目录
- 前言
- 一、 背景与核心概念
- 1-1、多模态大语言模型(MLLMs)的定义
- 二、MLLMs的架构设计
- 2-1、三大核心模块
- 2-2、架构优化趋势
- 三、训练策略与数据
- 3-1、 三阶段训练流程
- 四、 评估方法
- 4-1、 闭集评估(Closed-set)
- 4-2、开集评估(Open-set)
- 4-3、多模态幻觉评估
- 4-4、 多模态综合能力评估
- 五、扩展方向与技术
- 5-1、模态支持扩展
- 5-2、 交互粒度扩展
- 5-3、语言与文化扩展
- 5-4、 垂直领域扩展
- 5-5、效率优化扩展
- 5-6、 新兴技术融合
- 总结
前言
这篇综述系统梳理了多模态模型的技术栈,从基础架构到前沿应用,并指出当前瓶颈(如幻觉、长上下文)和解决思路。其核心价值在于(1)方法论:三阶段训练(预训练→指令微调→对齐)成为主流范式。(2)开源生态:LLaVA、MiniGPT-4等开源模型推动社区发展。(3)跨学科应用:在医疗、机器人等领域的渗透展示通用潜力。一、 背景与核心概念
1-1、多模态大语言模型(MLLMs)的定义
核心思想:以强大的大语言模型(如GPT-4、LLaMA)为“大脑”,通过模态接口(如视觉编码器)将图像、音频、视频等非文本模态与文本模态对齐,实现跨模态理解和生成。
与传统多模态模型的区别:
- 规模:MLLMs基于百亿参数规模的LLMs,而传统模型(如CLIP、OFA)参数更小。
- 能力:MLLMs展现涌现能力(如复杂推理、指令跟随),传统模型多为单任务专用。
多模态模型发展线如下所示:
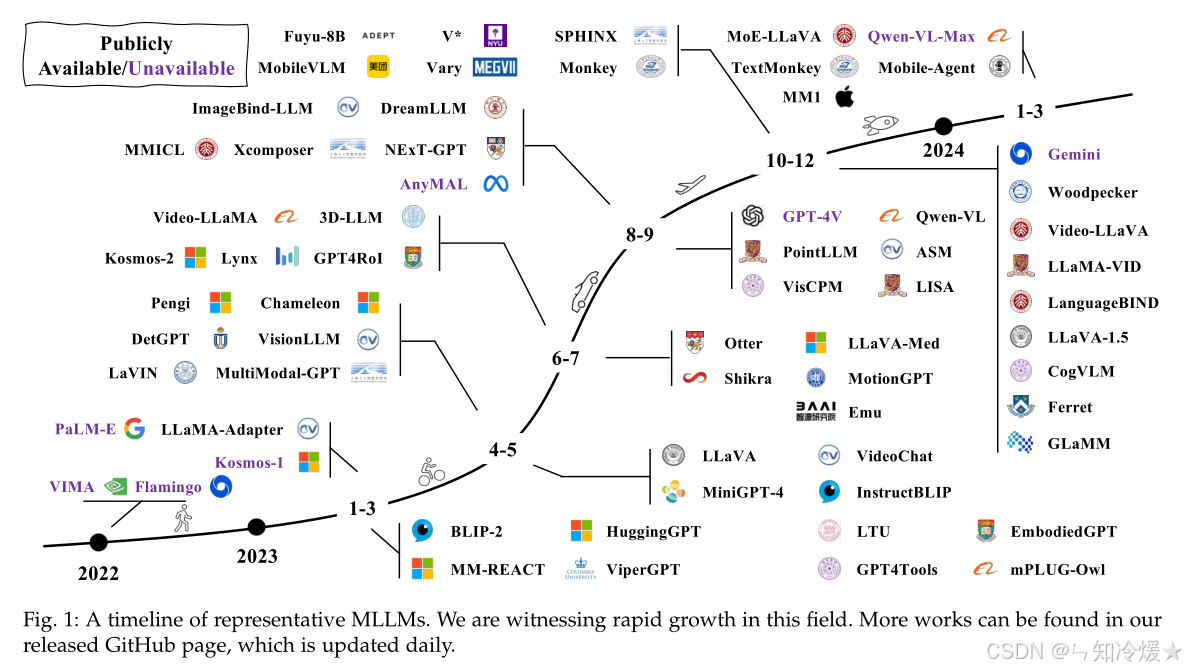
二、MLLMs的架构设计
2-1、三大核心模块
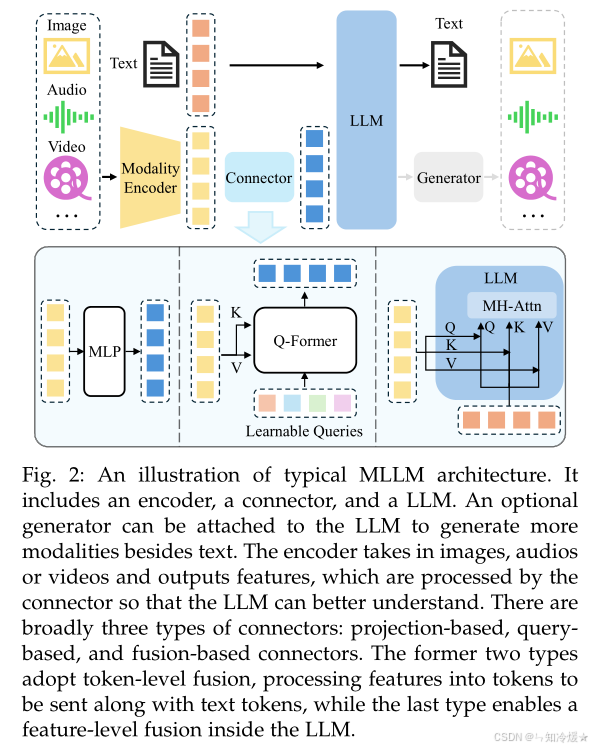
1、模态编码器(Modality Encoder)(眼睛/耳朵)
功能:将原始数据(如图像、音频、视屏等)转换为特征表示,使其能够与文本模态对其。(例如图像、音视频编码器)
常用模型:
-
图像:CLIP-ViT、EVA-CLIP(更高分辨率支持)、ConvNeXt(卷积架构)。
-
音频:CLAP、ImageBind(支持多模态统一编码)。
关键发现:输入分辨率对性能影响显著(如448x448比224x224更优)。即更高的分辨率可以获得更加显著的性能。
如图所示为常用的图像编码器:

2、大语言模型(LLM)(大脑)
功能: 作为MLLM的“大脑”,负责整合多模态信息,执行推理,生成文本输出。
-
选择:开源模型(LLaMA-2、Vicuna)或双语模型(Qwen)。
-
参数规模的影响:从13B→34B参数提升,中文零样本能力涌现(即使训练数据仅为英文)。
