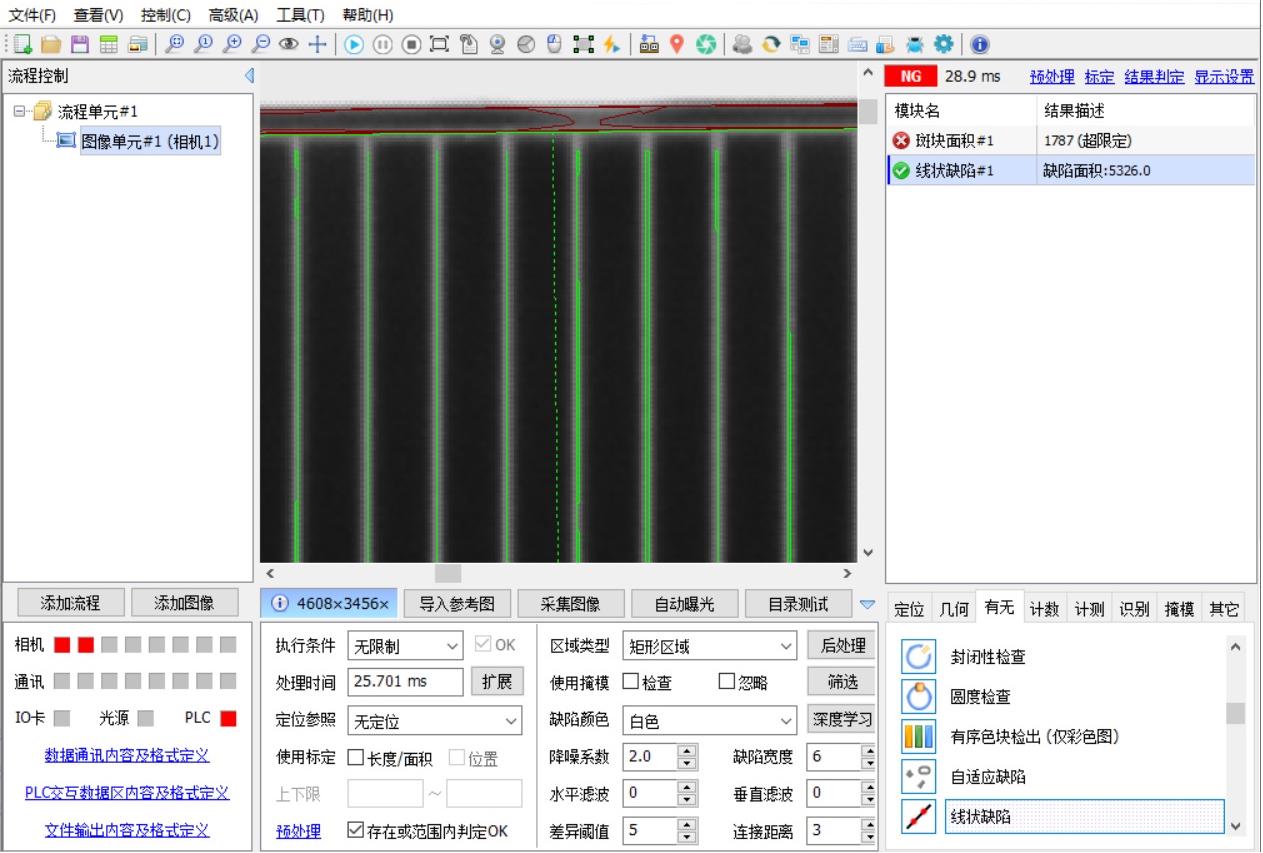
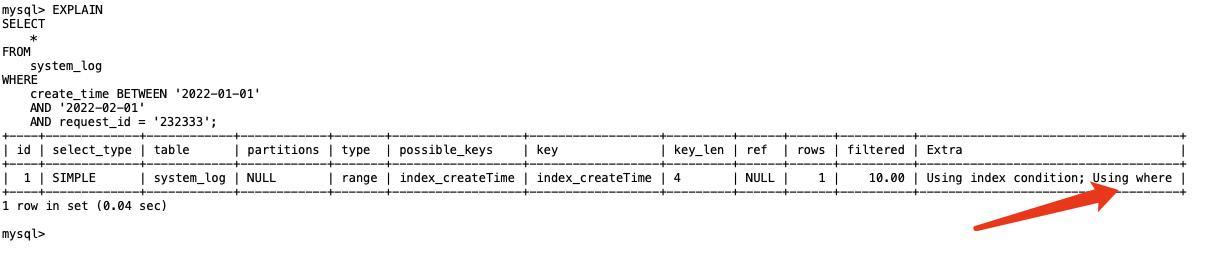
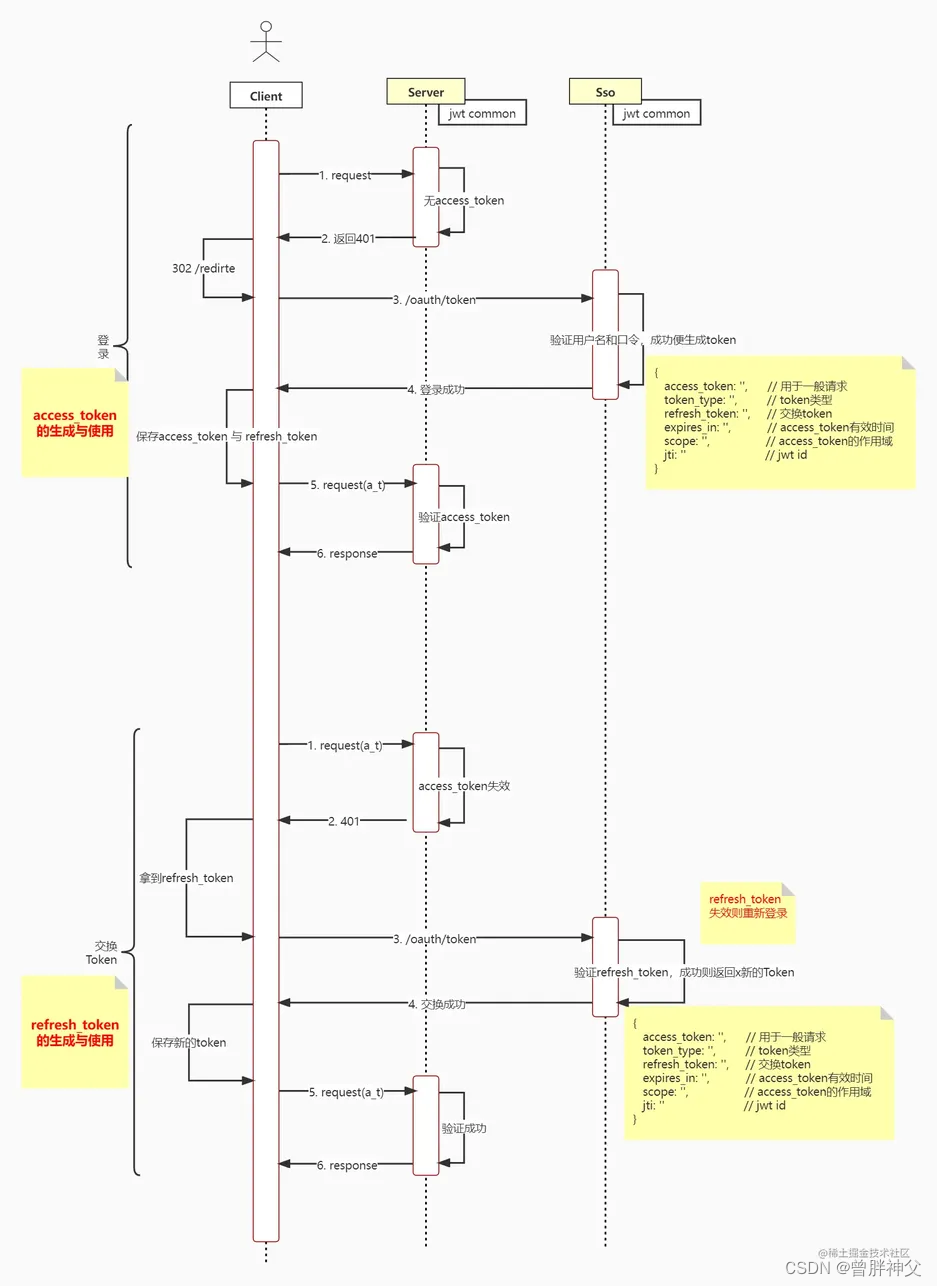
0x1. OneFlow/FasterTransformer SoftMax CUDA Kernel 实现学习
这篇文章主要学习了oneflow的softmax kernel实现以及Faster Transformer softmax kernel的实现,并以个人的角度分别解析了原理和代码实现,最后对性能做一个对比方便大家直观的感受到oneflow softmax kernel相比于FasterTransformer的优越性。我目前处于尽可能去理解oneflow的一些优秀的cuda实现的阶段,做一些知识储备,同时也调研和学习下相关的一些优化库的的cuda kernel。欢迎大家关注这个仓库 https://github.com/BBuf/how-to-optim-algorithm-in-cuda 一起交流学习。性能测试结果如下:
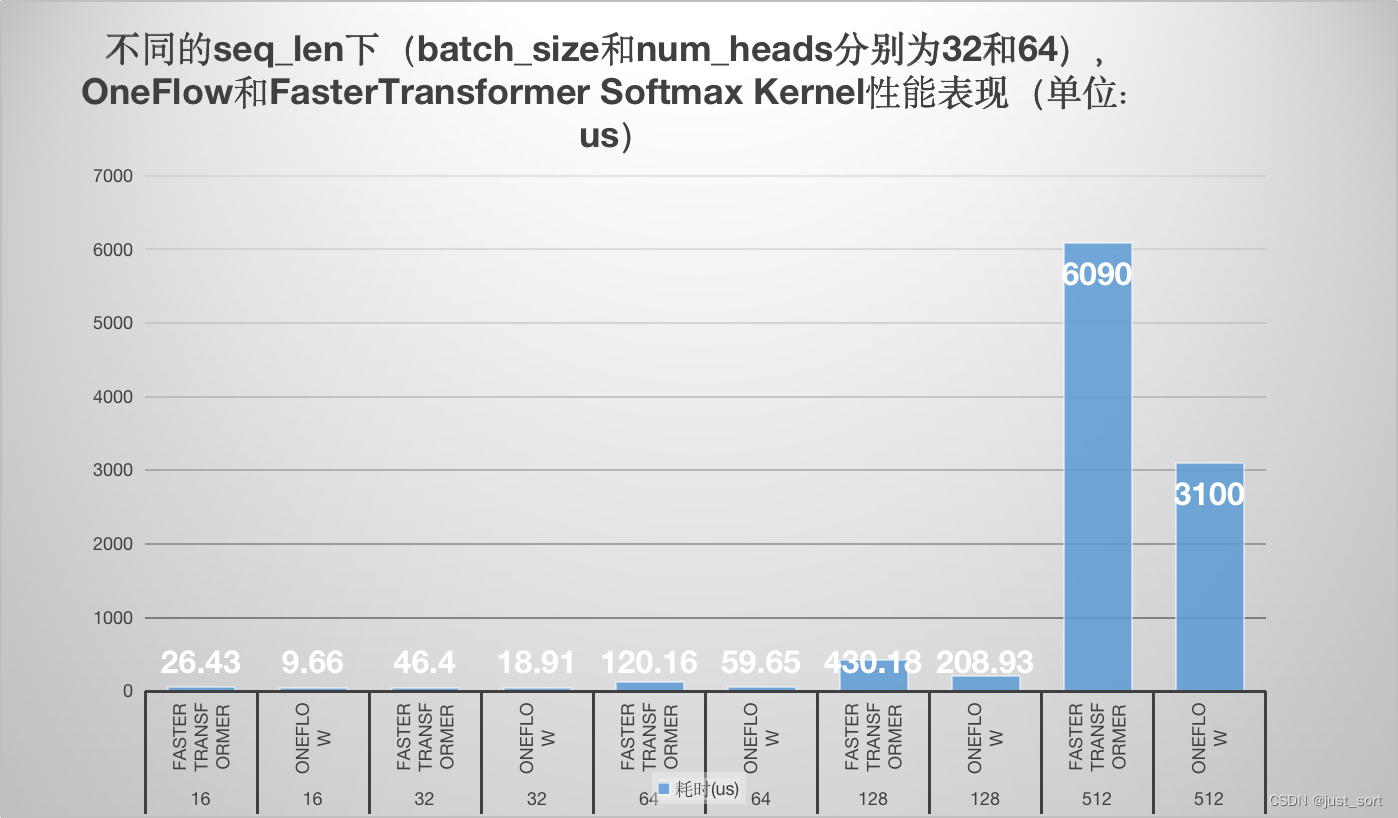
可以看到在各个 seq_len 下,oneflow 的 softmax cuda kernel性能均显著优于 FasterTransformer 的 cuda kernel性能,优化是非常有效的。测试的细节请看下面的 0x4. 性能测试章节。
0x2. OneFlow Softmax
OneFlow 已经有SoftMax的实现介绍:https://zhuanlan.zhihu.com/p/341059988 。我这里会更加详细的介绍其中的代码,最后和 Faster Transformer 的实现做一个对比。
OneFlow 的 softmax 实现被独立到了一个头文件中方便广大开发者使用或者改进,地址为:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/softmax.cuh 。
0x2.1 环境准备
我这里也直接将其搬过来使用并更详细的了解了其中的原理最后测试下性能,需要注意的是oneflow版本的softmax实现依赖了nvidia cub的block reduce,因为要在外面单独运行这个实现需要手动编译下 cub 才可以。接下来展示一下 cub 的完全编译流程:
- 构建trust
# Clone Thrust and CUB from Github. CUB is located in Thrust's
# `dependencies/cub` submodule.
git clone --recursive https://github.com/NVIDIA/thrust.git
cd thrust
# Create build directory:
mkdir build
cd build
# Configure -- use one of the following:
cmake -DTHRUST_INCLUDE_CUB_CMAKE=ON .. # Command line interface.
# Build:
#cmake --build . -j <num jobs> # invokes make (or ninja, etc)
make -j16
# Run tests and examples:
ctest
注意如果 cmake 时出现 Failed to detect a default CUDA architecture. 错误,需要我们自己手动指定一下自己的 nvcc 编译器以及 GPU 架构,也就是在 thrust 的顶层 CMakeLists.txt 加入:
set(CMAKE_CUDA_ARCHITECTURES 80) # 80对应修改为你自己的 GPU 架构
set(CMAKE_CUDA_COMPILER "/usr/local/cuda/bin/nvcc")
- 构建 cub
构建完 thrust 之后我们才可以构建cub。按照上述构建 thrust 的流程走完之后在 thrust/dependencies 这个文件夹下会有 cub 文件夹,我们需要进到这个文件夹里面执行:
$ mkdir build
$ cd build
$ cmake ..
