1. K-means 的原理
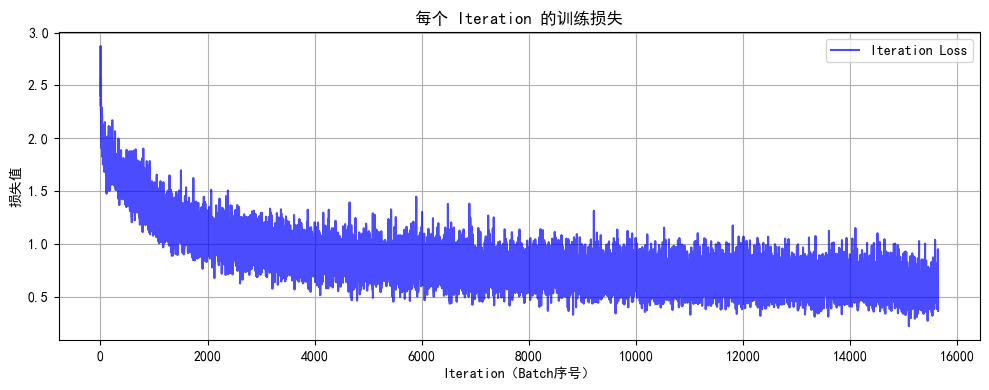
K-means 是一种经典的无监督学习算法,用于将数据集划分为 kk 个簇(cluster)。其核心思想是通过迭代优化,将数据点分配到最近的簇中心,并更新簇中心,直到簇中心不再变化或达到最大迭代次数。
算法步骤:
-
初始化: 随机选择 kk 个数据点作为初始簇中心(centroids)。
-
分配步骤(Assignment Step): 将每个数据点分配到距离最近的簇中心。
-
更新步骤(Update Step): 重新计算每个簇的中心(即簇内所有数据点的均值)。
-
迭代: 重复步骤 2 和 3,直到簇中心不再变化或达到最大迭代次数。
2. K-means 的公式推导
目标函数
K-means 的目标是最小化所有数据点到其所属簇中心的距离平方和(即误差平方和,SSE):
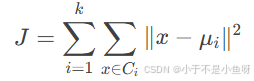
其中:
-
k:簇的数量。
-
Ci:第 i 个簇。
-
x:数据点。
-
μi:第 i 个簇的中心。
分配步骤
将每个数据点 x 分配到距离最近的簇中心:
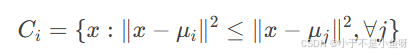
更新步骤
重新计算每个簇的中心 μi,即簇内所有数据点的均值:
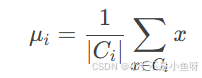
其中 ∣Ci∣ 是第 i 个簇中数据点的数量。
3. 手撕代码实现
下面是用 Python 实现 K-means 算法的代码: