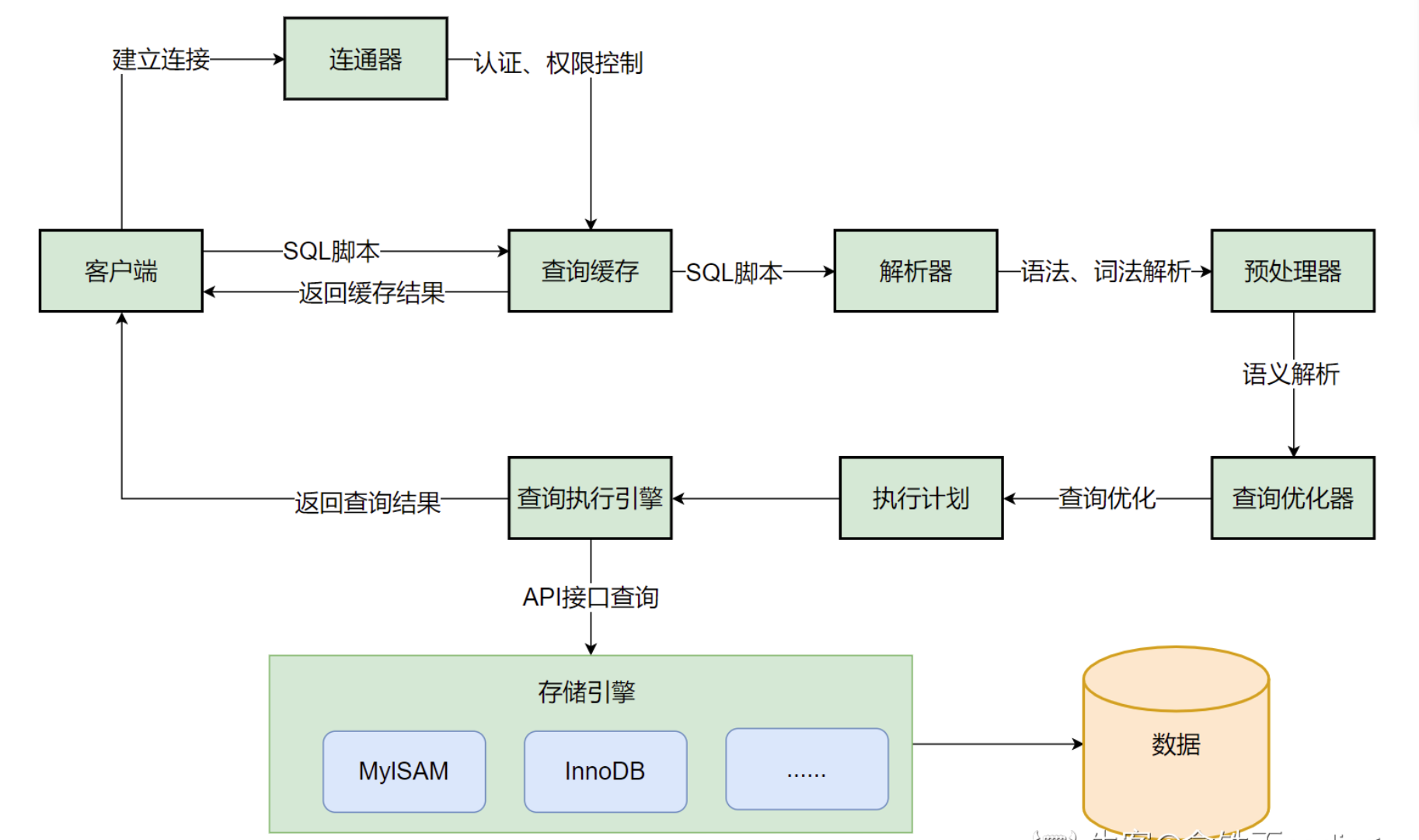
一、环境准备
1. 硬件要求(单节点建议)
- CPU:至少2核(生产环境4核+)
- 内存:至少4GB(生产环境建议16GB+,且为偶数,如8GB、16GB)
- 磁盘:至少50GB SSD(数据盘,建议使用高速存储)
- 系统:Linux(推荐CentOS 7+/Ubuntu 20.04+),不建议Windows生产环境
2. 软件版本
- Elasticsearch:7.6.1+(本文以7.8.0为例)
- JDK:必须为Java 11+(Elasticsearch 8.x需Java 17+)
二、安装前准备
1. 下载安装包
- 官网下载:Elasticsearch下载页
- 示例命令(以7.8.0为例):
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.8.0-linux-x86_64.tar.gz
2. 创建非root用户(重要!)