$ make -j16
注意如果这里 cmake 时出现 Failed to detect a default CUDA architecture. 错误,需要我们自己手动指定一下自己的 nvcc 编译器以及 GPU 架构,也就是在 thrust/dependencies/CMakeLists.txt 的顶层加入:
set(CMAKE_CUDA_ARCHITECTURES 80) # 80对应修改为你自己的 GPU 架构
set(CMAKE_CUDA_COMPILER "/usr/local/cuda/bin/nvcc")
最后在编译 oneflow_softmax.cu 这个源文件时我们需要额外指定一下 cub 的头文件路径:
/usr/local/cuda/bin/nvcc -arch=sm_80 -o bin/oneflow_softmax oneflow_softmax.cu -I/home/xxx/thrust/dependencies/cub/build/headers
0x2.2 优化解读
在 如何实现一个高效的Softmax CUDA kernel?——OneFlow 性能优化分享 (https://zhuanlan.zhihu.com/p/341059988) 这篇文章中已经较为详细的阐述了 OneFlow 的 softmax cuda kernel的优化技巧,我这里就不重复讲解其中的内容了。不过当时阅读这个文章的时候感觉对其中一些代码细节以及用法还有一些疑问,本次我在重新阅读的过程中为 oneflow 的 softmax cuda kernel添加了详细的注释以及用法示例。oneflow softmax cuda kernel要求输入数据的shape为(num_rows, num_cols),然后根据 num_cols 的大小进行分段处理:

oneflow cuda kernel实现中最复杂的就是第一种实现(一个 warp 处理一行或者两行),为了方便感兴趣的读者理解,我为这部分实现添加了详细的注释:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/softmax/oneflow_softmax.cu#L12-L540 。由于篇幅太长可以自行查看,欢迎交流。
------------------分割线-----------------
当输入数据的列数也就是 1024 < num_cols <= 4096 时,oneflow softmax kernel使用一个 Block 来处理一行,并且借助 Shared Memory 来保存中间的计算结果。第二种实现的代码实现和解释如下:
// 一个 Block 处理一行元素, 利用 BlockAllReduce 完成 Warp 内各线程间的求 Global Max 和 Global Sum 操作。
// BlockAllReduce 是借助 Cub 的 BlockReduce 方法实现的。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int block_size,
Algorithm algorithm>
__global__ void SoftmaxBlockSMemImpl(LOAD load, STORE store, const int64_t rows,
const int64_t cols) {
extern __shared__ __align__(sizeof(double)) unsigned char shared_buf[];
auto* buf = reinterpret_cast<ComputeType*>(shared_buf);
const int tid = threadIdx.x;
assert(cols % pack_size == 0);
const int num_packs = cols / pack_size;
// 一个 Block 处理一行元素
for (int64_t row = blockIdx.x; row < rows; row += gridDim.x) {
// 当前线程的最大值初始化为 -inf
ComputeType thread_max = -Inf<ComputeType>();
// 以向量化的方式加载一行数据,然后执行pack reduce操作
// 这里的 pack reduce操作我在 https://zhuanlan.zhihu.com/p/596012674 最后一节也有介绍
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
buf[i * num_packs + pack_id] = pack[i];
thread_max = max(thread_max, pack[i]);
}
}
// 执行block reduce获取当前行(由一个 Block 进行处理)的最大值
const ComputeType row_max = BlockAllReduce<MaxOp, ComputeType, block_size>(thread_max);
ComputeType thread_sum = 0;
for (int col = tid; col < cols; col += block_size) {
if (algorithm == Algorithm::kSoftmax) {
const ComputeType exp_x = Exp(buf[col] - row_max);
buf[col] = exp_x;
thread_sum += exp_x;
} else {
const ComputeType x = buf[col] - row_max;
buf[col] = x;
thread_sum += Exp(x);
}
}
// 同理,获得当前行的sum
