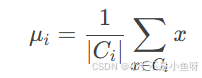论文发表于人工智能顶会NeurIPS(原文链接),研究了GPT(Generative Pre-trained Transformer)中事实关联的存储和回忆,发现这些关联与局部化、可直接编辑的计算相对应。因此:
1、开发了一种因果干预方法,用于识别对模型的事实预测起决定性作用的神经元。
2、为了验证这些神经元是否对应于事实关联的回忆,使用秩一模型编辑 (Rank-One Model Editing, ROME) 修改前馈权重来更新特定的事实关联。
3、提出一个反事实断言数据集来评估ROME。
阅读本文请同时参考原始论文图表。
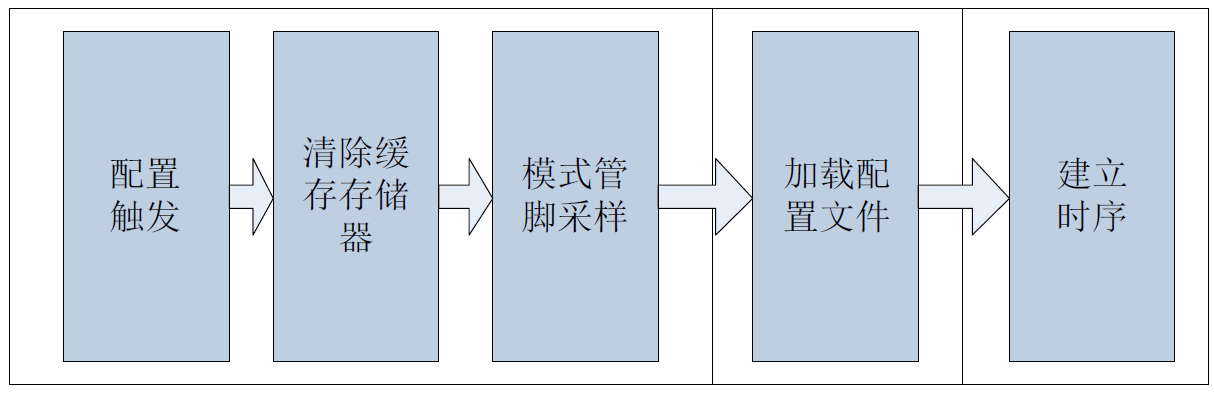
方法
如图1所示,将自回归模型的中间表示与输出之间的关系表示为图节点的形式,从而可以分析输出与中间表示之间的因果关系。定义输入语言变量为$x=[x_1,…,x_T]$,则第$i$个输入变量的第$l$层激活为$h_i^{(l)}$。模型各层计算可以表示为文中式(1):
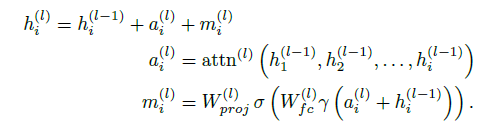
本文使用最后一个输入的最后一层激活$h^{(L)}_T$映射到词汇空间作为模型输出。实验使用包含事实三元组$(s,r,o)$的头$s$和关系$r$的句子作为输入,预测尾实体$o$。
因果中介分析
为了分析哪些中间激活对正确事实预测的贡献最大,使用三种配置对模型$G$推理三次:
1、Clean run:输入干净的句子,得到干净的中间激活$\{h_i^{(l)}|i\in [1,T],l\in[1,L]\}$和模型对尾实体$o$的预测概率$\mathbb{P}[o]$。
2、Corrupted run:用噪声污染每个$s$的词嵌入$h_i^{(0)}$,得到污染的中间激活$\{h_{i*}^{(l)}|i\in [1,T],l\in[1,L]\}$和模型对尾实体$o$的预测概率$\mathbb{P}_*[o]$。
3、Corrupted-with-restoration run:使用干净的中间激活替换污染的中间激活,得到替换$h_i^{(l)}$时模型对尾实体$o$的预测概率$\mathbb{P}_{*,clean\, h_i^{(l)}}[o]$。
定义总效应 $\text{TE}=\mathbb{P}[o]-\mathbb{P}_*[o]$,表示受污染的输入对模型性能的损害程度。
定义间接效应 $\text{IE}=\mathbb{P}_{*,clean\, h_i^{(l)}}[o]-\mathbb{P}_*[o]$,表示输入被污染后,恢复中间激活$h_i^{(l)}$对模型性能的恢复程度。下面关于各层模块输出的影响程度都是通过Average IE (AIE) 来评估。
其实验代码汇总并不是每次只恢复污染一个表示,而是一个窗口。如当窗口为10时,恢复层数为$[l-5,l+5]$11个表示。
分析结果1
图1e/f/g 可视化了模型在一个样本上分别恢复层激活$h_i^{l}$、FFN激活$m_i^{(l)}$、注意力激活$a_i^{(l)}$的影响,以恢复模型中间状态在正确答案上的概率来衡量。
图2a/b/c 可视化了模型在超过1000个样本上分别恢复三个激活对正确预测的平均影响程度,以IE来衡量。
根据图1/2,可以看出:
1、较前层的FFN在句子主体$s$的最后一个token位置的激活$m_i^{(l)}$对预测的影响较大。这说明本文提出的因果分析方法可以有效定位影响模型预测的中间激活,也和之前认为FFN保存知识的研究结果一致。
2、较后层的注意力模块在句子的最后一个token位置的激活$a_i^{(l)}$对预测影响较大,这是比较正常的现象。