- Elasticsearch禁止以
root用户启动,需创建专用用户:useradd es # 创建用户 passwd es # 设置密码(输入两次密码)
三、集群部署步骤(以3节点为例)
1. 解压与重命名
tar -zxvf elasticsearch-7.8.0-linux-x86_64.tar.gz -C /opt/module # 解压到指定目录
mv /opt/module/elasticsearch-7.8.0 /opt/module/es-cluster # 重命名为es-cluster
2. 配置文件详解(3节点需分别修改)
-
路径:
/opt/module/es-cluster/config/elasticsearch.yml -
通用配置(所有节点相同):
cluster.name: cluster-es # 集群名称,同一集群内必须一致 network.host: 0.0.0.0 # 绑定所有IP,允许外部访问 http.cors.enabled: true # 启用CORS跨域 http.cors.allow-origin: "*" # 允许所有来源访问 http.port: 9200 # HTTP服务端口(默认9200,可保持默认) transport.tcp.port: 9300 # 节点间通信端口(默认9300,可保持默认) http.max_content_length: 200mb # 最大请求体大小 -
节点差异化配置(每个节点唯一):
节点 node.name network.host(示例IP) cluster.initial_master_nodes discovery.seed_hosts(填写所有节点IP:9300) node-1 node-1 192.168.59.142 [“node-1”] [“192.168.59.142:9300”, “192.168.59.145:9300”, “192.168.59.146:9300”] node-2 node-2 192.168.59.145 [“node-1”] 同上 node-3 node-3 192.168.59.146 [“node-1”] 同上 关键参数说明:
node.master: true:允许该节点参与主节点选举(建议至少2个节点设置为true)。node.data: true:允许该节点存储数据(若为纯协调节点,可设为false)。cluster.initial_master_nodes:初始化集群时指定主节点候选列表(仅首次启动需配置,后续可删除)。discovery.seed_hosts:节点发现列表,用于自动发现集群内其他节点。
3. 系统权限与资源限制
-
设置文件权限:
chown -R es:es /opt/module/es-cluster # 赋予es用户所有权 -
修改系统限制(所有节点执行):
vi /etc/security/limits.conf # 编辑系统限制文件添加以下内容(提升文件句柄和进程数限制):
es soft nofile 65536 es hard nofile 65536 es soft nproc 4096 es hard nproc 4096 -
修改虚拟内存限制:
vi /etc/sysctl.conf # 编辑系统内核参数添加:
vm.max_map_count=655360 # 提升内存映射区域限制应用修改:
sysctl -p
四、启动集群
1. 切换至es用户
su - es
2. 启动单节点(3个节点分别执行)
/opt/module/es-cluster/bin/elasticsearch -d # 后台启动
3. 检查启动状态
-
查看日志(默认路径:
/opt/module/es-cluster/logs/elasticsearch.log):tail -f /opt/module/es-cluster/logs/elasticsearch.log搜索关键词
started,若出现[node-1] started表示启动成功。 -
检查HTTP端口(9200):
curl http://localhost:9200输出JSON信息表示服务运行正常。
-
检查集群节点状态:
curl http://localhost:9200/_cat/nodes?v预期输出类似:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 192.168.59.142 20 75 5 0.01 0.02 0.05 mdi * node-1 192.168.59.145 18 73 3 0.01 0.02 0.05 mdi - node-2 192.168.59.146 17 72 4 0.01 0.02 0.05 mdi - node-3master列的*表示主节点,-表示从节点。node.role:m=主节点候选,d=数据节点,i=索引节点。
五、集群管理与可视化
1. 安装Cerebro(可视化工具)
-
下载安装包:
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tar.gz tar -zxvf cerebro-0.9.4.tar.gz -C /opt/module -
配置文件修改:
vi /opt/module/cerebro/conf/application.conf修改以下内容:
server.http.port = 9001 # 端口号(默认9000,避免冲突可改为9001) # 取消注释并修改数据路径(避免默认路径权限问题) data.path: "/opt/module/cerebro/cerebro.db" -
启动Cerebro:
/opt/module/cerebro/bin/cerebro & # 后台启动 -
访问可视化界面:
浏览器打开http://服务器IP:9001,在“Node address”中输入任一ES节点地址(如http://192.168.59.142:9200),点击“Add cluster”即可查看集群状态。
六、常见问题与解决方案
1. 启动失败:不允许root用户启动
- 原因:未使用非root用户启动。
- 解决:确保以
es用户执行启动命令(见上文“切换至es用户”步骤)。
2. 节点无法加入集群
- 原因1:防火墙未关闭或端口被屏蔽。
- 解决:关闭防火墙(临时):
systemctl stop firewalld.service systemctl disable firewalld.service # 永久关闭(生产环境需配置防火墙规则开放9200/9300端口)
- 解决:关闭防火墙(临时):
- 原因2:
discovery.seed_hosts配置错误。- 解决:检查所有节点的IP和端口是否正确,确保节点间能通过9300端口通信(可使用
telnet IP 9300测试)。
- 解决:检查所有节点的IP和端口是否正确,确保节点间能通过9300端口通信(可使用
3. 内存不足导致启动失败
- 原因:JVM内存默认配置过高(如默认
-Xms1g -Xmx1g)。 - 解决:修改
jvm.options文件(路径:/opt/module/es-cluster/config/jvm.options),降低内存配置:-Xms512m # 初始内存 -Xmx512m # 最大内存(需与初始内存一致)
七、生产环境注意事项
-
数据持久化:
- 配置
path.data到独立磁盘(如/data/es/data),避免与系统盘混用。 - 定期备份数据(使用Elasticsearch快照功能)。
- 配置
-
安全加固:
- 启用SSL/TLS加密(HTTP和传输层)。
- 配置用户认证(如Elasticsearch内置安全模块)。
- 限制公网访问,仅允许可信IP访问9200端口。
-
监控与告警:
- 使用Elasticsearch自带的
_cluster/health接口监控集群状态。 - 集成Prometheus+Grafana或Elasticsearch Monitoring进行性能监控。
- 使用Elasticsearch自带的
-
版本一致性:
- 集群内所有节点必须使用相同的Elasticsearch版本,避免兼容性问题。
八、一键部署脚本(示例)
#!/bin/bash
# 注意:生产环境需根据实际情况修改IP、端口、版本等参数
echo "开始部署Elasticsearch集群..."
VERSION=7.8.0
USER=es
GROUP=es
ES_HOME=/opt/module/es-cluster
# 1. 创建用户
useradd -m $USER
echo "设置用户密码(需手动输入)"
passwd $USER
# 2. 解压安装包
tar -zxvf elasticsearch-${VERSION}-linux-x86_64.tar.gz -C /opt/module
mv /opt/module/elasticsearch-${VERSION} $ES_HOME
# 3. 配置文件
cat > $ES_HOME/config/elasticsearch.yml <<EOF
cluster.name: cluster-es
node.name: node-1 # 需根据节点修改为node-2、node-3
network.host: 192.168.59.142 # 需替换为当前节点IP
http.port: 9200
transport.tcp.port: 9300
cluster.initial_master_nodes: ["node-1"]
discovery.seed_hosts: ["192.168.59.142:9300", "192.168.59.145:9300", "192.168.59.146:9300"]
http.cors.enabled: true
http.cors.allow-origin: "*"
EOF
# 4. 设置权限
chown -R $USER:$GROUP $ES_HOME
# 5. 修改系统限制
cat >> /etc/security/limits.conf <<EOF
$USER soft nofile 65536
$USER hard nofile 65536
$USER soft nproc 4096
$USER hard nproc 4096
EOF
# 6. 启动服务
su - $USER -c "$ES_HOME/bin/elasticsearch -d"
echo "部署完成!访问http://$(hostname -I):9200查看状态"


![[论文阅读] 人工智能+项目管理 | 当 PMBOK 遇见 AI:传统项目管理框架的破局之路](https://i-blog.csdnimg.cn/direct/cc8d4ac7aa0348389cf21f6e6e006c01.png)