Android 的 Handler 机制 是 Android 应用中实现线程间通信、任务调度、消息分发的核心机制之一,它基于 消息队列(MessageQueue)+ 消息循环(Looper)+ 消息处理器(Handler) 组成。
1 handler的使用场景
| 功能类别 | 典型用途 | 使用方式 |
|---|---|---|
| 线程间通信 | 子线程通知主线程更新 UI | sendMessage() / post() |
| 延时任务 | 倒计时、延迟执行 | postDelayed() |
| 定时循环 | 动画帧刷新、轮播图切换 | postDelayed(Runnable) |
| 子线程任务管理 | 使用 HandlerThread 串行任务调度 | new Handler(looper) |
| 节流防抖 | 防止按钮重复点击、频繁操作 | removeCallbacks + postDelayed |
| 回主线程执行 | 框架内部切线程、UI 安全调用 | Handler(Looper.getMainLooper()) |
| 系统/组件内部通信机制 | ActivityThread、HandlerThread | 用于 Activity 启动/管理等 |
1.1 线程间通信(跨线程调度任务)
主线程不能执行耗时操作(如网络/IO),子线程完成后必须通知主线程更新 UI。由于只能主线程操作 UI,Handler 就是桥梁。
new Thread(() -> {
String data = getDataFromNetwork();
Message msg = Message.obtain();
msg.obj = data;
handler.sendMessage(msg); // 主线程 handler 处理
}).start();
这种情况子线程中无 Looper,只能用主线程的 Handler 来发送消息;消息进入主线程的 MessageQueue,由主线程 Looper 分发执行。
1.2 延时执行任务
需要在一定时间后再执行某个操作,比如自动关闭提示框、执行重试等。
handler.postDelayed(() -> {
// 执行延时任务
}, 3000); // 延时 3 秒
postDelayed() 本质是向 MessageQueue 中插入一个 when=now+delay 的 Message;
Looper 会按时间顺序读取,时间未到则继续等待。
1.3 循环/定时任务
用于实现定时器、动画帧刷新、轮播图等。
Runnable runnable = new Runnable() {
@Override
public void run() {
updateUI();
handler.postDelayed(this, 1000); // 每 1 秒执行一次
}
};
handler.post(runnable);
每次执行后重新 postDelayed 触发下一次;也可通过 handler.removeCallbacks(runnable) 停止循环。
1.4 子线程消息循环(HandlerThread)
希望在子线程中串行执行多个异步任务(如磁盘写入、数据库访问),使用 HandlerThread。
HandlerThread thread = new HandlerThread("Worker");
thread.start();
Handler workerHandler = new Handler(thread.getLooper());
workerHandler.post(() -> {
// 子线程中执行任务
});
HandlerThread 是自带 Looper 的子线程;
getLooper() 返回该线程的消息循环系统;
所有任务在这个线程的 MessageQueue 串行处理。
1.5 事件节流/防抖
控制按钮重复点击、频繁网络请求等行为(节流或防抖)。
handler.removeCallbacks(task);
handler.postDelayed(task, 300); // 最后一次触发后 300ms 执行
每次触发都取消上一次的 Runnable;
如果在 delay 时间内再次触发,就不断重置延迟;
适合处理频率敏感事件(如搜索框自动联想、滚动监听)。
1.6 主线程执行调度(Handler+Looper.getMainLooper())
某些非 UI 线程中又需要确保在主线程执行一段逻辑时(比如框架层调用 UI 回调)。
Handler mainHandler = new Handler(Looper.getMainLooper());
mainHandler.post(() -> {
// 保证在主线程中执行
});
使用主线程的 Looper;
保证 UI 相关代码运行在主线程,避免异常和崩溃。
1.7 框架内部通信封装(如 Retrofit/OkHttp 回调)
很多第三方库为了线程安全,使用 Handler 将回调切换回主线程。
Platform.get().callbackExecutor().execute(() -> {
handler.post(() -> callback.onSuccess(result));
});
2 Handler 消息机制全流程(按时间线)
handler机制可以用于两个线程的通讯,也可以用作单线程内部使用。为了方便理解,下面以线程A和线程B为例,进行推演。
下面是一个常规操作,子线程B执行下载文件,下载完毕通知主线程A。
2.1 线程初始化Lopper
Looper.prepare(); // 为当前线程(主线程A)创建 MessageQueue 和 Looper
