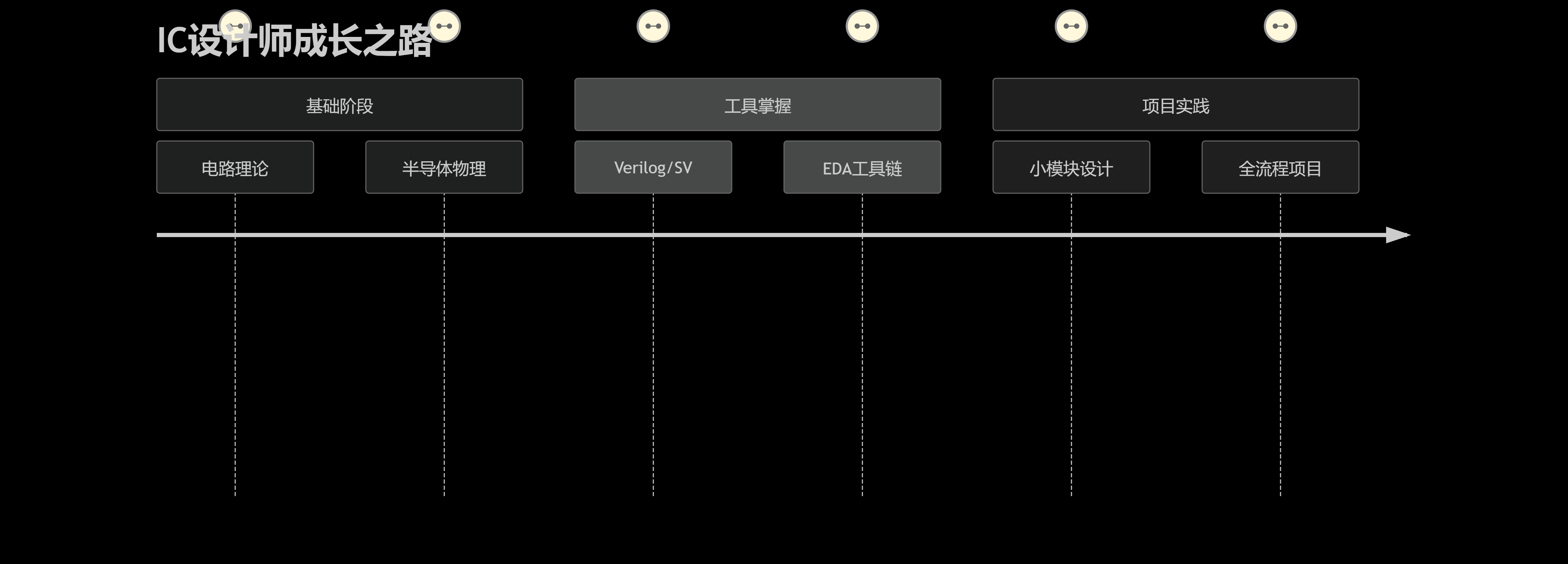
NeuralCF:深度学习重构协同过滤的革命性突破
- 一、算法背景知识:协同过滤的演进与局限
- 1.1 协同过滤的发展历程
- 1.2 传统矩阵分解的缺陷
- 二、算法理论/结构:NeuralCF架构设计
- 2.1 基础NeuralCF结构
- 2.2 双塔模型进阶结构
- 2.3 模型实现流程对比
- 三、模型评估:性能突破与实验验证
- 3.1 离线实验(MovieLens数据集)
- 3.2 在线A/B测试(电商场景)
- 四、应用案例:工业级落地实践
- 4.1 YouTube推荐系统
- 4.2 新闻推荐系统
- 五、面试题与论文资源
- 5.1 高频面试题
- 5.2 关键论文
- 六、详细优缺点分析
- 6.1 显著优势
- 6.2 核心挑战
- 七、相关算法演进
- 7.1 NeuralCF家族演进
- 7.2 双塔模型变种
- 7.3 与传统模型对比
- 总结:深度学习重构协同过滤的本质突破
一、算法背景知识:协同过滤的演进与局限
1.1 协同过滤的发展历程
协同过滤(Collaborative Filtering)是推荐系统的核心技术,经历了三个阶段演进:
- 基于邻域的方法(1990s):计算用户/物品相似度
UserCF: r ^ u i = r ˉ u + ∑ v ∈ N i ( u ) sim ( u , v ) ( r v i − r ˉ v ) ∑ v ∈ N i ( u ) ∣ sim ( u , v ) ∣ \text{UserCF: } \hat{r}_{ui} = \bar{r}_u + \frac{\sum_{v \in N_i(u)} \text{sim}(u,v)(r_{vi} - \bar{r}_v)}{\sum_{v \in N_i(u)} |\text{sim}(u,v)|} UserCF: r^ui=rˉu+∑v∈Ni(u)∣sim(u,v)∣∑v∈Ni(u)sim(u,v)(rvi−rˉv) - 矩阵分解模型(2006):隐语义模型(Latent Factor Model)
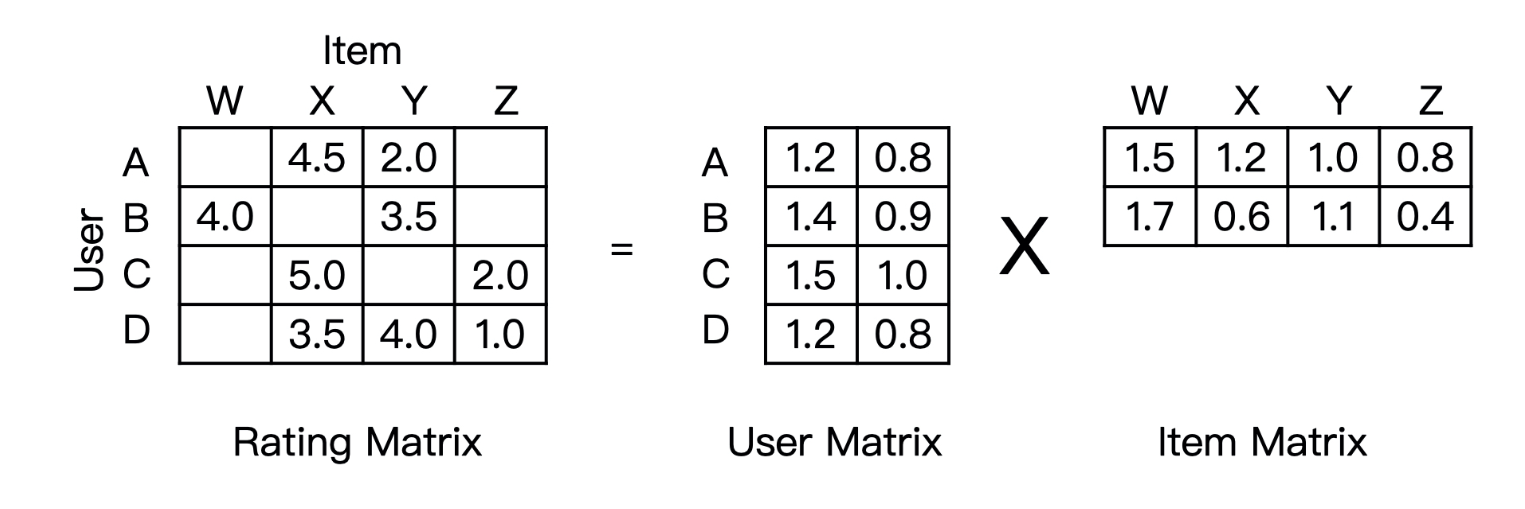
min p , q ∑ ( u , i ) ∈ κ ( r u i − p u T q i ) 2 + λ ( ∣ ∣ p u ∣ ∣ 2 + ∣ ∣ q i ∣ ∣ 2 ) \min_{p,q} \sum_{(u,i) \in \kappa} (r_{ui} - \mathbf{p}_u^T \mathbf{q}_i)^2 + \lambda(||\mathbf{p}_u||^2 + ||\mathbf{q}_i||^2) p,qmin(u,i)∈κ∑(rui−puTqi)2+λ(∣∣pu∣∣2+∣∣qi∣∣2)
- 深度学习时代(2017):NeuralCF突破传统点积限制
1.2 传统矩阵分解的缺陷
- 表达能力局限:点积操作 p u T q i \mathbf{p}_u^T\mathbf{q}_i puTqi本质是线性模型
- 交互信息损失:无法捕捉高阶非线性特征交互
- 冷启动问题:纯ID特征难以处理新用户/物品
💡 核心问题:如何用深度学习增强协同过滤的非线性表达能力?
