一、说明
Qwen3-235B 和 Qwen3-32B 的主要区别在于它们的参数规模和应用场景。
参数规模
- Qwen3-235B:总参数量为2350亿,激活参数量为220亿。
- Qwen3-32B:总参数量为320亿。
应用场景
- Qwen3-235B:作为旗舰模型,Qwen3-235B在复杂任务中表现出色,特别是在代码、数学和通用能力等基准测试中,与 DeepSeek-R1 、 o1 、 o3-mini 、 Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。
- Qwen3-32B:适合中大型任务,适合普通的企业级部署。
性能表现
- Qwen3-235B:在处理复杂任务时表现出色,能够提供高性能的推理结果。
- Qwen3-32B:虽然参数规模较小,但在实际使用中也能提供良好的性能表现。
二、飞桨AI studio部署模型
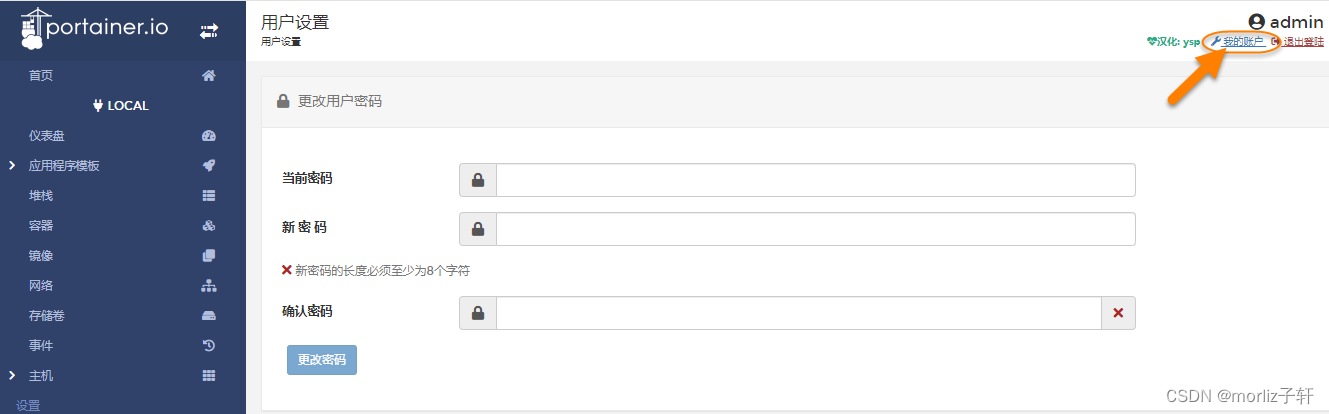
1、注册飞桨