3、可以看出层激活$h_i^{(l)}$对预测的影响是以上两者的综合。
附录B.2 图7进一步展示了模型三类模块在句子各部分的激活对模型输出的影响。
结果分析2
为了对FFN在句子的前半部分所起的作用有更清晰的理解,作者进一步修改因果图来研究其因果效应。如图3左所示,当把主体$s$最后一个token的层激活$h_{i}^{(l)}$修正(使用干净激活替换污染激活)时,对于其后面的隐藏状态$h^{(k)}_{i},k>l$,使用原始保存的没修正时(污染)的FFN输出$m_{i*}^{(k)}$代替后续计算出的$m_{i}^{(k)}$,从而在关于$h_i^{(l)}$对模型预测的影响中去除FFN的效应。从右图可以看出,FFN计算的去除使得较前层的$h_i^{(l)}$对模型预测的影响显著降低,说明$h_i^{(l)}$后续的FFN计算(读取记忆)对预测是至关重要的,而注意力模块(粉色)则没有这个结果。
秩一模型编辑 (ROME)
根据前面的分析,作者期望通过修改中间层FFN的权重来修改模型存储的事实。相较于之前的论文把FFN的第一层权重$W_{fc}^{(l)}$和第二层权重$W_{prop}^{(l)}$对应的行列向量看成键值对,本文:
1、把FFN的第二层权重$W_{prop}^{(l)}\in\R^{d_2\times d_1}$的工作机制看成Linear Associative Memory(线性相联存储器,不知道是不是这个意思)。
2、把FFN第一层的输出$K=[k_1,...,k_t]\in \R^{d_1\times t}$看成键。
3、把通过第二层权重$W_{prop}^{(l)}$的输出$V=WK=[v_1,…,v_t]\in\R^{d_2\times t}$看成值。
其中$t$表示训练过程中出现的所有可能的键值对的数量。在已知$K,V$的情况下,$W_{prop}^{(l)}$可以直接通过广义逆计算$W_{prop}^{(l)}=VK^+$。当我们需要新增一个知识时,就是给$K,V$新增一个键$k_*$和值$v_*$。此时就是在满足$\hat{W}k_*=v_*$的情况下,最小化$\|\hat{W}K-V\|$。可以通过拉格朗日方法得到闭式解,如式(2)所示。
![]()
其中$C=KK^T$是一个通过预训练数据计算得到的常数矩阵,$W$为原始矩阵,$\Lambda=(v_*-Wk_*)/(C^{-1}k_*)^Tk_*$是相较于原始矩阵的残差。
接下来就是计算新增知识的键值对$k_*,v_*$,如图4所示:
1、把句子输入模型,取主体$s$的最后一个token在需要修改的第$l^*$层的FFN的第一层激活作为$k_*$。为了获得更鲁棒的结果,计算多个以$s$结尾的句子的激活值的均值,如文中式(3)所示。
2、通过优化相应位置的向量来获得$v_*$,损失函数如式(4)所示,目的就是让$v_*$编码$(r,o^*)$。
3、用式(2)和$k_*,v_*$更新$W_{prop}^{(l)}$。
所谓的秩一,应该就是给$K,V$都增加一列,从而更新的$W$矩阵的秩可能加一。
实验
zsRE上的对比
在Zero-Shot关系抽取(zsRE)数据集上对GPT-2 XL的编辑实验。数据示例如附录图22所示,实验流程就是把模型关于输入”src”的输出修改为”answer”。实验结果如表1所示,对比了元学习方法MEND和KE。其中”+L”表示微调的同时使用无穷范数限制参数的更新,”-zsRE”表示相关基于元学习的超网络方法先在zsRE训练集上进行训练后再进行修改。Efficacy是模型输入”src”时的判断准确率,Paraphrase是模型输入同义句子时的预测准确率,Specificity是模型输入不相关句子时的预测准确率。Efficacy和Paraphrase指标可以看出ROME的确能正确修改事实,但是Specificity指标看起来是一个没有意义的指标。
