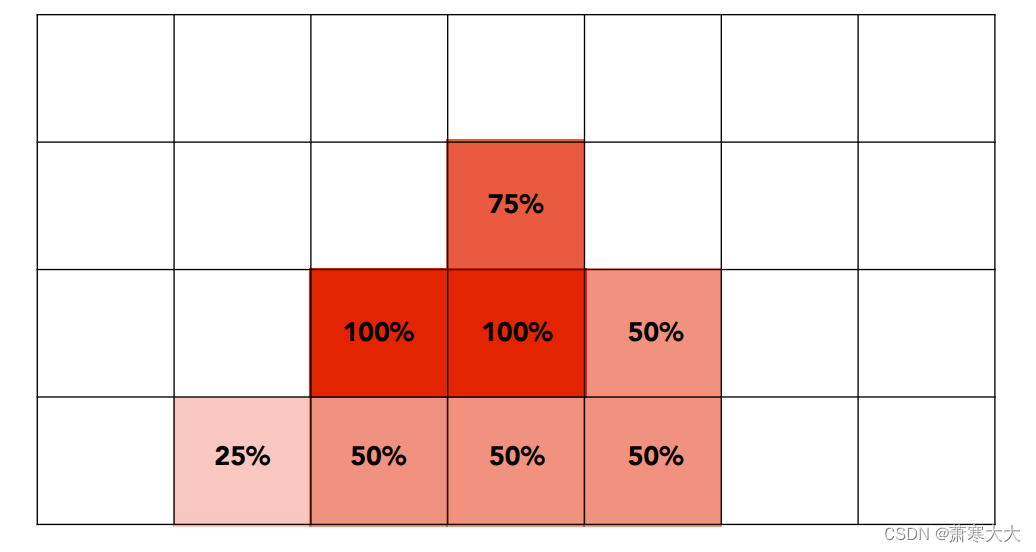
3.3 广告投放的地域分布
按照产品需求,需要完成如下统计的报表:
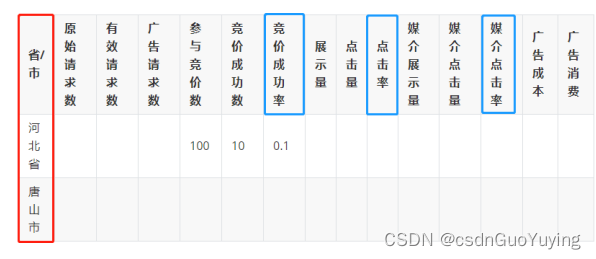
从上面的统计报表可以看出,其中包含三个“率”计算,说明如下:

报表字段信息
针对广告投放的地域分布统计,各个指标字段信息说明如下:
| Column(列名称) | Type(列类型) | Comment(列含义) |
|---|---|---|
| province | string NOT NULL | 省 |
| city | string NOT NULL | 市 |
| orginal_req_cnt | long NOT NULL | 原始请求数 |
| valid_req_cnt | long NOT NULL | 有效请求数 |
| ad_req_cnt | long NOT NULL | 广告请求数 |
| join_rtx_cnt | long NOT NULL | 参与竞价数 |
| success_rtx_cnt | long NOT NULL | 竞价成功数 |
| ad_show_cnt | long NOT NULL | 广告展示数量 |
| ad_click_cnt | long NOT NULL | 广告点击量 |
| media_show_cnt | long NOT NULL | 媒介展示量 |
| media_click_cnt | long NOT NULL | 媒介点击量 |
| dsp_pay_money | long NOT NULL | 广告成本 |
| dsp_cost_money | long NOT NULL | 广告消费 |
| success_rtx_rate | double NOT NULL | 竞价成功率 |
| ad_click_rate double | NOT NULL | 广告点击率 |
| media_click_rate double | NOT NULL | 媒体点击率 |
数据库创建表
在MySQL数据库【itcast_ads_report】中创建表【ads_region_analysis】,以便将结果数据保存,创建语句如下:
-- 创建表
-- DROP TABLE IF EXISTS itcast_ads_report.ads_region_analysis ;
CREATE TABLE `itcast_ads_report`.`ads_region_analysis` (
`report_date` varchar(255) NOT NULL,
`province` varchar(255) NOT NULL,
`city` varchar(255) NOT NULL,
`orginal_req_cnt` bigint DEFAULT NULL,
`valid_req_cnt` bigint DEFAULT NULL,
`ad_req_cnt` bigint DEFAULT NULL,
`join_rtx_cnt` bigint DEFAULT NULL,
`success_rtx_cnt` bigint DEFAULT NULL,
`ad_show_cnt` bigint DEFAULT NULL,
`ad_click_cnt` bigint DEFAULT NULL,
`media_show_cnt` bigint DEFAULT NULL,
`media_click_cnt` bigint DEFAULT NULL,
`dsp_pay_money` bigint DEFAULT NULL,
`dsp_cost_money` bigint DEFAULT NULL,
`success_rtx_rate` double DEFAULT NULL,
`ad_click_rate` double DEFAULT NULL,
`media_click_rate` double DEFAULT NULL,
PRIMARY KEY (`report_date`,`province`,`city`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ;
广告数据表相关字段
针对广告投放的地域分布统计需求,涉及到【广告数据表pmt_ads_info】相关字段:
| 字段 | 解释 |
|---|---|
| requestmode | 数据请求方式, 一般请求可能有三种, 如下 1 : 请求 2 : 展示 3 : 点击 |
| processnode | 流程节点, 1 : 请求量KPI, 只计算请求量 2 : 有效请求, 是一个有效的请求, 有效的请求可能也有一部分系统管理的请求 3 : 广告请求, 是一个和广告有关的请求 |
| adplatformproviderid | 广告平台商ID, >= 100000 : AdExchange、 < 100000 : AdNetwork |
| iseffective | 是否可以正常计费 |
| isbilling | 是否收费 |
| isbid | 是否是 RTB |
| adorderid | 广告 ID |