const ComputeType row_sum = BlockAllReduce<SumOp, ComputeType, block_size>(thread_sum);
// 计算结果并写回到全局内存中
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
if (algorithm == Algorithm::kSoftmax) {
pack[i] = Div(buf[i * num_packs + pack_id], row_sum);
} else if (algorithm == Algorithm::kLogSoftmax) {
pack[i] = buf[i * num_packs + pack_id] - Log(row_sum);
} else {
__trap();
}
}
store.template store<pack_size>(pack, row, pack_id * pack_size);
}
}
}
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int block_size,
Algorithm algorithm>
inline cudaError_t LaunchSoftmaxBlockSMemImpl(cudaStream_t stream, LOAD load, STORE store, int smem,
const int64_t rows, const int64_t cols) {
constexpr int waves = 32;
int grid_dim_x;
{
cudaError_t err = GetNumBlocks(block_size, rows, waves, &grid_dim_x);
if (err != cudaSuccess) { return err; }
}
SoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size, algorithm>
<<<grid_dim_x, block_size, smem, stream>>>(load, store, rows, cols);
return cudaPeekAtLastError();
}
// 执行的主体循环逻辑如下,根据 num_cols算出需要的 Shared Memory 大小作为 Launch Kernel 参数,
// 借助 Shared Memory 保存输入,后续计算直接从 Shared Memory 读取。
// 由于 SM 内的 Shared Memory 资源同样有限,因此当 num_cols超过一定范围,kernel 启动时申请 Shared Memory 超过最大限制,
// 就会出现无法启动的问题,因此,仅在调用 cudaOccupancyMaxActiveBlocksPerMultiprocessor 返回值大于0时采用 Shared Memory 方案。
// 此外,需要注意的是,由于 Block 内线程要做同步,当 SM 中正在调度执行的一个 Block 到达同步点时,SM 内可执行 Warp 逐渐减少,
// 若同时执行的 Block 只有一个,则 SM 中可同时执行的 Warp 会在此时逐渐降成0,会导致计算资源空闲,造成浪费,若此时同时有其他 Block 在执行,
// 则在一个 Block 到达同步点时仍然有其他 Block 可以执行。当 block_size 越小时,SM 可同时调度的 Block 越多,因此在这种情况下 block_size 越小越好。
// 但是当在调大 block_size,SM 能同时调度的 Block 数不变的情况下,block_size 应该是越大越好,越大就有越好的并行度。
// 因此代码中在选择 block_size 时,对不同 block_size 都计算了 cudaOccupancyMaxActiveBlocksPerMultiprocessor,若结果相同,使用较大的 block_size。
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, Algorithm algorithm>
inline cudaError_t TryDispatchSoftmaxBlockSMemImplBlockSize(cudaStream_t stream, LOAD load,
STORE store, const int64_t rows,
const int64_t cols, bool* success) {
// 设置4个不同的block_size
constexpr int block_size_conf_1 = 128;
constexpr int block_size_conf_2 = 256;
constexpr int block_size_conf_3 = 512;
constexpr int block_size_conf_4 = 1024;
// 计算第二种方案需要的共享内存大小
const size_t smem = cols * sizeof(ComputeType);
int max_active_blocks_conf_1;
{
// 占用计算器API cudaOccupancyMaxActiveBlocksPerMultiprocessor可以根据 kernel 的 block 大小和共享内存使用情况提供占用率预测。
cudaError_t err = cudaOccupancyMaxActiveBlocksPerMultiprocessor(
&max_active_blocks_conf_1,
SoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_1, algorithm>,
block_size_conf_1, smem);
if (err != cudaSuccess) { return err; }