飞桨AI Studio星河社区-人工智能学习与实训社区![]() https://aistudio.baidu.com/overview具体步骤不写了
https://aistudio.baidu.com/overview具体步骤不写了
2、部署模型
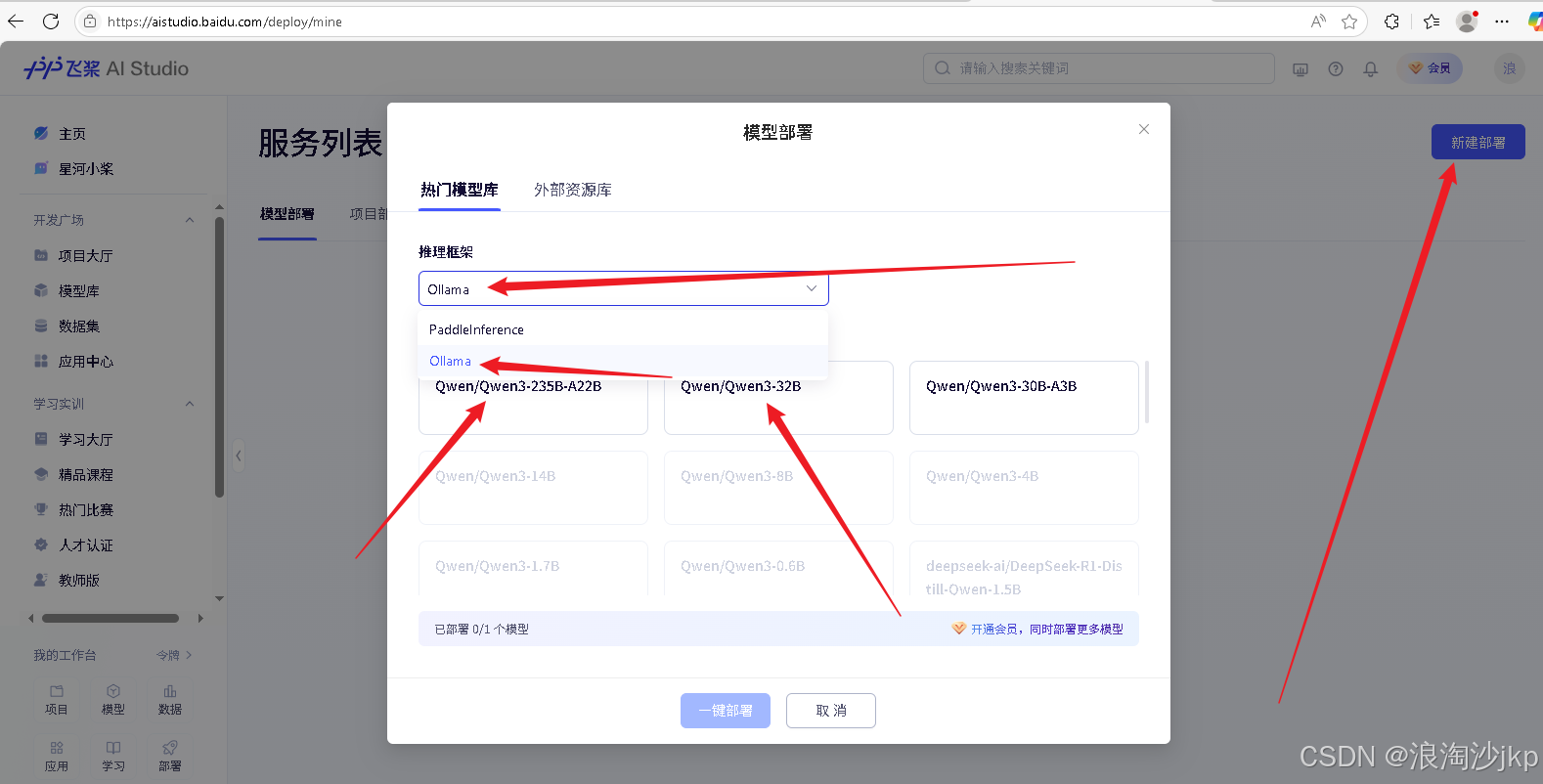
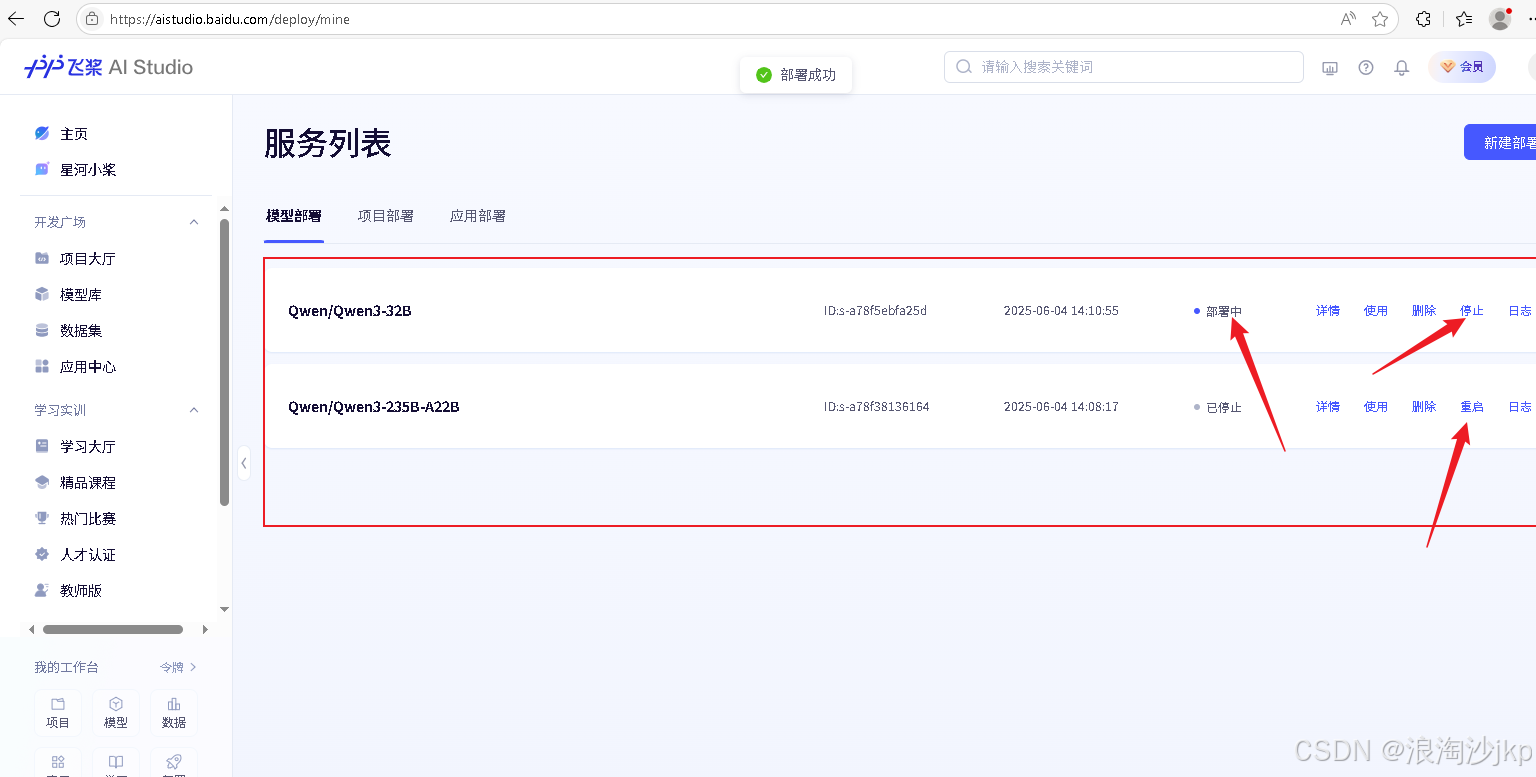
部署 Qwen/Qwen3-235B-A22B