| adcreativeid | 广告创意 ID, >= 200000 : DSP、 < 200000 : OSS |
| winprice | RTB 竞价成功价格 |
| adpayment | 转换后的广告消费 (保留小数点后 6 位) |
将各个指标与业务字段关联,编写SQL或DSL实现统计分析。
指标逻辑
完成广告投放地域分区报表,需要如下的指标逻辑:
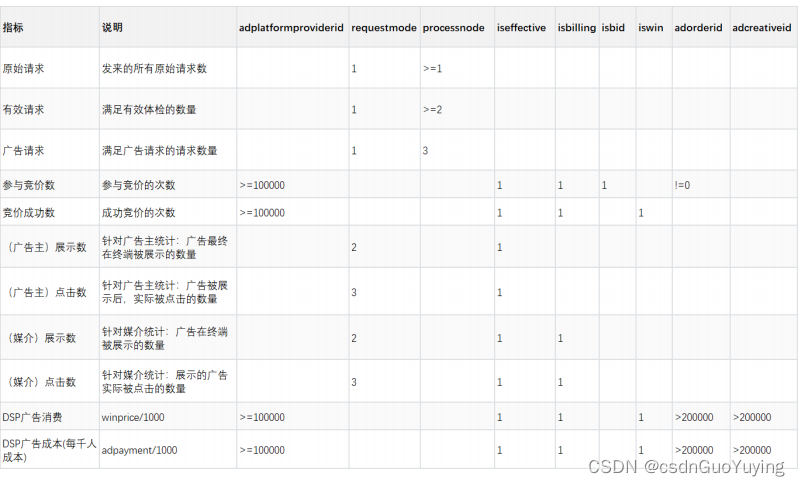
其中说明几点说明:

各个指标对于统计方式(使用类SQL表示)如下所示:
| 指标 | 说明 | 统计方式 |
|---|---|---|
| 原始请求 | 收到所有原始请求数量 | requestmode = 1 and processnode >= 1 |
| 有效请求 | 有效请求的数量 | requestmode = 1 and processnode >= 2 |
| 广告请求 | 广告请求的数量 | requestmode = 1 and processnode = 3 |
| 参与竞价数 | 参与竞价的数量 | adplatformproviderid >= 100000 and iseffective = 1 and isbilling = 1 and isbid = 1 and adorderid != 0 |
| 竞价成功数 | 成功竞价的数量 | adplatformproviderid >= 100000 and iseffective = 1 and isbilling = 1 and iswin = 1 and adorderid != 0 |
| 广告主展示数 | 广告主的广告请求被展示的数量 | requestmode = 2 and iseffective = 1 |
| 广告主点击数 | 广告主的广告请求被点击的数量 | requestmode = 3 and iseffective = 1 and adorderid != 0 |
| 媒介展示数 | 媒介:广告在终端被展示的数量 | requestmode = 2 and iseffective = 1 and isbilling=1 and isbid = 1 and iswin = 1 |
| 媒介点击数 | 媒介:广告在终端被点击的数量 | requestmode = 3 and iseffective = 1 and isbilling=1 and isbid = 1 and iswin = 1 |
| DSP 广告消费 | winprice/1000 | adplatformproviderid >= 100000 and iseffective = 1 and isbilling=1 and iswin = 1 and adorderid > 200000 and adcreativeid > 200000 |
| DSP广告成本 | adpayment/1000 | adplatformproviderid >= 100000 and iseffective = 1 and isbilling=1 and isbid = 1 and iswin = 1 and adorderid > 200000 and adcreativeid > 200000 |
可以看出各个指标计算,主要就是条件判断(使用CASE函数),再使用count/sum聚合函数即可。
报表分析
创建类【AdsRegionAnalysisReport.scala】,定义【report】方法,传递参数DataFrame,实现思路分为两步:
/*
不同业务报表统计分析时,两步骤:
i. 编写SQL或者DSL分析
ii. 将分析结果保存MySQL数据库表中
*/
整体代码框架如下,具体报表分析封装到方法中和保存结果封装到【saveResultToMySQL】方法,为了方便简洁直接使用DataFrame中format(“jdbc”):
package cn.itcast.spark.report
import cn.itcast.spark.config.ApplicationConfig
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
import org.apache.spark.sql.types.StringType
/**
* 广告区域统计:ads_region_analysis,区域维度:省份和城市
*/
object AdsRegionAnalysisReport {
/*
不同业务报表统计分析时,两步骤:
i. 编写SQL或者DSL分析
ii. 将分析结果保存MySQL数据库表中
*/
def doReport(dataframe: DataFrame) = {
// 第一、计算报表
//val resultDF: DataFrame = reportWithSql(dataframe) // sql 编程
//val resultDF: DataFrame = reportWithKpiSql(dataframe) // sql编程
//val resultDF: DataFrame = reportWithDsl(dataframe) // dsl 编程
