文章目录
- Go2机器人训练流程详细分析
- 概述
- 1. 训练启动流程
- 1.1 命令行参数解析
- RSL-RL相关参数组
- Isaac Sim应用启动参数组
- 1.2 RL配置
- 1.3 Isaac Sim启动
- 2. 环境配置加载
- 2.1 Hydra配置系统
- 3. 环境创建与初始化
- 3.1 Gym环境创建
- 3.2 Manager系统初始化
- 3.2.1 ObservationManager
- 3.2.2 ActionManager
- 3.2.3 RewardManager
- 3.2.4 TerminationManager
- 3.2.5 EventManager
- 3.2.6 CommandManager
- 4. 训练循环
- 4.1 RSL-RL包装器
- 4.2 训练器初始化
- 4.3 训练主循环
- 4.3.1 数据收集阶段(Rollout Phase)
- 4.3.2 优势函数计算(GAE - Generalized Advantage Estimation)
- 4.3.3 网络更新阶段(Policy Update Phase)
- 4.3.4 PPO损失函数详细实现
- 4.3.5 神经网络架构
- 4.3.6 学习率调度
- 4.3.7 训练监控和日志
- 4.3.8 完整训练循环
- 5. 仿真步骤详细流程
- 5.1 单步仿真流程
- 6 训练监控与日志
- 6.1 日志系统
- 6.2 监控指标
- 6. 总结
Go2机器人训练流程详细分析
概述
本文档详细分析了使用命令 python scripts/rsl_rl/base/train.py --task RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0 --headless 训练Go2机器人的完整流程,包括底层实现细节、MDP组件的使用以及Manager系统的工作原理。
1. 训练启动流程
1.1 命令行参数解析
# 在 train.py 中
parser = argparse.ArgumentParser(description="Train an RL agent with RSL-RL.")
parser.add_argument("--task", type=str, default=None, help="Name of the task.")
# 其他参数...
cli_args.add_rsl_rl_args(parser) # 添加RSL-RL特定参数
AppLauncher.add_app_launcher_args(parser) # 添加Isaac Sim启动参数
RSL-RL相关参数组
--experiment_name # 实验文件夹名称,日志将存储在此处
--run_name # 运行名称后缀,添加到日志目录
--resume # 是否从检查点恢复训练
--load_run # 要恢复的运行文件夹名称
--checkpoint # 要恢复的检查点文件
--logger # 日志记录模块 (wandb, tensorboard, neptune)
--log_project_name # 使用wandb或neptune时的项目名称
Isaac Sim应用启动参数组
--headless # 强制无头模式运行(无GUI)
--livestream # 启用直播流 (0:禁用, 1:原生[已弃用], 2:WebRTC)
--enable_cameras # 启用相机传感器和相关扩展依赖
--xr # 启用XR模式用于VR/AR应用
--device # 仿真运行设备 ("cpu", "cuda", "cuda:N")
--verbose # 启用详细级别的日志输出
--info # 启用信息级别的日志输出
--experience # 启动时加载的体验文件
--rendering_mode # 渲染模式 ("performance", "balanced", "quality", "xr")
--kit_args # 直接传递给Omniverse Kit的命令行参数
关键参数处理:
--task RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0: 指定训练任务--headless: 无头模式运行,不显示GUI--num_envs: 并行环境数量(默认4096)--max_iterations: 最大训练迭代次数
1.2 RL配置
import gymnasium as gym # 强化学习环境标准接口
import os # 文件路径操作
import torch # PyTorch 深度学习框架
from datetime import datetime # 时间戳生成
from rsl_rl.runners import OnPolicyRunner # RSL-RL 的策略梯度算法实现
from isaaclab.envs import (
DirectMARLEnv, # 多智能体直接控制环境
DirectMARLEnvCfg, # 多智能体环境配置
DirectRLEnvCfg, # 单智能体直接控制环境配置
ManagerBasedRLEnvCfg, # 基于管理层的环境配置(复杂任务)
multi_agent_to_single_agent, # 多智能体转单智能体的工具函数
)
from isaaclab_rl.rsl_rl import (
RslRlOnPolicyRunnerCfg, # RSL-RL 训练器配置
RslRlVecEnvWrapper # 将环境包装为 RSL-RL 需要的矢量化格式
)