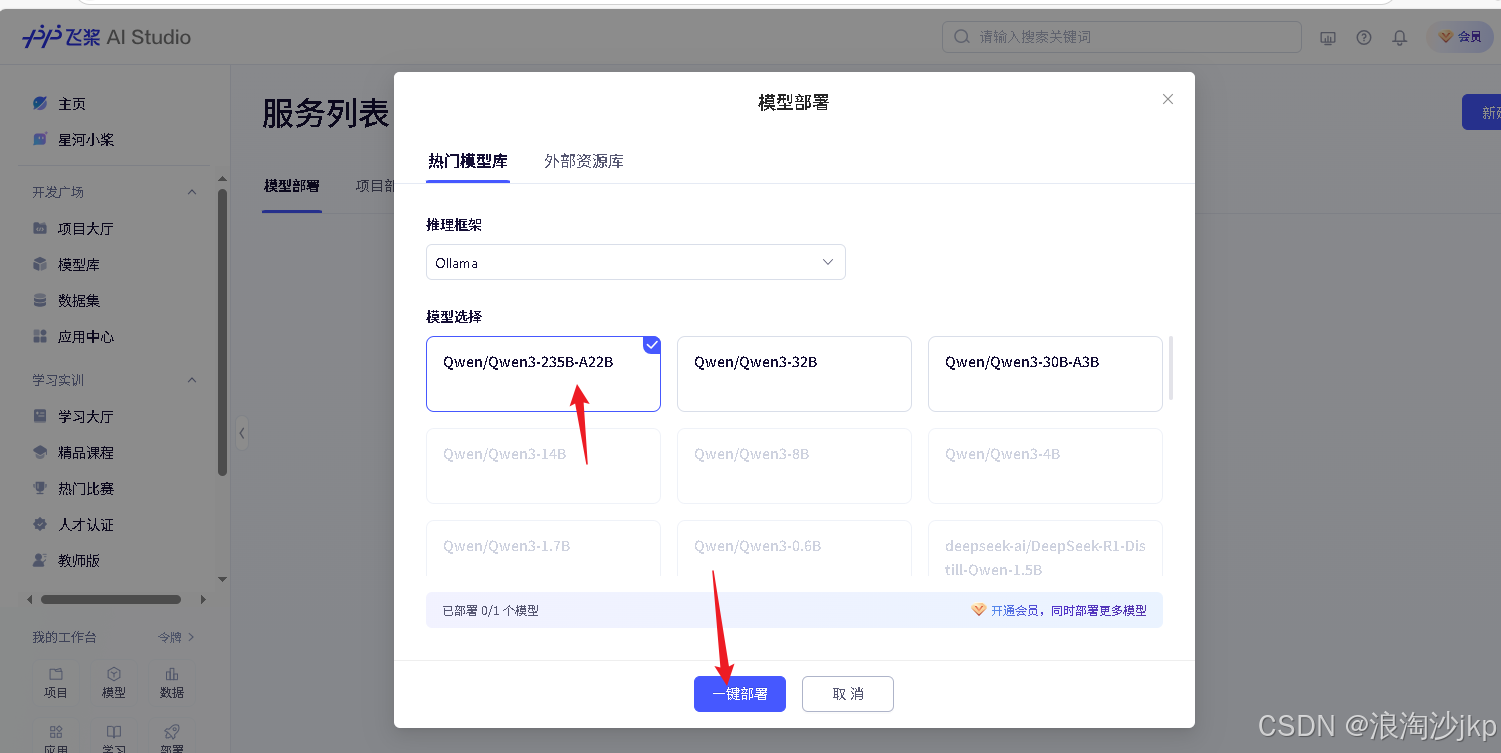
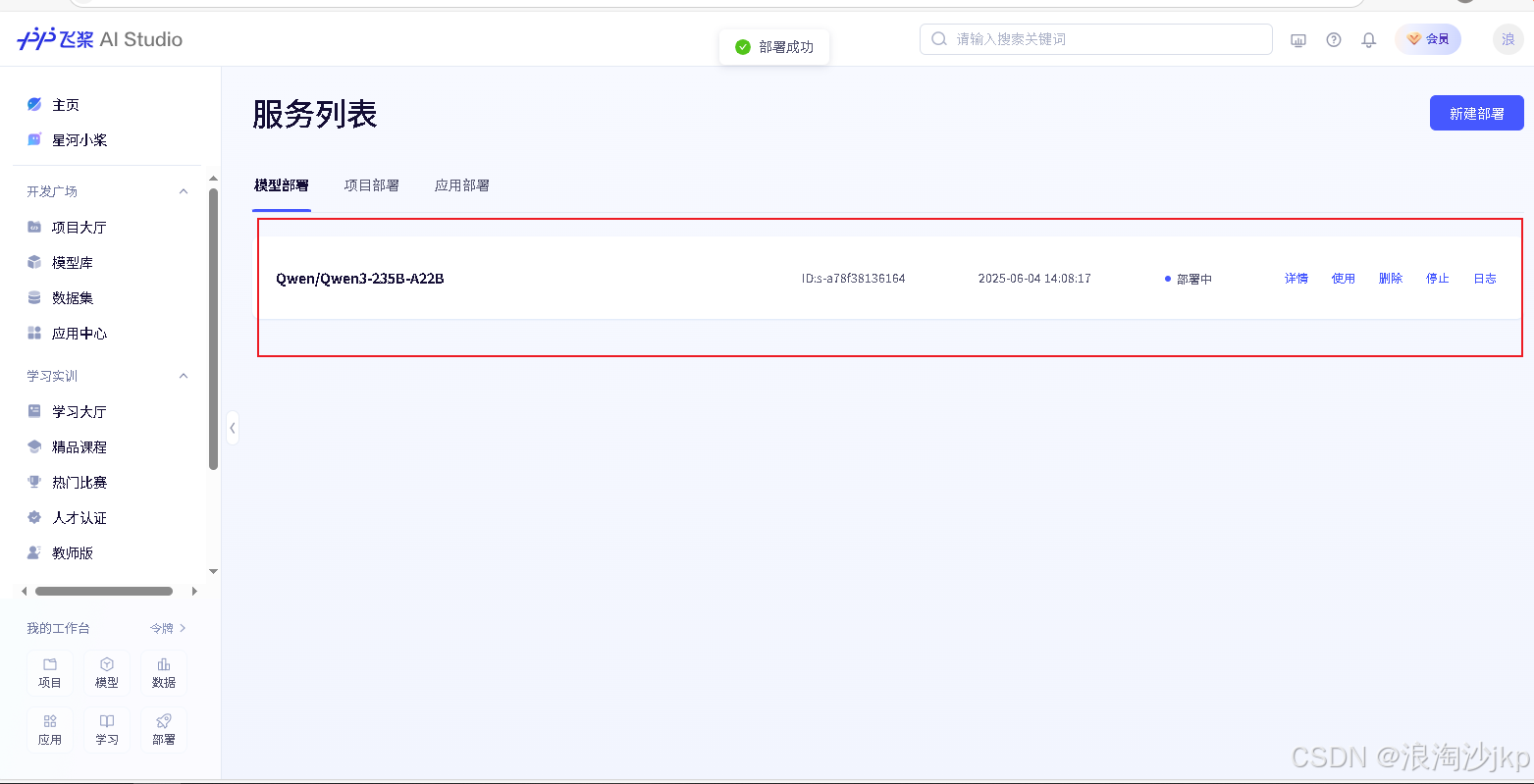
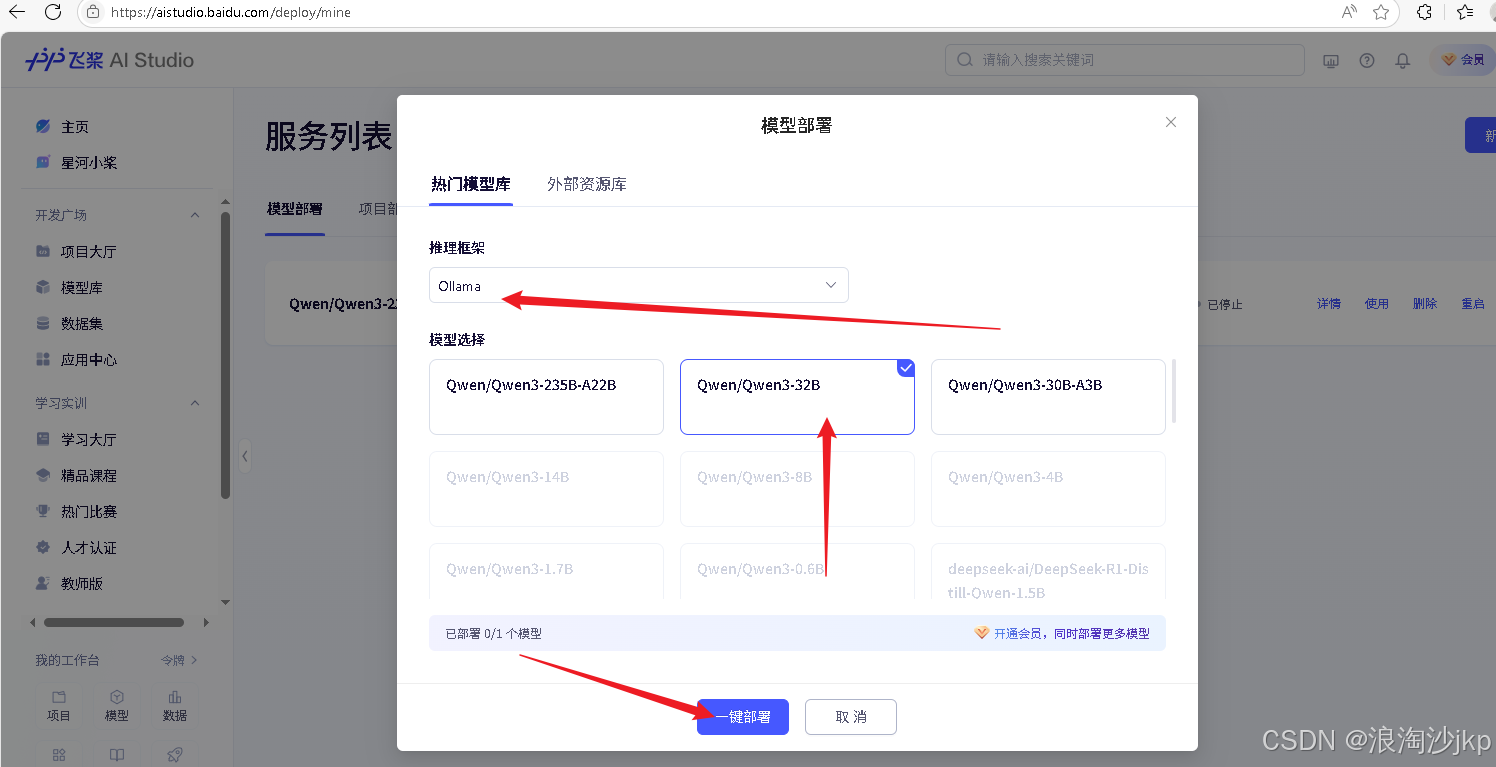
同样方法可以部署Qwen/Qwen3-32B
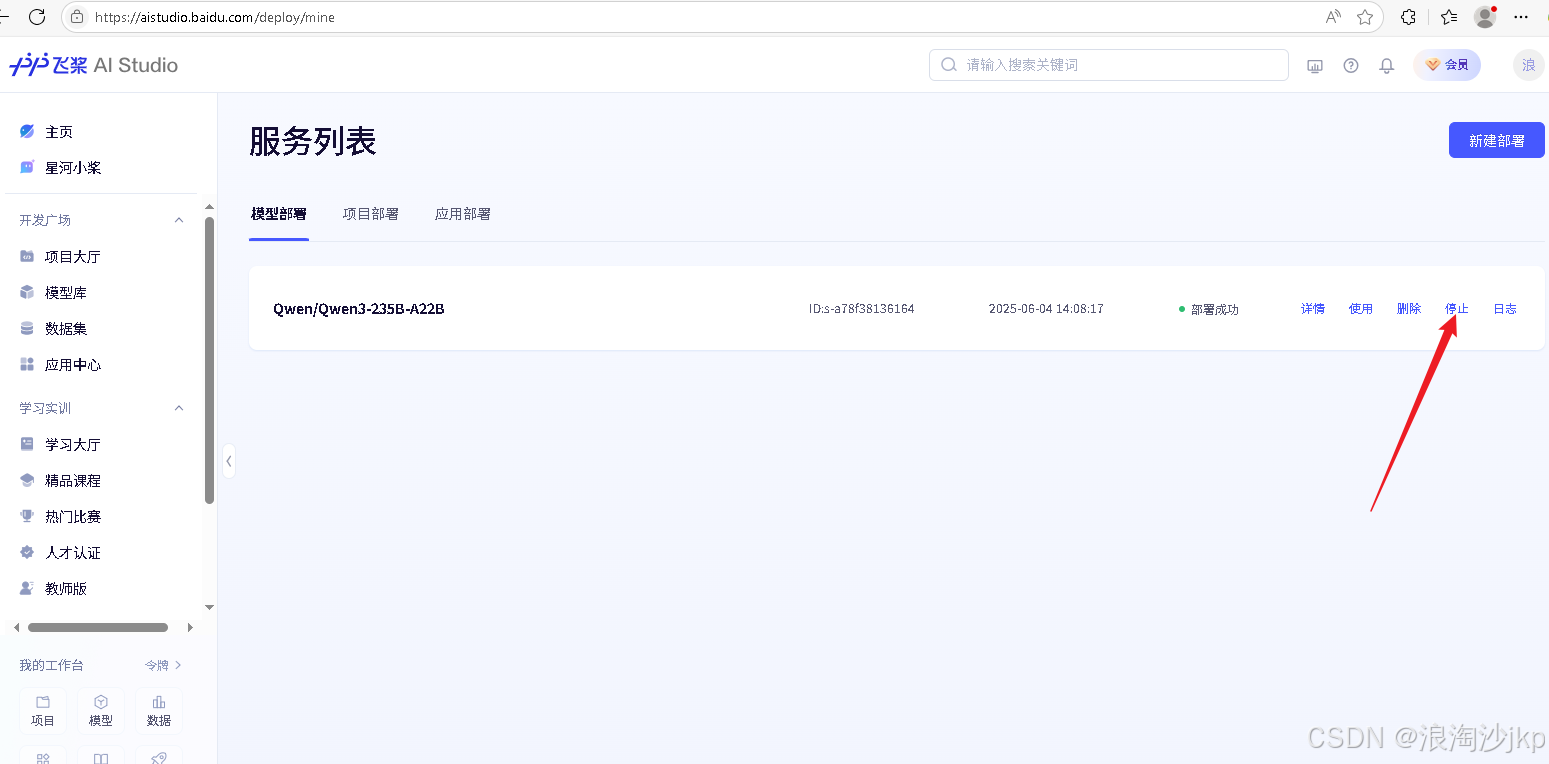
同时只能部署一个,部署之前我们要停止运行的模型
三、创建dify应用,引入模型
