一、部署架构设计
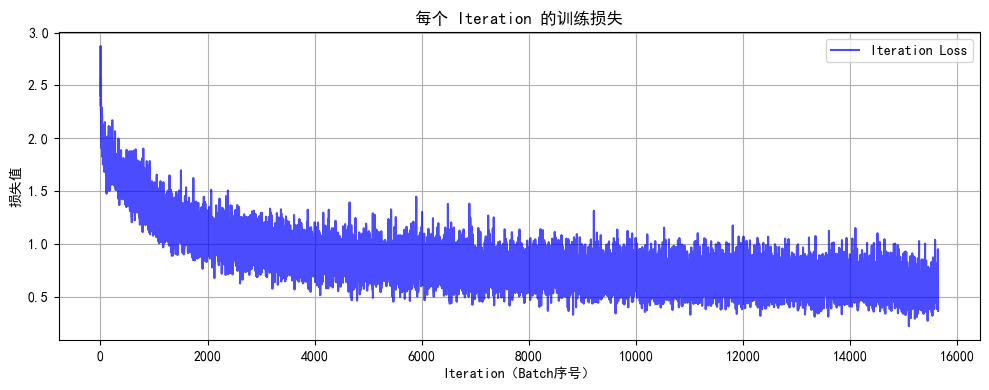
1. 集群架构
graph TD
Client([客户端]) --> JM1[JobManager 1]
Client --> JM2[JobManager 2]
Client --> JM3[JobManager 3]
subgraph ZooKeeper集群
ZK1[ZooKeeper 1]
ZK2[ZooKeeper 2]
ZK3[ZooKeeper 3]
end
subgraph TaskManager集群
TM1[TaskManager 1]
TM2[TaskManager 2]
TM3[TaskManager 3]
end
JM1 --> ZK1
JM2 --> ZK2
JM3 --> ZK3
JM1 --> TM1
JM1 --> TM2
JM1 --> TM32. 节点规划
| 节点 | 主机名 | IP 地址 | 角色分配 | 硬件配置 |
|---|---|---|---|---|
| 节点1 | flink-jm1 | 10.0.0.101 | JobManager + ZooKeeper | 8核16GB |
| 节点2 | flink-jm2 | 10.0.0.102 | JobManager + ZooKeeper | 8核16GB |
| 节点3 | flink-jm3 | 10.0.0.103 | JobManager + ZooKeeper | 8核16GB |
| 节点4 | flink-tm1 | 10.0.0.104 | TaskManager | 16核32GB |
| 节点5 | flink-tm2 | 10.0.0.105 | TaskManager | 16核32GB |
| 节点6 | flink-tm3 | 10.0.0.106 | TaskManager | 16核32GB |
二、环境准备
1. 系统要求
- 操作系统: CentOS 7.9 或 Ubuntu 20.04 LTS
- Java版本: OpenJDK 11 (建议使用 Azul Zulu 11)
- 防火墙: 开放以下端口
- JobManager: 6123, 6124, 8081, 8082
- TaskManager: 6121, 6122, 6125
- ZooKeeper: 2181, 2888, 3888
2. 基础配置(所有节点)
# 创建专用用户
sudo useradd -m -s /bin/bash flink
sudo passwd flink
# 配置主机名解析(所有节点)
sudo tee -a /etc/hosts <<EOF
10.0.0.101 flink-jm1
10.0.0.102 flink-jm2
10.0.0.103 flink-jm3
10.0.0.104 flink-tm1
10.0.0.105 flink-tm2
10.0.0.106 flink-tm3
EOF
# 配置SSH免密登录(JobManager节点间)
sudo -u flink ssh-keygen -t rsa -P ''
sudo -u flink ssh-copy-id flink@flink-jm1
sudo -u flink ssh-copy-id flink@flink-jm2
sudo -u flink ssh-copy-id flink@flink-jm3
# 安装Java
sudo apt install -y openjdk-11-jdk
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' | sudo tee /etc/profile.d/java.sh
source /etc/profile三、ZooKeeper集群部署
1. 安装配置(所有ZK节点执行)
# 下载解压
cd /opt
sudo wget https://downloads.apache.org/zookeeper/zookeeper-3.8.1/apache-zookeeper-3.8.1-bin.tar.gz
sudo tar -xzf apache-zookeeper-3.8.1-bin.tar.gz
sudo mv apache-zookeeper-3.8.1-bin zookeeper
sudo chown -R flink:flink /opt/zookeeper
# 创建数据目录
sudo mkdir /data/zookeeper
sudo chown flink:flink /data/zookeeper
# 配置zoo.cfg
sudo -u flink tee /opt/zookeeper/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
maxClientCnxns=100
admin.enableServer=false
server.1=flink-jm1:2888:3888
server.2=flink-jm2:2888:3888
server.3=flink-jm3:2888:3888
EOF
# 创建myid文件(每个节点不同)
# flink-jm1:
echo "1" | sudo -u flink tee /data/zookeeper/myid
# flink-jm2:
echo "2" | sudo -u flink tee /data/zookeeper/myid
# flink-jm3:
echo "3" | sudo -u flink tee /data/zookeeper/myid2. 启动与验证
# 所有ZK节点启动服务
sudo -u flink /opt/zookeeper/bin/zkServer.sh start
# 检查集群状态
sudo -u flink /opt/zookeeper/bin/zkCli.sh -server flink-jm1:2181
[zk: flink-jm1:2181(CONNECTED) 0] srvr四、Flink集群部署
1. 安装Flink(所有节点)
cd /opt
sudo wget https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
sudo tar -xzf flink-1.17.1-bin-scala_2.12.tgz