from isaaclab_tasks.utils import get_checkpoint_path # 加载模型检查点
from isaaclab_tasks.utils.hydra import hydra_task_config # Hydra 配置集成
import robot_lab.tasks # noqa: F401 # 注册机器人任务到 Gymnasium
from isaaclab.utils.dict import print_dict # 美观打印字典
from isaaclab.utils.io import dump_pickle, dump_yaml # 保存配置文件
torch.backends.cuda.matmul.allow_tf32 = True # 启用 TF32 加速矩阵运算
torch.backends.cudnn.allow_tf32 = True # 启用 cuDNN 的 TF32 支持
torch.backends.cudnn.deterministic = False # 禁用确定性算法(提升速度)
torch.backends.cudnn.benchmark = False # 禁用自动寻找最优卷积算法(避免波动)
OnPolicyRunner: 实现 PPO 等 on-policy 算法的训练流程(数据收集、策略更新、日志记录)。
1.3 Isaac Sim启动
app_launcher = AppLauncher(args_cli)
simulation_app = app_launcher.app
底层实现:
- 初始化Omniverse Kit应用
- 配置GPU设备和渲染设置
- 设置物理引擎参数(PhysX)
2. 环境配置加载
2.1 Hydra配置系统
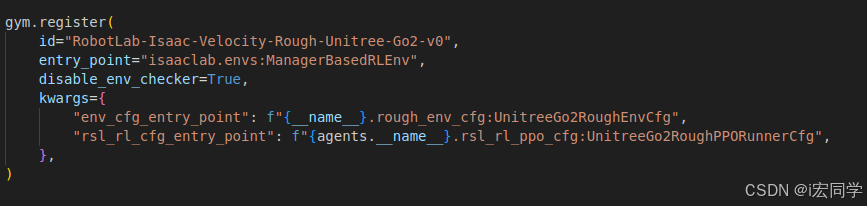
@hydra_task_config(args_cli.task, "rsl_rl_cfg_entry_point")
def main(env_cfg: ManagerBasedRLEnvCfg, agent_cfg: RslRlOnPolicyRunnerCfg):
配置加载过程:
-
根据任务名称
RobotLab-Isaac-Velocity-Rough-Unitree-Go2-v0查找对应配置
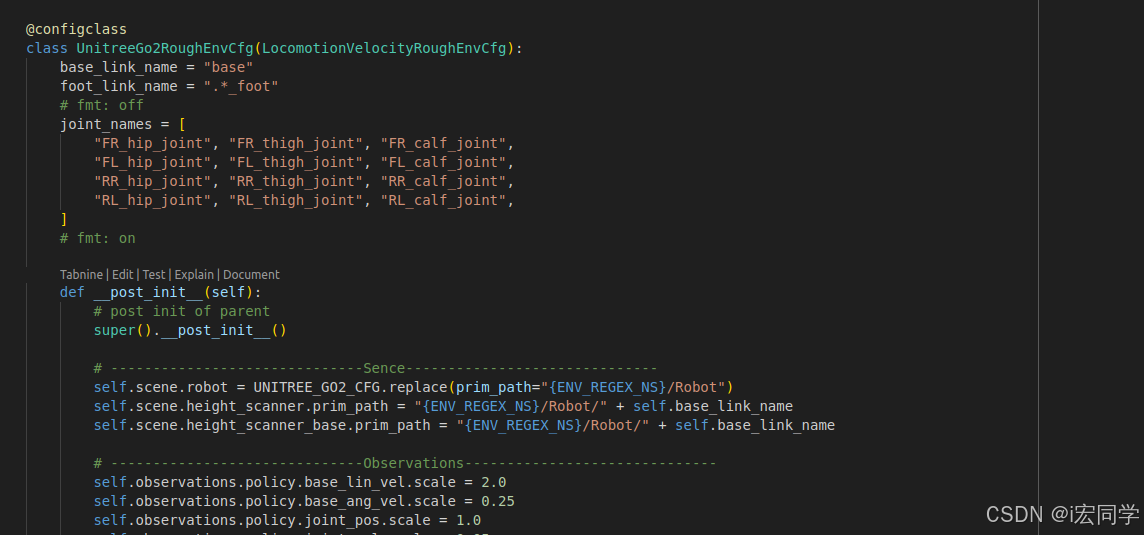
-
加载环境配置 (
UnitreeGo2RoughEnvCfg)
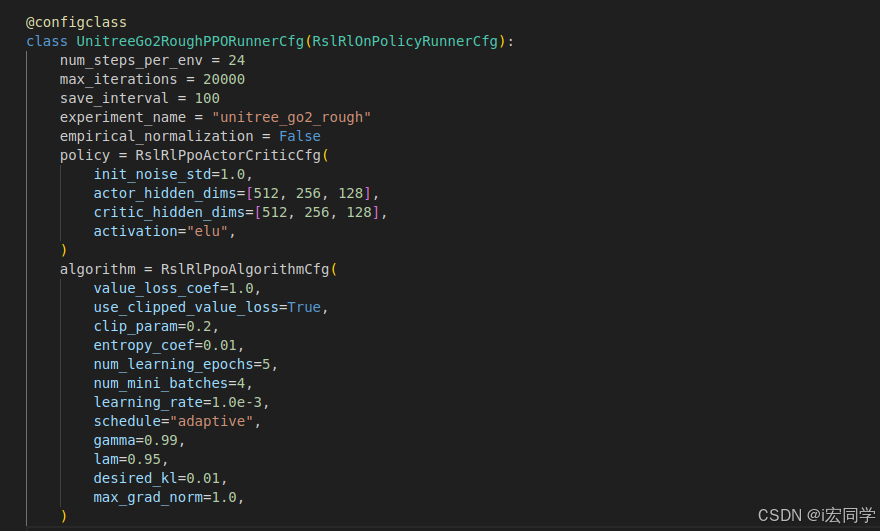
-
加载智能体配置 (
RslRlOnPolicyRunnerCfg)
3. 环境创建与初始化
3.1 Gym环境创建
env = gym.make(args_cli.task, cfg=env_cfg, render_mode="rgb_array" if args_cli.video else None)
底层创建过程:
-
场景初始化 (
MySceneCfg):- 地形生成(粗糙地形)
- 机器人模型加载(Go2 USD文件)
- 传感器配置(接触传感器、高度扫描器)
- 光照设置
-
物理世界设置:
- 重力设置
- 物理材料属性
- 碰撞检测配置
3.2 Manager系统初始化
环境使用ManagerBasedRLEnvCfg架构,包含以下Manager:
3.2.1 ObservationManager
@configclass
class ObservationsCfg:
@configclass
class PolicyCfg(ObsGroup):
# 基础运动状态观测
base_lin_vel = ObsTerm(func=mdp.base_lin_vel, scale=2.0, noise=UniformNoise(n_min=-0.1, n_max=0.1))
base_ang_vel = ObsTerm(func=mdp.base_ang_vel, scale=0.25, noise=UniformNoise(n_min=-0.2, n_max=0.2))
# 重力投影向量(用于姿态感知)
projected_gravity = ObsTerm(func=mdp.projected_gravity, noise=UniformNoise(n_min=-0.05, n_max=0.05))
# 速度命令(目标速度)
velocity_commands = ObsTerm(func=mdp.generated_commands)
# 关节状态观测
joint_pos = ObsTerm(
func=mdp.joint_pos_rel,
scale=1.0,
noise=UniformNoise(n_min=-0.01, n_max=0.01),
params={"asset_cfg": SceneEntityCfg("robot", joint_names=self.joint_names)}
)
joint_vel = ObsTerm(
func=mdp.joint_vel_rel,
scale=0.05,
noise=UniformNoise(n_min=-1.5, n_max=1.5),
params={"asset_cfg": SceneEntityCfg("robot", joint_names=self.joint_names)}
)
# 历史动作信息
actions = ObsTerm(func=mdp.last_action)
# 地形高度扫描(在Go2配置中被禁用)
height_scan = None # 在Go2配置中设置为None
MDP函数调用时机:
- 每个仿真步骤后调用观测函数
