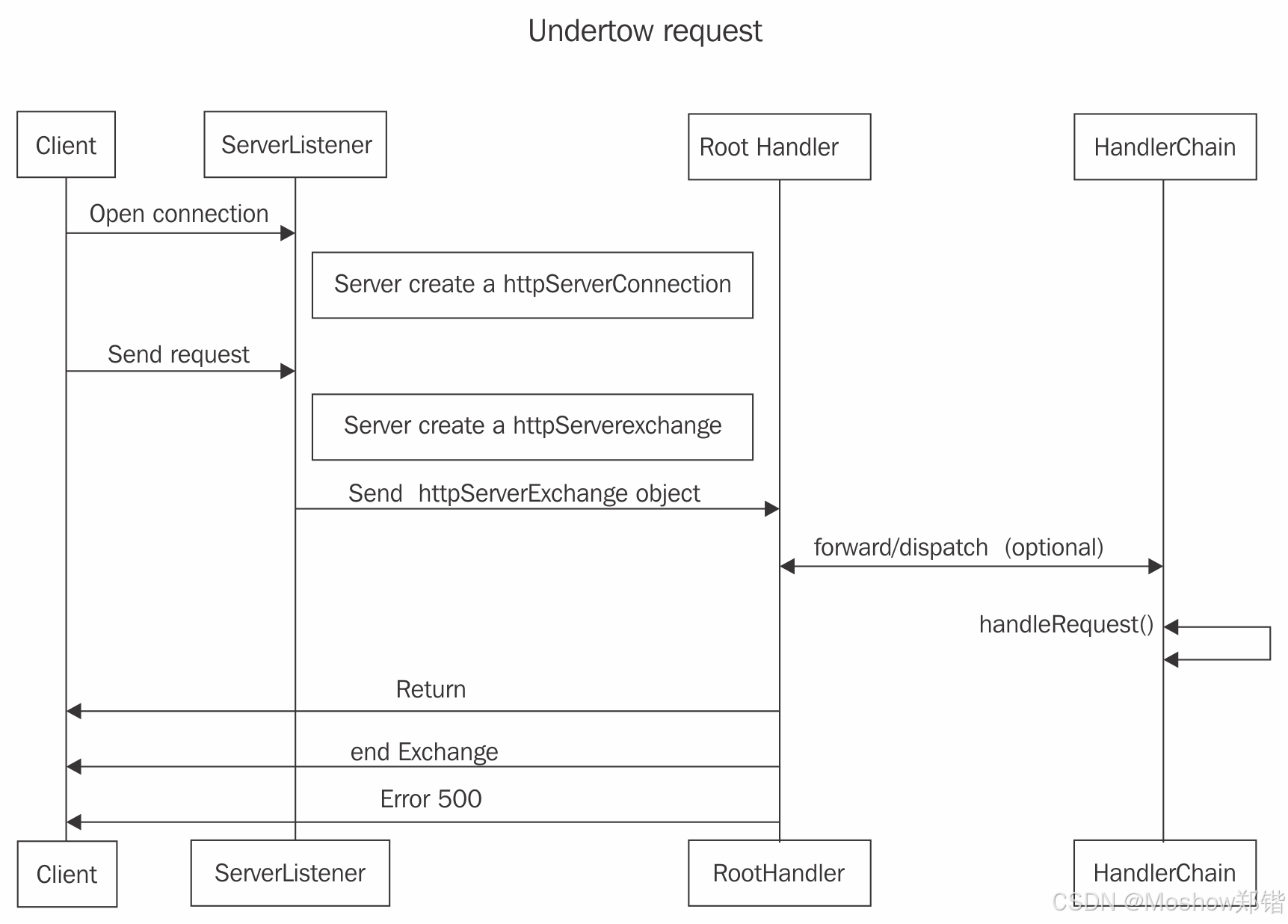
以下是 Hadoop 集群的核心配置步骤,基于之前的免密登录和文件同步基础,完成 Hadoop 分布式环境的搭建:
1. 集群规划
假设集群包含 3 个节点:
- master:NameNode、ResourceManager
- slave1:DataNode、NodeManager
- slave2:DataNode、NodeManager
2. 核心配置文件
在master 节点上编辑 Hadoop 配置文件(路径:/opt/hadoop/etc/hadoop):
2.1 core-site.xml
配置 HDFS 的默认文件系统和临时目录:
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/data/tmp</value>
</property>
</configuration>
2.2 hdfs-site.xml
配置 HDFS 的副本数和数据存储路径:
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 数据副本数,应小于等于DataNode数量 -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
2.3 mapred-site.xml
配置 MapReduce 运行在 YARN 上:
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
2.4 yarn-site.xml
配置 YARN 的资源调度器和 NodeManager:
xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
2.5 workers(原 slaves 文件)
指定 DataNode 和 NodeManager 所在的从节点:
plaintext
slave1
slave2
3. 同步配置到所有节点
使用之前的同步脚本将配置分发到所有节点:
bash
/opt/hadoop/bin/sync_hadoop.sh etc/hadoop/
4. 初始化 HDFS
在master 节点上执行:
bash
# 创建必要目录
mkdir -p /opt/hadoop/data/{tmp,namenode,datanode}
# 格式化NameNode(首次启动前执行)
hdfs namenode -format
5. 启动集群
在master 节点上执行:
bash
# 启动HDFS服务
start-dfs.sh
# 启动YARN服务
start-yarn.sh
# 查看进程状态
jps
预期看到的进程:
- master:NameNode、ResourceManager、SecondaryNameNode
- slave1/slave2:DataNode、NodeManager
6. 验证集群
6.1 Web 界面访问
- HDFS 管理界面:http://master:9870
- YARN 资源管理界面:http://master:8088
6.2 命令行测试
bash
# 创建测试目录
hdfs dfs -mkdir /test
# 上传文件
hdfs dfs -put /etc/hosts /test/
# 查看文件列表
hdfs dfs -ls /test
# 运行MapReduce示例
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar pi 10 100
7. 配置优化建议
内存分配优化
在yarn-site.xml中添加:
xml
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>8192</value> <!-- 每个NodeManager可用内存(MB) -->
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value> <!-- 单个容器最大内存(MB) -->
</property>
Java 堆内存优化
在hadoop-env.sh中添加:
bash
export HADOOP_NAMENODE_OPTS="-Xmx4g"
export HADOOP_DATANODE_OPTS="-Xmx2g"
8. 常见问题排查
- NameNode 启动失败:检查
/opt/hadoop/data/namenode目录权限 - DataNode 未注册:确保所有节点的
clusterID一致(查看data/namenode/current/VERSION) - YARN 任务无法运行:检查 NodeManager 日志,确认内存配置是否合理
完成以上配置后,你的 Hadoop 集群将具备分布式存储(HDFS)和计算(MapReduce/YARN)能力。
分享