}
if (max_active_blocks_conf_1 <= 0) {
*success = false;
return cudaSuccess;
}
// ... 省略了一部分代码
return LaunchSoftmaxBlockSMemImpl<LOAD, STORE, ComputeType, pack_size, block_size_conf_1,
algorithm>(stream, load, store, smem, rows, cols);
}
在第二种实现中,需要特别注意的是给 Shared memory 赋值过程中,若采用下面方法,当 pack size=2,每个线程写连续两个4 byte 地址,就会产生 Bank Conflicts。
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
buf[pack_id * pack_size * i] = pack[i];
thread_max = max(thread_max, pack[i]);
}
因此,在实现(2)中,对Shared memory采用了新的内存布局,避免了同一个Warp访问相同bank的不同地址,避免了Bank Conflicts。
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
buf[num_packs * i + pack_id] = pack[i];
thread_max = max(thread_max, pack[i]);
}
我们需要仔细思考一下这里的原因,我们知道使用 shared memory 要特别小心 bank conflict 。实际上,shared memory 是由 32 个 bank 组成的,如下面这张 PPT 所示:

而 bank conflict 指的就是在一个 warp 内,有2个或者以上的线程访问了同一个 bank 上不同地址的内存。比如:
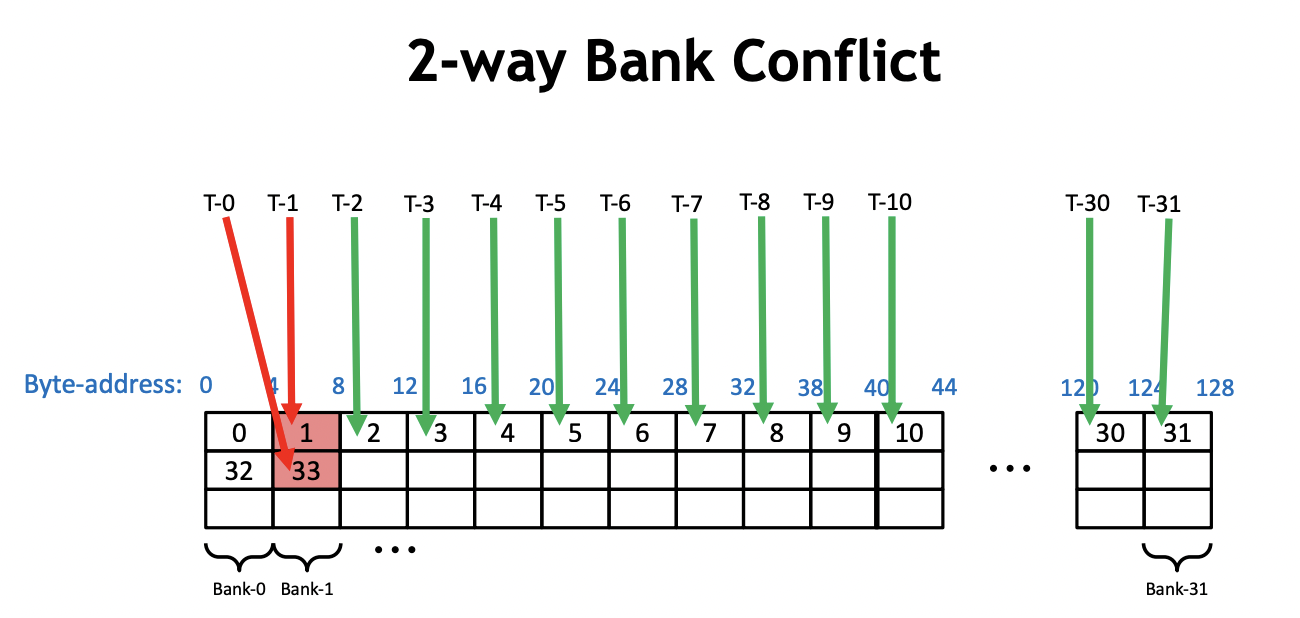
当 pack_size=1,每个线程连续写4个字节时,每个warp刚好完整访问shared memory的一行,这个时候并不会出现bank conflict。而当pack_size=2时,每个线程写连续2个4字节时(可以看成8个字节),这个时候以0号warp为例,0号线程访问的地址在第0和第1个 bank,1号线程访问的地址在第2和第3个 bank,以此类推,16号线程访问地址又在第0和第1个 bank内,和0号线程访问了同一个bank的不同地址,此时即产生了 Bank Conflicts。实际上这里的连续写就对应了这段代码:
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
buf[pack_id * pack_size * i] = pack[i];
thread_max = max(thread_max, pack[i]);
}
}
要避免它产生的bank conflict,就需要对内存的布局进行调整,把它从按行连续写(【num_packs, pack_size】)变成按列的非连续写(【pack_size, num_packs】)。
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
buf[i * num_packs + pack_id] = pack[i];
thread_max = max(thread_max, pack[i]);
}
}
还是当pack_size=2时,每个线程写连续2个4字节时(可以看成8个字节),这个时候以0号warp为例,0号线程访问的地址总是0号 bank,1号线程访问的地址在总是1号 bank,以此类推,现在这种数据排布方法并不会产生 Bank Conflicts。
------------------分割线-----------------
oneflow softmax kernel的最后一种实现是针对仍然是一个 Block 处理一行元素,不同的是,不再用 Shared Memory 缓存输入x,而是在每次计算时重新读输入 x,这种实现没有最大 num_cols的限制,可以支持任意大小。
此外,需要注意的是,在这种实现中,block_size 应该设越大越好,block_size 越大,SM 中能同时并行执行的 Block 数就越少,对 cache 的需求就越少,就有更多机会命中 Cache,多次读x不会多次访问 Global Memory,因此在实际测试中,在能利用 Cache 情况下,有效带宽不会因为读3次x而降低几倍。代码实现如下:
template<typename LOAD, typename STORE, typename ComputeType, int pack_size, int block_size,
Algorithm algorithm>
__global__ void SoftmaxBlockUncachedImpl(LOAD load, STORE store, const int64_t rows,
const int64_t cols) {
const int tid = threadIdx.x;
assert(cols % pack_size == 0);
const int num_packs = cols / pack_size;
for (int64_t row = blockIdx.x; row < rows; row += gridDim.x) {
ComputeType thread_max = -Inf<ComputeType>();
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unroll
for (int i = 0; i < pack_size; ++i) { thread_max = max(thread_max, pack[i]); }
}
const ComputeType row_max = BlockAllReduce<MaxOp, ComputeType, block_size>(thread_max);
ComputeType thread_sum = 0;
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unroll
for (int i = 0; i < pack_size; ++i) { thread_sum += Exp(pack[i] - row_max); }
}
const ComputeType row_sum = BlockAllReduce<SumOp, ComputeType, block_size>(thread_sum);
for (int pack_id = tid; pack_id < num_packs; pack_id += block_size) {
ComputeType pack[pack_size];
load.template load<pack_size>(pack, row, pack_id * pack_size);
#pragma unroll
for (int i = 0; i < pack_size; ++i) {
if (algorithm == Algorithm::kSoftmax) {
pack[i] = Div(Exp(pack[i] - row_max), row_sum);
} else if (algorithm == Algorithm::kLogSoftmax) {
pack[i] = (pack[i] - row_max) - Log(row_sum);
} else {
__trap();
}
}
store.template store<pack_size>(pack, row, pack_id * pack_size);
}
}
}
第三种实现的代码较为简单,就不仔细添加注释了。
0x3. FasterTransformer Softmax
接下来我们看一下 FasterTransformer 的 softmax kernel实现,这部分的代码实现在:https://github.com/NVIDIA/FasterTransformer/blob/release/v1.0_tag/fastertransformer/cuda/open_attention.cu#L189-L268 。是需要注意的是这里的 kernel 需要传入一个 mask 的输入作用于解码器,这个大家应该都比较熟悉,是 transformer 架构解码器的一个操作,因为解码的时候我们无法看到句子中当前 token 的后续 token。这个地方为了便于对比 oneflow 的 softmax kernel,我在最小实现中屏蔽掉了这个 mask 只对输入做一个裸的 softmax 运算来对比性能。我的最小实现代码位置在:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/softmax/faster_transformer_softmax.cu 。
这个代码和 oneflow softmax kernel的第三种实现类似,我们先来看一下如何启动FasterTransformer的2种softmax kernel:
// input shape: [bacth_size, head_num, seq_len, seq_len]
const int batch_size = 32;
const int head_num = 64;
const int seq_len = 32;
const float scaler = 1.0;
const int N = batch_size * head_num * seq_len * seq_len;
float* input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 1.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
cudaStream_t stream;
cudaStreamCreate(&stream);
dim3 grid, block;
if(seq_len <= 32)
block.x = 32;
else if(seq_len > 32 && seq_len <= 64)
block.x = 64;
else if(seq_len > 64 && seq_len <= 128)
block.x = 128;
else if(seq_len > 128 && seq_len <= 256)
block.x = 256;
else if(seq_len > 256 && seq_len <= 512)
block.x = 512;
else
block.x = 1024;
// 如果 batch_size 和 head_num 的乘积 <= 120,block 数量设置为 batch_size * head_num * seq_len,也就是一个 block 负责处理 seq_len 个元素
if(batch_size * head_num <= 120)
{
grid.x = batch_size * head_num * seq_len;
softmax_kernel_v2<float><<<grid, block, 0, stream>>>(input_device, /*attr_mask*/ batch_size, head_num, seq_len, scaler);
}
// 否则,block的数量设置为 batch_size * head_num, 也就是一个 block 负责处理 seq_len * seq_len 个元素
else
{