- 从场景中提取机器人状态信息
- 应用噪声和归一化处理
- Go2特定配置:禁用了基础线速度和高度扫描观测
3.2.2 ActionManager
@configclass
class ActionsCfg:
joint_pos = mdp.JointPositionActionCfg(
asset_name="robot",
joint_names=[
"FR_hip_joint", "FR_thigh_joint", "FR_calf_joint",
"FL_hip_joint", "FL_thigh_joint", "FL_calf_joint",
"RR_hip_joint", "RR_thigh_joint", "RR_calf_joint",
"RL_hip_joint", "RL_thigh_joint", "RL_calf_joint"
],
# Go2特定的动作缩放:髋关节较小缩放,其他关节较大缩放
scale={".*_hip_joint": 0.125, "^(?!.*_hip_joint).*": 0.25},
clip={".*": (-100.0, 100.0)},
use_default_offset=True
)
动作处理流程:
- 接收神经网络输出的动作(12维向量,对应12个关节)
- 应用不同的缩放系数(髋关节0.125,其他关节0.25)
- 应用动作裁剪(±100.0)
- 转换为关节位置目标
- 发送给PD控制器
3.2.3 RewardManager
@configclass
class RewardsCfg:
# 速度跟踪奖励(主要奖励)
track_lin_vel_xy_exp = RewTerm(
func=mdp.track_lin_vel_xy_exp,
weight=3.0, # Go2中权重较高
params={"command_name": "base_velocity", "std": math.sqrt(0.25)}
)
track_ang_vel_z_exp = RewTerm(
func=mdp.track_ang_vel_z_exp,
weight=1.5,
params={"command_name": "base_velocity", "std": math.sqrt(0.25)}
)
# 运动约束惩罚
lin_vel_z_l2 = RewTerm(func=mdp.lin_vel_z_l2, weight=-2.0) # 垂直速度惩罚
ang_vel_xy_l2 = RewTerm(func=mdp.ang_vel_xy_l2, weight=-0.05) # 俯仰滚转惩罚
# 关节相关惩罚
joint_torques_l2 = RewTerm(func=mdp.joint_torques_l2, weight=-2.5e-5)
joint_acc_l2 = RewTerm(func=mdp.joint_acc_l2, weight=-2.5e-7)
joint_pos_limits = RewTerm(func=mdp.joint_pos_limits, weight=-5.0)
joint_power = RewTerm(func=mdp.joint_power, weight=-2e-5)
# 动作平滑性
action_rate_l2 = RewTerm(func=mdp.action_rate_l2, weight=-0.01)
# 接触相关奖励
undesired_contacts = RewTerm(
func=mdp.undesired_contacts,
weight=-1.0,
params={"sensor_cfg": SceneEntityCfg("contact_forces", body_names="^(?!.*_foot).*")}
)
contact_forces = RewTerm(
func=mdp.contact_forces,
weight=-1.5e-4,
params={"sensor_cfg": SceneEntityCfg("contact_forces", body_names=".*_foot")}
)
# 足部高度控制
feet_height_body = RewTerm(
func=mdp.feet_height_body,
weight=-5.0,
params={
"target_height": -0.2,
"asset_cfg": SceneEntityCfg("robot", body_names=".*_foot")
}
)
# 向上运动奖励
upward = RewTerm(func=mdp.upward, weight=1.0)
奖励计算过程:
- 每个仿真步骤计算所有奖励项
- 使用MDP模块中的奖励函数
- 应用权重并求和得到总奖励
- Go2特定:强调速度跟踪,禁用了多个奖励项(权重设为0或None)
3.2.4 TerminationManager
@configclass
class TerminationsCfg:
# 超时终止
time_out = DoneTerm(func=mdp.time_out, time_out=True)
# 非法接触终止(在Go2配置中被禁用)
illegal_contact = None # Go2配置中设置为None,不使用此终止条件
Go2特定配置:
- 只保留超时终止条件
- 禁用了非法接触终止,使训练更加稳定
3.2.5 EventManager
@configclass
class EventCfg:
# 重置时的位置和速度随机化
randomize_reset_base = EventTerm(