sudo mv flink-1.17.1 flink
sudo chown -R flink:flink /opt/flink
# 设置环境变量
echo 'export FLINK_HOME=/opt/flink' | sudo tee /etc/profile.d/flink.sh
echo 'export PATH=$PATH:$FLINK_HOME/bin' | sudo tee /etc/profile.d/flink.sh
source /etc/profile2. 高可用配置(JobManager节点)
flink-conf.yaml 关键配置:
# flink-jm1、flink-jm2、flink-jm3节点配置
# /opt/flink/conf/flink-conf.yaml
# 高可用配置
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha
high-availability.zookeeper.quorum: flink-jm1:2181,flink-jm2:2181,flink-jm3:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /flink-cluster
# 状态后端配置(需HDFS支持)
state.backend: rocksdb
state.checkpoints.dir: hdfs:///flink/checkpoints
state.savepoints.dir: hdfs:///flink/savepoints
state.backend.rocksdb.checkpoint.transfer.thread.num: 4
state.backend.rocksdb.localdir: /data/rocksdb
# JobManager配置
jobmanager.rpc.address: flink-jm1
jobmanager.rpc.port: 6123
jobmanager.memory.process.size: 4096m
jobmanager.scheduler: adaptive
# TaskManager配置
taskmanager.memory.process.size: 24576m # 24GB
taskmanager.memory.managed.size: 8192m # 8GB 堆外内存
taskmanager.numberOfTaskSlots: 8
taskmanager.memory.network.min: 512m
taskmanager.memory.network.max: 1024m
# 网络与通信
taskmanager.network.bind-policy: ip
akka.ask.timeout: 60s
# Web UI
rest.address: 0.0.0.0
rest.port: 8081
# 检查点配置
execution.checkpointing.interval: 5min
execution.checkpointing.timeout: 10min
execution.checkpointing.mode: EXACTLY_ONCEmasters配置:
# /opt/flink/conf/masters(所有JobManager节点相同)
flink-jm1:8081
flink-jm2:8081
flink-jm3:8081workers配置:
# /opt/flink/conf/workers(所有节点相同)
flink-tm1
flink-tm2
flink-tm33. TaskManager节点配置
# /opt/flink/conf/flink-conf.yaml(所有TaskManager节点)
# 覆盖JobManager地址配置
jobmanager.rpc.address: flink-jm1
# TaskManager专用配置
taskmanager.memory.process.size: 24576m
taskmanager.memory.managed.size: 8192m
taskmanager.numberOfTaskSlots: 84. 配置HDFS支持(可选)
# 所有节点
sudo tee -a /opt/flink/conf/flink-conf.yaml <<EOF
fs.hdfs.hadoopconf: /etc/hadoop/conf
fs.hdfs.hdfsdefault: hdfs-default.xml
fs.hdfs.hdfssite: hdfs-site.xml
EOF
# 复制Hadoop配置文件到Flink目录
sudo cp /etc/hadoop/conf/*-site.xml /opt/flink/conf/五、启动集群
1. 启动JobManager集群
# 在每个JobManager节点执行
sudo -u flink $FLINK_HOME/bin/jobmanager.sh start
# 检查启动状态
sudo -u flink $FLINK_HOME/bin/jobmanager.sh status2. 启动TaskManager集群
# 在每个TaskManager节点执行
sudo -u flink $FLINK_HOME/bin/taskmanager.sh start
# 检查启动状态
sudo -u flink $FLINK_HOME/bin/taskmanager.sh status3. 查看集群状态
# 查看JobManager列表
sudo -u flink $FLINK_HOME/bin/jobmanager.sh list
# 查看Web UI
http://flink-jm1:8081
http://flink-jm2:8081
http://flink-jm3:8081六、高可用验证测试
1. 提交示例作业
$FLINK_HOME/bin/flink run -m flink-jm1:8081 \
$FLINK_HOME/examples/streaming/StateMachineExample.jar2. 故障转移测试
# 查找主JobManager PID
ps aux | grep '[j]obmanager'
# 模拟故障,杀死主JobManager
kill -9 <JM_PID>