// 第二、保存数据
//resultDF.show(20 ,truncate = false)
saveResultToMySQL(resultDF)
}
/**
* 保存数据至MySQL表中,直接使用DataFrame Writer操作,但是不符合实际应用需求
*/
def saveResultToMySQL(dataframe: DataFrame): Unit = {
dataframe
.coalesce(1)
.write
.mode(SaveMode.Append)
.format("jdbc")
// 设置MySQL数据库相关属性
.option("driver", ApplicationConfig.MYSQL_JDBC_DRIVER)
.option("url", ApplicationConfig.MYSQL_JDBC_URL)
.option("user", ApplicationConfig.MYSQL_JDBC_USERNAME)
.option("password", ApplicationConfig.MYSQL_JDBC_PASSWORD)
.option("dbtable", "itcast_ads_report.ads_region_analysis")
.save()
}
}
基于SQL分析
先依据需求编写SQL,三率指标(竞价成功率、广告点击率、媒体点击率)依赖于其他指标计算,所以使用SQL子查询方式,将SQL封装到特质:ReportSQLConstant中。
package cn.itcast.spark.report
/**
* 统计报表的SQL语句
*/
object ReportSQLConstant {
/**
* 广告投放的地域分布的SQL语句
* @param tempViewName DataFrame注册的临时视图名称
*/
def reportAdsRegionSQL(tempViewName: String): String = {
// 在Scala语言中,字符串可以使用双引号和三引号
s"""
|SELECT
| cast(date_sub(current_date(), 1) AS string) AS report_date,
| t.province, t.city,
| SUM(
| CASE
| WHEN (t.requestmode = 1 and t. processnode >= 1)
| THEN 1
| ELSE 0
| END
| ) AS orginal_req_cnt,
| SUM(
| CASE
| WHEN (t.requestmode = 1 and t.processnode >= 2)
| THEN 1
| ELSE 0
| END
| ) AS valid_req_cnt,
| SUM(
| CASE
| WHEN (t.requestmode = 1 and t.processnode = 3)
| THEN 1
| ELSE 0
| END
| ) AS ad_req_cnt,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.isbid = 1
| AND t.adorderid != 0) THEN 1
| ELSE 0
| END) AS join_rtx_cnt,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.iswin = 1) THEN 1
| ELSE 0
| END) AS success_rtx_cnt,
| SUM(CASE
| WHEN (t.requestmode = 2
| AND t.iseffective = 1) THEN 1
| ELSE 0
| END) AS ad_show_cnt,
| SUM(CASE
| WHEN (t.requestmode = 3
| AND t.iseffective = 1) THEN 1
| ELSE 0
| END) AS ad_click_cnt,
| SUM(CASE
| WHEN (t.requestmode = 2
| AND t.iseffective = 1
| AND t.isbilling = 1) THEN 1
| ELSE 0
| END) AS media_show_cnt,
| SUM(CASE
| WHEN (t.requestmode = 3
| AND t.iseffective = 1
| AND t.isbilling = 1) THEN 1
| ELSE 0
| END) AS media_click_cnt,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.iswin = 1
| AND t.adorderid > 200000
| AND t.adcreativeid > 200000) THEN floor(t.winprice / 1000)
| ELSE 0
| END) AS dsp_pay_money,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.iswin = 1