反事实数据集上的对比
由于以上对比的指标差异并不显著,为了让方法效果更容易区分,作者构建了一个反事实 (COUNTERFACT) 数据集,旨在将模型携带的正确事实$(s,r,o^c)$修改为错误事实$(s,r,o^*)$。这是因为模型对正确事实的预测分数通常比错误事实高,如果编辑方法能使错误事实的预测分数比正确事实高,就能更好地说明方法的有效性。数据集汇总和对比如表2/3所示。
定义$\mathbb{P}[o^*],\mathbb{P}[o^c]$分别为模型编辑后对错误事实和正确事实的预测分数。评价指标如下:
1、Efficacy Score (ES)为$\mathbb{P}[o^*]>\mathbb{P}[o^c]$的测试样本的比例,Efficacy Magnitude (EM)为$\mathbb{P}[o^*]-\mathbb{P}[o^c]$的测试均值。
2、同上定义在同义句子上测试的Paraphrase Scores (PS)和Paraphrase Magnitude (PM)。
3、搜集有正确答案$o^c$的不同事实$(s_n,r,o^c)$,在将模型进行事实编辑$(s,r,o^*)$后,测试模型对于$(s_n,r,?)$的预测是否依旧有$\mathbb{P}[o^c]>\mathbb{P}[o^*]$,定义相应的Neighborhood Score (NS)和Neighborhood Magnitude (NM)。
4、cos similarity (CS):让编辑后的模型生成以$s$开头的文本,计算其unigram TF-IDF,然后与包含$s,o^*$的参考文本的unigram TF-IDF计算余弦相似度。
5、GE:评估模型生成的流利退化程度。也就是计算生成句子$x$的bi-/tri-gram熵$H(f(x))$,其中$f(x)$表示n-gram的频率分布。指标越高,生成句子的多样性越高,但不知道和流利度有什么关系。
图5展示了对模型不同层和句子不同位置的组合对应的FFN权重进行编辑,得到的结果。可以看出对主体$s$的最后一个token(红线)在模型中间层的激活进行编辑得到最好的结果,有最高的准确率和泛化率,以及对邻居事实最低的损害度。
表4展示了各模型在反事实数据上的结果,其中”-CF” 表示先在其训练集上进行训练后再进行测试。本文方法有较好地修改效果的同时,能保持相邻事实的不变性(Specificity),而其它方法都不能实现。
与集成梯度归因的对比
图10:本文因果干预方法归因的中间激活对预测的影响可视化。
图16:KN的集成梯度方法归因的中间激活对预测的影响可视化。
可以看出集成梯度方法没有明确揭示出事实主体$s$对预测的重要性,归因出几乎所有token的激活对最终预测都有影响,这是不合理的。当然,这里的归因与KN不同的是,KN论文中仅仅对[MASK]位置的激活进行归因,而且是在激活的元素层面上进行的,而这里是对所有激活向量进行归因。
Attention模块对预测的影响
附录第I节,用微调对Att模块的各个注意力映射矩阵进行修改(取名为AttnEdit),与ROME方法进行对比,定性结果如表25所示。ROME和AttnEdit都能成功编辑,但是AttnEdit无法泛化到相近提问。
总结
与KN的对比:
1、KN通过集成梯度仅仅定位激活的一个元素,并修改FFN第二层权重对应的一个向量,并且直接通过翻倍或者置零实现,是一种很粗糙的编辑。
2、ROME的定位比KN往上一个层级,用因果干预方法定位整个激活向量,然后修改FFN第二层的整个权重来实现编辑。简单来说就是把要编辑的事实对应于该权重的输入输出,加入模型原始训练数据对应于该权重的输入输出列表中,让这个权重重新适应这个列表。
本文定位方法更有理论依据,编辑对其它知识的影响也可以从优化角度来量化。