func=mdp.reset_root_state_uniform,
mode="reset",
params={
"pose_range": {
"x": (-0.5, 0.5), "y": (-0.5, 0.5), "z": (0.0, 0.2),
"roll": (-3.14, 3.14), "pitch": (-3.14, 3.14), "yaw": (-3.14, 3.14)
},
"velocity_range": {
"x": (-0.5, 0.5), "y": (-0.5, 0.5), "z": (-0.5, 0.5),
"roll": (-0.5, 0.5), "pitch": (-0.5, 0.5), "yaw": (-0.5, 0.5)
}
}
)
# 启动时的质量随机化
randomize_rigid_body_mass = EventTerm(
func=mdp.randomize_rigid_body_mass,
mode="startup",
params={
"asset_cfg": SceneEntityCfg("robot", body_names=["base"]),
"mass_distribution_params": (-3.0, 3.0)
}
)
# 质心位置随机化
randomize_com_positions = EventTerm(
func=mdp.randomize_rigid_body_com,
mode="startup",
params={
"asset_cfg": SceneEntityCfg("robot", body_names=["base"]),
"com_distribution_params": {"x": (-0.1, 0.1), "y": (-0.1, 0.1), "z": (-0.1, 0.1)}
}
)
# 外力扰动
randomize_apply_external_force_torque = EventTerm(
func=mdp.apply_external_force_torque,
mode="interval",
params={
"asset_cfg": SceneEntityCfg("robot", body_names=["base"]),
"force_range": {"x": (-50.0, 50.0), "y": (-50.0, 50.0), "z": (0.0, 0.0)},
"torque_range": {"x": (-10.0, 10.0), "y": (-10.0, 10.0), "z": (-10.0, 10.0)}
}
)
3.2.6 CommandManager
@configclass
class CommandsCfg:
base_velocity = mdp.UniformVelocityCommandCfg(
asset_name="robot",
resampling_time_range=(10.0, 10.0), # 每10秒重新采样命令
rel_standing_envs=0.02, # 2%的环境保持静止
rel_heading_envs=1.0, # 100%的环境包含航向命令
ranges=mdp.UniformVelocityCommandCfg.Ranges(
lin_vel_x=(-1.0, 1.0), # 前进后退速度范围
lin_vel_y=(-1.0, 1.0), # 左右平移速度范围
ang_vel_z=(-1.0, 1.0), # 转向角速度范围
heading=(-3.14, 3.14) # 航向角范围
)
)
命令生成特点:
- 每10秒重新采样速度命令
- 支持全向运动(前后、左右、转向)
- 包含航向控制
- 少量环境保持静止状态用于训练稳定性
4. 训练循环
4.1 RSL-RL包装器
env = RslRlVecEnvWrapper(env, clip_actions=agent_cfg.clip_actions)
包装器功能:
- 适配RSL-RL接口
- 处理动作裁剪
- 批量环境管理
4.2 训练器初始化
runner = OnPolicyRunner(env, agent_cfg.to_dict(), log_dir=log_dir, device=agent_cfg.device)
OnPolicyRunner组件:
- PPO算法实现
- 经验缓冲区管理
- 策略和价值网络更新
4.3 训练主循环
runner.learn(num_learning_iterations=agent_cfg.max_iterations, init_at_random_ep_len=True)
每次迭代包含:
4.3.1 数据收集阶段(Rollout Phase)
def collect_rollouts(self):
"""收集经验数据的详细流程"""
# 重置经验缓冲区
self.storage.clear()
for step in range(self.num_steps_per_env): # 默认24步
# 1. 获取当前观测
obs = self.env.get_observations()["policy"] # 形状: [num_envs, obs_dim]
# 2. 策略网络前向推理
with torch.no_grad():
actions, log_probs, values, mu, sigma = self.actor_critic.act(obs)