grid.x = batch_size * head_num;
softmax_kernel<float><<<grid, block, 0, stream>>>(input_device, /*attr_mask*/ batch_size, head_num, seq_len, scaler);
}
float *output_host = (float*)malloc(N * sizeof(float));
cudaMemcpy(output_host, input_device, N * sizeof(float), cudaMemcpyDeviceToHost);
// 1 / 32 = 0.03125
for (int i = 0; i < 32; i++){
printf("%.5f\n", output_host[i]);
}
对于这里的 softmax_kernel 以及 softmax_kernel_v2 它们的输入参数都是一致的:
// 以 BERT 为例
// query, key, value shape: [batch_size, head_num, seq_len, size_per_head]
// qk_buf shape: [batch_size, head_num, seq_len, seq_len]
// attr_mask shape: [seq_len, seq_len]
// scaler: 缩放系数
template <typename T>
__global__
void softmax_kernel(T* qk_buf_, /*const T* attr_mask*/ const int batch_size, const int head_num, const int seq_len,
const T scaler){
...
}
也就是说FasterTransformer里面的softmax kernel需要满足输入数据的shape是 [batch_size, head_num, seq_len, seq_len],然后在最后一个维度上进行 softmax 得到每个句子里面的单词和单词的相似度。
从上面启动 kernel 的代码来看,trick也非常简单,首先根据 seq_len 来选一个合适的 block_size,然后如果 batch_size 和 head_num 的乘积 <= 120,block 数量设置为 batch_size * head_num * seq_len,也就是一个 block 负责处理 seq_len 个元素。否则,block的数量设置为 batch_size * head_num, 也就是一个 block 负责处理 seq_len * seq_len 个元素。kernel的代码实现就是一个经典的 block reduce代码,这里就不再赘述。可以直接查看我上面给出的最小代码的链接:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/softmax/faster_transformer_softmax.cu 。
0x4. 性能对比
使用ncu在A100 PCIE 40G上进行profile,以FasterTransformer为准,我们挑选如下的几个shape(batch_size, num_heads, seq_len, seq_len)我们只变化 seq_len:
- (32, 64, 16, 16)
- (32, 64, 32, 32)
- (32, 64, 64, 64)
- (32, 64, 128, 128)
- (32, 64, 512, 512)
对于 oneflow 的实现来说,我们只需要把 num_rows 设置成 batch_size * num_heads * seq_len ,把 num_cols 设置成 seq_len 即可。接下来我们分别测试下上面这些情况下 oneflow 和 FasterTransformer softmax cuda kernel 的性能表现(此处设定数据类型都为 float ):
| seq_len | 框架 | 耗时(us) |
|---|---|---|
| 16 | FasterTransformer | 26.43 |
| 16 | OneFlow | 9.66 |
| 32 | FasterTransformer | 46.40 |
| 32 | OneFlow | 18.91 |
| 64 | FasterTransformer | 120.16 |
| 64 | OneFlow | 59.65 |
| 128 | FasterTransformer | 430.18 |
| 128 | OneFlow | 208.93 |
| 512 | FasterTransformer | 6090 |
| 512 | OneFlow | 3100 |
为了更直观,这里画一个图:
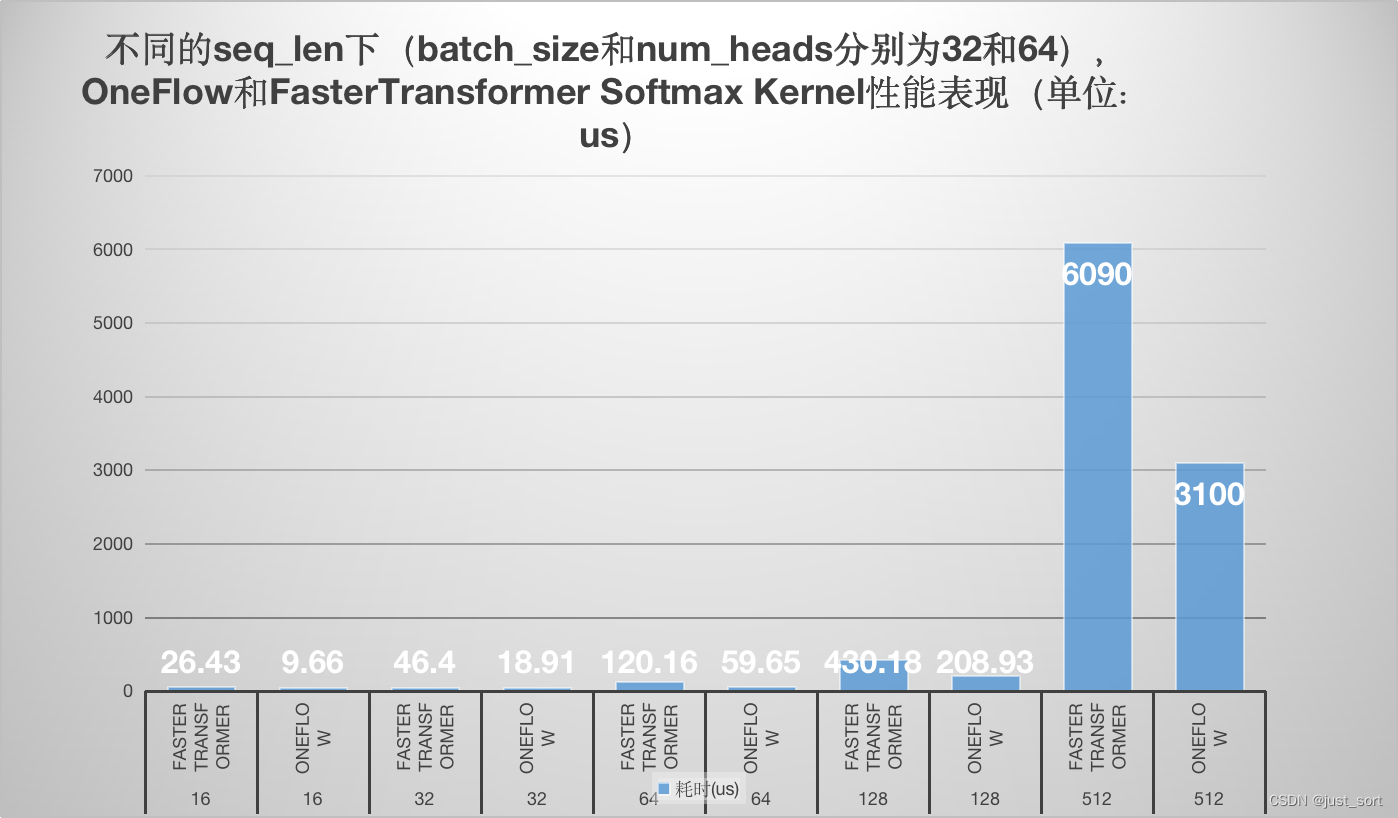
可以看到在各个 seq_len 下,oneflow 的 softmax cuda kernel性能均显著优于 FasterTransformer 的 cuda kernel性能,优化是非常有效的。
0x5. 总结
这篇文章主要学习了oneflow的softmax kernel实现以及Faster Transformer softmax kernel的实现,并以个人的角度分别解析了原理和代码实现,最后对性能做一个对比方便大家直观的感受到oneflow softmax kernel相比于FasterTransformer的优越性。我目前处于尽可能去理解oneflow的一些优秀的cuda实现的阶段,做一些知识储备,同时也调研和学习下相关的一些优化库的的cuda kernel。欢迎大家关注这个仓库 https://github.com/BBuf/how-to-optim-algorithm-in-cuda 一起交流学习。