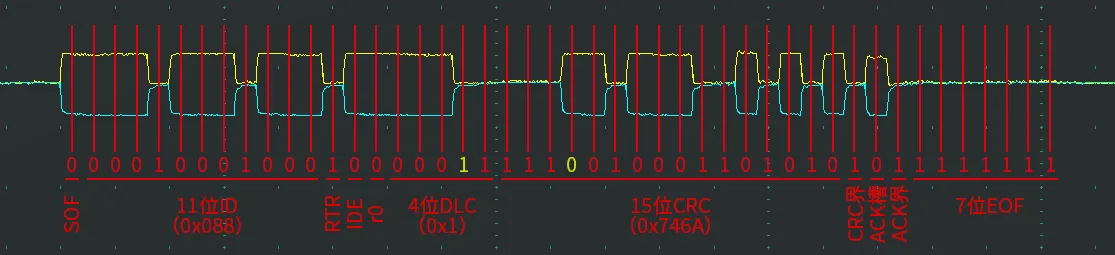
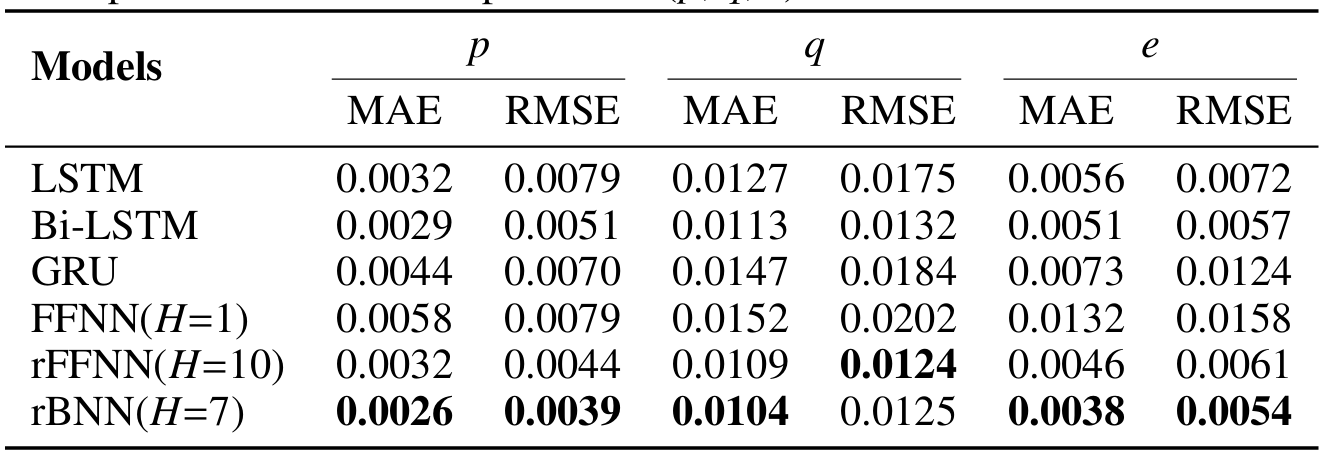
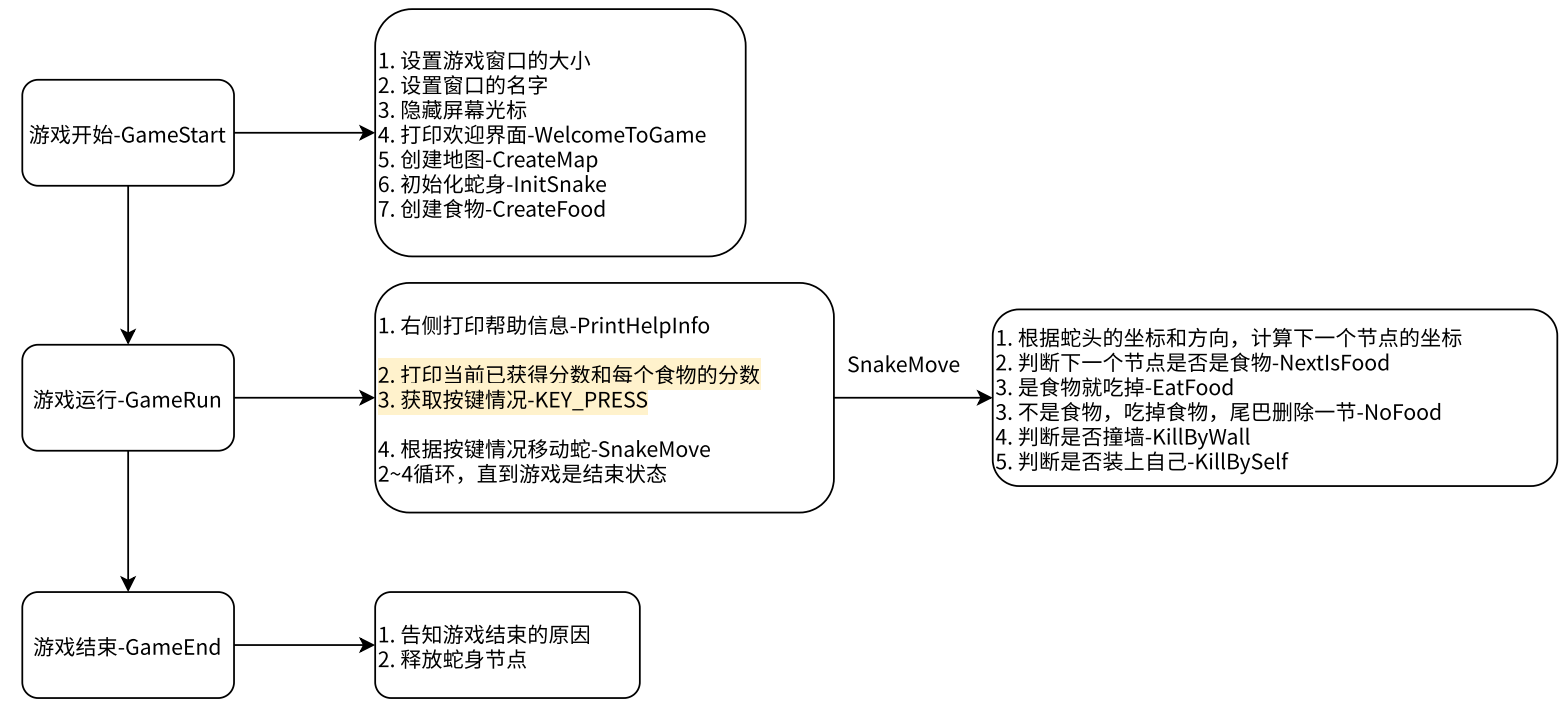
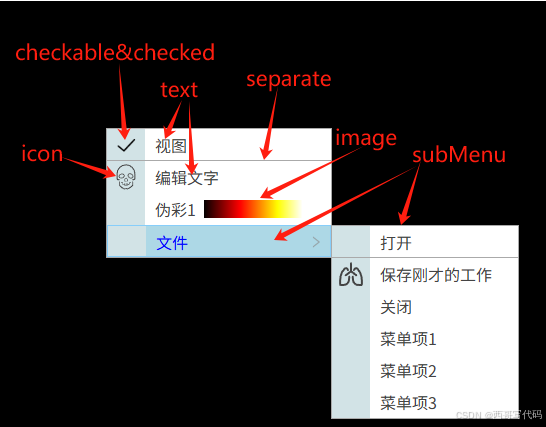
前言
最近想开一个关于强化学习专栏,因为DeepSeek-R1很火,但本人对于LLM连门都没入。因此,只是记录一些类似的读书笔记,内容不深,大多数只是一些概念的东西,数学公式也不会太多,还望读者多多指教。本次阅读书籍为:马克西姆的《深度强化学习实践》。
限于篇幅原因,请读者首先看下历史文章:
马尔科夫过程
马尔科夫奖励过程
马尔科夫奖励过程二
RL框架Gym简介
本篇继续介绍:openai的RL开源框架Gym。在介绍之前,先来玩一个经典游戏。
1、CartPole游戏介绍

如下图所示:CartPole游戏就是平衡木游戏:游戏中,智能体需要控制左或者右动作来维持平衡,当然,这个环境的观察是4个浮点数,包含了木棒质点的x坐标、速度、与平台的角度以及角速度的信息。
由于目前还没有学习到RL算法,因此,本文首先借助Gym实现一个随机智能体。
2、代码
import gym
if __name__ == "__main__":
env = gym.make("CartPole-v0")
total_reward = 0.0
total_steps = 0
obs = env.reset()
while True:
action = env.action_space.sample()
obs, reward, done, _ = env.step(action)
total_reward += reward
total_steps += 1
if done:
break
print("Episode done in %d steps, total reward %.2f" % (total_steps, total_reward))
这个代码是一个随机的智能体,即没有任何的学习策略,每次都是随机选择向左或者向右移动。同时每次调用env.step会返回当前的观察、奖励以及游戏是否结束(木棍倒了)。之后在累加奖励和步长。如果游戏结束,则跳出循环。
可以看出,这个智能体是没有任务策略,而且也没有用到观察、以及奖励作为反馈。如果你运行代码:大概得到以下结果:

从上述结果可以看出:当执行到13步时候游戏结束,且最终返回的总奖励为13。当然这个结果很差,但这只是个随机智能体版本,后续会借助RL算法来不断优化性能,使其坚持的步骤更多。
总结
本篇只是用gym实现了一个简单的CartPole智能体,无须担心,后面博客会介绍用其余RL算法来逐渐改进这个智能体。