# actions: [num_envs, action_dim] - 采样的动作
# log_probs: [num_envs] - 动作的对数概率
# values: [num_envs] - 状态价值估计
# mu, sigma: 策略分布的均值和标准差
# 3. 环境步进
next_obs, rewards, dones, infos = self.env.step(actions)
# 4. 存储经验到缓冲区
self.storage.add_transitions(
observations=obs,
actions=actions,
rewards=rewards,
dones=dones,
values=values,
log_probs=log_probs,
mu=mu,
sigma=sigma
)
# 5. 处理环境重置
if torch.any(dones):
# 重置完成的环境
reset_env_ids = torch.where(dones)[0]
self.env.reset_idx(reset_env_ids)
# 6. 计算最后一步的价值估计(用于优势函数计算)
with torch.no_grad():
last_values = self.actor_critic.evaluate(next_obs)
# 7. 计算回报和优势函数
self.storage.compute_returns(last_values, self.gamma, self.lam)
4.3.2 优势函数计算(GAE - Generalized Advantage Estimation)
def compute_returns(self, last_values, gamma=0.99, lam=0.95):
"""使用GAE计算优势函数和回报"""
# 初始化
advantages = torch.zeros_like(self.rewards)
returns = torch.zeros_like(self.rewards)
# 从后往前计算
gae = 0
for step in reversed(range(self.num_steps_per_env)):
if step == self.num_steps_per_env - 1:
next_non_terminal = 1.0 - self.dones[step]
next_values = last_values
else:
next_non_terminal = 1.0 - self.dones[step + 1]
next_values = self.values[step + 1]
# TD误差
delta = (self.rewards[step] +
gamma * next_values * next_non_terminal -
self.values[step])
# GAE优势函数
gae = delta + gamma * lam * next_non_terminal * gae
advantages[step] = gae
# 回报 = 优势 + 价值估计
returns[step] = gae + self.values[step]
# 标准化优势函数
self.advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
self.returns = returns
4.3.3 网络更新阶段(Policy Update Phase)
def update_policy(self):
"""PPO策略更新的详细流程"""
# 获取所有经验数据
obs_batch = self.storage.observations.view(-1, *self.storage.observations.shape[2:])
actions_batch = self.storage.actions.view(-1, *self.storage.actions.shape[2:])
old_log_probs_batch = self.storage.log_probs.view(-1)
advantages_batch = self.advantages.view(-1)
returns_batch = self.returns.view(-1)
old_values_batch = self.storage.values.view(-1)
# 多轮更新
for epoch in range(self.num_learning_epochs): # 默认5轮
# 随机打乱数据
indices = torch.randperm(obs_batch.size(0))
# 分批更新
for start in range(0, obs_batch.size(0), self.mini_batch_size):
end = start + self.mini_batch_size
batch_indices = indices[start:end]
# 获取mini-batch数据
obs_mini = obs_batch[batch_indices]
actions_mini = actions_batch[batch_indices]
old_log_probs_mini = old_log_probs_batch[batch_indices]
advantages_mini = advantages_batch[batch_indices]
returns_mini = returns_batch[batch_indices]
old_values_mini = old_values_batch[batch_indices]
# 前向传播
log_probs, values, entropy = self.actor_critic.evaluate_actions(