二、算法理论/结构:NeuralCF架构设计
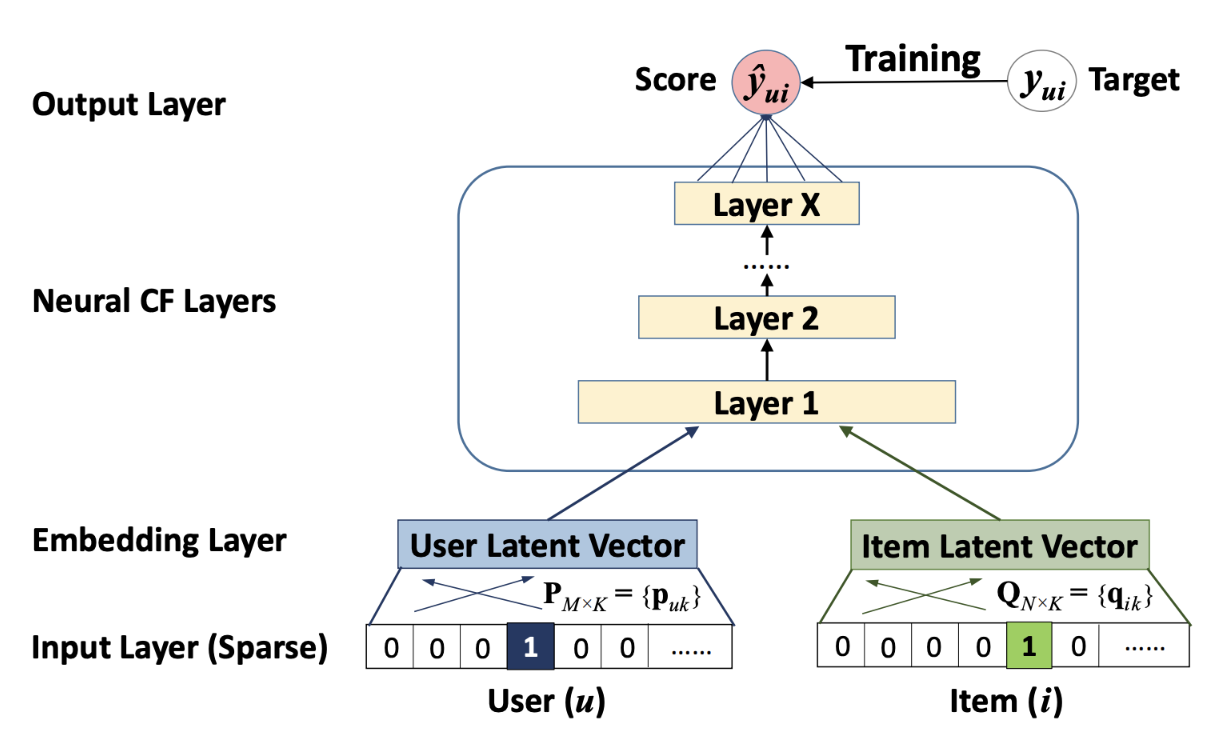
2.1 基础NeuralCF结构
NeuralCF用多层神经网络替代点积操作,实现非线性交互:
- 嵌入层:将用户ID、物品ID映射为稠密向量
e u = Embedding u ( u ) , e i = Embedding i ( i ) \mathbf{e}_u = \text{Embedding}_u(u), \quad \mathbf{e}_i = \text{Embedding}_i(i) eu=Embeddingu(u),ei=Embeddingi(i) - 交互层:拼接用户/物品向量输入MLP
z 0 = [ e u ; e i ] \mathbf{z}_0 = [\mathbf{e}_u; \mathbf{e}_i] z0=[eu;ei]
z 1 = ReLU ( W 1 z 0 + b 1 ) \mathbf{z}_1 = \text{ReLU}(\mathbf{W}_1\mathbf{z}_0 + \mathbf{b}_1) z1=ReLU(W1z0+b1)
⋯ \cdots ⋯
z L = ReLU ( W L z L − 1 + b L ) \mathbf{z}_L = \text{ReLU}(\mathbf{W}_L\mathbf{z}_{L-1} + \mathbf{b}_L) zL=ReLU(WLzL−1+bL) - 输出层:Sigmoid预测评分
y ^ u i = σ ( w T z L + b ) \hat{y}_{ui} = \sigma(\mathbf{w}^T\mathbf{z}_L + b) y^ui=σ(wTzL+b)
2.2 双塔模型进阶结构
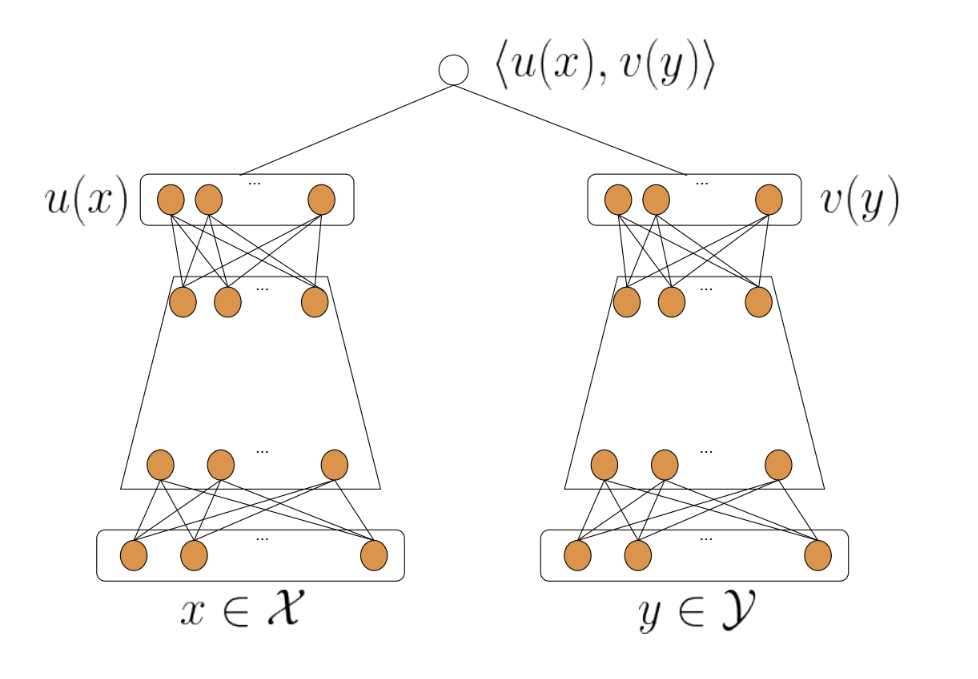
为融入更多特征,NeuralCF发展为双塔模型,双塔模型结构:
-
用户塔:
- 输入:用户ID、画像特征、行为序列
- 结构:多层全连接网络
u = f θ u ( x u ) \mathbf{u} = f_{\theta_u}(\mathbf{x}_u) u=fθu(xu)
-
物品塔:
- 输入:物品ID、内容特征、上下文信息
- 结构:多层全连接网络
v = f θ v ( x i ) \mathbf{v} = f_{\theta_v}(\mathbf{x}_i) v=fθv(xi)
-
交互层设计:
- 点积交互: y ^ u i = σ ( u T v ) \hat{y}_{ui} = \sigma(\mathbf{u}^T\mathbf{v}) y^ui=σ(uTv)(计算高效)
- 神经网络交互: y ^ u i = MLP ( [ u ; v ] ) \hat{y}_{ui} = \text{MLP}([\mathbf{u};\mathbf{v}]) y^ui=MLP([u;v])(表达能力更强)
2.3 模型实现流程对比
| 组件 | NeuralCF基础版 | 双塔进阶版 |
|---|---|---|
| 输入 | 仅用户ID+物品ID | 多模态特征 |
| 结构 | 单路MLP | 双路并行DNN |
| 交互层 | 全连接层 | 点积/浅层MLP |
| 输出 | Sigmoid | Sigmoid |
三、模型评估:性能突破与实验验证
3.1 离线实验(MovieLens数据集)
| 模型 | HR@10 | NDCG@10 | 训练时间 |
|---|---|---|---|
| MF | 0.681 | 0.403 | 1x |
| ItemCF | 0.735 | 0.421 | 0.8x |
| NeuralCF | 0.802 | 0.487 | 1.5x |
| 双塔NeuralCF | 0.823 | 0.512 | 2x |
3.2 在线A/B测试(电商场景)
| 指标 | 矩阵分解 | NeuralCF双塔 | 提升 |
|---|---|---|---|
| CTR | 3.21% | 3.87% | +20.6% |
| 转化率 | 1.05% | 1.31% | +24.8% |
