在数据驱动决策的时代,传统BI工具日益显露出扩展性弱、灵活性差、资源利用率低等痛点。衡石科技推出的HENGSHI SENSE平台,创新性地采用BI PaaS(平台即服务)架构,为企业构建了一个强大、开放、可扩展的数据分析基础设施。本文将深入解析其核心技术架构与价值。
一、 为何需要BI PaaS?传统BI的瓶颈与突破
传统BI解决方案多为单体应用或SaaS模式,存在以下关键限制:
-
扩展性瓶颈: 用户量、数据量激增时,性能急剧下降,难以横向扩展。
-
定制化困难: 难以深度嵌入业务系统或满足高度个性化的分析需求。
-
集成成本高: 与企业现有数据栈(数仓、数据湖、业务系统)对接复杂。
-
资源隔离与效率: 多租户/多项目场景下,资源争抢严重,缺乏有效隔离与弹性伸缩。
-
开发运维负担: 安装、配置、升级、维护工作量大,占用IT团队大量精力。
BI PaaS应运而生,其核心思想是将BI能力平台化:
-
提供基础能力: 将数据连接、建模、计算、可视化、权限等核心BI功能封装为标准化服务。
-
开放API与SDK: 提供丰富的接口,供开发者灵活调用、集成和扩展。
-
弹性基础设施: 基于云原生技术,实现资源的动态分配与高效管理。
-
专注核心业务: 企业无需从零构建BI基础设施,聚焦于数据价值挖掘。
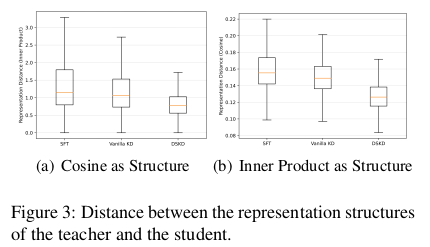
二、 衡石HENGSHI SENSE:BI PaaS架构的核心技术实现
HENGSHI SENSE平台的设计哲学是构建一个“Analytics Infrastructure”(分析基础设施)。其技术架构的关键支柱包括:
-
云原生微服务架构:
-