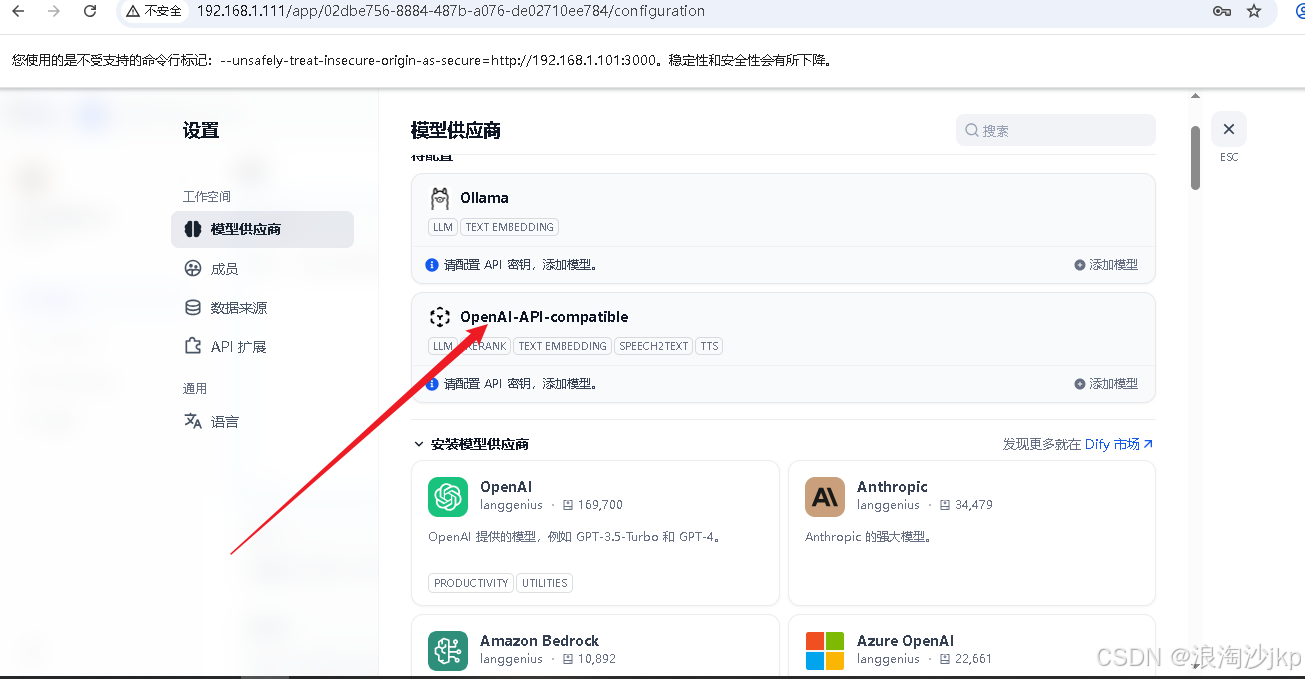
1、安装插件OpenAI-API-compatible
详细步骤我们不说,安装后在这里找到插件
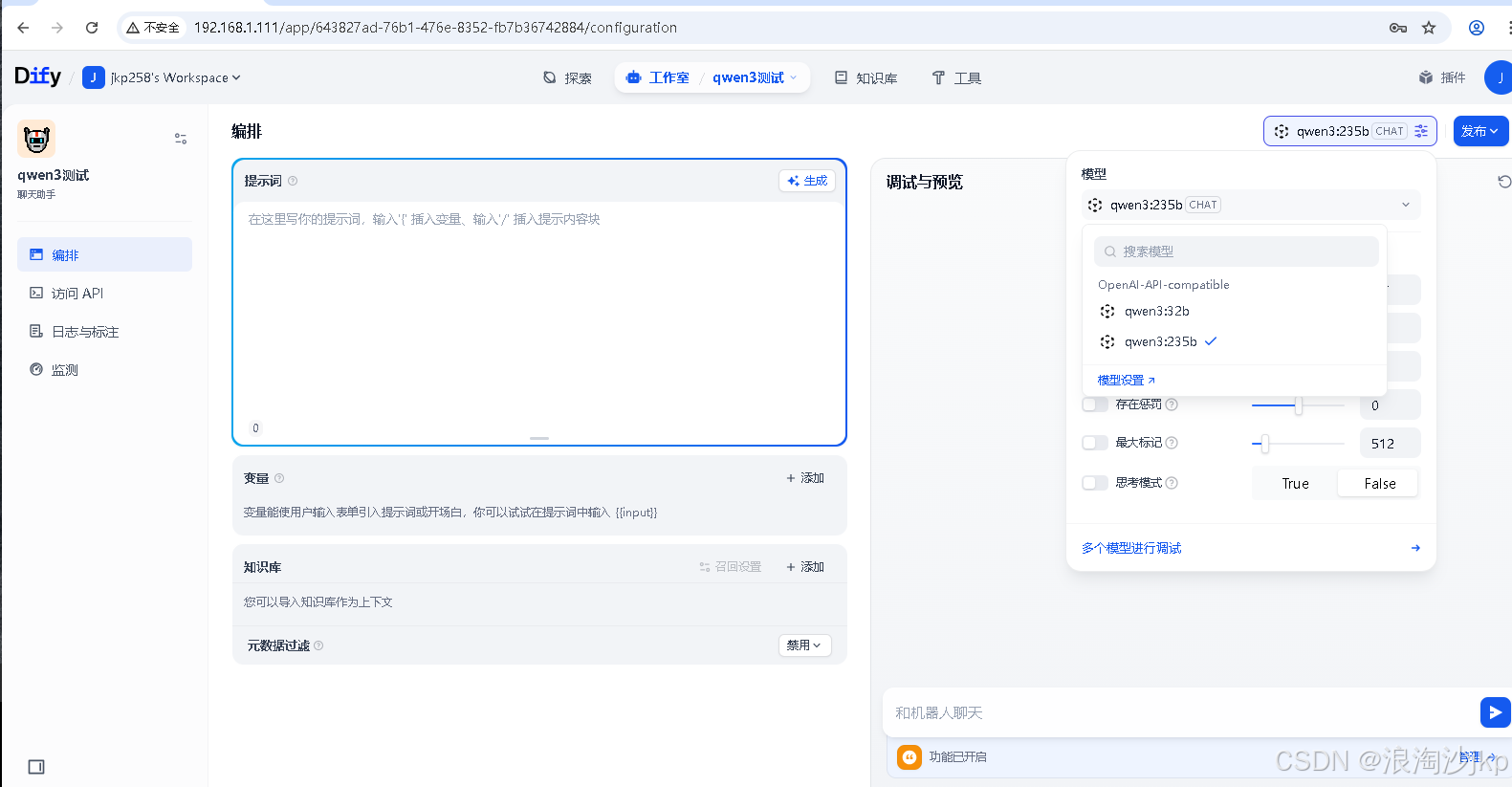
2、导入模型
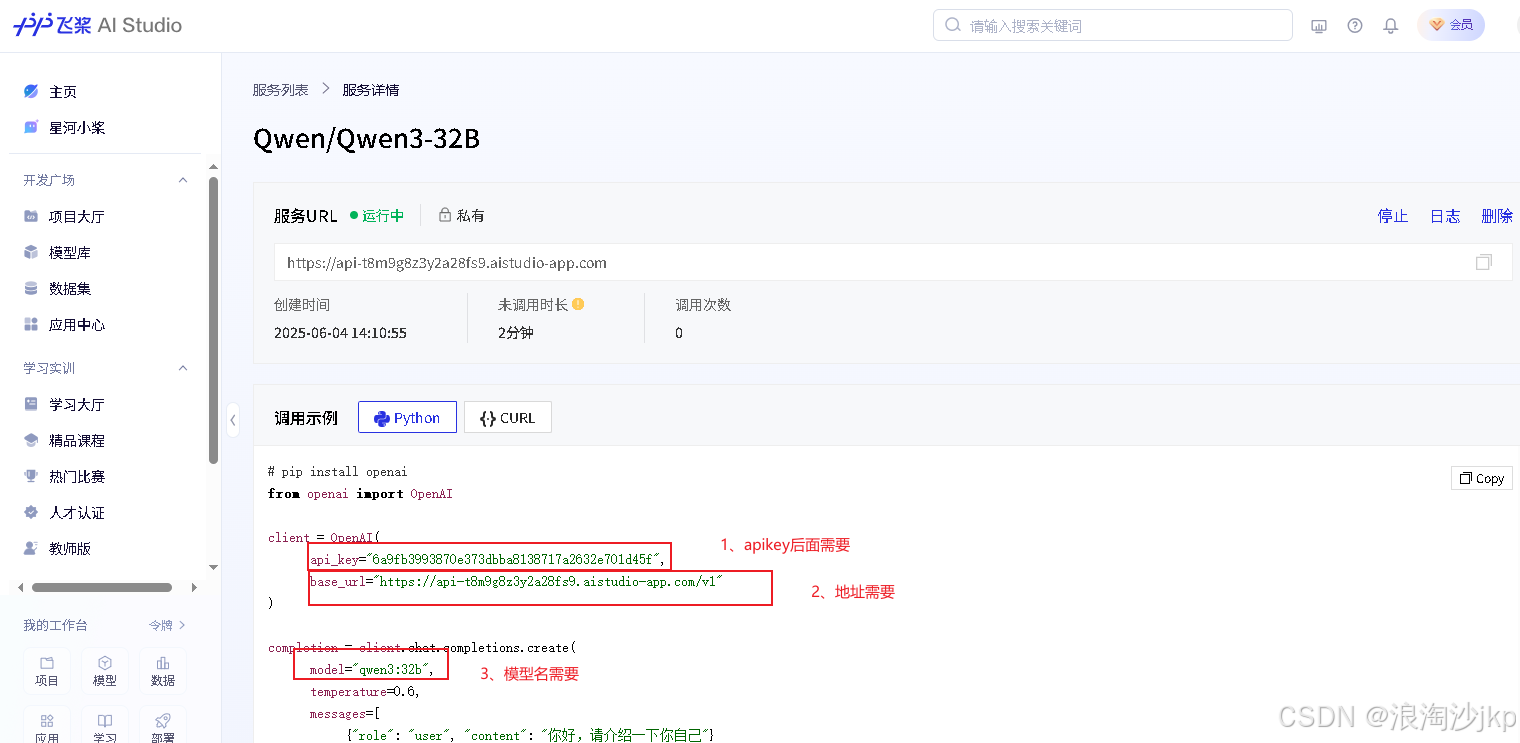
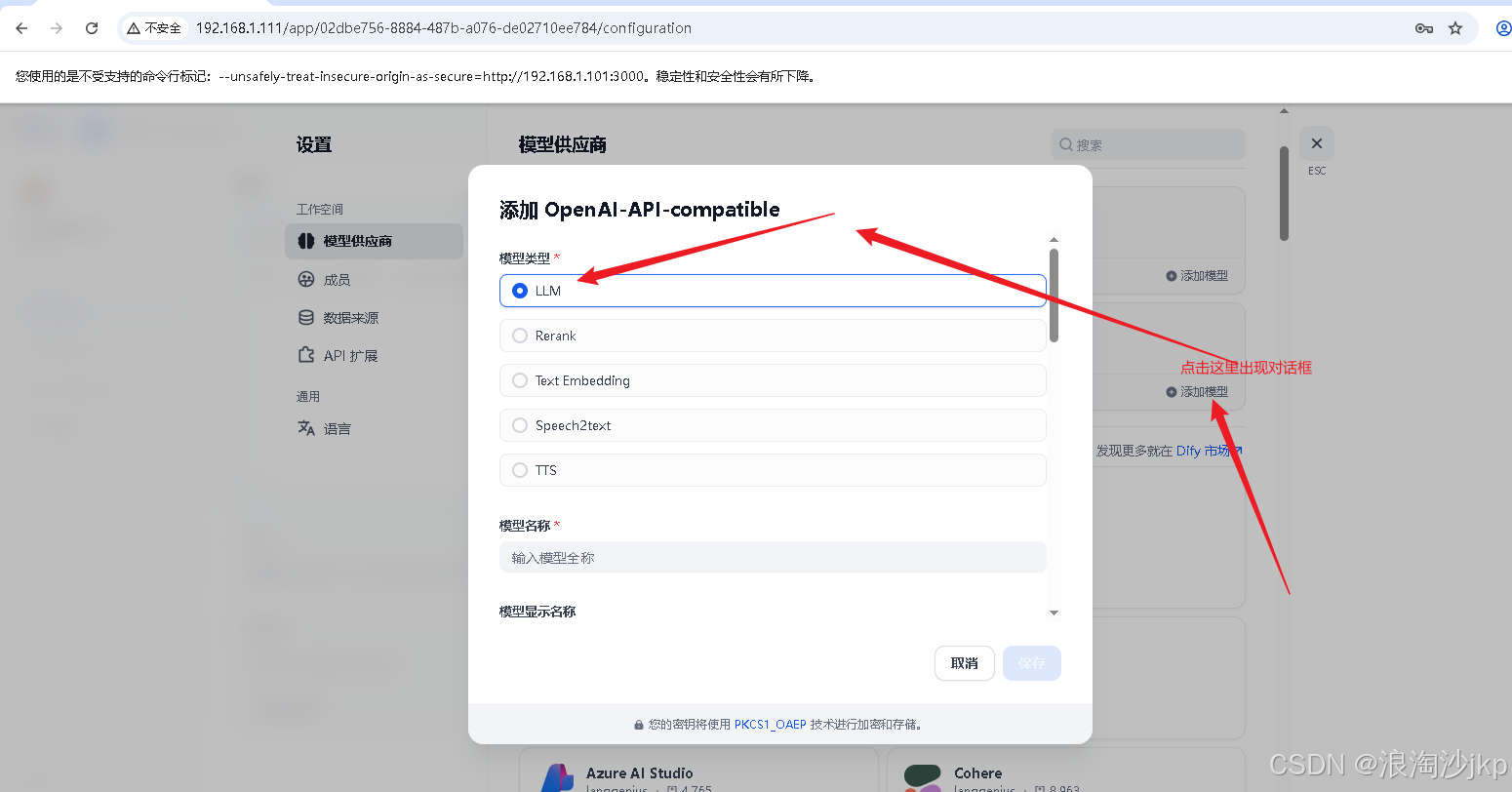
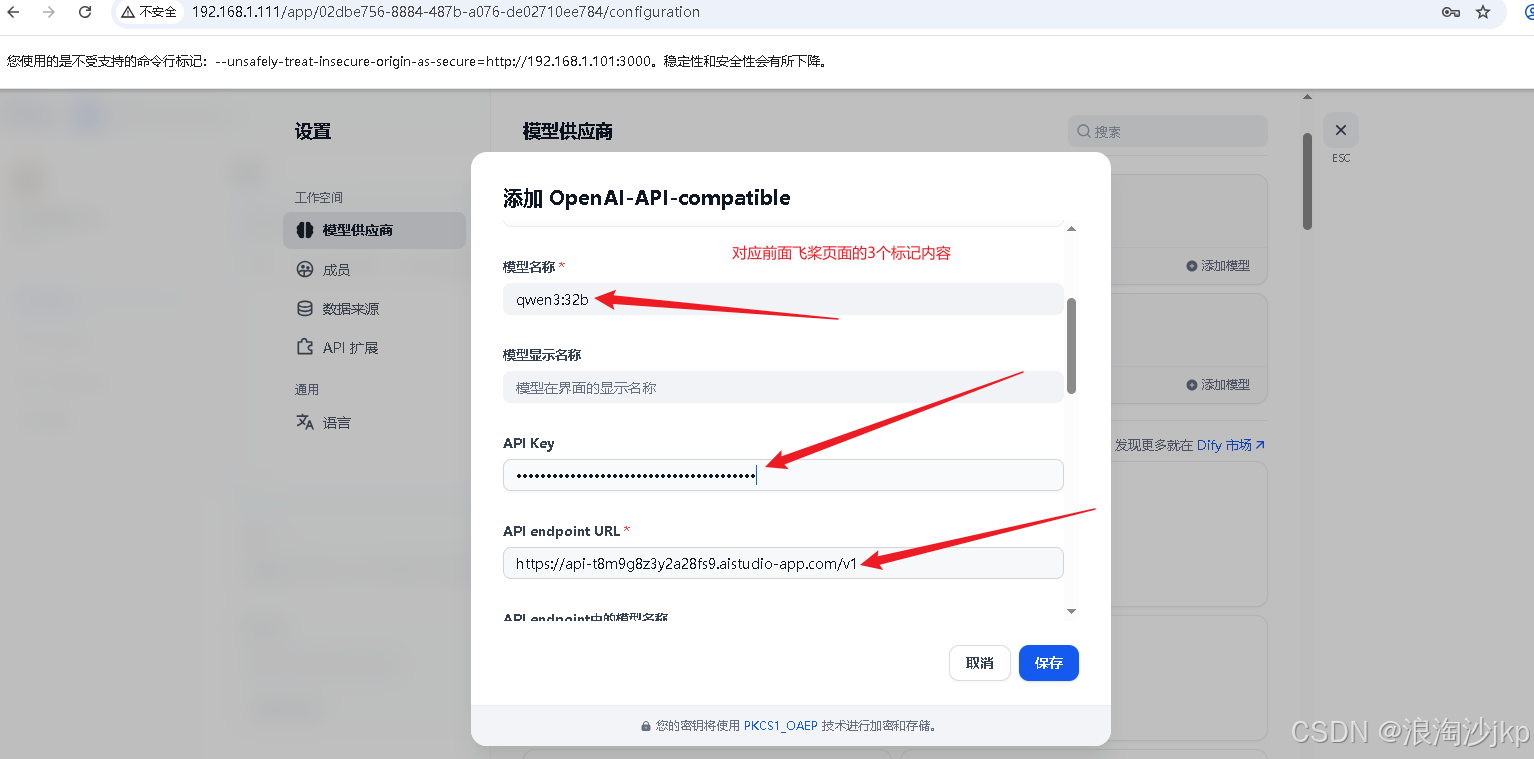