主线程A执行prepare, 那么MessageQueue 和 Looper在主线程A。主线程默认带有Looper,这里只是为了理解写的代码。
2.2 创建 Handler 实例(并与 Looper 绑定)
Handler mainHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
// 处理消息逻辑
}
};
主线程A创建一个mainHandler 。
2.3 发送消息
Message msg = handler.obtainMessage(1, "data");
mainHandler .sendMessage(msg); // 消息加入 MessageQueue
子线程B把文件下载完了,通过子线程B的
2.4 启动消息循环
Looper.loop(); // 开始无限循环,从 MessageQueue 取出消息
主线程的Looper在无线循环,拿到了子线程通过mainHandler发送过来的消息。
2.5 Looper 取出消息并调用目标 Handler 处理
mainHandler.dispatchMessage(msg); → mainHandler.handleMessage(msg)
主线程处理了子线程的消息。
2.6 完整例子
public class MainActivity extends AppCompatActivity {
// 创建主线程 Handler
private Handler mainHandler = new Handler(Looper.getMainLooper()) {
@Override
public void handleMessage(Message msg) {
// 接收到子线程传来的消息
String result = (String) msg.obj;
Log.d("MainHandler", "收到任务完成通知:" + result);
// 这里可以更新 UI,比如:
// textView.setText(result);
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// 启动子线程执行耗时任务
new Thread(() -> {
Log.d("WorkerThread", "开始耗时任务");
// 模拟耗时操作(比如网络请求)
try {
Thread.sleep(2000); // 2 秒耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
String result = "任务完成,结果为:42";
// 向主线程发送消息
Message msg = Message.obtain();
msg.obj = result;
mainHandler.sendMessage(msg);
}).start();
}
}
通常有以下两种方式传递消息,根据不同场景选取。
| 用法 | 特点 |
|---|---|
sendMessage() + handleMessage() | 适合复杂消息传递,带参数 |
post(Runnable) | 简洁、直接执行主线程逻辑 |
3 handler底层数据结果的关系

3.1 MessageQueue 工作机制
是一个时间排序的单向链表,每个 Message 有 when 字段(何时处理)。
插入消息时按 when 排序插入。
next() 方法通过 epoll() 或 nativePollOnce() 在等待消息。
这里可以引申出epoll和nativePollOnce的概念。
3.1.1 epoll
epoll() 是 Linux 提供的 高性能 I/O 多路复用机制。
它的作用是阻塞等待文件描述符(FD)上有事件发生,比如网络数据、管道、匿名 fd、有输入等,它是 select/poll 的高效替代,适合大规模并发事件等待场景。
3.1.2 nativePollOnce
nativePollOnce() 是 Android native 层封装的 epoll 封装,在 MessageQueue 的 native 实现中(android_os_MessageQueue.cpp),会通过 Looper::pollOnce() 调用 epoll_wait() 封装函数。
//这个调用就是 在 native 层阻塞等待是否有新的消息需要处理。
int Looper::pollOnce(int timeoutMillis, ...) {
return epoll_wait(epoll_fd, events, maxEvents, timeoutMillis);
}
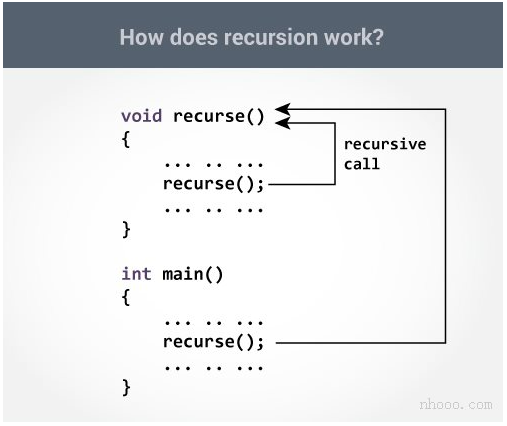
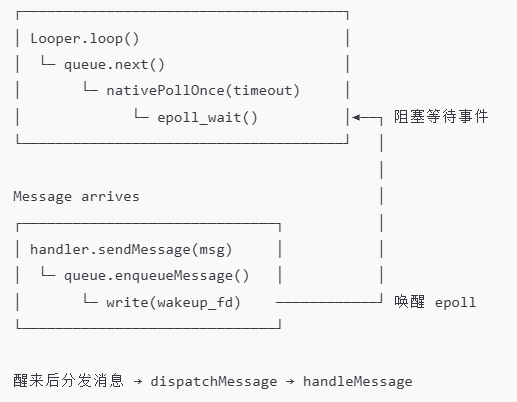
3.1.3 为什么 Looper.loop() 是死循环但不会卡死?
for (;;) {
Message msg = queue.next(); // 这一步是“阻塞等待”
msg.target.dispatchMessage(msg); // 派发给 Handler
}
queue.next() 其实最终会调用到 native 的 nativePollOnce(timeout)
当没有消息可处理时,会阻塞在 epoll 上:
epoll_wait(...) // nativePollOnce 里核心操作
关键点:阻塞不是“卡死”,而是高效等待。
CPU 不做无意义运算,也不 busy-loop(不会疯狂循环空转),
而是 挂起线程直到有事件到来,这就是 epoll 的魅力。
3.1.4 事件是怎么唤醒的?为什么能收到消息?
Handler 发消息过程:
你在 Java 层调用 handler.sendMessage(),消息被插入 MessageQueue,如果 Looper 正在 epoll_wait 阻塞,它会被唤醒。
唤醒原理是,MessageQueue 中有一个 “wakeup pipe”。插入消息时,向管道写入一个字节,epoll 监听管道,立刻从阻塞中醒来,处理消息!epoll + pipe 配合,让死循环变成“事件驱动”。
Q&A
一个线程可以有多少个messagequeue?
不能,最多只能有一个
一个线程可以有多少个handler?
是的,可以有。
| 问题 | 答案 |
|---|---|
| 一个线程能有多少个 Handler? | 没有限制,可以有很多个 |
| 它们之间共享什么? | 共享同一个 Looper 和 MessageQueue |
| 各个 Handler 的职责? | 每个 Handler 处理自己的消息,逻辑可以分开组织 |
为什么需要多个handler呢,一个是可以做到逻辑拆分,这个好理解。
另外一个是可以做到不同的延时和优先级策略,比如说:
handlerA.sendMessageDelayed(…)
handlerB.postAtTime(…)
这两个函数都会被加入同一个 MessageQueue,但根据时间排序执行。
需要注意的是。
| 项 | 说明 |
|---|---|
| 一个线程只能有一个 Looper | 否则 Looper.prepare() 会抛异常 |
| Handler 必须绑定 Looper | 默认绑定当前线程的 Looper |
| 线程没 Looper 时创建 Handler 会报错 | ❌ 需先调用 Looper.prepare() |
一个线程可以有多少个Looper?
不能。
假如有A和B通讯,执行A线程的handler.post(),那么逻辑在哪里执行?
调用 A线程 中的 Handler 的 post(),Runnable 中的逻辑一定会在 A 线程中执行。

handler.post()这个函数的执行,背后发生了什么?
handler.post(runnable) 背后会把 Runnable 包装成 Message,插入到 MessageQueue,由绑定的 Looper 线程轮询取出并调用 Runnable.run()。

handler发送消息到messagequeue,Looper从messagequeue取消息,取到的消息去到哪里了?
取到的消息会被传给 msg.target.dispatchMessage(msg),也就是消息所属的 Handler 处理。最终:
- 如果是
handler.post(runnable):执行的是runnable.run() - 如果是
handler.sendMessage(msg):执行的是handler.handleMessage(msg)
所以Looper 取出的消息,会被交给它对应的 Handler 处理。
I/O 多路复用机制怎么理解?
传统阻塞式 I/O 有个问题:
每次 read() 或 recv() 调用都会 阻塞当前线程,直到数据到来。
如果你要同时监听 100 个 socket,就得起 100 个线程或写 100 次轮询代码,很低效。
I/O 多路复用就是用一个线程(或很少线程)高效处理多个连接的状态变化,避免大量线程阻塞、切换。
下面是常见的多路复用系统调用。
| 方法 | 描述 | 效率 | 主要平台 |
|---|---|---|---|
select() | 最早的方式,基于 FD 数组 | 差(每次都遍历全部) | UNIX/Linux |
poll() | 改进版,基于 FD 列表 | 中等 | UNIX/Linux |
epoll() | 高效事件驱动,使用内核数据结构 | 高 | Linux |
kqueue | 类似 epoll,用于 BSD/macOS | 高 | BSD/macOS |
IOCP | Windows 的完成端口机制 | 高 | Windows |
epoll的工作路程大致是这样的。
- 注册关注的 I/O 事件(比如某 socket 可读)
epoll_ctl(epfd, EPOLL_CTL_ADD, sockfd, &event);
- 阻塞等待事件触发(所有监听的 fd 中,哪个变了?)
epoll_wait(epfd, events, MAX_EVENTS, timeout);
- 事件来了后再去读/写
read(events[i].fd, buf, len);
它不会遍历全部 FD,只关注“谁发生了事件”。由内核来辅助管理事件队列,可处理成千上万个连接(用于高并发服务器)。
下面来个比较好理解的类比。
| 模型 | 行为 |
|---|---|
| 阻塞 I/O | 每个顾客分一个服务员,服务员只能盯着一个人(低效) |
| 非阻塞轮询 | 一个服务员轮流问每个顾客“你吃好了吗?”(忙碌) |
| 多路复用 | 一个服务员装了对讲机,顾客吃好了主动通知他(高效) |
持续更新中。。。