解耦与弹性: 平台核心功能(如查询引擎、任务调度、元数据管理、渲染服务、权限服务等)被拆分为独立的微服务。
-
容器化部署: 基于Kubernetes等容器编排技术,实现服务的快速部署、滚动升级、故障自愈和水平扩展。用户量或计算负载增加时,可动态扩展相应服务实例。
-
高可用与容灾: 微服务架构和容器编排天然支持多副本部署,保障服务的高可用性。
-
-
统一数据建模层 (Semantic Layer):
-
核心枢纽: 这是SENSE平台的核心竞争力之一。它抽象了底层复杂的数据源(关系型数据库、数据仓库、数据湖、API、文件等),定义统一的业务指标(如“销售额”、“活跃用户数”)和维度(如“时间”、“地区”、“产品”)。
-
逻辑统一,物理分散: 业务人员和分析师在统一的语义层上进行拖拽式分析,无需关心底层物理数据存储位置和方言差异。平台自动将逻辑查询转换为对底层数据源的物理查询(如SQL)。
-
保障一致性: “Single Source of Truth”,确保不同分析报告中的指标定义和计算逻辑一致。
-
-
高性能分布式查询引擎:
-
智能下推: 引擎核心优化策略是将计算尽可能下推到数据源(如Pushdown到MPP数仓或Spark集群),仅拉取必要结果,最大化利用底层引擎的计算能力,减少网络传输。
-
多引擎适配: 内置或可扩展适配多种主流计算引擎(如Presto/Trino, Spark, Doris, ClickHouse等),根据数据源特性和查询复杂度选择最优执行路径。
-
缓存优化: 智能缓存常用查询结果和中间数据,加速重复查询响应。
-
-
开放API与深度集成能力:
-
全方位API: 提供覆盖数据连接管理、模型构建、看板/报告创建、渲染、用户权限、任务调度等全生命周期的RESTful API。
-
SDK支持: 提供易用的SDK(如JavaScript SDK),方便将SENSE的分析能力(如可视化图表、仪表板)无缝嵌入到企业自有的业务系统、门户网站或移动应用中,实现深度集成。
-
嵌入式分析: 支持将分析模块作为组件嵌入第三方应用,提供沉浸式数据分析体验。
-
-
多租户与资源隔离:
-
精细管控: 平台层面支持多租户架构,可在组织、部门、项目等不同层级进行资源(计算、存储、并发)隔离和配额管理。
-
租户级定制: 不同租户可拥有独立的数据源连接、数据模型、分析内容、用户体系和权限配置,满足大型企业内不同业务单元的需求。
-
-
安全与治理:
-
细粒度权限: 提供从数据源、数据模型、行级、列级到看板/报告/图表的精细权限控制。
-
审计追踪: 记录关键操作日志,满足合规性要求。
-
数据加密: 支持数据传输和存储加密。
-
三、 BI PaaS架构带来的核心价值
基于以上技术实现,HENGSHI SENSE BI PaaS平台为企业带来显著价值:
-
敏捷交付与创新加速:
-
开发者和业务团队能基于平台能力,快速构建和迭代定制化的数据分析应用,无需从零开始。
-
嵌入式分析缩短了数据洞察融入业务流程的路径。
-
-
极致扩展性与弹性:
-
云原生架构轻松应对用户、数据量和并发查询的增长,按需伸缩资源,优化成本。
-
分布式查询引擎有效利用底层大数据基础设施。
-
-
降本增效:
-
集中化的平台管理大幅降低分散部署和运维的成本与复杂度。
-
资源池化和弹性伸缩提高基础设施利用率,避免资源浪费。
-
-
统一与一致的数据体验:
-
统一的语义层是构建企业级数据文化的基石,确保“说同一种数据语言”。
-
消除数据孤岛,提供跨数据源的统一分析视图。
-
-
生态构建与未来兼容:
-
开放API架构易于与企业现有IT生态(身份认证、流程引擎、监控系统等)集成。
-
平台的可扩展性便于未来接入新的数据源、计算引擎或分析算法。
-
四、 总结:构建面向未来的数据分析基础设施
衡石HENGSHI SENSE平台通过其先进的BI PaaS架构,成功将BI从孤立的应用工具升级为企业级的数据分析基础设施。其云原生微服务底座、强大的统一语义层、高性能分布式查询引擎、全面的开放API和精细的租户管理,共同支撑起一个高扩展、高灵活、深度集成、安全可控的现代化分析平台。
对于追求通过数据驱动实现业务增长、需要处理海量数据、拥有复杂IT环境、且需要深度定制和嵌入分析能力的企业而言,采用基于BI PaaS架构的衡石HENGSHI SENSE平台,无疑是构建坚实、灵活、面向未来的数据分析能力核心基座的战略性选择。它不仅仅是一个工具,更是企业释放数据潜能、加速数字化转型的引擎。



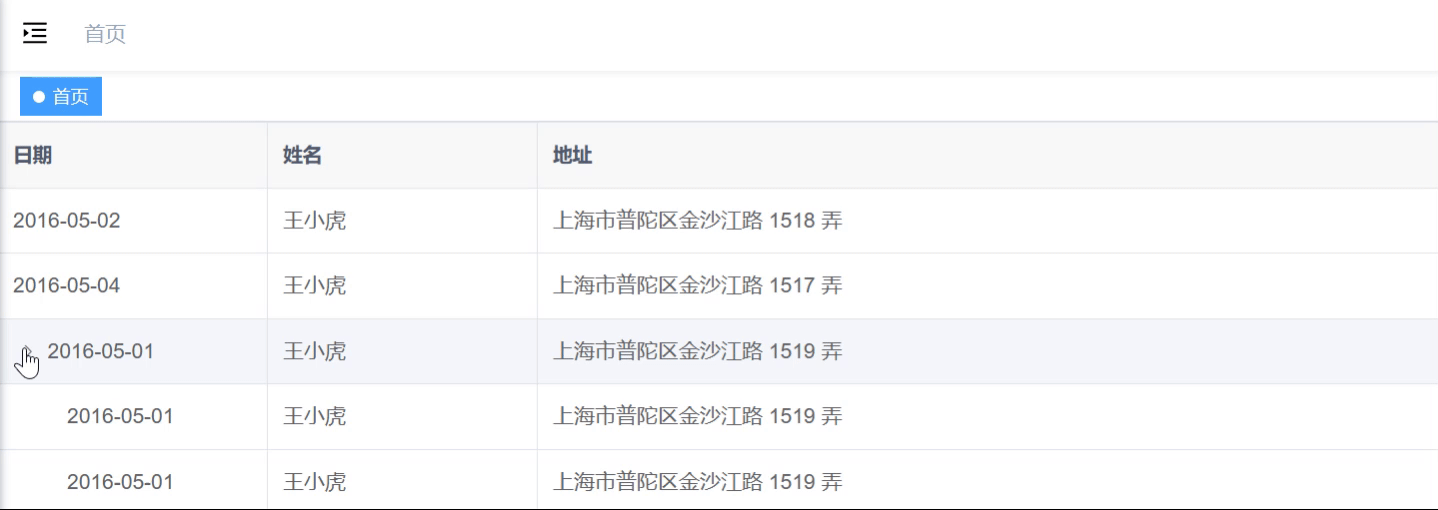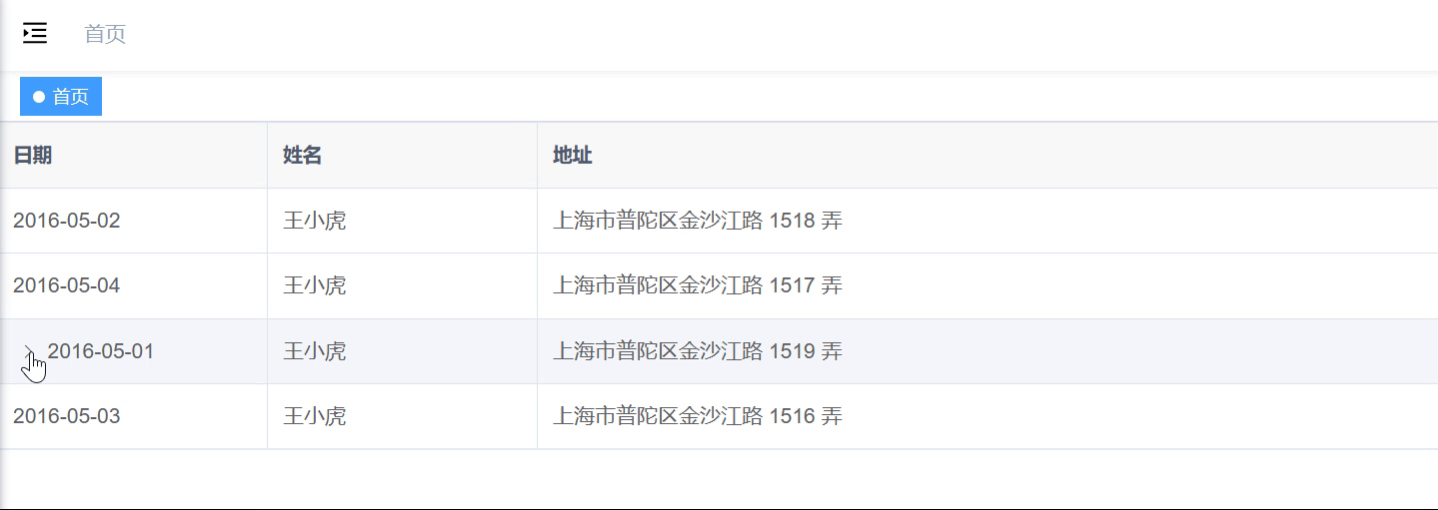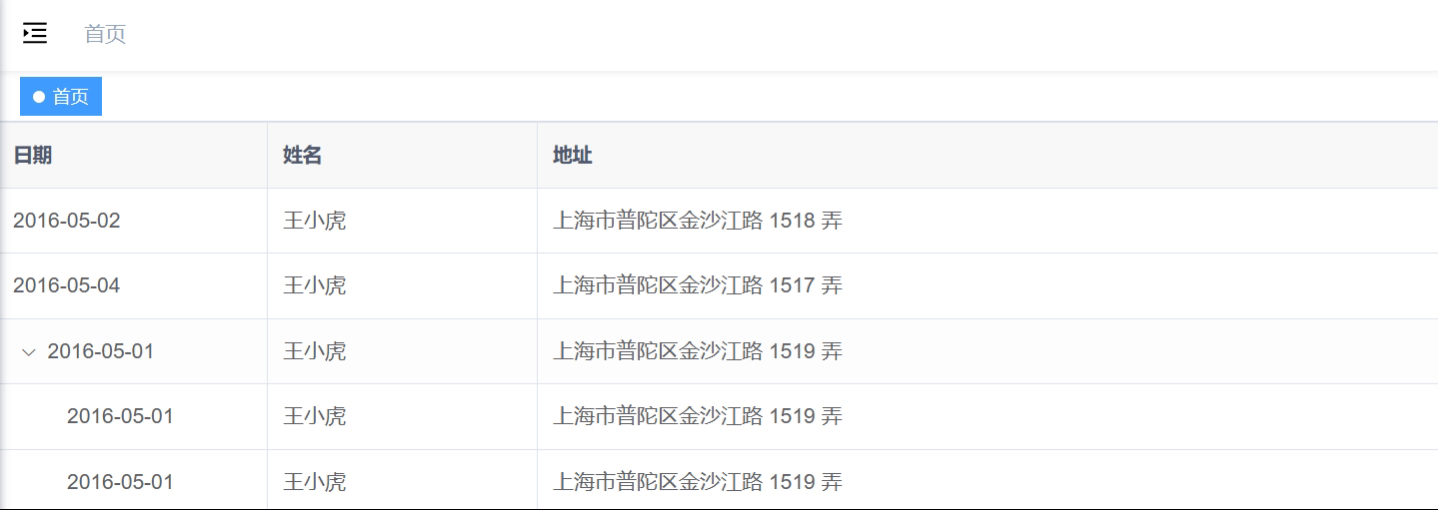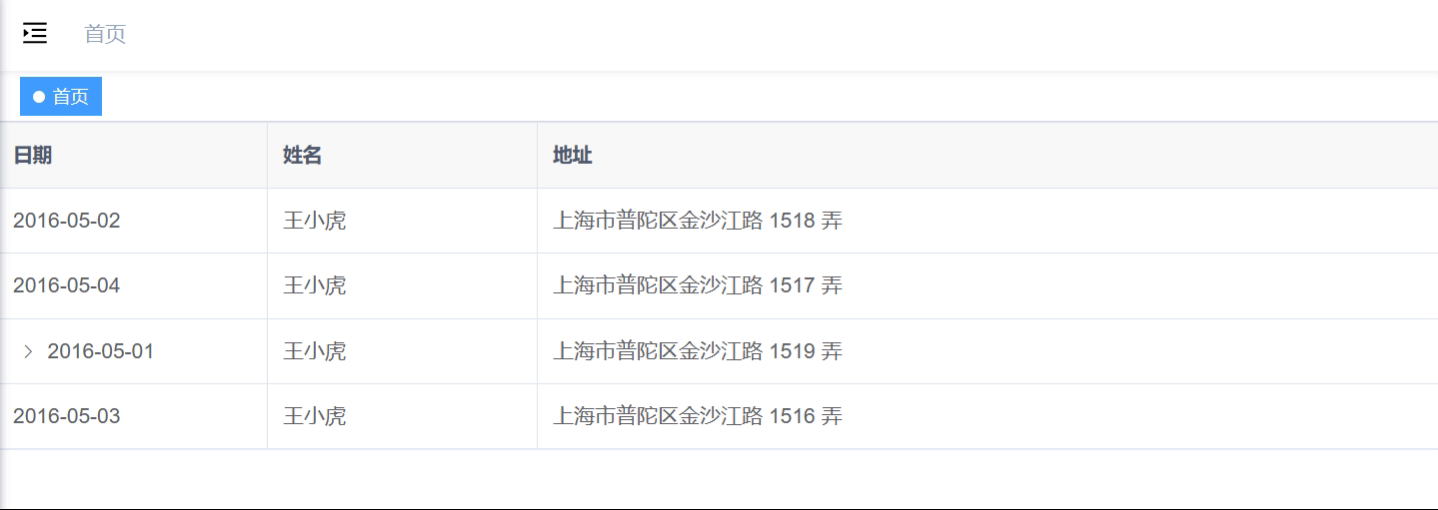



![学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2]](https://i-blog.csdnimg.cn/direct/db92e58cde9b4aa194d3629461b095ab.png)