-
知识注入:领域适配,例如数据微调,或者工具调用,即通过指令微调教会LLM调用外部API。
如图所示为常用公开的大语言模型:

3、模态接口(Modality Interface):用于对齐不同的模态
可学习接口:
-
Token级融合:如BLIP-2的Q-Former,将视觉特征压缩为少量Token。
-
特征级融合:如CogVLM在LLM每层插入视觉专家模块。
**专家模型:**调用现成模型(如OCR工具)将图像转为文本,再输入LLM(灵活性差但无需训练)。
如图所示为典型多模态模型架构示意图:
4、模块协同工作示例(以LLaVA为例)
- 图像编码:CLIP-ViT将图像编码为视觉特征。
- 特征对齐:通过两层MLP将视觉特征投影到LLaMA的文本嵌入空间。
- 指令微调:联合训练视觉-文本特征,使LLaMA能理解“描述图像中第三只猫的颜色”。
- 推理生成:LLaMA基于对齐特征生成自然语言响应。
2-2、架构优化趋势
高分辨率支持:通过分块(Monkey)、双编码器(CogAgent)处理高分辨率图像。
稀疏化:混合专家(MoE)架构(如MoE-LLaVA)在保持计算成本的同时增加参数量。
三、训练策略与数据
3-1、 三阶段训练流程
1、预训练(Pretraining)
目标:将不同模态(如图像、音频)的特征映射到统一的语义空间,通过大规模数据吸收通用知识(如物体识别、基本推理)。
数据:大规模粗粒度图文对(如LAION-5B)或高质量细粒度数据(如GPT-4V生成的ShareGPT4V)。计算图文相似度,移除相似度太低的样本。
关键技巧:冻结编码器和LLM,仅训练接口(防止灾难性遗忘)。
如图所示为预训练所用的通用数据集:
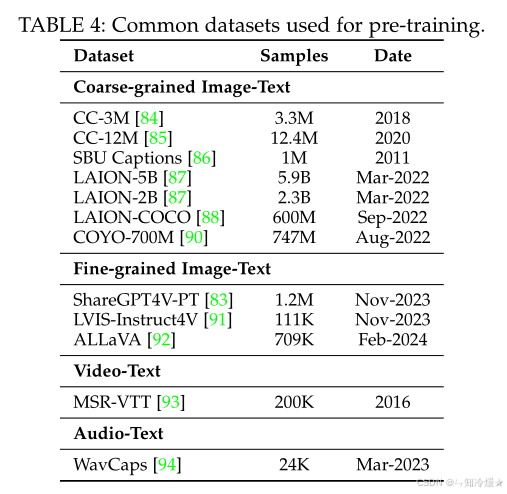
2、指令微调(Instruction Tuning)
目标:使模型能够理解和执行多样化的用户指令(如“描述图像中的情感”),指令调优学习如何泛化到不可见的任务。
数据构建方法:
- 任务适配:将VQA数据集转为指令格式(如“Question: <问题> Answer: <答案>”)。
- 自指令生成:用GPT-4生成多轮对话数据(如LLaVA-Instruct)。
发现:
- 指令多样性(设计不同句式(疑问句、命令句)和任务类型(描述、推理、创作))比数据量更重要。
- 数据质量比数量更重要。
- 包含推理步骤的指令,可以显著提升模型的性能。
如图所示描述任务的指令(相关范例):

3、对齐微调(Alignment Tuning)
目标:减少幻觉(确保生成内容与输入模态一致(如不虚构图中未出现的物体)),使输出更符合人类偏好。(简介、安全,符合伦理)
方法:
- RLHF:通过人类偏好数据训练奖励模型,再用PPO优化策略(如LLaVA-RLHF)。
- DPO:直接优化偏好对(无需显式奖励模型)。
如图所示为三种典型学习范式的比较:
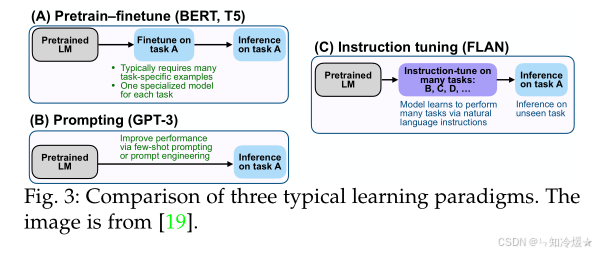
四、 评估方法
4-1、 闭集评估(Closed-set)
定义:在预定义任务和答案范围内测试模型性能,适用于标准化任务(如分类、问答)。
核心指标:
- 准确率(Accuracy):直接匹配模型输出与标准答案(如ScienceQA数据集)。
- CIDEr(Consensus-based Image Description Evaluation):衡量生成文本与参考描述的语义相似性(常用于图像描述任务)。
- BLEU-4:基于词重叠的机器翻译指标,适用于短文本生成(如VQA简短回答)。
4-2、开集评估(Open-set)
定义:评估模型在开放场景下的生成能力(如自由对话、创造性任务),答案不固定。
核心方法:
人工评分(Human Rating):
- 评分维度:相关性、事实性、连贯性、多样性、安全性。
- 流程:标注员按1-5分对模型输出打分(如LLaVA的对话能力评估)。
GPT-4评分(GPT-as-a-Judge):
- 方法:用GPT-4对模型输出评分(示例提示):
Instruction: 请根据相关性(1-5分)和准确性(1-5分)评价以下回答:
问题:<问题>
模型回答:<回答>
- 优点:低成本、可扩展;缺点:依赖GPT-4的偏见和文本理解能力。
4-3、多模态幻觉评估
定义:检测模型生成内容与输入模态不一致的问题(如虚构图中未出现的对象)。
评估方法:
POPE(Polling-based Object Probing Evaluation):
- 流程:生成多项选择题(如“图中是否有狗?”),统计模型回答的准确率。
- 指标:准确率、假阳性率(FP)。
CHAIR(Caption Hallucination Assessment with Image Relevance):
步骤:
- 提取生成描述中的所有名词(如“猫、桌子”)。
- 检测这些名词是否在图像中存在(通过目标检测模型)。
指标:幻觉率(错误名词占比)。
FaithScore:
方法:将生成文本拆分为原子事实(如“猫是黑色的”),用视觉模型验证每个事实是否成立。
指标:原子事实准确率。
4-4、 多模态综合能力评估
(1) 多维度基准测试
1、MME(Multimodal Evaluation Benchmark):
涵盖能力:感知(物体计数、颜色识别)、认知(推理、常识)。
任务示例:
- 感知任务:“图中红色物体的数量?”
- 认知任务:“如果移除支撑杆,积木会倒塌吗?为什么?”
