GAN简介
GAN思想是一种二人的零和博弈思想,GAN中有两个博弈者,一个生成器(G),一个判别器(D),这两个模型都有各自的输入和输出。具体功能如下:
生成器(G):输入一个随机噪声样本,通过生成器生成一个与真实样本无差的样本。
判别器(D):对输出模型进行打分,类似一个分类器,打分的对照样本是真实样本。
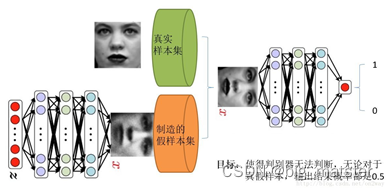
GAN的简易模型如下:
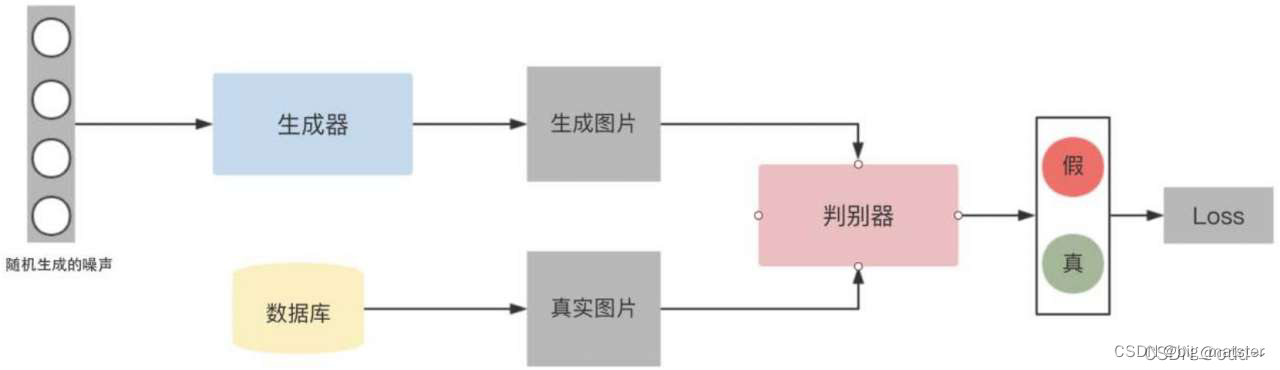
- GAN训练
- GAN训练一开始都是训练判别器的,目的是让判别器获得一个标准的,也就是说,让判别器看一堆好的图片,从而知道好图究竟是怎么样的,这些图片可以来自于各种地方,一般是将好的图片收集到数据库中,在从中抽取这些图片输入判别器。
- 训练完判别器后,判别器已经有标准了,此时再来训练生成器,生成器的训练流程也比较简单,随便生成一组噪声给生成器即可,如生成符合正太分布的噪声。生成器会通过这些噪声生成一张图片,当然一开始这张图片是惨不忍睹的,这种图片过不论判别器这关。
- 生成图片后,判别器就会判断这张图片是来自数据库的真实图片,还是来自于生成器的生成图片。如果判断是真实图片,就会给图片赋予一个较高的分数,如真实图片赋为1,如果判断是生成土图片,就赋予图片一个较低的分数,如生成图片赋予0,同时还会产生一个损失。
GAN的简要流程如下:
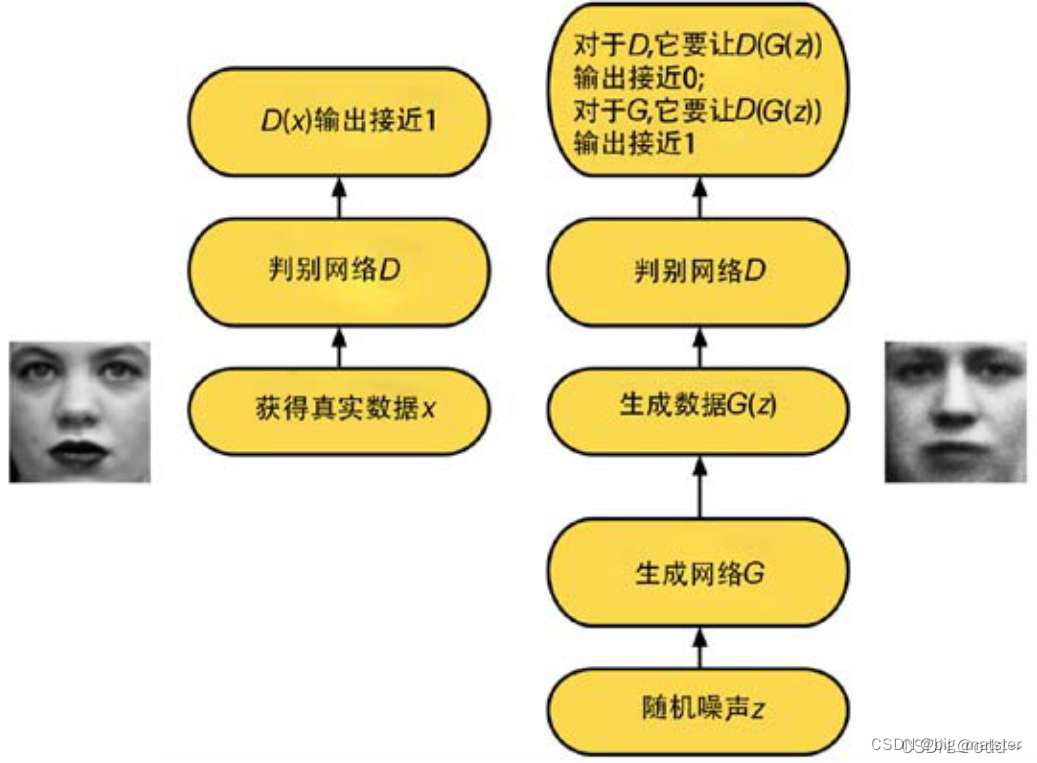
GAN公式如下:
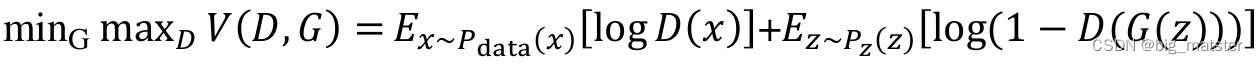
生成器的目标就是让判别器无法判断是生成图片还是真实图片,换种说法就是,生成器的目标都是生成真实图片,至少让判别器认为是真实的,生成器一开始生成图片过于模糊抽象,判别器可以轻易的将其识别,生成器为了提高自己生成图片的能力,就要不断的学习,具体而言,就是找到自己生成图片与真实图片的差距。然后弥补这个差距。这就是所谓的差距,其实就是损失,也就是在高维空间中生成图片的概率分布与真实图片的概率分布的不同之处,具体而言,就是两个概率图片的
J
S
散
度
JS散度
JS散度就是最小化生成图片的概率分布与真实图片的概率分布的
J
S
JS
JS散度。
- 生成器损失:判别器给生成图片赋予的分数和目标分数,的差距。
- 判别器损失:其损失由两部分构成,判别器给真实图片赋予的分数和目标分数的差距。判别器给生成图片和目标分数的差距。
计算损失时候使用 t f . n n . s i g m o i d c r o s s e n t r o p y w i t h l o g i t s tf.nn.sigmoid_cross_entropy_with_logits tf.nn.sigmoidcrossentropywithlogits的方法,其对传入 l o g i t s logits logits参数,先使用 S i g m o i d 函 数 计 算 Sigmoid函数计算 Sigmoid函数计算,然后再计算它们的 c r o s s e n t r o p y cross entropy crossentropy交叉熵损失,同时该方法优化了交叉熵的计算方式,使得结果不会溢出。
import tensorflow as tf
from tensorflow import keras
from matplotlib import pyplot as plt
from tensorflow.keras import layers
# mnist = tf.keras.datasets.mnist
# (x_train, y_train), (x_test, y_test) = mnist.load_data()
# # 可视化训练集输入特征的第一个元素
# plt.imshow(x_train[0], cmap='gray') # 绘制灰度图
# plt.show()
(train_images, train_labels), (_, _) = keras.datasets.mnist.load_data()
'''mnist中的reshape
x_image = tf.reshape(x, [-1, 28, 28, 1])
这里是将一组图像矩阵x重建为新的矩阵,该新矩阵的维数为(a,28,28,1),其中-1表示a由实际情况来定'''
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images-127.5)/127.5 # -1~1
BATCH_SIZE = 256
BUFFER_SIZE = 60000
datasets = tf.data.Dataset.from_tensor_slices(train_images)
datasets = datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
# 生成器
def generator_model(): # 用100个随机数(噪音)生成手写数据集
model = keras.Sequential()
model.add(layers.Dense(256, input_shape=(100,), use_bias=False))
model.add(layers.BatchNormalization()) # 规范化
