 exchange 算子表示网络传输有所不同,这个计划里的网络传输被封到了一号算子里。一号算子是 DISTRIBUTED TABLE SCAN,含义是 TABLE SCAN 走了 DAS 执行。
大家可以简单地把 DAS 理解成是一种特殊场景下,对网络传输的优化。
DAS 不需要像 remote 或者 exchange 算子一样在网络中把复杂的 SQL 或者子计划在节点间传来传去,而是直接跟存储层交互,通过 RPC 拉取到存储层的数据。
DAS 一般会出现在简单的点查,或者全局索引回表中(刚好就是用户的场景,did = ? 是点查,并且还有全局索引的回表)。DAS 可以通过特殊的 RPC 和存储层直接进行远程数据的交互,所以可以减少在网络里传输 SQL 和子计划的开销。在这两种场景下,通过 DAS 的方式进行数据的网络传输,资源消耗是最小的。
DAS 执行的介绍详见官网链接:https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000217873,咱们依然不在这里多啰嗦。

我们以 proxy 转发 SQL 到 zone2 这台 observer 上为例,那么 zone2 上这台 observer 就会通过 DAS 发 RPC 拉取另外几个节点上的主表数据,进行全局索引回表。
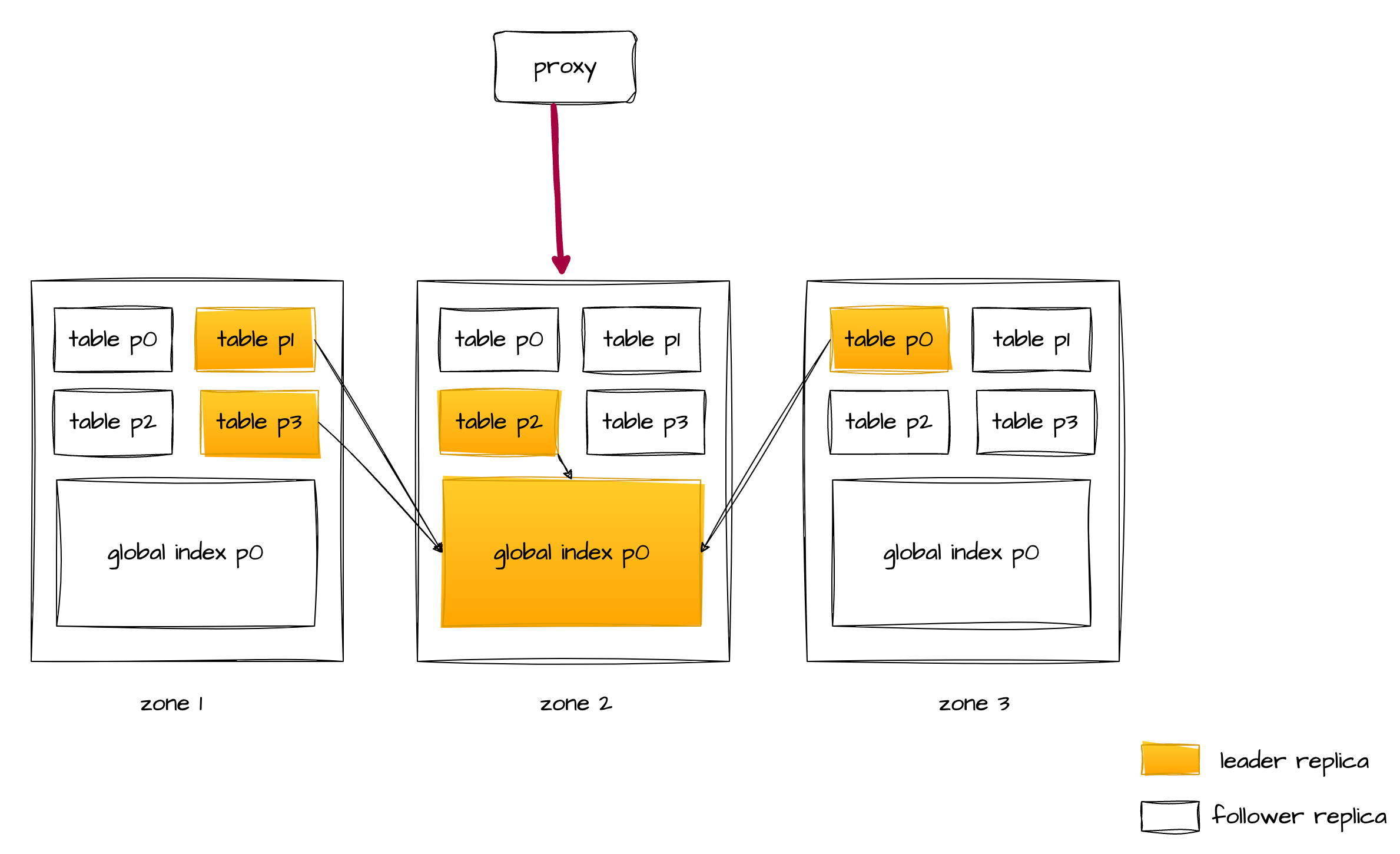
我们以 proxy 转发 SQL 到 zone1 这台 observer 上为例,那么 zone1 上这台 observer 首先会通过 DAS 发 RPC 直接拉取 zone2 上 global index 主副本上的经过过滤之后的数据(过滤条件也一起下压过去了),然后再通过 DAS 发 RPC 拉取另外几个节点上的主表数据,进行全局索引回表。
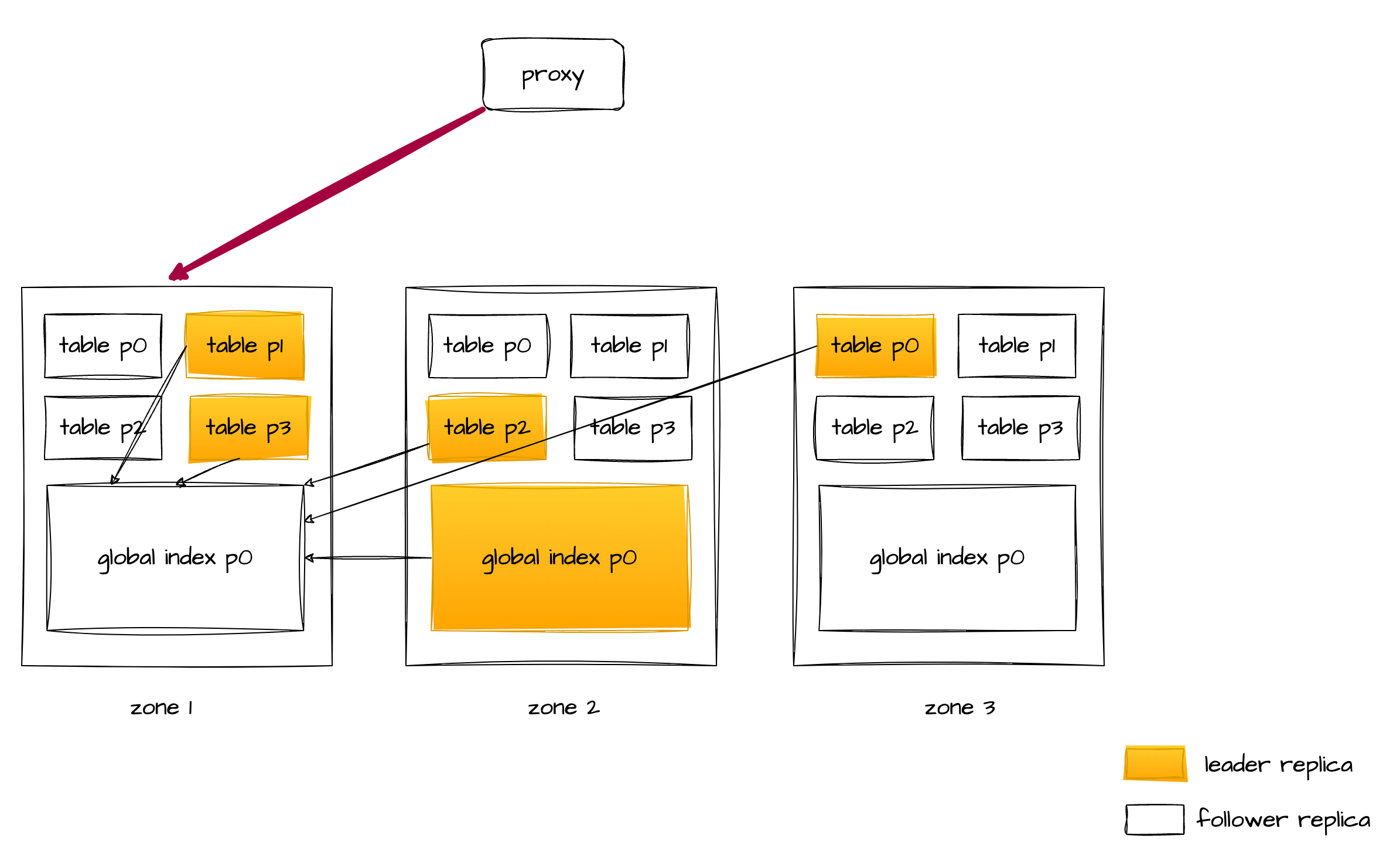
所以无论 proxy 把 SQL 路由到哪个节点,这条 SQL 中网络传输的动作,都被封到一号 DISTRIBUTED TABLE SCAN 算子里了(一号算子通过 DAS 执行完成了全部的网络传输),因此可以生成稳定的计划。