| AND t.adorderid > 200000
| AND t.adcreativeid > 200000) THEN floor(t.adpayment / 1000)
| ELSE 0
| END) AS dsp_cost_money
|FROM
| $tempViewName t
|GROUP BY
| t.province, t.city
|""".stripMargin
}
/**
* 统计竞价成功率、广告点击率、媒体点击率的SQL
*/
def reportAdsRegionRateSQL(tempViewName: String): String = {
s"""
|SELECT
| t.*,
| round(t.success_rtx_cnt / t.join_rtx_cnt, 2) AS success_rtx_rate,
| round(t.ad_click_cnt / t.ad_show_cnt, 2) AS ad_click_rate,
| round(t.media_click_cnt / t.media_show_cnt, 2) AS media_click_rate
|FROM
| $tempViewName t
|WHERE
| t.join_rtx_cnt != 0 AND t.success_rtx_cnt != 0
| AND t.ad_show_cnt != 0 AND t.ad_click_cnt != 0
| AND t.media_show_cnt != 0 AND t.media_click_cnt != 0
|""".stripMargin
}
}
在【AdsRegionAnalysisReport】类中,定义【reportWithSql】方法,使用SQL分析:
/**
* 使用SQL方式计算广告投放报表
*/
def reportWithSql(dataframe: DataFrame): DataFrame = {
// 从DataFrame中获取SparkSession对象
val spark: SparkSession = dataframe.sparkSession
/*
在SparkSQL中使用SQL分析数据时,步骤分为两步:
- 第一步、将DataFrame注册为临时视图
- 第二步、编写SQL语句,使用SparkSession执行
*/
// i. 注册广告数据集为临时视图:tmp_view_pmt
dataframe.createOrReplaceTempView("tmp_view_pmt")
// ii. 编写SQL并执行获取结果
val reportDF: DataFrame = spark.sql(
ReportSQLConstant.reportAdsRegionSQL("tmp_view_pmt")
)
//reportDF.printSchema()
//reportDF.show(20, truncate = false)
// iii. 为了计算“三率”首先注册DataFrame为临时视图
reportDF.createOrReplaceTempView("tmp_view_report")
// iv. 编写SQL并执行获取结果
val resultDF: DataFrame = spark.sql(
ReportSQLConstant.reportAdsRegionRateSQL("tmp_view_report")
)
//resultDF.printSchema()
//resultDF.show(20, truncate = false)
// iii. 返回结果
resultDF
}
运行PmtReportRunner类,保存至MySQL数据库表中:
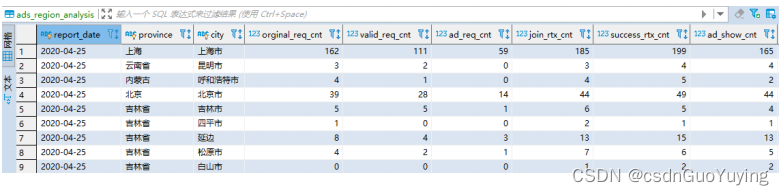
上述SQL使用子查询方式,需要两次注册DataFrame为临时视图,编写SQL语句,可以使用With As语句优化。
优化SQL:With As 语句
当书写一些结构相对复杂的SQL语句时,可能某个子查询在多个层级多个地方存在重复使用的情况,可以使用 WITH AS 语句将其独立出来,极大提高SQL可读性,简化SQL,语法如下:
WITH t1 AS (
SELECT *
FROM carinfo
),
t2 AS (
SELECT *
FROM car_blacklist
)
SELECT *
FROM t1, t2 ;
WITH AS 也叫做子查询部分,首先定义一个SQL片段,该SQL片段会被整个SQL语句所用到。WITH AS 就类似于一个视图或临时表,属于一次性的,而且必须要和其他sql一起使用才可以。其最大的好处就是适当的提高代码可读性,而且如果with子句在后面要多次使用到,可以大大的简化SQL;更重要的是:一次分析,多次使用,这也是为什么会提供性能的地方,达到了“少读”的目标。
在【ReportSQLConstant】中添加【reportAdsRegionKpiSQL】方法,使用WITH AS实现SQL:
/**
* 使用WITH AS 子查询语句分析
* @param tempViewName 视图名称