model.add(layers.LeakyReLU())
model.add(layers.Dense(512, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(28 * 28 * 1, use_bias=False, activation='tanh'))
model.add(layers.BatchNormalization())
model.add(layers.Reshape((28, 28, 1)))
return model
# 判别器
def discriminator_model(): # 识别输入的图片
model = keras.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(512, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(256, use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Dense(1))
return model
cross_entropy = keras.losses.BinaryCrossentropy(from_logits=True)
# 判别器损失
def discriminator_loss(real_out, fake_out):
real_loss = cross_entropy(tf.ones_like(real_out), real_out)
fake_loss = cross_entropy(tf.zeros_like(fake_out), fake_out)
return real_loss + fake_loss
# 生成器损失
def generator_loss(fake_out):
return cross_entropy(tf.ones_like(fake_out), fake_out)
generator_opt = keras.optimizers.Adam(1e-4)
discriminator_opt = keras.optimizers.Adam(1e-4)
generator = generator_model()
discriminator = discriminator_model()
noise_dim = 100 # 即用100个随机数生成图片
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
real_out = discriminator(images, training=True)
gen_image = generator(noise, training=True)
fake_out = discriminator(gen_image, training=True)
gen_loss = generator_loss(fake_out)
disc_loss = discriminator_loss(real_out, fake_out)
gradient_gen = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradient_disc = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_opt.apply_gradients(zip(gradient_gen, generator.trainable_variables))
discriminator_opt.apply_gradients(zip(gradient_disc, discriminator.trainable_variables))
def generate_plot_image(gen_model, test_noise):
pre_images = gen_model(test_noise, training=False)
plt.figure(figsize=(4, 4))
for i in range(pre_images.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow((pre_images[i, :, :, 0] + 1)/2, cmap='gray')
plt.axis('off')
plt.show()
EPOCHS = 100 # 训练100次
num_exp_to_generate = 16 # 生成16张图片
seed = tf.random.normal([num_exp_to_generate, noise_dim]) # 16组随机数组,每组含100个随机数,用来生成16张图片。
def train(dataset, epochs):
for epoch in range(epochs):
for image_batch in dataset:
train_step(image_batch)
print('.', end='')
if epoch % 10 == 0:
print('epoch: ', epoch)
generate_plot_image(generator, seed)
train(datasets, EPOCHS)