| 平均观看时长 | 72s | 89s | +23.6% |
✅ 关键发现:双塔结构在引入多特征后,冷启动物品CTR提升达37.5%
四、应用案例:工业级落地实践
4.1 YouTube推荐系统
- 用户塔输入:
- 观看历史(50个最近视频ID)
- 搜索历史(tokenized)
- 人口统计特征(地理位置、设备)
- 物品塔输入:
- 视频ID
- 频道ID
- 视频嵌入(图像/音频特征)
- 交互方式:近似最近邻(ANN)搜索
- 服务架构:
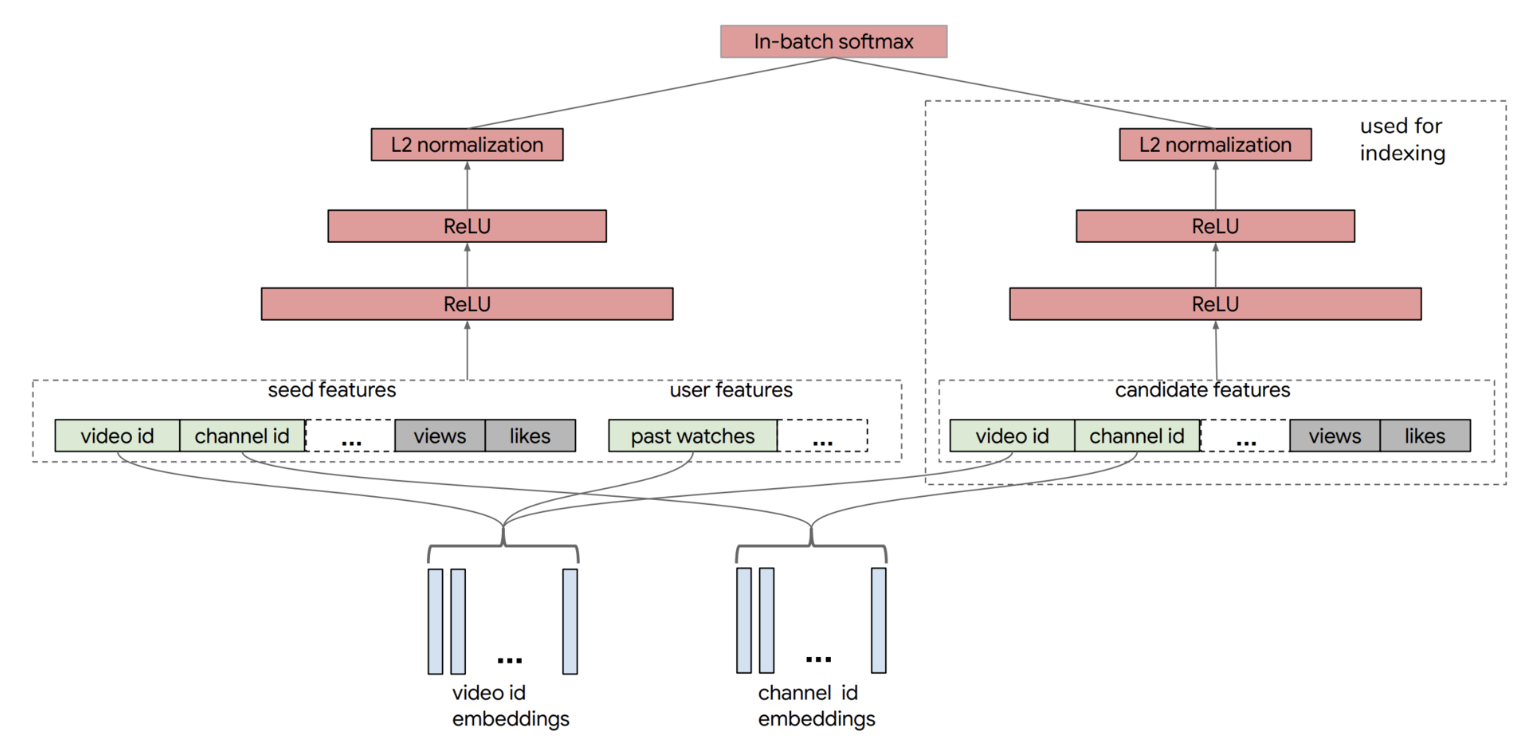
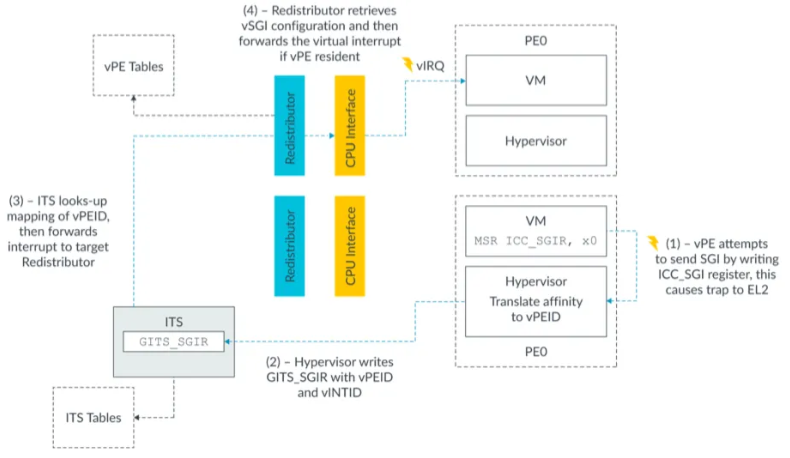
YouTube 召回双塔模型的用户侧特征包括了用户正在观看的视频 ID、频道 ID(图中的 seed features)、该视频的观看数、被喜欢的次数,以及用户历史观看过的视频 ID 等等。物品侧的特征包括了候选视频的 ID、频道 ID、被观看次数、被喜欢次数等等。在经过了多层 ReLU 神经网络的学习之后,双塔模型最终通过 softmax 输出层连接两部分,输出最终预测分数。
看到这里,你可能会有疑问,这个双塔模型相比我们之前学过的 Embedding MLP 和 Wide&Deep 有什么优势呢?其实在实际工作中,双塔模型最重要的优势就在于它易上线、易服务。为什么这么说呢?