obs_mini, actions_mini
)
# 计算各种损失
policy_loss = self._compute_policy_loss(
log_probs, old_log_probs_mini, advantages_mini
)
value_loss = self._compute_value_loss(
values, old_values_mini, returns_mini
)
entropy_loss = entropy.mean()
# 总损失
total_loss = (policy_loss +
self.value_loss_coef * value_loss -
self.entropy_coef * entropy_loss)
# 反向传播和优化
self.optimizer.zero_grad()
total_loss.backward()
torch.nn.utils.clip_grad_norm_(
self.actor_critic.parameters(),
self.max_grad_norm
)
self.optimizer.step()
4.3.4 PPO损失函数详细实现
def _compute_policy_loss(self, log_probs, old_log_probs, advantages):
"""计算PPO策略损失(带裁剪)"""
# 重要性采样比率
ratio = torch.exp(log_probs - old_log_probs)
# 未裁剪的策略损失
surr1 = ratio * advantages
# 裁剪的策略损失
surr2 = torch.clamp(
ratio,
1.0 - self.clip_param, # 默认0.2
1.0 + self.clip_param
) * advantages
# 取较小值(更保守的更新)
policy_loss = -torch.min(surr1, surr2).mean()
return policy_loss
def _compute_value_loss(self, values, old_values, returns):
"""计算价值函数损失"""
if self.use_clipped_value_loss:
# 裁剪的价值损失
values_clipped = old_values + torch.clamp(
values - old_values,
-self.clip_param,
self.clip_param
)
value_loss1 = (values - returns).pow(2)
value_loss2 = (values_clipped - returns).pow(2)
value_loss = torch.max(value_loss1, value_loss2).mean()
else:
# 标准MSE损失
value_loss = F.mse_loss(values, returns)
return value_loss
4.3.5 神经网络架构
class ActorCritic(nn.Module):
"""Actor-Critic网络架构"""
def __init__(self, obs_dim, action_dim, hidden_dims=[512, 256, 128]):
super().__init__()
# 共享特征提取器
self.feature_extractor = nn.Sequential(
nn.Linear(obs_dim, hidden_dims[0]),
nn.ELU(),
nn.Linear(hidden_dims[0], hidden_dims[1]),
nn.ELU(),
nn.Linear(hidden_dims[1], hidden_dims[2]),
nn.ELU()
)
# Actor网络(策略)
self.actor_mean = nn.Linear(hidden_dims[2], action_dim)
self.actor_logstd = nn.Parameter(torch.zeros(action_dim))
# Critic网络(价值函数)
self.critic = nn.Linear(hidden_dims[2], 1)
# 初始化权重
self._init_weights()
def forward(self, obs):
"""前向传播"""
features = self.feature_extractor(obs)
# 策略分布参数
action_mean = self.actor_mean(features)
action_std = torch.exp(self.actor_logstd)
# 状态价值
value = self.critic(features)
return action_mean, action_std, value
def act(self, obs):
"""采样动作"""
action_mean, action_std, value = self.forward(obs)
# 创建正态分布
dist = torch.distributions.Normal(action_mean, action_std)
# 采样动作
action = dist.sample()
log_prob = dist.log_prob(action).sum(dim=-1)
return action, log_prob, value, action_mean, action_std
def evaluate_actions(self, obs, actions):