* @return
*/
def reportAdsRegionKpiSQL(tempViewName: String): String = {
s"""
|WITH tmp AS (
| SELECT
| cast(date_sub(current_date(), 1) AS string) AS report_date,
| t.province, t.city,
| SUM(
| CASE
| WHEN (t.requestmode = 1 and t. processnode >= 1)
| THEN 1
| ELSE 0
| END
| ) AS orginal_req_cnt,
| SUM(
| CASE
| WHEN (t.requestmode = 1 and t.processnode >= 2)
| THEN 1
| ELSE 0
| END
| ) AS valid_req_cnt,
| SUM(
| CASE
| WHEN (t.requestmode = 1 and t.processnode = 3)
| THEN 1
| ELSE 0
| END
| ) AS ad_req_cnt,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.isbid = 1
| AND t.adorderid != 0) THEN 1
| ELSE 0
| END) AS join_rtx_cnt,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.iswin = 1) THEN 1
| ELSE 0
| END) AS success_rtx_cnt,
| SUM(CASE
| WHEN (t.requestmode = 2
| AND t.iseffective = 1) THEN 1
| ELSE 0
| END) AS ad_show_cnt,
| SUM(CASE
| WHEN (t.requestmode = 3
| AND t.iseffective = 1) THEN 1
| ELSE 0
| END) AS ad_click_cnt,
| SUM(CASE
| WHEN (t.requestmode = 2
| AND t.iseffective = 1
| AND t.isbilling = 1) THEN 1
| ELSE 0
| END) AS media_show_cnt,
| SUM(CASE
| WHEN (t.requestmode = 3
| AND t.iseffective = 1
| AND t.isbilling = 1) THEN 1
| ELSE 0
| END) AS media_click_cnt,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.iswin = 1
| AND t.adorderid > 200000
| AND t.adcreativeid > 200000) THEN floor(t.winprice / 1000)
| ELSE 0
| END) AS dsp_pay_money,
| SUM(CASE
| WHEN (t.adplatformproviderid >= 100000
| AND t.iseffective = 1
| AND t.isbilling = 1
| AND t.iswin = 1
| AND t.adorderid > 200000
| AND t.adcreativeid > 200000) THEN floor(t.adpayment / 1000)
| ELSE 0
| END) AS dsp_cost_money
| FROM
| $tempViewName t
| GROUP BY
| t.province, t.city
|)
|SELECT
| tt.*,
| round(tt.success_rtx_cnt / tt.join_rtx_cnt, 2) AS success_rtx_rate,
| round(tt.ad_click_cnt / tt.ad_show_cnt, 2) AS ad_click_rate,
| round(tt.media_click_cnt / tt.media_show_cnt, 2) AS media_click_rate
|FROM
| tmp tt
|WHERE
| tt.join_rtx_cnt != 0 AND tt.success_rtx_cnt != 0
| AND tt.ad_show_cnt != 0 AND tt.ad_click_cnt != 0
| AND tt.media_show_cnt != 0 AND tt.media_click_cnt != 0
|""".stripMargin
}
再在【AdsRegionAnalysisReport】类中,定义【reportWithKpiSql】方法,使用SQL分析:
/**
* 使用SQL方式计算广告投放报表
*/
def reportWithKpiSql(dataframe: DataFrame): DataFrame = {