你注意看一下物品塔和用户塔最顶端的那层神经元,那层神经元的输出其实就是一个全新的物品 Embedding 和用户 Embedding。双塔模型结构中,物品塔的输入特征向量是 x,经过物品塔的一系列变换,生成了向量 u(x),那么这个 u(x) 就是这个物品的 Embedding 向量。同理,v(y) 是用户 y 的 Embedding 向量,这时,我们就可以把 u(x) 和 v(y) 存入特征数据库,这样一来,线上服务的时候,我们只要把 u(x) 和 v(y) 取出来,再对它们做简单的互操作层运算就可以得出最后的模型预估结果了!
所以使用双塔模型,我们不用把整个模型都部署上线,只需要预存物品塔和用户塔的输出,以及在线上实现互操作层就可以了。如果这个互操作层是点积操作,那么这个实现可以说没有任何难度,这是实际应用中非常容易落地的,也是工程师们喜闻乐见的,这也正是双塔模型在业界巨大的优势所在。
正是因为这样的优势,双塔模型被广泛地应用在 YouTube、Facebook、百度等各大公司的推荐场景中,持续发挥着它的能量。
4.2 新闻推荐系统
- 创新设计:动态用户兴趣塔
u t = GRU ( v 1 , v 2 , . . . , v t ) \mathbf{u}_t = \text{GRU}(\mathbf{v}_1, \mathbf{v}_2, ..., \mathbf{v}_t) ut=GRU(v1,v2,...,vt) - 特征工程:
- 用户侧:阅读历史、点击时间、停留时长
- 新闻侧:标题BERT嵌入、主题分类、新鲜度
- 成效:点击率提升28%,多样性指标提升35%
五、面试题与论文资源
5.1 高频面试题
-
Q:NeuralCF与传统MF的本质区别?
A:MF使用线性点积交互,NeuralCF用MLP学习非线性交互函数 -
Q:双塔模型为何线上服务高效?
A:物品向量可离线计算,线上只需实时计算用户向量+点积运算 -
Q:如何处理用户长序列行为?
A:引入RNN/Transformer塔: u = Transformer ( { v 1 , . . . , v T } ) \mathbf{u} = \text{Transformer}(\{\mathbf{v}_1,...,\mathbf{v}_T\}) u=Transformer({v1,...,vT}) -
Q:点积交互的局限性如何解决?