点击保存后
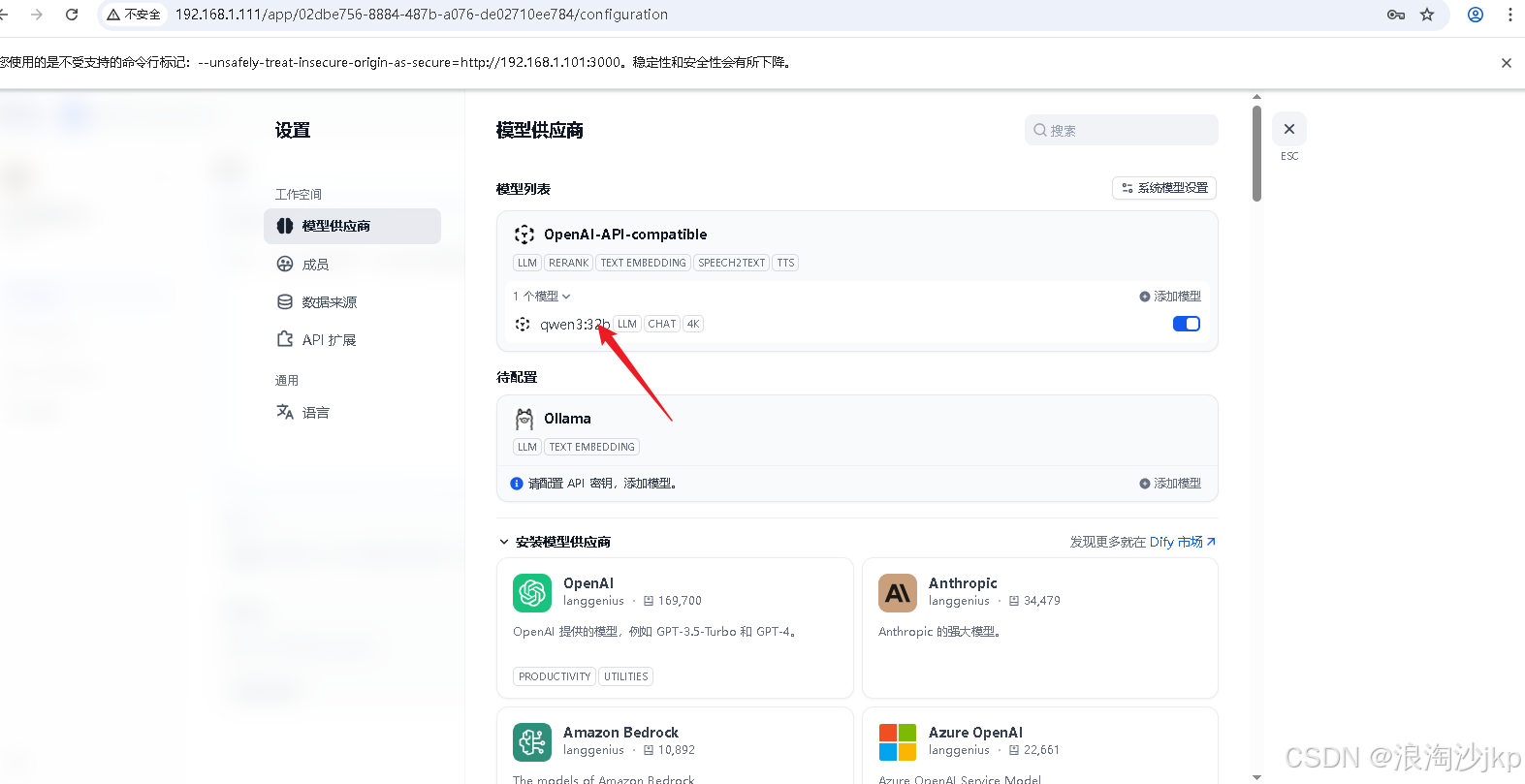
同样我们也可以添加Qwen3-235B-A22B的模型
注意飞桨同时只能打开一个模型,没交钱的情况下
需要关闭32b,然后运行235b模型,然后再配置
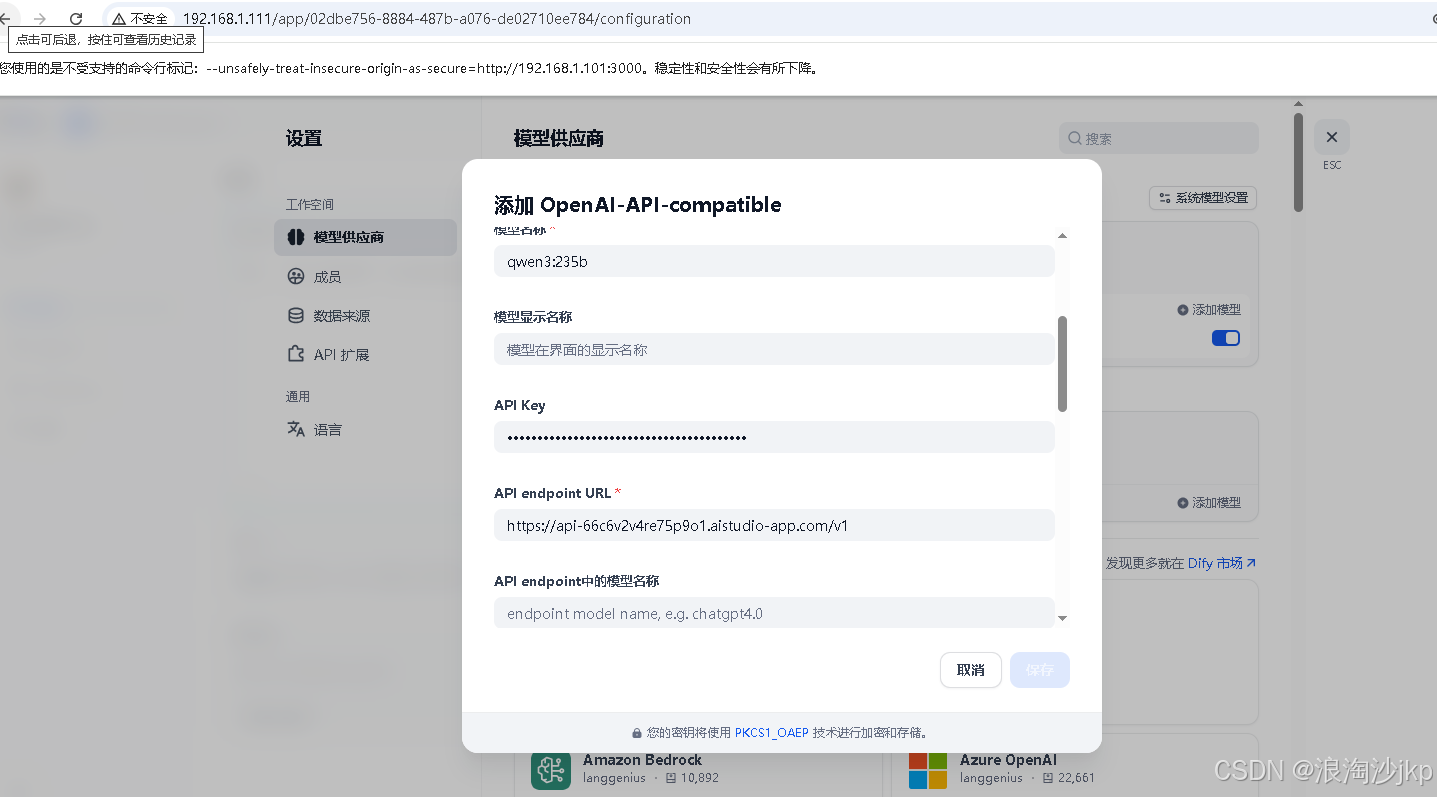
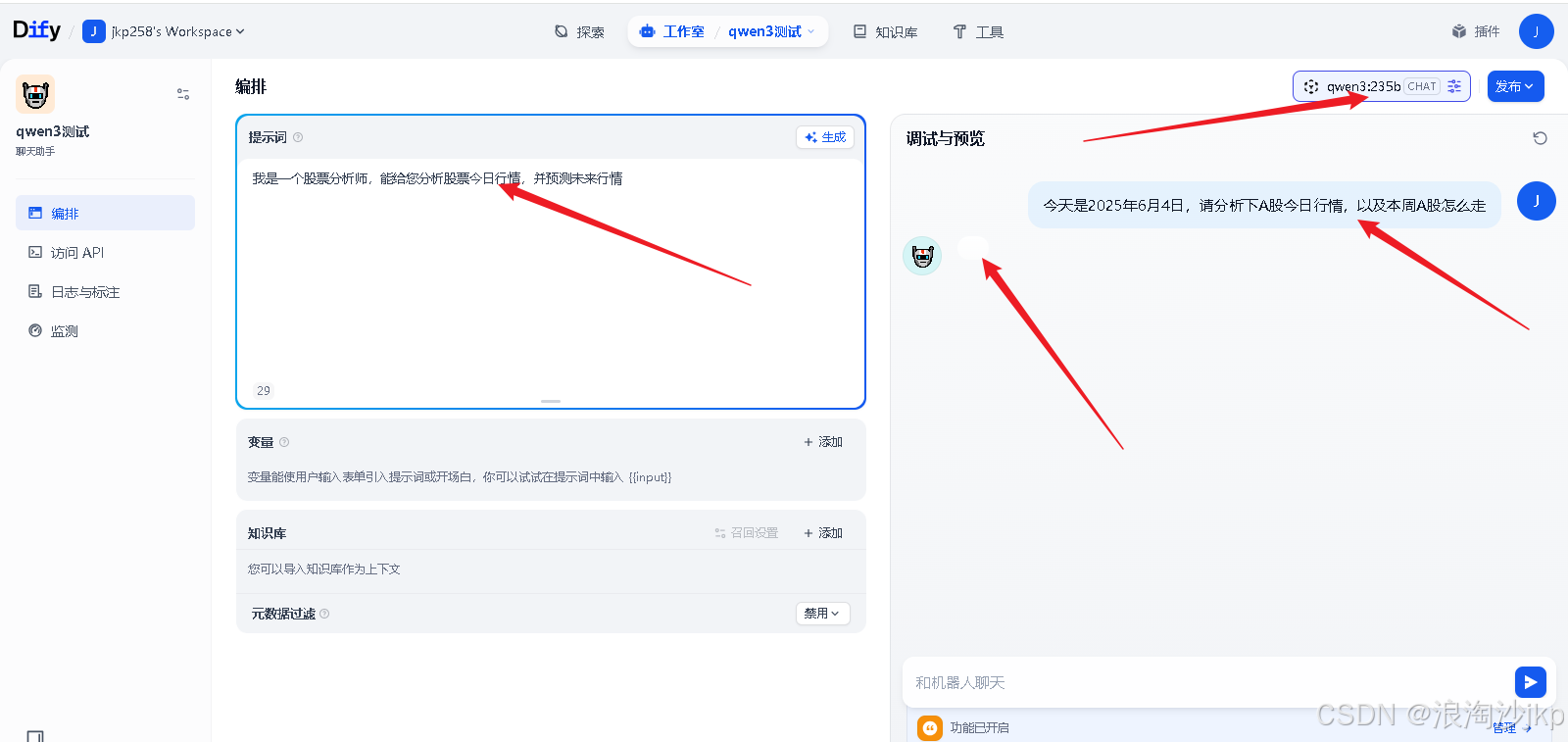