指标:综合得分(感知分 + 认知分)。
2、MMBench:
特点:覆盖20+任务类型(如OCR、时序推理),使用ChatGPT将开放答案匹配到预定义选项。
指标:准确率(标准化为0-100分)。
五、扩展方向与技术
多模态大语言模型的扩展方向主要集中在提升功能多样性、支持更复杂场景、优化技术效率以及拓展垂直领域应用。以下是具体分类与技术细节
5-1、模态支持扩展
一、 输入模态扩展
1、3D点云(Point Cloud)
技术:将3D数据(如LiDAR扫描)编码为稀疏或密集特征。
案例:
- PointLLM:通过投影网络将点云特征对齐到LLM的文本空间,支持问答(如“房间中有多少把椅子?”)。
- 3D-LLM:结合视觉和3D编码器,实现跨模态推理(如分析物体空间关系)。
挑战:3D数据的高维稀疏性、计算开销大。
2、传感器融合(Sensor Fusion)
技术:整合多种传感器数据(如热成像、IMU惯性测量)。
案例:
- ImageBind-LLM:支持图像、音频、深度、热成像等多模态输入,通过统一编码器对齐特征。
应用:自动驾驶(融合摄像头、雷达、激光雷达数据)。
二、输出模态扩展
1、多模态生成:
技术:结合扩散模型(如Stable Diffusion)生成图像、音频或视频。
案例:
- NExT-GPT:输入文本生成图像+音频,或输入视频生成文本描述+配乐。
- Emu:通过视觉解码器生成高分辨率图像,支持多轮编辑(如“将图中的猫换成狗”)。
指标:生成质量(FID、CLIP Score)、跨模态一致性。
5-2、 交互粒度扩展
一、细粒度输入控制
1、区域指定(Region-specific):
技术:支持用户通过框选(Bounding Box)、点击(Point)指定图像区域。
案例:
- Ferret:接受点、框或草图输入,回答与指定区域相关的问题(如“这个红框内的物体是什么?”)。
- Shikra:输出回答时自动关联图像坐标(如“左侧的狗(坐标[20,50,100,200]在奔跑”)。
2、像素级理解(Pixel-level):
技术:结合分割模型(如Segment Anything)实现掩码级交互。
案例:
- LISA:通过文本指令生成物体掩码(如“分割出所有玻璃杯”)。
二、多轮动态交互
历史记忆增强:
技术:在对话中维护跨模态上下文缓存(如缓存前几轮的图像特征)。
案例:
- Video-ChatGPT:支持多轮视频问答(如“第三秒出现的车辆是什么品牌?”)。
5-3、语言与文化扩展
一、多语言支持
低资源语言适配:
技术:通过翻译增强(Translate-Train)或跨语言迁移学习。
案例:
- VisCPM:基于中英双语LLM,用英文多模态数据训练,通过少量中文数据微调实现中文支持。
挑战:缺乏非拉丁语系的图文对齐数据(如阿拉伯语、印地语)。
二、文化适应性
本地化内容生成:
技术:在指令数据中注入文化特定元素(如节日、习俗)。
案例:
- Qwen-VL:支持生成符合中文文化背景的描述(如“端午节龙舟赛”)。
5-4、 垂直领域扩展
一、医疗领域
技术:领域知识注入(如医学文献微调)、数据增强(合成病理图像)。
案例:
- LLaVA-Med:支持胸部X光诊断问答(如“是否存在肺炎迹象?”),准确率超放射科住院医师平均水平。
挑战:数据隐私、伦理审查。
二、自动驾驶
技术:多传感器融合、实时性优化(如模型轻量化)。
案例:
- DriveLLM:结合高精地图和摄像头数据,回答复杂驾驶场景问题(如“能否在此路口变道?”)。
三、工业检测
技术:高分辨率缺陷检测、小样本学习。
案例:
- Industrial-VLM:通过文字提示定位产品缺陷(如“检测电路板上的虚焊点”)。
5-5、效率优化扩展
一、轻量化部署
技术:
- 模型压缩:量化(INT8)、知识蒸馏(如TinyLLaVA)。
- 硬件适配:针对移动端(如NPU)优化计算图。
案例:
- MobileVLM:1.4B参数模型可在手机端实时运行,支持图像描述和简单问答。
二、混合专家(MoE)架构
技术:稀疏激活,仅调用部分专家模块处理输入。
案例:
- MoE-LLaVA:在视觉问答任务中,MoE架构比同参数规模模型准确率提升5%-10%。
5-6、 新兴技术融合
一、具身智能(Embodied AI)
技术:将MLLMs与机器人控制结合,实现“感知-推理-行动”闭环。
案例:
- PALM-E:通过视觉-语言模型控制机械臂完成复杂操作(如“把红色积木放在蓝色盒子旁边”)。
二、增强现实(AR)
技术:实时多模态交互(如语音+手势+视觉)。
案例:
- AR-LLM:在AR眼镜中叠加MLLM生成的实时导航提示(如“前方路口右转”)。
参考文章:
多模态模型综述文章
Github地址
注意: 原文内容较多,本文仅限部分内容笔记,建议直接阅读原文。
总结
好困,真的好困。🐑