"""评估给定动作的概率和价值"""
action_mean, action_std, value = self.forward(obs)
# 创建分布
dist = torch.distributions.Normal(action_mean, action_std)
# 计算对数概率和熵
log_prob = dist.log_prob(actions).sum(dim=-1)
entropy = dist.entropy().sum(dim=-1)
return log_prob, value.squeeze(), entropy
4.3.6 学习率调度
def update_learning_rate(self, current_iteration):
"""自适应学习率调度"""
if self.schedule == "adaptive":
# 基于KL散度调整学习率
if self.mean_kl > self.desired_kl * 2.0:
self.learning_rate = max(1e-5, self.learning_rate / 1.5)
elif self.mean_kl < self.desired_kl / 2.0:
self.learning_rate = min(1e-2, self.learning_rate * 1.5)
elif self.schedule == "linear":
# 线性衰减
self.learning_rate = self.initial_lr * (
1.0 - current_iteration / self.max_iterations
)
# 更新优化器学习率
for param_group in self.optimizer.param_groups:
param_group['lr'] = self.learning_rate
4.3.7 训练监控和日志
def log_training_info(self, iteration):
"""记录训练信息"""
# 计算统计信息
mean_reward = self.storage.rewards.mean().item()
mean_episode_length = self.episode_lengths.float().mean().item()
# 策略相关指标
mean_kl = self.mean_kl.item()
policy_loss = self.policy_loss.item()
value_loss = self.value_loss.item()
entropy = self.entropy.item()
# 记录到TensorBoard/WandB
self.logger.log_scalar("Train/MeanReward", mean_reward, iteration)
self.logger.log_scalar("Train/MeanEpisodeLength", mean_episode_length, iteration)
self.logger.log_scalar("Train/PolicyLoss", policy_loss, iteration)
self.logger.log_scalar("Train/ValueLoss", value_loss, iteration)
self.logger.log_scalar("Train/Entropy", entropy, iteration)
self.logger.log_scalar("Train/KL", mean_kl, iteration)
self.logger.log_scalar("Train/LearningRate", self.learning_rate, iteration)
# 打印训练进度
print(f"Iteration {iteration}: "
f"Reward={mean_reward:.2f}, "
f"PolicyLoss={policy_loss:.4f}, "
f"ValueLoss={value_loss:.4f}")
4.3.8 完整训练循环
def learn(self, num_learning_iterations, init_at_random_ep_len=True):
"""完整的PPO训练循环"""
# 初始化
if init_at_random_ep_len:
self.env.reset()
for iteration in range(num_learning_iterations):
start_time = time.time()
# 1. 数据收集阶段
self.collect_rollouts()
# 2. 网络更新阶段
self.update_policy()
# 3. 学习率调度
self.update_learning_rate(iteration)
# 4. 记录日志
self.log_training_info(iteration)
# 5. 保存检查点
if iteration % self.save_interval == 0:
self.save_checkpoint(iteration)
# 6. 计算训练时间
end_time = time.time()
print(f"Iteration {iteration} completed in {end_time - start_time:.2f}s")
# 训练完成,保存最终模型
self.save_checkpoint(num_learning_iterations)
print("Training completed!")