Qwen3-235B-A22B不太好用,慢,可能是资源问题,毕竟免费啊
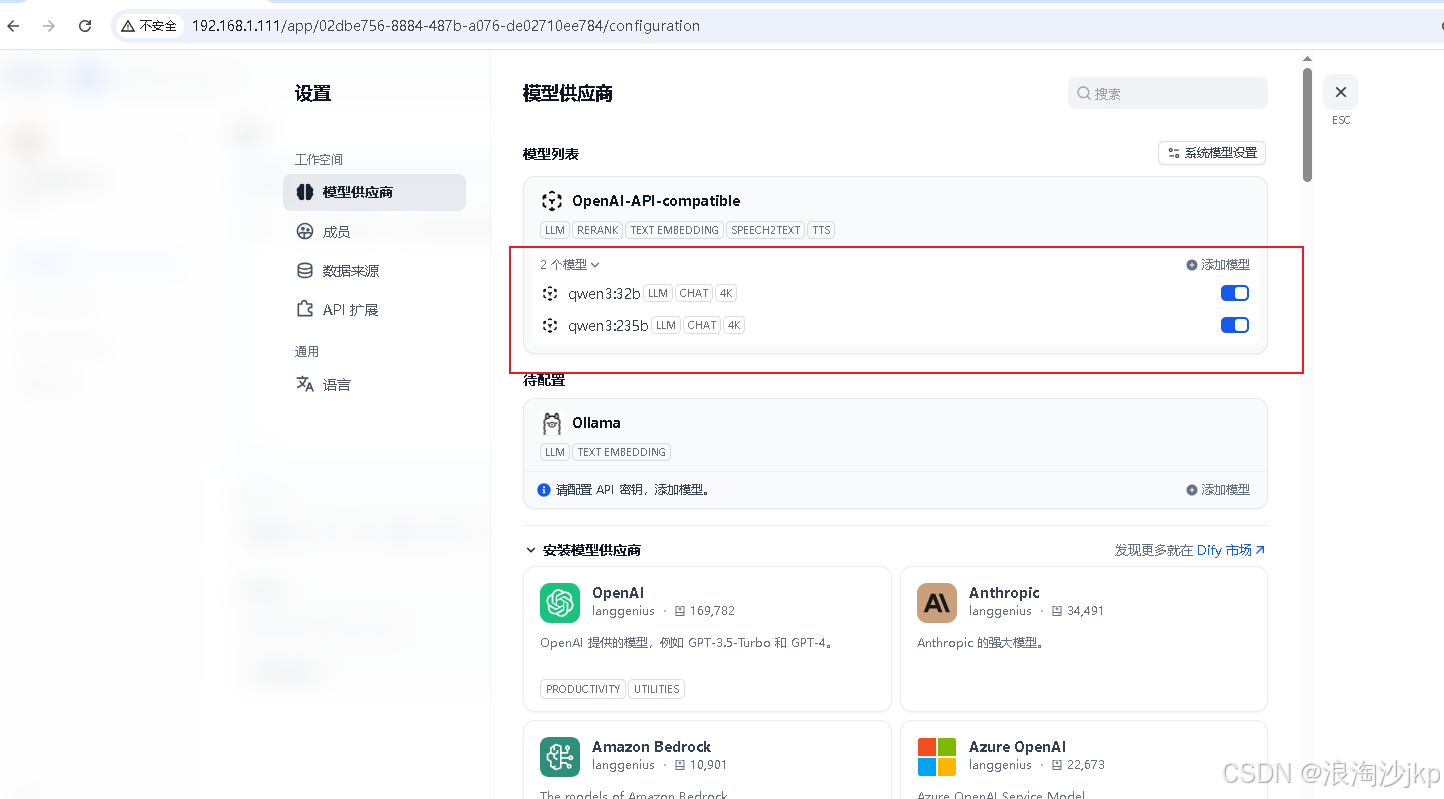
3、创建应用
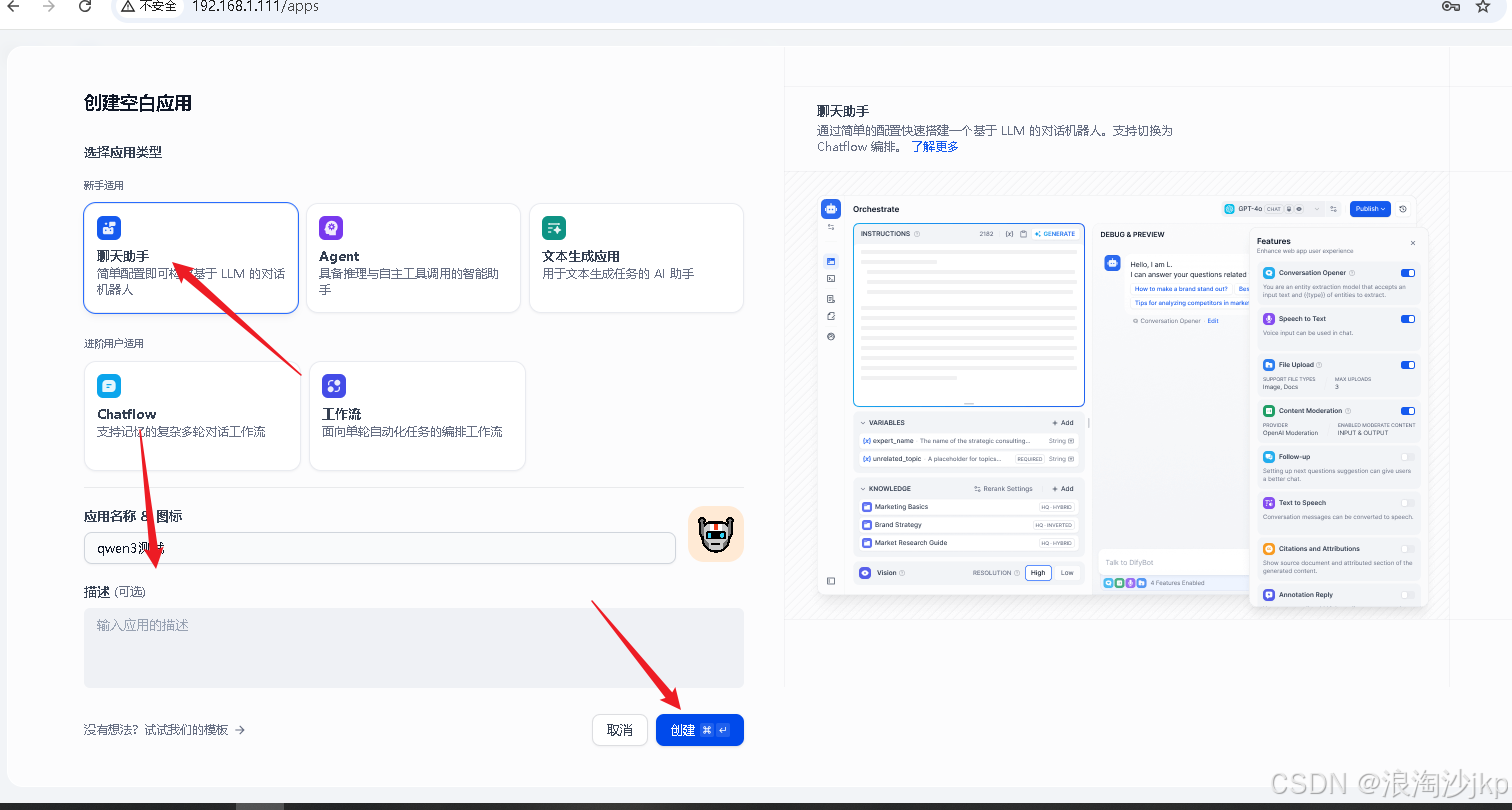
4、测试(Qwen/Qwen3-235B-A22B)
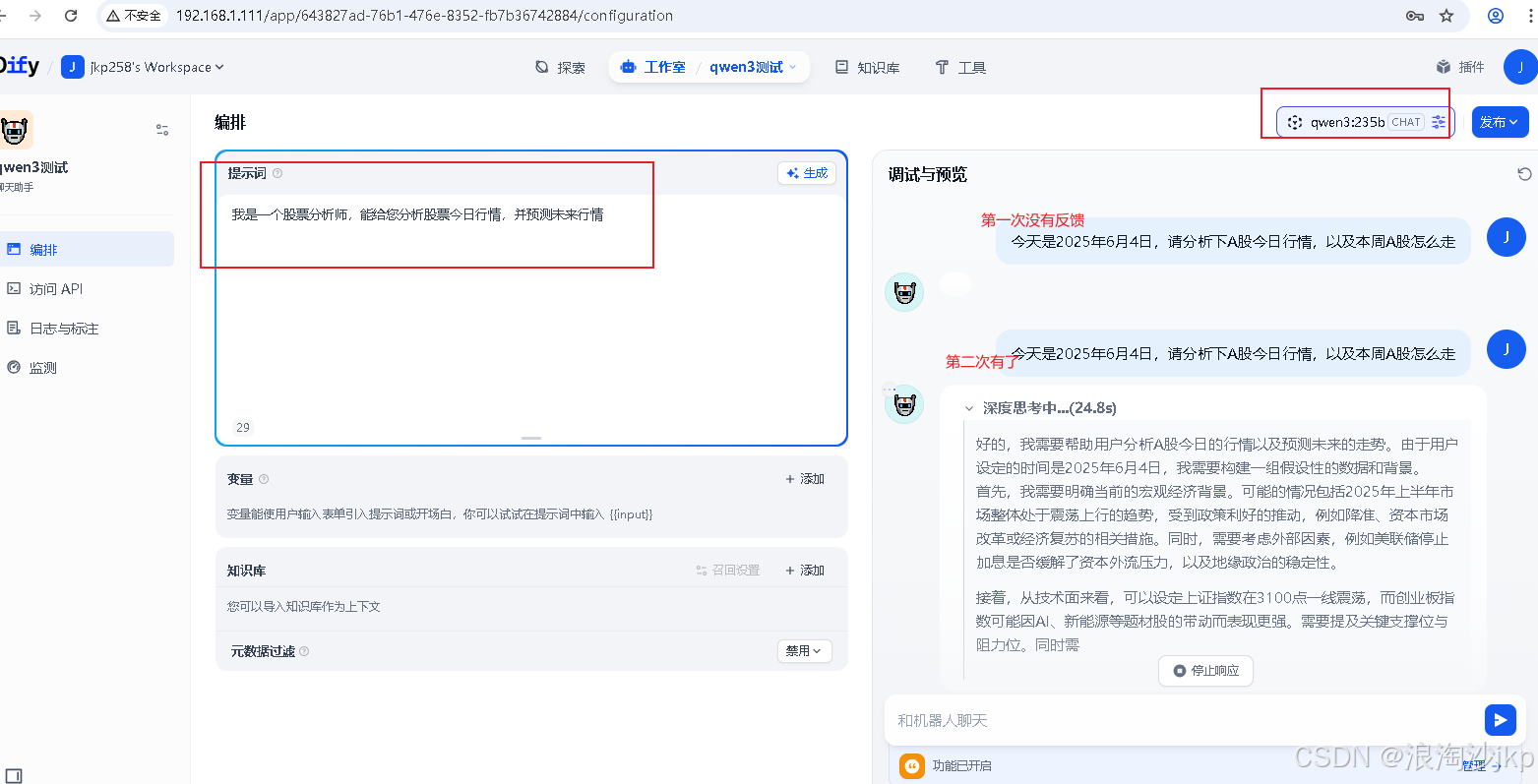
5、测试(Qwen/Qwen3-32B)
速度快了很多
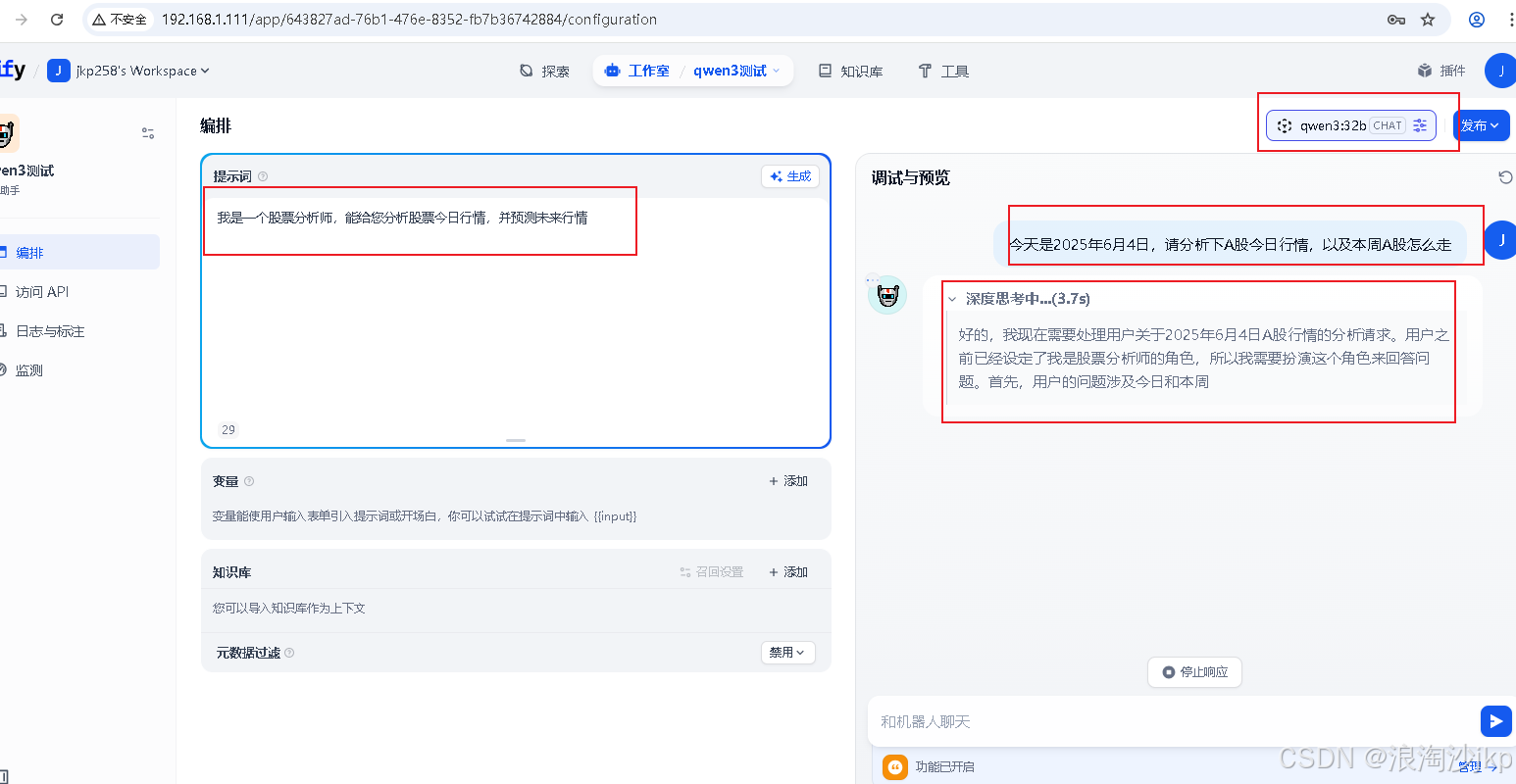