// 从DataFrame中获取SparkSession对象
val spark: SparkSession = dataframe.sparkSession
/*
在SparkSQL中使用SQL分析数据时,步骤分为两步:
- 第一步、将DataFrame注册为临时视图
- 第二步、编写SQL语句,使用SparkSession执行
*/
// i. 注册广告数据集为临时视图:tmp_view_pmt
dataframe.createOrReplaceTempView("tmp_view_pmt")
// ii. 编写SQL并执行获取结果
val kpiSql: String = ReportSQLConstant.reportAdsRegionKpiSQL("tmp_view_pmt")
//println(kpiSql)
val reportDF: DataFrame = spark.sql(kpiSql)
//reportDF.show(20, truncate = false)
// iii. 返回结果
reportDF
}
基于DSL分析
使用DataFrame API和函数实现上述SQL语句功能,在【AdsRegionAnalysisReport】类中,定义【reportWithDsl】方法,代码如下:
/**
* 使用DSL方式计算广告投放报表
*/
def reportWithDsl(dataframe: DataFrame): DataFrame = {
// i. 导入隐式转换及函数库
import dataframe.sparkSession.implicits._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.StringType
// ii. 报表开发
val reportDF: DataFrame = dataframe
// 第一步、按照维度分组:省份和城市
.groupBy($"province", $"city")
// 第二步、使用agg进行聚合操作, 主要使用CASE...wHEN...函数和SUM函数
.agg(
// 原始请求:requestmode = 1 and processnode >= 1
sum(
when($"requestmode".equalTo(1)
.and($"processnode".geq(1)), 1
).otherwise(0)
).as("orginal_req_cnt"),
// 有效请求:requestmode = 1 and processnode >= 2
sum(
when($"requestmode".equalTo(1)
.and($"processnode".geq(2)), 1
).otherwise(0)
).as("valid_req_cnt"),
// 广告请求:requestmode = 1 and processnode = 3
sum(
when($"requestmode".equalTo(1)
.and($"processnode".equalTo(3)), 1
).otherwise(0)
).as("ad_req_cnt"),
// 参与竞价数
sum(
when($"adplatformproviderid".geq(100000)
.and($"iseffective".equalTo(1))
.and($"isbilling".equalTo(1))
.and($"isbid".equalTo(1))
.and($"adorderid".notEqual(0)), 1
).otherwise(0)
).as("join_rtx_cnt"),
// 竞价成功数
sum(
when($"adplatformproviderid".geq(100000)
.and($"iseffective".equalTo(1))
.and($"isbilling".equalTo(1))
.and($"iswin".equalTo(1))
.and($"adorderid".notEqual(0)), 1
).otherwise(0)
).as("success_rtx_cnt"),
// 广告主展示数: requestmode = 2 and iseffective = 1
sum(
when($"requestmode".equalTo(2)
.and($"iseffective".equalTo(1)), 1
).otherwise(0)
).as("ad_show_cnt"),
// 广告主点击数: requestmode = 3 and iseffective = 1 and adorderid != 0
sum(
when($"requestmode".equalTo(3)
.and($"iseffective".equalTo(1))
.and($"adorderid".notEqual(0)), 1
).otherwise(0)
).as("ad_click_cnt"),
// 媒介展示数
sum(
when($"requestmode".equalTo(2)