# 观察日志(约10-30秒后自动恢复)
tail -f /opt/flink/log/flink-flink-jobmanager-*.log3. 检查点验证
# 查看检查点状态
hdfs dfs -ls /flink/checkpoints
# 列出正在运行的作业
$FLINK_HOME/bin/flink list -m flink-jm2:8081七、运维管理脚本
1. 集群启动/停止脚本
#!/bin/bash
# flink-cluster.sh
case $1 in
start)
for jm in flink-jm1 flink-jm2 flink-jm3; do
ssh flink@$jm "$FLINK_HOME/bin/jobmanager.sh start"
done
for tm in flink-tm1 flink-tm2 flink-tm3; do
ssh flink@$tm "$FLINK_HOME/bin/taskmanager.sh start"
done
;;
stop)
for tm in flink-tm1 flink-tm2 flink-tm3; do
ssh flink@$tm "$FLINK_HOME/bin/taskmanager.sh stop"
done
for jm in flink-jm1 flink-jm2 flink-jm3; do
ssh flink@$jm "$FLINK_HOME/bin/jobmanager.sh stop"
done
;;
restart)
$0 stop
sleep 5
$0 start
;;
status)
for jm in flink-jm1 flink-jm2 flink-jm3; do
echo "=== $jm ==="
ssh flink@$jm "$FLINK_HOME/bin/jobmanager.sh status"
done
for tm in flink-tm1 flink-tm2 flink-tm3; do
echo "=== $tm ==="
ssh flink@$tm "$FLINK_HOME/bin/taskmanager.sh status"
done
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
exit 1
;;
esac2. 日志监控脚本
#!/bin/bash
# monitor-flink-logs.sh
tail -f /opt/flink/log/flink-flink-*.log \
| awk '
/ERROR/ {print "\033[31m" $0 "\033[39m"; next}
/WARN/ {print "\033[33m" $0 "\033[39m"; next}
/Transition.+MASTER/ {print "\033[32m" $0 "\033[39m"; next}
{print}
'八、常见问题解决
1. JobManager无法选举
症状:日志中出现No leader available错误
解决方案:
# 检查ZooKeeper连接
$FLINK_HOME/bin/flink list -m zookeeper
# 清空临时状态(谨慎操作)
hdfs dfs -rm -r /flink/ha/*2. TaskManager无法注册
症状:Web UI中不显示TaskManager
解决方案:
# 检查网络连通性
telnet flink-jm1 6123
# 检查防火墙
sudo ufw status
# 增加网络超时(flink-conf.yaml)
taskmanager.registration.timeout: 5min3. 检查点失败
症状:作业因检查点超时失败
解决方案:
# 优化配置(flink-conf.yaml)
execution.checkpointing.interval: 2min
execution.checkpointing.timeout: 5min
state.backend.rocksdb.localdir: /data/rocksdb九、备份与恢复
1. Savepoint操作
# 手动创建Savepoint
flink savepoint <job-id> hdfs:///flink/savepoints
# 从Savepoint恢复
flink run -s hdfs:///flink/savepoints/savepoint-... \
-m flink-jm1:8081 /path/to/job.jar2. 配置备份
# 备份关键配置
tar -czvf flink-conf-backup.tar.gz /opt/flink/conf
# 备份作业JAR包
hdfs dfs -copyFromLocal /opt/flink/jobs /flink/job-backups十、安全增强建议
1. 启用Kerberos认证
# flink-conf.yaml
security.kerberos.login.keytab: /etc/security/keytabs/flink.service.keytab
security.kerberos.login.principal: flink/_HOST@REALM
security.kerberos.login.contexts: Client2. SSL加密通信
# flink-conf.yaml
security.ssl.enabled: true
security.ssl.keystore: /etc/ssl/flink.keystore
security.ssl.truststore: /etc/ssl/flink.truststore
security.ssl.keystore-password: changeme
security.ssl.truststore-password: changeme3. 访问控制
# Web UI访问限制
rest.address: 127.0.0.1
# 或使用代理+Nginx基础认证完成上述部署后,您将获得一个高可用的 Flink 集群,能够承受节点故障并保证作业持续运行。建议首次部署完成后进行完整的故障转移测试,确保高可用功能按预期工作。
十一、关联知识
【分布式技术】中间件-分布式协调服务zookeeper