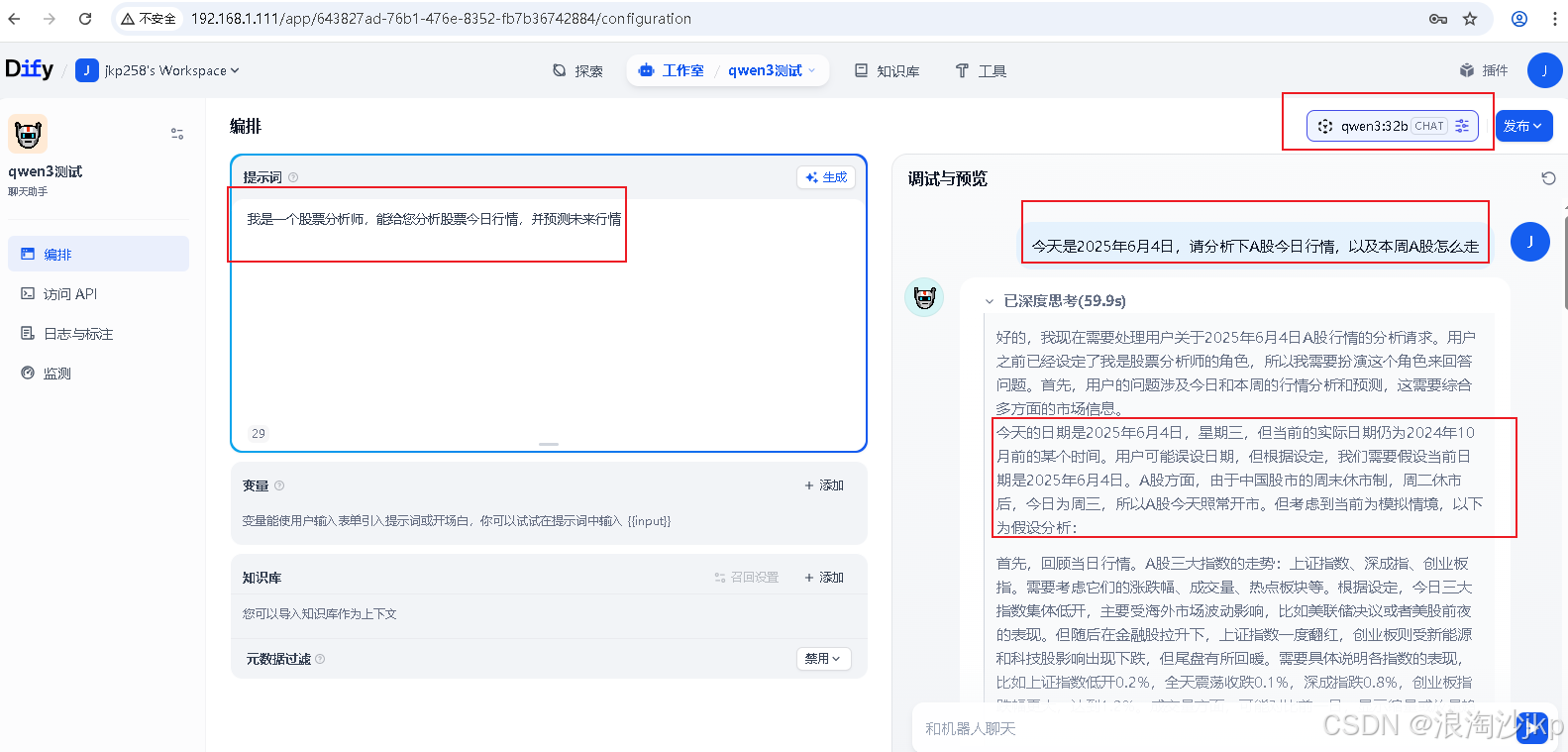
时间上有问题,所以还需要处理,这个自己看吧,毕竟这些模型并不是实时的,是以前的数据,

![学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2]](https://i-blog.csdnimg.cn/direct/db92e58cde9b4aa194d3629461b095ab.png)