.and($"iseffective".equalTo(1))
.and($"isbilling".equalTo(1))
.and($"isbid".equalTo(1))
.and($"iswin".equalTo(1)), 1
).otherwise(0)
).as("media_show_cnt"),
// 媒介点击数
sum(
when($"requestmode".equalTo(3)
.and($"iseffective".equalTo(1))
.and($"isbilling".equalTo(1))
.and($"isbid".equalTo(1))
.and($"iswin".equalTo(1)), 1
).otherwise(0)
).as("media_click_cnt"),
// DSP 广告消费
sum(
when($"adplatformproviderid".geq(100000)
.and($"iseffective".equalTo(1))
.and($"isbilling".equalTo(1))
.and($"iswin".equalTo(1))
.and($"adorderid".gt(200000))
.and($"adcreativeid".gt(200000)), floor($"winprice" / 1000)
) otherwise (0)
).as("dsp_pay_money"),
// DSP广告成本
sum(
when($"adplatformproviderid".geq(100000)
.and($"iseffective".equalTo(1))
.and($"isbilling".equalTo(1))
.and($"isbid".equalTo(1))
.and($"iswin".equalTo(1))
.and($"adorderid".gt(200000))
.and($"adcreativeid".gt(200000)), floor($"adpayment" / 1000)
) otherwise (0)
).as("dsp_cost_money")
)
// 第三步、过滤非0数据
.filter(
$"join_rtx_cnt".notEqual(0)
.and($"success_rtx_cnt".notEqual(0))
.and($"ad_show_cnt".notEqual(0))
.and($"ad_click_cnt".notEqual(0))
.and($"media_show_cnt".notEqual(0))
.and($"media_click_cnt".notEqual(0))
)
// 第四步、计算“三率”, 增加三列数据
.withColumn(
"success_rtx_rate", //
round($"success_rtx_cnt" / $"join_rtx_cnt", 2) // 保留两位有效数字
)
.withColumn(
"ad_click_rate", //
round($"ad_click_cnt" / $"ad_show_cnt", 2) // 保留两位有效数字
)
.withColumn(
"media_click_rate", //
round($"media_click_cnt" / $"media_show_cnt", 2) // 保留两位有效数字
)
// 第五步、增加报表的日期
.withColumn(
"report_date", // 报表日期字段
date_sub(current_date(), 1).cast(StringType)
)
//reportDF.printSchema()
//reportDF.show(20, truncate = false)
// iii. 返回结果数据
reportDF
}
主要使用groupBy、agg、filter和withColumn API实现报表分析,与前面SQL分析性能完全一致,原因在于SparkSQL中Catalyst引擎,无论是SQL还是DSL,最终生成物理计划都是一样的。
3.4 广告投放其他维度分布统计
广告投放统计,还可以依据【APP、设备、网络类型、网络运营及渠道】进行分组统计分析,获取报表数据,存储到MySQL表中。各个不同维度分组聚合统计,与前面的地域维度分组聚合统计的指标一致,仅仅是分组维度不一样而已,所以修改各个分组字段即可,具体说明如下:
1、APP维度:广告投放的APP分布
- App应用ID:app_id、App应用名称:app_name
2、设备维度:广告投放的设备分布
- 手机设备类型:client(1 android, 2 ios, 3 wp, 4 others)
- 手机设备型号:device (手机的品牌)
3、网络类型维度:广告投放的网络类型分布
- 网络类型ID:networkmannerid、网络类型名称:networkmannername
- 0:WIFI、1:4G、2:3G、3:2G、4:OPERATOROTHER
4、网络运营商维度:广告投放的网络运营商分布
- 网络运营商ID和名称:ispid, ispname
5、渠道维度:广告投放的渠道分布
- 渠道ID:channelid