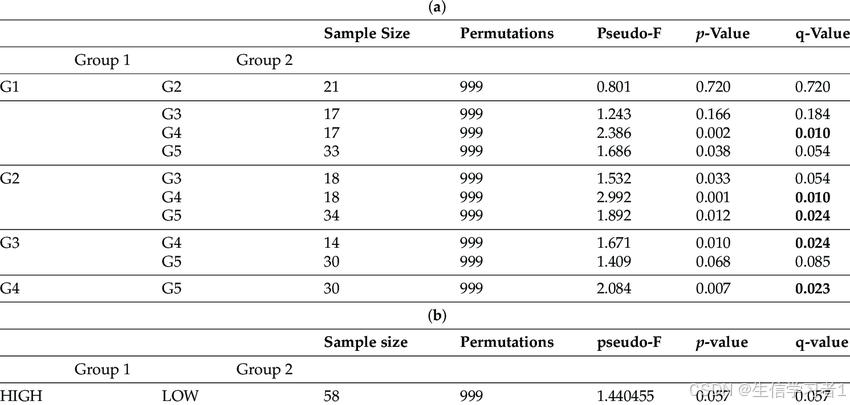
一、SVM的动机:大间隔分类器
1、逻辑回归回顾
-
假设函数为 sigmoid 函数:
h θ ( x ) = 1 1 + e − θ T x h_\theta(x) = \frac{1}{1 + e^{-\theta^Tx}} hθ(x)=1+e−θTx1 -
分类依据是 h θ ( x ) ≥ 0.5 h_\theta(x) \geq 0.5 hθ(x)≥0.5 为正类,反之为负类。
2、SVM 的思路
- SVM 不采用 sigmoid,而是直接构造优化目标:
- 最大化间隔(margin):希望分类边界离最近的点尽可能远。
- 构造代价函数时:
- 对正类样本 y = 1 y=1 y=1,如果 θ T x ≥ 1 \theta^T x \geq 1 θTx≥1 则无惩罚,否则惩罚。
- 对负类样本 y = 0 y=0 y=0,如果 θ T x ≤ − 1 \theta^T x \leq -1 θTx≤−1 则无惩罚,否则惩罚。
二、SVM 的代价函数与优化
1、硬间隔 vs 软间隔
- 硬间隔(hard margin):
- 不允许分类错误,适合线性可分的情况。
- 软间隔(soft margin):
- 允许一定的错误分类,提升鲁棒性。
2、SVM 的标准形式
目标函数如下:
min
θ
1
2
∥
θ
∥
2
+
C
∑
i
=
1
m
cost
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
\min_{\theta} \frac{1}{2} \|\theta\|^2 + C \sum_{i=1}^{m} \text{cost}(h_\theta(x^{(i)}), y^{(i)})
θmin21∥θ∥2+Ci=1∑mcost(hθ(x(i)),y(i))
其中:
- ∣ ∣ θ ∥ 2 ||\theta\|^2 ∣∣θ∥2 控制模型复杂度(间隔)。
- C C C 控制对错误分类的惩罚程度。
- cost ( ⋅ ) \text{cost}(\cdot) cost(⋅) 是 hinge loss。
三、支持向量与最大间隔的直观理解
- 训练集中距离分类边界最近的点称为支持向量,它们决定了最终的分类超平面。
- 最大化间隔等价于最小化 ∣ ∣ θ ∥ 2 ||\theta\|^2 ∣∣θ∥2。
四、核函数(Kernel Function)
1、核函数的作用
- 核函数可将输入数据映射到更高维空间,在高维空间中实现线性可分。
- 避免显式计算高维特征,用核技巧计算内积。
2、常见核函数
-
线性核(Linear Kernel):
K ( x , z ) = x T z K(x, z) = x^T z K(x,z)=xTz -
多项式核(Polynomial Kernel):
K ( x , z ) = ( x T z + c ) d K(x, z) = (x^T z + c)^d K(x,z)=(xTz+c)d -
高斯核 / RBF(Radial Basis Function):
K ( x , z ) = exp ( − ∥ x − z ∥ 2 2 σ 2 ) K(x, z) = \exp\left(-\frac{\|x - z\|^2}{2\sigma^2}\right) K(x,z)=exp(−2σ2∥x−z∥2)
3、高斯核的参数选择
- σ(或 γ)控制分布宽度:
- σ 小 → 拟合更 “尖锐”,可能过拟合。
- σ 大 → 拟合更平滑,可能欠拟合。
五、SVM 的使用建议
1、特征缩放
- 特征归一化非常重要,尤其在使用核函数时,避免某些维度主导距离计算。
2、SVM 的优点
- 通常表现优于逻辑回归,尤其在特征维度高、样本数较少的场景。
- 在文本分类、图像识别中表现优异。
3、与其他模型的对比
| 特点 | 逻辑回归 | 支持向量机 |
|---|---|---|
| 分类边界 | 最大似然 | 最大间隔 |
| 可扩展到核函数 | 较难 | 支持各种核函数 |
| 参数解释性 | 较强 | 较弱 |
| 小样本泛化能力 | 一般 | 强 |
六、SVM 的训练与实现
1、训练库推荐
- 推荐使用现有库如:
- LIBSVM:C++ 实现,接口广泛。
- Scikit-learn 中的
sklearn.svm.SVC - MATLAB/Octave 中也有内建支持。
2、超参数调优建议
- 交叉验证选取最佳的:
- 惩罚参数 C。
- 核函数参数(如 σ)。