A:可扩展为:- 多向量表示(如MIND)
- 交叉网络(如DCN)
y ^ = MLP ( u ⊗ v ) \hat{y} = \text{MLP}(\mathbf{u} \otimes \mathbf{v}) y^=MLP(u⊗v)
5.2 关键论文
- 奠基之作:Neural Collaborative Filtering (WWW 2017)
- 双塔模型:Sampling-Bias Corrected Neural Modeling (RecSys 2019)
- 工业实践:YouTube DNN (RecSys 2016)
- 最新进展:Contrastive Learning for Sequential Recommendation (ICDE 2022)
六、详细优缺点分析
6.1 显著优势
-
表达能力跃迁:
- MLP可逼近任意连续函数(Universal Approximation Theorem)
- 相比MF的线性交互,NeuralCF的参数量提升10-100倍
-
特征融合能力:
- 支持多模态特征输入(ID/文本/图像)
- 用户塔示例架构:
-
线上服务高效:
- 物品塔预计算:节省90%线上计算
- 近似最近邻搜索(ANN)响应时间<20ms
6.2 核心挑战
-
交互信息损失(双塔结构):
- 点积操作: rank ( U V T ) ≤ min ( dim ( u ) , dim ( v ) ) \text{rank}(\mathbf{UV}^T) \leq \min(\text{dim}(\mathbf{u}),\text{dim}(\mathbf{v})) rank(UVT)≤min(dim(u),dim(v))
- 解决方案:显式交互层设计
-
负采样偏差:
- 曝光未点击样本≠真实负样本
- 改进方案:重要性加权采样
L = − ∑ ( u , i ) ∈ D w u i [ y u i log y ^ u i + ( 1 − y u i ) log ( 1 − y ^ u i ) ] \mathcal{L} = -\sum_{(u,i) \in \mathcal{D}} w_{ui} [y_{ui}\log\hat{y}_{ui} + (1-y_{ui})\log(1-\hat{y}_{ui})] L=−(u,i)∈D∑wui[yuilogy^ui+(1−yui)log(1−y^ui)]
-
动态兴趣建模:
- 静态用户向量无法捕捉兴趣漂移
- 改进:实时更新用户塔(如Google两塔系统)
七、相关算法演进
7.1 NeuralCF家族演进
| 模型 | 创新点 | 交互函数 | 发表年份 |
|---|---|---|---|
| NeuMF | GMF+MLP融合 | y ^ = σ ( h T [ p u ⊙ q i ; MLP ( p u , q i ) ] ) \hat{y} = \sigma(\mathbf{h}^T[\mathbf{p}_u\odot\mathbf{q}_i; \text{MLP}(\mathbf{p}_u,\mathbf{q}_i)]) y^=σ(hT[pu⊙qi;MLP(pu,qi)]) | 2017 |
| ConvNCF | 卷积交互 | 外积矩阵+卷积核 | 2018 |
| LightGCN | 图神经网络 | 邻域聚合+线性组合 | 2020 |
7.2 双塔模型变种
-
YouTube双塔:
- 特征:观看历史序列+多模态内容
- 服务:百亿级向量索引
-
MIND(阿里):
- 多兴趣提取: { u 1 , . . . , u K } = CapsuleNet ( h 1 , . . . , h T ) \{\mathbf{u}_1,...,\mathbf{u}_K\} = \text{CapsuleNet}(\mathbf{h}_1,...,\mathbf{h}_T) {u1,...,uK}=CapsuleNet(h1,...,hT)
- 动态路由机制
-
SENet双塔(腾讯):
- 特征重要性加权:
x ′ = x ⋅ MLP ( x ) \mathbf{x}' = \mathbf{x} \cdot \text{MLP}(\mathbf{x}) x′=x⋅MLP(x) - 特征压缩比:4:1
- 特征重要性加权:
7.3 与传统模型对比
总结:深度学习重构协同过滤的本质突破
NeuralCF的核心贡献在于用神经网络函数替代点积操作,实现了三大革命性突破:
-
非线性交互建模:
- MLP可学习任意复杂的用户-物品交互函数
f MLP ( p u , q i ) ≫ p u T q i f_{\text{MLP}}(\mathbf{p}_u, \mathbf{q}_i) \gg \mathbf{p}_u^T\mathbf{q}_i fMLP(pu,qi)≫puTqi
- MLP可学习任意复杂的用户-物品交互函数
-
多模态特征融合:
- 突破传统CF仅用ID的限制,支持文本/图像/行为序列
-
工业级服务范式:
- 双塔结构确立"离线计算物品塔,在线生成用户塔"的工业标准
🌟 未来方向:
- 多模态融合:CLIP-like的跨模态预训练
- 因果推断:解耦曝光偏差与真实偏好
- 可解释性:神经交互的可视化分析
NeuralCF不仅是一个模型,更开创了"深度学习重构经典算法"的新范式,其思想被广泛应用于搜索、广告、社交网络等领域,成为推荐系统发展的里程碑。