关键超参数配置:
# PPO超参数(Go2默认配置)
{
"num_steps_per_env": 24, # 每个环境收集的步数
"num_learning_epochs": 5, # 每次更新的epoch数
"num_mini_batches": 4, # mini-batch数量
"clip_param": 0.2, # PPO裁剪参数
"gamma": 0.99, # 折扣因子
"lam": 0.95, # GAE lambda参数
"learning_rate": 1e-3, # 初始学习率
"value_loss_coef": 1.0, # 价值损失系数
"entropy_coef": 0.01, # 熵损失系数
"max_grad_norm": 1.0, # 梯度裁剪
"desired_kl": 0.01, # 目标KL散度
"schedule": "adaptive", # 学习率调度策略
}
5. 仿真步骤详细流程
5.1 单步仿真流程
1. 获取当前观测 (ObservationManager)
├── 调用mdp.base_lin_vel()获取线速度
├── 调用mdp.joint_pos_rel()获取关节位置
├── 调用mdp.height_scan()获取地形信息
└── 应用噪声和归一化
2. 策略网络推理
├── 输入观测向量
└── 输出动作向量
3. 动作执行 (ActionManager)
├── 调用mdp.JointPositionActionCfg处理动作
├── 应用缩放和偏移
└── 发送给关节PD控制器
4. 物理仿真步进
├── PhysX物理引擎计算
├── 碰撞检测
└── 动力学积分
5. 奖励计算 (RewardManager)
├── 调用mdp.track_lin_vel_xy_exp()计算速度跟踪奖励
├── 调用mdp.GaitReward()计算步态奖励
├── 调用其他奖励函数
└── 加权求和得到总奖励
6. 终止条件检查 (TerminationManager)
├── 调用mdp.time_out()检查超时
├── 调用mdp.illegal_contact()检查非法接触
└── 决定是否重置环境
7. 事件处理 (EventManager)
├── 检查是否需要随机化
├── 调用相应的mdp事件函数
└── 更新环境参数
8. 命令更新 (CommandManager)
├── 检查是否需要重新采样命令
└── 生成新的速度命令
6 训练监控与日志
6.1 日志系统
log_dir = os.path.join("logs", "rsl_rl", agent_cfg.experiment_name)
dump_yaml(os.path.join(log_dir, "params", "env.yaml"), env_cfg)
dump_yaml(os.path.join(log_dir, "params", "agent.yaml"), agent_cfg)
6.2 监控指标
- 平均奖励
- 成功率
- 策略损失
- 价值损失
- 熵值
6. 总结
Go2机器人的训练流程是一个复杂的系统,涉及多个层次的组件协作:
- 顶层:训练脚本和命令行接口
- 配置层:Hydra配置系统和环境参数
- 环境层:Isaac Sim物理仿真和场景管理
- Manager层:观测、动作、奖励、终止、事件管理
- MDP层:具体的状态转移、奖励计算函数
- 算法层:RSL-RL的PPO实现
- 底层:GPU加速的物理仿真和张量计算